YOLOv5中Ghostbottleneck结构shortcut=True和shortcut=False有什么区别
GhostBotleneck结构中的shodcut=True和shorcut=False的区别在干是否使用残差连接。当shorcu=True时,使用残差连接,可以以加速模型的收敛速度和提高模型的准确率,当shorcu=False时,不使用残差连接,可以减少模型的参数数量和计算量。
实际上不只是Ghostbottleneck具有残差连接,在C3、C2f等具有Bottleneck模块的结构均可根据此例举一反三。 相关问题
init (self, in channels, out channels, stride, shortcut=True, if first=False, num seg=8, name=None)
这是一个类的初始化函数,它有以下参数:
- in channels:输入特征图的通道数
- out channels: 输出特征图的通道数。
- stride: 卷积操作的步长。
- shortcut. 是否使用短连接结构如果为 True,会在卷积层中添加短连接,以避免梯度消失和梯度爆炸的问题
- if_first::是否是网络中的第一层。如果是第一层,会使用不同的初始化方式。
- num_seg:残差块中分段卷积的分段数。
- name:层的名称,用于区分不同的层
这个函数的作用是初始化一个残差块的参数。残差块是深度卷积神经网络中的一种基本模块,可以有效地解决梯度消失和梯度爆炸的问题。
相关文章:

Yolov11-detect训练自己的数据集
至此,整个YOLOv11的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。

YOLOv10训练自己的数据集
至此,整个YOLOv10的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。
YOLOv10环境搭建、模型预测和ONNX推理
运行后会在文件yolov10s.pt存放路径下生成一个的yolov10s.onnxONNX模型文件。安装完成之后,我们简单执行下推理命令测试下效果,默认读取。终端,进入base环境,创建新环境。(1)onnx模型转换。

YOLOv7-Pose 姿态估计-环境搭建和推理
终端,进入base环境,创建新环境,我这里创建的是p38t17(python3.8,pytorch1.7)安装pytorch:(网络环境比较差时,耗时会比较长)下载好后打开yolov7-pose源码包。imgpath:需要预测的图片的存放路径。modelpath:模型的存放路径。Yolov7-pose权重下载。打开工程后,进入设置。

YOLOv8-Detect训练CoCo数据集+自己的数据集
至此,整个训练预测阶段完成。此过程同样可以在linux系统上进行,在数据准备过程中需要仔细,保证最后得到的数据准确,最好是用显卡进行训练。有问题评论区见!

