六大主题报告,四大技术专题,AI开发者大会首日精华内容全回顾

9月6-7日,2019中国AI开发者大会(AI ProCon 2019) 在北京拉开帷幕。本次大会由新一代人工智能产业技术创新战略联盟(AITISA)指导,鹏城实验室、北京智源人工智能研究院支持,专业中文IT技术社区CSDN主办。
60+中美顶尖AI专家、知名企业代表、逾千名 AI 开发者齐聚现场,就人工智能的最新技术及深度实践,进行为期两天的全方位解读及论证。大会将企业转型、提高企业生产效能、驱动产业变革的落地AI技术带到千万开发者面前,让这些实实在在的经验助力开发者技术跃迁以及企业智能化升级。
本次大会全力聚焦AI开发者,以“AI技术与应用”为核心,在主题报告之外,设置有 9 个技术专题论坛,深度聚焦人工智能的技术创新与行业应用,他们从研究成果到技术实践,再到产品架构设计、行业应用案例,全方位剖析深耕于企业内的 AI 技术,分享 AI 技术落地与转型的硬核实践经验。
围绕“只讲技术”的宗旨,大会邀请到具有超强 AI 落地环境国内外领军企业的重磅演讲嘉宾,包括亚马逊、Google、微软、华为、百度、阿里、小米、滴滴、美团、快手、商汤、旷视等各大国内外一线企业的技术负责人亲临现场。
六大主题报告,以及四大技术专题演讲,以上AI业内知名技术专家就所在领域的研究成果及技术应用思考进行了精彩分享。AI科技大本营特此整理了大会首日内容,以飨读者。
实力嘉宾亮相主题报告,共话AI技术落地与应用

大会伊始,CSDN 创始人&董事长、极客帮创始合伙人蒋涛以《AI 时代的开发者机会》为题开场致辞。蒋涛表示开发者是对技术变革最敏感的人群,在CSDN 2700万用户中,有230万开发者正在阅读、撰写与研究 AI 技术。
为什么AI时代如此重要?蒋涛说道:“AI可能是比移动互联网、比我们过去面临的技术革命更深远的一次革命,AI会改变每一个行业,每个行业的领航者都将是行业大脑系统创新者,今后企业的竞争将成为行业大脑的竞争。”由此带来了强烈的AI人才需求,以BAT、字节跳动为代表的互联网企业,加上以华为、网易、美团、平安、滴滴、商汤等数十种不同领域不同类型的企业均对AI人才有着巨大需求量。

鹏城实验室人工智能研究中心副主任田永鸿教授发表《鹏城云脑——打造新一代人工智能基础理论开源开放创新平台》主题演讲。
田永鸿教授表示,人工智能是当前国际科技竞争的重点领域,我们需要加快建立新一代人工智能关键共性技术体系,在短板上抓紧布局。
面对高水平人才不足,AI基础理论和原创算法差距较大,高端芯片、关键部件、高精度传感器等基础薄弱,未形成具有国际影响力的人工智能开源开放平台等问题。对此,鹏城实验室从平台筑基、标准张脉、开源赋能三个维度入手,着力建设具有国际影响力的 AI 超算平台,支撑 AI 基础研究与重大应用需求;建立 AI国家/团体标准,齐心协力,求同存异,加速开放共享;以开源开放形式AI赋能应用场景,促进AI发展,构建AI生态。

亚马逊首席科学家李沐以《构建深度学习开源生态的努力和思考》为题,立足于深度学习技术,与大家共同探讨他在构建深度学习开源生态的经验。
李沐自2014年进入深度学习领域,从降低深度学习上手门槛、减少深度学习机器成本这两点出发,在过去五年探索出一些开源的深度学习工具,包括Apache MXNet、GluonNLP、书籍《动手学深度学习》,来帮助不同层次的开发者。
另外,他谈到机器成本是学习成本外的障碍,机器成本下降比不过算法复杂度的增加,在新硬件上优化快速变化的深度学习模型很困难。对此,专门AI定制的芯片或者边缘计算可以有效缓解,他们还采用编译器解耦计算实现和硬件优化来促使支持新算法和新硬件更简单。最后他表示,深度学习开源的落地场景、用户需求仍在快速变化,没有尘埃落定,开发者应有开放的心态来拥抱这些改变。

