开源sk-dist,超参数调优仅需3.4秒,sk-learn训练速度提升100倍

【导语】这篇文章为大家介绍了一个开源项目——sk-dist。在一台没有并行化的单机上进行超参数调优,需要 7.2 分钟,而在一百多个核心的 Spark 群集上用它进行超参数调优,只需要 3.4 秒,把训练 sk-learn 的速度提升了 100 倍。

import time
from sklearn import datasets, svm
from skdist.distribute.search import DistGridSearchCV
from pyspark.sql import SparkSession
# instantiate spark session
spark = ( SparkSession .builder .getOrCreate() )
sc = spark.sparkContext
# the digits dataset
digits = datasets.load_digits()
X = digits["data"]
y = digits["target"]
# create a classifier: a support vector classifier
classifier = svm.SVC()
param_grid = { "C": [0.01, 0.01, 0.1, 1.0, 10.0, 20.0, 50.0], "gamma": ["scale", "auto", 0.001, 0.01, 0.1], "kernel": ["rbf", "poly", "sigmoid"] }
scoring = "f1_weighted"
cv = 10
# hyperparameter optimization
start = time.time()
model = DistGridSearchCV( classifier, param_grid, sc=sc, cv=cv, scoring=scoring, verbose=True )
model.fit(X,y)
print("Train time: {0}".format(time.time() - start))
print("Best score: {0}".format(model.best_score_))
------------------------------
Spark context found; running with spark
