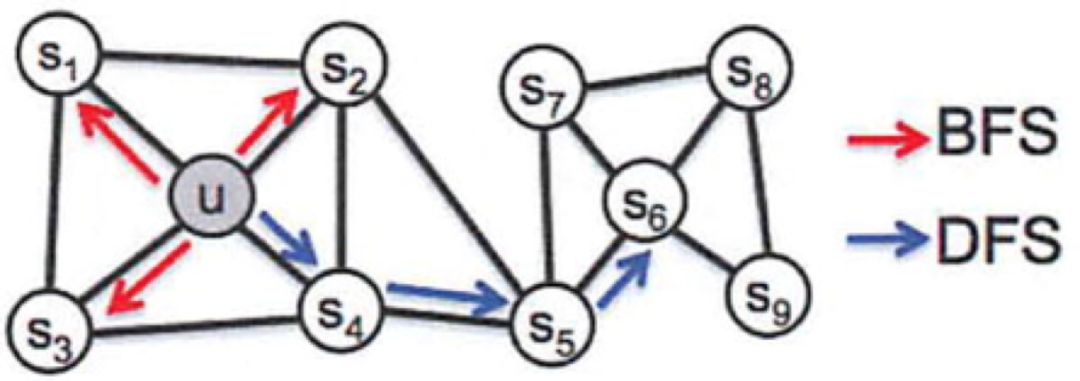
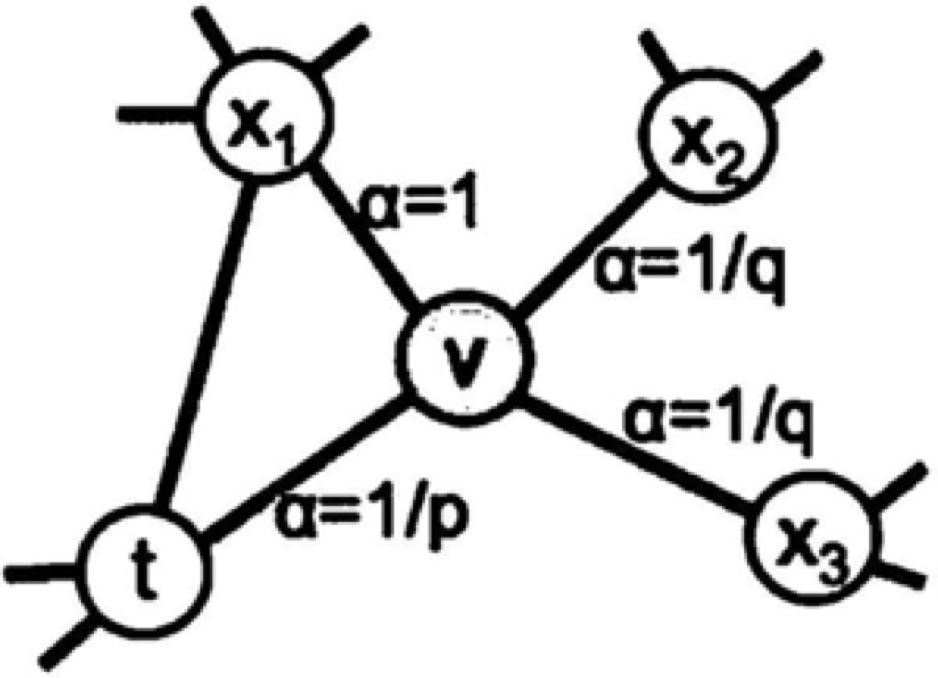