华为云通用AI服务总经理、语音语义创新Lab主任、首席科学家袁晶以《AI的落地和落地的AI》为题,立足于人工智能技术,与大家共同探讨人工智能技术与行业AI落地实践。
AI是一种新的生产力,改变将涉及各个行业。例如教育、健康、媒体、制药、物流、金融等各行各业都将在AI的加持下向更加智慧的方向发展。
袁晶强调,探索AI落地的唯一方式便是实践,他特别介绍了华为全栈全场景AI,其中应用使能提供全流程服务(ModelArts),分层API和预集成方案;MindSpore支持端、边、云独立的和协同的统一训练和推理框架;CANN是芯片算子库和高度自动化算子开发工具;Ascend是基于统一、可扩展架构的系列化AI IP和芯片。
华为开放多年AI研发积累,将更多的开放能力全面释放。其中包括面向所有AI开发者打造的一站式AI开发平台ModelArts,将大幅提升AI开发效率,降低开发门槛;HiLens端云协同AI开发及应用平台,提供一站式AI应用开发、分发、部署、管理平台,Skill开发、Skill市场、设备管理、数据管理等功能。华为全栈全场景AI服务与面向开发者的种种权益,华为将自己的能力开放出来,不仅可以让开发者们紧抓AI技术红利,更能促使整个AI行业在实践中快速落地。

百度深度学习技术平台部总监马艳军以《飞桨大规模分布式训练和高速推理引擎》为题,分享了开源深度学习平台飞桨的核心框架设计和技术。
马艳军表示,深度学习框架极大降低了研发门槛,但放眼深度学习开源框架现状,国外的居多,开源深度学习框架飞桨则具备五大优势:兼具动态图和静态图两种计算图的优势,精选应用效果最佳的算法模型并官方支持,大规模稀疏参数场景工业实践全面开源,端到端部署,提供系统化深度学习技术服务的平台。

随后,乂学教育-松鼠AI联合创始人&CTO樊星立足于人工智能技术,为在场开发者分享了AI+教育的背景下,人工智能技术对学习效率提升的革新之路。
会上,樊星列举了传统教育中的困境,并借助AI得以突破以上难题。他随后介绍了基于松鼠AI智适应学习引擎架构,利用人工智能技术破解难题。其中,AI智适应学习引擎架构第一层基础数据中的Content Map、Learning Map、Mistake Reasoning Ontology,将形成行为目标,利用数据收集与分析,评估学生状态,尝试推荐学习行为。
樊星认为,利用AI解决“好”教育迫在眉睫,AI将会为教育带来这样的革命:学生少做80%的题目;一考定终身的现象将会消失;教育将变得更加透明;每个孩子对学习上瘾,掌握真正的学习能力与方法。

