【redis】技术派中的缓存一致性解决方案
1.概述
转载:技术派中的缓存一致性解决方案 我觉得这个图画的很好,转载学习一下。
今天就结合技术派项目,告诉大家如何去实现 MySQL 和 Redis 的一致性。
在讲解实战部分之前,我们还是先回顾一下理论知识,根据网上的众多解决方案,我们总结出 6 种:
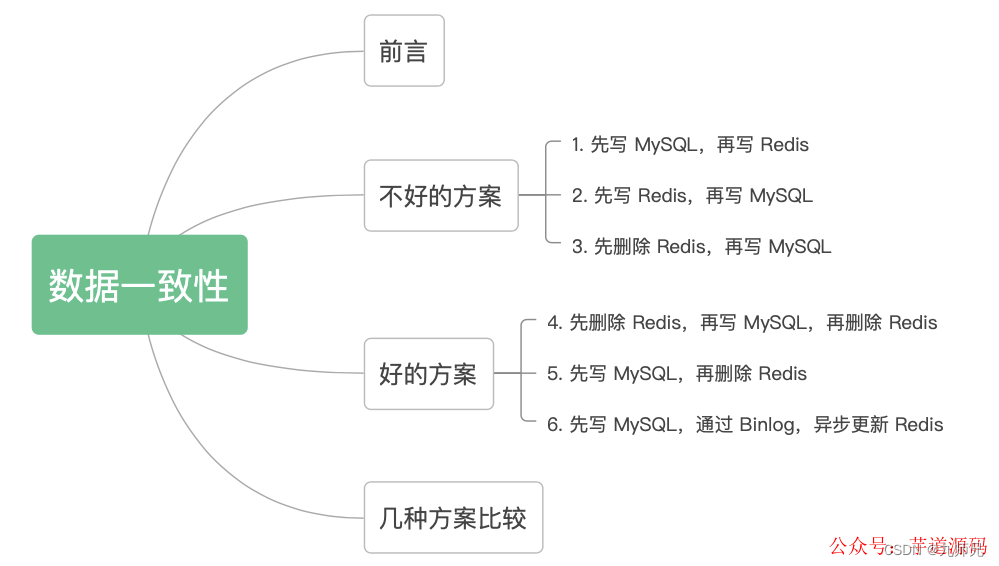
你可以先想想,技术派会采用哪种方案呢?
一、理论知识
温馨提示:如果你对理论知识已经非常清楚,可以直接跳到文章的实战部分。
1.1 不好的方案
- 先写 MySQL,再写 Redis
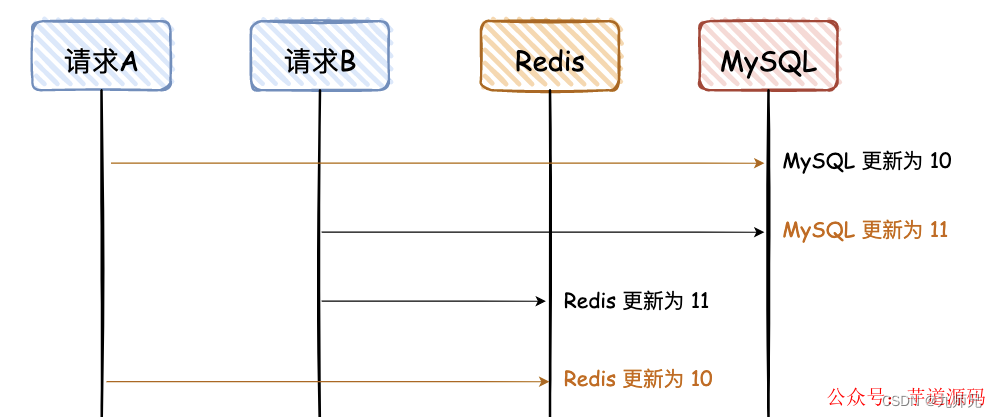
图解说明:
这是一副时序图,描述请求的先后调用顺序;
橘黄色的线是请求 A,黑色的线是请求 B;
橘黄色的文字,是 MySQL 和 Redis 最终不一致的数据;
数据是从 10 更新为 11;
后面所有的图,都是这个含义,不再赘述。
请求 A、B 都是先写 MySQL,然后再写 Redis,在高并发情况下,如果请求 A 在写 Redis 时卡了一会,请求 B 已经依次完成数据的更新,就会出现图中的问题。
这个图已经画的很清晰了,我就不用再去啰嗦了吧,不过这里有个前提,就是对于读请求,先去读 Redis,如果没有,再去读 DB,但是读请求不会再回写 Redis。大白话说一下,就是读请求不会更新 Redis。
- 先写 Redis,再写 MySQL
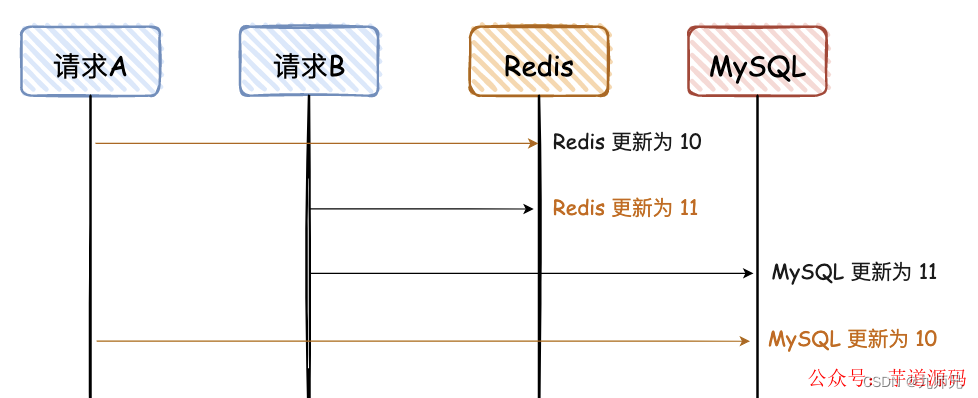
同“先写 MySQL,再写 Redis”,看图可秒懂。
- 先删除 Redis,再写 MySQL
