【Linux系统化学习】进程的父子关系 | fork 进程
=========================================================================
个人主页点击直达:小白不是程序媛
Linux专栏:Linux系统化学习
=========================================================================
目录
前言:
上篇文章我们谈到了进程,运行在内存的程序、被执行的指令都可以是一个进程;并且对Linux的进程有一定的认识,知道如何使用指令查看进程和第一个系统调用。进程还有很多的奥秘需要我们探索,让我们开始今天的学习吧!
父子进程
父子进程的引入
还是上篇文章的代码和指令,每个进程都PID,在属性列表前面的PPID为父进程的ID。

我们对自己写的可执行程序进行多次的运行和终止,会发现每次的进程ID都会变,而父进程ID始终不变。
 经过查询我们可以知道这个父进程就是我们的命令行解释器(bash)。
经过查询我们可以知道这个父进程就是我们的命令行解释器(bash)。

总结:
- 启动进程本质就是创建进程,一般是通过父进程创建的(父子关系)
- 我们命令行启动的进程都是bash的子进程
查看父子进程
新的进程创建时操作系统会给每个进程创建一个task_struct(PCB),里面存放着关于这个进程的各种信息、属性等;其中就包括PID和PPID是操作系统内部的数据,操作系统那片文章我们提到用户是无法拿到操作系统内部的数据的要通过系统调用才可以,Linux也给我们提供了相应的函数接口供我们使用。
- 获取子进程ID:getpid()
- 获取父进程ID:getppid()
通过man指令可以查询到这两个函数的使用方法。

