卷积神经网络中十大拍案叫绝的操作

作者 | Justin ho
来源 | 知乎
CNN从2012年的AlexNet发展至今,科学家们发明出各种各样的CNN模型,一个比一个深,一个比一个准确,一个比一个轻量。下面会对近几年一些具有变革性的工作进行简单盘点,从这些充满革新性的工作中探讨日后的CNN变革方向。
一、卷积只能在同一组进行吗?-- Group convolution
Group convolution 分组卷积,最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给多个GPU分别进行处理,最后把多个GPU的结果进行融合。
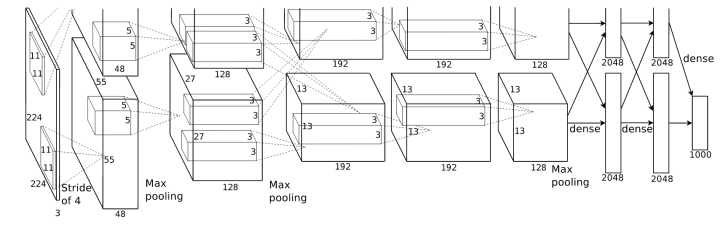
Alexnet
分组卷积的思想影响比较深远,当前一些轻量级的SOTA(State Of The Art)网络,都用到了分组卷积的操作,以节省计算量。但题主有个疑问是,如果分组卷积是分在不同GPU上的话,每个GPU的计算量就降低到 1/groups,但如果依然在同一个GPU上计算,最终整体的计算量是否不变?找了pytorch上有关组卷积操作的介绍,望读者解答我的疑问。

