如何学习SVM?怎么改进实现SVM算法程序?答案来了

编辑 | 忆臻
来源 | 深度学习这件小事(ID:DL_NLP)
【导读】在 3D 动作识别领域,需要用到 SVM(支持向量机算法),但是现在所知道的 SVM 算法很多很乱,相关的程序包也很多,有什么方法可以帮助我们更好地理解 SVM 算法,以及如何利用 matlab 编程实现 SVM 算法,同时在理解原有的程序包以及在原有的程序包基础上进行改进有什么好的方法?本文为知乎问题“如何学习 SVM(支持向量机)以及改进实现 SVM 算法程序?”下的两个答案。
作者:韦易笑https://www.zhihu.com/question/31211585/answer/640501555
学习 SVM 的最好方法是实现一个 SVM,可讲理论的很多,讲实现的太少了。
假设你已经读懂了 SVM 的原理,并了解公式怎么推导出来的,比如到这里:
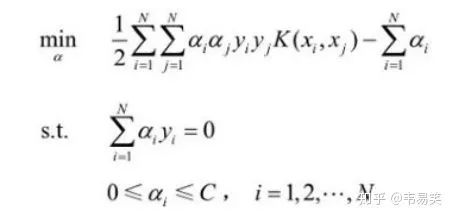
SVM 的问题就变成:求解一系列满足约束的 alpha 值,使得上面那个函数可以取到最小值。然后记录下这些非零的 alpha 值和对应样本中的 x 值和 y 值,就完成学习了,然后预测的时候用:
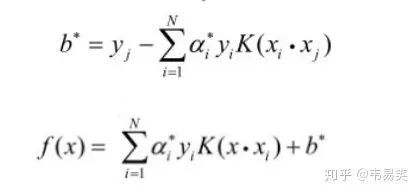
上面的公式计算出 f(x) ,如果返回值 > 0 那么是 +1 类别,否则是 -1 类别,先把这一步怎么来的,为什么这么来找篇文章读懂,不然你会做的一头雾水。
那么剩下的 SVM 实现问题就是如何求解这个函数的极值。方法有很多,我们先找个起点,比如 Platt 的 SMO 算法,它后面有伪代码描述怎么快速求解 SVM 的各个系数。
第一步:实现传统的 SMO 算法
现在大部分的 SVM 开源实现,源头都是 platt 的 smo 算法,读完他的文章和推导,然后照着伪代码写就行了,核心代码没几行:
target = desired output vector
point = training point matrix procedure takeStep(i1,i2) if (i1 == i2) return 0 alph1 = Lagrange multiplier for i1 y1 = target[i1] E1 = SVM output on point[i1] – y1 (check in error cache) s = y1*y2 Compute L, H via equations (13) and (14) if (L == H) return 0 k11 = kernel(point[i1],point[i1]) k12 = kernel(point[i1],point[i2]) k22 = kernel(point[i2],point[i2]) eta = k11+k22-2*k12 if (eta > 0) { a2 = alph2 + y2*(E1-E2)/eta if (a2 < L) a2 = L else if (a2 > H) a2 = H } else { Lobj = objective function at a2=L Hobj = objective function at a2=H if (Lobj < Hobj-eps) a2 = L else if (Lobj > Hobj+eps) a2 = H else a2 = alph2 } if (|a2-alph2| < eps*(a2+alph2+eps)) return 0 a1 = alph1+s*(alph2-a2) Update threshold to reflect change in Lagrange multipliers Update weight vector to reflect change in a1 & a2, if SVM is linear Update error cache using new Lagrange multipliers Store a1 in the alpha array Store a2 in the alpha array return 1
