hadoop作业初始化过程详解(源码分析第三篇)
(一)概述
我们在上一篇blog已经详细的分析了一个作业从用户输入提交命令到到达JobTracker之前的各个过程。在作业到达JobTracker之后初始化之前,JobTracker会通过submitJob方法,为每个作业都创建一个JobInProgress对象(本文以后简称JIP),用于维护作业的运行时信息以及监控正在运行作业的运行状态和进度。然后检查提交作业的用户是否具有指定队列的作业提交权限,接着检查用户提交作业时候的自己配置的内存量情况是否在管理员的配置范围内,具体点说就是用户提交作业时,配置的mapred.job.map.memory.mb和mapred.job.reduce.memory.mb不能超过管理员配置的
mapred.cluster.max.map.memory.mb和mapred.cluster.max.reduce.memory.mb,一旦提交作业就会直接失败。最后JobTracker通知TaskScheduler初始化作业,作业初始化这一步是我们本文讨论的内容。
(二)作业初始化的时机以及框架调度流程
(1)作业初始化时机
当JobTracker收到用户提交的作业后,不会马上为其进行初始化而是会交给任务调度器调用EagerTaskInitializationListener对作业进行初始化操作。JobTracker接收到新提交的任务后不对其马上进行初始化是因为考虑到几方面的因素:
作业一旦被初始化了就一定会占用一定量的内存资源,如果大量已被初始化的作业在队列中而暂时得不到调度的话,那么会造成不必要内存资源的浪费。因此Hadoop会按照一定可行策略来对作业进行初始化操作以节省内存资源。
任务调度器的作用是根据每个节点的资源使用情况以及本地性要求为节点分配最适合的任务,而只有被初始化后的作业才能够被任务调度器调度,这里有一个先后过程,因此将作业的初始化嵌套在任务调度中是一种比较合理的设计方法。 |
(2)框架调度流程
Hadoop任务调度器的内部实现都是实现了TaskScheduler接口,具有热插拔性。Hadoop的默认任务调度器是JobQueueTaskScheduler(FIFO),管理员可以通过mapred.jobtracker.taskScheduler参数进行配置,其他比较常用的任务调度器还有Fair Scheduler和Capacity Scheduler。
JobTracker和TaskScheduler之前采用了“观察者模式”,JobTracker作业主题会将“新增作业、更新作业状态、kill掉作业”等命令通知“观察者”TaskScheduler中的EagerTaskInitializationListener和JobQueueJobInProgressListener。其整体调用框架如下图:
.jpg")
用户提交作业到JobTracker之后,通知任务调度器新增作业的代码定位到JobTracker类的addJob(JobID jobId, JobInProgress job)方法,代码如下:
/*** Adds a job to the jobtracker. Make sure that the checks are inplace before* adding a job. This is the core job submission logic* @param jobId The id for the job submitted which needs to be added*/private synchronized JobStatus addJob(JobID jobId, JobInProgress job)throws IOException {totalSubmissions++;synchronized (jobs) {synchronized (taskScheduler) {jobs.put(job.getProfile().getJobID(), job);for (JobInProgressListener listener : jobInProgressListeners) {listener.jobAdded(job);//主要由EagerTaskInitializationListener和JobQueueJobInProgressListener来进行实现}}}......}上面代码会逐个向已经在JobTracker上注册的监听器发放“新增作业”通知,其中listener的jobAdded(job)方法主要由EagerTaskInitializationListener和JobQueueJobInProgressListener来进行实现。
EagerTaskInitializationListener中的实现,其主要功能是对将作业添加到初始化队列以及对作业进行排序,代码如下:
/*** We add the JIP to the jobInitQueue, which is processed* asynchronously to handle split-computation and build up* the right TaskTracker/Block mapping.*/
@Override
public void jobAdded(JobInProgress job) {synchronized (jobInitQueue) {jobInitQueue.add(job);//将作业添加到作业初始化队列中resortInitQueue();//根据作业的优先级和提交时间对作业进行排序jobInitQueue.notifyAll();}
}JobQueueJobInProgressListener中的实现,其主要功能是将作业添加到作业列表当中。
public void jobAdded(JobInProgress job) {jobQueue.put(new JobSchedulingInfo(job.getStatus()), job);
}其中JobSchedulingInfo主要维护了3个变量信息:
private JobPriority priority;
private long startTime;
private JobID id;(三)作业初始化详细过程分析
任务调度器中的EagerTaskInitializationListener将作业的初始化封装为线程,并且放到了固定大小的线程池(FixedThreadPool)中,其线程池的数量由mapred.jobinit.threads配置,默认大小为4。其线程结构代码如下:
class InitJob implements Runnable {private JobInProgress job;public InitJob(JobInProgress job) {this.job = job;}public void run() {ttm.initJob(job);}
}变量ttm对象为TaskTrackerManager接口,其实是由JobTracker来实现的,话句话说就是调用了JobTracker里面的initJob方法对作业进行初始化操作的。JobTracker中的initJob方法主要做了2件事情。第一件:构造和初始化Map Task和Reduce Task任务(接下来主要分析的环节),第二件:发通知给任务调度器去更新作业当前状态。大体代码如下:
public void initJob(JobInProgress job) {if (null == job) {LOG.info("Init on null job is not valid");return;}try {JobStatus prevStatus = (JobStatus)job.getStatus().clone();LOG.info("Initializing " + job.getJobID());job.initTasks();//构造和初始化Map Task和Reduce Task任务// Inform the listeners if the job state has changed// Note : that the job will be in PREP state.JobStatus newStatus = (JobStatus)job.getStatus().clone();if (prevStatus.getRunState() != newStatus.getRunState()) {JobStatusChangeEvent event =new JobStatusChangeEvent(job, EventType.RUN_STATE_CHANGED, prevStatus,newStatus);synchronized (JobTracker.this) {updateJobInProgressListeners(event);//发通知给任务调度器去更新作业当前状态}}}(1)MapTask和ReduceTask任务的构造和初始