关于这个问题,知乎用户朋友 @蔡冠羽 提出了他的见解:
https://www.zhihu.com/people/cai-guan-yu-62/activities
我感觉group conv本身应该就大大减少了参数,比如当input channel为256,output channel也为256,kernel size为3*3,不做group conv参数为256*3*3*256,若group为8,每个group的input channel和output channel均为32,参数为8*32*3*3*32,是原来的八分之一。这是我的理解。
我的理解是分组卷积最后每一组输出的feature maps应该是以concatenate的方式组合,而不是element-wise add,所以每组输出的channel是 input channels / #groups,这样参数量就大大减少了。
二、卷积核一定越大越好?-- 3×3卷积核
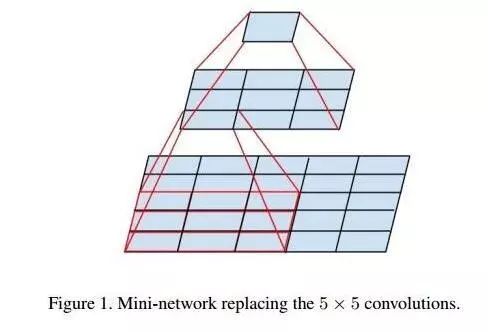
AlexNet中用到了一些非常大的卷积核,比如11×11、5×5卷积核,之前人们的观念是,卷积核越大,receptive field(感受野)越大,看到的图片信息越多,因此获得的特征越好。虽说如此,但是大的卷积核会导致计算量的暴增,不利于模型深度的增加,计算性能也会降低。于是在VGG(最早使用)、Inception网络中,利用2个3×3卷积核的组合比1个5×5卷积核的效果更佳,同时参数量(3×3×2+1 VS 5×5×1+1)被降低,因此后来3×3卷积核被广泛应用在各种模型中。
三、每层卷积只能用一种尺寸的卷积核?-- Inception结构
传统的层叠式网络,基本上都是一个个卷积层的堆叠,每层只用一个尺寸的卷积核,例如VGG结构中使用了大量的3×3卷积层。事实上,同一层feature map可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核的要好,谷歌的GoogleNet,或者说Inception系列的网络,就使用了多个卷积核的结构:
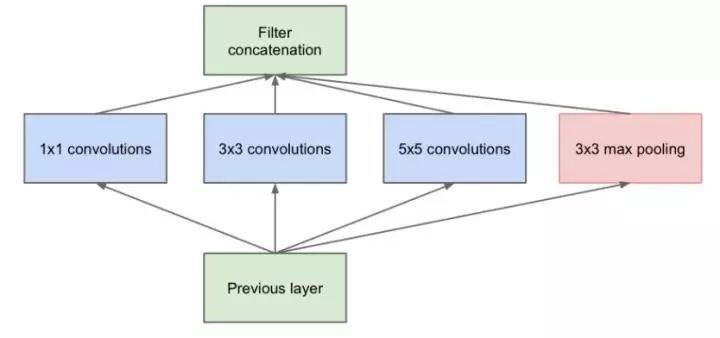
最初版本的Inception结构
如上图所示,一个输入的feature map分别同时经过1×1、3×3、5×5的卷积核的处理,得出的特征再组合起来,获得更佳的特征。但这个结构会存在一个严重的问题:参数量比单个卷积核要多很多,如此庞大的计算量会使得模型效率低下。这就引出了一个新的结构。
四、怎样才能减少卷积层参数量?-- Bottleneck
发明GoogleNet的团队发现,如果仅仅引入多个尺寸的卷积核,会带来大量的额外的参数,受到Network In Network中1×1卷积核的启发,为了解决这个问题,他们往Inception结构中加入了一些1×1的卷积核,如图所示:
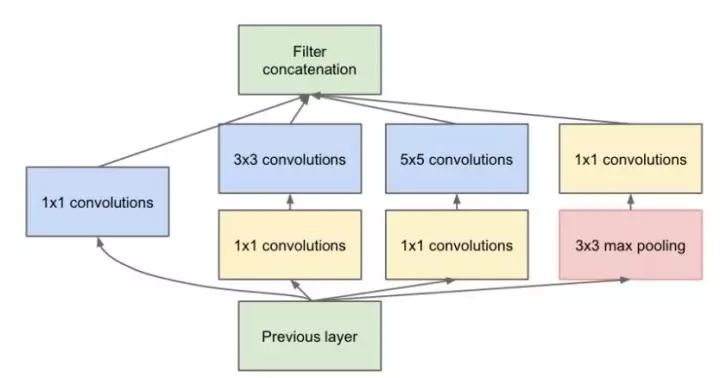