1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4
5 {
6 printf("我是一个进程,我的PID为:%d;我的PPID为:%d\n",getpid(),getppid());
7 return 0;
8 }
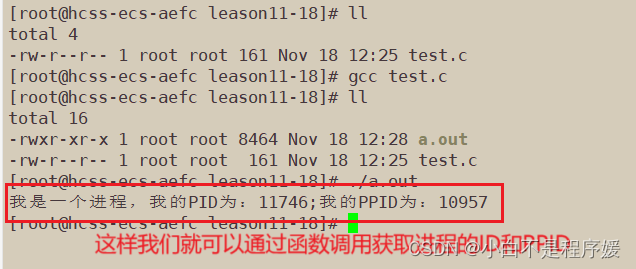
通过编写代码,函数调用获取我们的ID和PPID。
查询进程的动态目录
Linux操作系统下有一个有一个动态的目录结构,存放着所有进程;可以通过每个进程的PID查询到这个目录
- 指令: proc/PID
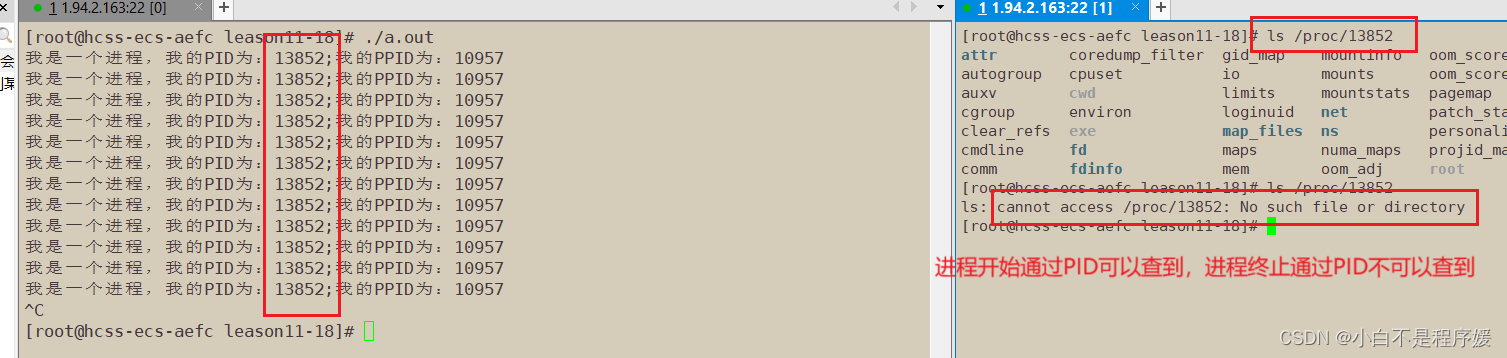
我们将整个进程的完整目录调出来
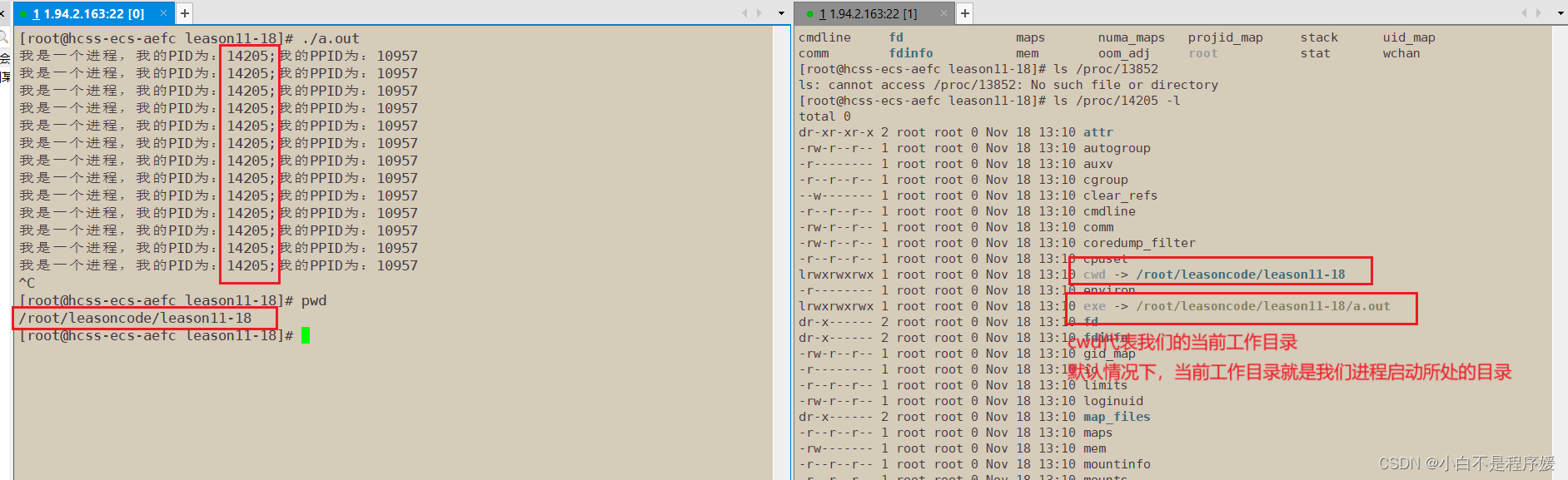
更改进程的工作目录
我们可以使用chdir()修改当前工作目录
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4
5 {
6 chdir("/root");
7 while(1)
8 {
9 printf("我是一个进程,我的PID为:%d;我的PPID为:%d\n",getpid(),getppid());
10 sleep(1);
11 }
12 return 0;
13 }
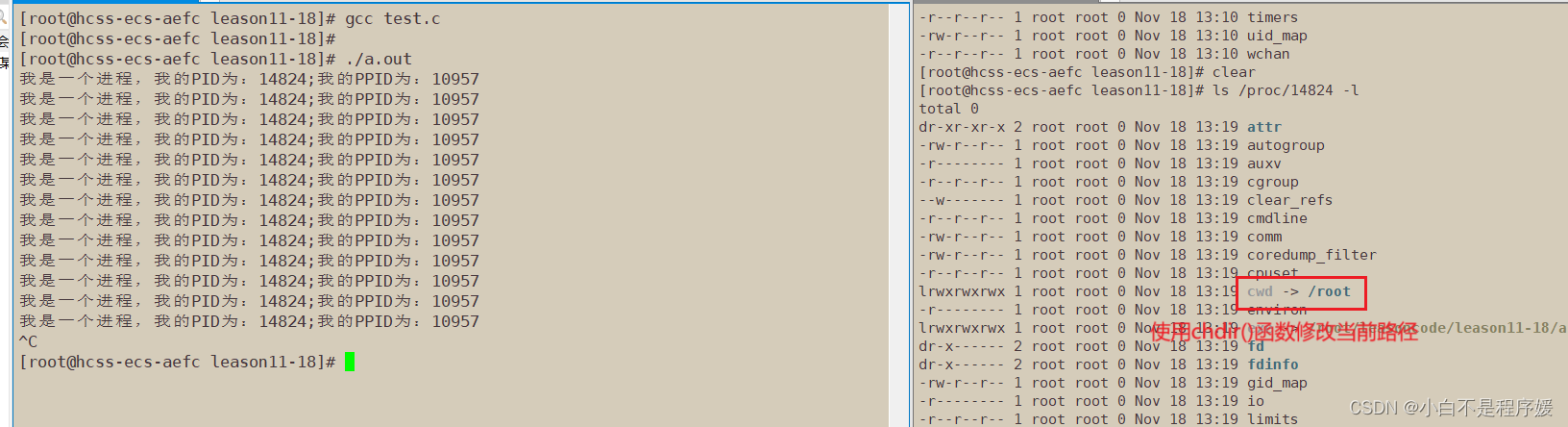
fork创建进程
fork的引入
在Linux操作系统下有两种创建进程的方式
- 命令行中直接启动进程(手动启动)
- 通过代码来创建进程(fork)
我们一直在使用第一种方式创建进程,下面将通过演示fork来创建进程。
fork的使用
man fork 查看fork如何使用

1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4
5 {
6 printf("我是一个进程,我的PID为:%d;我的PPID为:%d\n",getpid(),getppid());
7 fork();
8
9 printf("我是一个进程,我的PID为:%d;我的PPID为:%d\n",getpid(),getppid());
10 sleep(1);
11 return 0;
12 }

运行我们编译好的程序我们发现同一条输出语句运行了两次。这是因为在fork之前只有一个进程,fork创建了一个进程,所以才会执行两次。
fork的原理
fork如何实现的?
fork是一个函数,函数可以设置返回值;当fork子进程成功时给父进程返回子进程的PID,给子进程返回0;fork子进程失败时返回-1;子进程创建成功后会将fork下面的代码拷贝一份,相当有两个进程执行同一份代码,因此会输出两条语句。
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4
5 {
6 pid_t id =fork();
7 if(id<0)
8 {
9 return 0;
10 }
11 else if ( id == 0 )
12 {
13 while(1)
14 {
15 printf("我是子进程,我的Pid为:%d,我的PPid为:%d\n",getpid(),getppid());
16 }
17 sleep(1);
18 }
19 else
20 {
21
22 while(1)
23 {
24 printf("我是父进程,我的Pid为:%d,我的PPid为:%d\n",getpid(),getppid());
25 }
26 sleep(1);
27 }
28 return 0;
29 }

