Caffe基础介绍
Caffe的全称应该是Convolutional Architecture for Fast Feature Embedding,它是一个清晰、高效的深度学习框架,它是开源的,核心语言是C++,它支持命令行、Python和Matlab接口,它既可以在CPU上运行也可以在GPU上运行。它的license是BSD 2-Clause。
Deep Learning比较流行的一个原因,主要是因为它能够自主地从数据上学到有用的feature。特别是对于一些不知道如何设计feature的场合,比如说图像和speech。
Caffe的设计:基本上,Caffe follow了神经网络的一个简单假设----所有的计算都是以layer的形式表示的,layer做的事情就是take一些数据,然后输出一些计算以后的结果,比如说卷积,就是输入一个图像,然后和这一层的参数(filter)做卷积,然后输出卷积的结果。每一个layer需要做两个计算:forward是从输入计算输出,然后backward是从上面给的gradient来计算相对于输入的gradient,只要这两个函数实现了以后,我们就可以把很多层连接成一个网络,这个网络做的事情就是输入我们的数据(图像或者语音或者whatever),然后来计算我们需要的输出(比如说识别的label),在training的时候,我们可以根据已有的label来计算loss和gradient,然后用gradient来update网络的参数,这个就是Caffe的一个基本流程。
基本上,最简单地用Caffe上手的方法就是先把数据写成Caffe的格式,然后设计一个网络,然后用Caffe提供的solver来做优化看效果如何,如果你的数据是图像的话,可以从现有的网络,比如说alexnet或者googlenet开始,然后做fine tuning,如果你的数据稍有不同,比如说是直接的float vector,你可能需要做一些custom的configuration,Caffe的logistic regression example兴许会很有帮助。
Fine tune方法:fine tuning的想法就是说,在imagenet那么大的数据集上train好一个很牛的网络了,那别的task上肯定也不错,所以我们可以把pretrain的网络拿过来,然后只重新train最后几层,重新train的意思是说,比如我以前需要classify imagenet的一千类,现在我只想识别是狗还是猫,或者是不是车牌,于是我就可以把最后一层softmax从一个4096*1000的分类器变成一个4096*2的分类器,这个strategy在应用中非常好使,所以我们经常会先在imagenet上pretrain一个网络,因为我们知道imagenet上training的大概过程会怎么样。
Caffe可以应用在视觉、语音识别、机器人、神经科学和天文学。
Caffe提供了一个完整的工具包,用来训练、测试、微调和部署模型。
Caffe的亮点:
(1)、模块化:Caffe从一开始就设计得尽可能模块化,允许对新数据格式、网络层和损失函数进行扩展。
(2)、表示和实现分离:Caffe的模型(model)定义是用Protocol Buffer语言写进配置文件的。以任意有向无环图的形式,Caffe支持网络架构。Caffe会根据网络的需要来正确占用内存。通过一个函数调用,实现CPU和GPU之间的切换。
(3)、测试覆盖:在Caffe中,每一个单一的模块都对应一个测试。
(4)、Python和Matlab接口:同时提供Python和Matlab接口。
(5)、预训练参考模型:针对视觉项目,Caffe提供了一些参考模型,这些模型仅应用在学术和非商业领域,它们的license不是BSD。
Caffe架构:
(1)、数据存储:Caffe通过”blobs”即以4维数组的方式存储和传递数据。Blobs提供了一个统一的内存接口,用于批量图像(或其它数据)的操作,参数或参数更新。Models是以Google Protocol Buffers的方式存储在磁盘上。大型数据存储在LevelDB数据库中。
(2)、层:一个Caffe层(Layer)是一个神经网络层的本质,它采用一个或多个blobs作为输入,并产生一个或多个blobs作为输出。网络作为一个整体的操作,层有两个关键职责:前向传播,需要输入并产生输出;反向传播,取梯度作为输出,通过参数和输入计算梯度。Caffe提供了一套完整的层类型。
(3)、网络和运行方式:Caffe保留所有的有向无环层图,确保正确的进行前向传播和反向传播。Caffe模型是终端到终端的机器学习系统。一个典型的网络开始于数据层,结束于loss层。通过一个单一的开关,使其网络运行在CPU或GPU上。在CPU或GPU上,层会产生相同的结果。
(4)、训练一个网络:Caffe训练一个模型(Model)靠快速、标准的随机梯度下降算法。
在Caffe中,微调(Fine tuning),是一个标准的方法,它适应于存在的模型、新的架构或数据。对于新任务,Caffe 微调旧的模型权重并按照需要初始化新的权重。
Blobs,Layers,and Nets:深度网络的组成模式表示为数据块工作的内部连接层的集合。以它自己的model模式,Caffe定义了层层(layer-by-layer)网络。Caffe网络定义了从低端到顶层整个model,从输入数据到loss层。随着数据通过网络的前向传播和反向传播,Caffe存储、通信、信息操作作为Blobs。Blob是标准阵列和统一内存接口框架。Blob用来存储数据、参数以及loss。随之而来的layer作为model和计算的基础,它是网络的基本单元。net作为layer的连接和集合,网络的搭建。blob详细描述了layer与layer或net是怎样进行信息存储和通信的。Solver是Net的求解。
