Google Protocol Buffers介绍
Google Protocol Buffers(简称Protobuf),是Google的一个开源项目,它是一种结构化数据存储格式,是Google公司内部的混合语言数据标准,是一个用来序列化(将对象的状态信息转换为可以存储或传输的形式的过程)结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)的技术,支持多种语言诸如C++、Java以及Python。可以使用该技术来持久化数据(将内存中的数据模型转换为存储模型或者将存储模型转换为内存中的数据模型)或者序列化成网络传输的数据。它是语言无关、平台无关的、扩展性好的用于通讯协议、数据存储的结构化数据序列化方法。相比较一些其它的如XML技术而言,该技术的一个明显特点就是更加节省空间(以二进制流存储)、速度更快也更加灵活。
通常,编写一个Protobuf应用需要三步:
1. 定义消息格式文件,最好以proto作为后缀名:proto文件即消息协议原型定义文件,在该文件中可以通过使用描述性语言来定义程序中需要用到的数据格式。
在Protobuf术语中,结构化数据被称为message。message是消息定义的关键字,等同于C++中的struct/class。在.proto文件中,message可以嵌套message。
在一个.proto文件中,可以用import关键字引入在其它.proto文件中定义的消息,这可以称作import message或者dependency message。import message的用处主要在于提供方便的代码管理机制,可以将一些公用的message定义在一个package中,然后在别的.proto文件中引入该package,进而使用其中的消息定义。
一般情况下,使用Protobuf会先写好.proto文件,再用Protobuf编译器生成目标语言所需要的源代码文件,然后将这些生成的代码和应用程序一起编译。在某些情况下,可能无法预先知道.proto文件,需要动态处理一些未知的.proto文件,这就需要动态编译.proto文件,并使用其中的message。Protobuf提供了google::protobuf::compiler包来完成动态编译的功能。
在定义Protobuf消息时,可以使用和C++代码同样的方式添加注释(“//”)。枚举值之间的分隔符是分号,而不是逗号。可以为枚举值指定任意整型值,而无需总是从0开始定义。可以在同一个.proto文件中定义多个message,这样便可以很容易的实现嵌套消息的定义。
每个字段(field)都有一个修饰符、字段类型和字段标签(Tag,数字1,2,…)组成。
三个修饰符(required/repeated/optional):
(1)、required:初值是必须要提供的,否则字段的值是未初始化的。在序列化和在反序列化(解析,从序列化的表示形式中提取数据,并直接设置对象状态)时对该字段的解析会失败。
(2)、optional:如果未进行初始化,那么一个默认值将赋予该字段,也可以自己指定默认值。
(3)、repeated:该字段可以重复多个,出现0次也是可以的。
一个格式良好的消息一定要含有一个required字段,表示该值是必须要设置的。每个消息中可以包含0个或多个optional类型的字段。repeated表示的字段可以包含0个或多个数据。
如果打算在原有消息协议中添加新的字段,同时还要保证老版本的程序能够正常读取或写入,那么对于新添加的字段必须是optional或repeated。
字段标签:消息中的每一个字段都有一个独一无二的数值类型的Tag,标示了字段在二进制流中存放的位置,这个是必须的,而且序列化与反序列化时相同的字段的标签值必须对应,否则反序列化时会出现意想不到的问题。
在.proto文件中定义消息的字段标签时,可以是不连续的,但是如果将其定义为连续递增的数值,将获得更好的编码和解码性能。
Tag用来在消息的二进制格式中识别各个字段的,一旦开始使用就不能够再改变。最小的标签号可以从1开始,最大到2^29-1.不可以使用其中的19000-19999的标识号,Protobuf实现中对这些进行了预留。如果非要在.proto文件中使用这些预留标识号,编译时就会报警。
如果字段的属性值是固定的几个值,可以使用枚举。
2. 使用Google提供的Protobuf编译器使proto文件生成代码文件,针对C++语言,一般为.pb.h和.pb.cc文件,主要是对消息格式以特定的语言方式描述。
Protobuf在windows上的编译以及编译proto文件的步骤参见:http://blog.csdn.net/fengbingchun/article/details/47905907
