Windows7 64bit VS2013 Caffe train MNIST操作步骤
1. 使用http://blog.csdn.net/fengbingchun/article/details/47905907中生成的Caffe静态库;
2. 使用http://blog.csdn.net/fengbingchun/article/details/49794453中生成的LMDB数据库文件;
3. 新建一个train_mnist控制台工程;
4. 修改源文件中的caffe/examples/mnist/lenet_solver.prototxt文件:
(1)、net: "E:/GitCode/Caffe/src/caffe/caffe/examples/mnist/lenet_train_test.prototxt"
(2)、snapshot_prefix:"E:/GitCode/Caffe/src/caffe/caffe/examples/mnist/lenet"
(3)、solver_mode: CPU
5. 修改源文件中的caffe/examples/mnist/lenet_train_test.prototxt文件,指定LMDB数据库文件存放位置:
(1)、source:"E:/GitCode/Caffe/src/caffe/caffe/data/mnist/lmdb/train"
(2)、source:"E:/GitCode/Caffe/src/caffe/caffe/data/mnist/lmdb/test"
6. train_mnist.cpp文件中内容为(是对caffe/tools/caffe.cpp的修改):
#include "stdafx.h"
#include <iostream>#include <glog/logging.h>
#include <cstring>
#include <map>
#include <string>
#include <vector>#include "caffe/common.hpp"
#include "boost/algorithm/string.hpp"
#include "caffe/caffe.hpp"
#include "caffe/util/io.hpp"
#include "caffe/blob.hpp"
#include "caffe/layer_factory.hpp"
#include "boost/smart_ptr/shared_ptr.hpp"using caffe::Blob;
using caffe::Caffe;
using caffe::Net;
using caffe::Layer;
using caffe::Solver;
using caffe::shared_ptr;
using caffe::string;
using caffe::Timer;
using caffe::vector;
using std::ostringstream;DEFINE_string(solver, "E:/GitCode/Caffe/src/caffe/caffe/examples/mnist/lenet_solver.prototxt","The solver definition protocol buffer text file.");
DEFINE_string(snapshot, "E:/GitCode/Caffe/src/caffe/caffe/examples/mnist/lenet_iter_10000.solverstate","Optional; the snapshot solver state to resume training.");
DEFINE_string(weights, "E:/GitCode/Caffe/src/caffe/caffe/examples/mnist/xxxx.caffemodel","Optional; the pretrained weights to initialize finetuning, ""separated by ','. Cannot be set simultaneously with snapshot.");// A simple registry for caffe commands.
typedef int(*BrewFunction)();
typedef std::map<caffe::string, BrewFunction> BrewMap;
BrewMap g_brew_map;#define RegisterBrewFunction(func) \
namespace { \
class __Registerer_##func { \public: /* NOLINT */ \__Registerer_##func() { \g_brew_map[#func] = &func; \} \
}; \
__Registerer_##func g_registerer_##func; \
}static BrewFunction GetBrewFunction(const caffe::string& name) {if (g_brew_map.count(name)) {return g_brew_map[name];}else {LOG(ERROR) << "Available caffe actions:";for (BrewMap::iterator it = g_brew_map.begin(); it != g_brew_map.end(); ++it) {LOG(ERROR) << "\t" << it->first;}LOG(FATAL) << "Unknown action: " << name;return NULL; // not reachable, just to suppress old compiler warnings.}
}// Load the weights from the specified caffemodel(s) into the train and test nets.
void CopyLayers(caffe::Solver<float>* solver, const std::string& model_list) {std::vector<std::string> model_names;boost::split(model_names, model_list, boost::is_any_of(","));for (int i = 0; i < model_names.size(); ++i) {LOG(INFO) << "Finetuning from " << model_names[i];solver->net()->CopyTrainedLayersFrom(model_names[i]);for (int j = 0; j < solver->test_nets().size(); ++j) {solver->test_nets()[j]->CopyTrainedLayersFrom(model_names[i]);}}
}// Train / Finetune a model.
int train() {CHECK_GT(FLAGS_solver.size(), 0) << "Need a solver definition to train.";//CHECK(!FLAGS_snapshot.size() || !FLAGS_weights.size()) << "Give a snapshot to resume training or weights to finetune but not both.";caffe::SolverParameter solver_param;caffe::ReadProtoFromTextFileOrDie(FLAGS_solver, &solver_param);Caffe::set_mode(Caffe::CPU);shared_ptr<Solver<float> > solver(caffe::GetSolver<float>(solver_param));//if (FLAGS_snapshot.size()) { // resume training// LOG(INFO) << "Resuming from " << FLAGS_snapshot;// solver->Restore(FLAGS_snapshot.c_str());//}//else if (FLAGS_weights.size()) { // finetune// CopyLayers(solver.get(), FLAGS_weights);//}LOG(INFO) << "Starting Optimization";solver->Solve();LOG(INFO) << "Optimization Done.";return 0;
}
RegisterBrewFunction(train);int main(int argc, char* argv[])
{argc = 2;
#ifdef _DEBUG argv[0] = "E:/GitCode/Caffe/lib/dbg/x86_vc12/train_mnist[dbg_x86_vc12].exe";
#else argv[0] = "E:/GitCode/Caffe/lib/rel/x86_vc12/train_mnist[rel_x86_vc12].exe";
#endif argv[1] = "train";// 每个进程中至少要执行1次InitGoogleLogging(),否则不产生日志文件google::InitGoogleLogging(argv[0]);// 设置日志文件保存目录,此目录必须是已经存在的FLAGS_log_dir = "E:\\GitCode\\Caffe";FLAGS_max_log_size = 1024;//MB// Print output to stderr (while still logging).FLAGS_alsologtostderr = 1;// Usage message.gflags::SetUsageMessage("command line brew\n""usage: caffe <command> <args>\n\n""commands:\n"" train train or finetune a model\n");// Run tool or show usage.//caffe::GlobalInit(&argc, &argv);// 解析命令行参数 gflags::ParseCommandLineFlags(&argc, &argv, true);if (argc == 2) {return GetBrewFunction(caffe::string(argv[1]))();}else {gflags::ShowUsageWithFlagsRestrict(argv[0], "tools/caffe");}std::cout << "OK!!!" << std::endl;return 0;
}7. 执行完train_mnist后会生成四个文件:lenet_iter_5000.caffemodel、lenet_iter_5000.solverstate、lenet_iter_10000.caffemodel、lenet_iter_10000.solverstate
8. 运行结果如下图:
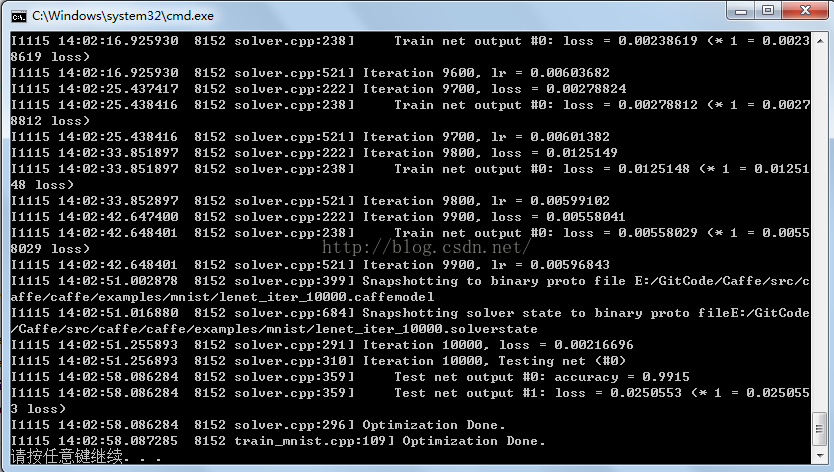
GitHub:https://github.com/fengbingchun/Caffe_Test
相关文章:

NLP机器翻译深度学习实战课程基础 | 深度应用
作者 | 小宋是呢来源 | CSDN博客0.前言深度学习用的有一年多了,最近开始 NLP 自然处理方面的研发。刚好趁着这个机会写一系列 NLP 机器翻译深度学习实战课程。本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:…

个人站点渲染和跳转过滤功能
核心逻辑:在url里加入正则,匹配分类、标签、年月日和其后面的参数,在视图函数接收这些参数,然后进行过滤。 urls.py # 个人站点的跳转 re_path(r^(?P<username>\w)/(?P<condition>tag|category|archive)/(?P<pa…

三步10分钟搞定数据库版本的降迁 (将后台数据库SQL2008R2降为SQL2005版本)
三步10分钟搞定数据库版本的降迁 (将SQL2008R2降为SQL2005版本)转载原文,并注明出处!虽无多少技术含量,毕竟是作者心血原创,希望理解。转自 http://blog.csdn.net/claro/article/details/6449824前思后想仍…

jdbc链接数据库
JDBC简介 JDBC全称为:Java Data Base Connectivity (java数据库连接),可以为多种数据库提供填统一的访问。JDBC是sun开发的一套数据库访问编程接口,是一种SQL级的API。它是由java语言编写完成,所以具有很好的跨平台特性…
Google Protocol Buffers介绍
Google Protocol Buffers(简称Protobuf),是Google的一个开源项目,它是一种结构化数据存储格式,是Google公司内部的混合语言数据标准,是一个用来序列化(将对象的状态信息转换为可以存储或传输的形式的过程)结…