这幅图和上面有些不一样,前面的请求 A 和 B 都是更新请求,这里的请求 A 是更新请求,但是请求 B 是读请求,且请求 B 的读请求会回写 Redis。
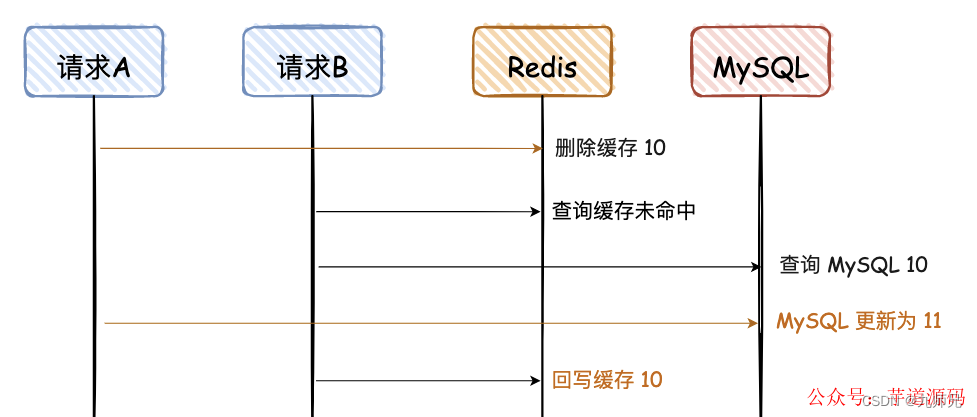
请求 A 先删除缓存,可能因为卡顿,数据一直没有更新到 MySQL,导致两者数据不一致。
这种情况出现的概率比较大,因为请求 A 更新 MySQL 可能耗时会比较长,而请求 B 的前两步都是查询,会非常快。
1.2 好的方案
4. 先删除 Redis,再写 MySQL,再删除 Redis
对于“先删除 Redis,再写 MySQL”,如果要解决最后的不一致问题,其实再对 Redis 重新删除即可,这个也是大家常说的“缓存双删”。
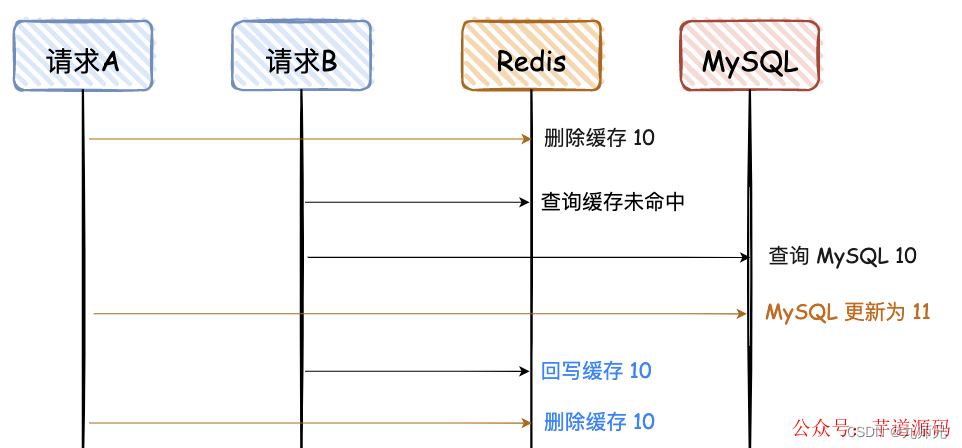
为了便于大家看图,对于蓝色的文字,“删除缓存 10”必须在“回写缓存10”后面,那如何才能保证一定是在后面呢?网上给出的第一个方案是,让请求 A 的最后一次删除,等待 500ms。
对于这种方案,看看就行,反正我是不会用,太 Low 了,风险也不可控。
那有没有更好的方案呢,我建议异步串行化删除,即删除请求入队列。
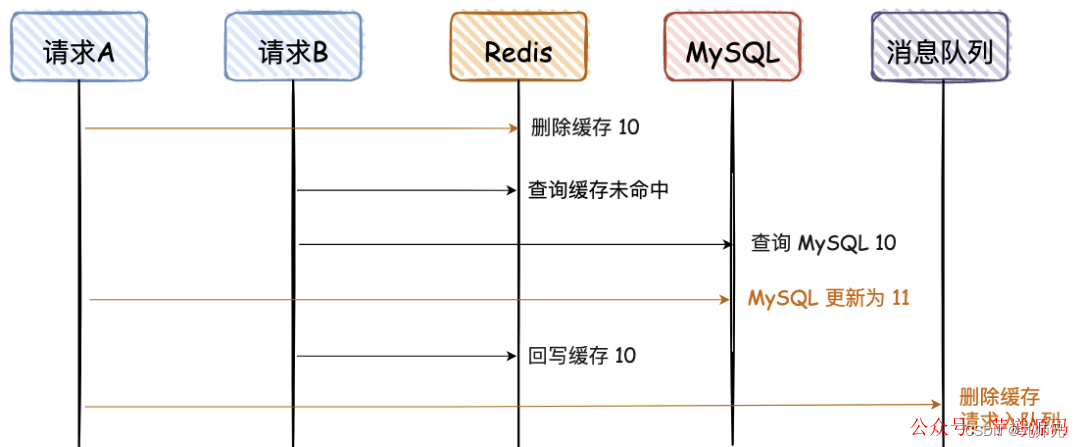
异步删除对线上业务无影响,串行化处理保障并发情况下正确删除。
如果双删失败怎么办,网上有给 Redis 加一个缓存过期时间的方案,这个不敢苟同。个人建议整个重试机制,可以借助消息队列的重试机制,也可以自己整个表,记录重试次数,方法很多。
简单小结一下:
“缓存双删”不要用无脑的 sleep 500 ms;
通过消息队列的异步&串行,实现最后一次缓存删除;
缓存删除失败,增加重试机制。
5. 先写 MySQL,再删除 Redis
