C/C++,动态 DP 问题的计算方法与源程序

1 文本格式
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int maxn = 500010;
const int INF = 0x3f3f3f3f;
int Begin[maxn], Next[maxn], To[maxn], e, n, m;
int size[maxn], son[maxn], top[maxn], fa[maxn], dis[maxn], p[maxn], id[maxn], End[maxn];
int cnt, tot, a[maxn], f[maxn][2];
struct matrix {
int g[2][2];
matrix() { memset(g, 0, sizeof(g)); }
matrix operator*(const matrix& b) const
{
matrix c;
for (int i = 0; i <= 1; i++)
for (int j = 0; j <= 1; j++)
for (int k = 0; k <= 1; k++)
c.g[i][j] = max(c.g[i][j], g[i][k] + b.g[k][j]);
return c;
}
} Tree[maxn], g[maxn];
inline void PushUp(int root) {
Tree[root] = Tree[root << 1] * Tree[root << 1 | 1];
}
inline void Build(int root, int l, int r) {
if (l == r) {
Tree[root] = g[id[l]];
return;
}
int Mid = l + r >> 1;
Build(root << 1, l, Mid);
Build(root << 1 | 1, Mid + 1, r);
PushUp(root);
}
inline matrix Query(int root, int l, int r, int L, int R) {
if (L <= l && r <= R) return Tree[root];
int Mid = l + r >> 1;
if (R <= Mid) return Query(root << 1, l, Mid, L, R);
if (Mid < L) return Query(root << 1 | 1, Mid + 1, r, L, R);
return Query(root << 1, l, Mid, L, R) *
Query(root << 1 | 1, Mid + 1, r, L, R);
}
inline void Modify(int root, int l, int r, int pos) {
if (l == r) {
Tree[root] = g[id[l]];
return;
}
int Mid = l + r >> 1;
if (pos <= Mid)
Modify(root << 1, l, Mid, pos);
else
Modify(root << 1 | 1, Mid + 1, r, pos);
PushUp(root);
}
inline void Update(int x, int val) {
g[x].g[1][0] += val - a[x];
a[x] = val;
while (x) {
matrix last = Query(1, 1, n, p[top[x]], End[top[x]]);
Modify(1, 1, n, p[x]);
matrix now = Query(1, 1, n, p[top[x]], End[top[x]]);
x = fa[top[x]];
g[x].g[0][0] +=
max(now.g[0][0], now.g[1][0]) - max(last.g[0][0], last.g[1][0]);
g[x].g[0][1] = g[x].g[0][0];
g[x].g[1][0] += now.g[0][0] - last.g[0][0];
}
}
inline void add(int u, int v) {
To[++e] = v;
Next[e] = Begin[u];
Begin[u] = e;
}
inline void DFS1(int u) {
size[u] = 1;
int Max = 0;
f[u][1] = a[u];
for (int i = Begin[u]; i; i = Next[i]) {
int v = To[i];
if (v == fa[u]) continue;
dis[v] = dis[u] + 1;
fa[v] = u;
DFS1(v);
size[u] += size[v];
if (size[v] > Max) {
Max = size[v];
son[u] = v;
}
f[u][1] += f[v][0];
f[u][0] += max(f[v][0], f[v][1]);
}
}
inline void DFS2(int u, int t) {
top[u] = t;
p[u] = ++cnt;
id[cnt] = u;
End[t] = cnt;
g[u].g[1][0] = a[u];
g[u].g[1][1] = -INF;
if (!son[u]) return;
DFS2(son[u], t);
for (int i = Begin[u]; i; i = Next[i]) {
int v = To[i];
if (v == fa[u] || v == son[u]) continue;
DFS2(v, v);
g[u].g[0][0] += max(f[v][0], f[v][1]);
g[u].g[1][0] += f[v][0];
}
g[u].g[0][1] = g[u].g[0][0];
}
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++) scanf("%d", &a[i]);
for (int i = 1; i <= n - 1; i++) {
int u, v;
scanf("%d%d", &u, &v);
add(u, v);
add(v, u);
}
dis[1] = 1;
DFS1(1);
DFS2(1, 1);
Build(1, 1, n);
for (int i = 1; i <= m; i++) {
int x, val;
scanf("%d%d", &x, &val);
Update(x, val);
matrix ans = Query(1, 1, n, 1, End[1]);
printf("%d\n", max(ans.g[0][0], ans.g[1][0]));
}