打造 AI Beings,和微信合作…第七代微软小冰的成长之路
8月15日, “第七代微软小冰”年度发布会在北京举行。本次发布会上,微软(亚洲)互联网工程院带来了微软小冰在 Dual AI 领域的新进展,全新升级的部分核心技术,最新的人工智能创造成果,以及更多的合作与产品落地。其中&am…

感知机介绍及实现
感知机(perceptron)由Rosenblatt于1957年提出,是神经网络与支持向量机的基础。感知机是最早被设计并被实现的人工神经网络。感知机是一种非常特殊的神经网络,它在人工神经网络的发展史上有着非常重要的地位,尽管它的能力非常有限,…
不甘心只做输入工具,搜狗输入法上线AI助手,提供智能服务
8月19日搜狗输入法上线了新功能——智能汪仔,在输入法中引入了AI助手,这是搜狗输入法继今年5月推出“语音变声功能”后又一个AI落地产品。 有了智能汪仔AI助手的加持后,搜狗输入法能够在不同的聊天场景,提供丰富多样的表达方式从…

可构造样式表 - 通过javascript来生成css的新方式
可构造样式表是一种使用Shadow DOM进行创建和分发可重用样式的新方法。 使用Javascript来创建样式表是可能的。然而,这个过程在历史上一直是使用document.createElement(style)来创建<style>元素,然后通过访问其sheet属性来获得一个基础的CSSStyle…

模板方法模式与策略模式的区别
2019独角兽企业重金招聘Python工程师标准>>> 模板方法模式:在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。 策略模式:定义一个…

简单明了,一文入门视觉SLAM
作者 | 黄浴转载自知乎【导读】SLAM是“Simultaneous Localization And Mapping”的缩写,可译为同步定位与建图。最早,SLAM 主要用在机器人领域,是为了在没有任何先验知识的情况下,根据传感器数据实时构建周围环境地图,…

大主子表关联的性能优化方法
【摘要】主子表是数据库最常见的关联关系之一,最典型的包括合同和合同条款、订单和订单明细、保险保单和保单明细、银行账户和账户流水、电商用户和订单、电信账户和计费清单或流量详单。当主子表的数据量较大时,关联计算的性能将急剧降低,在…
Windows7上配置Python Protobuf 操作步骤
1、 按照http://blog.csdn.net/fengbingchun/article/details/8183468 中步骤,首先安装Python 2.7.10; 2、 按照http://blog.csdn.net/fengbingchun/article/details/47905907 中步骤,配置、编译Protobuf; 3、 将(2)中生成的pr…
鲜为人知的静态、命令式编程语言——Nimrod
Nimrod是一个新型的静态类型、命令式编程语言,支持过程式、函数式、面向对象和泛型编程风格而保持简单和高效。Nimrod从Lisp继承来的一个特殊特性抽象语法树(AST)作为语言规范的一部分,可以用作创建领域特定语言的强大宏系统。它还…

机器学习进阶-图像形态学操作-腐蚀操作 1.cv2.erode(进行腐蚀操作)
1.cv2.erode(src, kernel, iteration) 参数说明:src表示的是输入图片,kernel表示的是方框的大小,iteration表示迭代的次数 腐蚀操作原理:存在一个kernel,比如(3, 3),在图像中不断的平移,在这个9…
无需成对示例、无监督训练,CycleGAN生成图像简直不要太简单
作者 | Jason Brownlee译者 | Freesia,Rachel编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】图像到图像的转换技术一般需要大量的成对数据,然而要收集这些数据异常耗时耗力。因此本文主要介绍了无需成对示例便能实现图…
Git使用常见问题解决方法汇总
1. 在Ubuntu下使用$ git clone时出现server certificate verification failed. CAfile:/etc/ssl/certs/ca-certificates.crt CRLfile: none 解决方法:在执行$ git clone 之前,在终端输入: export GIT_SSL_NO_VERIFY1 2. 在Windows上更新了…