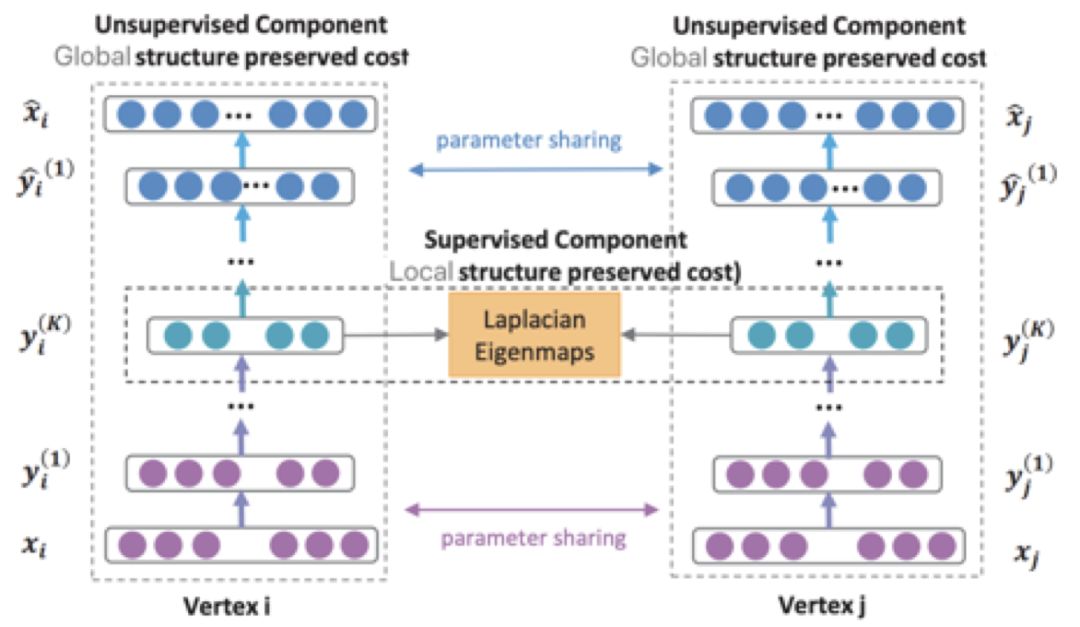
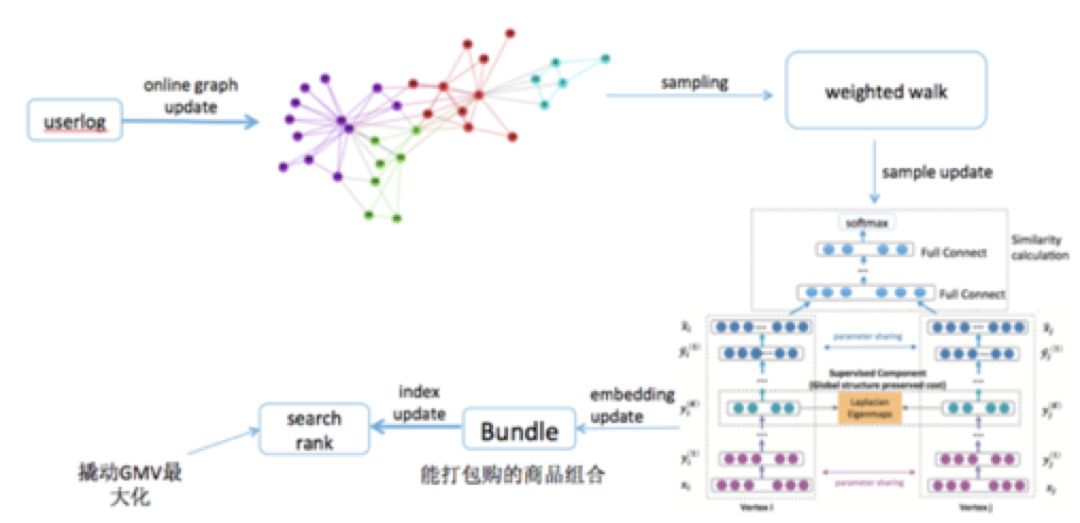
知乎算法团队负责人孙付伟:Graph Embedding在知乎的应用实践