Blob 存储和传输:一个blob是对要处理的实际数据的封装,它通过Caffe传递。在CPU和GPU之间,blob也提供同步能力。在数学上,blob是存储连续的N维数组阵列。
Caffe通过blobs存储和传输数据。blobs提供统一的内存接口保存数据,例如,批量图像,model参数,导数的优化。
Blobs隐藏了计算和混合CPU/GPU的操作根据需要从主机CPU到设备GPU进行同步的开销。主机和设备的内存是按需分配。
对于批量图像数据,blob常规容量是图像数N*通道数K*图像高H*图像宽W。在布局上,Blob存储以行为主,因此最后/最右边的维度改变最快。例如,在一个4D blob中,索引(n, k, h, w)的值物理位置索引是((n * K + k) * H + h) * W + w。对于非图像应用,用blobs也是有效的,如用2D blobs。
参数blob尺寸根据当前层的类型和配置而变化。
一个blob存储两块内存,data和diff,前者是前向传播的正常数据,后者是通过网络计算的梯度。
一个blob使用SyncedMem类同步CPU和GPU之间的值,为了隐藏同步的详细信息和尽量最小的数据传输。
Layer计算和连接:Layer是模型(model)的本质和计算的基本单元。Layer卷积滤波、pool、取内积、应用非线性、sigmoid和其它元素转换、归一化、载入数据,计算losses.
每一个layer类型定义了三个至关重要的计算:设置、前向和反向。(1)、设置:初始化这个layer及在model初始化时连接一次;(2)、前向:从底部对于给定的输入数据计算输出并传送到顶端;(3)、反向:对于给定的梯度,顶端输出计算这个梯度到输入并传送到低端。
有两个前向(forward)和反向(backward)函数执行,一个用于CPU,一个用于GPU。
Caffe layer的定义由两部分组成,层属性和层参数。
每个layer有输入一些’bottom’blobs,输出一些’top’ blobs.
Net定义和操作:net由组成和分化共同定义了一个函数和它的梯度。每一层输出计算函数来完成给定的任务,每一层反向从学习任务中通过loss计算梯度.Caffe model是终端到终端的机器学习引擎。
Net是layers组成的有向无环图(DAG)。一个典型的net开始于数据层,此layer从磁盘加载数据,终止于loss层,此layer计算目标任务,如分类和重建。
Model初始化通过Net::Init()进行处理。初始化主要做了两件事:通过创建blobs和layers来构建整个DAG,调用layers的SetUp()函数。它也做了一系列的其它bookkeeping(簿记)的事情,比如验证整个网络架构的正确性。
Model格式:The models are defined in plaintext protocol buffer schema(prototxt) while the learned models are serialized as binary protocol buffer(binaryproto) .caffemodel files. The model format is defined by the protobufschema in caffe.proto.
Forward and Backward:Forward inference, Backward learning.
Solver优化一个model通过首先调用forward得到输出和loss,然后调用backward生成model的梯度,接着合并梯度到权值(weight)更新尽量减少loss.Solver, Net和Layer之间的分工,使Caffe保持模块化和开放式发展。
Loss:在Caffe中,作为大多数机器学习,学习(learning)是通过loss函数(error, cost, or objective函数)来驱动。一个loss函数指定了学习的目标通过映射参数设置(例如,当前的网络权值)到一个标量值。因此,学习的目标是找到最小化loss函数权值的设置。
在Caffe中,loss是由网络的forward计算。每一个layer采用一组输入blobs(bottom,表示输入),并产生一组输出blobs(top,表示输出)。一些layer的输出可能会用在loss函数中。对于分类任务,一个典型的loss函数选择是SoftmaxWithLoss函数。
Loss weights:net通过许多个layers产生一个loss,loss weights能被用于指定它们的相对重要性。
按照惯例,带有”loss”后缀的Caffe layer类型应用于loss函数,但其它layers是被假定为纯碎用于中间计算。然而,任一个layer都能被用于loss,通过添加一个”loss_weight”字段到一个layer定义。
在Caffe中,最后的loss是被计算通过所有的weighted loss加和通过网络。
Solver:Solver通过协调网络的前向推理和后向梯度形成参数更新试图改善loss达到model优化。Learning的职责是被划分为Solver监督优化和产生参数更新,Net产生loss和梯度。
Caffe solver方法:随机梯度下降(Stochastic Gradient Descent, type:”SGD”);AdaDelta(type:”AdaDelta”);自适应梯度(Adaptive Gradient,type:”AdaGrad”);Adam(type:”Adam”);Nesterov’s Accelerated Gradient(type:”Nesterov”);RMSprop(type:”RMSProp”).