3. 将生成的.pb.h和.pb.cc文件加入自己的工程中,使用Protobuf库提供的API来编写应用程序。
Protobuf支持的标量数值类型:double、float、int32、int64、uint32、uint64、sint32、sint64、fixed32、fixed64、sfixed32、sfixed64、bool、string、bytes。
Protobuf消息更新原则:(1)、不要修改已经存在字段的标签号;(2)、任何新添加的字段必须是optional和repeated限定符,否则无法保证新老程序在互相传递消息时的消息兼容性;(3)、在原有的消息中,不能移除已经存在的required字段,optional和repeated类型的字段可以被移除,但是它们之前使用的标签号必须被保留,不能被新的字段重用;(4)、int32、uint32、int64、uint64和bool等类型之间是兼容的,sint32和sint64是兼容的,string和bytes是兼容的,fixed32和sfixed32,以及fixed64和sfixed64之间是兼容的,这意味着如果想修改原有字段的类型时,为了保证兼容性,只能将其修改为与其原有类型兼容的类型,否则就将打破新老消息格式的兼容性;(5)、optional和repeated限定符也是相互兼容的;(6)、不需要的字段可以删除,删除字段的Tag不应该在新的消息定义中使用;(7)、不需要的字段可以转换为扩展,反之亦然,只要类型和数值依然保留。
在.proto文件中定义的包名,该包名在生成对应的C++文件时,将被替换为名字空间名称。
Protobuf允许在.proto文件中定义一些常用的选项,这样可以指示Protobuf编译器帮助我们生成更为匹配的目标语言代码。Protobuf内置的选项被分为三个级别:(1)、文件级别,这样的选项将影响当前文件中定义的所有消息和枚举;(2)、消息级别,这样的选项仅影响某个消息及其包含的所有字段;(3)、字段级别,这样的选项仅仅影响与其相关的字段。
optionoptimize_for = LITE_RUNTIME; optimize_for是文件级别的选项,Protobuf定义三种优化级别SPEED/CODE_SIZE/LITE_RUNTIME。缺省情况下是SPEED。(1)、SPEED:表示生成的代码运行效率高,但是由此生成的代码编译后会占用更多的空间;(2)、CODE_SIZE:和SPEED恰恰相反,代码运行效率较低,但是由此生成的代码编译后会占用更少的空间,通常用于资源有限的平台,如Mobile;(3)、LITE_RUNTIME:生成的代码执行效率高,同时生成代码编译后的所占用的空间也是非常少,这是以牺牲Protobuf提供的反射功能为代价的。因此在C++中链接Protobuf库时仅需链接libprotobuf-lite,而非libprotobuf.对于LITE_MESSAGE选项而言,其生成的代码均将继承自MessageLite,而非Message。MessageLite类是Message类的父类。
对于数值型的repeated字段,可通过添加[packed= true]的字段选项,以通知Protobuf在为该类型的消息对象编码时更加高效。如果设置该选项,那么元素数量为0的repeated字段将不会被编码,否则数组中的所有元素会被编码成一个单一的key/value形式。该编码形式,对包含较小的整型元素而言,优化后的编码结果可以节省更多的空间。该选项仅适用于2.3.0以上的Protobuf。
[default = default_value]:optional类型的字段,如果在序列化时没有被设置,或者是老版本的消息中根本不存在该字段,那么在反序列化该类型的消息时,optional的字段将被赋予类型相关的缺省值,如bool被设置为false,string默认为空串,数字类型默认0,枚举类型,默认为类型定义中的第一个值。.Protobuf也支持自定义的缺省值。
Protobuf中的消息都是由一系列的键值对构成的。每个消息的二进制版本都是使用标签号作为key,而每一个字段的名字和类型均是在解码的过程中根据目标类型(反序列化后的对象类型)进行配对的。在进行消息编码时,key/value被连接成字节流。在解码时,解析器可以直接跳过不识别的字段,这样就可以保证新老版本消息定义在新老程序之间的兼容性,从而有效地避免了使用older消息格式的older程序在解析newer程序发来的newer消息时,一旦遇到未知(新添加的)字段时而引发的解析和对象初始化的错误。
Protobuf目前有2个大版本,proto3是最新版本,它引入了一个新的语言版本Protocol Buffers,以及一些新特性在现有的语言版本proto2。proto3简化了Protocol Buffers语言,易用性更高使它可以成为一个广泛的编程语言。目前,proto3只有beta版,注意,两个语言版本的api不是完全兼容。