Fitting 10 folds for each of 105 candidates, totalling 1050 fits
Train time: 3.380601406097412
Best score: 0.981450024203508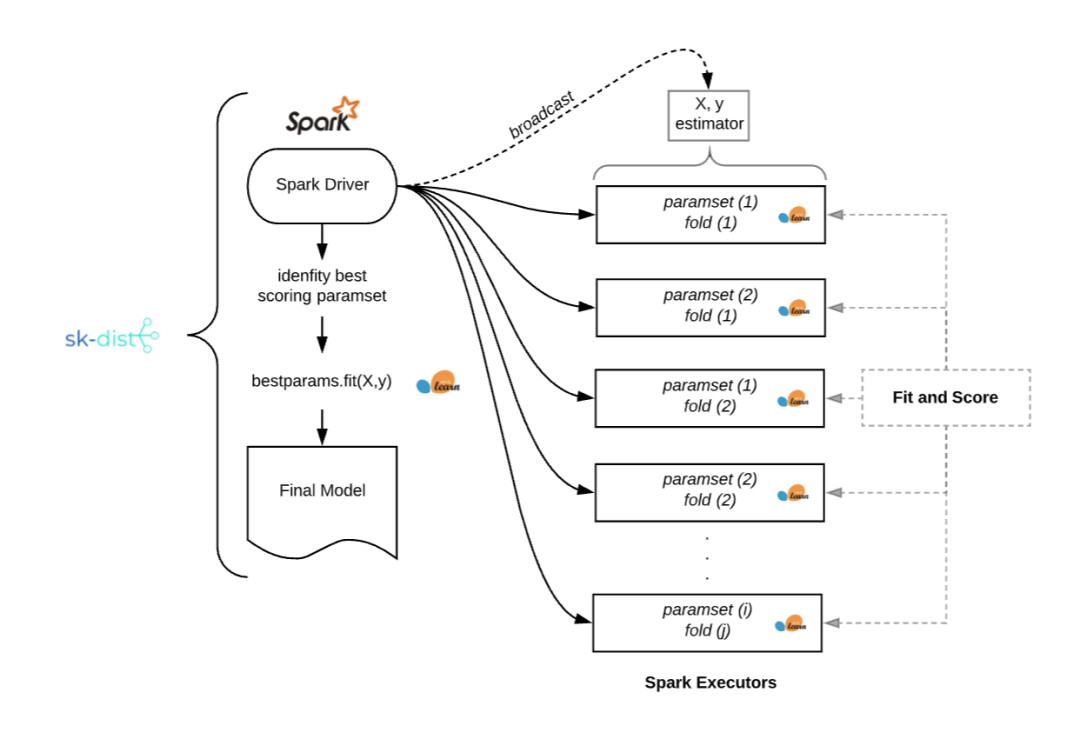
- 分布式训练:使用 Spark 分发元估计器训练。支持以下算法:使用网格搜索和随机搜索的超参数调优,使用随机森林的树集成,其他树和随机树嵌入,以及一对多、一对一的多类别问题策略。
- 分布式预测:使用 Spark DataFrames 分配拟合后的 scikit-learn 估计器进行预测。通过便携式的 scikit-learn 估计器,该方法使得大尺度的分布式预测成为可能。这些估计器可以与 Spark 一起使用,也可以不与 Spark 一起使用。
- 特征编码:使用 Encoderizer 对特征进行灵活编码。 Encoderizer 可以使用或不使用Spark 并行化。它将推断数据类型和形状,自动选择并应用最佳的默认特征变换器,对数据进行编码。作为一个完全可定制的特征联合编码器,它还具有使用 Spark 进行分布式变换的附加优势。
- 传统的机器学习: 广义线性模型,随机梯度下降,最近邻,决策树和朴素贝叶斯等方法与 sk-dist 配合良好。这些模型都已在 scikit-learn 中集成,用户可以使用 sk-dist 元估计器直接实现。
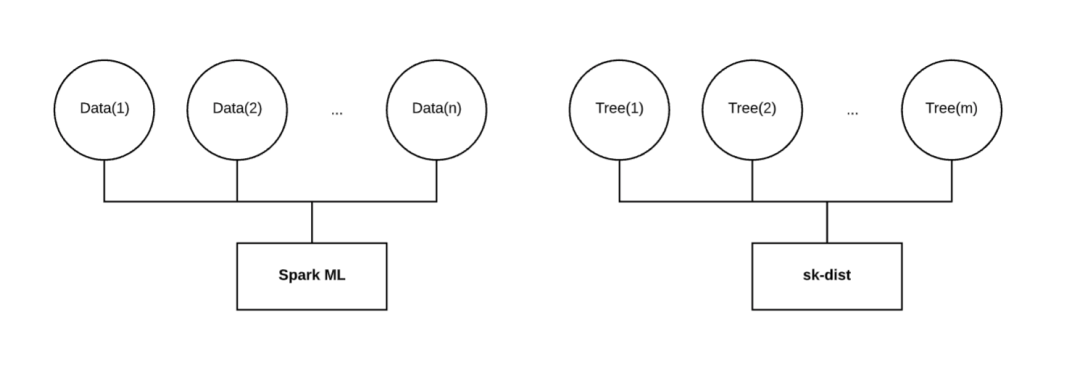
- 中小型数据:大数据无法与 sk-dist 一起使用。值得注意的是,训练分布的维度是沿着模型的轴,而不是数据。数据不仅需要适合每个执行器的内存,还要小到可以广播。根据 Spark 的配置,最大广播量可能会受到限制。
- Spark 的使用:sk-dist 的核心功能需要运行Spark。对于个人或小型数据科学团队而言,从经济上来讲可能并不可行。此外,为了以经济有效的方式充分利用 sk-dist,需要对 Spark 进行一些调整和配置,这要求使用者具备一些 Spark 的基础知识。
六大主题报告,四大技术专题,AI开发者大会首日精华内容全回顾
AI ProCon圆满落幕,五大技术专场精彩瞬间不容错过
CSDN“2019 优秀AI、IoT应用案例TOP 30+”正式发布
如何打造高质量的机器学习数据集?
从模型到应用,一文读懂因子分解机
用Python爬取淘宝2000款套套
7段代码带你玩转Python条件语句
高级软件工程师教会小白的那些事!
谁说 C++ 的强制类型转换很难懂?