所有Task的普通信息以及运行状态都封装在TaskInProgress类,并且有其对Task进行状态的更新和管理,因此创建TaskInProgress(简称TIP)类其实相当于创建了Task任务。Hadoop中Task任务可以分为Map Task、Reduce Task、Setup Task、Cleanup Task,下面主要分析这几种Task的初始化过程。
第一步,读取InputSplit元数据文件job.splitmetainfo,还原成为描述InputSplit具体信息(上一篇blog已经详细说过)的TaskSplitMetaInfo对象,详细代码可以定位到JobInProgress类的initTasks方法(主要负责任务的初始化工作),还原对象的代码如下:
//// read input splits and create a map per a split//TaskSplitMetaInfo[] splits = createSplits(jobId);//还原TaskSplitMetaInfo对象if (numMapTasks != splits.length) {throw new IOException("Number of maps in JobConf doesn't match number of " +"recieved splits for job " + jobId + "! " +"numMapTasks=" + numMapTasks + ", #splits=" + splits.length);}numMapTasks = splits.length;// Sanity check the locations so we don't create/initialize unnecessary tasksfor (TaskSplitMetaInfo split : splits) {NetUtils.verifyHostnames(split.getLocations());}第二步,根据第一步还原的TaskSplitMetaInfo对象信息创建InputSplit.length个TIP对应Map Task,具体代码如下:
maps = new TaskInProgress[numMapTasks];for(int i=0; i < numMapTasks; ++i) {inputLength += splits[i].getInputDataLength();maps[i] = new TaskInProgress(jobId, jobFile,splits[i],jobtracker, conf, this, i, numSlotsPerMap);}第三步,创建mapred.reduce.tasks(默认配置为1)个TIP对应Reduce Task,另外需要注意的是,Reduce Task虽然已经被初始化了,但是不会立即得到调用的,因为它的输入依赖于Map Task的输出,它要等待Map Task完成一定的比例数目才会得到调用,此完成数目比例由参数mappred.reduce.completed.maps配置,默认为0.05。
......// Create reduce tasks//this.reduces = new TaskInProgress[numReduceTasks];//创建Reduce Taskfor (int i = 0; i < numReduceTasks; i++) {reduces[i] = new TaskInProgress(jobId, jobFile,numMapTasks, i,jobtracker, conf, this, numSlotsPerReduce);nonRunningReduces.add(reduces[i]);//将新建的Reudce Task放到没有运行的Reduce Task列表中}
// Calculate the minimum number of maps to be complete before// we should start scheduling reducescompletedMapsForReduceSlowstart = //设定Reduce Task 启动的时机参数(int)Math.ceil((conf.getFloat("mapred.reduce.slowstart.completed.maps",DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART) *numMapTasks));第四步,创建2个TIP分别对应Map Cleanup Task和Reduce Cleanup Task,其作用是清除任务运行之后产生的临时文件信息,他们运行完之后整个作业的状态会由原先的RUNNIN状态变为SUCCEEDED状态,具体代码如下:
// create cleanup two cleanup tips, one map and one reduce.cleanup = new TaskInProgress[2];// cleanup map tip. This map doesn't use any splits. Just assign an empty// split.TaskSplitMetaInfo emptySplit = JobSplit.EMPTY_TASK_SPLIT;cleanup[0] = new TaskInProgress(jobId, jobFile, emptySplit,jobtracker, conf, this, numMapTasks, 1);cleanup[0].setJobCleanupTask();// cleanup reduce tip.cleanup[1] = new TaskInProgress(jobId, jobFile, numMapTasks,numReduceTasks, jobtracker, conf, this, 1);cleanup[1].setJobCleanupTask();第五步,创建2个TIP分别对应Map Setup Task和Reduce Setup Task,其作用就是做一些很简单的初始化工作,比如建临时目录等,其具体实现代码在FileOutputCommitter类的setupJob(JobContext context)方法中,如下:
public void setupJob(JobContext context) throws IOException {JobConf conf = context.getJobConf();Path outputPath = FileOutputFormat.getOutputPath(conf);if (outputPath != null) {Path tmpDir = new Path(outputPath, FileOutputCommitter.TEMP_DIR_NAME);FileSystem fileSys = tmpDir.getFileSystem(conf);if (!fileSys.mkdirs(tmpDir)) {LOG.error("Mkdirs failed to create " + tmpDir.toString());}}}当此任务完成之后整个作业的状态会由PREP变成RUNNING。
特殊说明: (1)由上面代码我们可以看出当Setup/Cleanup Task创建时,放的是一个空的InputSplit(e mptySplit),是因为这2中任务不负责对InputSplit数据进行处理的。其任务状态只有“开始”和“结束”,进度只有0%和100%。 (2)Map/Reduce Setup Task运行时分别占用一个Map slot和一个Reduce slot,但是Hadoop认为他们功能是类似的,他们不能同时运行,话句话说Map Setup Task开始运行就会将Reudce Setup Task杀死,相反Reduce Setup Task开始运行时就会将Map Setup Task杀死。 |
(四)作业初始化详细过程分析总结

