假设检验怎么做?这次把方法+Python代码一并教给你

作者 | Jose Garcia
译者 | 张睿毅
校对 | 张一豪、林亦霖
编辑 | 于腾凯
来源 | 数据派THU(ID:DatapiTHU)
【导读】本文中,作者给出了假设检验的解读与Python实现的详细的假设检验中的主要操作。
也许所有机器学习的初学者,或者中级水平的学生,或者统计专业的学生,都听说过这个术语,假设检验。我将简要介绍一下这个当我学习时给我带来了麻烦的主题。我把所有这些概念放在一起,并使用python进行示例。
在我寻求更广泛的事情之前要考虑一些问题 ——什么是假设检验?我们为什么用它?什么是假设的基本条件?什么是假设检验的重要参数?
让我们一个个地开始吧:
1、 什么是假设检验?
假设检验是一种统计方法,用于使用实验数据进行统计决策。假设检验基本上是我们对人口参数做出的假设。
例如:你说班里的学生平均年龄是40岁,或者一个男生要比女生高。
我们假设所有这些例子都需要一些统计方法来证明这些。无论我们假设什么是真的,我们都需要一些数学结论。
2、我们为什么要用它?
假设检验是统计学中必不可少的过程。假设检验评估关于总体的两个相互排斥的陈述,以确定样本数据最佳支持哪个陈述。当我们说一个发现具有统计学意义时,这要归功于一个假设检验。
3、什么是假设的基本条件?
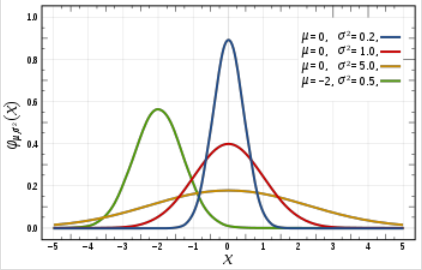
不同均值和方差下的正态分布
假设的基础是规范化和标准规范化
https://en.wikipedia.org/wiki/Normalization_(statistics);https://stats.stackexchange.com/questions/10289/whats——the——difference——between——normalization——and——standardization
我们所有的假设都围绕这两个术语的基础。让我们看看这些。
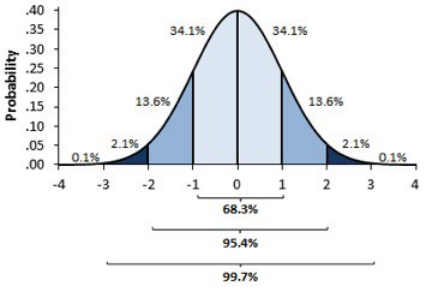
标准化的正态曲线图像和数据分布及每个部分的百分比
你一定想知道这两个图像之间有什么区别,有人可能会说我找不到,而其他人看到的图像会比较平坦,而不是陡峭的。好吧伙计这不是我想要表达的,首先你可以看到有不同的正态曲线所有那些正态曲线可以有不同的均值和方差,如第二张图像,如果你注意到图形是合理分布的,总是均值= 0和方差= 1。当我们使用标准化的正态数据时,z—score的概念就出现了。
正态分布
如果变量的分布具有正态曲线的形状——一个特殊的钟形曲线,则该变量被称为正态分布或具有正态分布。正态分布图称为正态曲线,它具有以下所有属性:1.均值,中位数和众数是相等。
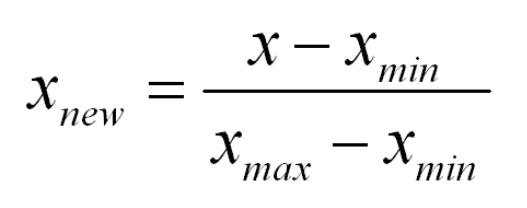
正态分布方程
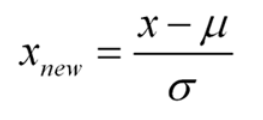
标准化正态分布
标准正态分布是平均值为0,标准差为1的正态分布
4、哪些是假设检验的重要参数?
- 零假设:
- 备择假设:

 。
。
- T校验(学生T校验)
- Z校验
- ANOVA校验
- 卡方检验
链接:https://www.investopedia.com/terms/v/variance.asp
链接:https://www.investopedia.com/terms/h/hypothesistesting.asp
- 单样本t检验
- 双样本t检验
from scipy.stats import ttest_1sampimport
numpy as npages = np.genfromtxt
(“ages.csv”)print(ages)ages_mean = np.mean(ages)
print(ages_mean)tset, pval = ttest_1samp(ages, 30)
print(“p-values”,pval)if pval < 0.05: # alpha value is 0.05 or 5% print
(" we are rejecting null hypothesis")else: print("we are accepting null hypothesis”)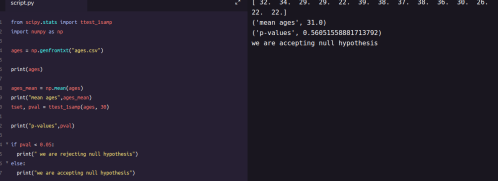
from scipy.stats import ttest_indimport numpy as npweek1 = np.genfromtxt
("week1.csv", delimiter=",")
week2 = np.genfromtxt
("week2.csv", delimiter=",")print(week1)
print("week2 data :-\n")print(week2)
week1_mean = np.mean(week1
)week2_mean = np.mean(week2)print
("week1 mean value:",week1_mean)print
("week2 mean value:",week2_mean)
week1_std = np.std(week1)week2_std =
np.std(week2)print("week1 std value:",week1_std)
print("week2 std value:",week2_std)
ttest,pval = ttest_ind(week1,week2)print
("p-value",pval)if pval <0.05: print
("we reject null hypothesis")else: print("we accept null hypothesis”)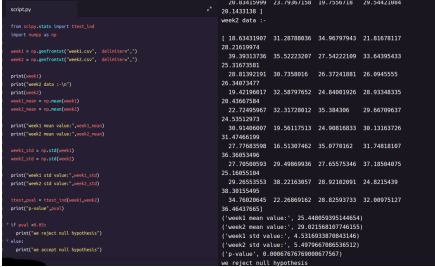
import pandas as pd
from scipy import stats
df = pd.read_csv("blood_pressure.csv")
df[['bp_before','bp_after']].describe()
ttest,pval = stats.ttest_rel(df['bp_before'], df['bp_after'])
print(pval)
if pval<0.05: print("reject null hypothesis")
else: print("accept null hypothesis")链接:https://www.statisticshowto.datasciencecentral.com/probability——and——statistics/hypothesis——testing/f——test/https://www.statisticshowto.datasciencecentral.com/probability——and——statistics/chi——square/https://www.statisticshowto.datasciencecentral.com/probability——and——statistics/t——test/
您的样本量大于30,否则,请使用t检验。
链接:https://www.statisticshowto.datasciencecentral.com/probability——and——statistics/find——sample——size/
数据点应彼此独立,换句话说,一个数据点不相关或不影响另一个数据点。
链接:https://www.statisticshowto.datasciencecentral.com/probability——and——statistics/dependent——events——independent/
您的数据应该是正常分布的。但是,对于大样本量(超过30个),这并不总是重要的。
您的数据应从人口中随机选择,每个项目都有相同的选择机会。
如果可能的话,样本量应该相等。
import pandas as pd
from scipy import statsfrom statsmodels.stats import weightstats as stestsztest ,pval = stests.ztest(df['bp_before'], x2=None, value=156)
print(float(pval))if pval<0.05: print("reject null hypothesis")
else: print("accept null hypothesis")ztest ,pval1 = stests.ztest(df['bp_before'],
x2=df['bp_after'],
value=0,alternative='two-sided')print(float(pval1))if pval<0.05: print("reject null hypothesis")else: print("accept null hypothesis")链接:https://en.wikipedia.org/ wiki/Analysis_of_variance
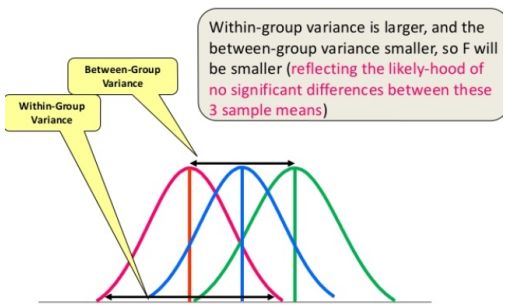
df_anova = pd.read_csv('PlantGrowth.csv')
df_anova = df_anova[['weight','group']]grps = pd.unique(df_anova.group.values)