一些来自Google的工程师们指出使用required弊大于利,尽量使用optional和repeated。
Protobuf支持更深层次的嵌套和分组嵌套,但是为了结构清晰可见,不建议使用过深层次的嵌套。
Protobuf编译器会为每个消息生成一个类,每个类包含基本函数、消息实现、嵌套类型、访问器等部分。
由于一些历史原因,基本数值类型的repeated的字段并没有被尽可能的高效编码。在新的代码中,用户应该使用特殊选项[packed = true]来保证更高效的编码。
enum值是使用可变编码方式的,对负数不够高效,因此不推荐在enum中使用负数。
通过扩展,可以将一个范围内的字段标签号声明为可被第三方扩展所用。然后,其他人就可以在自己的.proto文件中为该消息类型声明新的字段,而不必去编辑原始文件了。关键字为”extensions”
如果你的消息中有很多可选字段,并且同时至多一个字段会被设置,你可以加强这个行为,使用oneof特性节省内存。oneof字段就像可选字段,除了它们会共享内存,至多一个字段会被设置。设置其中一个字段会清除其它oneof字段。为了在.proto定义oneof字段,你需要在名字前面加上oneof关键字。可以增加任意类型的字段,但是不能使用required、optional、repeated关键字。
可以为.proto文件新增一个可选的package声明符,用来防止不同的消息类型有命名冲突。包的声明符会根据使用语言的不同影响生成的代码。
Probobuf的简单使用可以参见:http://blog.csdn.net/fengbingchun/article/details/48768039
下面举一个在Caffe中使用的例子:
caffe_tmp.proto内容如下,此proto文件并无实际意义,只是从caffe.proto中选取的一段,为以后分析caffe.proto做个准备:
// syntax关键字,以指明proto文件的Protobuf协议版本,不指明则是v2
// syntax = "proto3"; //v3
syntax = "proto2";
package caffe_tmp;// Specifies the shape (dimensions) of a Blob.
message BlobShape {repeated int64 dim = 1 [packed = true];
}message BlobProto {optional BlobShape shape = 7;repeated float data = 5 [packed = true];repeated float diff = 6 [packed = true];// 4D dimensions -- deprecated. Use "shape" instead.optional int32 num = 1 [default = 0];optional int32 channels = 2 [default = 0];optional int32 height = 3 [default = 0];optional int32 width = 4 [default = 0];
}message Datum {optional int32 channels = 1;optional int32 height = 2;optional int32 width = 3;// the actual image data, in bytesoptional bytes data = 4;optional int32 label = 5;// Optionally, the datum could also hold float data.repeated float float_data = 6;// If true data contains an encoded image that need to be decodedoptional bool encoded = 7 [default = false];
}enum Phase {TRAIN = 0;TEST = 1;
}message NetState {optional Phase phase = 1 [default = TEST];optional int32 level = 2 [default = 0];repeated string stage = 3;
}// Update the next available ID when you add a new LayerParameter field.