加入1×1卷积核的Inception结构
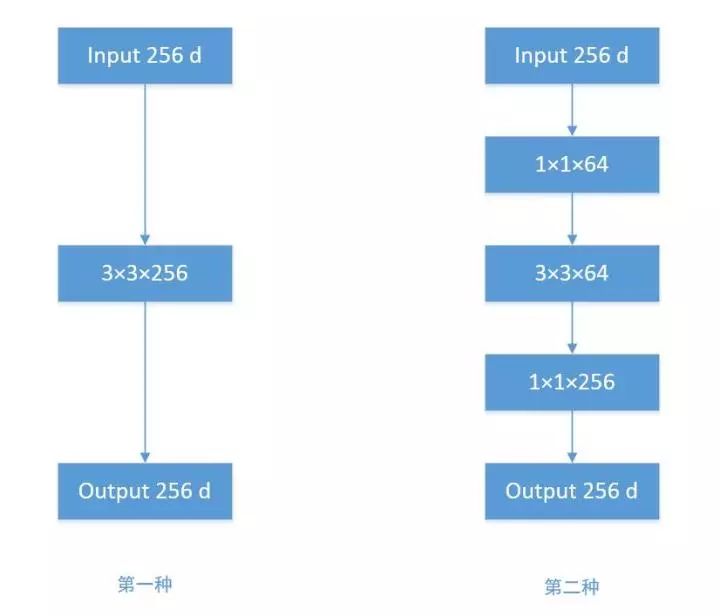
根据上图,我们来做个对比计算,假设输入feature map的维度为256维,要求输出维度也是256维。有以下两种操作:
五、越深的网络就越难训练吗?-- Resnet残差网络
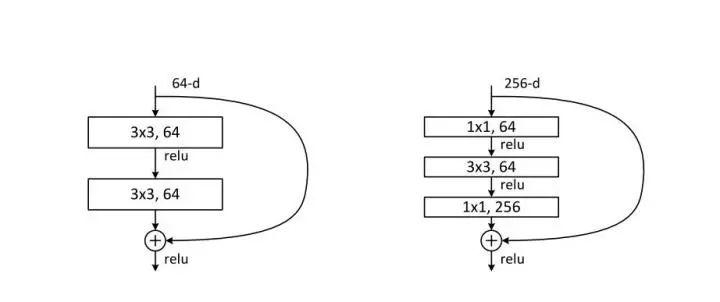 ResNet skip connection
ResNet skip connection[1]张俊林博客:https://blog.csdn.net/malefactor/article/details/67637785 [2]https://zhuanlan.zhihu.com/p/28124810?group_id=883267168542789632
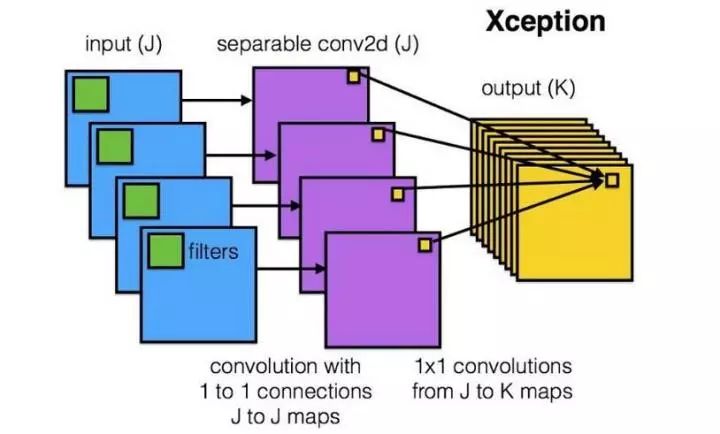
六、卷积操作时必须同时考虑通道和区域吗?-- DepthWise操作
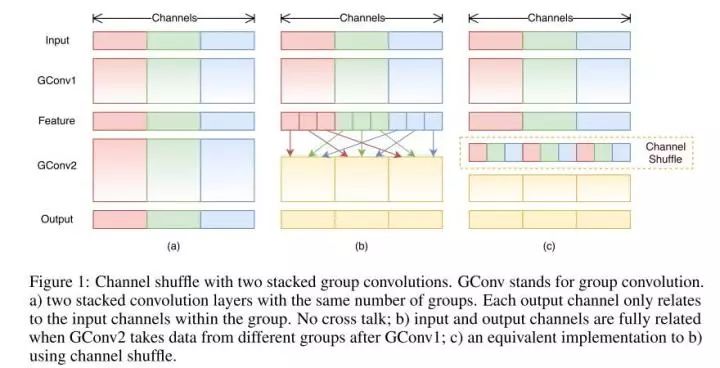
七、分组卷积能否对通道进行随机分组?-- ShuffleNet
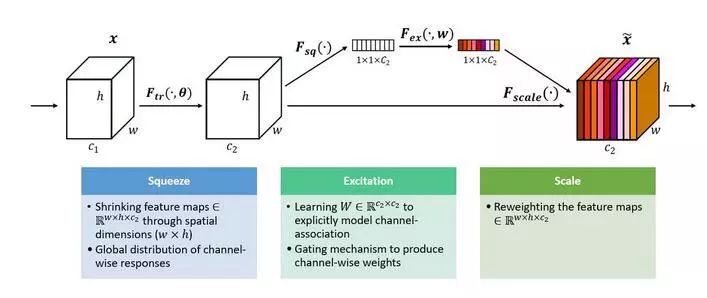
八、通道间的特征都是平等的吗?-- SEnet
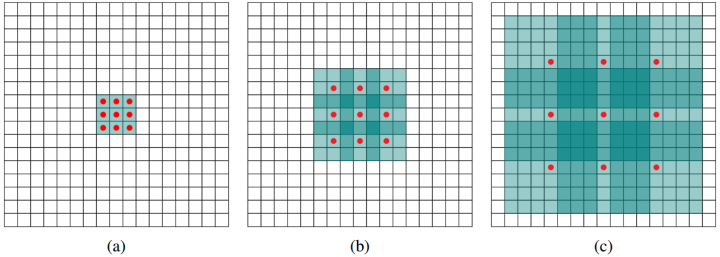
九、能否让固定大小的卷积核看到更大范围的区域?-- Dilated convolution
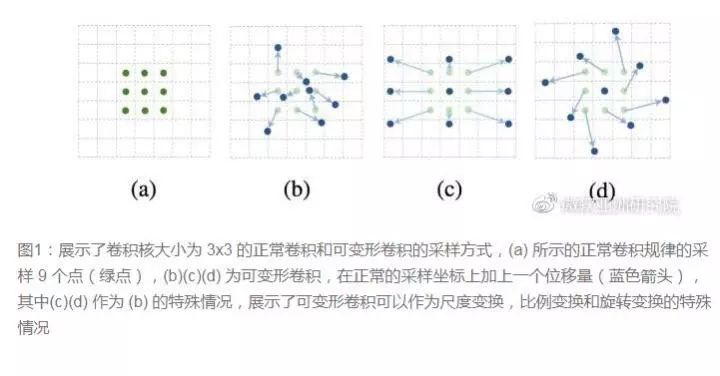
十、卷积核形状一定是矩形吗?-- Deformable convolution 可变形卷积核
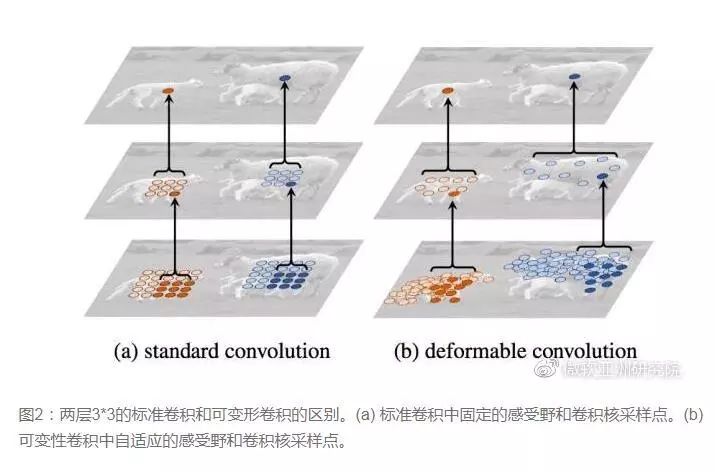
启发与思考
卷积核方面:
- 大卷积核用多个小卷积核代替;
- 单一尺寸卷积核用多尺寸卷积核代替;
- 固定形状卷积核趋于使用可变形卷积核;
- 使用1×1卷积核(bottleneck结构)。
卷积层通道方面:
- 标准卷积用depthwise卷积代替;
- 使用分组卷积;
- 分组卷积前使用channel shuffle;
- 通道加权计算。
使用skip connection,让模型更深;
densely connection,使每一层都融合上其它层的特征输出(DenseNet)
谷歌NIPS论文Transformer模型解读:只要Attention就够了
阿里云弹性计算负责人蒋林泉:亿级场景驱动的技术自研之路
开源sk-dist,超参数调优仅需3.4秒,sk-learn训练速度提升100倍
你在北边的西二旗被水淹没,我在东边的八通线不知所措
为什么说边缘计算的发展比5G更重要?
C/C++ 最易受攻击、70% 漏洞无效,揭秘全球开源组件安全现状
首批共享单车死于 2019
公钥加密、加密Hash散列、Merkle树……区块链的密码学你知多少?

