【剑指offer|图解|二分查找】点名 + 统计目标成绩的出现次数

🌈个人主页:聆风吟
🔥系列专栏:数据结构、剑指offer每日一练
🔖少年有梦不应止于心动,更要付诸行动。
文章目录
一. ⛳️点名
1.1 题目
某班级 n 位同学的学号为 0 ~ n-1。点名结果记录于升序数组 records。假定仅有一位同学缺席,请返回他的学号。
1.2 示例
输入: records = [0,1,2,3,5]
输出: 4
1.3 限制
- 1 <= records.length <= 10000
1.4 解题思路一
二分查找
根据题意,数组可以按照以下规则进行划分为两部分:
- 左子数组:records[i] = i
- 右子数组:records[i] != i
缺失的数字等于 右子数组的首位元素 对应的索引,因此我们可以使用二分查找右子数组首元素。

算法执行过程:
- 初始化 :左边界 l = 0 和 右边界 r = records.size() - 1
- 循环二分:当 l <= r 时循环
- 计算中心点 mid = (l + r) / 2;
- 如果 records[mid] = mid 说明要查找的值在区间[mid + 1, r] 之间,因此执行 l = mid + 1;
- 如果 records[mid] != mid 说明要查找的值在区间[l, mid - 1] 之间,因此执行 r = mid - 1;
- 返回值:循环跳出时,返回 l 即可。

c++代码
class Solution {
public:
int takeAttendance(vector<int>& records) {
int sz = records.size();
int l = 0;
int r = sz - 1;
while(l <= r)
{
int mid = (l + r) >> 1;
if(records[mid] == mid) l = mid + 1;
else r = mid -1;
}
return l;
};
1.5 解题思路二
求和做差
有题目可知:
将 0 ~ n - 1 之间所有同学的学号加在一起,然后减去数组中的每个元素,所得结果即是缺课人学号。

c++代码
class Solution {
public:
int takeAttendance(vector<int>& records) {
int sz = records.size();
int sum = sz*(sz+1)/2;//使用等差求和公式求全班学号的总和
//将全班人的学号 - 数组中的每一个元素
for(int i = 0; i < sz; i++)
{
sum -= records[i];
}
return sum;
}
};
二. ⛳️统计目标成绩的出现次数
1.1 题目
某班级考试成绩按非严格递增顺序记录于整数数组 scores,请返回目标成绩 target 的出现次数。
1.2 示例
输入: scores = [2, 2, 3, 4, 4, 4, 5, 6, 6, 8], target = 4
输出: 3
1.3 限制
- 0 <= scores.length <= 105
- -109 <= scores[i] <= 109
- scores 是一个非递减数组
- -109 <= target <= 109
1.4 解题思路
对于已经排好序的数组查找问题,首先我们可以想到是用二分查找。
对于排序数组 scores 中所有数字 target 形成一个窗口,记做窗口的 左 / 右边界 索引分别为 left 和 right,分别对应窗口的左右两边。因此本题求数字 target 出现的次数,就可以转化为:使用二分法分别求出窗口的左边界 left 和 右边界 right,容易得出数字 target 出现的次数 right - left + 1。

1. 查找右边界:
//查找右边界
while(l < r)
{
int mid = (l + r + 1) >> 1;
if(scores[mid] <= target) l = mid;
else r = mid - 1;
}