驭势科技联合创始人、董事长、CEO吴甘沙则讲述了无人驾驶产业化的AI挑战和机遇。吴甘沙表示,无人驾驶要尊重汽车产业长期存在的规律 ,要有敬畏之心。如今无人驾驶技术中,AI 感知不是重要的问题,决策才是重要的问题。而传统AI是基于数据和规则,现在需基于学习,再是博弈+学习来设计。传统无人车关注的是舒适性、安全性,现在需关注其竞争性和社会性。
谈及下一步的AI发展,吴甘沙表示,现在的AI还很笨,根据条条框框来训练。后续他们将从背景知识和常识,模仿学习、强化学习,因果推理,基于迁移学习的举一反三等方面来提升AI的算法能力。
紧接着,CSDN重磅发布《CSDN 2019 Top 30+ 案例评选榜单》,该榜单是由CSDN联合多个行业内技术专家,根据创新性、先进性、 引领性、效率性四大标准,从数百个优秀案例中评选出来的会影响未来社会发展变革性的 AI、IoT产品及解决方案。
四大技术专题,19位重磅嘉宾的技术风暴
知识图谱技术专题
出品人:华为云通用 AI 服务总经理、语音语义创新 Lab 主任、首席科学家 袁晶
为了提升效率、专业传承、管理优化,我们需要从数据化转型走向知识化转型。对此,华为云提出全栈、全生命周期知识计算解决方案。该方案华为云知识图谱云服务,支持全量或增量,多源融合,是基于高性能自研图引擎研发的。最后,他分享了其在企业场景中的落地应用,在石油勘探、生物医疗领域、政务知识图谱构建,交互式智慧运营中心,灵活配置对话服务,华为云智能外呼机器人等均有实践落地应用。
复旦大学教授、博士生导师,复旦大学知识工场实验室负责人 肖仰华
随着大数据时代的到来,使得自动化知识获取成为可能,知识工程有望突破知识库的规模与质量瓶颈。知识工程在知识图谱技术引领下进入大数据知识工程全新阶段(BigKE),BigKE将显著提升机器认知智能水平。
OpenKG 联合创始人王昊奋
人工智能时代的感知型企业需要融合使用全量数据,将面临多源异构数据难以融合、数据模式动态变迁困难、非结构化数据计算机难以理解、数据使用专业程度过高、分散的数据难以统一消费利用的挑战。基于知识图谱的认知智能中台完成知识图谱简单使用到生态打造的跃迁,可实现敏捷并规模化创新,并最终实现大数据智能。
美团点评 NLP 中心知识图谱团队负责人 张富峥
美团大脑在搜索推荐场景中有精确性、多样性、可解释性三大应用:为商家和商品引入了更多的语义关系,深层次发现用户兴趣;提供不同的关系连接种类,利于搜索推荐结果的发散,避免结果越来越限于单一类型;连接用户的兴趣历史和搜索推荐结果,提高用户对结果的满意度。
阿里巴巴业务平台商品知识图谱负责人 张伟
阿里巴巴知识引擎由4个模块、10种算法和其他工具搭建。在知识建模上,用TransE来分析上下位对、同义词对;知识获取运用到Transformer的文本分类模型、短文本NER+Entity Linking;知识融合上,基于ML的实体对齐、基于规则的实体对齐的创新技术实现。张伟还分享了知识推理Jena-RDF-Json框架,这个推理引擎是基于规则槽填充、规则、深度学习生成关系边,基于规则画像,规则过滤算法结果,将知识放大。这些技术应用在零售场景中,能更智能地分析用户搜索行为和挖掘,让用户更精准的搜索结果。
AI开源技术专题
鹏城实验室人工智能研究中心副主任 邱景飞
为什么要开源?邱景飞总结了五点:丰富行业应用,带动行业生态;集中资源形成联盟;技术共享和同业交流;作为产品特性获取竞争优势;体现社会责任及优化形象。会上,邱景飞还重点向现场的开发者介绍了如何开源的6项要点:第一,确定开源项目;第二,确定代码平台;第三,选择许可证;第四,编写项目说明;第五,编写贡献说明;第六,建立行为准则。
阿里妈妈搜索广告排序和机制算法负责人 林伟
图深度学习面临着许多技术挑战,比如数据结构方面,是超大规模、动态更新的,同时计算模式也发生了变化,这就对平台提出了新的要求。当前,图深度学习有基于 Random Walk、Neighbor Aggregation 两种主要 Pattern。Euler 采用分层灵活可扩展设计、大规模高性能异构图学习、灵活多样的图算法支持、通用 GNN 训练加速的设计理念,支持图分割和高效稳定的分布式训练,可以轻松支撑数十亿点、数百亿边的计算规模。
亚马逊AWS AI应用科学家 马超
与传统基于张量 (Tensor) 的神经网络相比,图神经网络将图 (Graph) 作为输入,从而学习和推演图中节点之间的关系,该方法已被证明在许多场景可以取得很好的效果。然而,使用传统的深度学习框架(比如 TensorFlow、Pytorch、MXNet)并不能方便地进行图神经网络的开发和训练,而 DGL 作为专门面向图神经网络的框架,可以很好地弥补这一缺陷。由此,马超从 API、系统优化、可扩展性等多个维度深入分享如何使用 DGL 进行大规模神经网络的开发和训练。