◆
精彩推荐
◆
由易观携手CSDN联合主办的第三届易观算法大赛正在火热进行中!冠军奖3万元,每团队不超过5人参赛。
本次比赛主要预测访问平台的相关事件的PV,UV流量(包括Web端,移动端等),大赛将会提供相应事件的流量数据,以及对应时间段内的所有事件明细表和用户属性表等数据,进行模型训练,并用训练好的模型预测规定日期范围内的事件流量。

顶配12699 元、没有5G,“浴霸三摄”的iPhone你会买吗
卷积神经网络中十大拍案叫绝的操作
5大必知的图算法,附Python代码实现
如何在Apache Flink中使用Python API?
使用Python进行机器学习的假设检验(附链接&代码)
备受期待的原子交换,将如何对中心化交易所构成威胁?
马云淡出「理想国」

相关文章:
一维码Codabar简介及其解码实现(zxing-cpp)
一维码Codabar:由4条黑色线条,3条白色线条,合计7条线条所组成,每一个字元与字元之间有一间隙Gap做区隔。条形码Codabar包含21个字元:(1)、10个数字0~9;(2)、””, ”-”,”*”, ”/”, ”$”, .”, ”:”等7个特殊符号…

node 压缩模块速成
1. 压缩与解压缩处理可以使用zlib模块进行压缩及解压缩处理,压缩文件以后可以减少体积,加快传输速度和节约带宽 代码2. 压缩对象压缩和解压缩对象都是一个可读可写流方法说明zlib.createGzip返回Gzip流对象,使用Gzip算法对数据进行压缩处理zlib.createGu…

hadoop作业初始化过程详解(源码分析第三篇)
(一)概述我们在上一篇blog已经详细的分析了一个作业从用户输入提交命令到到达JobTracker之前的各个过程。在作业到达JobTracker之后初始化之前,JobTracker会通过submitJob方法,为每个作业都创建一个JobInProgress对象(本文以后简称…

百度无人车急刹车
导语:没人会怀疑人工智能在未来的地位,也没人会怀疑无人驾驶将改变我们的生活,但百度首次出现亏损,“现金牛”业务遭遇越发严重的挑战,无人驾驶行业的征途却越发漫长且荆棘密布,这个公司该如何走到“流着奶…
STM32中EXTI和NVIC的关系
(1)NVIC(嵌套向量中断):NVIC是Cortex-M3核心的一部分,关于它的资料不在《STM32的技术参考手册》中,应查阅ARM公司的《Cortex-M3技术参考手册》Cortex-M3的向量中断统一由NVIC管理。 (2)EXTI(外部…

一维码Code 93简介及其解码实现(zxing-cpp)
一维码Code 93: Code 93码与Code 39码的字符集相同,但93码的密度要比39码高,因而在面积不足的情况下,可以用93码代替39码。它没有自校验功能,为了确保数据安全性,采用了双校验字符,其可靠性比39条码还要高.一维码Code 39的介绍可以参考&#…

HEVC/H.265 的未来必须是使用并行处理(OpenCL?) OpenCV和OpenCL区别
1 扩展库简介OpenCV(Open Source Computer Vision Library)是一个致力于实时处理计算机视觉问题的开源库。它最初由Intel公司开发,以GPL许可协议发布,后来由Willow Garage基金会负责开发和维护,以BSD许可协议发布&…

一维码Code 128简介及其解码实现(zxing-cpp)
一维码Code 128:1981年推出,是一种长度可变、连续性的字母数字条码。与其他一维条码比较起来,相对较为复杂,支持的字元也相对较多,又有不同的编码方式可供交互运用,因此其应用弹性也较大。Code 128特性&…