注意:
- 在查找完右边界后,需要用
scores[right]判断一下数组中是否含有 target,若不包含则直接提前返回 0,无需继续查找左边界- 记得让指针 l,r 重新回到起点处
2. 查找左边界:
//查找左边界
while(l < r)
{
int mid = (l + r) >> 1;
if(scores[mid] >= target) r = mid;
else l = mid + 1;
}
由于左边界的查找同右边界运行类似,大家可以在下面自己画出图形,调试。
c++代码
class Solution {
public:
int countTarget(vector<int>& scores, int target) {
int sz = scores.size();
int l = 0;
int r = sz - 1;
// 搜索右边界
while(l < r)
{
int mid = (l + r + 1) >> 1;
if(scores[mid] <= target) l = mid;
else r = mid - 1;
}
int right = r;
// 若数组中无 target ,则提前返回
if(r >= 0 && scores[right] != target) return 0;
// 搜索左边界
l = 0, r = sz - 1;//让指针返回到初始状态
while(l < r)
{
int mid = (l + r) >> 1;
if(scores[mid] >= target) r = mid;
else l = mid + 1;
}
int left = l;
return right - left + 1;
}
};
📝结语
今天的干货分享到这里就结束啦!如果觉得文章还可以的话,希望能给个三连支持一下,聆风吟的主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是作者前进的最大动力!

相关文章:
23种策略模式之策略模式
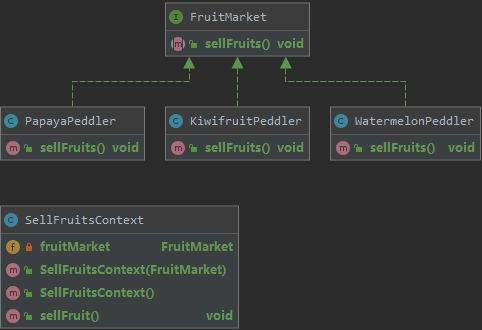
在软件开发中,设计模式是为了解决常见问题而提供的一套可重用的解决方案。策略模式(Strategy Pattern)是其中一种常见的设计模式,它属于行为型模式。该模式的核心思想是将不同的算法封装成独立的策略类,使得它们可以相互替换,而不影响客户端的使用。策略模式与其他设计模式有一些明显的区别。与模板方法模式相比,策略模式强调算法的灵活性,允许在运行时切换不同的策略。与状态模式相比,策略模式更注重不同算法之间的替换性,而非状态的内部转换。策略Context(上下文)
VM-Linux 桥接网络设置
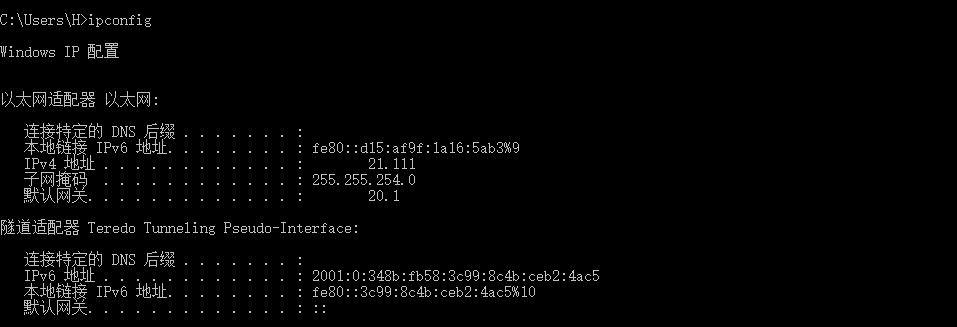
网络桥接是将两个或多个独立的网络进行连接的一种方法。它可以把两个网络的数据传输机制集成在一起,使得用户可以更顺畅地访问各个网络,从而实现更高效的数据传输。在网络桥接中,桥接设备是实现连接的关键。它可以根据需要连接多个网络,将数据的帧从源设备转发到目标设备。这些桥接设备多数使用硬件或软件技术进行实现,并提供低延迟和高吞吐量的传输性能。网络桥接的应用范围非常广泛,例如以太网、无线局域网和广域网等。通过这种方法,企业和个人用户可以快速进行文件共享、远程访问、视频聊天等网络任务,提高了工作和生活效率。