服务器监控常用命令
在网站性能优化中,我们经常要检查服务器的各种指标,以便快速找到害群之马。大多情况下,我们会使用cacti、nagois或者zabbix之类的监控软件,但是这类软件安装起来比较麻烦,在一个小型服务器,我们想尽快找到问…
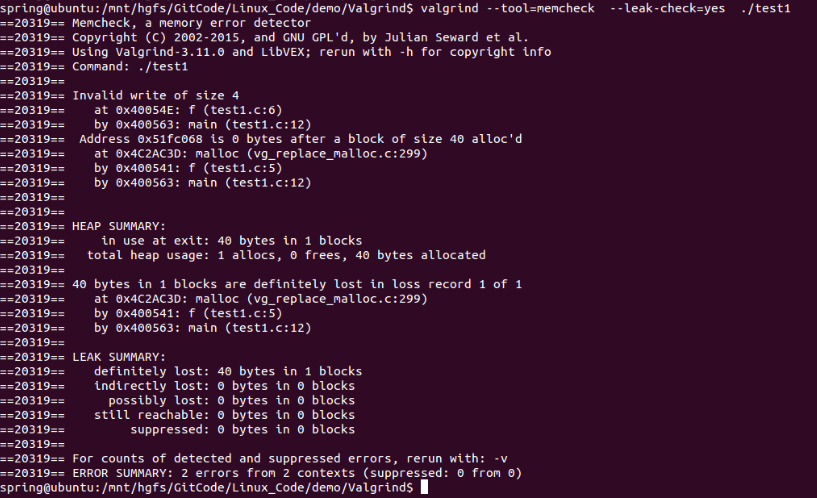
Ubuntu下内存泄露检测工具Valgrind的使用
在VS中可以用VLD检测是否有内存泄露,可以参考http://blog.csdn.net/fengbingchun/article/details/44195959,下面介绍下Ubuntu中内存泄露检测工具Valgrind的使用。Valgrind目前最新版本是3.11.0, 可以从http://www.valgrind.org/ 通过下载源码…
数据为王的时代,如何用图谱挖掘商业数据背后的宝藏?
这是一个商业时代,一个数据为王的时代,也是一个 AI 迎来黄金发展期的时代。据史料记载,商业在商朝已初具规模。斗转星移,时光流转,到 2019 年,商业形式已发生翻天覆地的变化,但是商业的本质——…
旋转卡壳——模板(对踵点)
这东西学了我大概两天吧。。其实不应该学这么久的,但是这两天有点小困,然后学习时间被削了很多\(QwQ\) 说几个坑点。 - 对于题目不保证有凸包的情况,要选用左下角的点,而非单纯的最下边的点构造凸包。 - 对于凸包中只有\(1/2\)个点…
SNMP 协议 OID的使用
为什么80%的码农都做不了架构师?>>> SNMP 协议 OID的使用 SNMP(Simple Network Management Protocol简单网络管理)协议 是现在网络管理系统(NMS)监控网络设备状态的协议,是现在网管事实上的标准…
颜色空间YUV简介
YUV概念:YUV是被欧洲电视系统所采用的一种颜色编码方法(属于PAL,Phase Alternation Line),是PAL和SECAM模拟彩色电视制式采用的颜色空间。其中的Y、U、V几个字母不是英文单词的组合词,Y代表亮度,其实Y就是图像的灰度值…

基于RNN的NLP机器翻译深度学习课程 | 附实战代码
作者 | 小宋是呢来源 | CSDN博客深度学习用的有一年多了,最近开始NLP自然处理方面的研发。刚好趁着这个机会写一系列 NLP 机器翻译深度学习实战课程。本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:…
trash-cli设置Linux 回收站
trash-cli 设置 Linux 回收站 trash-cli是一个使用 python 开发的软件包,包含 trash-put、restore-trash、trash-list、trash-empty、trash-rm等命令,我们可以通过这条命令,将文件移动到回收站,或者还原删除了的文件。 trash-cli的…
磁盘有时也不可靠
实验服务器的磁盘是最近买的,当卖家问我要普通的还是高级的, 我选择了普通,现在追悔莫及。今天的分析更加详细。首先发现每次实验,出错的文件都不一样,所以应该不是临界条件的问题。下表总结了出错的位置,原…
从原理到落地,七大维度详解矩阵分解推荐算法
作者 | gongyouliu编辑丨Zandy来源 | 大数据与人工智能 ( ID: ai-big-data)导语:作者在《协同过滤推荐算法》这篇文章中介绍了 user-based 和 item-based 协同过滤算法,这类协同过滤算法是基于邻域的算法(也称为基于内存的协同过…
libyuv库的使用
libyuv是Google开源的实现各种YUV与RGB之间相互转换、旋转、缩放的库。它是跨平台的,可在Windows、Linux、Mac、Android等操作系统,x86、x64、arm架构上进行编译运行,支持SSE、AVX、NEON等SIMD指令加速。下面说一下libyuv在Windows7VS2013 x6…
封装 vue 组件的过程记录
在我们使用vue的开发过程中总会遇到这样的场景,封装自己的业务组件。 封装页面组件前要考虑几个问题:1、该业务组件的使用场景 2、在什么条件下展示一些什么数据,数据类型是什么样的,及长度颜色等 3、如果是通用的内容,…

Service的基本组成
Service与Activity的最大区别就是一有界面,一个没有界面。 如果某些程序操作很消耗时间,那么可以将这些程序定义在Service之中,这样就可以完成程序的后台运行, 其实Service就是一个没有界面的Activity,执行跨进程访问也…