linux常用操作指令—— 查看磁盘、内存使用情况(df、du、free、top)
查看磁盘、内存使用情况
文章目录
df命令,查看磁盘占用情况
df -h #查看全部磁盘空间占用情况,包括共享目录
df -hl #查看本地磁盘空间占用情况
top命令,查看内存CPU占用率
top #查看CPU使用情况
top -u [用户名] #查看某用户CPU使用情况
du命令,查看目录大小
du -hs [目录名] #查看某目录或文件大小
1、df 显示磁盘分区上可以使用的磁盘空间
显示指定磁盘文件的可用空间。如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。默认情况下,磁盘空间将以 1KB为单位进行显示,除非环境变量 POSIXLY_CORRECT 被指定,那样将以512字节为单位进行显示。
使用方式
df [选项] [文件]
命令参数
-a 列出所有的文件系统,包括系统特有的 /proc 等文件系统
-k 以 KBytes 的容量显示各文件系统。命令 df -k 同命令 df
-m 以 MBytes 的容量显示各文件系统
-h 以人们较易阅读的 GBytes、MBytes、KBytes 等格式自行显示
-H 等于“-h”,但是计算式,1K=1000,而不是1K=1024
-i 不用磁盘容量,而以 inode 的数量来显示
-l 只显示本地文件系统。命令 df -l 同命令 df
--no-sync 忽略 sync 命令
-P 输出格式为POSIX
--sync 在取得磁盘信息前,先执行sync命令
-T 连同该磁盘分区的文件系统名称(例如 xfs)也列出
--block-size=<区块大小> 指定区块大小
-t <文件系统类型> 只显示选定文件系统的磁盘信息
-x <文件系统类型> 不显示选定文件系统的磁盘信息
--help 显示帮助信息
--version 显示版本信息
使用实例
实例1:显示磁盘使用情况
[root@server1 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1196004 16615452 7% /
devtmpfs 497216 0 497216 0% /dev
tmpfs 508188 0 508188 0% /dev/shm
tmpfs 508188 6736 501452 2% /run
tmpfs 508188 0 508188 0% /sys/fs/cgroup
/dev/vda1 1038336 141508 896828 14% /boot
tmpfs 101640 0 101640 0% /run/user/0
1、Filesystem:代表文件系统对应的设备文件的路径名(一般是硬盘上的分区);
2、1K-blocks:说明下面的数字单位是 1KB,可利用 -h 或 -m 来改变容量;
3、Used:使用掉的磁盘空间;
4、Available:也就是剩下的磁盘空间大小;用户也许会感到奇怪的是,第3,4列块数之和不等于第2列中的块数。这是因为缺省的每个分区都留了少量空间供系统管理员使用。即使遇到普通用户空间已满的情况,管理员仍能登录和留有解决问题所需的工作空间清单中;
5、Use%:就是磁盘的使用率,如果使用率高达 90% 以上,最好注意一下,免得容量不足造成系统问题,例如最容易占满的 /var/spool/mail 这个保存邮件的目录;
6、Mounted on:就是磁盘的挂载目录(挂载点)。
实例2:以inode模式来显示磁盘使用情况
[root@server1 ~]# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/mapper/rhel-root 8910848 35051 8875797 1% /
devtmpfs 124304 374 123930 1% /dev
tmpfs 127047 1 127046 1% /dev/shm
tmpfs 127047 410 126637 1% /run
tmpfs 127047 16 127031 1% /sys/fs/cgroup
/dev/vda1 524288 328 523960 1% /boot
tmpfs 127047 1 127046 1% /run/user/0
实例3:列出文件系统的类型
[root@server1 ~]# df -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root xfs 17811456 1196004 16615452 7% /
devtmpfs devtmpfs 497216 0 497216 0% /dev
tmpfs tmpfs 508188 0 508188 0% /dev/shm
tmpfs tmpfs 508188 6740 501448 2% /run
tmpfs tmpfs 508188 0 508188 0% /sys/fs/cgroup
/dev/vda1 xfs 1038336 141508 896828 14% /boot
tmpfs tmpfs 101640 0 101640 0% /run/user/0
实例4:显示目前磁盘空间和使用情况 (最常用)
[root@server1 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/rhel-root 17G 1.2G 16G 7% /
devtmpfs 486M 0 486M 0% /dev
tmpfs 497M 0 497M 0% /dev/shm
tmpfs 497M 6.6M 490M 2% /run
tmpfs 497M 0 497M 0% /sys/fs/cgroup
/dev/vda1 1014M 139M 876M 14% /boot
tmpfs 100M 0 100M 0% /run/user/0