详解Spring@AutoWired多种方式的依赖注入——List,Map类型
在Spring框架进行bean对象依赖注入时,@Autowired利用可以对成员变量、方法和构造函数进行标注,来完成自动装配的工作。@Autowired可标注在成员变量,也可以标注在成员变量的set方法上,以及类得构造函数上。对于标注在成员变量上的方式,通常的做法是标注在单个类型的变量上,Spring框架提供了强大的DI能力能够实现对Collection类型的自动注入。
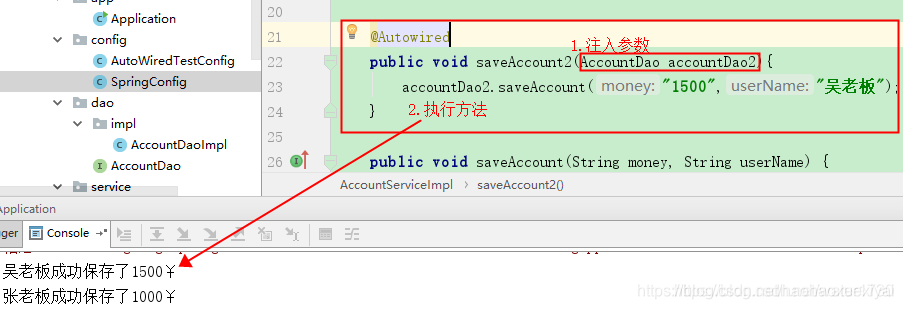
Spring中@Autowired注解作用在方法上和属性上说明
换句话说,在Spring创建bean的过程中,会为这个bean中标有@Autowired注解的构造器,变量域,方法和方法参数中自动注入我们需要的已经在Spring IOC容器里面的bean,,而无需我们手动完成,并且注入的bean都是单实例,也就是在两个bean中都依赖第三个bean,那么这两个bean中注入的第三个bean会是同一个bean(JVM中指向的地址相同)。下面进行测试,打印的结果显示可以拿到Wheel类,说明@Autowired注解在IOC容器中只有一个类型的bean时,按照类型进行注入。

Linux安装JDK 并在 单台服务器 搭建多个tomcat version 1.8 并解决 多个tomcat 无法同时启动问题以及 关闭单个tomcat 导致其他tomcat一同关闭
假如 虚拟机没有配置网络JDK 1.8Tomcat-8。

颜色十六进制代码对照表
淡紫色 #DB70DB 84 浅绿色 #8FBC8F 85 粉红色 #BC8F8F。巧克力色 #5C3317 11 蓝紫色 #9F5F9F 12 黄铜色 #B5A642。浅蓝色 #C0D9D9 48 浅灰色 #A8A8A8 49 浅钢蓝色 #8F8FBD。半甜巧克力色#6B4226 93 赭色 #8E6B23 94 银色 #E6E8FA。

讲解from .pycaffe import Net, SGDSolver, NesterovSolver, AdaGradSolver, RMSPropSolver, AdaDeltaSolver,
相比于AdaGrad,AdaDelta算法进一步减少了学习率震荡的问题,并提供了更平稳的优化过程。以上六个模块在Caffe中发挥着重要的作用,为深度学习模型的训练和优化提供了基础支持。通过合理选择和配置这些模块,我们可以根据具体任务和模型需求进行高效的训练和推理。它是一种自适应学习率方法,通过使用梯度平方的滑动平均值来调整每个参数的学习率。如果你对Caffe框架、深度学习模型训练有进一步的兴趣,建议你阅读Caffe的官方文档和资源,深入学习和探索。模块,我们可以创建和操控神经网络,从而进行模型训练和推理。

