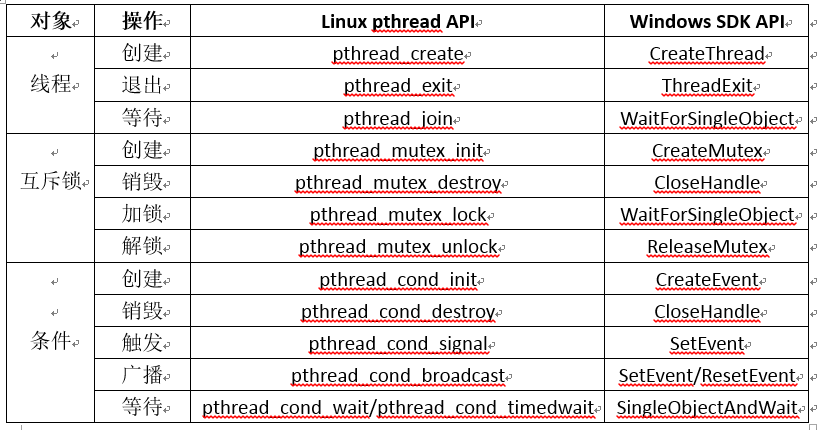
为什么80%的码农都做不了架构师?>>> 
序
本文主要研究一下flink的HistoryServer
HistoryServer
flink-1.7.2/flink-runtime-web/src/main/java/org/apache/flink/runtime/webmonitor/history/HistoryServer.java
public class HistoryServer {private static final Logger LOG = LoggerFactory.getLogger(HistoryServer.class);private final Configuration config;private final String webAddress;private final int webPort;private final long webRefreshIntervalMillis;private final File webDir;private final HistoryServerArchiveFetcher archiveFetcher;@Nullableprivate final SSLHandlerFactory serverSSLFactory;private WebFrontendBootstrap netty;private final Object startupShutdownLock = new Object();private final AtomicBoolean shutdownRequested = new AtomicBoolean(false);private final Thread shutdownHook;public static void main(String[] args) throws Exception {ParameterTool pt = ParameterTool.fromArgs(args);String configDir = pt.getRequired("configDir");LOG.info("Loading configuration from {}", configDir);final Configuration flinkConfig = GlobalConfiguration.loadConfiguration(configDir);try {FileSystem.initialize(flinkConfig);} catch (IOException e) {throw new Exception("Error while setting the default filesystem scheme from configuration.", e);}// run the history serverSecurityUtils.install(new SecurityConfiguration(flinkConfig));try {SecurityUtils.getInstalledContext().runSecured(new Callable<Integer>() {@Overridepublic Integer call() throws Exception {HistoryServer hs = new HistoryServer(flinkConfig);hs.run();return 0;}});System.exit(0);} catch (Throwable t) {final Throwable strippedThrowable = ExceptionUtils.stripException(t, UndeclaredThrowableException.class);LOG.error("Failed to run HistoryServer.", strippedThrowable);strippedThrowable.printStackTrace();System.exit(1);}}public HistoryServer(Configuration config) throws IOException, FlinkException {this(config, new CountDownLatch(0));}public HistoryServer(Configuration config, CountDownLatch numFinishedPolls) throws IOException, FlinkException {Preconditions.checkNotNull(config);Preconditions.checkNotNull(numFinishedPolls);this.config = config;if (config.getBoolean(HistoryServerOptions.HISTORY_SERVER_WEB_SSL_ENABLED) && SSLUtils.isRestSSLEnabled(config)) {LOG.info("Enabling SSL for the history server.");try {this.serverSSLFactory = SSLUtils.createRestServerSSLEngineFactory(config);} catch (Exception e) {throw new IOException("Failed to initialize SSLContext for the history server.", e);}} else {this.serverSSLFactory = null;}webAddress = config.getString(HistoryServerOptions.HISTORY_SERVER_WEB_ADDRESS);webPort = config.getInteger(HistoryServerOptions.HISTORY_SERVER_WEB_PORT);webRefreshIntervalMillis = config.getLong(HistoryServerOptions.HISTORY_SERVER_WEB_REFRESH_INTERVAL);String webDirectory = config.getString(HistoryServerOptions.HISTORY_SERVER_WEB_DIR);if (webDirectory == null) {webDirectory = System.getProperty("java.io.tmpdir") + File.separator + "flink-web-history-" + UUID.randomUUID();}webDir = new File(webDirectory);String refreshDirectories = config.getString(HistoryServerOptions.HISTORY_SERVER_ARCHIVE_DIRS);if (refreshDirectories == null) {throw new FlinkException(HistoryServerOptions.HISTORY_SERVER_ARCHIVE_DIRS + " was not configured.");}List<RefreshLocation> refreshDirs = new ArrayList<>();for (String refreshDirectory : refreshDirectories.split(",")) {try {Path refreshPath = WebMonitorUtils.validateAndNormalizeUri(new