return 0;
}
2 代码格式
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int maxn = 500010;
const int INF = 0x3f3f3f3f;
int Begin[maxn], Next[maxn], To[maxn], e, n, m;
int size[maxn], son[maxn], top[maxn], fa[maxn], dis[maxn], p[maxn], id[maxn], End[maxn];
int cnt, tot, a[maxn], f[maxn][2];
struct matrix {
int g[2][2];
matrix() { memset(g, 0, sizeof(g)); }
matrix operator*(const matrix& b) const
{
matrix c;
for (int i = 0; i <= 1; i++)
for (int j = 0; j <= 1; j++)
for (int k = 0; k <= 1; k++)
c.g[i][j] = max(c.g[i][j], g[i][k] + b.g[k][j]);
return c;
}
} Tree[maxn], g[maxn];
inline void PushUp(int root) {
Tree[root] = Tree[root << 1] * Tree[root << 1 | 1];
}
inline void Build(int root, int l, int r) {
if (l == r) {
Tree[root] = g[id[l]];
return;
}
int Mid = l + r >> 1;
Build(root << 1, l, Mid);
Build(root << 1 | 1, Mid + 1, r);
PushUp(root);
}
inline matrix Query(int root, int l, int r, int L, int R) {
if (L <= l && r <= R) return Tree[root];
int Mid = l + r >> 1;
if (R <= Mid) return Query(root << 1, l, Mid, L, R);
if (Mid < L) return Query(root << 1 | 1, Mid + 1, r, L, R);
return Query(root << 1, l, Mid, L, R) *
Query(root << 1 | 1, Mid + 1, r, L, R);
}
inline void Modify(int root, int l, int r, int pos) {
if (l == r) {
Tree[root] = g[id[l]];
return;
}
int Mid = l + r >> 1;
if (pos <= Mid)
Modify(root << 1, l, Mid, pos);
else
Modify(root << 1 | 1, Mid + 1, r, pos);
PushUp(root);
}
inline void Update(int x, int val) {
g[x].g[1][0] += val - a[x];
a[x] = val;
while (x) {
matrix last = Query(1, 1, n, p[top[x]], End[top[x]]);
Modify(1, 1, n, p[x]);
matrix now = Query(1, 1, n, p[top[x]], End[top[x]]);
x = fa[top[x]];
g[x].g[0][0] +=
max(now.g[0][0], now.g[1][0]) - max(last.g[0][0], last.g[1][0]);
g[x].g[0][1] = g[x].g[0][0];
g[x].g[1][0] += now.g[0][0] - last.g[0][0];
}
}
inline void add(int u, int v) {
To[++e] = v;
Next[e] = Begin[u];
Begin[u] = e;
}
inline void DFS1(int u) {
size[u] = 1;
int Max = 0;
f[u][1] = a[u];
for (int i = Begin[u]; i; i = Next[i]) {
int v = To[i];
if (v == fa[u]) continue;
dis[v] = dis[u] + 1;
fa[v] = u;
DFS1(v);
size[u] += size[v];
if (size[v] > Max) {
Max = size[v];
son[u] = v;
}
f[u][1] += f[v][0];
f[u][0] += max(f[v][0], f[v][1]);
}
}
inline void DFS2(int u, int t) {
top[u] = t;
p[u] = ++cnt;
id[cnt] = u;
End[t] = cnt;
g[u].g[1][0] = a[u];
g[u].g[1][1] = -INF;
if (!son[u]) return;
DFS2(son[u], t);
for (int i = Begin[u]; i; i = Next[i]) {
int v = To[i];
if (v == fa[u] || v == son[u]) continue;
DFS2(v, v);
g[u].g[0][0] += max(f[v][0], f[v][1]);
g[u].g[1][0] += f[v][0];
}
g[u].g[0][1] = g[u].g[0][0];
}
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++) scanf("%d", &a[i]);
for (int i = 1; i <= n - 1; i++) {
int u, v;
scanf("%d%d", &u, &v);
add(u, v);
add(v, u);
}
dis[1] = 1;
DFS1(1);
DFS2(1, 1);
Build(1, 1, n);
for (int i = 1; i <= m; i++) {
int x, val;
scanf("%d%d", &x, &val);
Update(x, val);
matrix ans = Query(1, 1, n, 1, End[1]);
printf("%d\n", max(ans.g[0][0], ans.g[1][0]));
}
return 0;
}相关文章:

软路由R4S+iStoreOS如何实现公网远程桌面本地电脑
本文主要讲解如何使用软路由R4S和iStoreOS实现公网远程桌面本地电脑

将labelme标注的人体姿态Json文件转成训练Yolov8-Pose的txt格式
最近在训练Yolov8-Pose时遇到一个问题,就是如何将自己使用labelme标注的Json文件转化成可用于Yolov8-Pose训练的txt文件。

【redis】Redis中AOF的重写机制
为了避免子进程在重写过程过程中,主进程中的数据发生变化,导致AOF文件里面的数据和redis内存中的数据不一致,redis中还做了一个优化,也就是说在子进程在做这个重写的过程中,主进程中的数据变更,需要追加到AOF的重写缓冲区中,等到AOF重写完成以后,再把AOF重写缓冲区的数据,追加到新的AOF文件里面,这样意料就能保证新的AOF文件里面的数据和当前Redis中的数据保持一致。子进程在进行重写的过程中,主进程依然可以去处理客户端的一个请求,这样一来子进程在重写的过程中,不耽误客户端的使用。

【redis】为什么Redis集群的最大槽数是16384个?
对网络同学开销的平衡:redis集群中的每个节点,会发送心跳消息,而心跳包中会携带节点的完整配置,他能够以幂等的方式来实现配置的更新。但是修改集群的槽位数量需要进行数据迁移和重新均衡,会对集群产生较大的影响,因此一般情况下建议使用默认的 16384 个槽位。可用性和容错性:16384 是一个较大的数字,可以提供足够的槽位数量来分布数据,从而提高集群的可用性和容错性。应用程序去存储一个key的时候会通过,对key进行一个CRC16去计算,再取模,然后路由到hash slot所在的节点。
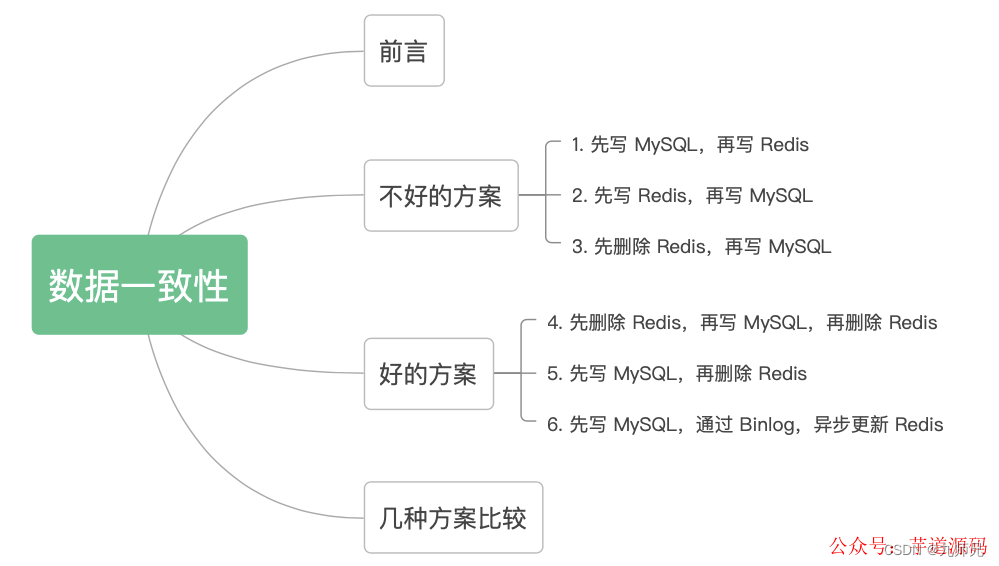
【redis】技术派中的缓存一致性解决方案
对于上面这种情况,对于第一次查询,请求 B 查询的数据是 10,但是 MySQL 的数据是 11,只存在这一次不一致的情况,对于不是强一致性要求的业务,可以容忍。这个图已经画的很清晰了,我就不用再去啰嗦了吧,不过这里有个前提,就是对于读请求,先去读 Redis,如果没有,再去读 DB,但是读请求不会再回写 Redis。请求 A、B 都是先写 MySQL,然后再写 Redis,在高并发情况下,如果请求 A 在写 Redis 时卡了一会,请求 B 已经依次完成数据的更新,就会出现图中的问题。