解决方案:avcodec_receive_packet AVERROR(EAGAIN)
FFmpeg是一个开源的跨平台音视频处理工具集,它由一个主命令行工具和一组库组成,提供了音视频编解码、格式转换、流媒体处理、音视频过滤、音视频录制和播放等功能。错误,我们将继续循环,直到获取到一个有效的数据包或遇到其他错误。同时,根据实际情况,调整解码器的缓冲区大小也可能有助于提高解码性能和减少错误发生的频率。然后,我们获取音频解码器并创建解码器上下文,并进行解码器的初始化。错误,并在实际应用场景中对解码后的音频数据包进行处理和分析。你可以根据自己的需求,进一步扩展和定制代码。,如果是的话,我们继续循环。
ERROR: EMQX 5.3.1 using node name ‘emqx@127.0.0.1‘ failed 120 probes
' 失败 120 次探测”的错误消息,你可以通过修改节点名称、检查监听地址和端口,以及检查配置文件的语法和格式来解决这个问题。如果有其他进程使用了相同的IP地址和端口,你可以修改EMQX的配置文件,将IP地址和端口修改为其他可用的值。在使用EMQX 5.3.1作为 MQTT 消息代理服务器时,你可能会遇到一个错误消息:“ERROR: EMQX 5.3.1 使用节点名称 '确保每个节点的名称是唯一的,例如可以添加一个后缀来区分不同的节点。如果你在部署EMQX节点时,已经有一个节点使用了相同的名称 '

C/C++,FEISTDLIB的部分源代码
C/C++,FEISTDLIB的部分源代码

23种设计模式之单例模式(懒汉,饿汉,线程安全懒汉)
我们知道设计模式分为23种但是具体划分的话,又分为三大类①:创建型②:结构型③:行为型,本文会介绍创建型的单例模式希望各位能够简单的去了解单例模式以及能够在正常的开发中得到运用,单例模式常见的有饿汉型单例模式、懒汉型单例模式、懒汉线程安全型单例模式,实际上单例模式有七种左右,本文仅介绍常见的三种。从具体实现角度来说,就是以下三点:一是单例模式的类只提供私有的构造函数,二是类定义中含有一个该类的静态私有对象,三是该类提供了一个静态的公有的函数用于创建或获取它本身的静态私有对象。显然单例模式的要点有三个;
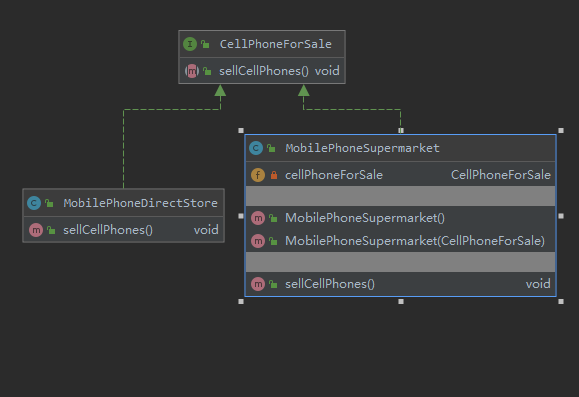
23种设计模式之代理模式(抽象层,代理者,被代理者)
设计模式原则之一开闭原则简而言之就是扩展开发修改关闭以上面的案例来说扩展开发当我们将手机直营店代理后,只要抽象层手机出售接口拥有的行为 我们的手机超市都可以拥有,当手机直营店行为不是特别满足需求时,我们也可以在手机超市上去为手机直营店进行扩展。修改关闭手机超市并不能改变手机直营店的出售手机行为,能对原有的业务进行扩展,并且不修改原有的代码,这就是开闭原则。异变代理模式个人认为 代理模式只是为了控制外界对被代理对象的访问,不应该因为业务需求强行在代理类中增加业务代码,不然跟装饰者模式有什么区别呢?
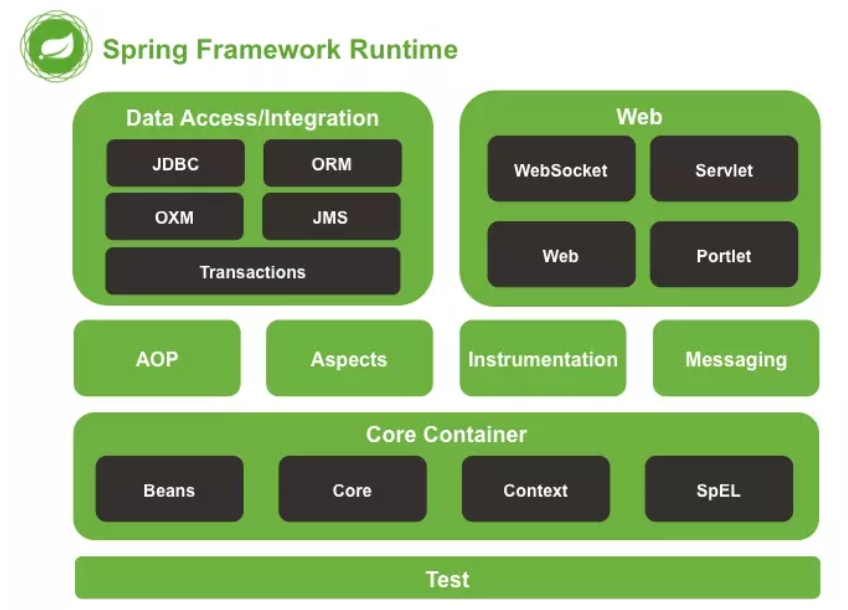
spring 笔记一 spring快速入门和配置文件详解
Spring是分层的 Java SE/EE应用full-stack 轻量级开源框架,以 IoC(Inverse Of Control:反转控制)和AOP(Aspect Oriented Programming:面向切面编程)为内核。提供了展现层SpringMVC 和持久层 Spring JDBCTemplate以及业务层事务管理等众多的企业级应用技术,还能整合开源世界众多著名的第三方框架和类库,逐渐成为使用最多的Java EE 企业应用开源框架。