改进的yolov5目标检测-yolov5替换骨干网络-yolo剪枝(TensorRT及NCNN部署)
改进的yolov5目标检测-yolov5替换骨干网络-yolo剪枝(TensorRT及NCNN部署)2021.10.30 复现TPH-YOLOv52021.10.31 完成替换backbone为Ghostnet2021.11.02 完成替换backbone为Shufflenetv22021.11.05 完成替换backbone为Mobilenetv3Small2021.11.10 完成EagleEye对YOLOv5系列剪枝支持2021.11.14 完成MQBench对YOLOv5系列量
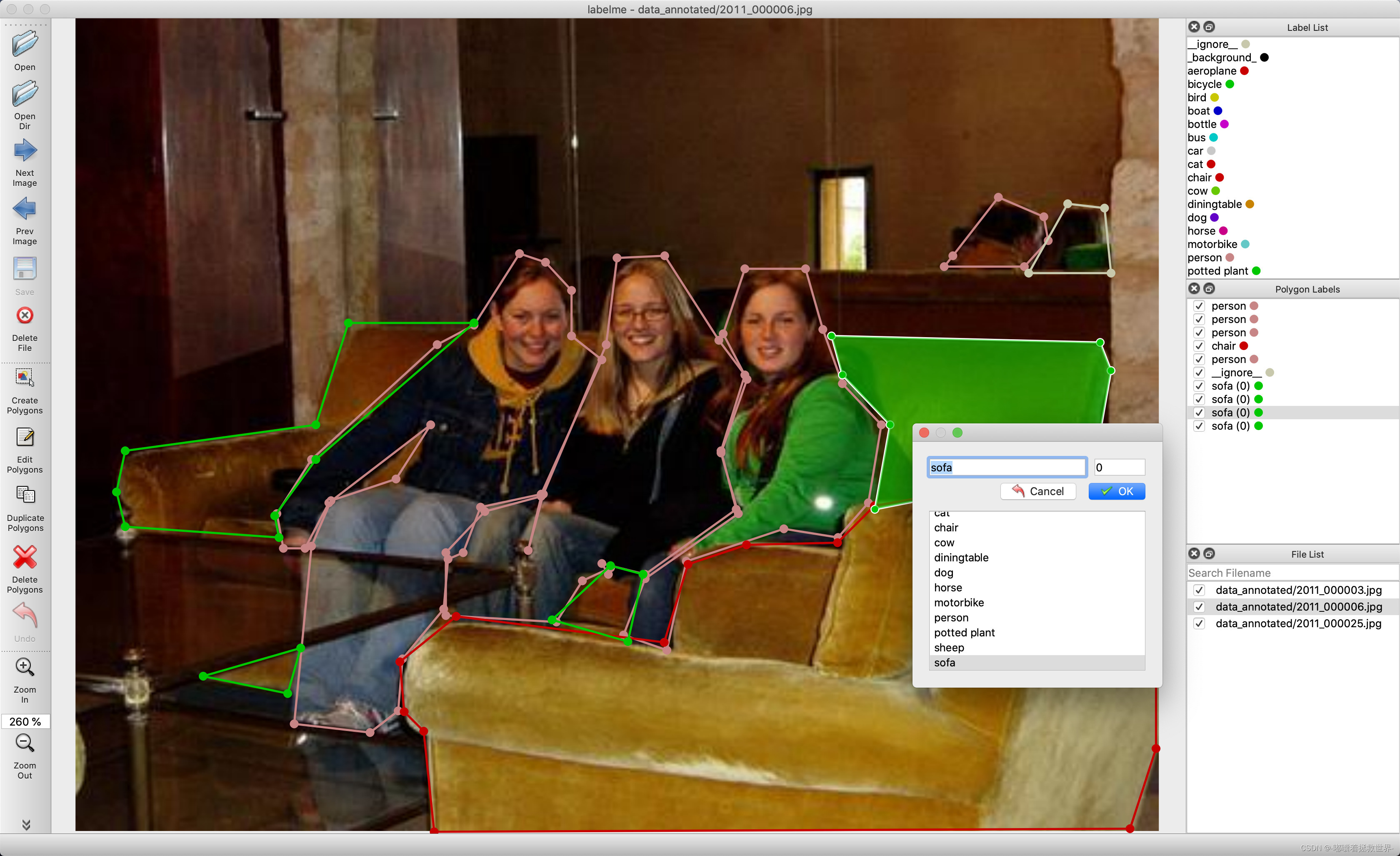
labelme安装与使用教程(内附一键运行包和转格式代码)
Labelme是一个开源的图像标注工具,由麻省理工学院的计算机科学和人工智能实验室(CSAIL)开发。它主要用于创建计算机视觉和机器学习应用所需的标记数据集。LabelMe让用户可以在图片上标注对象和区域,为机器学习模型提供训练数据。它支持多种标注类型,如矩形框、多边形和线条等。它是用 Python 编写的,并使用 Qt 作为其图形界面。
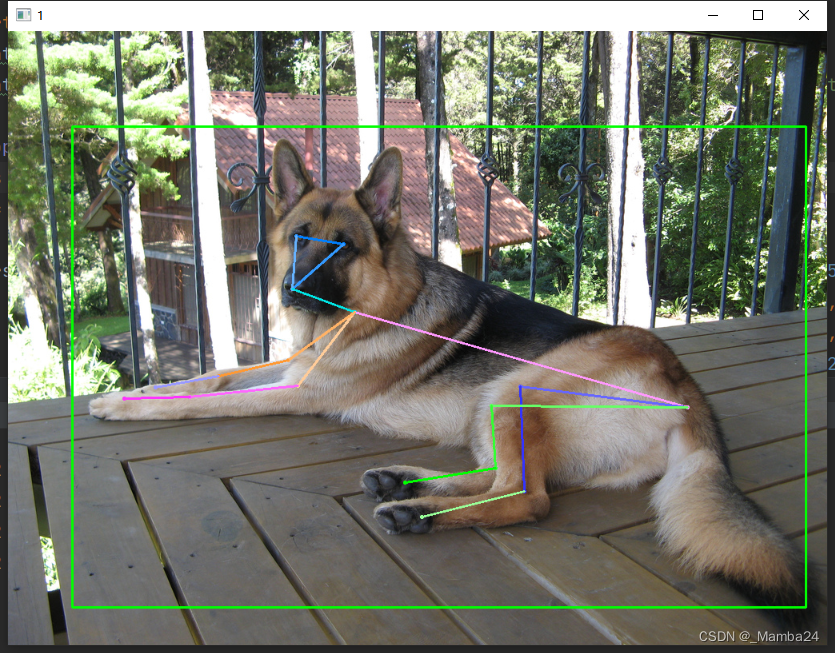
将AP-10K数据集Json格式转成Yolov8-Pose姿态的txt格式
class-index>是对象的类的索引,<x> <y> <width> <height>是边界框的坐标,<px1> <py1> <px2> <py2> ... <pxn> <pyn>是关键点的像素坐标。这样就将AP-10K数据集Json格式转成Yolov8-Pose的txt格式了。将txt的信息可视化在图片上进行验证。检查生成的txt是否准确。

YOLOv8-Pose训练自己的数据集
至此,整个YOLOv8-Pose模型训练预测阶段完成。此过程同样可以在linux系统上进行,在数据准备过程中需要仔细,保证最后得到的数据准确,最好是用显卡进行训练。有问题评论区见!

将labelme标注的人体姿态Json文件转成训练Yolov8-Pose的txt格式
最近在训练Yolov8-Pose时遇到一个问题,就是如何将自己使用labelme标注的Json文件转化成可用于Yolov8-Pose训练的txt文件。

【卷积神经网络】YOLO 算法原理
文章浏览阅读128次。在计算机视觉领域中,目标检测(Object Detection)是一个具有挑战性且重要的新兴研究方向。目标检测不仅要预测图片中是否包含待检测的目标,还需要在图片中指出它们的位置。2015年,Joseph Redmon, Santosh Divvala 等人提出第一个 YOLO 模型,该模型具有实时性高、支持多物体检测的特点,已成为目标检测领域热门的研究算法。本文主要介绍 YOLO 算法及其基本原理。