相关文章:
windows7下解决caffe check failed registry.count(type) == 1(0 vs. 1) unknown layer type问题
在Windows7下调用vs2013生成的Caffe静态库时经常会提示Check failed: registry.count(type) 1 (0 vs. 1) Unknown layer type的错误,如下图:这里参考网上资料汇总了几种解决方法:1. 不使用Caffe的静态库,直接将Caffe的sourc…

js 变量提升 和函数提升
2019独角兽企业重金招聘Python工程师标准>>> 创建函数有两种形式,一种是函数声明,另外一种是函数字面量,只有函数声明才有变量提升 console.log(a) // f a() { console.log(a) } console.log(b) //undefinedfunction a() {consol…

.net_ckeditor+ckfinder的图片上传配置
CKEditor和CKFinder的最新版可以到官方网站(http://cksource.com)上下载获得。 把以上两个资源放到网站的根目录: /CKEditor 和 /CKFinder (不区分大小写) 在页面使用 CKEditor: <textarea cols"80" id"prcont…
VS2013在Windows7 64位上变慢的解决方法
重装了windows7系统,又重装了vs2013,发现在打开vs2013、编译工程及调试的时候,vs2013都会变的比较慢,参考网上资料,这里列出几种可能的解决方法: 1. 打开工具--> 选项 --> 源代码管理 --> 插件选…
Key-Value数据库:Redis与Memcached之间如何选择?
华为云分布式缓存Redis5.0和Memcached都是华为云DCS的核心产品。 那么在不同的使用场景之下,如何选择Redis5.0和Memcached呢? 就由小编为大家进行详细的数据对比分析吧Redis和Memcached都是非常受欢迎的开源内存数据库,相对关系型数据库&…

