NLP机器翻译深度学习实战课程基础 | 深度应用

作者 | 小宋是呢
来源 | CSDN博客
0.前言
深度学习用的有一年多了,最近开始 NLP 自然处理方面的研发。刚好趁着这个机会写一系列 NLP 机器翻译深度学习实战课程。
本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:(更新ing)
NLP 机器翻译深度学习实战课程·零(基础概念)
NLP 机器翻译深度学习实战课程·壹(RNN base)
NLP 机器翻译深度学习实战课程·贰(RNN+Attention base)
NLP 机器翻译深度学习实战课程·叁(CNN base)
NLP 机器翻译深度学习实战课程·肆(Self-Attention base)
NLP 机器翻译深度学习实战课程·伍(应用部署)
本系列教程参考博客:https://me.csdn.net/chinatelecom08
1.NLP机器翻译发展现状
1.1 机器翻译现状
1.1.1 什么是机器翻译?
什么是机器翻译?
说白了就是通过计算机将一种语言转化成其他语言,就是机器翻译。
这对我们同学们而言都很熟悉了,那么机器翻译背后的理论支持到底是什么呢?而且几十年前的机器翻译和现在我们天天口中说的神经网络到底有什么区别呢?
首先我们从机器翻译历史发展的角度来对它进行大致的讲述一下,机器翻译的历史大致经历了三个阶段:
基于规则的机器翻译(70 年代)
基于统计的机器翻译(1990 年)
基于神经网络的机器翻译(2014 年)
基于规则的机器翻译(70 年代)
基于规则的机器翻译的想法第一次出现是在70年代。科学家根据对翻译者工作的观察,试图驱使计算机同样进行翻译行为。这些翻译系统的组成部分包括:
双语词典(俄语->英文)
针对每种语言制定一套语言规则(例如,名词以特定的后缀 -heit、-keit、-ung 等结尾)
如此而已。如果有必要,系统还可以补充各种技巧性的规则,如名字、拼写纠正、以及音译词等。
感兴趣的同学可以去网上仔细查看一下相关的资料,这里就贴上一个大致的流程图,来表示基于规则的机器翻译的实现流程。
根据规则调整句子结构,然后去字典中查找对应的词片段的意思,重新组成新的句子,最后利用一些方法来对生成的句子进行语法调整。
基于统计的机器翻译( 1990 年)
在 1990 年早期,IBM 研究中心的一台机器翻译系统首次问世。它并不了解整体的规则和语言学,而是分析两种语言中的相似文本,并试图理解其中的模式。
统计模型的思路是把翻译当成机率问题。原则上是需要利用平行语料,然后逐字进行统计。例如,机器虽然不知道“知识”的英文是什么,但是在大多数的语料统计后,会发现只要有知识出现的句子,对应的英文例句就会出现“Knowledge”这个字。如此一来,即使不用人工维护词典与文法规则,也能让机器理解单词的意思。
这个概念并不新,因为最早 Warren Weave 就提出过类似的概念,只不过那时并没有足够的平行语料以及限于当时计算机的能力太弱,因此没有付诸实行。现代的统计机器翻译要从哪里去找来“现代的罗赛塔石碑”呢?最主要的来源其实是联合国,因为联合国的决议以及公告都会有各个会员国的语言版本,但除此之外,要自己制作平行语料,以现在人工翻译的成本换算一下就会知道这成本高到惊人。
现在我们自己的系统使用的 2000 万语料有一大部分是来自联合国的平行语料。
https://cms.unov.org/UNCorpus/zh#format
在 14 年之前,大家所熟悉的 Google 翻译都是基于统计机器翻译。听到这,应该大家就清楚统计翻译模型是无法成就通天塔大业的。在各位的印像中,机器翻译还只停留在“堪用”而非是“有用”的程度。
基于神经网络的机器翻译(2014 年)