小米深度学习框架负责人 何亮亮
何亮亮向开发者们详细介绍了MACE开源深度学习框架的设计思路、优化方法以及典型应用案例。这将帮助开发者了解移动端深度学习框架的原理和特点,以及端侧深度学习应用的落地关键技术和实践,助力开发者更高效地开发端侧人工智能应用。
华为MindSpore资深架构师 于璠
AI行业研究到全场景应用存在巨大鸿沟,开发门槛高、运营成本高、部署时间长的业界挑战;新编程范式、新执行模式、新协作方式的技术创新,促使着MindSpore跨越应用鸿沟,助力普惠AI。于璠详细介绍了MindSpore的设计理念,第一,新编程范式,AI算法即代码,降低AI 开发门槛;第二,新执行模式,Ascend Natave的执行引擎;第三,全场景按需协同,更好的资源效率和隐私保护。
5G驱动AIoT技术专题
出品人:微软(中国)首席技术官 韦青
在5G的普及过程中会逐渐产生全新的连接与计算模式。应用的革命:沉浸式,触觉式,合作式
;智能的普及:AI/ML驱动的无线电、天线、资源和运维;蜂窝通讯从户外到户内。
北京邮电大学教授、博士生导师 孙松林
他介绍了物联网的发展规律及特点:流量总量低、时延容忍度高,终端CT大部分时间静默,每天传送的数据量极低,且允许一定的传输延迟;终端静止、位置固定,少量终端都需要移动性,大量的物联网终端长期处于静止状态;逆向流量,与“人”的连接不同,物联网的流量模型不再是以下行为主,可能是以上行为主。
华为IoT标准产业与创新总监 张朝辉
为什么通信等规模化行业是AI应用效果显著的第一波?在张朝辉看来,通信行业的网络效应,要求高度的标准化保障全网全程的一致性,从而形成了规模,尤其是一致性数据的规模。internet服务天然的与设备解耦基于通信基础设施,也具备了规模效应。规模化又加速了迭代和创新。行业市场AIoT规模之路在何方?一言以蔽之,他认为碎片化阻碍了行业市场走向AI创新的正循环。如何消除碎片化,形成规模化数据是产业生态需要面对的关键问题
云知声董事长、CTO 梁家恩
AIoT的空间很大,但是我们仍然任重而道远。我们要把手机应用分散到各个IoT当中,应该是整体的智能应用,用户真正互动起来让模式发生改变,这个产业才能真正形成,底层无论是边缘计算还是数据,这些真正起来之后,才能够有效支撑IoT的发展。
金山云AIoT事业部高级研发总监 肖江
AIoT是IoT的发展方向,IoT需要AI来提升其价值。5G是连接AI与IoT的桥梁,其高带宽、高可靠低时延、大连接,开拓了AIoT更广阔的应用领域。AIoT目前仅是起步阶段,有很大的发展空间,也面临着重大挑战, 创新永远在路上。
推荐系统技术专题
出品人:阿里妈妈深度学习算法平台负责人 朱小强
互联网技术发展到今天,个性化非常重要,如何充分洞察用户的兴趣、习惯提供更好的个性化体验,是需要融入血液的事情。推荐系统本身其实是一个信息配置的问题,如何能够把合适的物品推荐给合适的用户。当商品数量量级已经达到人无法计算的程度,我们需要用数据和算法解决这个问题。这是推荐系统遵循的基本范式。
快手科技推荐架构负责人 任恺
他分享了短视频推荐系统架构设计与前沿技术中的探索。今年6月,快手日活突破了2亿,对推荐系统提出巨大挑战。快手采用四种手段对整个推荐系统进行优化。第一,采用多阶段的排序方式优化排序;第二,快手通过计算存储分离的形式提高拓展性,逐步对推荐系统各个服务进行拆分,使得每个服务单独进行扩展;第三,数据和模型实时化,把数据和模型的时效性推到极致,有效将最新最热的视频推荐给用户;第四,软件和硬件结合,异构计算与异构存储提升单机性能,在硬件发展中挖掘到新的性能,构建出更强大的推荐服务。
华为诺亚方舟实验室推荐与搜索项目组资深研究员 唐睿明
他介绍了华为诺亚方舟实验室在深度学习、强化学习与 AutoML 结合上的最新进展,如聚焦在建模特征之间相互关系的PIN模型,交互特征自动化探索 AutoGroup,正在计划进行的 AutoML 工作等。在他看来,深度学习算法将成为业界主流,平台+算力+算法+数据是深度学习推荐系统能力的核心竞争力。
京东集团高级总监 殷大伟
殷大伟介绍了工业界电商的架构。他表示,在工业界,电商的架构基本上是在数百亿级的商品中为用户推荐感兴趣的商品。在此过程中,京东用到了检索,如基于商品图谱(知识图谱)的方法,定位在商品上的关系,以及基于Embedding的方法。因为电商场均考虑的因素非常复杂,如回归时长、App驻留时长等,输入信号也相应非常复杂,京东会用Statc-action Embedding的方法,预测用户的驻留时长,并采取相应的措施。
精彩技术分享继续
9月7日,机器学习、计算机视觉、自然语言处理、AI+DevOps、AI+小程序五大技术专题等你来,精彩技术内容分享不容错过。