讲解cv2.setNumThreads
本文讲解了 cv2.setNumThreads 函数的作用和用法。通过设置并行处理的线程数目,我们可以控制 OpenCV 在图像和视频处理中使用的线程数量,从而提高程序的性能和效率。了解和正确使用 cv2.setNumThreads 函数对于优化计算机视觉应用程序的性能非常重要。希望本文能对读者理解并正确使用 cv2.setNumThreads 函数提供帮助。

讲解undefined reference to symbol ‘_ZN2cv7imwriteERKNS_6StringERKNS_11_InputArrayERKSt6vectorIiSaIiEE‘
在本文中,我们讨论了一个常见的错误信息,并解释了它的含义以及可能的解决方法。请记住,在遇到这种错误时,你应该首先确认是否正确链接库文件,包含正确的头文件,正确配置环境以及检查版本兼容性。通过采取适当的措施,你应该能够解决这个错误并顺利编译和链接你的程序。当遇到这个错误时,通常是因为在编译和链接时没有正确地指定OpenCV库文件。下面是一个示例代码,展示了如何使用OpenCV的imwrite函数来保存图像。首先,你需要确保你的系统已经安装了OpenCV,并正确配置了环境。// 读取图像if (!

讲解Expected more than 1 value per channel when training, got input size torch.Size
在训练深度学习模型时,遇到错误消息"Expected more than 1 value per channel when training, got input size torch.Size"时,我们需要检查数据预处理的过程,确保输入数据的形状满足模型的要求。通过检查数据形状、数据预处理代码和模型的输入层,我们可以找出错误的原因并进行修复。这样,我们就可以成功训练模型并获得预期的结果。
讲解RuntimeError: cudnn64_7.dll not found.
"RuntimeError: cudnn64_7.dll not found" 错误是在使用GPU加速深度学习过程中的常见错误之一。本文介绍了解决这个错误的几种常见方法,包括检查CUDA和cuDNN的安装、确认环境变量配置、检查软件依赖关系以及重新安装CUDA和cuDNN。通过按照以上步骤逐一排查和解决,您应该能够成功地解决这个错误,并顺利进行GPU加速的深度学习任务。祝您顺利完成深度学习项目!
讲解Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False
"Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False" 错误提示表明您的代码尝试将一个在 CUDA 设备上训练好的模型加载到不支持 CUDA 的设备上,或者是将其加载到 CPU 上。在 PyTorch 中,当您试图将一个已经在 CUDA 设备上训练好的模型加载到 CPU 上时,或者当尝试将一个在 CUDA 设备上训练好的模型加载到不支持 CUDA 的设备上时,就会出现这个错误。

C/C++,图算法——Dinic最大流量算法
C/C++,图算法——Dinic最大流量算法
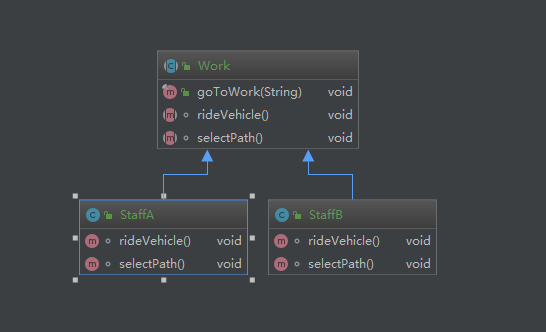
23种设计模式之模板方法模式(模板模式)
分别运行StaffA以及StaffB这两个类我们可以看到整个的步骤顺序是没有变的,只有交通工具以及路线发生了变化,个人认为代码已经诠释了模板模式的精髓,我们平时出现多个类似的功能功能点比如解析DOC文件或者XLSX等不同的文件,前期一些初始化的操作可以封装到模板方法中,到了具体解析哪一种类型的文件,再去交给子类实现。比如,在 Hibernate 中,Session 是一个抽象类,它定义了一系列的模板方法,如 save()、update() 和 delete(),用于执行数据库操作。②:出行交通工具的选择。
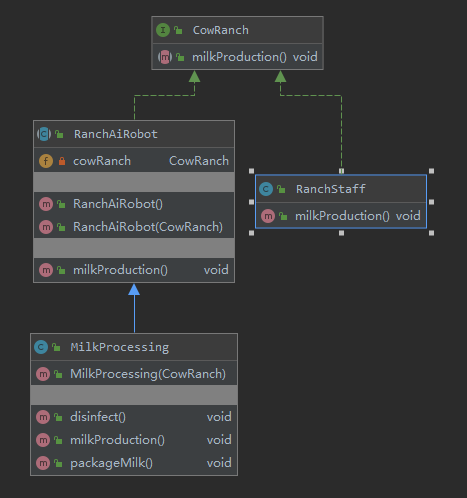
23种设计模式之装饰者模式(被装饰者,接口层,装饰抽象层,具体装饰者)
装饰者模式 其核心就是为了增强方法,对原业务的扩展,以上面的场景来说,牧场工作人员只做牛奶的生产,但是想要对牛奶进行销售,只生产是不够的,生产前后都需要增加其他的行为。装饰抽象层存在的意义抽象类实现接口,可以选择性的去实现接口的抽象方法,并不需要重写接口所有方法,装饰抽象层可以精确的让具体装饰者去装饰某一个行为。异变代理模式。