Path(refreshDirectory).toUri());FileSystem refreshFS = refreshPath.getFileSystem();refreshDirs.add(new RefreshLocation(refreshPath, refreshFS));} catch (Exception e) {// there's most likely something wrong with the path itself, so we ignore it from here onLOG.warn("Failed to create Path or FileSystem for directory '{}'. Directory will not be monitored.", refreshDirectory, e);}}if (refreshDirs.isEmpty()) {throw new FlinkException("Failed to validate any of the configured directories to monitor.");}long refreshIntervalMillis = config.getLong(HistoryServerOptions.HISTORY_SERVER_ARCHIVE_REFRESH_INTERVAL);archiveFetcher = new HistoryServerArchiveFetcher(refreshIntervalMillis, refreshDirs, webDir, numFinishedPolls);this.shutdownHook = ShutdownHookUtil.addShutdownHook(HistoryServer.this::stop,HistoryServer.class.getSimpleName(),LOG);}@VisibleForTestingint getWebPort() {return netty.getServerPort();}public void run() {try {start();new CountDownLatch(1).await();} catch (Exception e) {LOG.error("Failure while running HistoryServer.", e);} finally {stop();}}// ------------------------------------------------------------------------// Life-cycle// ------------------------------------------------------------------------void start() throws IOException, InterruptedException {synchronized (startupShutdownLock) {LOG.info("Starting history server.");Files.createDirectories(webDir.toPath());LOG.info("Using directory {} as local cache.", webDir);Router router = new Router();router.addGet("/:*", new HistoryServerStaticFileServerHandler(webDir));if (!webDir.exists() && !webDir.mkdirs()) {throw new IOException("Failed to create local directory " + webDir.getAbsoluteFile() + ".");}createDashboardConfigFile();archiveFetcher.start();netty = new WebFrontendBootstrap(router, LOG, webDir, serverSSLFactory, webAddress, webPort, config);}}void stop() {if (shutdownRequested.compareAndSet(false, true)) {synchronized (startupShutdownLock) {LOG.info("Stopping history server.");try {netty.shutdown();} catch (Throwable t) {LOG.warn("Error while shutting down WebFrontendBootstrap.", t);}archiveFetcher.stop();try {LOG.info("Removing web dashboard root cache directory {}", webDir);FileUtils.deleteDirectory(webDir);} catch (Throwable t) {LOG.warn("Error while deleting web root directory {}", webDir, t);}LOG.info("Stopped history server.");// Remove shutdown hook to prevent resource leaksShutdownHookUtil.removeShutdownHook(shutdownHook, getClass().getSimpleName(), LOG);}}}// ------------------------------------------------------------------------// File generation// ------------------------------------------------------------------------static FileWriter createOrGetFile(File folder, String name) throws IOException {File file = new File(folder, name + ".json");if (!file.exists()) {Files.createFile(file.toPath());}FileWriter fr = new FileWriter(file);return fr;}private void createDashboardConfigFile() throws IOException {try (FileWriter fw = createOrGetFile(webDir, "config")) {fw.write(createConfigJson(DashboardConfiguration.from(webRefreshIntervalMillis, ZonedDateTime.now())));fw.flush();} catch (IOException ioe) {LOG.error("Failed to write config file.");throw ioe;}}private static String createConfigJson(DashboardConfiguration dashboardConfiguration) throws IOException {StringWriter writer = new StringWriter();JsonGenerator gen = JsonFactory.JACKSON_FACTORY.createGenerator(writer);gen.writeStartObject();gen.writeNumberField(DashboardConfiguration.FIELD_NAME_REFRESH_INTERVAL, dashboardConfiguration.getRefreshInterval());gen.writeNumberField(DashboardConfiguration.FIELD_NAME_TIMEZONE_OFFSET, dashboardConfiguration.getTimeZoneOffset());gen.writeStringField(DashboardConfiguration.FIELD_NAME_TIMEZONE_NAME, dashboardConfiguration.getTimeZoneName());gen.writeStringField(DashboardConfiguration.FIELD_NAME_FLINK_VERSION, dashboardConfiguration.getFlinkVersion());gen.writeStringField(DashboardConfiguration.FIELD_NAME_FLINK_REVISION, dashboardConfiguration.getFlinkRevision());gen.writeEndObject();gen.close();return writer.toString();}/*** Container for the {@link Path} and {@link FileSystem} of a refresh directory.*/static class RefreshLocation {private final Path path;private final FileSystem fs;private RefreshLocation(Path path, FileSystem fs) {this.path = path;this.fs = fs;}public Path getPath() {return path;}public FileSystem getFs() {return fs;}}
}
- HistoryServer提供了finished jobs的相关查询功能;构造器从配置中读取historyserver.web.address、historyserver.web.port(
默认8082)、historyserver.web.refresh-interval(默认10秒)、historyserver.web.tmpdir、historyserver.archive.fs.dir、historyserver.archive.fs.refresh-interval(默认10秒),然后创建了HistoryServerArchiveFetcher - 其run方法主要是调用start方法,该方法主要是启动HistoryServerArchiveFetcher,然后创建WebFrontendBootstrap
- 构造器使用ShutdownHookUtil.addShutdownHook注册了ShutdownHook,在shutdown时执行stop方法,stop方法主要是调用WebFrontendBootstrap的shutdown方法以及HistoryServerArchiveFetcher的stop方法,然后清理webDir,移除shutdownHook
HistoryServerArchiveFetcher
flink-1.7.2/flink-runtime-web/src/main/java/org/apache/flink/runtime/webmonitor/history/HistoryServerArchiveFetcher.java
class HistoryServerArchiveFetcher {private static final Logger LOG = LoggerFactory.getLogger(HistoryServerArchiveFetcher.class);private static final JsonFactory jacksonFactory = new JsonFactory();private static final ObjectMapper mapper = new ObjectMapper();private final ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor(new ExecutorThreadFactory("Flink-HistoryServer-ArchiveFetcher"));private final JobArchiveFetcherTask fetcherTask;private final long refreshIntervalMillis;HistoryServerArchiveFetcher(long refreshIntervalMillis, List<HistoryServer.RefreshLocation> refreshDirs, File webDir, CountDownLatch numFinishedPolls) {this.refreshIntervalMillis = refreshIntervalMillis;this.fetcherTask = new JobArchiveFetcherTask(refreshDirs, webDir, numFinishedPolls);if (LOG.isInfoEnabled()) {for (HistoryServer.RefreshLocation refreshDir : refreshDirs) {LOG.info("Monitoring directory {} for archived jobs.", refreshDir.getPath());}}}void start() {executor.scheduleWithFixedDelay(fetcherTask, 0, refreshIntervalMillis, TimeUnit.MILLISECONDS);}void stop() {executor.shutdown();try {if (!executor.awaitTermination(1, TimeUnit.SECONDS)) {executor.shutdownNow();}} catch (InterruptedException ignored) {executor.shutdownNow();}}/*** {@link TimerTask} that polls the directories configured as {@link HistoryServerOptions#HISTORY_SERVER_ARCHIVE_DIRS} for* new job archives.