endprocedure核心代码很紧凑,就是给定两个 ai, aj 然后迭代出新的 ai, aj 出来,还有一层循环会不停的选择最需要被优化的系数 ai, aj,然后调用这个函数。如何更新权重和 b 变量(threshold)文章里面都有说,再多调试一下,可以用 python 先调试过了,再换成 C/C++,保证得到一个正确可用的 svm 程序,这是后面的基础。
第二步:实现核函数缓存
观察下上面的伪代码,开销最大的就是计算核函数 K(xi, xj),有些计算又反复用到,一个 100 个样本的数据集求解,假设总共要调用核函数 20 万次,但是 xi, xj 的组和只有 100x100=1万种,有缓存的话你的效率可以提升 20 倍。
样本太大时,如果你想存储所有核函数的组和,需要 N*N * sizeof(double) 的空间,如果训练集有 10 万个样本,那么需要 76 GB 的内存,显然是不可能实现的,所以核函数缓存是一个有限空间的 LRU 缓存,SVM 的 SMO 求解过程中其实会反复的用到特定的几个有限的核函数求解,所以命中率不用担心。
有了这个核函数缓存,你的 svm 求解程序能瞬间快几十倍。
第三步:优化误差值求解
注意看上面的伪代码,里面需要计算一个估计值和真实值的误差 Ei 和 Ej,他们的求解方法是:
这就是目前为止 SMO 这段为代码里代价最高的函数,因为回顾下上面的公式,计算一遍 f(x) 需要 for 循环做乘法加法。
platt 的文章建议是做一个 E 函数的缓存,方便后面选择 i, j 时比较,我看到很多入门版本 svm 实现都是这么搞得。其实这是有问题的,后面我们会说到。最好的方式是定义一个 g(x) 令其等于:
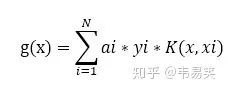
也就是 f(x) 公式除了 b 以外前面那一坨最费时的计算,那么我们随时可以计算误差:
所以最好的办法是对 g(x) 进行缓存,platt 的方法里因为所有 alpha 值初始化成了 0,所以 g(x) 一开始就可以全部设置成 0,稍微观察一下 g(x) 的公式,你就会发现,因为去掉了 b 的干扰,而每次 SMO 迭代更新 ai, aj 参数时,这两个值都是线性变化的,所以我们可以给 g(x) 求一个关于 a 的偏导,假设 ai,aj 变化了步长 delta,那么所有样本对应的 g(x) 加上一个 delta 乘以针对 ai, aj 的偏导数就行了,具体代码类似:
double Kik = kernel(i, k);
double Kjk = kernel(j, k);
G[k] += delta_alpha_i * Kik * y[i] + delta_alpha_j * Kjk * y[j];把这段代码放在 takeStep 后面,每次成功更新一对 ai, aj 以后,更新所有样本对应的 g(x) 缓存,这样通过每次迭代更新 g(x) 避免了大量的重复计算。
这其实是很直白的一种优化方式,我查了一下,有人专门发论文就讲了个类似的方法。
第四步:实现冷热数据分离
Platt 的文章里也证明过一旦某个 alpha 出于边界(0 或者 C)的时候,就很不容易变动,而且伪代码里也是优先再工作集里寻找 > 0 and < C 的 alpha 值进行优化,找不到了,再对工作集整体的 alpha 值进行迭代。
那么我们势必就可以把工作集分成两个部分,热数据在前(大于0小于C的alpha值),冷数据在后(小于等于0 或者大于等于 C 的alpha)再后。
随着迭代加深,会发现大部分时候只需要再热数据里求解,并且热数据的大小会逐步不停的收缩,所以区分了冷热以后你的 SVM 大部分都在针对有限的热数据迭代,偶尔不行了,再全部迭代一次,然后又回到冷热迭代,性能又能提高不少。
第五步:支持 Ensemble
大家都知道,通过 Ensemble 可以让多个不同的弱模型组和成一个强模型,而传统 SVM 实现并不能适应一些类似 AdaBoost 的集成方法,所以我们需要做一些改动。可以让外面针对某一个分类传入一个“权重”过来,修正 SVM 的识别结果。