为什么fork之前的代码不执行?
在学习C语言的时候我们知道,代码执行的时候会有一个指针执行一条语句,指针就会随着变化;执行到fork时候,指针也变化到fork语句;因此只能将fork之后的语句拷贝给另一个进程。
为什么要有两个返回值?
这和我们用户使用计算机的场景有关,就像我现在在同一个浏览器里一边在CSDN写着博客,一边还在查找相关的资料。浏览器这一个进程含有两个进程,两个进程做着不同的事情,甚至更多。但是当前我们只能让做相同的事情,执行同一份代码。在以后的学习中我们会通过返回值让他们执行不同的代码片段。
今天对Linux下父子进程和fork进程的介绍分享到这就结束了,希望大家读完后有很大的收获,也可以在评论区点评文章中的内容和分享自己的看法。您三连的支持就是我前进的动力,感谢大家的支持!!!
相关文章:

Yolov11-detect训练自己的数据集
至此,整个YOLOv11的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。

【Linux之升华篇】Linux内核锁、用户模式与内核模式、用户进程通讯方式
alloc_pages(gfp_mask, order),_ _get_free_pages(gfp_mask, order)等。字符设备描述符 struct cdev,cdev_alloc()用于动态的分配 cdev 描述符,cdev_add()用于注。外,还支持语义符合 Posix.1 标准的信号函数 sigaction(实际上,该函数是基于 BSD 的,BSD。从最初的原子操作,到后来的信号量,从。(2)命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的。
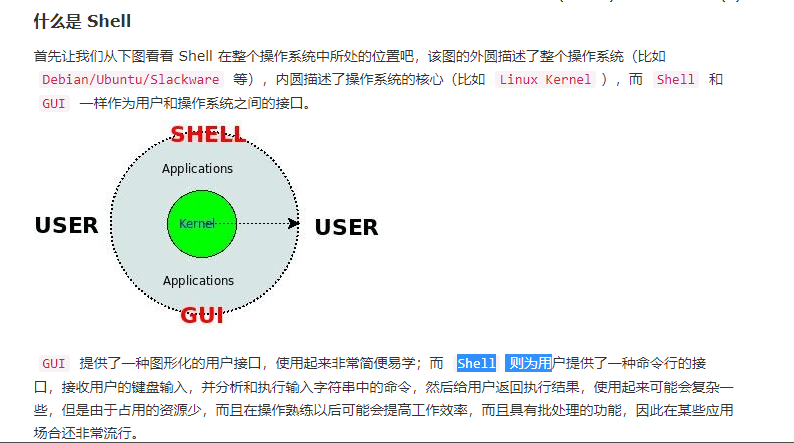
shell编程
简单来说“Shell 编程就是对一堆 Linux 命令的逻辑化处理”。

HackQuest介绍 web3 学习平台
官网地址: https://www.hackquest.io/zhHackQuest是一个专注于Web3技术教育的在线学习平台,旨在帮助全球开发者掌握区块链、加密货币和去中心化应用(DApps)领域的最新技能。该平台汇聚了超过14000名活跃开发者,与100多个领先的Web3生态系统和项目紧密合作,为用户提供全面的教育资源。

Ubuntu下安装和配置Redis
找到 /ect/redis/redis.conf 文件修改如下:注释掉 127.0.0.1 ,如果不需要远程连接redis则不需要这个操作。使用客户端向 Redis 服务器发送一个 PING ,如果服务器运作正常的话,会返回一个 PONG。默认情况下,Redis服务器不允许远程访问,只允许本机访问,所以我们需要设置打开远程访问的功能。执行sudo apt-get install redis-server 安装命令。查看 redis 是否启动,重新打开一个窗口。停止/启动/重启redis。

YOLOv10训练自己的数据集
至此,整个YOLOv10的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。
YOLOv10环境搭建、模型预测和ONNX推理
运行后会在文件yolov10s.pt存放路径下生成一个的yolov10s.onnxONNX模型文件。安装完成之后,我们简单执行下推理命令测试下效果,默认读取。终端,进入base环境,创建新环境。(1)onnx模型转换。