裴健等9名华人当选加拿大皇家学会院士
【导读】近日,加拿大皇家学会(RSC,The Royal Society of Canada)官网宣布已评选出今年的新增院士。其中,京东副总裁、加拿大西蒙弗雷泽大学计算科学学院教授裴健和其他 8 名华人学者均在这份名单之中,而裴健…
Linux中shell命令的用法和技巧
使用Linux shell是我每天的基本工作,但我经常会忘记一些有用的shell命令和l技巧。当然,命令我能记住,但我不敢说能记得如何用它执行某个特定任务。于是,我开始在一个文本文件里记录这些用法,并放在我的Dropbox里&#…
Caffe中Layer注册机制
Caffe内部维护一个注册表用于查找特定Layer对应的工厂函数(Layer Factory的设计用到了设计模式里的工厂模式)。Caffe的Layer注册表是一组键值对(key, value)( LayerRegistry里用map数据结构维护一个CreatorRegistry list, 保存各个Layer的creator的函数句柄),key为L…

自动驾驶行业观察 | 停车不再难,L2到L4的泊车辅助系统技术剖析
作者 | 陈光来源 | 自动驾驶干货铺(ID:IntelligentDrive)【导读】在汽车智能化的浪潮中,车载传感器发展迅速,越来越多搭载了先进传感器的汽车进入了我们的视野。比如能够在高速公路上实现单车道巡航的凯迪拉克CT6,以及…
Unity Log重新定向
Unity Log重新定向 使用Unity的Log的时候有时候需要封装一下Debug.Log(message),可以屏蔽Log或者把log内容写到文本中。通过把文本内容传送到服务器中,查找bug出现的原因。但是封装之后的日志系统如果双击跳转的时候,会跳转到自定义的日志系统…
Javascript 检查一组 radio 中的哪一个被勾选
2019独角兽企业重金招聘Python工程师标准>>> 以前检查单选按钮是否被选择时,我使用的是 if else 一个一个的检查其 checked 属性。 这样虽然可以,但是当一组 radio 有很多个时,就很麻烦了。 可以通过 getElementsByName 得到所有…

二维码Aztec简介及其解码实现(zxing-cpp)
Aztec Code是1995年,由Hand HeldProducts公司的Dr. Andrew Longacre设计。它是一种高容量的二维条形码格式。它可以对ASCII和扩展ASCII码进行编码。当使用最高容量和25%的纠错级别的時候,Aztec可以对3000个字符或者3750个数字进行编码。Aztec的矩阵大小在…

顶配12699 元、没有5G,“浴霸三摄”的iPhone你会买吗?
作者 | 屠敏出品 | CSDN(ID:CSDNnews)北京时间 9 月 11 日凌晨 1 点,以「Apple 特别活动」为主题的苹果秋季发布会正式于史蒂夫乔布斯剧院拉开帷幕。按照惯例,在发布会之前,业界“毫不留情”地对新品进行了…
阿里P7架构师告诉你Java架构师必须知道的 6 大设计原则
在软件开发中,前人对软件系统的设计和开发总结了一些原则和模式, 不管用什么语言做开发,都将对我们系统设计和开发提供指导意义。本文主要将总结这些常见的原则,和具体阐述意义。 开发原则 面向对象的基本原则(solid)是五个&#…
rhel6用centos163 yum源
cd /etc/yum.repos.d/wget wget http://mirrors.163.com/.help/CentOS6-Base-163.reposed -i "s/\$releasever/6/" CentOS6-Base-163.repo

打破深度学习局限,强化学习、深度森林或是企业AI决策技术的“良药”
算法、算力和数据是人工智能时代的三驾马车,成为企业赋能人工智能的动力,但它们自身的特性也为企业和高校在研究和落地应用过程带来了重重挑战。比如,训练算法的成本高昂,数据从采集、处理到存储已面临瓶颈,目前针对算…
JAVA springboot微服务b2b2c电子商务系统(十三)断路器聚合监控(Hystrix Turbine)
讲述了如何利用Hystrix Dashboard去监控断路器的Hystrix command。当我们有很多个服务的时候,这就需要聚合所以服务的Hystrix Dashboard的数据了。这就需要用到Spring Cloud的另一个组件了,即Hystrix Turbine。一、Hystrix Turbine简介看单个的Hystrix D…

二维码Data Matrix的解码实现(zxing-cpp)
二维码Data Matrix的介绍可以参考http://blog.csdn.net/fengbingchun/article/details/44279967 ,以下是通过zxing-cpp开源库实现的对Data Matrix进行解码的测试代码:#include "funset.hpp" #include <string> #include <fstream> #include &…