Solver作用:Solver是Net的求解.(1)、优化bookkeeping、创建learning训练网络、对网络进行评估;(2)、调用forward/backward迭代优化和更新参数;(3)、定期评估测试网络;(4)、整个优化快照model和solver状态。
Solver的每一次迭代执行:(1)、调用网络forward计算输出和loss;(2)、调用网络backward计算梯度;(3)、按照solver方法,采用渐变进行参数更新;(4)、按照学习率、历史和方法更新solver状态。通过以上执行来获得所有的weights从初始化到learned model.
像Caffe models,Caffe solvers也可以在CPU或GPU模式下运行。
solver方法处理最小化loss的总体优化问题。
实际的weight更新是由solver产生,然后应用到net参数。
Layer Catalogue:为了创建一个Caffe model,你需要定义model架构在一个prototxt文件(protocol buffer definition file)中。Caffe layers和它们的参数是被定义在protocol buffer definitions文件中,对于Caffe工程是caffe.proto.
Vision Layers:Vision layers通常以图像作为输入,并产生其它图像作为输出:
(1)、Convolution(Convolution):卷积层通过将输入图像与一系列可学习的滤波进行卷积,在输出图像中,每一个产生一个特征图;(2)、Pooling(Pooling);(3)、Local Response Normalization(LRN);(4)、im2col。
Loss Layers:Loss驱动学习通过比较一个输出对应一个目标和分配成本到最小化。Loss本身是被计算通过前向传输,梯度到loss是被计算通过后向传输:
(1)、Softmax(SoftmaxWithLoss);(2)、Sum-of-Squares/Euclidean(EuclideanLoss);(3)、Hinge/Margin(HingeLoss);(4)、SigmoidCross-Entropy(SigmoidCrossEntropyLoss);(5)、Infogain(InfogainLoss);(6)、Accuracy andTop-k。
Activation/NeuronLayers:一般Activation/Neuron Layers是逐元素操作,输入一个bottom blob,产生一个同样大小的top blob:
(1)、ReLU/Rectified-Linearand Leaky-ReLU(ReLU);(2)、Sigmoid(Sigmoid);(3)、TanH/Hyperbolic Tangent(TanH);(4)、Absolute Value(AbsVal);(5)、Power(Power);(6)、BNLL(BNLL)。
Data Layers:数据输入Caffe通过Data Layers,它们在网络的低端。数据可以来自于:高效的数据库(LevelDB或LMDB)、直接来自内存、在不注重效率的情况下,也可以来自文件,磁盘上HDF5数据格式或普通的图像格式:
(1)、Database(Data);(2)、In-Memory(MemoryData);(3)、HDF5Input(HDF5Data);(4)、HDF5 Output(HDF5Output);(5)、Images(ImageData);(6)、Windows(WindowData);(7)、Dummy(DummyData).
Common Layers:(1)、InnerProduct(InnerProduct);(2)、Splitting(Split);(3)、Flattening(Flatten);(4)、Reshape(Reshape);(5)、Concatenation(Concat);(6)、Slicing(Slice);(7)、Elementwise Operations(Eltwise);(8)、Argmax(ArgMax);(9)、Softmax(Softmax);(10)、Mean-VarianceNormalization(MVN)。
Data:在Caffe中,数据存储在Blobs中。Data Layers加载输入和保存输出通过转换从blob到其它格式。普通的转换像mean-subtraction和feature-scaling是通过配置data layer来完成。新的输入类型需要开发一个新的data layer来支持。
以上内容来自于Caffe官方网站的翻译和一些网络blog的整理,主要参考:
1. 《Caffe: Convolutional Architecture for Fast Feature Embedding》
2. http://caffe.berkeleyvision.org/tutorial/
3. http://suanfazu.com/t/caffe/281/3
4. http://mp.weixin.qq.com/s?__biz=MzAxNTE2MjcxNw==&mid=206508839&idx=1&sn=4dea40d781716da2f56d93fe23c158ab#rd
5. https://yufeigan.github.io/
关于Caffe在Windows上的配置可以参考: http://blog.csdn.net/fengbingchun/article/details/50987353
GitHub: https://github.com/fengbingchun/Caffe_Test
相关文章:

飞桨博士会第三期来啦!中国深度学习技术俱乐部诚邀您加入
飞桨博士会是由百度开源深度学习平台飞桨(PaddlePaddle)发起的中国深度学习技术俱乐部,旨在打造深度学习核心开发者交流圈,助力会员拓展行业高端人脉、交流前沿技术。俱乐部为会员制,成员皆为博士生导师或博士…

canvas 拼图
效果 代码 <!DOCTYPE html> <html lang"zh_CN"> <head><meta charset"UTF-8"><title>拼图</title><script src"https://code.jquery.com/jquery-3.3.1.js"></script> </head> <body&g…

性能优化之Java(Android)代码优化
最新最准确内容建议直接访问原文:性能优化之Java(Android)代码优化 本文为Android性能优化的第三篇——Java(Android)代码优化。主要介绍Java代码中性能优化方式及网络优化,包括缓存、异步、延迟、数据存储、算法、JNI、逻辑等优化方式。(时间仓促&#…

1小时上手MaskRCNN·Keras开源实战 | 深度应用
作者 | 小宋是呢来源 | CSDN博客0. 前言介绍开源地址:https://github.com/matterport/Mask_RCNN个人主页:http://www.yansongsong.cn/MaskRCNN 是何恺明基于以往的 faster rcnn 架构提出的新的卷积网络,一举完成了 object instance segmentat…

MNIST数据库介绍及转换
MNIST数据库介绍:MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集。它是NIST数据库的一个子集。MNIST数据库官方网址为:http://yann.lecun.com/exdb/mnist/ ,也可以在windows下直接下载,train-im…
PostgreSQL学习笔记(1)
安装psql brew install postgresql 启动服务 brew services start postgresql 使用psql进入控制台,报错: psql: FATAL: database "<user>" does not exist 看来是没有给我的当前用户创建数据库,使用下面命令进入名为templat…

怎样使一个Android应用不被杀死?(整理)
2019独角兽企业重金招聘Python工程师标准>>> 方法 : 对于一个service,可以首先把它设为在前台运行: public void MyService.onCreate() { super.onCreate(); Notification notification new Notification(android.R.drawable.my_…