*/static class JobArchiveFetcherTask extends TimerTask {private final List<HistoryServer.RefreshLocation> refreshDirs;private final CountDownLatch numFinishedPolls;/** Cache of all available jobs identified by their id. */private final Set<String> cachedArchives;private final File webDir;private final File webJobDir;private final File webOverviewDir;private static final String JSON_FILE_ENDING = ".json";JobArchiveFetcherTask(List<HistoryServer.RefreshLocation> refreshDirs, File webDir, CountDownLatch numFinishedPolls) {this.refreshDirs = checkNotNull(refreshDirs);this.numFinishedPolls = numFinishedPolls;this.cachedArchives = new HashSet<>();this.webDir = checkNotNull(webDir);this.webJobDir = new File(webDir, "jobs");webJobDir.mkdir();this.webOverviewDir = new File(webDir, "overviews");webOverviewDir.mkdir();}@Overridepublic void run() {try {for (HistoryServer.RefreshLocation refreshLocation : refreshDirs) {Path refreshDir = refreshLocation.getPath();FileSystem refreshFS = refreshLocation.getFs();// contents of /:refreshDirFileStatus[] jobArchives;try {jobArchives = refreshFS.listStatus(refreshDir);} catch (IOException e) {LOG.error("Failed to access job archive location for path {}.", refreshDir, e);continue;}if (jobArchives == null) {continue;}boolean updateOverview = false;for (FileStatus jobArchive : jobArchives) {Path jobArchivePath = jobArchive.getPath();String jobID = jobArchivePath.getName();try {JobID.fromHexString(jobID);} catch (IllegalArgumentException iae) {LOG.debug("Archive directory {} contained file with unexpected name {}. Ignoring file.",refreshDir, jobID, iae);continue;}if (cachedArchives.add(jobID)) {try {for (ArchivedJson archive : FsJobArchivist.getArchivedJsons(jobArchive.getPath())) {String path = archive.getPath();String json = archive.getJson();File target;if (path.equals(JobsOverviewHeaders.URL)) {target = new File(webOverviewDir, jobID + JSON_FILE_ENDING);} else if (path.equals("/joboverview")) { // legacy pathjson = convertLegacyJobOverview(json);target = new File(webOverviewDir, jobID + JSON_FILE_ENDING);} else {target = new File(webDir, path + JSON_FILE_ENDING);}java.nio.file.Path parent = target.getParentFile().toPath();try {Files.createDirectories(parent);} catch (FileAlreadyExistsException ignored) {// there may be left-over directories from the previous attempt}java.nio.file.Path targetPath = target.toPath();// We overwrite existing files since this may be another attempt at fetching this archive.// Existing files may be incomplete/corrupt.Files.deleteIfExists(targetPath);Files.createFile(target.toPath());try (FileWriter fw = new FileWriter(target)) {fw.write(json);fw.flush();}}updateOverview = true;} catch (IOException e) {LOG.error("Failure while fetching/processing job archive for job {}.", jobID, e);// Make sure we attempt to fetch the archive againcachedArchives.remove(jobID);// Make sure we do not include this job in the overviewtry {Files.delete(new File(webOverviewDir, jobID + JSON_FILE_ENDING).toPath());} catch (IOException ioe) {LOG.debug("Could not delete file from overview directory.", ioe);}// Clean up job files we may have createdFile jobDirectory = new File(webJobDir, jobID);try {FileUtils.deleteDirectory(jobDirectory);} catch (IOException ioe) {LOG.debug("Could not clean up job directory.", ioe);}}}}if (updateOverview) {updateJobOverview(webOverviewDir, webDir);}}} catch (Exception e) {LOG.error("Critical failure while fetching/processing job archives.", e);}numFinishedPolls.countDown();}}private static String convertLegacyJobOverview(String legacyOverview) throws IOException {JsonNode root = mapper.readTree(legacyOverview);JsonNode finishedJobs = root.get("finished");JsonNode job = finishedJobs.get(0);JobID jobId = JobID.fromHexString(job.get("jid").asText());String name = job.get("name").asText();JobStatus state = JobStatus.valueOf(job.get("state").asText());long startTime = job.get("start-time").asLong();long endTime = job.get("end-time").asLong();long duration = job.get("duration").asLong();long lastMod = job.get("last-modification").asLong();JsonNode tasks = job.get("tasks");int numTasks = tasks.get("total").asInt();int pending = tasks.get("pending").asInt();int running = tasks.get("running").asInt();int finished = tasks.get("finished").asInt();int canceling = tasks.get("canceling").asInt();int canceled = tasks.get("canceled").asInt();int failed = tasks.get("failed").asInt();int[] tasksPerState = new int[ExecutionState.values().length];// pending is a mix of CREATED/SCHEDULED/DEPLOYING// to maintain the correct number of task states we have to pick one of themtasksPerState[ExecutionState.SCHEDULED.ordinal()] = pending;tasksPerState[ExecutionState.RUNNING.ordinal()] = running;tasksPerState[ExecutionState.FINISHED.ordinal()] = finished;tasksPerState[ExecutionState.CANCELING.ordinal()] = canceling;tasksPerState[ExecutionState.CANCELED.ordinal()] = canceled;tasksPerState[ExecutionState.FAILED.ordinal()] = failed;JobDetails jobDetails = new JobDetails(jobId, name, startTime, endTime, duration, state, lastMod, tasksPerState, numTasks);MultipleJobsDetails multipleJobsDetails = new MultipleJobsDetails(Collections.singleton(jobDetails));StringWriter sw = new StringWriter();mapper.writeValue(sw, multipleJobsDetails);return sw.toString();}/*** This method replicates the JSON response that would be given by the JobsOverviewHandler when* listing both running and finished jobs.** <p>Every job archive contains a joboverview.json file containing the same structure. Since jobs are archived on* their own however the list of finished jobs only contains a single job.** <p>For the display in the HistoryServer WebFrontend we have to combine these overviews.*/private static void updateJobOverview(File webOverviewDir, File webDir) {try (JsonGenerator gen = jacksonFactory.createGenerator(HistoryServer.createOrGetFile(webDir, JobsOverviewHeaders.URL))) {File[] overviews = new File(webOverviewDir.getPath()).listFiles();if (overviews != null) {Collection<JobDetails> allJobs = new ArrayList<>(overviews.length);for (File overview : overviews) {MultipleJobsDetails subJobs = mapper.readValue(overview, MultipleJobsDetails.class);allJobs.addAll(subJobs.getJobs());}mapper.writeValue(gen, new MultipleJobsDetails(allJobs));}} catch (IOException ioe) {LOG.error("Failed to update job overview.", ioe);}}
}
- HistoryServerArchiveFetcher主要是以historyserver.archive.fs.refresh-interval的时间间隔从historyserver.archive.fs.dir目录拉取job archives;它内部创建了JobArchiveFetcherTask来执行这个任务
- JobArchiveFetcherTask继承了jdk的TimerTask,其run方法就是遍历refreshDirs,然后执行FileSystem.listStatus,然后使用FsJobArchivist.getArchivedJsons获取ArchivedJson根据不同path写入到指定文件
- 如果path是/jobs/overview,则写入webDir/overviews/jobID.json文件;如果path是/joboverview,则先调用convertLegacyJobOverview转换json,然后再写入webDir/overviews/jobID.json文件;其他的path则写入webDir/path.json文件
WebFrontendBootstrap
flink-1.7.2/flink-runtime-web/src/main/java/org/apache/flink/runtime/webmonitor/utils/WebFrontendBootstrap.java