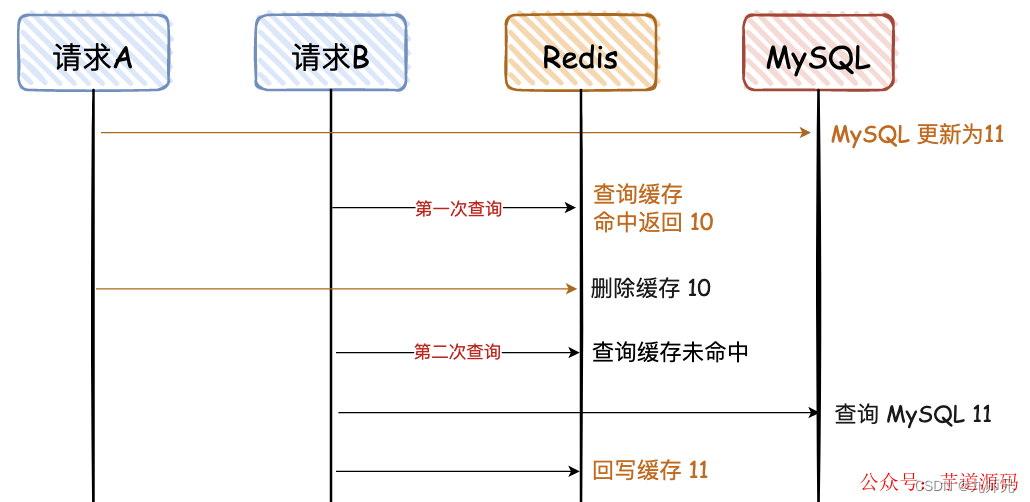
对于上面这种情况,对于第一次查询,请求 B 查询的数据是 10,但是 MySQL 的数据是 11,只存在这一次不一致的情况,对于不是强一致性要求的业务,可以容忍。(那什么情况下不能容忍呢,比如秒杀业务、库存服务等。)
当请求 B 进行第二次查询时,因为没有命中 Redis,会重新查一次 DB,然后再回写到 Reids。
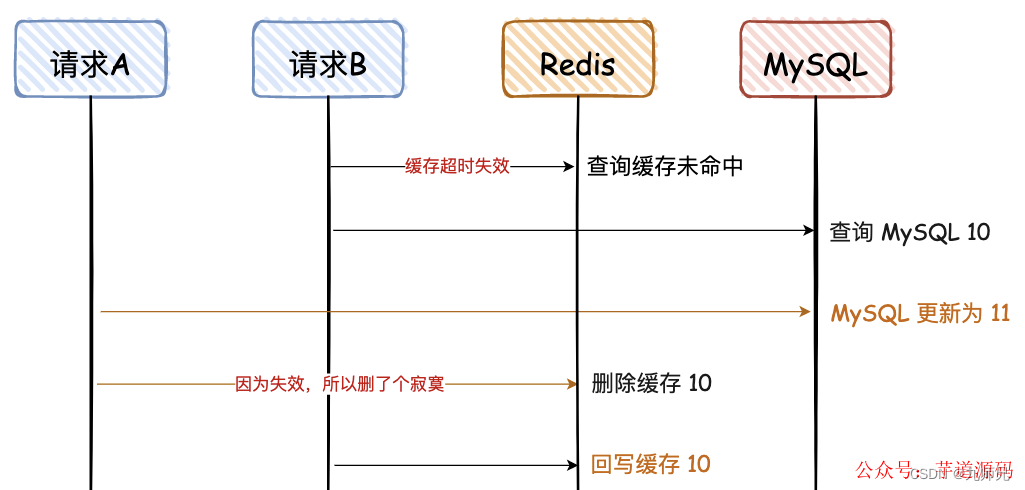
这里需要满足 2 个条件:
缓存刚好自动失效;
请求 B 从数据库查出 10,回写缓存的耗时,比请求 A 写数据库,并且删除缓存的还长。
对于第二个条件,我们都知道更新 DB 肯定比查询耗时要长,所以出现这个情况的概率很小,同时满足上述条件的情况更小。
- 先写 MySQL,通过 Binlog,异步更新 Redis
这种方案,主要是监听 MySQL 的 Binlog,然后通过异步的方式,将数据更新到 Redis,这种方案有个前提,查询的请求,不会回写 Redis。
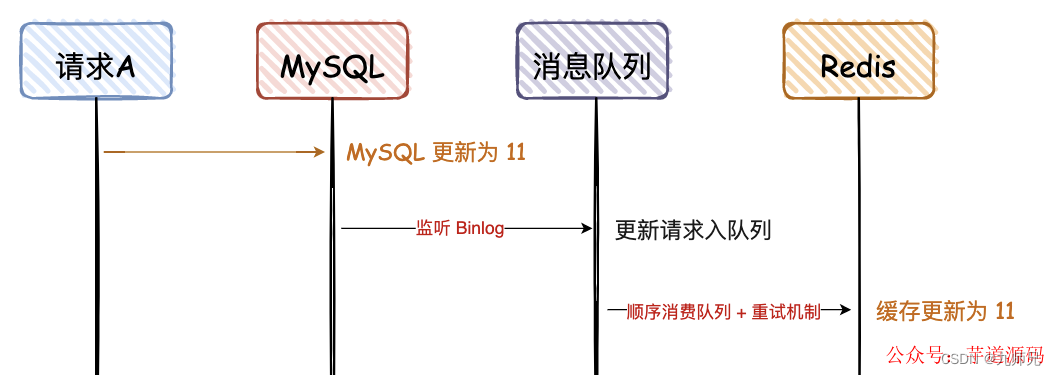
这个方案,会保证 MySQL 和 Redis 的最终一致性,但是如果中途请求 B 需要查询数据,如果缓存无数据,就直接查 DB;如果缓存有数据,查询的数据也会存在不一致的情况。
所以这个方案,是实现最终一致性的终极解决方案,但是不能保证实时性。
1.3 几种方案比较
我们对比上面讨论的 6 种方案:
1、先写 Redis,再写 MySQL
这种方案,我肯定不会用,万一 DB 挂了,你把数据写到缓存,DB 无数据,这个是灾难性的;
我之前也见同学这么用过,如果写 DB 失败,对 Redis 进行逆操作,那如果逆操作失败呢,是不是还要搞个重试?
