感知机介绍及实现
感知机(perceptron)由Rosenblatt于1957年提出,是神经网络与支持向量机的基础。
感知机是最早被设计并被实现的人工神经网络。感知机是一种非常特殊的神经网络,它在人工神经网络的发展史上有着非常重要的地位,尽管它的能力非常有限,主要用于线性分类。
感知机还包括多层感知机,简单的线性感知机用于线性分类器,多层感知机(含有隐层的网络)可用于非线性分类器。本文中介绍的均是简单的线性感知机。
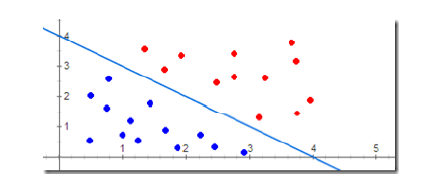
图 1
感知机工作方式:
(1)、学习阶段:修改权值和偏置,根据”已知的样本”对权值和偏置不断修改----有监督学习。当给定某个样本的输入/输出模式对时,感知机输出单元会产生一个实际输出向量,用期望输出(样本输出)与实际输出之差来修正网络连接权值和偏置。
(2)、工作阶段:计算单元变化,由响应函数给出新输入下的输出。
感知机学习策略:
感知机学习的目标就是求得一个能够将训练数据集中正负实例完全分开的分类超平面,为了找到分类超平面,即确定感知机模型中的参数w和b,需要定义一个基于误分类的损失函数,并通过将损失函数最小化来求w和b。
(1)、数据集线性可分性:在二维平面中,可以用一条直线将+1类和-1类完美分开,那么这个样本空间就是线性可分的。因此,感知机都基于一个前提,即问题空间线性可分;
(2)、定义损失函数,找到参数w和b,使得损失函数最小。
损失函数的选取:
(1)、损失函数的一个自然选择就是误分类点的总数,但是这样的点不是参数w,b的连续可导函数,不易优化;
(2)、损失函数的另一个选择就是误分类点到划分超平面S(w*x+b=0)的总距离。

以上理论部分主要来自: http://staff.ustc.edu.cn/~qiliuql/files/DM2013/2013SVM.pdf
以下代码根据上面的描述实现:
perceptron.hpp:
#ifndef _PERCEPTRON_HPP_
#define _PERCEPTRON_HPP_#include <vector>namespace ANN {typedef std::vector<float> feature;
typedef int label;class Perceptron {
private:std::vector<feature> feature_set;std::vector<label> label_set;int iterates;float learn_rate;std::vector<float> weight;int size_weight;float bias;void initWeight();float calDotProduct(const feature feature_, const std::vector<float> weight_);void updateWeight(const feature feature_, int label_);public:Perceptron(int iterates_, float learn_rate_, int size_weight_, float bias_);void getDataset(const std::vector<feature> feature_set_, const std::vector<label> label_set_);bool train();label predict(const feature feature_);
};}#endif // _PERCEPTRON_HPP_
#include "perceptron.hpp"
#include <assert.h>
#include <time.h>
#include <iostream>namespace ANN {void Perceptron::updateWeight(const feature feature_, int label_)
{for (int i = 0; i < size_weight; i++) {weight[i] += learn_rate * feature_[i] * label_; // formula 5}bias += learn_rate * label_; // formula 5
}float Perceptron::calDotProduct(const feature feature_, const std::vector<float> weight_)
{assert(feature_.size() == weight_.size());float ret = 0.;for (int i = 0; i < feature_.size(); i++) {ret += feature_[i] * weight_[i];}return ret;
}void Perceptron::initWeight()
{srand(time(0));float range = 100.0;for (int i = 0; i < size_weight; i++) {float tmp = range * rand() / (RAND_MAX + 1.0);weight.push_back(tmp);}
}Perceptron::Perceptron(int iterates_, float learn_rate_, int size_weight_, float bias_)
{iterates = iterates_;learn_rate = learn_rate_;size_weight = size_weight_;bias = bias_;weight.resize(0);feature_set.resize(0);label_set.resize(0);
}void Perceptron::getDataset(const std::vector<feature> feature_set_, const std::vector<label> label_set_)
{assert(feature_set_.size() == label_set_.size());feature_set.resize(0);label_set.resize(0);for (int i = 0; i < feature_set_.size(); i++) {feature_set.push_back(feature_set_[i]);label_set.push_back(label_set_[i]);}
}bool Perceptron::train()
{initWeight();for (int i = 0; i < iterates; i++) {bool flag = true;for (int j = 0; j < feature_set.size(); j++) {float tmp = calDotProduct(feature_set[j], weight) + bias;if (tmp * label_set[j] <= 0) {updateWeight(feature_set[j], label_set[j]);flag = false;}}if (flag) {std::cout << "iterate: " << i << std::endl;std::cout << "weight: ";for (int m = 0; m < size_weight; m++) {std::cout << weight[m] << " ";}std::cout << std::endl;std::cout << "bias: " << bias << std::endl;return true;}}return false;
}label Perceptron::predict(const feature feature_)
{assert(feature_.size() == size_weight);return calDotProduct(feature_, weight) + bias >= 0 ? 1 : -1; //formula 2
}}test_NN.cpp:
#include <iostream>
#include "perceptron.hpp"int test_perceptron();int main()
{test_perceptron();std::cout << "ok!" << std::endl;
}int test_perceptron()
{// prepare dataconst int len_data = 20;const int feature_dimension = 2;float data[len_data][feature_dimension] = { { 10.3, 10.7 }, { 20.1, 100.8 }, { 44.9, 8.0 }, { -2.2, 15.3 }, { -33.3, 77.7 },{ -10.4, 111.1 }, { 99.3, -2.2 }, { 222.2, -5.5 }, { 10.1, 10.1 }, { 66.6, 30.2 },{ 0.1, 0.2 }, { 1.2, 0.03 }, { 0.5, 4.6 }, { -22.3, -11.1 }, { -88.9, -12.3 },{ -333.3, -444.4 }, { -111.2, 0.5 }, { -6.6, 2.9 }, { 3.3, -100.2 }, { 5.6, -88.8 } };int label_[len_data] = { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,-1, -1, -1, -1, -1, -1, -1, -1, -1, -1 };std::vector<ANN::feature> set_feature;std::vector<ANN::label> set_label;for (int i = 0; i < len_data; i++) {ANN::feature feature_single;for (int j = 0; j < feature_dimension; j++) {feature_single.push_back(data[i][j]);}set_feature.push_back(feature_single);set_label.push_back(label_[i]);feature_single.resize(0);}// trainint iterates = 1000;float learn_rate = 0.5;int size_weight = feature_dimension;float bias = 2.5;ANN::Perceptron perceptron(iterates, learn_rate, size_weight, bias);perceptron.getDataset(set_feature, set_label);bool flag = perceptron.train();if (flag) {std::cout << "data set is linearly separable" << std::endl;}else {std::cout << "data set is linearly inseparable" << std::endl;return -1;}// predictANN::feature feature1;feature1.push_back(636.6);feature1.push_back(881.8);std::cout << "the correct result label is 1, " << "the real result label is: " << perceptron.predict(feature1) << std::endl;ANN::feature feature2;feature2.push_back(-26.32);feature2.push_back(-255.95);std::cout << "the correct result label is -1, " << "the real result label is: " << perceptron.predict(feature2) << std::endl;return 0;
}运行结果如下图:

GitHub:https://github.com/fengbingchun/NN
相关文章:
不甘心只做输入工具,搜狗输入法上线AI助手,提供智能服务
8月19日搜狗输入法上线了新功能——智能汪仔,在输入法中引入了AI助手,这是搜狗输入法继今年5月推出“语音变声功能”后又一个AI落地产品。 有了智能汪仔AI助手的加持后,搜狗输入法能够在不同的聊天场景,提供丰富多样的表达方式从…

可构造样式表 - 通过javascript来生成css的新方式
可构造样式表是一种使用Shadow DOM进行创建和分发可重用样式的新方法。 使用Javascript来创建样式表是可能的。然而,这个过程在历史上一直是使用document.createElement(style)来创建<style>元素,然后通过访问其sheet属性来获得一个基础的CSSStyle…

模板方法模式与策略模式的区别
2019独角兽企业重金招聘Python工程师标准>>> 模板方法模式:在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。 策略模式:定义一个…

简单明了,一文入门视觉SLAM
作者 | 黄浴转载自知乎【导读】SLAM是“Simultaneous Localization And Mapping”的缩写,可译为同步定位与建图。最早,SLAM 主要用在机器人领域,是为了在没有任何先验知识的情况下,根据传感器数据实时构建周围环境地图,…

大主子表关联的性能优化方法
【摘要】主子表是数据库最常见的关联关系之一,最典型的包括合同和合同条款、订单和订单明细、保险保单和保单明细、银行账户和账户流水、电商用户和订单、电信账户和计费清单或流量详单。当主子表的数据量较大时,关联计算的性能将急剧降低,在…

Windows7上配置Python Protobuf 操作步骤
1、 按照http://blog.csdn.net/fengbingchun/article/details/8183468 中步骤,首先安装Python 2.7.10; 2、 按照http://blog.csdn.net/fengbingchun/article/details/47905907 中步骤,配置、编译Protobuf; 3、 将(2)中生成的pr…
鲜为人知的静态、命令式编程语言——Nimrod
Nimrod是一个新型的静态类型、命令式编程语言,支持过程式、函数式、面向对象和泛型编程风格而保持简单和高效。Nimrod从Lisp继承来的一个特殊特性抽象语法树(AST)作为语言规范的一部分,可以用作创建领域特定语言的强大宏系统。它还…