最传统的修改方式就是将不等式约束 C 分为 Cp 和 Cn 两个针对 +1 分类的 C,和针对 -1 分类的 C。修改方式是直接用原始的 C 乘以各自分类的权重,得到 Cp 和 Cn,然后迭代时,不同的样本根据它的 y 值符号,用不同的 C 值带入计算。
这样 SVM 就能用各种集成方法同其他模型一起组成更为强大精准的模型了。
实现到这一步你就得到了功能上和性能上同 libsvm 类似的东西,接下来我们继续优化。
第六步:继续优化核函数计算
核函数缓存非常消耗内存,libsvm 数学上已经没得挑了,但是工程方面还有很大改进余地,比如它的核缓存实现。
由于标准 SVM 核函数用的是两个高维矢量的内积,根据内积的几个条件,SVM 的核函数又是一个正定核,即 K(xi, xj) = K(xj, xi),那么我们同样的内存还能再多存一倍的核函数,性能又能有所提升。
针对核函数的计算和存储有很多优化方式,比如有人对 NxN 的核函数矩阵进行采样,只计算有限的几个核函数,然后通过插值的方式求解出中间的值。还有人用 float 存储核函数值,又降低了一倍空间需求。
第七步:支持稀疏向量和非稀疏向量
对于高维样本,比如文字这些,可能有上千维,每个样本的非零特征可能就那么几个,所以稀疏向量会比较高效,libsvm 也是用的稀疏向量。
但是还有很多时候样本是密集向量,比如一共 200 个特征,大部分样本都有 100个以上的非零特征,用稀疏向量存储的话就非常低效了,opencv 的 svm 实现就是非稀疏向量。
非稀疏向量直接是用数组保存样本每个特诊的值,在工程方面就有很多优化方式了,比如用的最多的求核函数的时候,直接上 SIMD 指令或者 CUDA,就能获得更好的计算性能。
所以最好的方式是同时支持稀疏和非稀疏,兼顾时间和空间效率,对不同的数据选择最适合的方式。
第八步:针对线性核进行优化
传统的 SMO 方法,是 SVM 的通用求解方法,然而针对线性核,就是:
还有很多更高效的求解思路,比如 Pegasos 算法就用了一种类似随机梯度下降的方法,快速求 svm 的解权重 w,如果你的样本适合线性核,是用一些针对性的非 SMO 算法可以极大的优化 SVM 求解,并且能处理更加庞大的数据集,LIBLINEAR 就是做这件事情的。
同时这类算法也适合 online 训练和并行训练,可以逐步更新的方式增量训练新的样本,还可以用到多核和分布式计算来训练模型,这是 SMO 算法做不到的地方。
但是如果碰到非线性核,权重 w 处于高维核空间里(有可能无限维),你没法梯度下降迭代 w,并且 pegasos 的 pdf 里面也没有提到如何用到非线性核上,LIBLINEAR 也没有办法处理非线性核。
或许哪天出个数学家又找到一种更好的方法,可以用类似 pegasos 的方式求解非线性核,那么 SVM 就能有比较大的进展了。
后话
上面八条,你如果实现前三条,基本就能深入理解 SVM 的原理了,如果实现一大半,就可以得到一个类似 libsvm 的东西,全部实现,你就能得到一个比 libsvm 更好用的 svm 库了。
上面就是如何实现一个相对成熟的 svm 模型的思路,以及配套优化方法,再往后还有兴趣,可以接着实现支持向量回归,也是一个很有用的东西。
作者:mmggqqhttps://www.zhihu.com/question/31211585/answer/334551171
讲道理,现在绝大部分的开源 SVM 算法实现都比自己实现的效率高不知道多少倍(除非你是超级大牛),如果你想更好地理解原有的程序包并且在其上面改进的话,除了读人家的实现库文档和源码并没有其他捷径。但是我还是建议在理论学习完 SVM 后自己实现一个简单的玩具,在实际运用中还是运用别人的库把,你需要的功能绝大部分上面都有实现。
(*本文为AI科技大本营转载文章,转载请联系作者)
推荐阅读
CSDN“2019 优秀AI、IoT应用案例TOP 30+”正式发布
六大主题报告,四大技术专题,AI开发者大会首日精华内容全回顾
如何打造高质量的机器学习数据集?这份超详指南不可错过
从模型到应用,一文读懂因子分解机
用Python爬取淘宝2000款套套
7段代码带你玩转Python条件语句
高级软件工程师教会小白的那些事!
谁说 C++ 的强制类型转换很难懂?