d_data = {grp:df_anova['weight'][df_anova.group == grp] for grp in grps} F, p = stats.f_oneway(d_data['ctrl'], d_data['trt1'], d_data['trt2'])
print("p-value for significance is: ", p)
if p<0.05: print("reject null hypothesis")
else: print("accept null hypothesis")链接:https://stattrek.com/Help/Glossary.aspx? Target=Categorical%20variable
import statsmodels.api as sm
from statsmodels.formula.api import olsdf_anova2 = pd.read_csv
("https://raw.githubusercontent.com/Opensourcefordatascience/Data-sets/master/crop_yield.csv")
model = ols('Yield ~ C(Fert)*C(Water)'
, df_anova2).fit()print(f"Overall model F
({model.df_model: .0f},{model.df_resid: .0f}) = {model.fvalue: .3f}, p = {model.f_pvalue: .4f}")
res = sm.stats.anova_lm(model, typ= 2)res链接:https://stattrek.com/Help/ Glossary.aspx?Target=Categorical%20variable
df_chi = pd.read_csv('chi-test.csv')
contingency_table=pd.crosstab(df_chi["Gender"],df_chi["Shopping?"])
print('contingency_table :-\n',contingency_table)
#Observed ValuesObserved_Values = contingency_table.values print
("Observed Values :
\n",Observed_Values)b=stats.chi2_contingency(contingency_table)
Expected_Values = b[3]print
("Expected Values :-\n",Expected_Values)
no_of_rows=len(contingency_table.iloc[0:2,0])
no_of_columns=len(contingency_table.iloc[0,0:2])ddof=(no_of_rows-1)*(no_of_columns-1)print
("Degree of Freedom:-",ddof
)alpha = 0.05from scipy.stats import chi2chi_square=sum([(o-e)
**2./e for o,e in zip(Observed_Values,Expected_Values)])
chi_square_statistic=chi_square[0]+chi_square[1]print
("chi-square statistic:-",chi_square_statistic)
critical_value=chi2.ppf(q=1-alpha,df=ddof)print
('critical_value:',critical_value)
#p-valuep_value=1-chi2.cdf(x=chi_square_statistic,df=ddof)
print('p-value:',p_value)print('Significance level: ',alpha)
print('Degree of Freedom: ',ddof)
print('chi-square statistic:',chi_square_statistic)
print('critical_value:',critical_value)print('p-value:',p_value)
if chi_square_statistic>=critical_value: print
("Reject H0,There is a relationship
between 2 categorical variables")
else: print("Retain H0,There is no relationship between 2 categorical variables") if p_value<=alpha: print
("Reject H0,There is a relationship
between 2 categorical variables")else: print
("Retain H0,There is no relationship between 2 categorical variables")译者介绍:张睿毅,北京邮电大学大二物联网在读。我是一个爱自由的人。在邮电大学读第一年书我就四处跑去蹭课,折腾整一年惊觉,与其在当下焦虑,不如在前辈中沉淀。于是在大二以来,坚持读书,不敢稍歇。资本主义国家的科学观不断刷新我的认知框架,同时因为出国考试很早出分,也更早地感受到自己才是那个一直被束缚着的人。太多真英雄在社会上各自闪耀着光芒。这才开始,立志终身向遇到的每一个人学习。做一个纯粹的计算机科学里面的小学生。喜欢算法,数据挖掘,图像识别,自然语言处理,神经网络,人工智能等方向。
原文链接:
https://towardsdatascience.com/hypothesis-testing-in-machine-learning-using-python-a0dc89e169ce
◆
精彩推荐
◆
倒计时!由易观携手CSDN联合主办的第三届易观算法大赛还剩 7 天,冠军团队将获得3万元!
本次比赛主要预测访问平台的相关事件的PV,UV流量(包括Web端,移动端等),大赛将会提供相应事件的流量数据,以及对应时间段内的所有事件明细表和用户属性表等数据,进行模型训练,并用训练好的模型预测规定日期范围内的事件流量。