PHP mongodb 的使用
mongodb 不用过多的介绍了,NOSQL的一种,是一个面向文档的数据库,以其方便灵活的数据结构,对于开发者来说是比较友好的,同时查询的速度也是比较快的,现在好多网站 开始使用mongodb ,具体的介绍可以网上查找。…

必看,61篇NeurIPS深度强化学习论文解读都这里了
作者 | DeepRL来源 | 深度强化学习实验室(ID: Deep-RL)NeurIPS可谓人工智能年度最大盛会。每年全球的人工智能爱好者和科学家都会在这里聚集,发布最新研究,并进行热烈探讨,大会的技术往往这未来几年就会演变成真正的研…

07-09-Exchange Server 2019-配置-Outlook 2019
[在此处输入文章标题] 《系统工程师实战培训》 -07-部署邮件系统 -09-Exchange Server 2019-配置-Outlook 2019 作者:学 无 止 境 QQ交流群:454544014 MSUCDemo01 MSUCDemo02 MSUCDemo03 MSUCDemo04 MSUCDemo05 启用邮箱 MSUCDemo01i-x-Cloud.com MSUCDe…

二维码QR Code简介及其解码实现(zxing-cpp)
二维码QR Code(Quick Response Code)是由Denso公司于1994年9月研制的一种矩阵二维码符号,它具有一维条码及其它二维条码所具有的信息容量大、可靠性高、可表示汉字及图象多种文字信息、保密防伪性强等优点。二维码QR Code呈正方形,常见的是黑白两色。在3…
jQuery学习(一)
因为项目需要,同时也因为兴趣,在近一段时间研究和使用了jQuery,它真的是太强大了,代码非常的优雅和简洁,好后悔现在才开始了解它,虽然目前网络上关于jQuery的资料、学习心得,教程多得你看不完&a…

知乎算法团队负责人孙付伟:Graph Embedding在知乎的应用实践
演讲嘉宾 | 孙付伟出品 | AI科技大本营(ID:rgznai100)9月6-7日,在由CSDN主办的2019中国AI开发者大会(AI ProCon 2019)的 机器学习专场中,知乎算法团队负责人孙付伟在机器学习专场中分享了《Graph Embedding…
一维码Codabar简介及其解码实现(zxing-cpp)
一维码Codabar:由4条黑色线条,3条白色线条,合计7条线条所组成,每一个字元与字元之间有一间隙Gap做区隔。条形码Codabar包含21个字元:(1)、10个数字0~9;(2)、””, ”-”,”*”, ”/”, ”$”, .”, ”:”等7个特殊符号…
node 压缩模块速成
1. 压缩与解压缩处理可以使用zlib模块进行压缩及解压缩处理,压缩文件以后可以减少体积,加快传输速度和节约带宽 代码2. 压缩对象压缩和解压缩对象都是一个可读可写流方法说明zlib.createGzip返回Gzip流对象,使用Gzip算法对数据进行压缩处理zlib.createGu…

hadoop作业初始化过程详解(源码分析第三篇)
(一)概述我们在上一篇blog已经详细的分析了一个作业从用户输入提交命令到到达JobTracker之前的各个过程。在作业到达JobTracker之后初始化之前,JobTracker会通过submitJob方法,为每个作业都创建一个JobInProgress对象(本文以后简称…

百度无人车急刹车
导语:没人会怀疑人工智能在未来的地位,也没人会怀疑无人驾驶将改变我们的生活,但百度首次出现亏损,“现金牛”业务遭遇越发严重的挑战,无人驾驶行业的征途却越发漫长且荆棘密布,这个公司该如何走到“流着奶…
STM32中EXTI和NVIC的关系
(1)NVIC(嵌套向量中断):NVIC是Cortex-M3核心的一部分,关于它的资料不在《STM32的技术参考手册》中,应查阅ARM公司的《Cortex-M3技术参考手册》Cortex-M3的向量中断统一由NVIC管理。 (2)EXTI(外部…

一维码Code 93简介及其解码实现(zxing-cpp)
一维码Code 93: Code 93码与Code 39码的字符集相同,但93码的密度要比39码高,因而在面积不足的情况下,可以用93码代替39码。它没有自校验功能,为了确保数据安全性,采用了双校验字符,其可靠性比39条码还要高.一维码Code 39的介绍可以参考&#…