spring 笔记二 spring配置数据源和整合测试功能
• 数据源(连接池)是提高程序性能如出现的• 事先实例化数据源,初始化部分连接资源• 使用连接资源时从数据源中获取• 使用完毕后将连接资源归还给数据源常见的数据源(连接池):DBCP、C3P0、BoneCP、Druid① 导入数据源的坐标和数据库驱动坐标② 创建数据源对象③ 设置数据源的基本连接数据④ 使用数据源获取连接资源和归还连接资源。

【Spring boot】RedisTemplate中String、Hash、List设置过期时间
putIfAbsent 指的是如果传入key对应的value已经存在,就返回存在的value,不进行替换。如果不存在,就添加key和value,返回null。如果传入key对应的value已经存在,就返回存在的value,不进行替换。如果不存在,就添加key和value,返回null。下面这两句话,可以实现向Redis插入Hash数据,并且设置整个Hash的过期时间。TimeUnit.MILLISECONDS:毫秒。TimeUnit.MILLISECONDS:微秒。TimeUnit.MINUTES:分。
【Harmony】鸿蒙操作系统架构
鸿蒙操作系统以其微内核架构、分布式能力和全场景覆盖的设计理念,成为当前技术领域一颗璀璨的明星。其架构设计满足了当前多样化的设备需求,注重了设备之间的协同工作和开发者的友好体验。随着鸿蒙操作系统的不断演进和生态系统的丰富,我们对于这个在全球范围内掀起一场科技变革的产物充满期待。在未来的智能互联时代,鸿蒙操作系统必将发挥更为重要的作用,引领技术的潮流。_鸿蒙系统的架构

Redis的opsForValue()和boundValueOps()区别
该模板的序列化机制改变起来也很容易,并且Redis模块在org.springframework.data.redis.serializer包中提供了多种可用的实现,详情请参考Serializers。大部分的用户都喜欢用RedisTemplate,它相应的包是org.springframework.data.redis.core。虽然RedisConnection提供接受和返回二进制值(字节数组)的低级方法,但该模板可以处理序列化和连接管理,使得用户不需要处理太多的细节。如果 两者是实现的效果是相同的。

C/C++,动态 DP 问题的计算方法与源程序
C/C++,动态 DP 问题的计算方法与源程序

软路由R4S+iStoreOS如何实现公网远程桌面本地电脑
本文主要讲解如何使用软路由R4S和iStoreOS实现公网远程桌面本地电脑

将labelme标注的人体姿态Json文件转成训练Yolov8-Pose的txt格式
最近在训练Yolov8-Pose时遇到一个问题,就是如何将自己使用labelme标注的Json文件转化成可用于Yolov8-Pose训练的txt文件。