// LayerParameter next available layer-specific
message LayerParameter {optional string name = 1; // the layer nameoptional string type = 2; // the layer typerepeated string bottom = 3; // the name of each bottom blobrepeated string top = 4; // the name of each top blob// The train / test phase for computation.optional Phase phase = 10;// The blobs containing the numeric parameters of the layer.repeated BlobProto blobs = 7;}// Message that stores parameters shared by loss layers
message LossParameter {// If specified, ignore instances with the given label.optional int32 ignore_label = 1;// If true, normalize each batch across all instances (including spatial// dimesions, but not ignored instances); else, divide by batch size only.optional bool normalize = 2 [default = true];
}message ConvolutionParameter {optional uint32 num_output = 1; // The number of outputs for the layeroptional bool bias_term = 2 [default = true]; // whether to have bias terms// Pad, kernel size, and stride are all given as a single value for equal// dimensions in height and width or as Y, X pairs.optional uint32 pad = 3 [default = 0]; // The padding size (equal in Y, X)optional uint32 pad_h = 6 [default = 0]; // The padding heightoptional uint32 pad_w = 7 [default = 0]; // The padding widthoptional uint32 kernel_size = 4; // The kernel size (square)optional uint32 kernel_h = 8; // The kernel heightoptional uint32 kernel_w = 9; // The kernel widthoptional uint32 group = 5 [default = 1]; // The group size for group convenum Engine {DEFAULT = 0;CAFFE = 1;CUDNN = 2;}optional Engine engine = 15 [default = DEFAULT];
}message MemoryDataParameter {optional uint32 batch_size = 1;optional uint32 channels = 2;optional uint32 height = 3;optional uint32 width = 4;
}message PoolingParameter {enum PoolMethod {MAX = 0;AVE = 1;STOCHASTIC = 2;}optional PoolMethod pool = 1 [default = MAX]; // The pooling method// Pad, kernel size, and stride are all given as a single value for equal// dimensions in height and width or as Y, X pairs.optional uint32 pad = 4 [default = 0]; // The padding size (equal in Y, X)optional uint32 pad_h = 9 [default = 0]; // The padding heightoptional uint32 pad_w = 10 [default = 0]; // The padding widthoptional uint32 kernel_size = 2; // The kernel size (square)optional uint32 kernel_h = 5; // The kernel heightoptional uint32 kernel_w = 6; // The kernel widthoptional uint32 stride = 3 [default = 1]; // The stride (equal in Y, X)optional uint32 stride_h = 7; // The stride heightoptional uint32 stride_w = 8; // The stride widthenum Engine {DEFAULT = 0;CAFFE = 1;CUDNN = 2;}optional Engine engine = 11 [default = DEFAULT];// If global_pooling then it will pool over the size of the bottom by doing// kernel_h = bottom->height and kernel_w = bottom->widthoptional bool global_pooling = 12 [default = false];