神经网络并不是新东西,事实上神经网络发明已经距今 80 多年了,但是自从2006 年 Geoffrey Hinton (深度学习三尊大神之首)改善了神经网络优化过于缓慢的致命缺点后,深度学习就不断地伴随各种奇迹似的成果频繁出现在我们的生活中。在 2015 年,机器首次实现图像识别超越人类;2016 年,Alpha Go 战胜世界棋王;2017 年,语音识别超过人类速记员;2018 年,机器英文阅读理解首次超越人类。当然机器翻译这个领域也因为有了深度学习这个超级肥料而开始枝繁叶茂。
Yoshua Bengio 在 2014 年的论文中,首次奠定了深度学习技术用于机器翻译的基本架构。他主要是使用基于序列的递归神经网络( RNN ),让机器可以自动捕捉句子间的单词特征,进而能够自动书写为另一种语言的翻译结果。此文一出,Google 如获至宝。很快地,在 Google 供应充足火药以及大神的加持之下,Google 于 2016 年正式宣布将所有统计机器翻译下架,神经网络机器翻译上位,成为现代机器翻译的绝对主流。
简单介绍一下基于神经网络的机器翻译的通用框架:编码器-解码器结构。
用通俗的话来讲,编码器是将信息压缩的过程,解码器就是将信息解码回人能够理解的过程,这种过程信息的损失越少越好。
结构如下图所示:
图1 gnmt机器翻译框架
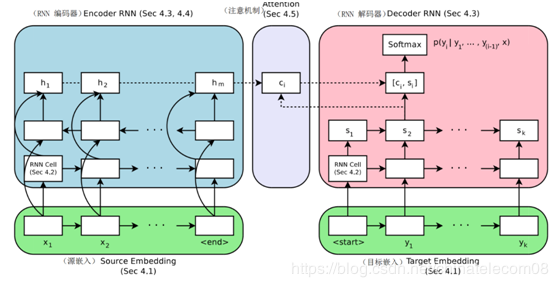
这个是 16 年谷歌发表的 gnmt 框架的结构,使用 lstm+attention 的机制实现,感兴趣的同学可以去查看论文或者百度相关的博客。
图2 transformer机器翻译框架
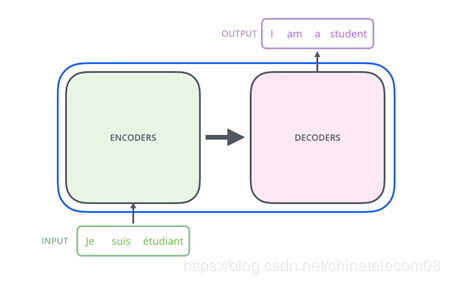
Transformer是谷歌在17年的一篇论文( https://arxiv.org/pdf/1706.03762.pdf )提出的具有开创性的架构,这个结构不同于之前所有的机器翻译网络结构,仅仅依靠模型的优势,就取得了state of the art的结果,优于以往任何方法的机器翻译结果。
1.1.2 相关论文
如果想更深入的了解其中的原理,还是需要阅读一些理论性的文章。如果仅仅想搭建这样一个系统,按照下一篇实践的内容,一步步的进行操作,你就可以拥有搭建基于世界上最先进模型的机器翻译系统的能力了。
这里整理了一些机器翻译中做需要的理论性介绍,包括以下一些内容:
词嵌入向量简单介绍:https://blog.csdn.net/u012052268/article/details/77170517
机器翻译相关论文:
Sequence to Sequence Learning with Neural Networks(2014)
(https://arxiv.org/abs/1409.3215v3)
Attention机制的提出(2016)
(https://arxiv.org/abs/1409.0473v7)
谷歌基于attention的gnmt(2016)
(https://arxiv.org/abs/1609.08144v2)
自注意力机制:transformer(2017)
(https://arxiv.org/abs/1706.03762)
1.1.3 相关会议
机器翻译最著名的顶级会议也是比赛就是 WMT,世界上所有著名的具有机器翻译引擎技术的巨头公司都在该比赛中取得过名次,该比赛从 17 年开始,所有取得前几名的队伍都是通过搭建 transformer 模型来进行优化迭代的。
其中一些队伍提出的方法和技巧,也被各个具有机器翻译技术的公司搜集整理,尝试在自己的翻译引擎中去。
原文链接:
https://blog.csdn.net/xiaosongshine/article/details/99619969
(*本文为 AI科技大本营转载文章,转载请联系作者)
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