2、先写 MySQL,再写 Redis
对于并发量、一致性要求不高的项目,很多就是这么用的,我之前也经常这么搞,但是不建议这么做;
当 Redis 瞬间不可用的情况,需要报警出来,然后线下处理。
3、先删除 Redis,再写 MySQL
这种方式,我还真没用过,直接忽略吧。
4、先删除 Redis,再写 MySQL,再删除 Redis
这种方式虽然可行,但是感觉好复杂,还要搞个消息队列去异步删除 Redis。
5、先写 MySQL,再删除 Redis
比较推荐这种方式,删除 Redis 如果失败,可以再多重试几次,否则报警出来;
这个方案,是实时性中最好的方案,在一些高并发场景中,推荐这种。
6、先写 MySQL,通过 Binlog,异步更新 Redis
对于异地容灾、数据汇总等,建议会用这种方式,比如 binlog + kafka,数据的一致性也可以达到秒级;
纯粹的高并发场景,不建议用这种方案,比如抢购、秒杀等。
个人结论
实时一致性方案 :采用“先写 MySQL,再删除 Redis”的策略,这种情况虽然也会存在两者不一致,但是需要满足的条件有点苛刻,所以是满足实时性条件下,能尽量满足一致性的最优解。
最终一致性方案 :采用“先写 MySQL,通过 Binlog,异步更新 Redis”,可以通过 Binlog,结合消息队列异步更新 Redis,是最终一致性的最优解。
二、项目实战
2.1 数据更新
因为项目对实时性要求高,所以采用方案 5,先写 MySQL,再删除 Redis 的方式。
下面只是一个示例,我们将文章的标签放入 MySQL 之后,再删除 Redis,所有涉及到 DB 更新的操作都需要按照这种方式处理。
这里加了一个事务,如果 Redis 删除失败,MySQL 的更新操作也需要回滚,避免查询时读取到脏数据。
@Override
@Transactional(rollbackFor = Exception.class)
public void saveTag(TagReq tagReq) {
TagDO tagDO = ArticleConverter.toDO(tagReq);
// 先写 MySQL
if (NumUtil.nullOrZero(tagReq.getTagId())) {
tagDao.save(tagDO);
} else {
tagDO.setId(tagReq.getTagId());
tagDao.updateById(tagDO);
}
// 再删除 Redis
String redisKey = CACHE_TAG_PRE + tagDO.getId();
RedisClient.del(redisKey);
}
Override
@Transactional(rollbackFor = Exception.class)
public void deleteTag(Integer tagId) {
TagDO tagDO = tagDao.getById(tagId);
if (tagDO != null){
// 先写 MySQL
tagDao.removeById(tagId);
// 再删除 Redis
String redisKey = CACHE_TAG_PRE + tagDO.getId();
RedisClient.del(redisKey);
}
}
@Override
public void operateTag(Integer tagId, Integer pushStatus) {
TagDO tagDO = tagDao.getById(tagId);
if (tagDO != null){
// 先写 MySQL
tagDO.setStatus(pushStatus);
tagDao.updateById(tagDO);
// 再删除 Redis
String redisKey = CACHE_TAG_PRE + tagDO.getId();
RedisClient.del(redisKey);
}
}
2.2 数据获取
这个也很简单,先查询缓存,如果有就直接返回;如果未查询到,需要先查询 DB ,再写入缓存。
我们放入缓存时,加了一个过期时间,用于兜底,万一两者不一致,缓存过期后,数据会重新更新到缓存。
@Override
public TagDTO getTagById(Long tagId) {
String redisKey = CACHE_TAG_PRE + tagId;
// 先查询缓存,如果有就直接返回
String tagInfoStr = RedisClient.getStr(redisKey);