推荐阅读
知乎算法团队负责人孙付伟:Graph Embedding在知乎的应用实践
必看,61篇NeurIPS深度强化学习论文解读都这里了
打破深度学习局限,强化学习、深度森林或是企业AI决策技术的“良药”
激光雷达,马斯克看不上,却又无可替代?
卷积神经网络中十大拍案叫绝的操作
Docker是啥?容器变革的火花?
5大必知的图算法,附Python代码实现
阿里云弹性计算负责人蒋林泉:亿级场景驱动的技术自研之路
40 岁身体死亡,11 年后成“硅谷霍金”,他用一块屏幕改变 100 万人!
AI大神如何用区块链解决模型训练痛点, AI+区块链的正确玩法原来是这样…… | 人物志

相关文章:
C++实现tar包解析
tar(tape archive)是Unix和类Unix系统上文件打包工具,可以将多个文件合并为一个文件,使用tar工具打出来的包称为tar包。一般打包后的文件名后缀为”.tar”,也可以为其它。tar代表未被压缩的tar文件,已被压缩的tar文件则追加压缩文…
HTML5的学习,各个标签的尝试
style标签的使用可以更好的改变各个标题风格 基本标签<p>,标题<h>,这里br是换行。 超链接的使用,属性href。 表格的使用table。 最后就是图片 img,和音频audio插入地址即可。 今天的学习就分享这些,谢谢大家。转载于:https://www…

Android获取内部和SDCard的存储空间
有时我们开Android项目开发时会用到文件存储或上传文件的一些操作,那么我们前提是要获取到该存储设备的大小,以方便于与我们需要操作的文件的大小做比较,如果操作的文件大小小于存储空间,那么就可以继续操作,反之则不能…
排序算法 Java实现
选择排序 核心思想 选择最小元素,与第一个元素交换位置;剩下的元素中选择最小元素,与当前剩余元素的最前边的元素交换位置。 分析 选择排序的比较次数与序列的初始排序无关,比较次数都是N(N-1)/2。 移动次数最多只有n-1次。 因此&…
正则表达式简介及在C++11中的简单使用
正则表达式(regular expression)是计算机科学中的一个概念,又称规则表达式,通常简写为regex、regexp、RE、regexps、regexes、regexen。 正则表达式是一种文本模式。正则表达式是强大、便捷、高效的文本处理工具。正则表达式本身,加上如同一…

经典再读 | NASNet:神经架构搜索网络在图像分类中的表现
(图片付费下载于视觉中国)作者 | Sik-Ho Tsang译者 | Rachel编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】从 AutoML 到 NAS,都是企业和开发者的热门关注技术,以往我们也分享了很多相关…
javascript面向对象技术基础(二)
数组我们已经提到过,对象是无序数据的集合,而数组则是有序数据的集合,数组中的数据(元素)通过索引(从0开始)来访问,数组中的数据可以是任何的数据类型.数组本身仍旧是对象,但是由于数组的很多特性,通常情况下把数组和对象区别开来分别对待(Throughout this book, objects and a…

MediaPipe:Google Research 开源的跨平台多媒体机器学习模型应用框架
作者 | MediaPipe 团队来源 | TensorFlow(ID:tensorflowers)【导读】我爱计算机视觉(aicvml)CV君推荐道:“虽然它是出自Google Research,但不是一个实验品,而是已经应用于谷歌多款产…
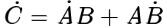
机器学习研究的七个迷思
作者 Oscar Chang 总结了机器学习研究中的七大迷思,每个问题都很有趣,也可能是你在研究机器学习的过程中曾经遇到过的“想当然”问题。AI 前线对这篇文章进行了编译,以飨读者。迷思之一:TensorFlow 是张量操作库 它实际上就是一个…
Caffe源码中common文件分析
Caffe源码(caffe version:09868ac , date: 2015.08.15)中的一些重要头文件如caffe.hpp、blob.hpp等或者外部调用Caffe库使用时,一般都会include<caffe/common.hpp>文件,下面分析此文件的内容:1. include的文件:boost中…

编程乐趣:C#彻底删除文件
经常用360的文件粉碎,删除隐私文件貌似还不错的。不过C#也可以实现彻底删除文件。试了下用360文件恢复恢复不了源文件了。代码如下:public class AbsoluteFile{public event EventHandler FinishDeleteFileEvent null;public event EventHandler Finish…