public class WebFrontendBootstrap {private final Router router;private final Logger log;private final File uploadDir;private final ServerBootstrap bootstrap;private final Channel serverChannel;private final String restAddress;public WebFrontendBootstrap(Router router,Logger log,File directory,@Nullable SSLHandlerFactory serverSSLFactory,String configuredAddress,int configuredPort,final Configuration config) throws InterruptedException, UnknownHostException {this.router = Preconditions.checkNotNull(router);this.log = Preconditions.checkNotNull(log);this.uploadDir = directory;ChannelInitializer<SocketChannel> initializer = new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) {RouterHandler handler = new RouterHandler(WebFrontendBootstrap.this.router, new HashMap<>());// SSL should be the first handler in the pipelineif (serverSSLFactory != null) {ch.pipeline().addLast("ssl", serverSSLFactory.createNettySSLHandler());}ch.pipeline().addLast(new HttpServerCodec()).addLast(new ChunkedWriteHandler()).addLast(new HttpRequestHandler(uploadDir)).addLast(handler.getName(), handler).addLast(new PipelineErrorHandler(WebFrontendBootstrap.this.log));}};NioEventLoopGroup bossGroup = new NioEventLoopGroup(1);NioEventLoopGroup workerGroup = new NioEventLoopGroup();this.bootstrap = new ServerBootstrap();this.bootstrap.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).childHandler(initializer);ChannelFuture ch;if (configuredAddress == null) {ch = this.bootstrap.bind(configuredPort);} else {ch = this.bootstrap.bind(configuredAddress, configuredPort);}this.serverChannel = ch.sync().channel();InetSocketAddress bindAddress = (InetSocketAddress) serverChannel.localAddress();InetAddress inetAddress = bindAddress.getAddress();final String address;if (inetAddress.isAnyLocalAddress()) {address = config.getString(JobManagerOptions.ADDRESS, InetAddress.getLocalHost().getHostName());} else {address = inetAddress.getHostAddress();}int port = bindAddress.getPort();this.log.info("Web frontend listening at {}" + ':' + "{}", address, port);final String protocol = serverSSLFactory != null ? "https://" : "http://";this.restAddress = protocol + address + ':' + port;}public ServerBootstrap getBootstrap() {return bootstrap;}public int getServerPort() {Channel server = this.serverChannel;if (server != null) {try {return ((InetSocketAddress) server.localAddress()).getPort();}catch (Exception e) {log.error("Cannot access local server port", e);}}return -1;}public String getRestAddress() {return restAddress;}public void shutdown() {if (this.serverChannel != null) {this.serverChannel.close().awaitUninterruptibly();}if (bootstrap != null) {if (bootstrap.group() != null) {bootstrap.group().shutdownGracefully();}if (bootstrap.childGroup() != null) {bootstrap.childGroup().shutdownGracefully();}}}
}
- WebFrontendBootstrap使用netty启动了一个http server,其pipeline有HttpServerCodec、ChunkedWriteHandler、HttpRequestHandler、RouterHandler、PipelineErrorHandler;其中这里的RouterHandler的Router有个GET的route,其使用的是HistoryServerStaticFileServerHandler,用于给HistoryServer提供静态文件服务
小结
- HistoryServer提供了finished jobs的相关查询功能;其主要由HistoryServerArchiveFetcher以及WebFrontendBootstrap两部分组成;其run方法主要是调用start方法,该方法主要是启动HistoryServerArchiveFetcher,然后创建WebFrontendBootstrap
- HistoryServerArchiveFetcher主要是以historyserver.archive.fs.refresh-interval的时间间隔从historyserver.archive.fs.dir目录拉取job archives;它内部创建了JobArchiveFetcherTask来执行这个任务;JobArchiveFetcherTask继承了jdk的TimerTask,其run方法就是遍历refreshDirs,然后执行FileSystem.listStatus,然后使用FsJobArchivist.getArchivedJsons获取ArchivedJson根据不同path写入到指定文件
- WebFrontendBootstrap使用netty启动了一个http server,其pipeline有HttpServerCodec、ChunkedWriteHandler、HttpRequestHandler、RouterHandler、PipelineErrorHandler;其中这里的RouterHandler的Router有个GET的route,其使用的是HistoryServerStaticFileServerHandler,用于给HistoryServer提供静态文件服务
doc
- HistoryServer