这里要特别说明一下,上面的图是我按照JobInProgress类的顺序逐步分析的任务初始化结果,但是任务初始化过程的顺序和运行的顺序是不同的。Task运行的过程是这样的:start->TaskInProgress(Setup Task)->TaskInProgress(Map/Reduce Task)->TaskInProgress(CleanUp Task)。
---------------------------------------hadoop源码分析系列------------------------------------------------------------------------------------------------------------
hadoop作业分片处理以及任务本地性分析(源码分析第一篇)
hadoop作业提交过程分析(源码分析第二篇)
hadoop作业初始化过程详解(源码分析第三篇)
JobTracker之作业恢复与权限管理机制(源码分析第四篇)
JobTracker之辅助线程和对象映射模型分析(源码分析第五篇)
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
参考文献:
[1]《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》
[2] http://hadoop.apache.org/
相关文章:

百度无人车急刹车
导语:没人会怀疑人工智能在未来的地位,也没人会怀疑无人驾驶将改变我们的生活,但百度首次出现亏损,“现金牛”业务遭遇越发严重的挑战,无人驾驶行业的征途却越发漫长且荆棘密布,这个公司该如何走到“流着奶…

STM32中EXTI和NVIC的关系
(1)NVIC(嵌套向量中断):NVIC是Cortex-M3核心的一部分,关于它的资料不在《STM32的技术参考手册》中,应查阅ARM公司的《Cortex-M3技术参考手册》Cortex-M3的向量中断统一由NVIC管理。 (2)EXTI(外部…

一维码Code 93简介及其解码实现(zxing-cpp)
一维码Code 93: Code 93码与Code 39码的字符集相同,但93码的密度要比39码高,因而在面积不足的情况下,可以用93码代替39码。它没有自校验功能,为了确保数据安全性,采用了双校验字符,其可靠性比39条码还要高.一维码Code 39的介绍可以参考&#…

HEVC/H.265 的未来必须是使用并行处理(OpenCL?) OpenCV和OpenCL区别
1 扩展库简介OpenCV(Open Source Computer Vision Library)是一个致力于实时处理计算机视觉问题的开源库。它最初由Intel公司开发,以GPL许可协议发布,后来由Willow Garage基金会负责开发和维护,以BSD许可协议发布&…

一维码Code 128简介及其解码实现(zxing-cpp)
一维码Code 128:1981年推出,是一种长度可变、连续性的字母数字条码。与其他一维条码比较起来,相对较为复杂,支持的字元也相对较多,又有不同的编码方式可供交互运用,因此其应用弹性也较大。Code 128特性&…