Java 线程的基本概念
当 Context Switch 发生时,需要由操作系统保存当前线程的状态,并恢复另一个线程的状态,Java 中对应的概念就是程序计数器(Program Counter Register),它的作用是记住下一条 jvm 指令的执行地址,是线程私有的。有一种特殊的线程叫做守护线程,只要其它非守护线程运行结束了,即使守护线程的代码没有执行完,也会强制结束.程序在 t1 线程运行,FileReader.read() 方法调用是异步的。打断 sleep 的线程, 会清空打断状态,以 sleep 为例。

【Redis】Redis的事务碰上Spring的事务 @Transactional导致问题
建议大家去看原文,这里是学到了,记录一下。最近项目的生产环境遇到一个奇怪的问题:现象 :每天早上客服人员在后台创建客服事件时,都会创建失败。当我们重启 这个微服务后,后台就可以正常创建了客服事件了。到第二天早上又会创建失败,又得重启这个微服务才行。初步排查 :创建一个客服事件时,会用到 Redis 的递增操作来生成一个唯一的分布式 ID 作为事件 id。而恰巧每天早上这个递增操作都会返回 null,进而导致后面的一系列逻辑出错,保存客服事件失败。当重启微服务后,这个递增操作又正常了。

【redis】bitmap技术解析:redis与roaringBitmap
然后再看这个好理解一些。bitmap的表象意义是,使用一个01标识位来表示是否的状态,可以达到节省空间和高效判定的效果。在我们的实际工作中,也有着许多的应用场景,相信了解bitmap定会给你带来一些额外的收获。

【Linux系统化学习】进程的父子关系 | fork 进程
本篇文章介绍了进程的父子关系和使用fork函数创建一个进程!

【Linux系统化学习】探索进程的奥秘 | 第一个系统调用
本片文章主要介绍了Linux下的进程和第一个系统调用。

【C++干货铺】解密vector底层逻辑
本片文章主要是vector的介绍使用和手撕模拟实现!!!!

【C++干货铺】剖析string | 底层实现
探索string底层,模拟实现string。

【Linux系统化学习】冯诺依曼体系结构 | 操作系统
本篇文章介绍了冯诺依曼体系结构,描述了操作系统。

【C++干货铺】STL简述 | string类的使用指南
STL简述!!! string类接口使用指南!!!

【C++干货铺】初识模板
初识C++模板!!!函数模板&类模板!!!超详解!!!

【C++干货铺】内存管理new和delete
C&C++内存管理!!!malloc/realloc/calloc/free!!!new/delete!!!

人工智能时代:AIGC的横空出世
AIGC是一种新的人工智能技术,即人工智能生成内容。它是一种基于机器学习和自然语言处理的技术,能够自动产生文本、图像、音频等多种类型的内容。