[root@server1 ~]# df -H
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/rhel-root 19G 1.3G 18G 7% /
devtmpfs 510M 0 510M 0% /dev
tmpfs 521M 0 521M 0% /dev/shm
tmpfs 521M 7.0M 514M 2% /run
tmpfs 521M 0 521M 0% /sys/fs/cgroup
/dev/vda1 1.1G 145M 919M 14% /boot
tmpfs 105M 0 105M 0% /run/user/0
[root@server1 ~]# df -lh
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/rhel-root 17G 1.2G 16G 7% /
devtmpfs 486M 0 486M 0% /dev
tmpfs 497M 0 497M 0% /dev/shm
tmpfs 497M 6.6M 490M 2% /run
tmpfs 497M 0 497M 0% /sys/fs/cgroup
/dev/vda1 1014M 139M 876M 14% /boot
tmpfs 100M 0 100M 0% /run/user/0
[root@server1 ~]# df -k
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1196004 16615452 7% /
devtmpfs 497216 0 497216 0% /dev
tmpfs 508188 0 508188 0% /dev/shm
tmpfs 508188 6740 501448 2% /run
tmpfs 508188 0 508188 0% /sys/fs/cgroup
/dev/vda1 1038336 141508 896828 14% /boot
tmpfs 101640 0 101640 0% /run/user/0
说明:
-h更具目前磁盘空间和使用情况 以更易读的方式显示
-H根上面的-h参数相同,不过在根式化的时候,采用1000而不是1024进行容量转换
-k以单位显示磁盘的使用情况
-l显示本地的分区的磁盘空间使用率,如果服务器nfs了远程服务器的磁盘,那么在df上加上-l后系统显示的是过滤nsf驱动器后的结果
-i显示inode的使用情况。linux采用了类似指针的方式管理磁盘空间影射。这也是一个比较关键应用
2、du 显示每个文件和目录的磁盘使用空间
显示每个文件和目录的磁盘使用空间
使用方式
df [选项] [文件]
命令参数
-a或-all 列出所you的文件与目录容量,因为默认仅统计目录下面的文件量
-b或-bytes 显示目录或文件大小时,以byte为单位。
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
-k或--kilobytes 以KB(1024bytes)为单位输出。
-m或--megabytes 以MB为单位输出。
-s或--summarize 仅显示总量,只列出最后加总的值,而不列出每个个别的目录占用容量。
-S或--separate-dirs 不包括子目录下的总计,与 -s 有点差别
-h或--human-readable 以K,M,G为单位,提高信息的可读性。
-x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
-L<符号链接>或--dereference<符号链接> 显示选项中所指定符号链接的源文件大小。
-X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
--exclude=<目录或文件> 略过指定的目录或文件。
-D或--dereference-args 显示指定符号链接的源文件大小。
-H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。
-l或--count-links 重复计算硬件链接的文件。
使用实例
实例1:显示目录或者文件所占空间
[root@server1 ~]# du
48 ./nginx-1.14.2/auto/cc
...
2468 ./nginx-1.15.8/objs
9464 ./nginx-1.15.8
20980 .
说明:
直接输入 du 没有加任何选项时,则 du 会分析【目前所在目录】的文件与目录所占用的磁盘空间。
但是,实际显示时,仅显示目录容量(不含文件),因此(.)目录有很多文件没有列出来。
所以全部的目录相加不会等于(.)的容量,此外,输出的数据为 1K 大小的容量单位
实例2:显示指定文件所占空间
[root@server1 ~]# du date.txt
4 date.txt
实例3:查看指定目录的所占空间
[root@server1 ~]# du nginx-1.14.2
48 nginx-1.14.2/auto/cc
...
9348 nginx-1.14.2
实例4:显示多个文件所占空间
[root@server1 ~]# du nginx-1.14.2.tar.gz nginx-1.15.8.tar.gz
992 nginx-1.14.2.tar.gz
1004 nginx-1.15.8.tar.gz
实例5:方便阅读的格式显示(常用)
[root@server1 ~]# du -h nginx-1.14.2
48K nginx-1.14.2/auto/cc
...
9.2M nginx-1.14.2
实例6:文件和目录都显示
[root@server1 ~]# du -ah nginx-1.14.2
4.0K nginx-1.14.2/auto/cc/acc
...