21个必须知道的机器学习开源工具!
作者 | SebastianScholl译者 | 刘静,责编 | 郭芮出品 | CSDN(ID:CSDNnews)本文将介绍21种用于机器学习的开源工具。以下为译文:你肯定已经了解流行的开源工具,如R、Python、Jupyter笔记本等。但是ÿ…

eclipse中egit插件使用
2019独角兽企业重金招聘Python工程师标准>>> 这篇文章当时制作有点粗糙,建议阅读升级版:eclipse中egit插件使用--升级版 使用git作为项目的代码管理工具现在是越来越火,网上有各种各样的文章、博客、讨论,其中以命令行…
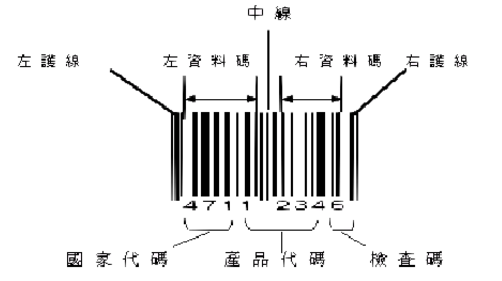
一维码EAN 8简介及其解码实现(zxing-cpp)
一维码EAN 8:属于国际标准条码,由8个数字组成,属EAN的简易编码形式(EAN缩短码)。当包装面积小于120平方公分以下无法使用标准码时,可以申请使用缩短码。依结构的不同,EAN条码可区分为:1. EAN 1…

三年、四大顶会,深度推荐系统18篇论文只有7个可以复现
作者 | 深度传送门来源 | 深度传送门(ID:gh_5faae7b50fc5)导读:本文是“深度推荐系统”专栏的第十篇文章,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文主要根据RecSys 2019中论文…
PHP教程中验证正整数is_int($value+0),为什么要这样?
2019独角兽企业重金招聘Python工程师标准>>> 最近学习PHP应用,其中有一段是要验证变量是否为正整数,除了is_numeric($value)外,还要加上is_int($value0)且($value0) > 0,为什么还要 0呢?直接验证$value不…
[给12306支招]取消车票预订-采用全额预售(充值)
为什么80%的码农都做不了架构师?>>> 取消车票预订 预订给车票销售带来的负面效应: 产生"占座", 如果用户不付款就会造成席位在支付期内无法销售.回收成本, 超过支付期需要回收车票.恶意占座, 如果恶意占座会造成大量真正要买票的客户无法购票…

一维码ITF 25简介及其解码实现(zxing-cpp)
一维码ITF 25又称交插25条码,常用在序号,外箱编号等应用。交插25码是一种条和空都表示信息的条码,交插25码有两种单元宽度,每一个条码字符由五个单元组成,其中二个宽单元,三个窄单元。在一个交插25码符号中…
微软云计算业务增长,或成全球最具价值上市公司
近日,有消息指出,微软公司在云计算业务上的豪赌正在取得回报,目前微软已超越苹果公司,成为全球市值最高的上市公司。就在几年前,这家软件制造商的市场前景还不被人看好,随着个人电脑销量的大幅度下滑&#…
激光雷达,马斯克看不上,却又无可替代?
作者 | Xingwei来源 | 辣笔小星(ID:XingweiSteven)【导读】最近Velodyne挑起的激光雷达LiDAR专利之战成为了业界热点。可以说在严苛的自动驾驶系统中激光雷达成为一种不可替代的传感器。今天让我们详细聊聊激光雷达LIDAR是怎么回事。什么是激光雷达LIDAR…
解决CSV文件中长数字以科学记数格式保存问题
今天因为需要做数据导入到数据表中,用xlxs文件做好了转化为csv文件,结果一看,傻眼了,全部变为科学记数了,在xlxs设置好的单元格格式为文本,可是转化为csv之后就变为了常规,而且也改变了。源文件…