linux常用操作指令—— 查看磁盘、内存使用情况(df、du、free、top)
显示指定磁盘文件的可用空间。如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。默认情况下,磁盘空间将以 1KB为单位进行显示,除非环境变量 POSIXLY_CORRECT 被指定,那样将以512字节为单位进行显示。free指令会显示内存的使用情况,包括实体内存,虚拟的交换文件内存,共享内存区段,以及系统核心使用的缓冲区等。当文件系统也确定删除了该文件后,这时候du与df就一致了。实例4:显示目前磁盘空间和使用情况 (最常用)top:“实时查看” ,按。退出 (实时动态显示)
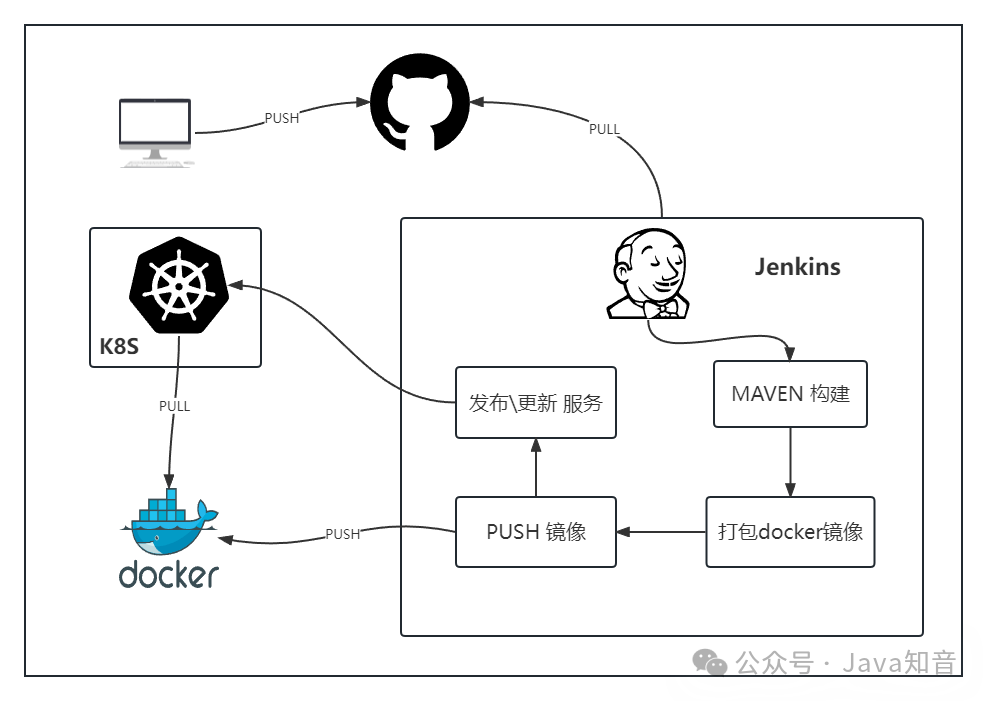
一键部署 SpringCloud 微服务,这套流程值得学习一波儿!
一键部署 springcloud 微服务,需要用到 Jenkins K8S Docker等工具。本文使用jenkins部署,流程如下图开发者将代码push到git运维人员通过jenkins部署,自动到git上pull代码通过maven构建代码将maven构建后的jar打包成docker镜像 并 push docker镜像到docker registry通过k8s发起 发布/更新 服务 操作其中 2~5步骤都会在jenkins中进行操作。
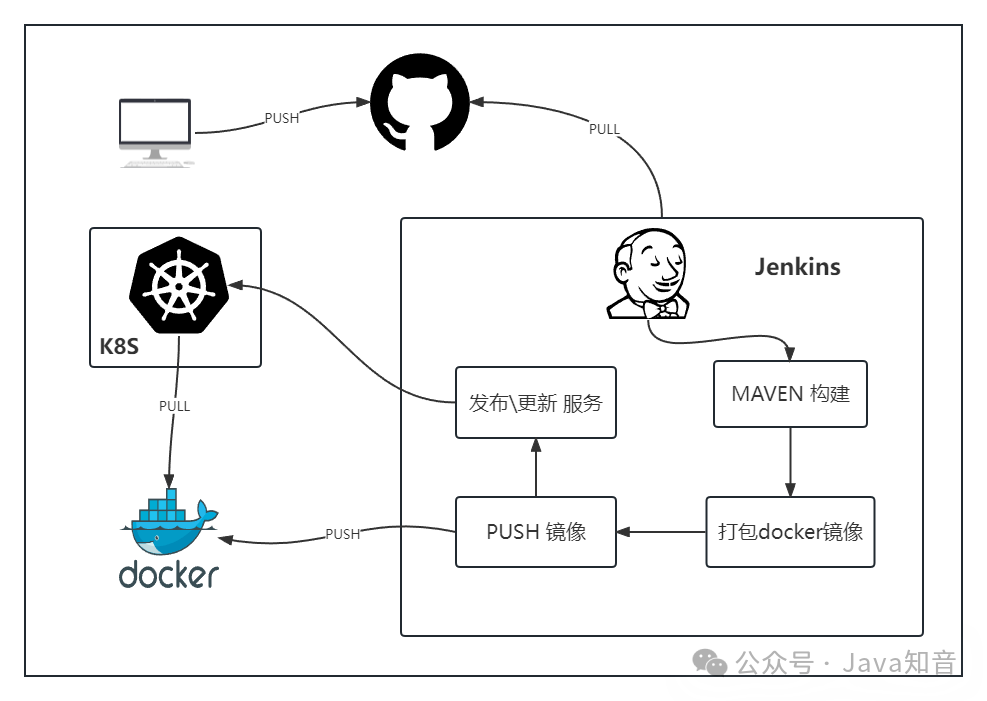
一键部署 SpringCloud 微服务,这套流程值得学习一波儿!
一键部署 springcloud 微服务,需要用到 Jenkins K8S Docker等工具。本文使用jenkins部署,流程如下图开发者将代码push到git运维人员通过jenkins部署,自动到git上pull代码通过maven构建代码将maven构建后的jar打包成docker镜像 并 push docker镜像到docker registry通过k8s发起 发布/更新 服务 操作其中 2~5步骤都会在jenkins中进行操作。
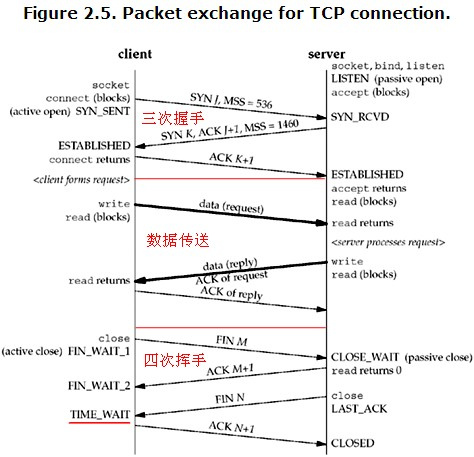
Linux下netstat命令详解&&netstat -anp | grep 讲解
Netstat是控制台命令,是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
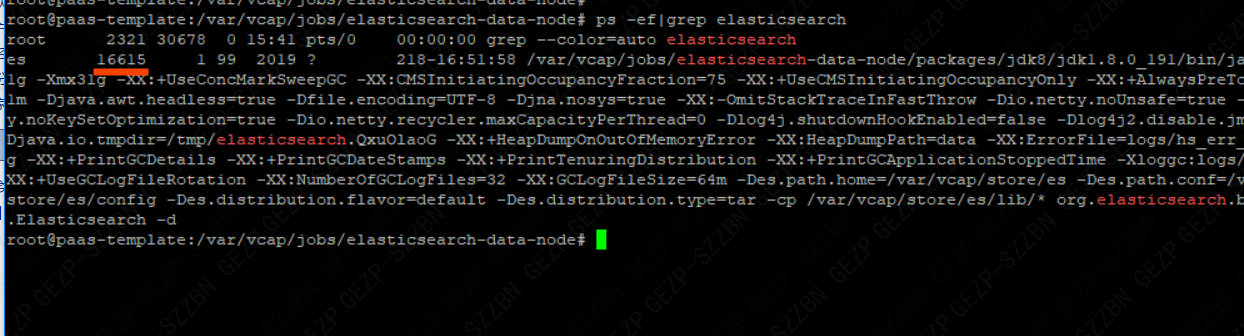
Linux命令——根据端口号查进程
查出的数据第二列(16615)是elasticsearch的进程号。通常我们会根据端口号查进程号,或者通过进程号查端口号。linux环境下,我们常常会查询进程号pid。最常用ps -ef |grep xx。根据端口port查进程。根据端口port查进程。根据进程pid查端口。根据进程pid查端口。