点击阅读原文,关注AI开发者大会第二日精彩内容
相关文章:

Git安装配置(Linux)
使用yum安装Git yum install git -y 编译安装 # 安装依赖关系 yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel # 编译安装 tar -zxf git-2.0.0.tar.gz cd git-2.0.0 make configure ./configure --prefix/usr make make install 配置Git…
卷积神经网络(CNN)代码实现(MNIST)解析
在http://blog.csdn.net/fengbingchun/article/details/50814710中给出了CNN的简单实现,这里对每一步的实现作个说明:共7层:依次为输入层、C1层、S2层、C3层、S4层、C5层、输出层,C代表卷积层(特征提取),S代表降采样层…
一点感悟和自勉
来学习linux,其实目的很简单,也很现实,就是为了学成之后找一份好的工作,能够养家糊口。 接触了几天,感觉挺难的,可能是因为我没有基础的原因吧,以前电脑只是用来打游戏和看电影,第一…

入门数据分析师,从了解元数据中心开始
作者丨凯凯连编辑丨Zandy来源 | 大数据与人工智能(ID:ai-big-data)【导读】上一篇文章,我们简单讲解了数据仓库的概念,并介绍了它的分层架构设计,相信大家对数据仓库体系已经有一定的了解了。那么ÿ…
PhpMyAdmin的简单安装和一个mysql到Redis迁移的简单例子
1.phpmyadmin的安装 sudo apt-get install phpmyadmin 之后发现http://localhost/phpmyadmin显示没有此url,于是想到本机上能显示的网页都在/var/www文件夹内,因此执行命令行:sudo ln /usr/share/phpmyadmin /var/www 这样就能使用了; 之…

聊聊flink的HistoryServer
为什么80%的码农都做不了架构师?>>> 序 本文主要研究一下flink的HistoryServer HistoryServer flink-1.7.2/flink-runtime-web/src/main/java/org/apache/flink/runtime/webmonitor/history/HistoryServer.java public class HistoryServer {private st…
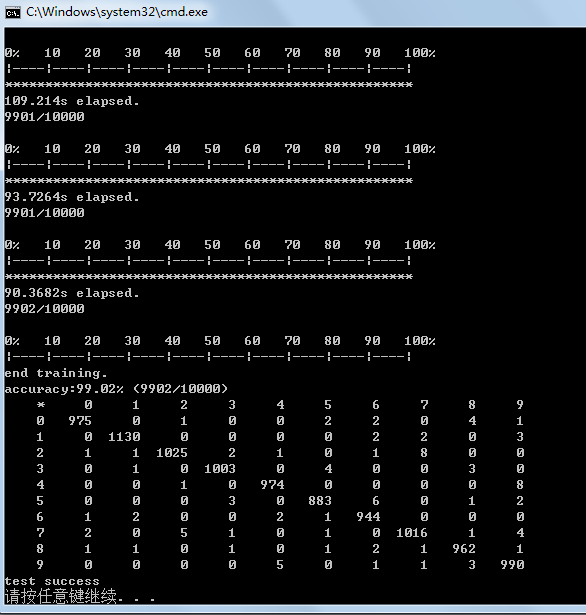
深度学习开源库tiny-dnn的使用(MNIST)
tiny-dnn是一个基于DNN的深度学习开源库,它的License是BSD 3-Clause。之前名字是tiny-cnn是基于CNN的,tiny-dnn与tiny-cnn相关又增加了些新层。此开源库很活跃,几乎每天都有新的提交,因此下面详细介绍下tiny-dnn在windows7 64bit …