你点的每个“在看”,我都认真当成了喜欢
相关文章:

跟着石头哥哥学cocos2d-x(三)---2dx引擎中的内存管理模型
2019独角兽企业重金招聘Python工程师标准>>> 2dx引擎中的对象内存管理模型,很简单就是一个对象池引用计数,本着学好2dx的好奇心,先这里开走吧,紧接上面两节,首先我们看一个编码场景代码: hello…

读8篇论文,梳理BERT相关模型进展与反思
作者 | 陈永强来源 | 微软研究院AI头条(ID:MSRAsia)【导读】BERT 自从在 arXiv 上发表以来获得了很大的成功和关注,打开了 NLP 中 2-Stage 的潘多拉魔盒。随后涌现了一大批类似于“BERT”的预训练(pre-trained)模型,有…
Dlib库中实现正脸人脸检测的测试代码
Dlib库中提供了正脸人脸检测的接口,这里参考dlib/examples/face_detection_ex.cpp中的代码,通过调用Dlib中的接口,实现正脸人脸检测的测试代码,测试代码如下:#include "funset.hpp" #include <string>…

20189317 《网络攻防技术》 第二周作业
一.黑客信息 (1)国外黑客 1971年,卡普尔从耶鲁大学毕业。在校期间,他专修心理学、语言学以及计算机学科。也就是在这时他开始对计算机萌生兴趣。他继续到研究生院深造。20世纪60年代,退学是许多人的一个选择。只靠知识…

centos 6.4 SVN服务器多个项目的权限分组管理
根据本博客中的cent OS 6.4下的SVN服务器构建 一文,搭建好SVN服务器只能管理一个工程,如何做到不同的项目,多个成员的权限管理分配呢?一 需求开发服务器搭建好SVN服务器,不可能只管理一个工程项目,如何做到…

cifar数据集介绍及到图像转换的实现
CIFAR是一个用于普通物体识别的数据集。CIFAR数据集分为两种:CIFAR-10和CIFAR-100。The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.CIFAR-10由…

取代Python?Rust凭什么
作者 | Nathan J. Goldbaum译者 | 弯月,责编 | 屠敏来源 | CSDN(ID:CSDNnews)【导语】Rust 也能实现神经网络?在前一篇帖子中,作者介绍了MNIST数据集以及分辨手写数字的问题。在这篇文章中,他将…