YOLOv7-Pose 姿态估计-环境搭建和推理
终端,进入base环境,创建新环境,我这里创建的是p38t17(python3.8,pytorch1.7)安装pytorch:(网络环境比较差时,耗时会比较长)下载好后打开yolov7-pose源码包。imgpath:需要预测的图片的存放路径。modelpath:模型的存放路径。Yolov7-pose权重下载。打开工程后,进入设置。
第三方消息推送回调Java app消息推送第三方选择
由于最先集成的是极光,因此根据官方给的推送设备区分方式中,选择了使用标签tag来进行区分管理方式,其接口提供了设置和清理标签, 每次设置会覆盖上次的结果,当然这个需要和极光后台进行交互,是异步返回的。5、由于其接口没有使用免费和付费区分,对于接口的访问没有限制,从使用的情况来看,经常会出现不准的情况,并且设置标签的效果其实是添加,导致业务需要改变标签时,需要先清除在设置,然而接口又经常出问题,导致这部分也是一塌糊涂了;如果想使用不受免费版本限制特性的推送服务,可以联系平台提供的商务对接,购买付费版本。
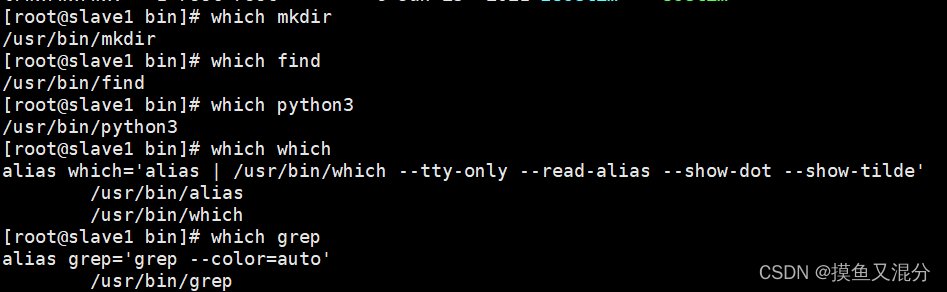
Linux搜索文件&搜索文件名&替换文件内容
locate是Linux系统提供的一种快速检索全局文件的系统命令,它并不是真的去检索所以系统目录,而是检索一个数据库文件locatedb(Ubuntu系置/var/cache/locate/locatedb),该数据库文件包含了系统所有文件的路径索引信息,所以查找速度很快。time结尾的选项,其单位为天,min结尾的选项其单位为分钟,这些选项的值都为一个正负整数, 如+7,表示,7天以前被访问过的文件,-7表示7天以内被访问过的文件,7表示恰好7天前被访问的文件。:快速返回某个指定命令的位置信息。
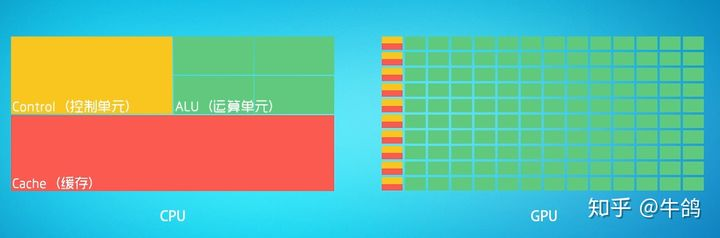
深度学习硬件基础:CPU与GPU
CPU:叫做中央处理器(central processing unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。[^3]可以形象的理解为有25%的ALU(运算单元)、有25%的Control(控制单元)、50%的Cache(缓存单元)GPU:叫做图形处理器。
[Ubuntu 22.04] Docker安装及使用
容器的生命周期由用户控制,用户可以选择手动删除容器或让其保留在系统中以供之后使用。选项允许你在容器内部创建一个交互式的终端会话,使你可以像在本地终端一样与容器进行交互。你可以在容器内执行命令,查看输出并输入命令。镜像拉取完成后,可以使用以下命令创建并启动一个基于 Ubuntu 20.04 镜像的容器。列出所有正在运行的容器,并显示它们的容器ID、镜像、命令、创建时间、状态等信息。以下命令可以中止容器,改命令将向容器发送一个停止信号,使其正常停止并退出。这将显示所有容器的列表,包括正在运行的和已停止的容器。

YOLOv8-Detect训练CoCo数据集+自己的数据集
至此,整个训练预测阶段完成。此过程同样可以在linux系统上进行,在数据准备过程中需要仔细,保证最后得到的数据准确,最好是用显卡进行训练。有问题评论区见!