相关文章:
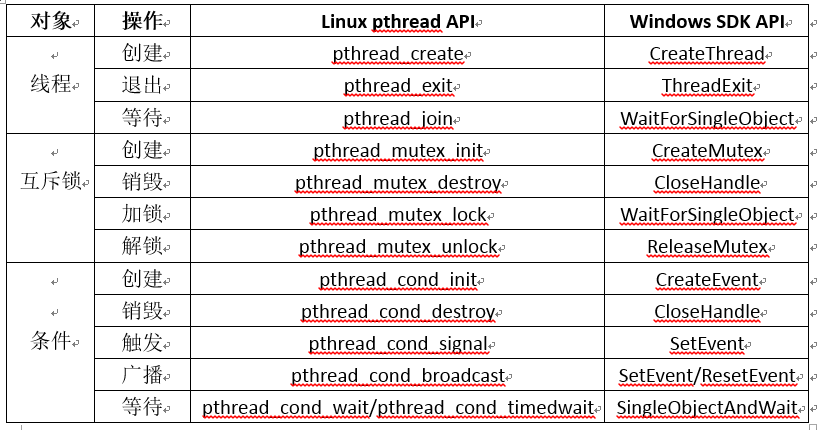
Windows和Linux下通用的线程接口
对于多线程开发,Linux下有pthread线程库,使用起来比较方便,而Windows没有,对于涉及到多线程的跨平台代码开发,会带来不便。这里参考网络上的一些文章,整理了在Windows和Linux下通用的线程接口。经过测试&am…

MySQL 性能调优的10个方法
MYSQL 应该是最流行了 WEB 后端数据库。WEB 开发语言最近发展很快,PHP, Ruby, Python, Java 各有特点,虽然 NOSQL 最近越來越多的被提到,但是相信大部分架构师还是会选择 MYSQL 来做数据存储。MYSQL 如此方便和稳定,以…

他们用卷积神经网络,发现了名画中隐藏的秘密
作者 | 神经小刀来源 |HyperAI超神经( ID: HyperAI)导语:著名的艺术珍品《根特祭坛画》,正在进行浩大的修复工作,以保证现在的人们能感受到这幅伟大的巨制,散发出的灿烂光芒。而随着技术的进步,…
机器学习公开课~~~~mooc
https://class.coursera.org/ntumlone-001/class/index

DLM:微信大规模分布式n-gram语言模型系统
来源 | 微信后台团队Wechat & NUS《A Distributed System for Large-scale n-gram Language Models at Tencent》分布式语言模型,支持大型n-gram LM解码的系统。本文是对原VLDB2019论文的简要翻译。摘要n-gram语言模型广泛用于语言处理,例如自动语音…
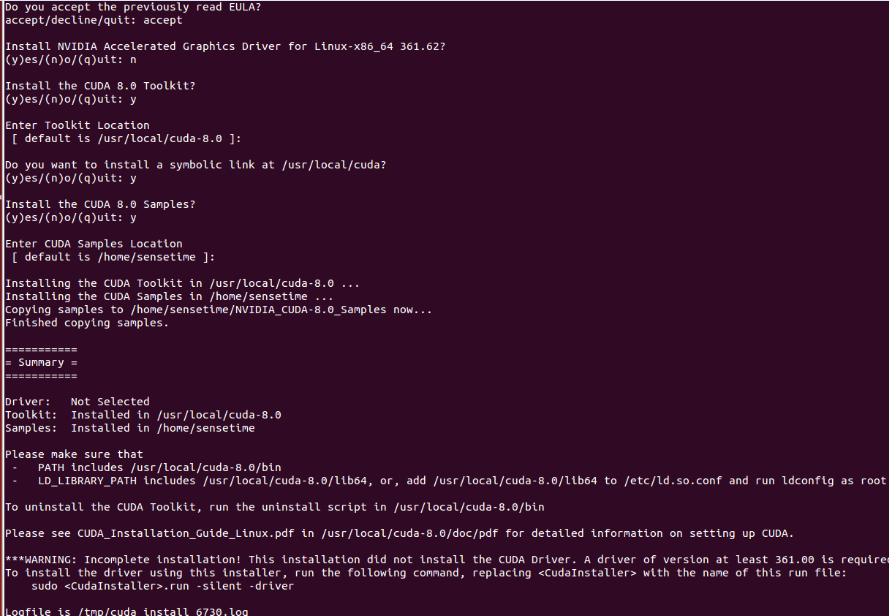
Ubuntu14.04 64位机上安装cuda8.0+cudnn5.0操作步骤
查看Ubuntu14.04 64位上显卡信息,执行:lspci | grep -i vga lspci -v -s 01:00.0 nvidia-smi第一条此命令可以显示一些显卡的相关信息;如果想查看某个详细信息,可以执行第二条命令;如果是NVIDIA卡, 可继续执行第三条命…