}
生成caffe_tmp.pb.h、caffe_tmp.pb.cc文件:protoc.execaffe_tmp.proto --cpp_out=./
分析caffe_tmp.pb.h文件:
因为caffe_tmp.proto中有9个message,因此会产生9个类,按照caffe_tmp.proto从上往下的顺序分别为BlobShape、BlobProto、Datum、NetState、LayerParameter、LossParameter、ConvolutionParameter、MemoryDataParameter、PoolingParameter。这9个类全部在命名空间caffe_tmp内。这9个类全部继承类::google::protobuf::Message。
caffe_tmp.proto中定义了4个枚举,Phase、ConvolutionParameter::Engine、PoolingParameter::PoolMethod、PoolingParameter::Engine。在caffe_tmp.pb.h中会定义这4个枚举,并分别会增加后缀为IsValid、Parse两个返回值为bool的函数,如ConvlutionParameter_Engine_IsValid、ConvolutionParameter_Engine_Parse。
新建一个控制台工程,测试代码如下:
#include "stdafx.h"
#include <iostream>
#include <string>
#include <assert.h>
#include <fstream>#include "caffe_tmp.pb.h"int main()
{// 序列化,将数据存入文件caffe_tmp::BlobShape blobShape;blobShape.add_dim(4);blobShape.add_dim(8);int size_blobShape = blobShape.ByteSize();caffe_tmp::BlobProto blobProto;blobProto.add_data(1.5);blobProto.add_diff(3.0);blobProto.set_channels(3);blobProto.set_height(100);blobProto.set_width(200);blobProto.set_num(5);blobProto.set_data(0, -1.0);blobProto.add_data(3.3);caffe_tmp::BlobShape* blobShape1 = blobProto.mutable_shape();blobShape1->add_dim(10);int size_blobProto = blobProto.ByteSize();caffe_tmp::Datum datum;byte tmp1[5] = { 1, 2, 3, 4, 5 };datum.set_data(tmp1, 5);int size_datum = datum.ByteSize();caffe_tmp::NetState netState;std::string str[3] = { "hello", "protobuf", "caffe" };netState.add_stage(str[0]);netState.add_stage(str[1]);netState.add_stage(str[2]);caffe_tmp::Phase phase = caffe_tmp::Phase::TRAIN;netState.set_phase(phase);int size_netState = netState.ByteSize();caffe_tmp::LossParameter lossParameter;lossParameter.set_normalize(false);int size_lossParameter = lossParameter.ByteSize();caffe_tmp::ConvolutionParameter convolutionParameter;convolutionParameter.set_num_output(2);convolutionParameter.set_engine(caffe_tmp::ConvolutionParameter::Engine::ConvolutionParameter_Engine_CAFFE);int size_convolutionParameter = convolutionParameter.ByteSize();caffe_tmp::PoolingParameter poolingParameter;poolingParameter.set_pool(caffe_tmp::PoolingParameter::PoolMethod::PoolingParameter_PoolMethod_AVE);poolingParameter.set_engine(caffe_tmp::PoolingParameter::Engine::PoolingParameter_Engine_CUDNN);int size_poolingParameter = poolingParameter.ByteSize();std::fstream output;output.open("./caffe.bin", std::ios::out | std::ios::trunc | std::ios::binary);if (!output.is_open()) {std::cout << "write, open file fail" << std::endl;return -1;}if (!blobShape.SerializeToOstream(&output) || !blobProto.SerializeToOstream(&output) || !datum.SerializeToOstream(&output) ||!netState.SerializeToOstream(&output) || !lossParameter.SerializeToOstream(&output) ||!convolutionParameter.SerializeToOstream(&output) || !poolingParameter.SerializeToOstream(&output)) {std::cout << "failed to write" << std::endl;return -1;}output.close();// 解析(反序列化)std::fstream input;input.open("./caffe.bin", std::ios::in | std::ios::binary);if (!input.is_open()) {std::cout << "read, open file fail" << std::endl;return -1;}char* buf = new char[1024];input.read((char*)buf, size_blobShape);caffe_tmp::BlobShape blobShape_;blobShape_.ParseFromString((char*)buf);assert(blobShape_.ByteSize() == size_blobShape);assert(blobShape_.dim_size() == 2);assert(blobShape_.dim(0) == 4);assert(blobShape_.dim(1) == 8);input.read(buf, size_blobProto);caffe_tmp::BlobProto blobProto_;blobProto_.ParseFromArray(buf, size_blobProto);assert(blobProto_.ByteSize() == size_blobProto);assert(blobProto_.has_shape() == true);blobShape_ = blobProto_.shape();assert(blobShape_.dim(0) == 10);assert(blobProto_.data_size() == 2);assert(blobProto_.data(0) == -1.0);assert(blobProto_.diff(0) == 3.0);assert(blobProto_.has_num() == true);input.read(buf, size_datum);caffe_tmp::Datum datum_;datum_.ParseFromArray(buf, size_datum);assert(datum_.ByteSize() == size_datum);assert(datum_.has_channels() == false);assert(datum_.float_data_size() == 0);assert(datum_.has_data() == true);std::string str1 = datum_.data();assert(str1.size() == 5);std::vector<byte> bytes(str1.begin(), str1.end());assert(bytes[4] == 5);input.read(buf, size_netState);caffe_tmp::NetState netState_;netState_.ParseFromArray(buf, size_netState);assert(netState_.ByteSize() == size_netState);assert(netState_.has_phase() == true);caffe_tmp::Phase phase_ = netState_.phase();assert(phase_ == 0);assert(netState_.has_level() == false);assert(netState_.stage_size() == 3);assert(netState_.stage(1) == "protobuf");input.read(buf, size_lossParameter);caffe_tmp::LossParameter lossParameter_;lossParameter_.ParseFromArray(buf, size_lossParameter);assert(lossParameter_.ByteSize() == size_lossParameter);assert(lossParameter_.has_ignore_label() == false);assert(lossParameter_.normalize() == false);input.read(buf, size_convolutionParameter);caffe_tmp::ConvolutionParameter convolutionParameter_;convolutionParameter_.ParseFromArray(buf, size_convolutionParameter);assert(convolutionParameter_.ByteSize() == size_convolutionParameter);assert(convolutionParameter_.has_kernel_size() == false);assert(convolutionParameter_.num_output() == 2);assert(convolutionParameter_.has_engine() == true);caffe_tmp::ConvolutionParameter_Engine engine_ = convolutionParameter_.engine();assert(engine_ == caffe_tmp::ConvolutionParameter::Engine::ConvolutionParameter_Engine_CAFFE);input.read(buf, size_poolingParameter);caffe_tmp::PoolingParameter