CSS局限属性contain:优化渲染性能的利器
在网页开发中,优化渲染性能是一个重要的目标。CSS局限属性contain是一个强大的工具,可以帮助我们提高网页的渲染性能。本文将介绍contain属性的基本概念、用法和优势,以及如何使用它来优化网页的渲染过程。
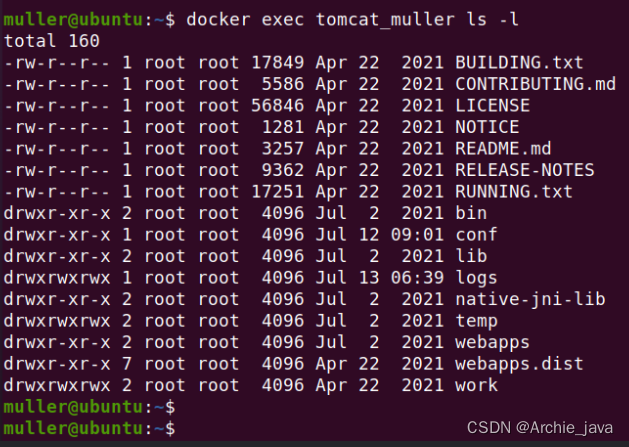
Docker exec命令详细使用指南
Docker exec命令是Docker提供的一个强大工具,用于在正在运行的容器中执行命令。本文将详细介绍Docker exec命令的用法和示例,帮助大家更好地理解和使用这个命令。Docker是一种流行的容器化平台,允许我们在容器中运行应用程序。有时候,在容器内执行命令可以帮助我们调试、排查问题或进行其他操作。这就是Docker exec命令发挥作用的时候。本文详细介绍了Docker exec命令的用法和示例。
10个常用python自动化脚本
大家好,Python凭借其简单和通用性,能够为解决每天重复同样的工作提供最佳方案。本文将探索10个Python脚本,这些脚本可以帮助自动化完成任务,提高工作效率。无论是开发者、数据分析师还是仅仅想简化工作流程的普通用户,这些脚本都能提供帮助。
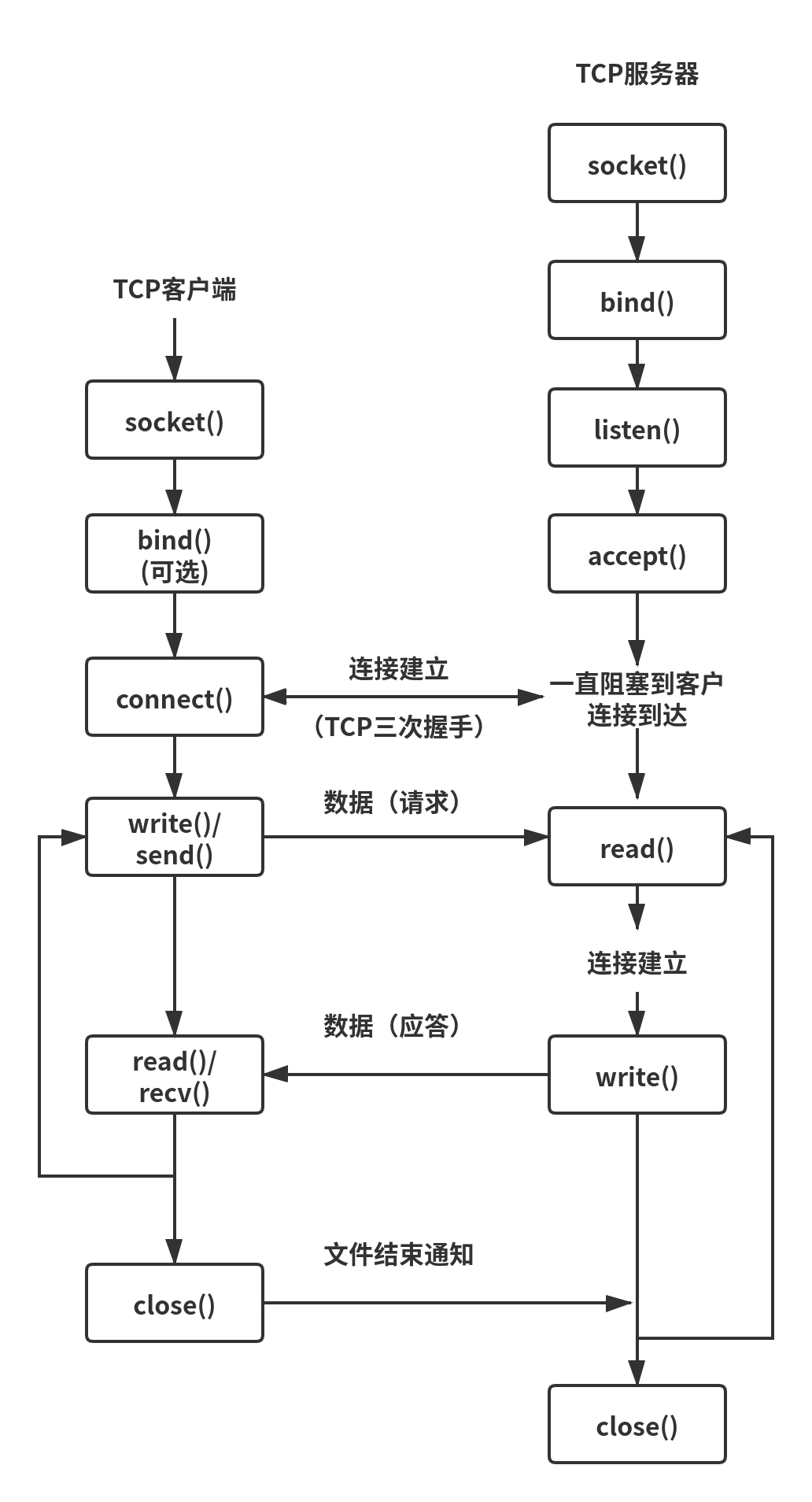
TCP服务器最多支持多少客户端连接
本文从理论和实际两个方面介绍了一个 TCP 服务器支持的最大连接数
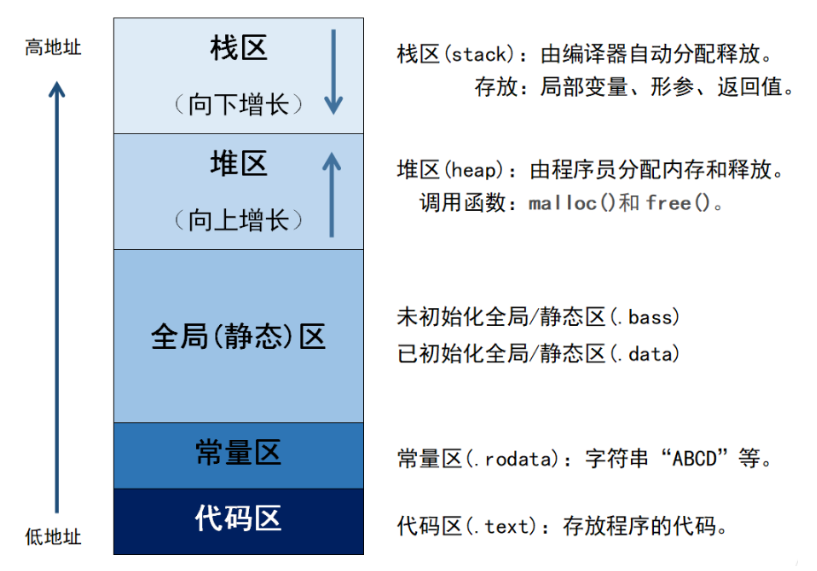
C程序的内存空间布局(栈、堆、数据区、常量区、代码区)
较详细的介绍了栈、堆、数据区、常量区、代码区
给服务器开通telnet的流程