【Mac】解决「无法将 chromedriver 移动到 /usr/bin 目录下」问题
问题描述 在搭建 Selenium 库 ChromeDriver 爬虫环境时,遇到了无法将 chromedriver 移动到 /usr/bin 目录下的问题,如下图: 一查原来是因为系统有一个 System Integrity Protection (SIP) 系统完整性保护,如果此功能不关闭&#…
【译文】怎样让一天有36个小时
作者:Jon Bischke原文地址:How to Have a 36 Hour Day 你经常听人说“真希望一天能多几个小时”或者类似的话吗?当然,现实中我们每天只有24小时。这么说吧,人和人怎样度过这24个小时是完全不同的。到现在这样的说法已经…
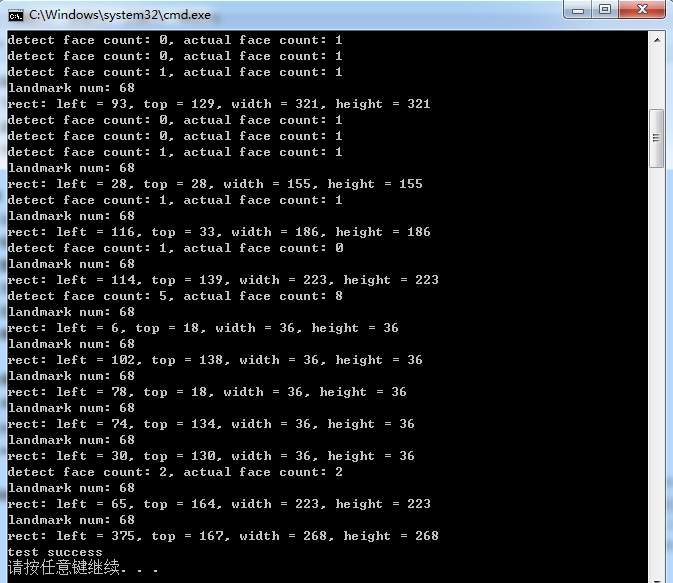
Dlib库中实现正脸人脸关键点(landmark)检测的测试代码
Dlib库中提供了正脸人脸关键点检测的接口,这里参考dlib/examples/face_landmark_detection_ex.cpp中的代码,通过调用Dlib中的接口,实现正脸人脸关键点检测的测试代码,测试代码如下:/* reference: dlib/examples/face_l…
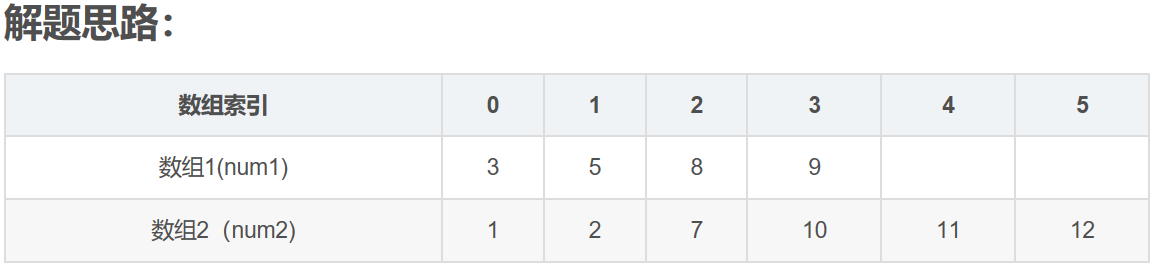
LeetCode--004--寻找两个有序数组的中位数(java)
转自https://blog.csdn.net/chen_xinjia/article/details/69258706 其中,N14,N26,size4610. 1,现在有的是两个已经排好序的数组,结果是要找出这两个数组中间的数值,如果两个数组的元素个数为偶数,则输出的是中间两个元…

开源sk-dist,超参数调优仅需3.4秒,sk-learn训练速度提升100倍
作者 | Evan Harris译者 | Monanfei编辑 | Jane 出品 | AI科技大本营(ID:rgznai100)【导语】这篇文章为大家介绍了一个开源项目——sk-dist。在一台没有并行化的单机上进行超参数调优,需要 7.2 分钟,而在一百多个核心的 Spark 群集…
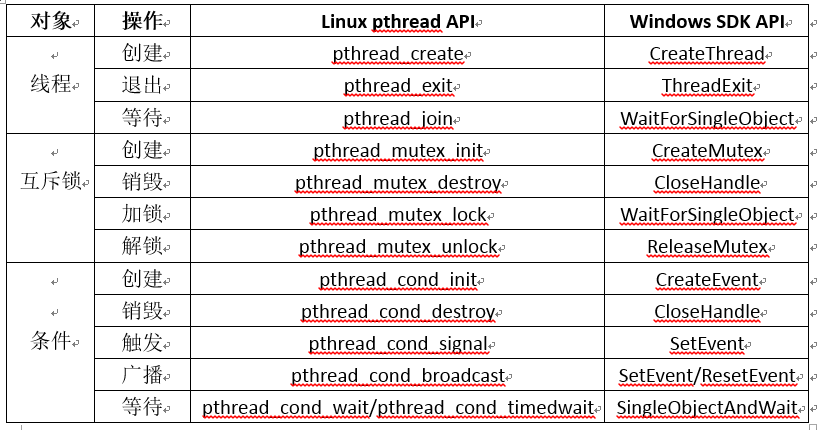
Windows和Linux下通用的线程接口
对于多线程开发,Linux下有pthread线程库,使用起来比较方便,而Windows没有,对于涉及到多线程的跨平台代码开发,会带来不便。这里参考网络上的一些文章,整理了在Windows和Linux下通用的线程接口。经过测试&am…
MySQL 性能调优的10个方法
MYSQL 应该是最流行了 WEB 后端数据库。WEB 开发语言最近发展很快,PHP, Ruby, Python, Java 各有特点,虽然 NOSQL 最近越來越多的被提到,但是相信大部分架构师还是会选择 MYSQL 来做数据存储。MYSQL 如此方便和稳定,以…