【redis】Redis中AOF的重写机制
为了避免子进程在重写过程过程中,主进程中的数据发生变化,导致AOF文件里面的数据和redis内存中的数据不一致,redis中还做了一个优化,也就是说在子进程在做这个重写的过程中,主进程中的数据变更,需要追加到AOF的重写缓冲区中,等到AOF重写完成以后,再把AOF重写缓冲区的数据,追加到新的AOF文件里面,这样意料就能保证新的AOF文件里面的数据和当前Redis中的数据保持一致。子进程在进行重写的过程中,主进程依然可以去处理客户端的一个请求,这样一来子进程在重写的过程中,不耽误客户端的使用。

【redis】为什么Redis集群的最大槽数是16384个?
对网络同学开销的平衡:redis集群中的每个节点,会发送心跳消息,而心跳包中会携带节点的完整配置,他能够以幂等的方式来实现配置的更新。但是修改集群的槽位数量需要进行数据迁移和重新均衡,会对集群产生较大的影响,因此一般情况下建议使用默认的 16384 个槽位。可用性和容错性:16384 是一个较大的数字,可以提供足够的槽位数量来分布数据,从而提高集群的可用性和容错性。应用程序去存储一个key的时候会通过,对key进行一个CRC16去计算,再取模,然后路由到hash slot所在的节点。
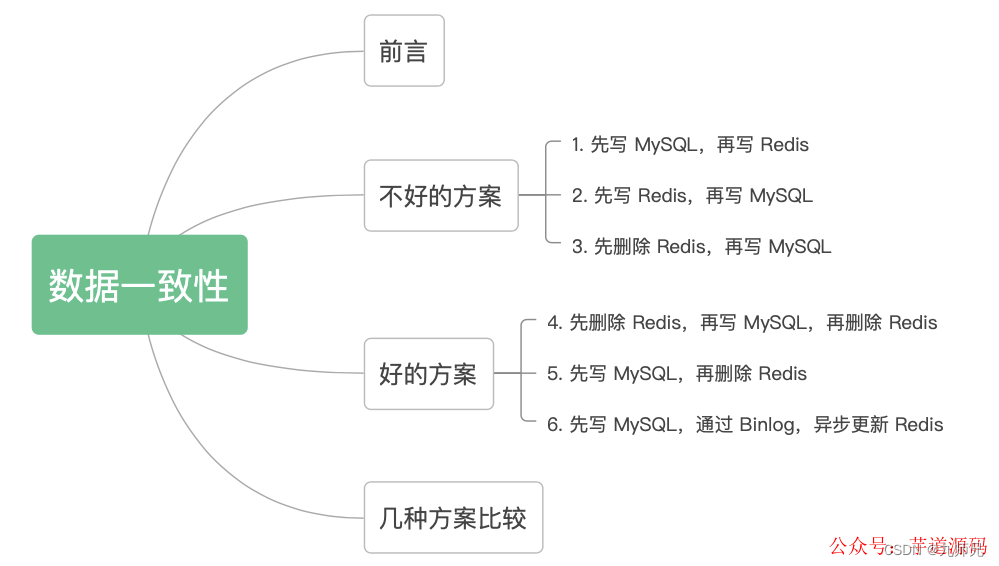
【redis】技术派中的缓存一致性解决方案
对于上面这种情况,对于第一次查询,请求 B 查询的数据是 10,但是 MySQL 的数据是 11,只存在这一次不一致的情况,对于不是强一致性要求的业务,可以容忍。这个图已经画的很清晰了,我就不用再去啰嗦了吧,不过这里有个前提,就是对于读请求,先去读 Redis,如果没有,再去读 DB,但是读请求不会再回写 Redis。请求 A、B 都是先写 MySQL,然后再写 Redis,在高并发情况下,如果请求 A 在写 Redis 时卡了一会,请求 B 已经依次完成数据的更新,就会出现图中的问题。
讲解cv2.setNumThreads
本文讲解了 cv2.setNumThreads 函数的作用和用法。通过设置并行处理的线程数目,我们可以控制 OpenCV 在图像和视频处理中使用的线程数量,从而提高程序的性能和效率。了解和正确使用 cv2.setNumThreads 函数对于优化计算机视觉应用程序的性能非常重要。希望本文能对读者理解并正确使用 cv2.setNumThreads 函数提供帮助。