大数据工程师手册:全面系统的掌握必备知识与工具
作者 | Phoebe Wong译者 | 陆离编辑 | Jane出品 | AI科技大本营(ID:rgznai100)前言如何才能成为一名真正的“全栈(full-stack)”数据科学家?需要了解哪些知识?掌握哪些技能?概括来讲…
JSON.stringify()
写在前边 不言而喻,JSON.stringify() 是用来将合法的JSON数据字符串化的!然而在正常的工作中我们用到的只是最基础的功能;今天我们就探索不一样的JSON.stringify()。 基础用法 基本数据类型 JSON.stringify(2) // "2" JSON.stringi…
C++中前置声明介绍
前置声明是指对类、函数、模板或者结构体进行声明,仅仅是声明,不包含相关具体的定义。在很多场合我们可以用前置声明来代替#include语句。类的前置声明只是告诉编译器这是一个类型,但无法告知类型的大小,成员等具体内容。在未提供…
在Java SE中使用Hibernate处理数据
如今,Hibernate正在迅速成为非常流行的(如果不是最流行的)J2EE O/R映射程序/数据集成框架。它为开发人员提供了处理企业中的关系数据库的整洁、简明且强大的工具。但如果外部需要访问这些已被包装在J2EE Web应用程序中的实体又该怎么办&#…
利用OpenCV、Python和Ubidots构建行人计数器程序(附完整代码)
作者 | Jose Garcia译者 | 吴振东校对 | 张一豪、林亦霖,编辑 | 于腾凯来源 | 数据派(ID:datapi)导读:本文将利用OpenCV,Python和Ubidots来编写一个行人计数器程序,并对代码进行了较为详细的讲解…
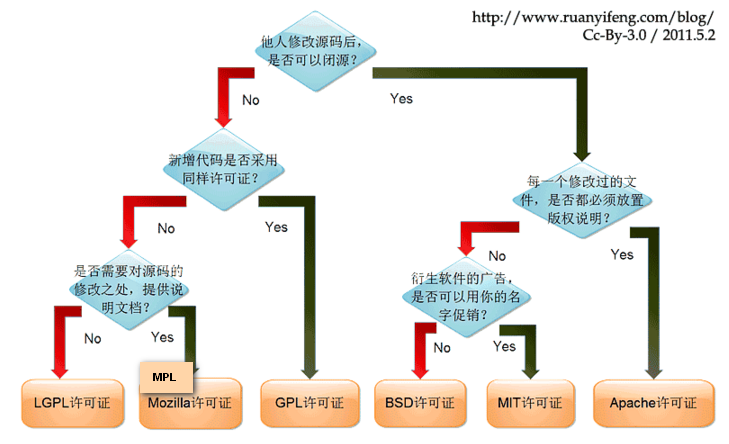
开源软件License汇总
开源软件英文为Open Source Software,简称OSS,又称开放源代码软件,是一种源代码可以任意获取的计算机软件,这种软件的著作权持有人在软件协议的规定之下保留一部分权利并允许用户学习、修改以及以任何目的向任何人分发该软件。 某…
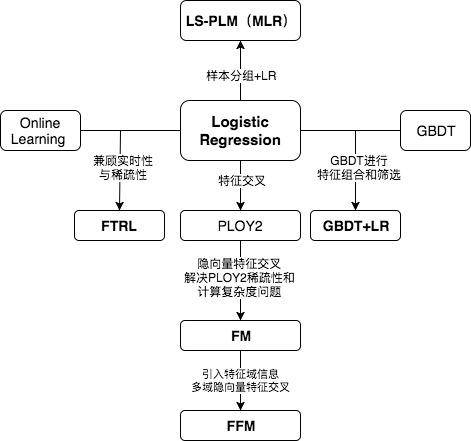
前深度学习时代CTR预估模型的演化之路:从LR到FFM\n
本文是王喆在 AI 前线 开设的原创技术专栏“深度学习 CTR 预估模型实践”的第二篇文章(以下“深度学习 CTR 预估模型实践”简称“深度 CTR 模型”)。专栏第一篇文章回顾:《深度学习CTR预估模型凭什么成为互联网增长的关键?》。重看…

神器与经典--sp_helpIndex
每每和那些NB的人学习技术的时候,往往都佩服他们对各个知识点都熟捻于心,更佩服的是可以在很短时间找出很多业界大师写的文章和开发的工具,就像机器猫的口袋,让人羡慕嫉妒恨啊!宋沄剑宋桑就是其中之一,打劫其硬盘的念头已计划很久,只待时机成…