但一些特殊场景下,比如要升级ssh,ssh不能用时,需要使用telnet,用过要关闭此服务。需要首先安装,如果telnet-server服务在xinetd之前安装了,要先删除telnet-server,再安装xinetd。安装顺序:xinetd--》telnet--》telnet-server。安装顺序:xinetd--》telnet--》telnet-server。2、卸载rpm包(如果已经安装了,又不清楚顺序,可以都卸载后统一安装)注意:telnet-server服务启动依赖xinetd服务,
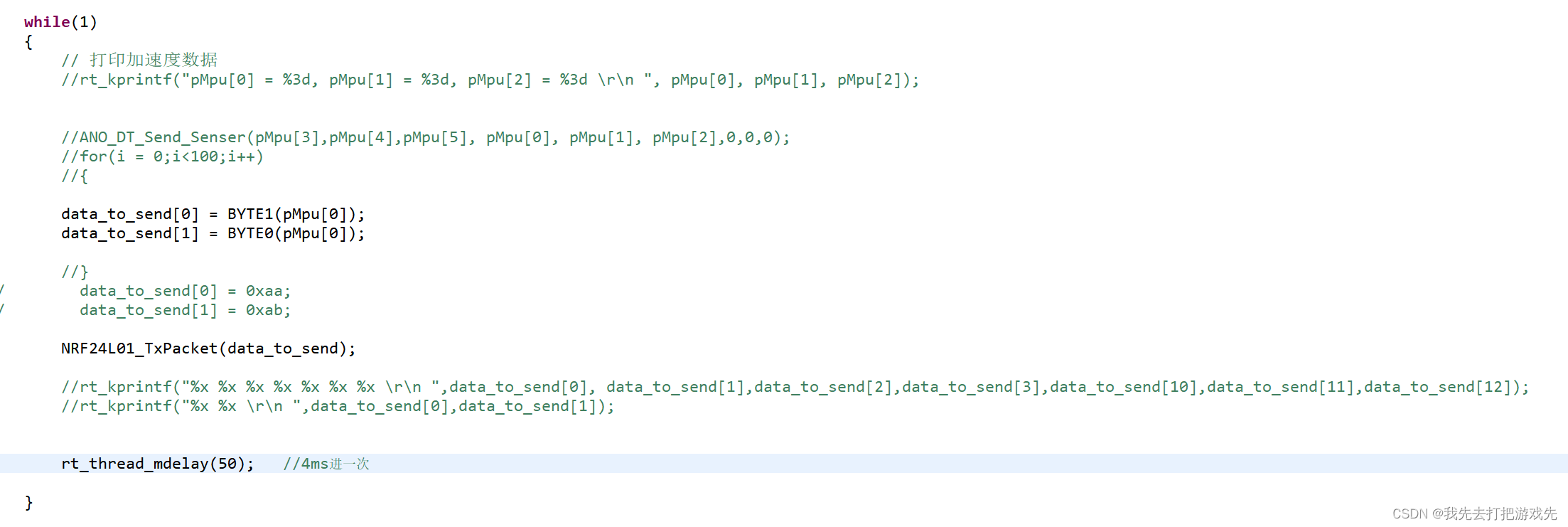
NRF24L01模块传输MPU6050数据,接收端数据一直为0问题记录
问题描述:一、发射端1、正确配置NRF模块,以及测试过能够正常通信,在发射端的发射线程中进行了如下操作2、这里是获取了陀螺仪的x轴数据,将其而分为两个8位的数据存入发送缓冲区中。因为一个陀螺仪x轴数据是16位的,所以对其进行了拆分,这里只获取gyro的x轴数据进行发送,目的是进行测试。3、这个是发送函数,只要把发送缓冲区的地址作为参数传入就可以发送了。二、接收端1、接收端的NRF24L01模块也正确配置后,在接收线程中进行如下操作2、读取NRF传输过来的数据,存到接收BUF中,然后打印
YOLOv5中Ghostbottleneck结构shortcut=True和shortcut=False有什么区别
GhostBotleneck结构中的shodcut=True和shorcut=False的区别在干是否使用残差连接。当shorcu=True时,使用残差连接,可以以加速模型的收敛速度和提高模型的准确率,当shorcu=False时,不使用残差连接,可以减少模型的参数数量和计算量。实际上不只是Ghostbottleneck具有残差连接,在C3、C2f等具有Bottleneck模块的结构均可根据此例举一反三。残差块是深度卷积神经网络中的一种基本模块,可以有效地解决梯度消失和梯度爆炸的问题。
如何在Nginx中配置防盗链?