他们用卷积神经网络,发现了名画中隐藏的秘密
作者 | 神经小刀来源 |HyperAI超神经( ID: HyperAI)导语:著名的艺术珍品《根特祭坛画》,正在进行浩大的修复工作,以保证现在的人们能感受到这幅伟大的巨制,散发出的灿烂光芒。而随着技术的进步,…
机器学习公开课~~~~mooc
https://class.coursera.org/ntumlone-001/class/index

DLM:微信大规模分布式n-gram语言模型系统
来源 | 微信后台团队Wechat & NUS《A Distributed System for Large-scale n-gram Language Models at Tencent》分布式语言模型,支持大型n-gram LM解码的系统。本文是对原VLDB2019论文的简要翻译。摘要n-gram语言模型广泛用于语言处理,例如自动语音…
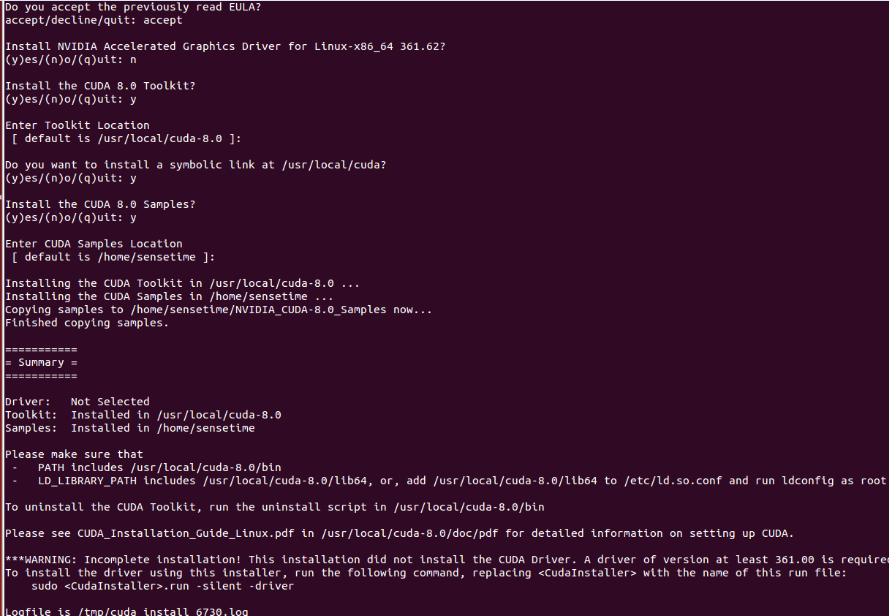
Ubuntu14.04 64位机上安装cuda8.0+cudnn5.0操作步骤
查看Ubuntu14.04 64位上显卡信息,执行:lspci | grep -i vga lspci -v -s 01:00.0 nvidia-smi第一条此命令可以显示一些显卡的相关信息;如果想查看某个详细信息,可以执行第二条命令;如果是NVIDIA卡, 可继续执行第三条命…

SQLI DUMB SERIES-5
less5 (1)输入单引号,回显错误,说明存在注入点。输入的Id被一对单引号所包围,可以闭合单引号 (2)输入正常时:?id1 说明没有显示位,因此不能使用联合查询了;可…
javascript RegExp
http://www.w3schools.com/jsref/jsref_obj_regexp.asp声明-------------modifiers:{i,g,m}1. var pattnew RegExp(pattern,modifiers);2. var patt/pattern/modifiers;------------------------例子:var str "Visit W3Schools"; //两…
Ubuntu14.04 64位机上安装OpenCV2.4.13(CUDA8.0)版操作步骤
Ubuntu14.04 64位机上安装CUDA8.0的操作步骤可以参考http://blog.csdn.net/fengbingchun/article/details/53840684,这里是在已经正确安装了CUDA8.0的基础上安装OpenCV2.4.13(CUDA8.0)操作步骤:1. 从http://opencv.org/downloads.html 下载OpenCV2.…
一篇文章能够看懂基础代码之CSS
web页面主要分为三块内容:js:控制用户行为和执行代码行为html元素:控制页面显示哪些控件(例如按钮,输入框,文本等)css:控制如何显示页面上的空间,例如布局,颜…