如何学习SVM?怎么改进实现SVM算法程序?答案来了
编辑 | 忆臻来源 | 深度学习这件小事(ID:DL_NLP)【导读】在 3D 动作识别领域,需要用到 SVM(支持向量机算法),但是现在所知道的 SVM 算法很多很乱,相关的程序包也很多,有什…
跟着石头哥哥学cocos2d-x(三)---2dx引擎中的内存管理模型
2019独角兽企业重金招聘Python工程师标准>>> 2dx引擎中的对象内存管理模型,很简单就是一个对象池引用计数,本着学好2dx的好奇心,先这里开走吧,紧接上面两节,首先我们看一个编码场景代码: hello…

读8篇论文,梳理BERT相关模型进展与反思
作者 | 陈永强来源 | 微软研究院AI头条(ID:MSRAsia)【导读】BERT 自从在 arXiv 上发表以来获得了很大的成功和关注,打开了 NLP 中 2-Stage 的潘多拉魔盒。随后涌现了一大批类似于“BERT”的预训练(pre-trained)模型,有…
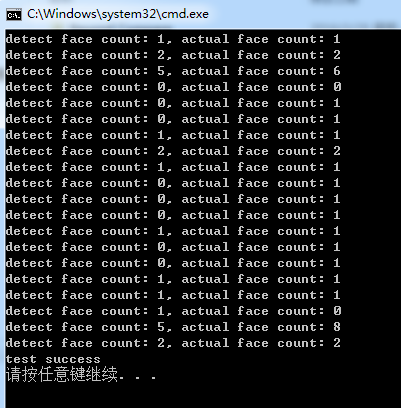
Dlib库中实现正脸人脸检测的测试代码
Dlib库中提供了正脸人脸检测的接口,这里参考dlib/examples/face_detection_ex.cpp中的代码,通过调用Dlib中的接口,实现正脸人脸检测的测试代码,测试代码如下:#include "funset.hpp" #include <string>…

20189317 《网络攻防技术》 第二周作业
一.黑客信息 (1)国外黑客 1971年,卡普尔从耶鲁大学毕业。在校期间,他专修心理学、语言学以及计算机学科。也就是在这时他开始对计算机萌生兴趣。他继续到研究生院深造。20世纪60年代,退学是许多人的一个选择。只靠知识…
centos 6.4 SVN服务器多个项目的权限分组管理
根据本博客中的cent OS 6.4下的SVN服务器构建 一文,搭建好SVN服务器只能管理一个工程,如何做到不同的项目,多个成员的权限管理分配呢?一 需求开发服务器搭建好SVN服务器,不可能只管理一个工程项目,如何做到…

cifar数据集介绍及到图像转换的实现
CIFAR是一个用于普通物体识别的数据集。CIFAR数据集分为两种:CIFAR-10和CIFAR-100。The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.CIFAR-10由…

取代Python?Rust凭什么
作者 | Nathan J. Goldbaum译者 | 弯月,责编 | 屠敏来源 | CSDN(ID:CSDNnews)【导语】Rust 也能实现神经网络?在前一篇帖子中,作者介绍了MNIST数据集以及分辨手写数字的问题。在这篇文章中,他将…