SQLI DUMB SERIES-5
less5 (1)输入单引号,回显错误,说明存在注入点。输入的Id被一对单引号所包围,可以闭合单引号 (2)输入正常时:?id1 说明没有显示位,因此不能使用联合查询了;可…
javascript RegExp
http://www.w3schools.com/jsref/jsref_obj_regexp.asp声明-------------modifiers:{i,g,m}1. var pattnew RegExp(pattern,modifiers);2. var patt/pattern/modifiers;------------------------例子:var str "Visit W3Schools"; //两…
Ubuntu14.04 64位机上安装OpenCV2.4.13(CUDA8.0)版操作步骤
Ubuntu14.04 64位机上安装CUDA8.0的操作步骤可以参考http://blog.csdn.net/fengbingchun/article/details/53840684,这里是在已经正确安装了CUDA8.0的基础上安装OpenCV2.4.13(CUDA8.0)操作步骤:1. 从http://opencv.org/downloads.html 下载OpenCV2.…
一篇文章能够看懂基础代码之CSS
web页面主要分为三块内容:js:控制用户行为和执行代码行为html元素:控制页面显示哪些控件(例如按钮,输入框,文本等)css:控制如何显示页面上的空间,例如布局,颜…

谷歌NIPS论文Transformer模型解读:只要Attention就够了
作者 | Sherwin Chen译者 | Major,编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100)导读:在 NIPS 2017 上,谷歌的 Vaswani 等人提出了 Transformer 模型。它利用自我注意(self-attention)来计算其…

中国移动与苹果联姻 三星在华霸主地位或遭取代
据国外媒体12月24日报道,在各方的期待下,苹果终于宣布中国移动将于2014年1月17日开始销售支持其网络的iPhone手机。而中国移动也将于12 月25日开始正式接受预定。作为中国以及世界最大的移动运营商,中国移动与苹果的合作,将会帮助…

二维码Data Matrix编码、解码使用举例
二维码Data Matrix的介绍见: http://blog.csdn.net/fengbingchun/article/details/44279967 ,这里简单写了个生成二维码和对二维码进行识别的测试例子,如下:int test_data_matrix_encode() {std::string str "中国_abc_DEF…
PDF文件如何转成markdown格式
百度上根据pdf转makrdown为关键字进行搜索,结果大多数是反过来的转换,即markdown文本转PDF格式。 但是PDF转markdown的解决方案很少。 正好我工作上有这个需求,所以自己实现了一个解决方案。 下图是一个用PDF XChange Editor打开的PDF文件&am…