8.0K nginx-1.14.2/src/stream/ngx_stream_upstream_round_robin.h
12K nginx-1.14.2/src/stream/ngx_stream_upstream_zone_module.c
32K nginx-1.14.2/src/stream/ngx_stream_variables.c
4.0K nginx-1.14.2/src/stream/ngx_stream_variables.h
8.0K nginx-1.14.2/src/stream/ngx_stream_write_filter_module.c
...
9.2M nginx-1.14.2
实例7:按照空间大小排序
[root@server1 ~]# du |sort -nr|more
20980 .
9464 ./nginx-1.15.8
940 ./nginx-1.14.2/objs/src/http
888 ./nginx-1.15.8/src/core
388 ./nginx-1.15.8/src/http/v2
140 ./nginx-1.15.8/contrib/vim
136 ./.vim
40 ./nginx-1.15.8/conf
...
0 ./nginx-1.14.2/objs/src/http/modules/perl
实例8:输出当前目录下各个子目录所使用的空间(常用)
[root@server1 ~]# du -h --max-depth=1
9.2M ./nginx-1.14.2
136K ./.vim
9.3M ./nginx-1.15.8
21M .
不带--max-depth参数,那么将循环列出文件夹下所有文件和文件夹占用的空间,带此参数,则是指定深入目录的层数。
2.1、Linux du命令和df命令区别
- 1、du :是通过搜索文件来计算每个文件的大小然后累加,du能看到的文件只是一些当前存在的,没有被删除的。他计算的大小就是当前他认为存在的所有文件大小的累加和。
- 2、 df: 通过文件系统来快速获取空间大小的信息,当我们删除一个文件的时候,这个文件不是马上就在文件系统当中消失了,而是暂时消失了,当所有程序都不用时,才会根据OS的规则释放掉已经删除的文件,df记录的是通过文件系统获取到的文件的大小,他比du强的地方就是能够看到已经删除的文件,而且计算大小的时候,把这一部分的空间也加上了,更精确了。
当文件系统也确定删除了该文件后,这时候du与df就一致了。
3、free 显示内存使用情况
free指令会显示内存的使用情况,包括实体内存,虚拟的交换文件内存,共享内存区段,以及系统核心使用的缓冲区等。
使用方式
free [-bkmhotV][-s <间隔秒数>]
命令参数
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-h 以合适的单位显示内存使用情况,最大为三位数,自动计算对应的单位值。单位有:
B = bytes
K = kilos
M = megas
G = gigas
T = teras
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
实例1:显示内存使用信息
[root@server1 ~]# free
total used free shared buffers cached
Mem: 254772 184568 70204 0 5692 89892
-/+ buffers/cache: 88984 165788
Swap: 524280 65116 459164
Mem行(单位均为M):
total 系统总的可用物理内存大小
used 已被使用的物理内存大小
free 还有多少物理内存可用
shared 被共享使用的物理内存大小
buff/cache 被 buffer 和 cache 使用的物理内存大小