【Mac】解决「无法将 chromedriver 移动到 /usr/bin 目录下」问题
问题描述 在搭建 Selenium 库 ChromeDriver 爬虫环境时,遇到了无法将 chromedriver 移动到 /usr/bin 目录下的问题,如下图: 一查原来是因为系统有一个 System Integrity Protection (SIP) 系统完整性保护,如果此功能不关闭&#…
【译文】怎样让一天有36个小时
作者:Jon Bischke原文地址:How to Have a 36 Hour Day 你经常听人说“真希望一天能多几个小时”或者类似的话吗?当然,现实中我们每天只有24小时。这么说吧,人和人怎样度过这24个小时是完全不同的。到现在这样的说法已经…
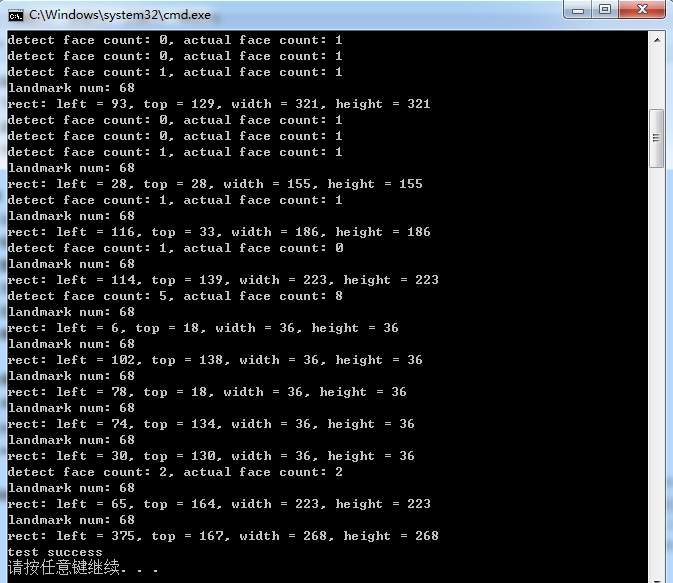
Dlib库中实现正脸人脸关键点(landmark)检测的测试代码
Dlib库中提供了正脸人脸关键点检测的接口,这里参考dlib/examples/face_landmark_detection_ex.cpp中的代码,通过调用Dlib中的接口,实现正脸人脸关键点检测的测试代码,测试代码如下:/* reference: dlib/examples/face_l…
LeetCode--004--寻找两个有序数组的中位数(java)
转自https://blog.csdn.net/chen_xinjia/article/details/69258706 其中,N14,N26,size4610. 1,现在有的是两个已经排好序的数组,结果是要找出这两个数组中间的数值,如果两个数组的元素个数为偶数,则输出的是中间两个元…

开源sk-dist,超参数调优仅需3.4秒,sk-learn训练速度提升100倍
作者 | Evan Harris译者 | Monanfei编辑 | Jane 出品 | AI科技大本营(ID:rgznai100)【导语】这篇文章为大家介绍了一个开源项目——sk-dist。在一台没有并行化的单机上进行超参数调优,需要 7.2 分钟,而在一百多个核心的 Spark 群集…
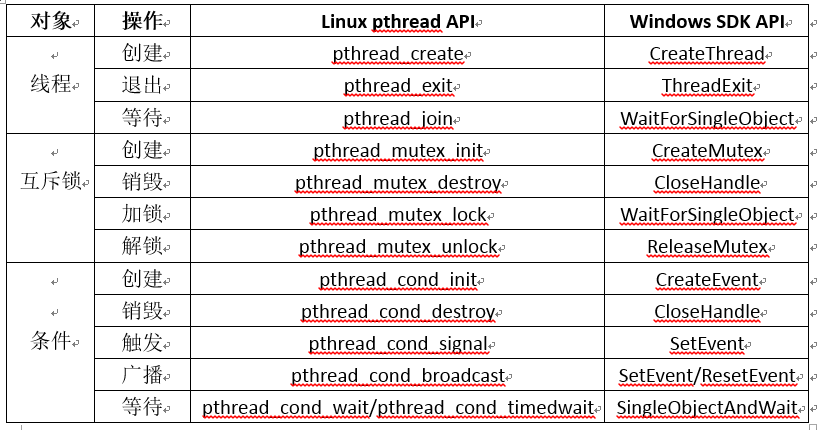
Windows和Linux下通用的线程接口
对于多线程开发,Linux下有pthread线程库,使用起来比较方便,而Windows没有,对于涉及到多线程的跨平台代码开发,会带来不便。这里参考网络上的一些文章,整理了在Windows和Linux下通用的线程接口。经过测试&am…
MySQL 性能调优的10个方法
MYSQL 应该是最流行了 WEB 后端数据库。WEB 开发语言最近发展很快,PHP, Ruby, Python, Java 各有特点,虽然 NOSQL 最近越來越多的被提到,但是相信大部分架构师还是会选择 MYSQL 来做数据存储。MYSQL 如此方便和稳定,以…