poolingParameter_;poolingParameter_.ParseFromArray(buf, size_poolingParameter);assert(poolingParameter_.ByteSize() == size_poolingParameter);assert(poolingParameter_.has_pool() == true);caffe_tmp::PoolingParameter_PoolMethod poolMethod = poolingParameter_.pool();assert(poolMethod == caffe_tmp::PoolingParameter::PoolMethod::PoolingParameter_PoolMethod_AVE);caffe_tmp::PoolingParameter_Engine pooling_engine_ = poolingParameter_.engine();assert(pooling_engine_ == 2);delete[] buf;input.close();return 0;
}参考文献:
1. http://www.cnblogs.com/royenhome/archive/2010/10/29/1864860.html
2. http://www.ibm.com/developerworks/cn/linux/l-cn-gpb/
3. http://www.cnblogs.com/stephen-liu74/category/442364.html
4. http://colobu.com/2015/01/07/Protobuf-language-guide/
相关文章:

打造 AI Beings,和微信合作…第七代微软小冰的成长之路
8月15日, “第七代微软小冰”年度发布会在北京举行。本次发布会上,微软(亚洲)互联网工程院带来了微软小冰在 Dual AI 领域的新进展,全新升级的部分核心技术,最新的人工智能创造成果,以及更多的合作与产品落地。其中&am…

感知机介绍及实现
感知机(perceptron)由Rosenblatt于1957年提出,是神经网络与支持向量机的基础。感知机是最早被设计并被实现的人工神经网络。感知机是一种非常特殊的神经网络,它在人工神经网络的发展史上有着非常重要的地位,尽管它的能力非常有限,…
不甘心只做输入工具,搜狗输入法上线AI助手,提供智能服务
8月19日搜狗输入法上线了新功能——智能汪仔,在输入法中引入了AI助手,这是搜狗输入法继今年5月推出“语音变声功能”后又一个AI落地产品。 有了智能汪仔AI助手的加持后,搜狗输入法能够在不同的聊天场景,提供丰富多样的表达方式从…

可构造样式表 - 通过javascript来生成css的新方式
可构造样式表是一种使用Shadow DOM进行创建和分发可重用样式的新方法。 使用Javascript来创建样式表是可能的。然而,这个过程在历史上一直是使用document.createElement(style)来创建<style>元素,然后通过访问其sheet属性来获得一个基础的CSSStyle…

模板方法模式与策略模式的区别
2019独角兽企业重金招聘Python工程师标准>>> 模板方法模式:在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。 策略模式:定义一个…

简单明了,一文入门视觉SLAM
作者 | 黄浴转载自知乎【导读】SLAM是“Simultaneous Localization And Mapping”的缩写,可译为同步定位与建图。最早,SLAM 主要用在机器人领域,是为了在没有任何先验知识的情况下,根据传感器数据实时构建周围环境地图,…

大主子表关联的性能优化方法
【摘要】主子表是数据库最常见的关联关系之一,最典型的包括合同和合同条款、订单和订单明细、保险保单和保单明细、银行账户和账户流水、电商用户和订单、电信账户和计费清单或流量详单。当主子表的数据量较大时,关联计算的性能将急剧降低,在…

Windows7上配置Python Protobuf 操作步骤
1、 按照http://blog.csdn.net/fengbingchun/article/details/8183468 中步骤,首先安装Python 2.7.10; 2、 按照http://blog.csdn.net/fengbingchun/article/details/47905907 中步骤,配置、编译Protobuf; 3、 将(2)中生成的pr…
鲜为人知的静态、命令式编程语言——Nimrod
Nimrod是一个新型的静态类型、命令式编程语言,支持过程式、函数式、面向对象和泛型编程风格而保持简单和高效。Nimrod从Lisp继承来的一个特殊特性抽象语法树(AST)作为语言规范的一部分,可以用作创建领域特定语言的强大宏系统。它还…

机器学习进阶-图像形态学操作-腐蚀操作 1.cv2.erode(进行腐蚀操作)
1.cv2.erode(src, kernel, iteration) 参数说明:src表示的是输入图片,kernel表示的是方框的大小,iteration表示迭代的次数 腐蚀操作原理:存在一个kernel,比如(3, 3),在图像中不断的平移,在这个9…
无需成对示例、无监督训练,CycleGAN生成图像简直不要太简单
作者 | Jason Brownlee译者 | Freesia,Rachel编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】图像到图像的转换技术一般需要大量的成对数据,然而要收集这些数据异常耗时耗力。因此本文主要介绍了无需成对示例便能实现图…
Git使用常见问题解决方法汇总
1. 在Ubuntu下使用$ git clone时出现server certificate verification failed. CAfile:/etc/ssl/certs/ca-certificates.crt CRLfile: none 解决方法:在执行$ git clone 之前,在终端输入: export GIT_SSL_NO_VERIFY1 2. 在Windows上更新了…

服务器监控常用命令