AI ProCon 2019 邀请到了亚马逊首席科学家@李沐,在大会的前一天(9.5)亲授「深度学习实训营」,通过动手实操,帮助开发者全面了解深度学习的基础知识和开发技巧。还有 9大技术论坛、60+主题分享,百余家企业、千余名开发者共同相约 2019 AI ProCon!距离5折优惠票结束还有5天!

推荐阅读
ImageNet错误率小于4%,数据量依然不够,N-Shot Learning或是终极解决之道
每天超50亿推广流量、3亿商品展现,阿里妈妈的推荐技术有多牛
Python冷知识,不一样的技巧带给你不一样的乐趣
写爬虫,怎么可以不会正则呢?
传阿里收购网易考拉谈崩;iOS 13 被指涉嫌垄断;新版 Edge Beta 浏览器发布 | 极客头条
高薪的 10 倍工程师不能带来 10 倍的产出
送50本 Python、数据库、java方面的书,包邮给你!!
App 穷途末路?
干货!学霸用12个决策模型告诉你,如何判断你到底需不需要区块链!

你点的每个“在看”,我都认真当成了喜欢
相关文章:

个人站点渲染和跳转过滤功能
核心逻辑:在url里加入正则,匹配分类、标签、年月日和其后面的参数,在视图函数接收这些参数,然后进行过滤。 urls.py # 个人站点的跳转 re_path(r^(?P<username>\w)/(?P<condition>tag|category|archive)/(?P<pa…

三步10分钟搞定数据库版本的降迁 (将后台数据库SQL2008R2降为SQL2005版本)
三步10分钟搞定数据库版本的降迁 (将SQL2008R2降为SQL2005版本)转载原文,并注明出处!虽无多少技术含量,毕竟是作者心血原创,希望理解。转自 http://blog.csdn.net/claro/article/details/6449824前思后想仍…

jdbc链接数据库
JDBC简介 JDBC全称为:Java Data Base Connectivity (java数据库连接),可以为多种数据库提供填统一的访问。JDBC是sun开发的一套数据库访问编程接口,是一种SQL级的API。它是由java语言编写完成,所以具有很好的跨平台特性…
Google Protocol Buffers介绍
Google Protocol Buffers(简称Protobuf),是Google的一个开源项目,它是一种结构化数据存储格式,是Google公司内部的混合语言数据标准,是一个用来序列化(将对象的状态信息转换为可以存储或传输的形式的过程)结…

打造 AI Beings,和微信合作…第七代微软小冰的成长之路
8月15日, “第七代微软小冰”年度发布会在北京举行。本次发布会上,微软(亚洲)互联网工程院带来了微软小冰在 Dual AI 领域的新进展,全新升级的部分核心技术,最新的人工智能创造成果,以及更多的合作与产品落地。其中&am…

感知机介绍及实现
感知机(perceptron)由Rosenblatt于1957年提出,是神经网络与支持向量机的基础。感知机是最早被设计并被实现的人工神经网络。感知机是一种非常特殊的神经网络,它在人工神经网络的发展史上有着非常重要的地位,尽管它的能力非常有限,…
不甘心只做输入工具,搜狗输入法上线AI助手,提供智能服务
8月19日搜狗输入法上线了新功能——智能汪仔,在输入法中引入了AI助手,这是搜狗输入法继今年5月推出“语音变声功能”后又一个AI落地产品。 有了智能汪仔AI助手的加持后,搜狗输入法能够在不同的聊天场景,提供丰富多样的表达方式从…