关于SAP BW提示“Carry out repairs in non-original only
为什么80%的码农都做不了架构师?>>> 这个提示是由于你在生产系统(正式系统)里面修改了一些东西,才提示"Carry out repairs in non-original system only if they are urgent"这个警告,理论上我们…
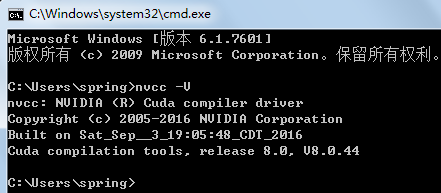
windows7 64位机上安装配置CUDA7.5(或8.0)+cudnn5.0操作步骤
按照官网文档 http://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html#axzz4TpI4c8vf 进行安装:在windows7上安装cuda8.0/cuda7.5的系统需求:(1)、ACUDA-capable GPU(本机显卡为GeForce GT 640M);(2)、A support…
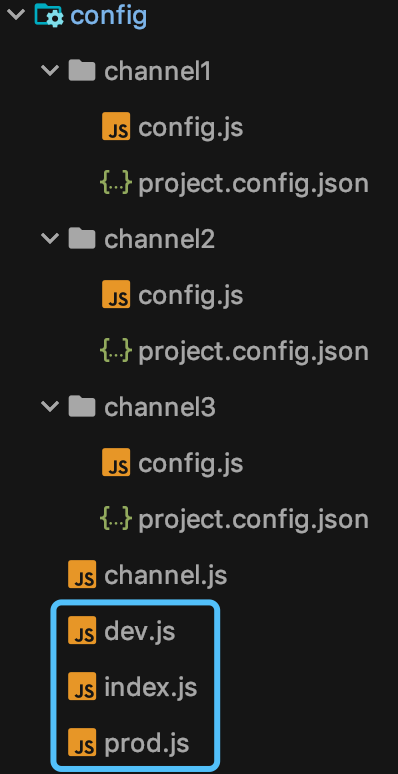
多重影分身:一套代码如何生成多个小程序?
前言 影分身术,看过火影的都知道,一个本体,多个分身。 大家肯定要问了,那小程序开发跟影分身术也能扯上关系?没错,那自然就是:一套代码,多个小程序啦。 各位先别翻白眼,且…

TensorFlow全家桶的落地开花 | 2019 Google开发者日
作者 | 唐小引写于上海世博中心出品 | GDD 合作伙伴 CSDN(ID:CSDNnews)Android 10 原生支持 5G,Flutter 1.9、Dart 2.5 正式发布这是 Google Developer Days 在中国的第四年,从 2016 年 Google Developers 中国网站正式…

css的background
背景属性——background是css中的核心属性。你应该对它有充分的了解。这篇文章详细讨论了background的所有相关属性,甚至包括background-p_w_upload,还为我们介绍了它在即将到来的CSS3中的样子,还有那些新加入的背景属性。使用CSS2中的背景属…
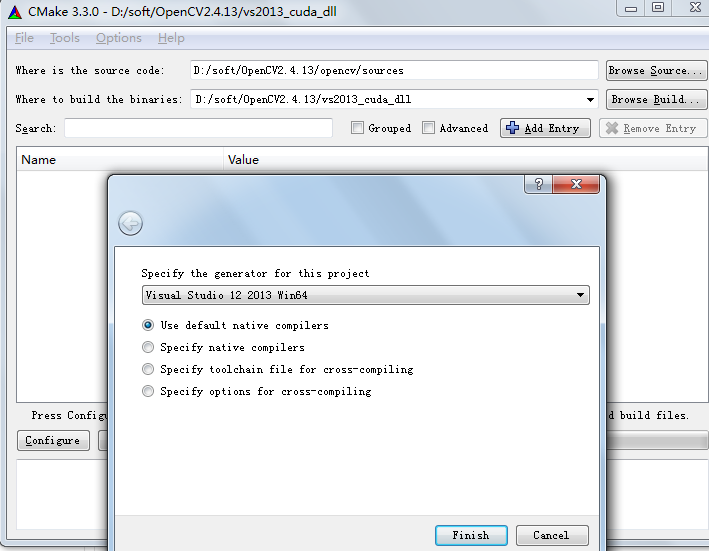
windows7 64位机上配置支持GPU版(CUDA7.5)的OpenCV2.4.13操作步骤
很久之前在windows7 32位上配置过GPU版的opencv,可参考http://blog.csdn.net/fengbingchun/article/details/9831837Windows7 64位CUDA7.5的配置可以参考:http://blog.csdn.net/fengbingchun/article/details/53892997这里是在CUDA7.5已正确安装后的操作…
值得注意的知识点
ImageView的属性adjustViewBounds www.jianshu.com/p/13de17744… 转载于:https://juejin.im/post/5c8b7742e51d454e02716e44