available 还可以被 应用程序 使用的物理内存大小
(-/+ buffers/cache)行:
(-buffers/cache): 真正使用的内存数,指的是第一部分的 used - buffers - cached
(+buffers/cache): 可用的内存数,指的是第一部分的 free + buffers + cached
Swap行指交换分区
实例2:以总和的形式查询内存的使用信息
[root@server1 ~]# free -t
total used free shared buffers cached
Mem: 254772 184868 69904 0 5936 89908
-/+ buffers/cache: 89024 165748
Swap: 524280 65116 459164
Total: 779052 249984 529068
实例3:周期性的查询内存使用信息
[root@server1 ~]# free -s 10 //每10s 执行一次命令
total used free shared buffers cached
Mem: 254772 187628 67144 0 6140 89964
-/+ buffers/cache: 91524 163248
Swap: 524280 65116 459164
total used free shared buffers cached
Mem: 254772 187748 67024 0 6164 89940
-/+ buffers/cache: 91644 163128
Swap: 524280 65116 459164
4、使用top命令监控系统进程
top:“实时查看” ,按q退出 (实时动态显示)
-a # 将进程按照使用内存排序
-b # 批处理的模式显示进程信息,输出结果可以传递给其他程序或写入到文件中,配合-n使用,一直打到-n设置的阈值
-c # 显示进程的整个命令路径,而不是只显示命令名称
-d # 指定每两次屏幕信息刷新之间的时间间隔
-H # 指定这个可以显示每个线程的情况,否则就是进程的总的状态
-i # 不显示闲置或者僵死的进程状态
-n # top输出信息更新的次数,完成后将推出top命令
-p # 显示指定的进程信息
键入 top,显示如下信息
top - 14:27:26 up 4:22, 1 user, load average: 0.08, 0.03, 0.05
Tasks: 96 total, 2 running, 94 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1865284 total, 1460360 free, 96264 used, 308660 buff/cache
KiB Swap: 1048572 total, 1048572 free, 0 used. 1595216 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2029 root 20 0 0 0 0 R 0.3 0.0 0:00.14 kworker/0:1
第一行:任务队列信息,同uptime命令的执行结果
14:27:26 # 当前系统时间
up 4:26 # 系统已经运行了4个半小时
1 user # 当前有1个用户登录系统
load average: 0.08, 0.03, 0.05 # 1分钟,5分钟,15分钟的平均负载情况
第二行:Tasks为任务(进程)。上面的信息显示为
共有96个进程,处于运行状态的有2个,94个在休眠,stoped状态0个,zombie状态有0个
第三行:CPU状态信息
us # 用户空间占用CPU的百分比
sy # 内核空间占用cpu的百分比
ni # 改变优先级的进程占用CPU的百分比
id # 空闲CPU百分比
wa # I/O等待只用CPU的百分比