可构造样式表 - 通过javascript来生成css的新方式
可构造样式表是一种使用Shadow DOM进行创建和分发可重用样式的新方法。 使用Javascript来创建样式表是可能的。然而,这个过程在历史上一直是使用document.createElement(style)来创建<style>元素,然后通过访问其sheet属性来获得一个基础的CSSStyle…

模板方法模式与策略模式的区别
2019独角兽企业重金招聘Python工程师标准>>> 模板方法模式:在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。 策略模式:定义一个…

简单明了,一文入门视觉SLAM
作者 | 黄浴转载自知乎【导读】SLAM是“Simultaneous Localization And Mapping”的缩写,可译为同步定位与建图。最早,SLAM 主要用在机器人领域,是为了在没有任何先验知识的情况下,根据传感器数据实时构建周围环境地图,…

大主子表关联的性能优化方法
【摘要】主子表是数据库最常见的关联关系之一,最典型的包括合同和合同条款、订单和订单明细、保险保单和保单明细、银行账户和账户流水、电商用户和订单、电信账户和计费清单或流量详单。当主子表的数据量较大时,关联计算的性能将急剧降低,在…
Windows7上配置Python Protobuf 操作步骤
1、 按照http://blog.csdn.net/fengbingchun/article/details/8183468 中步骤,首先安装Python 2.7.10; 2、 按照http://blog.csdn.net/fengbingchun/article/details/47905907 中步骤,配置、编译Protobuf; 3、 将(2)中生成的pr…
鲜为人知的静态、命令式编程语言——Nimrod
Nimrod是一个新型的静态类型、命令式编程语言,支持过程式、函数式、面向对象和泛型编程风格而保持简单和高效。Nimrod从Lisp继承来的一个特殊特性抽象语法树(AST)作为语言规范的一部分,可以用作创建领域特定语言的强大宏系统。它还…

机器学习进阶-图像形态学操作-腐蚀操作 1.cv2.erode(进行腐蚀操作)
1.cv2.erode(src, kernel, iteration) 参数说明:src表示的是输入图片,kernel表示的是方框的大小,iteration表示迭代的次数 腐蚀操作原理:存在一个kernel,比如(3, 3),在图像中不断的平移,在这个9…
无需成对示例、无监督训练,CycleGAN生成图像简直不要太简单
作者 | Jason Brownlee译者 | Freesia,Rachel编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】图像到图像的转换技术一般需要大量的成对数据,然而要收集这些数据异常耗时耗力。因此本文主要介绍了无需成对示例便能实现图…
Git使用常见问题解决方法汇总
1. 在Ubuntu下使用$ git clone时出现server certificate verification failed. CAfile:/etc/ssl/certs/ca-certificates.crt CRLfile: none 解决方法:在执行$ git clone 之前,在终端输入: export GIT_SSL_NO_VERIFY1 2. 在Windows上更新了…