阿里深度序列匹配模型SDM:如何刻画大型推荐系统的用户行为?
作者 | 石晓文来源 | 小小挖掘机(ID:wAIsjwj)今天给大家介绍的论文是:《SDM: Sequential Deep Matching Model for Online Large-scale Recommender System》论文下载地址:https://arxiv.org/abs/1909.00385v11、背景像…
find ip from hostname or find hostname from ip
1. find ip from hostname ping <hostname> 2.fin hostname from ip nslookup <ip>
Linux下多线程编程中信号量介绍及简单使用
在Linux中有两种方法用于处理线程同步:信号量和互斥量。线程的信号量是一种特殊的变量,它可以被增加或减少,但对其的关键访问被保证是原子操作。如果一个程序中有多个线程试图改变一个信号量的值,系统将保证所有的操作都将依次进行…
Linux环境HBase安装配置及使用
Linux环境HBase安装配置及使用 1. 认识HBase (1) HBase介绍 HBase Hadoop database,Hadoop数据库开源数据库官网:hbase.apache.org/HBase源于Google的BigTableApache HBase™是Hadoop数据库,是一个分布式,可扩展的大数据存储。当…

适合小团队作战,奖金+招聘绿色通道,这一届算法大赛关注下?
大赛背景伴随着5G、物联网与大数据形成的后互联网格局的逐步形成,日益多样化的用户触点、庞杂的行为数据和沉重的业务体量也给我们的数据资产管理带来了不容忽视的挑战。为了建立更加精准的数据挖掘形式和更加智能的机器学习算法,对不断生成的用户行为事…
Linq 集合处理(Union)
关于Union的两种情况 一、简单值类型或者string类型处理方式(集合需要实现IEnumerable接口) #region int类型List<int> ints1 new List<int> { 1, 2, 3, 4, 5, 6 };List<int> ints2 new List<int> { 5, 6, 7, 8, 9, 0 };IEnumerable<int> ints…

卷积神经网络中十大拍案叫绝的操作
作者 | Justin ho来源 | 知乎CNN从2012年的AlexNet发展至今,科学家们发明出各种各样的CNN模型,一个比一个深,一个比一个准确,一个比一个轻量。下面会对近几年一些具有变革性的工作进行简单盘点,从这些充满革新性的工作…
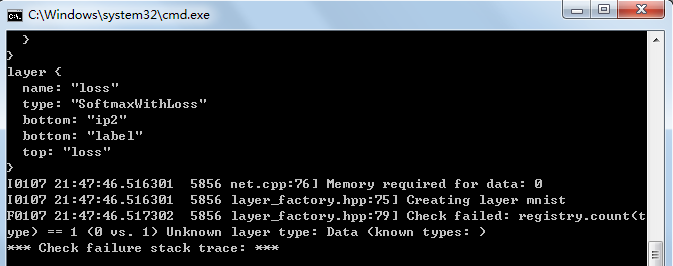
windows7下解决caffe check failed registry.count(type) == 1(0 vs. 1) unknown layer type问题
在Windows7下调用vs2013生成的Caffe静态库时经常会提示Check failed: registry.count(type) 1 (0 vs. 1) Unknown layer type的错误,如下图:这里参考网上资料汇总了几种解决方法:1. 不使用Caffe的静态库,直接将Caffe的sourc…
js 变量提升 和函数提升
2019独角兽企业重金招聘Python工程师标准>>> 创建函数有两种形式,一种是函数声明,另外一种是函数字面量,只有函数声明才有变量提升 console.log(a) // f a() { console.log(a) } console.log(b) //undefinedfunction a() {consol…