在网站性能优化中,我们经常要检查服务器的各种指标,以便快速找到害群之马。大多情况下,我们会使用cacti、nagois或者zabbix之类的监控软件,但是这类软件安装起来比较麻烦,在一个小型服务器,我们想尽快找到问…
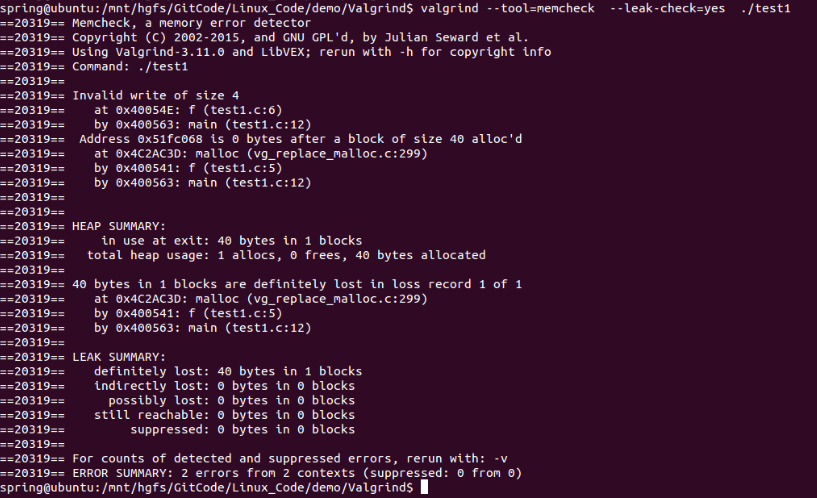
Ubuntu下内存泄露检测工具Valgrind的使用
在VS中可以用VLD检测是否有内存泄露,可以参考http://blog.csdn.net/fengbingchun/article/details/44195959,下面介绍下Ubuntu中内存泄露检测工具Valgrind的使用。Valgrind目前最新版本是3.11.0, 可以从http://www.valgrind.org/ 通过下载源码…
数据为王的时代,如何用图谱挖掘商业数据背后的宝藏?
这是一个商业时代,一个数据为王的时代,也是一个 AI 迎来黄金发展期的时代。据史料记载,商业在商朝已初具规模。斗转星移,时光流转,到 2019 年,商业形式已发生翻天覆地的变化,但是商业的本质——…
旋转卡壳——模板(对踵点)
这东西学了我大概两天吧。。其实不应该学这么久的,但是这两天有点小困,然后学习时间被削了很多\(QwQ\) 说几个坑点。 - 对于题目不保证有凸包的情况,要选用左下角的点,而非单纯的最下边的点构造凸包。 - 对于凸包中只有\(1/2\)个点…
SNMP 协议 OID的使用
为什么80%的码农都做不了架构师?>>> SNMP 协议 OID的使用 SNMP(Simple Network Management Protocol简单网络管理)协议 是现在网络管理系统(NMS)监控网络设备状态的协议,是现在网管事实上的标准…
颜色空间YUV简介
YUV概念:YUV是被欧洲电视系统所采用的一种颜色编码方法(属于PAL,Phase Alternation Line),是PAL和SECAM模拟彩色电视制式采用的颜色空间。其中的Y、U、V几个字母不是英文单词的组合词,Y代表亮度,其实Y就是图像的灰度值…

基于RNN的NLP机器翻译深度学习课程 | 附实战代码
作者 | 小宋是呢来源 | CSDN博客深度学习用的有一年多了,最近开始NLP自然处理方面的研发。刚好趁着这个机会写一系列 NLP 机器翻译深度学习实战课程。本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:…
trash-cli设置Linux 回收站
trash-cli 设置 Linux 回收站 trash-cli是一个使用 python 开发的软件包,包含 trash-put、restore-trash、trash-list、trash-empty、trash-rm等命令,我们可以通过这条命令,将文件移动到回收站,或者还原删除了的文件。 trash-cli的…
磁盘有时也不可靠
实验服务器的磁盘是最近买的,当卖家问我要普通的还是高级的, 我选择了普通,现在追悔莫及。今天的分析更加详细。首先发现每次实验,出错的文件都不一样,所以应该不是临界条件的问题。下表总结了出错的位置,原…
从原理到落地,七大维度详解矩阵分解推荐算法
作者 | gongyouliu编辑丨Zandy来源 | 大数据与人工智能 ( ID: ai-big-data)导语:作者在《协同过滤推荐算法》这篇文章中介绍了 user-based 和 item-based 协同过滤算法,这类协同过滤算法是基于邻域的算法(也称为基于内存的协同过…
libyuv库的使用
libyuv是Google开源的实现各种YUV与RGB之间相互转换、旋转、缩放的库。它是跨平台的,可在Windows、Linux、Mac、Android等操作系统,x86、x64、arm架构上进行编译运行,支持SSE、AVX、NEON等SIMD指令加速。下面说一下libyuv在Windows7VS2013 x6…
封装 vue 组件的过程记录
在我们使用vue的开发过程中总会遇到这样的场景,封装自己的业务组件。 封装页面组件前要考虑几个问题:1、该业务组件的使用场景 2、在什么条件下展示一些什么数据,数据类型是什么样的,及长度颜色等 3、如果是通用的内容,…

Service的基本组成
Service与Activity的最大区别就是一有界面,一个没有界面。 如果某些程序操作很消耗时间,那么可以将这些程序定义在Service之中,这样就可以完成程序的后台运行, 其实Service就是一个没有界面的Activity,执行跨进程访问也…
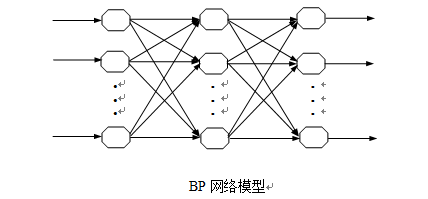
BP神经网络公式推导及实现(MNIST)
BP神经网络的基础介绍见:http://blog.csdn.net/fengbingchun/article/details/50274471,这里主要以公式推导为主。BP神经网络又称为误差反向传播网络,其结构如下图。这种网络实质是一种前向无反馈网络,具有结构清晰、易实现、计算…
AI应用落地哪家强?CSDN AI Top 30+案例评选等你来秀!
人工智能历经百年发展,如今迎来发展的黄金时期。目前,AI 技术已涵盖自然语言处理、模式识别、图像识别、数据挖掘、机器学习等领域的研究,在汽车、金融、教育、医疗、安防、零售、家居、文娱、工业等行业获得了令人印象深刻的成果。 在各行业…

安利Mastodon:属于未来的社交网络
我为Mastodon开发了一款安卓客户端,v1.0版本已经发布,欢迎下载使用 源码在这里:https://github.com/shuiRong/Gakki ??? 正文 Mastodon(长毛象)是什么? 是一个免费开源、去中心化、分布式的微博客社交网络,是微博、…
通过案例练习掌握SSH 的整合
1. SSH整合_方案01 ** 整合方案01 Struts2框架 Spring框架 在Spring框架中整合了Hibernate(JDBC亦可) 一些业务组件(Service组件)也可以放入Spring框架中迚行管理(昨天的例子) 1. 请求࿰…

tiny-cnn开源库的使用(MNIST)
tiny-cnn是一个基于CNN的开源库,它的License是BSD 3-Clause。作者也一直在维护更新,对进一步掌握CNN很有帮助,因此下面介绍下tiny-cnn在windows7 64bit vs2013的编译及使用。 1. 从https://github.com/nyanp/tiny-cnn下载源码࿱…