hi # 硬中断占用CPU的百分比
si # 软中断
st # 虚拟机占用CPU的百分比
第四行:内存状态
total # 物理内存总量
used # 使用中的内存总量
free # 空闲内存总量
buffers # 缓冲的内存量
第五行:swap交换分区信息
total # 交换分区总量
used # 使用的交换区总量
free # 空闲交换区总量
cached # 缓存的内存量
第六行:空行
第七行:给出的各进程(任务)的状态监控
PID # 进程iD
USER # 进程所有者
PR # 进程优先级
NI # nice值,负值表示高优先级,正值表示低优先级
VIRT # 进程使用的虚拟内存总量,单位为KB
RES # 进程使用的,未被换出的物理内存大小,单位KB
SHR # 共享内存大小,单位为kb
S # 进程状态,D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程
%CPU # 上次更新到现在的CPU时间占用百分比
%MEM # 进程使用的物理内存百分比
TIME+ # 进程使用的物理内存百分比
COMMAND # 进程名称
参考
1、https://www.jianshu.com/p/0aed4feba213
2、https://www.runoob.com/linux/linux-comm-free.html
3、https://blog.csdn.net/qq_42303254/article/details/89487143
相关文章:

【Linux之升华篇】Linux内核锁、用户模式与内核模式、用户进程通讯方式
alloc_pages(gfp_mask, order),_ _get_free_pages(gfp_mask, order)等。字符设备描述符 struct cdev,cdev_alloc()用于动态的分配 cdev 描述符,cdev_add()用于注。外,还支持语义符合 Posix.1 标准的信号函数 sigaction(实际上,该函数是基于 BSD 的,BSD。从最初的原子操作,到后来的信号量,从。(2)命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的。

@Scheduled注解的scheduler属性什么作用
注解是 Spring Framework 提供的一种机制,用于定义计划任务,即周期性执行的任务。 注解可以应用于方法上,以指示 Spring 容器在特定的时间间隔或按照某种调度规则来调用该方法。 属性是 注解的一个可选属性,它的作用是允许开发者指定一个自定义的 对象来控制任务的调度方式。默认情况下, 注解使用 Spring 内部的 来执行任务,但如果需要更高级的定制化需求,可以通过 属性指定一个自定义的 实现。自定义调度器:共享调度器资源:高级调度需求:假设你想使用 作为调度器,并且希望所有带有

Ubuntu下安装和配置Redis
找到 /ect/redis/redis.conf 文件修改如下:注释掉 127.0.0.1 ,如果不需要远程连接redis则不需要这个操作。使用客户端向 Redis 服务器发送一个 PING ,如果服务器运作正常的话,会返回一个 PONG。默认情况下,Redis服务器不允许远程访问,只允许本机访问,所以我们需要设置打开远程访问的功能。执行sudo apt-get install redis-server 安装命令。查看 redis 是否启动,重新打开一个窗口。停止/启动/重启redis。
Linux下netstat命令详解&&netstat -anp | grep 讲解
Netstat是控制台命令,是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
Linux命令——根据端口号查进程
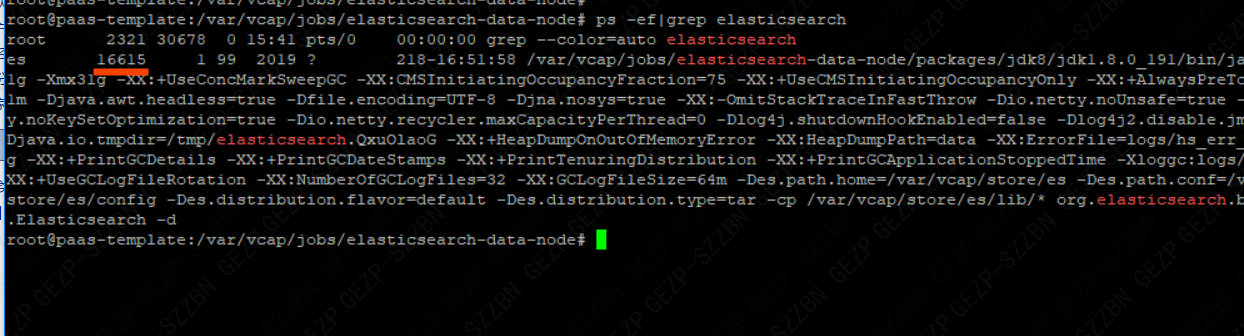