零基础搭建本地Nextcloud私有云结合内网穿透实现远程访问
本文主要讲解如何搭建本地Nextcloud私有云结合内网穿透实现远程访问

如何在外远程访问本地NAS威联通QNAP?
本文主要讲解在外远程访问本地NAS威联通QNAP。

使用Linux JumpServer堡垒机本地部署与远程访问
本文主要讲解如何使用Linux JumpServer堡垒机本地部署与远程访问。
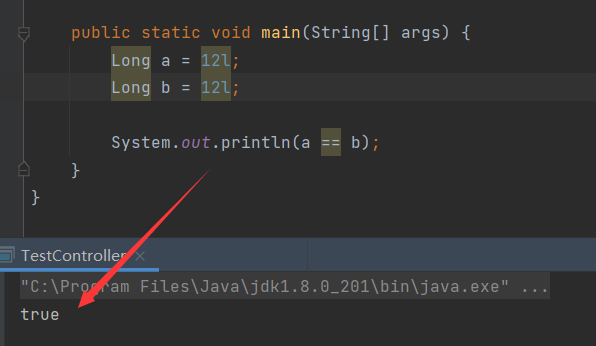
Java中判断两个Long类型是否相等
也就是说这个值在-128到127之间会使用缓存,超过就会创建一个对象,所以上述的两个值分别创建了两个对象,那么使用。可以使用 .longValue() 或 .equals() 进行比较。推荐使用equals方法进行比较。现象1和现象2结果不一样,现象2使用==判断两个Long类型的值,结果竟然是false!
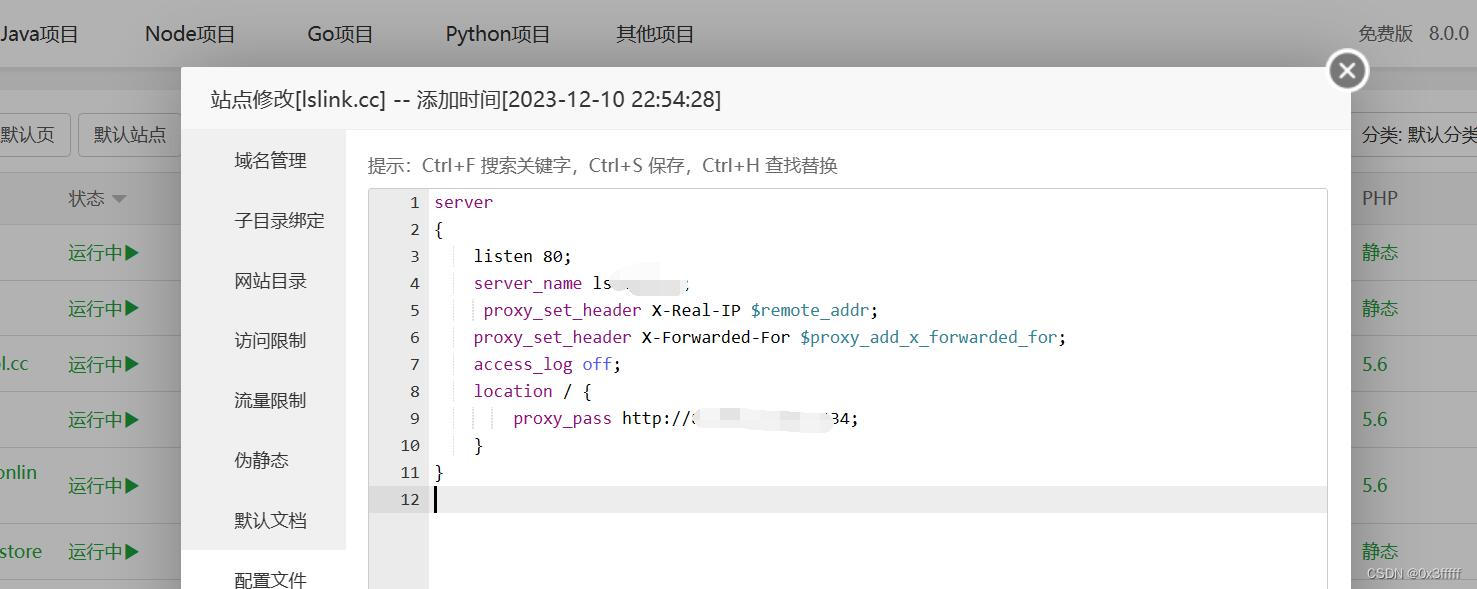
Nginx反向代理跳过国内备案(以宝塔面板为例)
Nginx代理跳过大陆备案验证,需要两台服务器,一台已备案或者免备案,一台国内主力服务器放你的项目。B服务器在配置文件里设置listen监听端口号。先把域名解析到A服务器。然后在A服务器里配置。