if (tagInfoStr != null && !tagInfoStr.isEmpty()) {
return JsonUtil.toObj(tagInfoStr, TagDTO.class);
}
// 如果未查询到,需要先查询 DB ,再写入缓存
TagDTO tagDTO = tagDao.selectById(tagId);
tagInfoStr = JsonUtil.toStr(tagDTO);
RedisClient.setStrWithExpire(redisKey, tagInfoStr, CACHE_TAG_EXPRIE_TIME);
return tagDTO;
}
2.3 测试用例
/**
* @author Louzai
* @date 2023/5/5
*/
@Slf4j
public class MysqlRedisService extends BasicTest {
@Autowired
private TagSettingService tagSettingService;
@Test
public void save() {
TagReq tagReq = new TagReq();
tagReq.setTag("Java");
tagReq.setTagId(1L);
tagSettingService.saveTag(tagReq);
log.info("save success:{}", tagReq);
}
@Test
public void query() {
TagDTO tagDTO = tagSettingService.getTagById(1L);
log.info("query tagInfo:{}", tagDTO);
}
}
我们看一下 Redis:
127.0.0.1:6379> get pai_cache_tag_pre_1
"{\"tagId\":1,\"tag\":\"Java\",\"status\":1,\"selected\":null}"
以及结果输出:

后记
这篇文章很基础,也非常实用,大家可以直接下载技术派项目,里面都有代码和测试用例,代码仓库详见:
https://github.com/itwanger/paicoding
后面我会把 RabbitMQ、ES、Nacos、MongoDB 和 prometheus 都集成到技术派项目,不为其它的,存粹为了自娱自乐。
相关文章:

【Mongdb之数据同步篇】什么是Oplog、Mongodb 开启oplog,java监听oplog并写入关系型数据库、Mongodb动态切换数据源
oplog是local库下的一个固定集合,Secondary就是通过查看Primary 的oplog这个集合来进行复制的。每个节点都有oplog,记录这从主节点复制过来的信息,这样每个成员都可以作为同步源给其他节点。Oplog 可以说是Mongodb Replication的纽带了。

Ubuntu下安装和配置Redis
找到 /ect/redis/redis.conf 文件修改如下:注释掉 127.0.0.1 ,如果不需要远程连接redis则不需要这个操作。使用客户端向 Redis 服务器发送一个 PING ,如果服务器运作正常的话,会返回一个 PONG。默认情况下,Redis服务器不允许远程访问,只允许本机访问,所以我们需要设置打开远程访问的功能。执行sudo apt-get install redis-server 安装命令。查看 redis 是否启动,重新打开一个窗口。停止/启动/重启redis。

Windows下安装和配置Redis
下载版本Redis-x64-5.0.14.1.zip。(可能需要开代理)
ON DUPLICATE KEY UPDATE 导致mysql自增主键ID跳跃增长
具体解决方案可以根据项目来选择,如果项目不大,可以考虑1和2。如果不考虑高并发问题,可以考虑3。
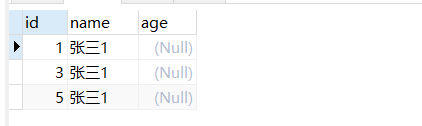
mysql唯一索引与null
根据NULL的定义,NULL表示的是未知,因此两个NULL比较的结果既不相等,也不不等,结果仍然是未知。根据这个定义,多个NULL值的存在应该不违反唯一约束,所以是合理的,在oracel也是如此。在mysql 的innodb引擎中,是允许在唯一索引的字段中出现多个null值的。有上面的表和数据可以看出,查询多条数据。

详解mybatis的insert,update,delete返回值