假设检验怎么做?这次把方法+Python代码一并教给你
(图片付费下载于视觉中国)作者 | Jose Garcia译者 | 张睿毅校对 | 张一豪、林亦霖编辑 | 于腾凯来源 | 数据派THU(ID:DatapiTHU)【导读】本文中,作者给出了假设检验的解读与Python实现的详细的假设检验中的…
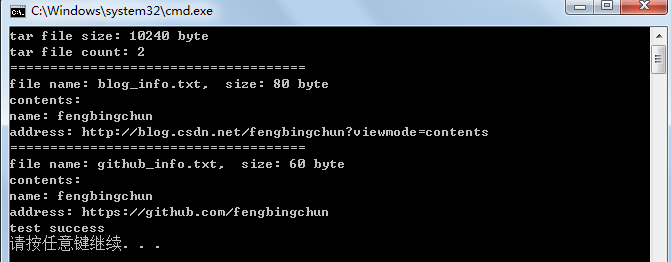
C++实现tar包解析
tar(tape archive)是Unix和类Unix系统上文件打包工具,可以将多个文件合并为一个文件,使用tar工具打出来的包称为tar包。一般打包后的文件名后缀为”.tar”,也可以为其它。tar代表未被压缩的tar文件,已被压缩的tar文件则追加压缩文…
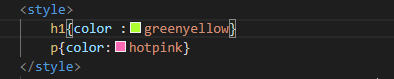
HTML5的学习,各个标签的尝试
style标签的使用可以更好的改变各个标题风格 基本标签<p>,标题<h>,这里br是换行。 超链接的使用,属性href。 表格的使用table。 最后就是图片 img,和音频audio插入地址即可。 今天的学习就分享这些,谢谢大家。转载于:https://www…
Android获取内部和SDCard的存储空间
有时我们开Android项目开发时会用到文件存储或上传文件的一些操作,那么我们前提是要获取到该存储设备的大小,以方便于与我们需要操作的文件的大小做比较,如果操作的文件大小小于存储空间,那么就可以继续操作,反之则不能…
排序算法 Java实现
选择排序 核心思想 选择最小元素,与第一个元素交换位置;剩下的元素中选择最小元素,与当前剩余元素的最前边的元素交换位置。 分析 选择排序的比较次数与序列的初始排序无关,比较次数都是N(N-1)/2。 移动次数最多只有n-1次。 因此&…
正则表达式简介及在C++11中的简单使用
正则表达式(regular expression)是计算机科学中的一个概念,又称规则表达式,通常简写为regex、regexp、RE、regexps、regexes、regexen。 正则表达式是一种文本模式。正则表达式是强大、便捷、高效的文本处理工具。正则表达式本身,加上如同一…

经典再读 | NASNet:神经架构搜索网络在图像分类中的表现
(图片付费下载于视觉中国)作者 | Sik-Ho Tsang译者 | Rachel编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】从 AutoML 到 NAS,都是企业和开发者的热门关注技术,以往我们也分享了很多相关…
javascript面向对象技术基础(二)
数组我们已经提到过,对象是无序数据的集合,而数组则是有序数据的集合,数组中的数据(元素)通过索引(从0开始)来访问,数组中的数据可以是任何的数据类型.数组本身仍旧是对象,但是由于数组的很多特性,通常情况下把数组和对象区别开来分别对待(Throughout this book, objects and a…

MediaPipe:Google Research 开源的跨平台多媒体机器学习模型应用框架
作者 | MediaPipe 团队来源 | TensorFlow(ID:tensorflowers)【导读】我爱计算机视觉(aicvml)CV君推荐道:“虽然它是出自Google Research,但不是一个实验品,而是已经应用于谷歌多款产…
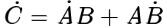
机器学习研究的七个迷思
作者 Oscar Chang 总结了机器学习研究中的七大迷思,每个问题都很有趣,也可能是你在研究机器学习的过程中曾经遇到过的“想当然”问题。AI 前线对这篇文章进行了编译,以飨读者。迷思之一:TensorFlow 是张量操作库 它实际上就是一个…
Caffe源码中common文件分析
Caffe源码(caffe version:09868ac , date: 2015.08.15)中的一些重要头文件如caffe.hpp、blob.hpp等或者外部调用Caffe库使用时,一般都会include<caffe/common.hpp>文件,下面分析此文件的内容:1. include的文件:boost中…

编程乐趣:C#彻底删除文件
经常用360的文件粉碎,删除隐私文件貌似还不错的。不过C#也可以实现彻底删除文件。试了下用360文件恢复恢复不了源文件了。代码如下:public class AbsoluteFile{public event EventHandler FinishDeleteFileEvent null;public event EventHandler Finish…

大数据工程师手册:全面系统的掌握必备知识与工具
作者 | Phoebe Wong译者 | 陆离编辑 | Jane出品 | AI科技大本营(ID:rgznai100)前言如何才能成为一名真正的“全栈(full-stack)”数据科学家?需要了解哪些知识?掌握哪些技能?概括来讲…
JSON.stringify()
写在前边 不言而喻,JSON.stringify() 是用来将合法的JSON数据字符串化的!然而在正常的工作中我们用到的只是最基础的功能;今天我们就探索不一样的JSON.stringify()。 基础用法 基本数据类型 JSON.stringify(2) // "2" JSON.stringi…
C++中前置声明介绍
前置声明是指对类、函数、模板或者结构体进行声明,仅仅是声明,不包含相关具体的定义。在很多场合我们可以用前置声明来代替#include语句。类的前置声明只是告诉编译器这是一个类型,但无法告知类型的大小,成员等具体内容。在未提供…