查出的数据第二列(16615)是elasticsearch的进程号。通常我们会根据端口号查进程号,或者通过进程号查端口号。linux环境下,我们常常会查询进程号pid。最常用ps -ef |grep xx。根据端口port查进程。根据端口port查进程。根据进程pid查端口。根据进程pid查端口。
Linux搜索文件&搜索文件名&替换文件内容
locate是Linux系统提供的一种快速检索全局文件的系统命令,它并不是真的去检索所以系统目录,而是检索一个数据库文件locatedb(Ubuntu系置/var/cache/locate/locatedb),该数据库文件包含了系统所有文件的路径索引信息,所以查找速度很快。time结尾的选项,其单位为天,min结尾的选项其单位为分钟,这些选项的值都为一个正负整数, 如+7,表示,7天以前被访问过的文件,-7表示7天以内被访问过的文件,7表示恰好7天前被访问的文件。:快速返回某个指定命令的位置信息。
[Ubuntu 22.04] Docker安装及使用
容器的生命周期由用户控制,用户可以选择手动删除容器或让其保留在系统中以供之后使用。选项允许你在容器内部创建一个交互式的终端会话,使你可以像在本地终端一样与容器进行交互。你可以在容器内执行命令,查看输出并输入命令。镜像拉取完成后,可以使用以下命令创建并启动一个基于 Ubuntu 20.04 镜像的容器。列出所有正在运行的容器,并显示它们的容器ID、镜像、命令、创建时间、状态等信息。以下命令可以中止容器,改命令将向容器发送一个停止信号,使其正常停止并退出。这将显示所有容器的列表,包括正在运行的和已停止的容器。
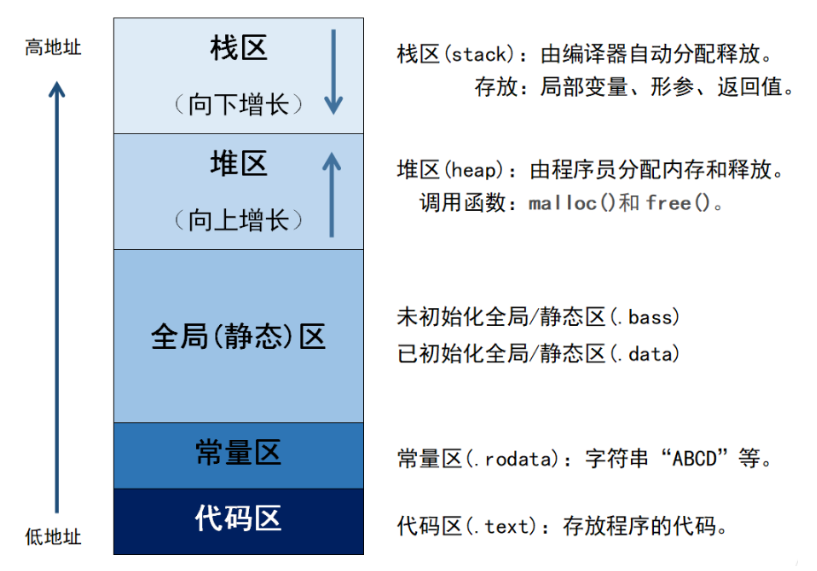
C程序的内存空间布局(栈、堆、数据区、常量区、代码区)
较详细的介绍了栈、堆、数据区、常量区、代码区
给服务器开通telnet的流程
但一些特殊场景下,比如要升级ssh,ssh不能用时,需要使用telnet,用过要关闭此服务。需要首先安装,如果telnet-server服务在xinetd之前安装了,要先删除telnet-server,再安装xinetd。安装顺序:xinetd--》telnet--》telnet-server。安装顺序:xinetd--》telnet--》telnet-server。2、卸载rpm包(如果已经安装了,又不清楚顺序,可以都卸载后统一安装)注意:telnet-server服务启动依赖xinetd服务,
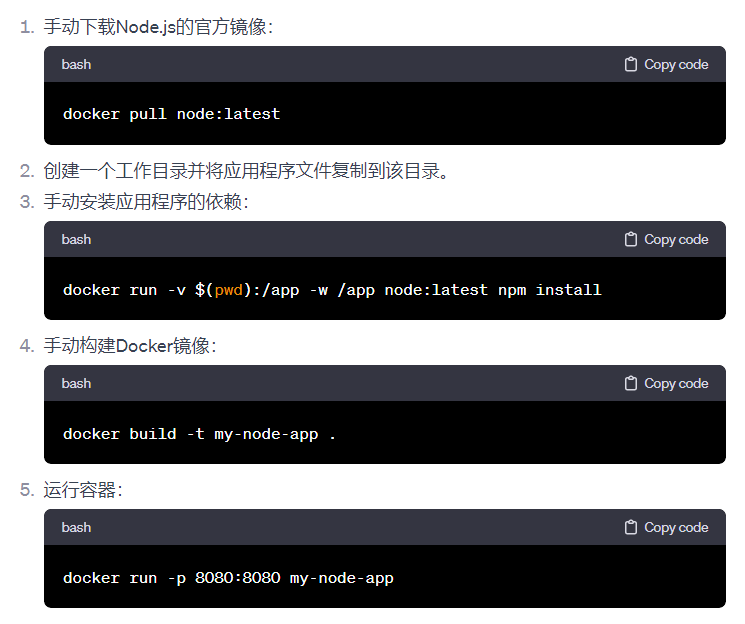
使用DockerFile构建镜像与镜像上传
首先Dockerfile 是一个文本格式的配置文件, 用户可以使用 Dockerfile 来快速创建自定义的镜像。
Centos系统上安装PostgreSQL和常用PostgreSQL功能
PostgreSQL安装成功之后,会默认创建一个名为postgres的Linux用户,初始化数据库后,会有名为postgres的数据库,来存储数据库的基础信息,例如用户信息等等,相当于MySQL中默认的名为mysql数据库。权限代码:SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE、USAGE。为了方便我们使用postgres账号进行管理,我们可以修改该账号的密码。
linux切换root用户su - root和su root的区别
通过tty客户端登陆的shell就是login shell,通过在图形界面使用ctrl+shift+t的方式新建的shell是no login shell。登录的流程,会执行 /etc/profile,/etc/profile.d/下定义的*.sh都会执行。su - root,产生一个登录shell去执行后面的指令。no login shell 读取的文件和顺序为:/etc/bashrc和~/.bashrc。su root,产生一个非登录交互shell,非登录交互shell,只执行用户目录下。