机器学习进阶-图像形态学操作-腐蚀操作 1.cv2.erode(进行腐蚀操作)
1.cv2.erode(src, kernel, iteration) 参数说明:src表示的是输入图片,kernel表示的是方框的大小,iteration表示迭代的次数 腐蚀操作原理:存在一个kernel,比如(3, 3),在图像中不断的平移,在这个9…
无需成对示例、无监督训练,CycleGAN生成图像简直不要太简单
作者 | Jason Brownlee译者 | Freesia,Rachel编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】图像到图像的转换技术一般需要大量的成对数据,然而要收集这些数据异常耗时耗力。因此本文主要介绍了无需成对示例便能实现图…
Git使用常见问题解决方法汇总
1. 在Ubuntu下使用$ git clone时出现server certificate verification failed. CAfile:/etc/ssl/certs/ca-certificates.crt CRLfile: none 解决方法:在执行$ git clone 之前,在终端输入: export GIT_SSL_NO_VERIFY1 2. 在Windows上更新了…

服务器监控常用命令
在网站性能优化中,我们经常要检查服务器的各种指标,以便快速找到害群之马。大多情况下,我们会使用cacti、nagois或者zabbix之类的监控软件,但是这类软件安装起来比较麻烦,在一个小型服务器,我们想尽快找到问…
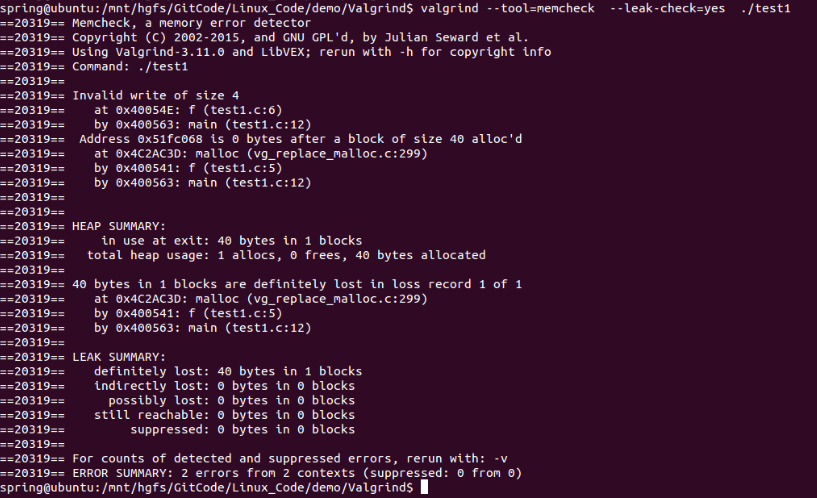
Ubuntu下内存泄露检测工具Valgrind的使用
在VS中可以用VLD检测是否有内存泄露,可以参考http://blog.csdn.net/fengbingchun/article/details/44195959,下面介绍下Ubuntu中内存泄露检测工具Valgrind的使用。Valgrind目前最新版本是3.11.0, 可以从http://www.valgrind.org/ 通过下载源码…
数据为王的时代,如何用图谱挖掘商业数据背后的宝藏?
这是一个商业时代,一个数据为王的时代,也是一个 AI 迎来黄金发展期的时代。据史料记载,商业在商朝已初具规模。斗转星移,时光流转,到 2019 年,商业形式已发生翻天覆地的变化,但是商业的本质——…
旋转卡壳——模板(对踵点)
这东西学了我大概两天吧。。其实不应该学这么久的,但是这两天有点小困,然后学习时间被削了很多\(QwQ\) 说几个坑点。 - 对于题目不保证有凸包的情况,要选用左下角的点,而非单纯的最下边的点构造凸包。 - 对于凸包中只有\(1/2\)个点…
SNMP 协议 OID的使用
为什么80%的码农都做不了架构师?>>> SNMP 协议 OID的使用 SNMP(Simple Network Management Protocol简单网络管理)协议 是现在网络管理系统(NMS)监控网络设备状态的协议,是现在网管事实上的标准…
颜色空间YUV简介
YUV概念:YUV是被欧洲电视系统所采用的一种颜色编码方法(属于PAL,Phase Alternation Line),是PAL和SECAM模拟彩色电视制式采用的颜色空间。其中的Y、U、V几个字母不是英文单词的组合词,Y代表亮度,其实Y就是图像的灰度值…