讲解undefined reference to symbol ‘_ZN2cv7imwriteERKNS_6StringERKNS_11_InputArrayERKSt6vectorIiSaIiEE‘
在本文中,我们讨论了一个常见的错误信息,并解释了它的含义以及可能的解决方法。请记住,在遇到这种错误时,你应该首先确认是否正确链接库文件,包含正确的头文件,正确配置环境以及检查版本兼容性。通过采取适当的措施,你应该能够解决这个错误并顺利编译和链接你的程序。当遇到这个错误时,通常是因为在编译和链接时没有正确地指定OpenCV库文件。下面是一个示例代码,展示了如何使用OpenCV的imwrite函数来保存图像。首先,你需要确保你的系统已经安装了OpenCV,并正确配置了环境。// 读取图像if (!

讲解Expected more than 1 value per channel when training, got input size torch.Size
在训练深度学习模型时,遇到错误消息"Expected more than 1 value per channel when training, got input size torch.Size"时,我们需要检查数据预处理的过程,确保输入数据的形状满足模型的要求。通过检查数据形状、数据预处理代码和模型的输入层,我们可以找出错误的原因并进行修复。这样,我们就可以成功训练模型并获得预期的结果。
讲解RuntimeError: cudnn64_7.dll not found.
"RuntimeError: cudnn64_7.dll not found" 错误是在使用GPU加速深度学习过程中的常见错误之一。本文介绍了解决这个错误的几种常见方法,包括检查CUDA和cuDNN的安装、确认环境变量配置、检查软件依赖关系以及重新安装CUDA和cuDNN。通过按照以上步骤逐一排查和解决,您应该能够成功地解决这个错误,并顺利进行GPU加速的深度学习任务。祝您顺利完成深度学习项目!
讲解Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False
"Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False" 错误提示表明您的代码尝试将一个在 CUDA 设备上训练好的模型加载到不支持 CUDA 的设备上,或者是将其加载到 CPU 上。在 PyTorch 中,当您试图将一个已经在 CUDA 设备上训练好的模型加载到 CPU 上时,或者当尝试将一个在 CUDA 设备上训练好的模型加载到不支持 CUDA 的设备上时,就会出现这个错误。

C/C++,图算法——Dinic最大流量算法
C/C++,图算法——Dinic最大流量算法
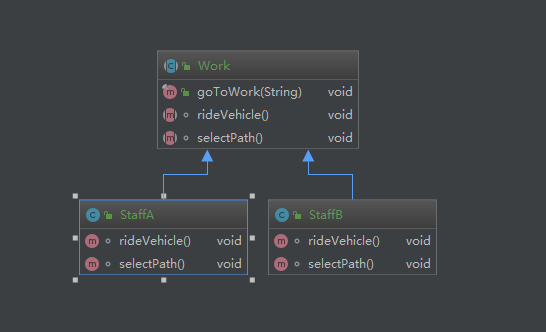
23种设计模式之模板方法模式(模板模式)
分别运行StaffA以及StaffB这两个类我们可以看到整个的步骤顺序是没有变的,只有交通工具以及路线发生了变化,个人认为代码已经诠释了模板模式的精髓,我们平时出现多个类似的功能功能点比如解析DOC文件或者XLSX等不同的文件,前期一些初始化的操作可以封装到模板方法中,到了具体解析哪一种类型的文件,再去交给子类实现。比如,在 Hibernate 中,Session 是一个抽象类,它定义了一系列的模板方法,如 save()、update() 和 delete(),用于执行数据库操作。②:出行交通工具的选择。