轻松管理Linux磁盘空间命令:df
通过使用--output选项,可以自定义df命令的输出格式,选择显示的列以及它们的顺序。这对于筛选特定信息以便进一步处理非常有用。本文我们介绍了Linux系统上的df命令,包括基本用法、进阶用法、实际案例和场景应用,以及一些实用技巧和注意事项。df命令是系统管理中的一个重要工具,能够帮助用户有效管理磁盘空间,预防和解决潜在问题。在实际使用中,请根据具体情况选择合适的df命令选项和参数,并结合其他命令,以获取更全面的系统信息。
Linux grep命令教程:强大的文本搜索工具(附案例详解和注意事项)
grep(Global Regular Expression Print)命令用来在文件中查找包含或者不包含某个字符串的行,它是强大的文本搜索工具,并可以使用正则表达式进行搜索。当你需要在文件或者多个文件中搜寻特定信息时,grep就显得无比重要啦。
保持Python程序在Linux上持续运行的几种方法
主要是用来定时执行任务的,但你也可以利用它来监控你的Python脚本是否正在运行,并在需要时重新启动它。是一个非常实用的命令,它可以让你的Python脚本在你退出shell后继续运行。总结起来,根据你的具体需求和环境,你可以选择以上任何一种方法来保持Python程序在Linux上的持续运行。使用这些工具,你可以随时断开SSH连接,而不用担心脚本会停止运行。通过这种方式,你可以安全地关闭终端,而脚本会继续在后台执行。这样,你的Python脚本就会作为系统服务运行,并且会在系统启动时自动启动。

linux环境中一次启动多个jar包,并且设置脚本开机自启
我们在通过jar启动项目时,有时候会比较多,启动会比较麻烦,需要编写shell脚本启动,将启动脚本存放在需要启动的jar包路径下。(文档存放在 /home/process_parent )PORTS 端口号,多个用空格隔开MODULES 模块,多个用空格隔开MODULE_NAMES 模块名称,多个用空格隔开。
windows11通过虚拟机安装Ubuntu20.04
window11通过虚拟机VMware Workstation 17 Player安装ubuntu20.04

开发版ubuntu系统上如何进行开机自启(四种方法一览)
如果省略该字段,则 systemd 将默认将当前服务的启动顺序设置为与其他服务无关,即在启动过程中没有任何依赖性关系,服务的启动顺序由系统自行决定。【ExecStart】 关键字段,服务启动命令,指定服务启动时需要执行的命令或脚本【WantedBy】用于指定服务的自动启动级别,在 Linux 系统中,多用户模式是指允许多个用户同时登录并使用系统资源的模式,与之相对的是单用户模式,只有一个用户可以登录并使用系统资源。保存文件的方法根据所使用的编辑器而有所不同,通常是按下特定的键组合,然后选择保存并退出。
你了解计算机网络的发展历史吗?
计算机网络是指将一群具有独立功能的计算机通过被互联起来的,在通信软件的支持下,实现的系统。计算机网络是计算机技术与通信技术紧密结合的产物,两者的迅速发展渗透形成了计算机网络技术。简而言之呢,计算机网络就是实现两台计算机相互沟通的介质。
Linux安装MongoDB教程
将解压后的 mongodb-linux-x86_64-rhel70-4.2.23 中的所有文件全部移动到 /usr/local/mongodb 中 :注意/*是所有子文件。也可以不用设置环境变量进行启动,但是不设置环境变量启动的话要每次启动写很多启动参数,比较麻烦,所以做好配置环境变量。在 mongodb 下创建 data 和 logs 目录,以及日志文件mongodb.log。在 /usr/local 目录中创建 mongodb 文件夹。启动 MongoDB(-conf 使用配置文件方式启动)