Ubuntu 14.04 64位机上用Caffe+MNIST训练Lenet网络操作步骤
1. 将终端定位到Caffe根目录; 2. 下载MNIST数据库并解压缩:$ ./data/mnist/get_mnist.sh 3. 将其转换成Lmdb数据库格式:$ ./examples/mnist/create_mnist.sh 执行完此shell脚本后,会在./examples/mnist下增加两个新…
IJCAI 2019:中国团队录取论文超三成,北大、南大榜上有名
作者 | 神经小姐姐来源 | HyperAI超神经( ID: HyperAI )【导读】AI 顶会 IJCAI 2019 已于 8 月 16 日圆满落幕。在连续 7 天的技术盛会中,与会者在工作坊了解了 AI 技术在各个领域的应用场景,聆听了 AI 界前辈的主题演讲,还有机会…
适合小小白的完整建设流程
时常有中小企业建站的客户问到我要自己建网站,应该怎么开始?建站有一定的技术门槛,首先要明白建站要做的哪些事情,里面有哪些坑,把流程弄清楚了才能避免入坑,半途而废!下面总结了建站的流程还有…
ios项目文件结构 目录的整理
2019独角兽企业重金招聘Python工程师标准>>> /<ProjectName>/Shared/Application # App delegate and related files/Controllers # Base view controllers/Models # Models, Core Data schema etc/Views # Shared views/Libr…

重磅!全球首个可视化联邦学习产品与联邦pipeline生产服务上线
【导读】作为全球首个联邦学习工业级技术框架,FATE支持联邦学习架构体系与各种机器学习算法的安全计算,实现了基于同态加密和多方计算(MPC)的安全计算协议,能够帮助多个组织机构在符合数据安全和政府法规前提下&#x…
SpringBoot之集成swagger2
maven配置 <dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.5.0</version> </dependency> <dependency><groupId>io.springfox</groupId><artifact…
Windows Caffe中MNIST数据格式转换实现
Caffe源码中src/caffe/caffe/examples/mnist/convert_mnist_data.cpp提供的实现代码并不能直接在Windows下运行,这里在源码的基础上进行了改写,使其可以直接在Windows 64位上直接运行,改写代码如下:#include "stdafx.h"…

关于less在DW中高亮显示问题
首先, 找到DW 安装目录。 Adobe Dreamweaver CS5.5\configuration\DocumentTypes 中的,MMDocumentTypes.xml 这个文件,然后用记事本打开,查找CSS 把 CSS 后边加上,less 然后到。C:\Users\Administrator\AppData\Roamin…
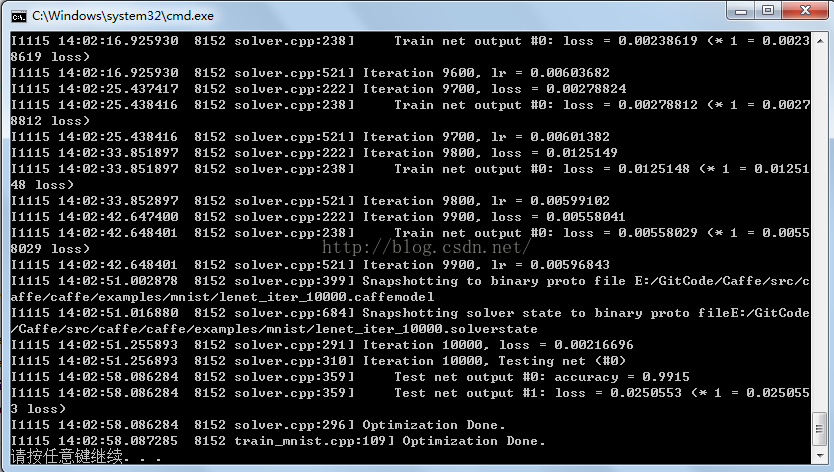
Windows7 64bit VS2013 Caffe train MNIST操作步骤
1. 使用http://blog.csdn.net/fengbingchun/article/details/47905907中生成的Caffe静态库; 2. 使用http://blog.csdn.net/fengbingchun/article/details/49794453中生成的LMDB数据库文件; 3. 新建一个train_mnist控制台工程&#…

NLP机器翻译深度学习实战课程基础 | 深度应用
作者 | 小宋是呢来源 | CSDN博客0.前言深度学习用的有一年多了,最近开始 NLP 自然处理方面的研发。刚好趁着这个机会写一系列 NLP 机器翻译深度学习实战课程。本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:…
个人站点渲染和跳转过滤功能
核心逻辑:在url里加入正则,匹配分类、标签、年月日和其后面的参数,在视图函数接收这些参数,然后进行过滤。 urls.py # 个人站点的跳转 re_path(r^(?P<username>\w)/(?P<condition>tag|category|archive)/(?P<pa…