21个必须知道的机器学习开源工具!
作者 | SebastianScholl译者 | 刘静,责编 | 郭芮出品 | CSDN(ID:CSDNnews)本文将介绍21种用于机器学习的开源工具。以下为译文:你肯定已经了解流行的开源工具,如R、Python、Jupyter笔记本等。但是ÿ…

eclipse中egit插件使用
2019独角兽企业重金招聘Python工程师标准>>> 这篇文章当时制作有点粗糙,建议阅读升级版:eclipse中egit插件使用--升级版 使用git作为项目的代码管理工具现在是越来越火,网上有各种各样的文章、博客、讨论,其中以命令行…
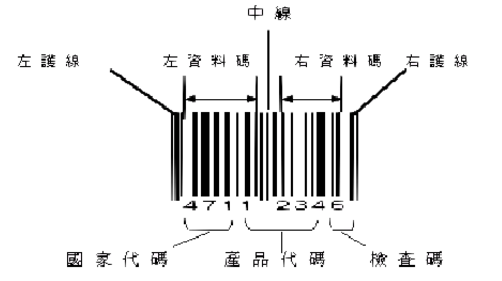
一维码EAN 8简介及其解码实现(zxing-cpp)
一维码EAN 8:属于国际标准条码,由8个数字组成,属EAN的简易编码形式(EAN缩短码)。当包装面积小于120平方公分以下无法使用标准码时,可以申请使用缩短码。依结构的不同,EAN条码可区分为:1. EAN 1…

三年、四大顶会,深度推荐系统18篇论文只有7个可以复现
作者 | 深度传送门来源 | 深度传送门(ID:gh_5faae7b50fc5)导读:本文是“深度推荐系统”专栏的第十篇文章,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文主要根据RecSys 2019中论文…
PHP教程中验证正整数is_int($value+0),为什么要这样?
2019独角兽企业重金招聘Python工程师标准>>> 最近学习PHP应用,其中有一段是要验证变量是否为正整数,除了is_numeric($value)外,还要加上is_int($value0)且($value0) > 0,为什么还要 0呢?直接验证$value不…
[给12306支招]取消车票预订-采用全额预售(充值)
为什么80%的码农都做不了架构师?>>> 取消车票预订 预订给车票销售带来的负面效应: 产生"占座", 如果用户不付款就会造成席位在支付期内无法销售.回收成本, 超过支付期需要回收车票.恶意占座, 如果恶意占座会造成大量真正要买票的客户无法购票…