服务器监控常用命令
在网站性能优化中,我们经常要检查服务器的各种指标,以便快速找到害群之马。大多情况下,我们会使用cacti、nagois或者zabbix之类的监控软件,但是这类软件安装起来比较麻烦,在一个小型服务器,我们想尽快找到问…
Ubuntu下内存泄露检测工具Valgrind的使用
在VS中可以用VLD检测是否有内存泄露,可以参考http://blog.csdn.net/fengbingchun/article/details/44195959,下面介绍下Ubuntu中内存泄露检测工具Valgrind的使用。Valgrind目前最新版本是3.11.0, 可以从http://www.valgrind.org/ 通过下载源码…
数据为王的时代,如何用图谱挖掘商业数据背后的宝藏?
这是一个商业时代,一个数据为王的时代,也是一个 AI 迎来黄金发展期的时代。据史料记载,商业在商朝已初具规模。斗转星移,时光流转,到 2019 年,商业形式已发生翻天覆地的变化,但是商业的本质——…
旋转卡壳——模板(对踵点)
这东西学了我大概两天吧。。其实不应该学这么久的,但是这两天有点小困,然后学习时间被削了很多\(QwQ\) 说几个坑点。 - 对于题目不保证有凸包的情况,要选用左下角的点,而非单纯的最下边的点构造凸包。 - 对于凸包中只有\(1/2\)个点…
SNMP 协议 OID的使用
为什么80%的码农都做不了架构师?>>> SNMP 协议 OID的使用 SNMP(Simple Network Management Protocol简单网络管理)协议 是现在网络管理系统(NMS)监控网络设备状态的协议,是现在网管事实上的标准…
颜色空间YUV简介
YUV概念:YUV是被欧洲电视系统所采用的一种颜色编码方法(属于PAL,Phase Alternation Line),是PAL和SECAM模拟彩色电视制式采用的颜色空间。其中的Y、U、V几个字母不是英文单词的组合词,Y代表亮度,其实Y就是图像的灰度值…

基于RNN的NLP机器翻译深度学习课程 | 附实战代码
作者 | 小宋是呢来源 | CSDN博客深度学习用的有一年多了,最近开始NLP自然处理方面的研发。刚好趁着这个机会写一系列 NLP 机器翻译深度学习实战课程。本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:…
trash-cli设置Linux 回收站
trash-cli 设置 Linux 回收站 trash-cli是一个使用 python 开发的软件包,包含 trash-put、restore-trash、trash-list、trash-empty、trash-rm等命令,我们可以通过这条命令,将文件移动到回收站,或者还原删除了的文件。 trash-cli的…
磁盘有时也不可靠
实验服务器的磁盘是最近买的,当卖家问我要普通的还是高级的, 我选择了普通,现在追悔莫及。今天的分析更加详细。首先发现每次实验,出错的文件都不一样,所以应该不是临界条件的问题。下表总结了出错的位置,原…
从原理到落地,七大维度详解矩阵分解推荐算法
作者 | gongyouliu编辑丨Zandy来源 | 大数据与人工智能 ( ID: ai-big-data)导语:作者在《协同过滤推荐算法》这篇文章中介绍了 user-based 和 item-based 协同过滤算法,这类协同过滤算法是基于邻域的算法(也称为基于内存的协同过…
libyuv库的使用
libyuv是Google开源的实现各种YUV与RGB之间相互转换、旋转、缩放的库。它是跨平台的,可在Windows、Linux、Mac、Android等操作系统,x86、x64、arm架构上进行编译运行,支持SSE、AVX、NEON等SIMD指令加速。下面说一下libyuv在Windows7VS2013 x6…
封装 vue 组件的过程记录
在我们使用vue的开发过程中总会遇到这样的场景,封装自己的业务组件。 封装页面组件前要考虑几个问题:1、该业务组件的使用场景 2、在什么条件下展示一些什么数据,数据类型是什么样的,及长度颜色等 3、如果是通用的内容,…

Service的基本组成
Service与Activity的最大区别就是一有界面,一个没有界面。 如果某些程序操作很消耗时间,那么可以将这些程序定义在Service之中,这样就可以完成程序的后台运行, 其实Service就是一个没有界面的Activity,执行跨进程访问也…
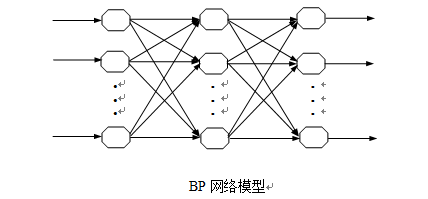
BP神经网络公式推导及实现(MNIST)
BP神经网络的基础介绍见:http://blog.csdn.net/fengbingchun/article/details/50274471,这里主要以公式推导为主。BP神经网络又称为误差反向传播网络,其结构如下图。这种网络实质是一种前向无反馈网络,具有结构清晰、易实现、计算…