三步10分钟搞定数据库版本的降迁 (将后台数据库SQL2008R2降为SQL2005版本)
三步10分钟搞定数据库版本的降迁 (将SQL2008R2降为SQL2005版本)转载原文,并注明出处!虽无多少技术含量,毕竟是作者心血原创,希望理解。转自 http://blog.csdn.net/claro/article/details/6449824前思后想仍…

jdbc链接数据库
JDBC简介 JDBC全称为:Java Data Base Connectivity (java数据库连接),可以为多种数据库提供填统一的访问。JDBC是sun开发的一套数据库访问编程接口,是一种SQL级的API。它是由java语言编写完成,所以具有很好的跨平台特性…
Google Protocol Buffers介绍
Google Protocol Buffers(简称Protobuf),是Google的一个开源项目,它是一种结构化数据存储格式,是Google公司内部的混合语言数据标准,是一个用来序列化(将对象的状态信息转换为可以存储或传输的形式的过程)结…

打造 AI Beings,和微信合作…第七代微软小冰的成长之路
8月15日, “第七代微软小冰”年度发布会在北京举行。本次发布会上,微软(亚洲)互联网工程院带来了微软小冰在 Dual AI 领域的新进展,全新升级的部分核心技术,最新的人工智能创造成果,以及更多的合作与产品落地。其中&am…

感知机介绍及实现
感知机(perceptron)由Rosenblatt于1957年提出,是神经网络与支持向量机的基础。感知机是最早被设计并被实现的人工神经网络。感知机是一种非常特殊的神经网络,它在人工神经网络的发展史上有着非常重要的地位,尽管它的能力非常有限,…
不甘心只做输入工具,搜狗输入法上线AI助手,提供智能服务
8月19日搜狗输入法上线了新功能——智能汪仔,在输入法中引入了AI助手,这是搜狗输入法继今年5月推出“语音变声功能”后又一个AI落地产品。 有了智能汪仔AI助手的加持后,搜狗输入法能够在不同的聊天场景,提供丰富多样的表达方式从…

可构造样式表 - 通过javascript来生成css的新方式
可构造样式表是一种使用Shadow DOM进行创建和分发可重用样式的新方法。 使用Javascript来创建样式表是可能的。然而,这个过程在历史上一直是使用document.createElement(style)来创建<style>元素,然后通过访问其sheet属性来获得一个基础的CSSStyle…
模板方法模式与策略模式的区别
2019独角兽企业重金招聘Python工程师标准>>> 模板方法模式:在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。 策略模式:定义一个…

简单明了,一文入门视觉SLAM
作者 | 黄浴转载自知乎【导读】SLAM是“Simultaneous Localization And Mapping”的缩写,可译为同步定位与建图。最早,SLAM 主要用在机器人领域,是为了在没有任何先验知识的情况下,根据传感器数据实时构建周围环境地图,…

大主子表关联的性能优化方法
【摘要】主子表是数据库最常见的关联关系之一,最典型的包括合同和合同条款、订单和订单明细、保险保单和保单明细、银行账户和账户流水、电商用户和订单、电信账户和计费清单或流量详单。当主子表的数据量较大时,关联计算的性能将急剧降低,在…
Windows7上配置Python Protobuf 操作步骤
1、 按照http://blog.csdn.net/fengbingchun/article/details/8183468 中步骤,首先安装Python 2.7.10; 2、 按照http://blog.csdn.net/fengbingchun/article/details/47905907 中步骤,配置、编译Protobuf; 3、 将(2)中生成的pr…
鲜为人知的静态、命令式编程语言——Nimrod
Nimrod是一个新型的静态类型、命令式编程语言,支持过程式、函数式、面向对象和泛型编程风格而保持简单和高效。Nimrod从Lisp继承来的一个特殊特性抽象语法树(AST)作为语言规范的一部分,可以用作创建领域特定语言的强大宏系统。它还…