一维码ITF 25简介及其解码实现(zxing-cpp)
一维码ITF 25又称交插25条码,常用在序号,外箱编号等应用。交插25码是一种条和空都表示信息的条码,交插25码有两种单元宽度,每一个条码字符由五个单元组成,其中二个宽单元,三个窄单元。在一个交插25码符号中…
微软云计算业务增长,或成全球最具价值上市公司
近日,有消息指出,微软公司在云计算业务上的豪赌正在取得回报,目前微软已超越苹果公司,成为全球市值最高的上市公司。就在几年前,这家软件制造商的市场前景还不被人看好,随着个人电脑销量的大幅度下滑&#…
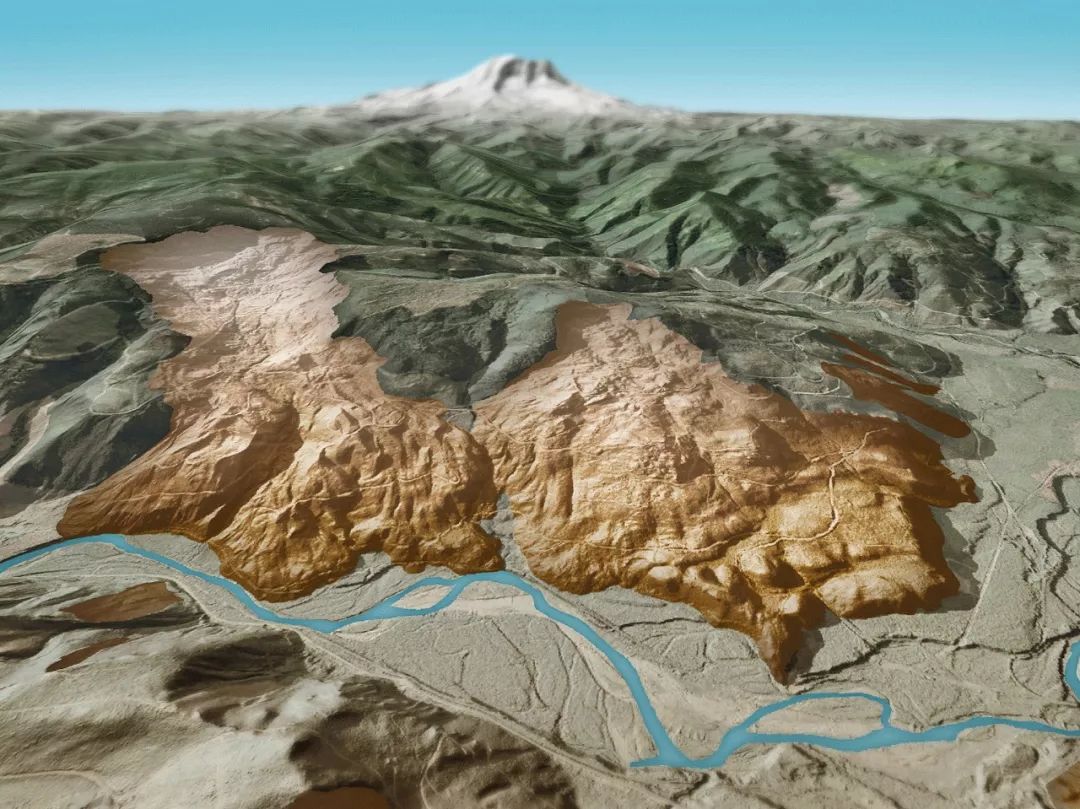
激光雷达,马斯克看不上,却又无可替代?
作者 | Xingwei来源 | 辣笔小星(ID:XingweiSteven)【导读】最近Velodyne挑起的激光雷达LiDAR专利之战成为了业界热点。可以说在严苛的自动驾驶系统中激光雷达成为一种不可替代的传感器。今天让我们详细聊聊激光雷达LIDAR是怎么回事。什么是激光雷达LIDAR…
解决CSV文件中长数字以科学记数格式保存问题
今天因为需要做数据导入到数据表中,用xlxs文件做好了转化为csv文件,结果一看,傻眼了,全部变为科学记数了,在xlxs设置好的单元格格式为文本,可是转化为csv之后就变为了常规,而且也改变了。源文件…

假设检验怎么做?这次把方法+Python代码一并教给你
(图片付费下载于视觉中国)作者 | Jose Garcia译者 | 张睿毅校对 | 张一豪、林亦霖编辑 | 于腾凯来源 | 数据派THU(ID:DatapiTHU)【导读】本文中,作者给出了假设检验的解读与Python实现的详细的假设检验中的…
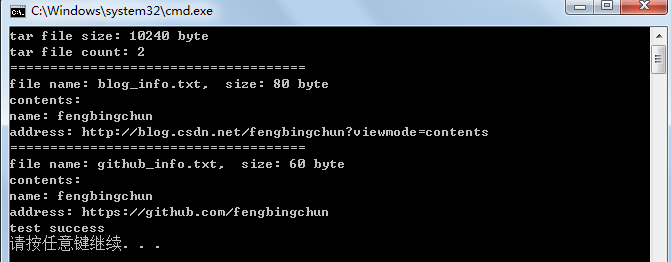
C++实现tar包解析
tar(tape archive)是Unix和类Unix系统上文件打包工具,可以将多个文件合并为一个文件,使用tar工具打出来的包称为tar包。一般打包后的文件名后缀为”.tar”,也可以为其它。tar代表未被压缩的tar文件,已被压缩的tar文件则追加压缩文…
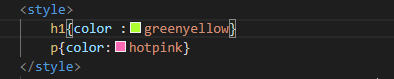
HTML5的学习,各个标签的尝试
style标签的使用可以更好的改变各个标题风格 基本标签<p>,标题<h>,这里br是换行。 超链接的使用,属性href。 表格的使用table。 最后就是图片 img,和音频audio插入地址即可。 今天的学习就分享这些,谢谢大家。转载于:https://www…
Android获取内部和SDCard的存储空间
有时我们开Android项目开发时会用到文件存储或上传文件的一些操作,那么我们前提是要获取到该存储设备的大小,以方便于与我们需要操作的文件的大小做比较,如果操作的文件大小小于存储空间,那么就可以继续操作,反之则不能…
排序算法 Java实现
选择排序 核心思想 选择最小元素,与第一个元素交换位置;剩下的元素中选择最小元素,与当前剩余元素的最前边的元素交换位置。 分析 选择排序的比较次数与序列的初始排序无关,比较次数都是N(N-1)/2。 移动次数最多只有n-1次。 因此&…
正则表达式简介及在C++11中的简单使用
正则表达式(regular expression)是计算机科学中的一个概念,又称规则表达式,通常简写为regex、regexp、RE、regexps、regexes、regexen。 正则表达式是一种文本模式。正则表达式是强大、便捷、高效的文本处理工具。正则表达式本身,加上如同一…