评分9.7!这本Python书彻底玩大了?程序员:真香!
「超级星推官/每周分享」是一个围绕程序员生活、学习相关的推荐栏目。CSDN出品,每周发布,暂定5期。关键词:靠谱!优质!本期内容,我们将抽1人送出由我司程序员奉为“超级神作”的《疯狂Python讲义》1本&#…
Caffe源码中caffe.proto文件分析
Caffe源码(caffe version:09868ac , date: 2015.08.15)中有一些重要文件,这里介绍下caffe.proto文件。在src/caffe/proto目录下有一个caffe.proto文件。proto目录下除了caffe.proto文件外,还有caffe.pb.h和caffe.pb.cc两个文件,此两个文件是根…
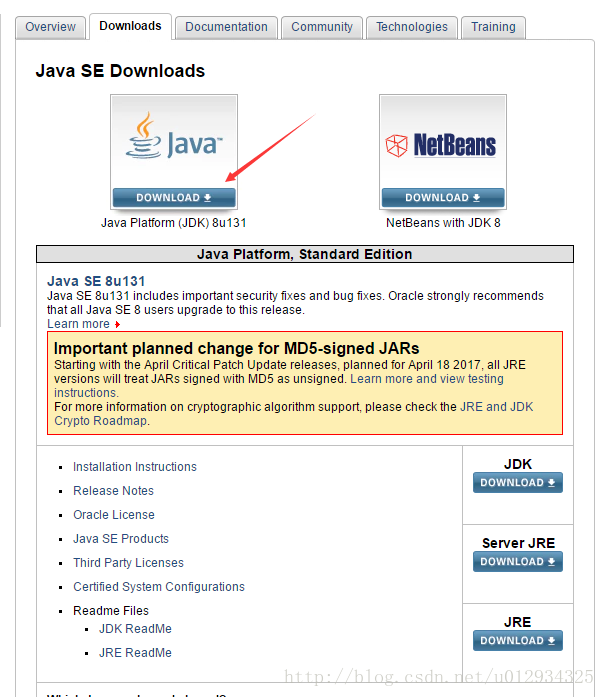
这套完美的Java环境安装教程,完整,详细,清晰可观,让你一目了然,简单易懂。⊙﹏⊙...
JDK下载与安装教程 2017年06月18日 22:53:16 Danishlyy1995 阅读数:349980版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012934325/article/details/73441617学习JAVA,必须得安装一下JDK(java dev…
【畅谈百度轻应用】云时代·轻应用·大舞台
云时代轻应用大舞台刘志勇君不见,上下班的地铁上,低头看手机;同事吃饭聊天,低头看手机;甚至朋友聚会,忙里偷闲打个招呼,然后继续低头看手机。正如微博上一个流传甚广的段子:“世界上…

如何画出高级酷炫的神经网络图?优秀程序员都用了这几个工具
(图片付费下载于视觉中国)作者 | 言有三 来源 | 有三AI(ID:yanyousan_ai)【导读】本文我们聊聊如何才能画出炫酷高大上的神经网络图,下面是常用的几种工具。1、NN-SVGNN-SVG 可以非常方便的画出各种类型的…
OpenBLAS简介及在Windows7 VS2013上源码的编译过程
OpenBLAS(Open Basic Linear Algebra Subprograms)是开源的基本线性代数子程序库,是一个优化的高性能多核BLAS库,主要包括矩阵与矩阵、矩阵与向量、向量与向量等操作。它的License是BSD-3-Clause,可以商用,目前最新的发布版本是0.…

技本功丨请带上纸笔刷着看:解读MySQL执行计划的type列和extra列
本萌最近被一则新闻深受鼓舞,西工大硬核“女学神”白雨桐,获6所世界顶级大学博士录取通知书。货真价值的才貌双全,别人家的孩子高考失利与心仪的专业失之交臂,选择了软件工程这门自己完全不懂的专业.即便全部归零,也要…
精美素材分享:16套免费的扁平化图标下载
在这篇文章中你可以看到16套华丽的扁平化图标素材,对于设计师来说非常有价值,能够帮助他们节省大量的时间。这些精美的扁平化图标可用于多种用途,如:GUI 设计,印刷材料,WordPress 主题,演示&…
Caffe源码中math_functions文件分析
Caffe源码(caffe version:09868ac , date: 2015.08.15)中有一些重要文件,这里介绍下math_functions文件。1. include文件:(1)、<glog/logging.h>:GLog库,它是google的一个开源的日志库,其使用可以参考&…

论文推荐 | 目标检测中不平衡问题算法综述
(图片付费下载于视觉中国)作者 | CV君来源 | 我爱计算机视觉(ID:aicvml)今天跟大家推荐一篇前几天新出的投向TPAMI的论文:Imbalance Problems in Object Detection: A Review,作者详细考察了目标…
php使用redis的GEO地理信息类型
redis3.2中增中了对GEO类型的支持,该类型存储经纬度,提供了经纬设置,查询,范围查询,距离查询,经纬度hash等操作。 <?php$redis new Redis(); $redis->connect(127.0.0.1, 6379, 60); $redis->au…