谷歌NIPS论文Transformer模型解读:只要Attention就够了
作者 | Sherwin Chen译者 | Major,编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100)导读:在 NIPS 2017 上,谷歌的 Vaswani 等人提出了 Transformer 模型。它利用自我注意(self-attention)来计算其…

中国移动与苹果联姻 三星在华霸主地位或遭取代
据国外媒体12月24日报道,在各方的期待下,苹果终于宣布中国移动将于2014年1月17日开始销售支持其网络的iPhone手机。而中国移动也将于12 月25日开始正式接受预定。作为中国以及世界最大的移动运营商,中国移动与苹果的合作,将会帮助…

二维码Data Matrix编码、解码使用举例
二维码Data Matrix的介绍见: http://blog.csdn.net/fengbingchun/article/details/44279967 ,这里简单写了个生成二维码和对二维码进行识别的测试例子,如下:int test_data_matrix_encode() {std::string str "中国_abc_DEF…
PDF文件如何转成markdown格式
百度上根据pdf转makrdown为关键字进行搜索,结果大多数是反过来的转换,即markdown文本转PDF格式。 但是PDF转markdown的解决方案很少。 正好我工作上有这个需求,所以自己实现了一个解决方案。 下图是一个用PDF XChange Editor打开的PDF文件&am…
关于SAP BW提示“Carry out repairs in non-original only
为什么80%的码农都做不了架构师?>>> 这个提示是由于你在生产系统(正式系统)里面修改了一些东西,才提示"Carry out repairs in non-original system only if they are urgent"这个警告,理论上我们…
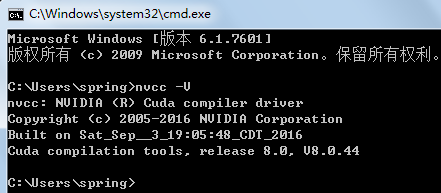
windows7 64位机上安装配置CUDA7.5(或8.0)+cudnn5.0操作步骤
按照官网文档 http://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html#axzz4TpI4c8vf 进行安装:在windows7上安装cuda8.0/cuda7.5的系统需求:(1)、ACUDA-capable GPU(本机显卡为GeForce GT 640M);(2)、A support…
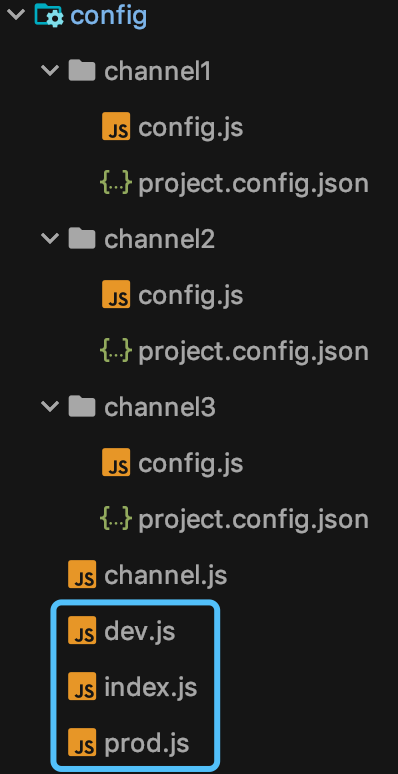
多重影分身:一套代码如何生成多个小程序?
前言 影分身术,看过火影的都知道,一个本体,多个分身。 大家肯定要问了,那小程序开发跟影分身术也能扯上关系?没错,那自然就是:一套代码,多个小程序啦。 各位先别翻白眼,且…

TensorFlow全家桶的落地开花 | 2019 Google开发者日
作者 | 唐小引写于上海世博中心出品 | GDD 合作伙伴 CSDN(ID:CSDNnews)Android 10 原生支持 5G,Flutter 1.9、Dart 2.5 正式发布这是 Google Developer Days 在中国的第四年,从 2016 年 Google Developers 中国网站正式…