经典再读 | NASNet:神经架构搜索网络在图像分类中的表现
(图片付费下载于视觉中国)作者 | Sik-Ho Tsang译者 | Rachel编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】从 AutoML 到 NAS,都是企业和开发者的热门关注技术,以往我们也分享了很多相关…
javascript面向对象技术基础(二)
数组我们已经提到过,对象是无序数据的集合,而数组则是有序数据的集合,数组中的数据(元素)通过索引(从0开始)来访问,数组中的数据可以是任何的数据类型.数组本身仍旧是对象,但是由于数组的很多特性,通常情况下把数组和对象区别开来分别对待(Throughout this book, objects and a…

MediaPipe:Google Research 开源的跨平台多媒体机器学习模型应用框架
作者 | MediaPipe 团队来源 | TensorFlow(ID:tensorflowers)【导读】我爱计算机视觉(aicvml)CV君推荐道:“虽然它是出自Google Research,但不是一个实验品,而是已经应用于谷歌多款产…
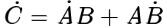
机器学习研究的七个迷思
作者 Oscar Chang 总结了机器学习研究中的七大迷思,每个问题都很有趣,也可能是你在研究机器学习的过程中曾经遇到过的“想当然”问题。AI 前线对这篇文章进行了编译,以飨读者。迷思之一:TensorFlow 是张量操作库 它实际上就是一个…
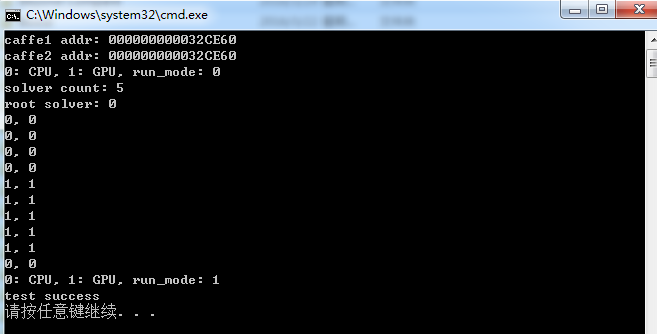
Caffe源码中common文件分析
Caffe源码(caffe version:09868ac , date: 2015.08.15)中的一些重要头文件如caffe.hpp、blob.hpp等或者外部调用Caffe库使用时,一般都会include<caffe/common.hpp>文件,下面分析此文件的内容:1. include的文件:boost中…

编程乐趣:C#彻底删除文件
经常用360的文件粉碎,删除隐私文件貌似还不错的。不过C#也可以实现彻底删除文件。试了下用360文件恢复恢复不了源文件了。代码如下:public class AbsoluteFile{public event EventHandler FinishDeleteFileEvent null;public event EventHandler Finish…