为什么要提数据的事呢,是因为据说这个save返回的就是插入的数据的条数。但是遗憾的是,我们的这个user怎么能没有id呢,没有id有怎么查,怎么删,怎么改。进来的是没有id的user,出去的是有id的user,真是太厉害了,没想到不仅把返回值改变了,连参数都发生了改变,真是太神奇了。keyProperty=“id” 这是id就是绑定的id,那我就疑惑了,这绑定的哪个id啊。这样一搞,如果插入成功的话返回的是1,如果不成功的话返回的是-1。我让你删id是222222的,我还没创建呢,看你怎么删。
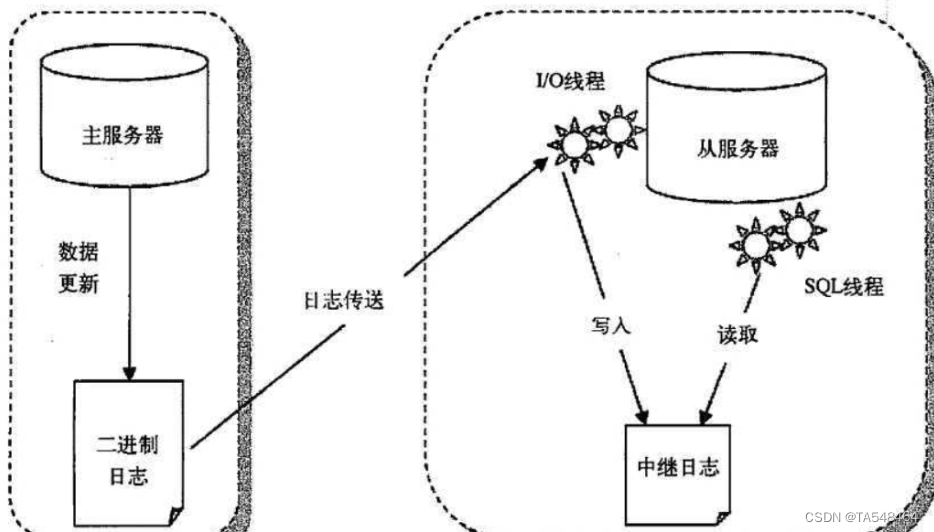
MySQL主从复制(基于binlog日志方式)
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。主从复制的作用1.做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。2.架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。3.读写分离,使数据库能支撑更大的并发。a.从服务器可以执行查询工作(就是我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
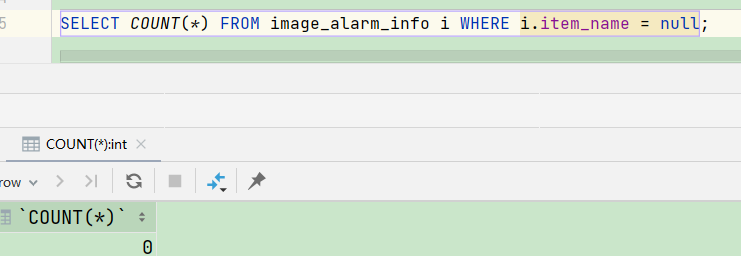
MySQL 中 is null 和 =null 的区别
如果 set ANSI_NULLS为 ON 时,表示SQL语句遵循SQL-92标准;如果 set ANSI_NULLS 为 OFF 时,表示不遵从 SQL-92 标准。但SQL-92 标准要求对null的 = 或不等于 (!= ,) 比较取值都为 false,也就是 =null 或者 null,返回的都是false。null 在MySQL中不代表任何值,通过运算符是得不到任何结果的,因此只能用 is null(默认情况)MySQL 中 null 不代表任务实际的值,类似于一个未知数。

CSS局限属性contain:优化渲染性能的利器
在网页开发中,优化渲染性能是一个重要的目标。CSS局限属性contain是一个强大的工具,可以帮助我们提高网页的渲染性能。本文将介绍contain属性的基本概念、用法和优势,以及如何使用它来优化网页的渲染过程。

配置nginx+keepalived高可用代理数据库ip端口
需求:配置nginx+keepalived高可用反向代理数据库ip端口(数据库服务器无法增加新SCAN IP或者需要隐藏数据库IP的情况下适用)本机ip为:192.168.20.10和192.168.20.11。2.任意节点关机或重启系统,浮动ip也会自动漂移到另外节点。1.任意节点停nginx:浮动ip会自动漂移到另外节点。安装依赖包和nginx和keepalived。浮动IP为:192.168.20.20。配置keepalived.conf。两台centos7.9。
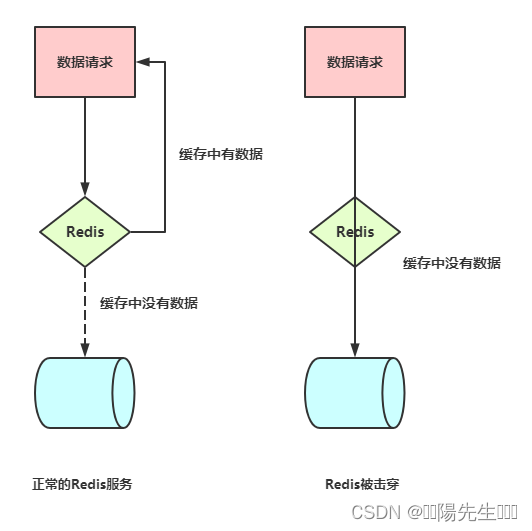
Redis 击穿、穿透、雪崩产生原因解决思路
也就是在设定的时间里数据没有取出来,但是锁由过期了,常见的思路是,锁过期时间值递增,但是想想不靠谱,因为第一个请求可能超时,如果后面的也超时呢,接连多次超时之后,锁过期时间值势必特别大了,这样做弊端太多。雪崩,和击穿类似,不同的是击穿是一个热点Key某时刻失效,而雪崩是大量的热点Key在一瞬间失效,网络上很多博客都在强调解决雪崩的策略是随机过期时间,这个非常不准确,举个例子,银行做活动,之前这个利息系数为2%,过了零点系数改为3%,这种情况能将用户的对应的key改为随机过期吗?如果用的过去的数据叫脏数据。
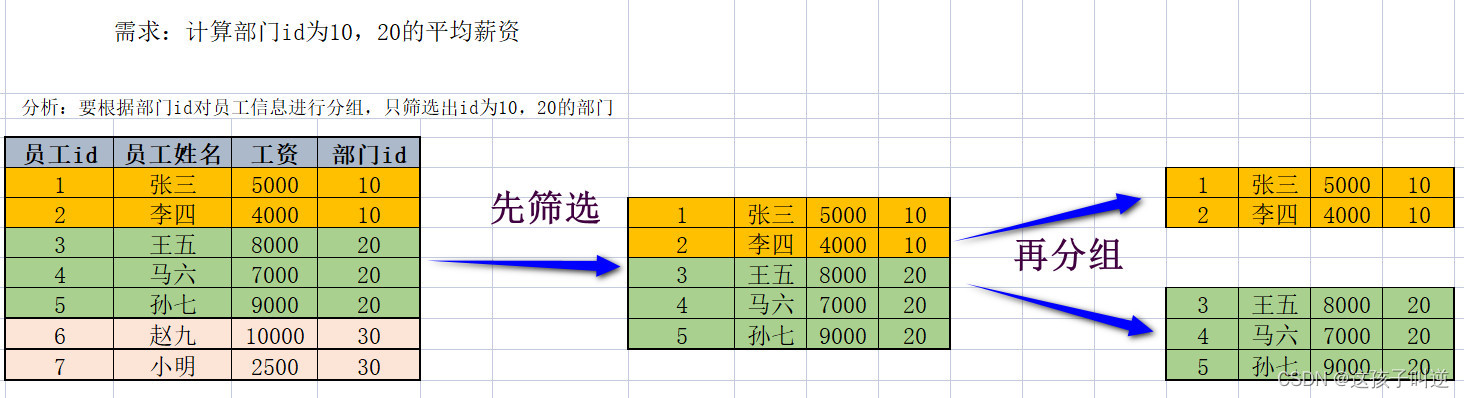
MySQL数据库查询语句之组函数,子查询语句
当一个SQL的执行需要借助另一个SQL的执行结果时,则需要进行SQL嵌套,该语法结构称之为子查询。先筛选出符合要求的数据,再对符合要求的数据进行分组时,分组的工作量会被减少,效率更高。先确定从哪张表进行操作-->对表中数据进行分组-->基于分组结果进行查询操作。执行顺序:优先执行小括号内的子SQL,根据子SQL的执行结果再执行外层SQL。执行顺序:from-->where-->group by-->select。执行顺序:from-->group by-->select。
鸿蒙harmony--数据库sqlite详解
今天是1月20号星期六,早安,岁末大寒至,静后春归来。愿他乡故人,漂泊有归宿,前程有奔赴,愿人间不寒,温暖常伴,诸事顺利,喜乐长安。