他们用卷积神经网络,发现了名画中隐藏的秘密
作者 | 神经小刀来源 |HyperAI超神经( ID: HyperAI)导语:著名的艺术珍品《根特祭坛画》,正在进行浩大的修复工作,以保证现在的人们能感受到这幅伟大的巨制,散发出的灿烂光芒。而随着技术的进步,…
机器学习公开课~~~~mooc
https://class.coursera.org/ntumlone-001/class/index

DLM:微信大规模分布式n-gram语言模型系统
来源 | 微信后台团队Wechat & NUS《A Distributed System for Large-scale n-gram Language Models at Tencent》分布式语言模型,支持大型n-gram LM解码的系统。本文是对原VLDB2019论文的简要翻译。摘要n-gram语言模型广泛用于语言处理,例如自动语音…
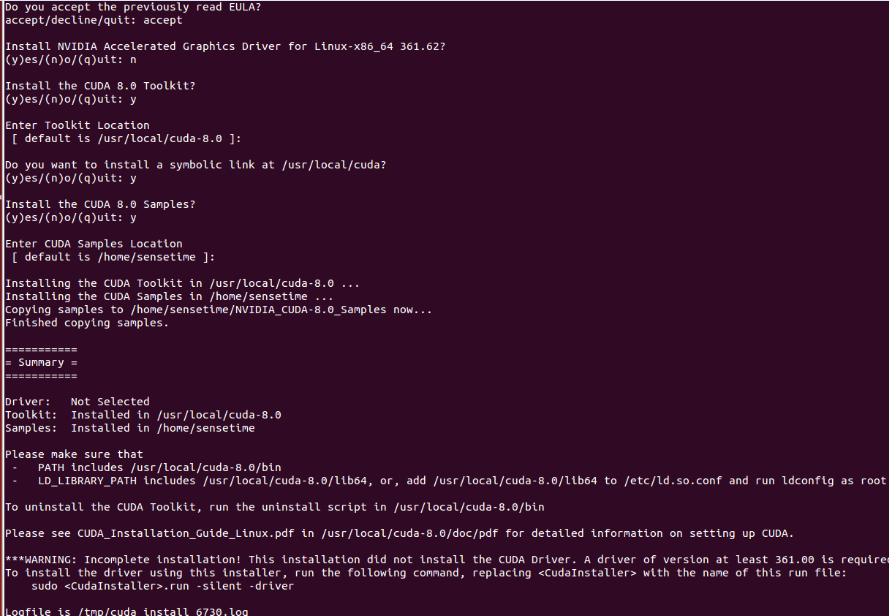
Ubuntu14.04 64位机上安装cuda8.0+cudnn5.0操作步骤
查看Ubuntu14.04 64位上显卡信息,执行:lspci | grep -i vga lspci -v -s 01:00.0 nvidia-smi第一条此命令可以显示一些显卡的相关信息;如果想查看某个详细信息,可以执行第二条命令;如果是NVIDIA卡, 可继续执行第三条命…

SQLI DUMB SERIES-5
less5 (1)输入单引号,回显错误,说明存在注入点。输入的Id被一对单引号所包围,可以闭合单引号 (2)输入正常时:?id1 说明没有显示位,因此不能使用联合查询了;可…
javascript RegExp
http://www.w3schools.com/jsref/jsref_obj_regexp.asp声明-------------modifiers:{i,g,m}1. var pattnew RegExp(pattern,modifiers);2. var patt/pattern/modifiers;------------------------例子:var str "Visit W3Schools"; //两…
Ubuntu14.04 64位机上安装OpenCV2.4.13(CUDA8.0)版操作步骤
Ubuntu14.04 64位机上安装CUDA8.0的操作步骤可以参考http://blog.csdn.net/fengbingchun/article/details/53840684,这里是在已经正确安装了CUDA8.0的基础上安装OpenCV2.4.13(CUDA8.0)操作步骤:1. 从http://opencv.org/downloads.html 下载OpenCV2.…
一篇文章能够看懂基础代码之CSS
web页面主要分为三块内容:js:控制用户行为和执行代码行为html元素:控制页面显示哪些控件(例如按钮,输入框,文本等)css:控制如何显示页面上的空间,例如布局,颜…