防盗链是一种防止网站资源被非法下载的技术。当用户尝试直接访问一个受保护的资源时,服务器会返回一个403 Forbidden错误,提示用户该资源受到保护,不能直接访问。这样可以避免用户通过搜索引擎或其他方式获取到未经授权的资源。通过以上步骤,我们可以在Linux系统中的Nginx Web服务器中使用Shell脚本实现防盗链的配置。这种方法可以有效地保护网站资源不被非法下载,提高用户体验,同时防止恶意攻击。在实际项目中,我们可以根据实际需求灵活配置受保护资源的URL和处理方式。
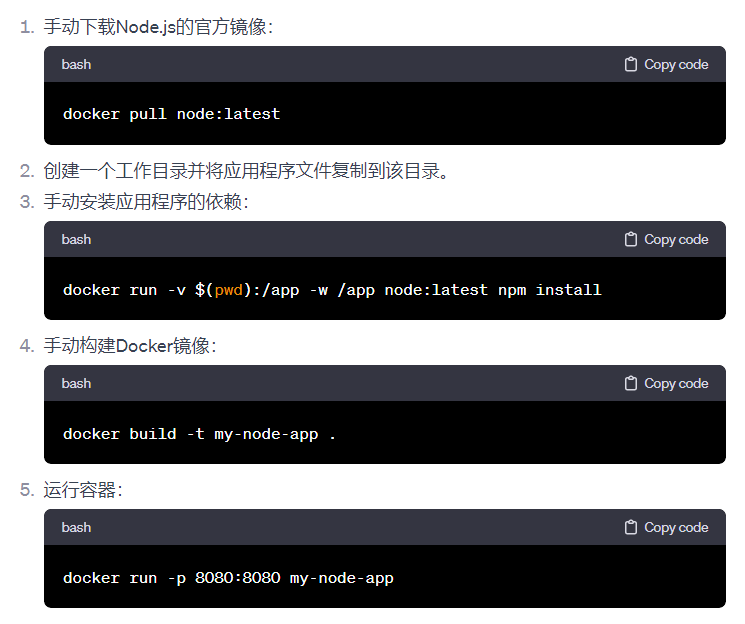
使用DockerFile构建镜像与镜像上传
首先Dockerfile 是一个文本格式的配置文件, 用户可以使用 Dockerfile 来快速创建自定义的镜像。

python基础小知识:引用和赋值的区别
通过引用,就可以在程序范围内任何地方传递大型对象而不必在途中进行开销巨大的赋值操作。不过需要注意的是,这种赋值仅能做到顶层赋值,如果出现嵌套的情况下仍不能进行深层赋值。赋值与引用不同,复制后会产生一个新的对象,原对象修改后不会影响到新的对象。如果在原位置修改这个可变对象时,可能会影响程序其他位置对这个对象的引用

k8s 使用tomcat官方镜像部署集群并解决访问页面404
官方镜像这里有个坑,使用kubectl启动之后,页面报错404,仔细检查发现,是因为tomcat的webapp目录下没有对应的文件,所以连初始界面都无法显示。要想显示,必须要根据官方镜像自己构建一个Dockerfile。根据上面的信息可以看出,该POD部署在k8s-node1上,映射POD的8080端口到master的30088端口上。这里需要将镜像上传到自己搭建的registry,并配置nodes节点都可以正常访问5000端口。三、根据官方镜像自己构建一个一次性就能启动的Tomcat镜像。