Redis的key过期策略是怎么实现的
这是一道经典的Redis面试题,一个Redis中可能存在很多很多的key,这些key中可能有很大一部分都有过期时间,此时Redis服务器咋知道哪些key已经过期,哪些还没过期呢?如果直接遍历所有的key,这显然是行不通的,效率非常低!!Redis整体的策略是定期删除和惰性删除相结合。举个栗子:假如我去小卖铺买东西,付款的时候,发现东西过期了。就告知老板,于是老板下架此产品。消费者发现过期了,才去下架,这就叫。小卖铺老板主动定期抽取一部分商品,进行筛查,这就叫定期删除。
雪花算法生成ID、UUID生成ID和MySql自增ID优缺点分析
综上所述,UUID适用于分布式系统和需要保密的场景,雪花ID适用于分布式系统和高并发环境,MySQL自增ID适用于单机系统和高效查询的场景。根据具体的业务需求和系统架构,选择合适的主键类型。通过本文的介绍和对比,希望读者能够更好地理解在MySQL中不推荐使用UUID或者雪花ID作为主键的原因,并能够根据实际情况做出明智的选择。在MySQL中,使用自增整数作为主键是一种常见的做法,因为它具有较小的存储空间、高效的索引和自动增长的特性。然而,具体选择何种主键类型还是要根据具体的业务需求和数据特点来决定。
【小白专用】C# 连接 MySQL 数据库
C# 连接 MySQL 数据库
如何用pthon连接mysql和mongodb数据库【极简版】
发现宝藏 前言 1. 连接mysql 1.1 安装 PyMySQL 1.2 导入 PyMySQL 1.3 建立连接 1.4 创建游标对象 1.5 执行查询 1.6 关闭连接 1.7 完整示例 2. 连接mongodb 2.1 安装 PyMongo 2.2 导入 PyMongo 2.3 建立连接 2.4
Springboot支付宝沙箱支付---完整详细步骤
两种方式进行配置。这里我采取的是默认方式: 开发者如需使用系统默认密钥/证书,可在开发信息中选择系统默认密钥。注意:使用API在线调试工具调试OpenAPI必须使用系统默认密钥。
Linux安装MongoDB教程
将解压后的 mongodb-linux-x86_64-rhel70-4.2.23 中的所有文件全部移动到 /usr/local/mongodb 中 :注意/*是所有子文件。也可以不用设置环境变量进行启动,但是不设置环境变量启动的话要每次启动写很多启动参数,比较麻烦,所以做好配置环境变量。在 mongodb 下创建 data 和 logs 目录,以及日志文件mongodb.log。在 /usr/local 目录中创建 mongodb 文件夹。启动 MongoDB(-conf 使用配置文件方式启动)
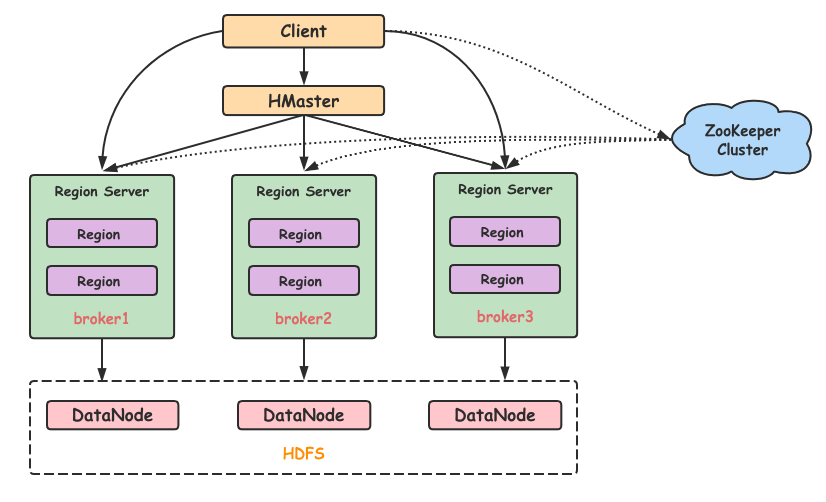
什么是HBase?终于有人讲明白了
在 HBase 表中,一条数据拥有一个全局唯一的键(RowKey)和任意数量的列(Column),一列或多列组成一个列族(Column Family),同一个列族中列的数据在物理上都存储在同一个 HFile 中,这样基于列存储的数据结构有利于数据缓存和查询。HBase Client 为用户提供了访问 HBase 的接口,可以通过元数据表来定位到目标数据的 RegionServer,另外 HBase Client 还维护了对应的 cache 来加速 Hbase 的访问,比如缓存元数据的信息。
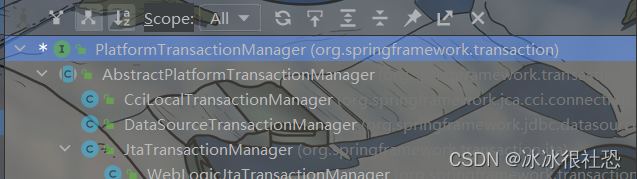
Spring中事务控制的API介绍(PlatformTransactionManager和TransactionDefinition)
事务传播行为(propagation behavior)指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行。例如:methodA事务方法调用methodB事务方法时,methodB是继续在调用者methodA的事务中运行呢,还是为自己开启一个新事务运行,这就是由methodB的事务传播行为决定的。属性,同时,Spring 还为我们提供了一个默认的实现类:DefaultTransactionDefinition,该类适用于大多数情况。作用:是一个事务管理器,负责开启、提交或回滚事务。
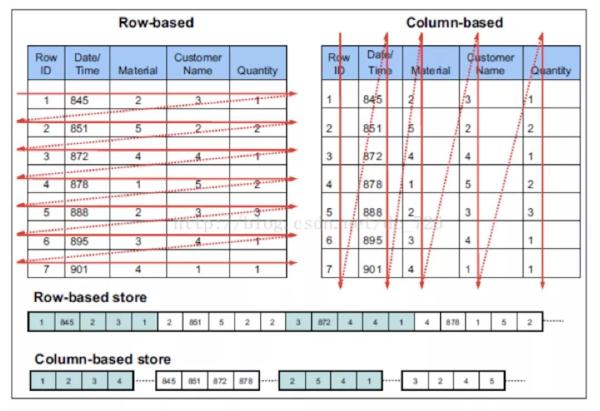
ClickHouse 与mysql等关系型数据库对比
先用一张图帮助理解两者的本质上的区。

Redis 除了用作缓存还能干吗?