基于RNN的NLP机器翻译深度学习课程 | 附实战代码
作者 | 小宋是呢来源 | CSDN博客深度学习用的有一年多了,最近开始NLP自然处理方面的研发。刚好趁着这个机会写一系列 NLP 机器翻译深度学习实战课程。本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:…
trash-cli设置Linux 回收站
trash-cli 设置 Linux 回收站 trash-cli是一个使用 python 开发的软件包,包含 trash-put、restore-trash、trash-list、trash-empty、trash-rm等命令,我们可以通过这条命令,将文件移动到回收站,或者还原删除了的文件。 trash-cli的…
磁盘有时也不可靠
实验服务器的磁盘是最近买的,当卖家问我要普通的还是高级的, 我选择了普通,现在追悔莫及。今天的分析更加详细。首先发现每次实验,出错的文件都不一样,所以应该不是临界条件的问题。下表总结了出错的位置,原…
从原理到落地,七大维度详解矩阵分解推荐算法
作者 | gongyouliu编辑丨Zandy来源 | 大数据与人工智能 ( ID: ai-big-data)导语:作者在《协同过滤推荐算法》这篇文章中介绍了 user-based 和 item-based 协同过滤算法,这类协同过滤算法是基于邻域的算法(也称为基于内存的协同过…
libyuv库的使用
libyuv是Google开源的实现各种YUV与RGB之间相互转换、旋转、缩放的库。它是跨平台的,可在Windows、Linux、Mac、Android等操作系统,x86、x64、arm架构上进行编译运行,支持SSE、AVX、NEON等SIMD指令加速。下面说一下libyuv在Windows7VS2013 x6…
封装 vue 组件的过程记录
在我们使用vue的开发过程中总会遇到这样的场景,封装自己的业务组件。 封装页面组件前要考虑几个问题:1、该业务组件的使用场景 2、在什么条件下展示一些什么数据,数据类型是什么样的,及长度颜色等 3、如果是通用的内容,…

Service的基本组成
Service与Activity的最大区别就是一有界面,一个没有界面。 如果某些程序操作很消耗时间,那么可以将这些程序定义在Service之中,这样就可以完成程序的后台运行, 其实Service就是一个没有界面的Activity,执行跨进程访问也…
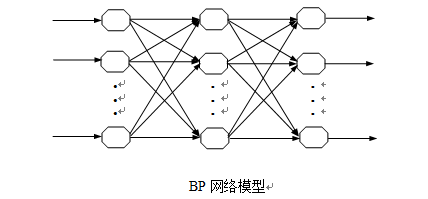
BP神经网络公式推导及实现(MNIST)
BP神经网络的基础介绍见:http://blog.csdn.net/fengbingchun/article/details/50274471,这里主要以公式推导为主。BP神经网络又称为误差反向传播网络,其结构如下图。这种网络实质是一种前向无反馈网络,具有结构清晰、易实现、计算…
AI应用落地哪家强?CSDN AI Top 30+案例评选等你来秀!
人工智能历经百年发展,如今迎来发展的黄金时期。目前,AI 技术已涵盖自然语言处理、模式识别、图像识别、数据挖掘、机器学习等领域的研究,在汽车、金融、教育、医疗、安防、零售、家居、文娱、工业等行业获得了令人印象深刻的成果。 在各行业…

安利Mastodon:属于未来的社交网络
我为Mastodon开发了一款安卓客户端,v1.0版本已经发布,欢迎下载使用 源码在这里:https://github.com/shuiRong/Gakki ??? 正文 Mastodon(长毛象)是什么? 是一个免费开源、去中心化、分布式的微博客社交网络,是微博、…
通过案例练习掌握SSH 的整合
1. SSH整合_方案01 ** 整合方案01 Struts2框架 Spring框架 在Spring框架中整合了Hibernate(JDBC亦可) 一些业务组件(Service组件)也可以放入Spring框架中迚行管理(昨天的例子) 1. 请求࿰…

tiny-cnn开源库的使用(MNIST)
tiny-cnn是一个基于CNN的开源库,它的License是BSD 3-Clause。作者也一直在维护更新,对进一步掌握CNN很有帮助,因此下面介绍下tiny-cnn在windows7 64bit vs2013的编译及使用。 1. 从https://github.com/nyanp/tiny-cnn下载源码࿱…
玩嗨的2亿快手“老铁”和幕后的极致视觉算法
作者 | Just出品 | AI科技大本营(ID:rgznai100)创立八年,短视频平台快手目前已经有超过两亿人在每天登陆使用,每天还有超过 1500 万条短视频被制作和上传,每天的累计观看数更是达到 150 亿。拥有如此庞大的用户数&…

lsmod命令详解
基础命令学习目录首页 原文链接:http://blog.sina.com.cn/s/blog_e6b2465d0101fuev.html lsmod——显示已载入系统的模块 lsmod 其实就是list modules的缩写,即 列出所有模块. 功能说明:显示已载入系统的模块。 语法:lsmod 说明&a…