Linux之后台执行命令:nohup和&的使用
如果不将 nohup 命令的输出重定向,输出将附加到当前目录的 nohup.out 文件中。command>out.file是将command的输出重定向到out.file文件,即输出内容不打印到屏幕上,而是输出到out.file文件中。2>&1是将标准错误(2)重定向到标准输出(&1),标准输出(&1)再被重定向输入到out.file文件中。作业在后台运行的时候,可以把输出重定向到某个文件中,相当于一个日志文件,记录运行过程中的输出。将sh test.sh任务放到后台,但是依然可以使用标准输入,
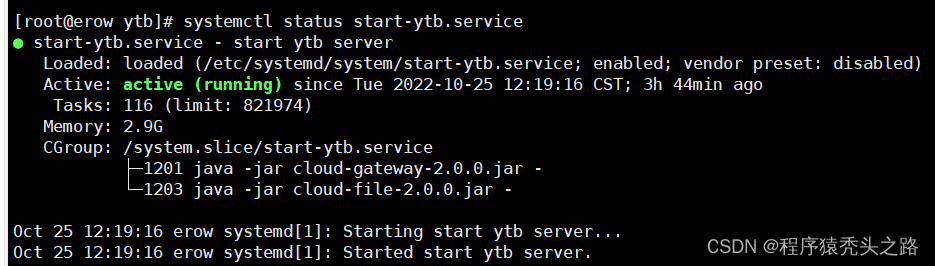
CentOS 7 设置 Jar包、MinIO、Nginx 开机自启动
根据需要,自己修改 Description 和 ExecStart 的内容即可(ExecStart后面的java命令需要全路径)ExecStart 服务运行执行的命令,放上面创建的脚本位置。[Install] 服务安装的相关设置,可设置为多用户。如果用 yum install 命令安装的,如果使用源码手动编译的则需要手动创建。文件,xxx 就是自定义的服务名称。After:设置在某个服务启动后启动。Description:服务的描述。可以使用这个命令来查看服务启动日志。里面的环境变量是必须的,将。

Linux系统中Java new Date()的时间和系统时间不一致
出现问题:new Date(),的时间和当前时间不一样,发现差了8小时,看到8小时就应该明白了,时区的问题。
linux中&和&&,|和||及分号(;)的用法
在linux中,我们经常会用到&和&&,|和||及分号,但是好多人对其会混淆,不明白其中的意思,今天为大家讲解一下&和&&,|和||及分号(;)各自的说明和用法。
Vim 粘贴内容时全变成注释的问题
在使用vim粘贴代码时,会出现注释代码后面的代码全被注释的情况。在paste模式下进行复制粘贴就变得很正常了。
网站如何创建百度地图显示地理位置
地图演示
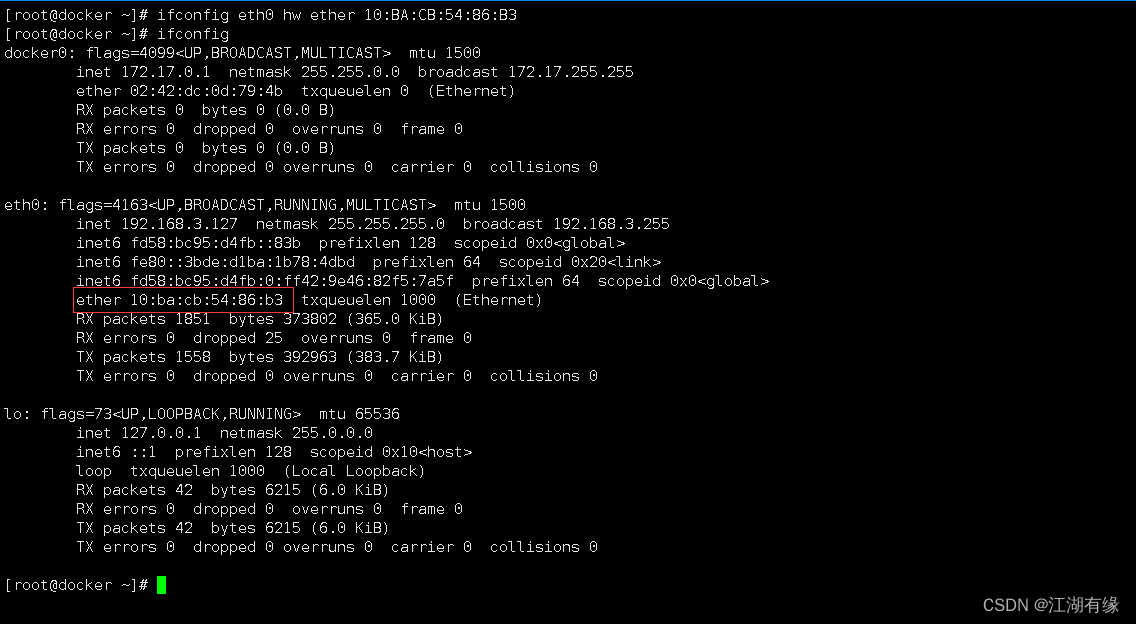
Linux系统之ifconfig命令的基本使用
ifconfig是Linux中常用的网络配置工具之一,用于配置和显示网络接口的具体状况。

e2studio开发LPS28DFW气压计(1)----轮询获取气压计数据
本文将介绍如何使用 LPS28DFW 传感器来读取数据。主要步骤包括初始化传感器接口、验证设备ID、配置传感器的数据输出率和滤波器,以及通过轮询方式持续读取气压数据和温度数据。读取到的数据会被转换为适当的单位并通过串行通信输出。

大数据Hadoop、HDFS、Hive、HBASE、Spark、Flume、Kafka、Storm、SparkStreaming这些概念你是否能理清?
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hadoop是大数据开发的重要框架,是一个由Apache基金会所开发的分布式系统基础架构,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,在Hadoop2.x时 代,增加 了Yarn,Yarn只负责资 源 的 调 度。当计算模型比较适合流式时,storm的流式处理,省去了批处理的收集数据的时间;
HDFS对比HBase、Hive对比Hbase
Hive和Hbase是两种基于Hadoop的不同技术Hive是一种类SQL的引擎,并且运行MapReduce任务Hbase是一种在Hadoop之上的NoSQL的Key/value数据库这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也 可以从Hive写到HBase,或者从HBase写回Hive。