Redis 是一种内存键值数据库。它支持多种数据结构,如 String, Hash, List, Set 和 SortedSet。
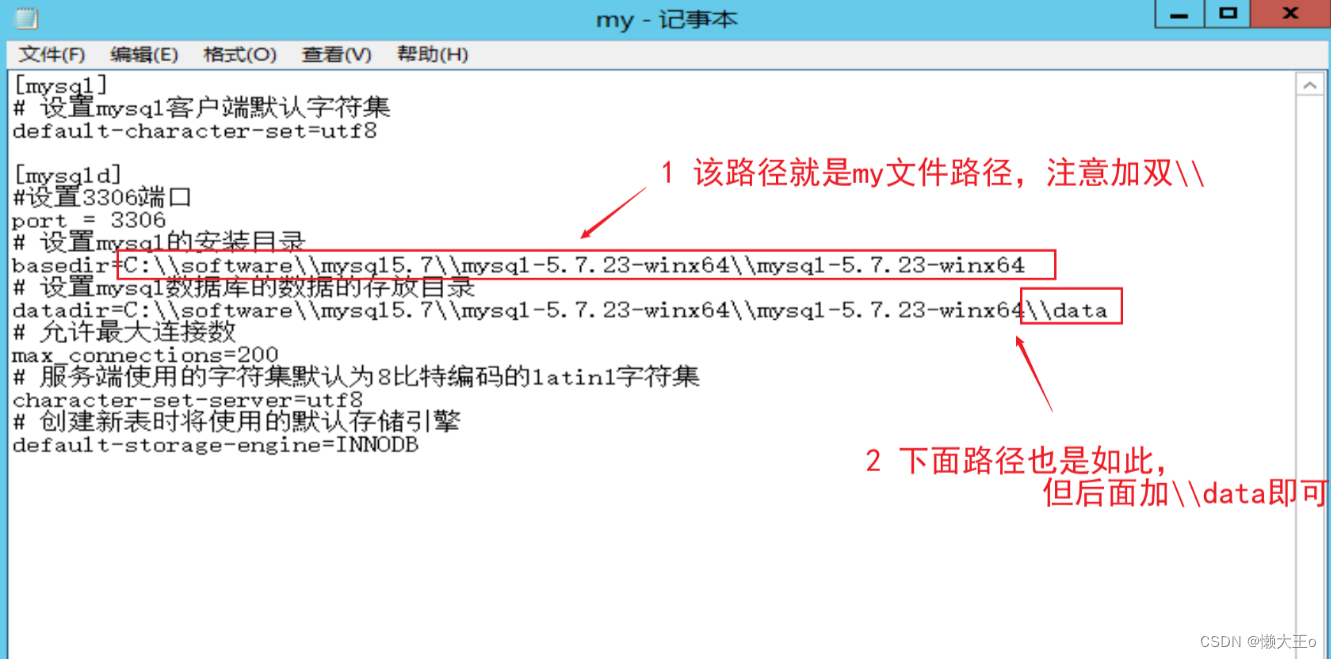
Windows安装MySQL及网络配置
向日葵软件是一种远程控制软件,可以让用户在不同设备之间进行远程桌面访问和文件传输。用户可以通过向日葵软件,在任何具有互联网连接的设备上远程控制其他设备,包括计算机、智能手机和平板电脑。用户只需安装向日葵软件,并使用登录凭据连接到目标设备,就可以实时控制目标设备上的屏幕、键盘和鼠标。向日葵软件还提供了一些辅助功能,如文件传输、远程打印和远程会议等。这使得向日葵软件成为一个方便实用的远程协助工具,适用于个人用户、技术支持人员和企业用户等各种场景。
Web数据库基本知识,SQL基本语法
SQL(Structured Query Language)是一种用于管理和操作关系型数据库管理系统(RDBMS)的特定领域语言。它是一种标准化的语言,用于定义和操作关系型数据库中的数据。SQL允许用户执行诸如查询数据、插入新数据、更新现有数据和删除数据等操作。分为四种DDL:数据库定义语言(define)DML:数据库操作管理语言(manage)DQL:数据库查询语言(query)DCL:数据库控制语言(control)
分库分表解决方案-ShardingSphere-JDBC
ShardingSphere-JDBC 是一个工作在客户端的,定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。

深入理解Mysql事务隔离级别与锁机制
我们的数据库一般都会并发执行多个事务,多个事务可能会并发的对相同的一批数据进行增删改查操作,可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。这些问题的本质都是数据库的多事务并发问题,为了解决多事务并发问题,数据库设计了事务隔离机制、锁机制、MVCC多版本并发控制隔离机制,用一整套机制来解决多事务并发问题。接下来,我们会深入讲解这些机制,让大家彻底理解数据库内部的执行原理。

在云计算环境中,如何利用 AI 改进云计算系统和数据库系统性能
2023年我想大家讨论最多,热度最大的技术领域就是 AIGC 了,AI绘画的兴起,ChatGPT的火爆,在微软背后推手的 OpenAI 大战 Google几回合后,国内各种的大语言模型产品也随之各家百花齐放,什么文心一言、通义千问、科大讯飞的星火以及华为的盘古等等,一下子国内也涌现出几十种人工智能的大语言模型产品。ChatGPT 爆火之后,你是否有冷静的思考过 AIGC 的兴起对我们有哪些机遇与挑战?我们如何将AI 应用到我们现有的工作学习中?_aigc k8s
thinkphp操作mongo数据的三种方法
'hostname' => '10.10.10.10', // MongoDB服务器地址。'hostport' => 2017, // MongoDB服务器端口。'database' => 'chatname', // 数据库名称。后面接着就可以任意使用Connection各类方法。后面接着就可以任意使用Collection各类方法。使用MongoDB PHP驱动程序,方法三。后面接着就可以任意使用db下的增删改查。使用tp中的db类,方法二。使用tp中的扩展,方法一。
获得JD商品评论 API 如何实现实时数据获取
随着互联网的快速发展,电商平台如雨后春笋般涌现,其中京东(JD)作为中国最大的自营式电商平台之一,拥有庞大的用户群体和丰富的商品资源。为了更好地了解用户对商品的反馈,京东开放了商品评论的API接口,允许开发者实时获取商品评论数据。本文将介绍如何通过JD商品评论API实现实时数据获取,并给出相应的代码示例。JD商品评论API提供了一系列的接口,允许开发者根据需要获取不同维度的评论数据。通过该API,开发者可以获取到商品的详细评论信息、评论的统计数据以及用户的评论行为数据等。