1小时上手MaskRCNN·Keras开源实战 | 深度应用

作者 | 小宋是呢
来源 | CSDN博客
0. 前言介绍
开源地址:
https://github.com/matterport/Mask_RCNN
个人主页:
http://www.yansongsong.cn/
MaskRCNN 是何恺明基于以往的 faster rcnn 架构提出的新的卷积网络,一举完成了 object instance segmentation。该方法在有效地目标的同时完成了高质量的语义分割。文章的主要思路就是把原有的 Faster-RCNN 进行扩展,添加一个分支使用现有的检测对目标进行并行预测。
此开源代码:这是在 Python 3,Keras 和 TensorFlow 上实现 Mask R-CNN 。该模型为图像中对象的每个实例生成边界框和分割蒙版。它基于特征金字塔网络(FPN)和ResNet101骨干网。
存储库包括:
Mask R-CNN的源代码,建立在FPN和ResNet101之上。
MS COCO的培训代码
MS COCO的预训练重量
Jupyter笔记本可以在每一步都可视化检测管道
ParallelModel类用于多GPU培训
评估MS COCO指标(AP)
您自己的数据集培训示例
代码记录在案,设计易于扩展。如果您在研究中使用它,请考虑引用此存储库(下面的bibtex)。如果您从事3D视觉,您可能会发现我们最近发布的Matterport3D数据集(https://mp.weixin.qq.com/s/Dt0jbw5Mg-NA_c1A4D_jhg)也很有用。该数据集是由我们的客户捕获的3D重建空间创建的,这些客户同意将其公开供学术使用。您可以在此链接(https://matterport.com/gallery/)查看更多示例。
1. MaskRCNN环境搭建
首先在项目源码地址下载源码到本机中:
https://github.com/matterport/Mask_RCNN
1.1 要求
Python 3.4,TensorFlow 1.3,Keras 2.0.8和其他常见软件包requirements.txt。
亲测Python版本为3.6也可以,建议3.4及以上。
Python安装建议使用 mini conda 安装和管理环境
TensorFlow,Keras 也建议直接使用 conda install tensorflow keras
1.2 MS COCO要求:
要在MS COCO上进行训练或测试,还需要:
pycocotools(下面的安装说明)
MS COCO数据集
下载5K迷你和35K 验证 - 减去迷你的子集。最初的快速R-CNN实现中的更多细节。
安装链接如下:
MS COCO数据集:
(http://cocodataset.org/#home)
迷你:(https://dl.dropboxusercontent.com/s/o43o90bna78omob/instances_minival2014.json.zip?dl=0)
验证 - 减去迷你的:(https://dl.dropboxusercontent.com/s/s3tw5zcg7395368/instances_valminusminival2014.json.zip?dl=0)
快速R-CNN:
(https://github.com/rbgirshick/py-faster-rcnn/blob/master/data/README.md)
如果您使用Docker,则已验证代码可以在 此Docker容器上运行(https://hub.docker.com/r/waleedka/modern-deep-learning/)。
为什么需要安装 pycocotools,经过看源码发现,训练 coco 数据集时用到了pycocotools 这个模块,如果不安装会报错无法正常运行。
1.3 安装
1. 克隆此存储库:https://github.com/matterport/Mask_RCNN
2. 安装依赖项(CD 进入项目根目录,pip3 不行的话可以尝试用 pip)
pip3 install -r requirements.txt在linux安装时,使用此方法一切正常,就是速度会有些慢,因为安装内容较多。
使用Windows安装时可能会遇到shapely,无法安装的情况,解决方法如下:
conda install shapely -y3. 从存储库根目录运行安装程序
python3 setup.py install不报错的话就安装完成了,如果报错可以根据错误提示,网络搜索解决。
python3 不行的话就用 python,还要注意一点你使用哪个python环境安装,后面运行的时候也要用此python环境运行MaskRCNN。
4. 从发布页面下载预先训练的COCO权重(mask_rcnn_coco.h5)。
这里提供一个下载地址,可以直接下载使用:
https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
5.(可选)pycocotools从这些回购中的一个训练或测试MS COCO安装。(这里就是1.2 MS COCO要求,需要安装pycocotools)
Linux:https://github.com/waleedka/coco
Windows:https://github.com/philferriere/cocoapi。您必须在路径上安装Visual C ++ 2015构建工具(有关其他详细信息,请参阅存储库)
经过本人安装测试,可以使用较为简单的方式来安装:
Linux中直接使用:
pip3 install pycocotoolswindows 中需要先安装 Visual C++ 2015,下载地址:https://go.microsoft.com/fwlink/?LinkId=691126
然后执行:注意要和安装MaskRCNN同一Python环境
pip3 install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI上述都执行完成的话,keras版本的MaskRCNN就安装完成了。下面我们动手试用一下。
2. 使用演示
用安装Mask RCNN的python环境打开 jupyter notebook,命令行,或shell运行:
jupyter notebook指定jupyter notebook默认路径,便于打开项目工程可以参考这个博客:https://www.cnblogs.com/awakenedy/p/9075712.html
运行完成后,会自动打开一个网页,如果不能就手动复制一下地址打开。
进入下载的MaskRCNN的根目录,打开 samples/demo.ipynb 文件。
代码如下:
In [1]:导入相关文件,设置参数,下载网络模型等:
由于下载速度慢,建议直接下载
https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
到根目录在运行下面代码
import os
import sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt # Root directory of the project
ROOT_DIR = os.path.abspath("../") # Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/")) # To find local version
import coco %matplotlib inline # Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs") # Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH): utils.download_trained_weights(COCO_MODEL_PATH) # Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")Using TensorFlow backend.In [2]:进行一些参数设置
我们将使用一个经过 MS-COCO 数据集训练的模型。这个模型的配置在coco.py 中的 cococonfig 类中。
为了进行推断,请稍微修改配置以适合任务。为此,对 cococonfig 类进行子类化,并重写需要更改的属性。
class InferenceConfig(coco.CocoConfig): # Set batch size to 1 since we'll be running inference on # one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU GPU_COUNT = 1 IMAGES_PER_GPU = 1 config = InferenceConfig()
config.display()Configurations:
BACKBONE resnet101
BACKBONE_STRIDES [4, 8, 16, 32, 64]
BATCH_SIZE 1
BBOX_STD_DEV [0.1 0.1 0.2 0.2]
COMPUTE_BACKBONE_SHAPE None
DETECTION_MAX_INSTANCES 100
DETECTION_MIN_CONFIDENCE 0.7
DETECTION_NMS_THRESHOLD 0.3
FPN_CLASSIF_FC_LAYERS_SIZE 1024
GPU_COUNT 1
GRADIENT_CLIP_NORM 5.0
IMAGES_PER_GPU 1
IMAGE_CHANNEL_COUNT 3
IMAGE_MAX_DIM 1024
IMAGE_META_SIZE 93
IMAGE_MIN_DIM 800
IMAGE_MIN_SCALE 0
IMAGE_RESIZE_MODE square
IMAGE_SHAPE [1024 1024 3]
LEARNING_MOMENTUM 0.9
LEARNING_RATE 0.001
LOSS_WEIGHTS {'rpn_class_loss': 1.0, 'rpn_bbox_loss': 1.0, 'mrcnn_class_loss': 1.0, 'mrcnn_bbox_loss': 1.0, 'mrcnn_mask_loss': 1.0}
MASK_POOL_SIZE 14
MASK_SHAPE [28, 28]
MAX_GT_INSTANCES 100
MEAN_PIXEL [123.7 116.8 103.9]
MINI_MASK_SHAPE (56, 56)
NAME coco
NUM_CLASSES 81
POOL_SIZE 7
POST_NMS_ROIS_INFERENCE 1000
POST_NMS_ROIS_TRAINING 2000
PRE_NMS_LIMIT 6000
ROI_POSITIVE_RATIO 0.33
RPN_ANCHOR_RATIOS [0.5, 1, 2]
RPN_ANCHOR_SCALES (32, 64, 128, 256, 512)
RPN_ANCHOR_STRIDE 1
RPN_BBOX_STD_DEV [0.1 0.1 0.2 0.2]
RPN_NMS_THRESHOLD 0.7
RPN_TRAIN_ANCHORS_PER_IMAGE 256
STEPS_PER_EPOCH 1000
TOP_DOWN_PYRAMID_SIZE 256
TRAIN_BN False
TRAIN_ROIS_PER_IMAGE 200
USE_MINI_MASK True
USE_RPN_ROIS True
VALIDATION_STEPS 50
WEIGHT_DECAY 0.0001 In [3]:建立网络模型,载入参数
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config) # Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)WARNING:tensorflow:From c:\datas\apps\rj\miniconda3\envs\tf_gpu\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From c:\datas\apps\rj\miniconda3\envs\tf_gpu\lib\site-packages\mask_rcnn-2.1-py3.6.egg\mrcnn\model.py:772: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.类名
模型对对象进行分类并返回类 ID,类 ID 是标识每个类的整数值。有些数据集将整数值赋给它们的类,而有些则没有。例如,在 MS-COCO 数据集中,“Person”类为 1,“Teddy Bear”类为 88。ID 通常是连续的,但并不总是连续的。例如,COCO 数据集具有与 ID70 和 72 相关联的类,但没有与 71 相关联的类。
为了提高一致性与同时支持对来自多个源的数据的训练,我们的 DataSet 类为每个类分配了它自己的顺序整数 ID。例如,如果使用我们的数据集类加载 COCO 数据集,“Person”类将获得类 ID=1(就像 COCO 一样),“Teddy Bear”获得类 78(不同于 COCO)。在将类 ID 映射到类名时,请记住这一点。
要获取类名列表,你需要加载数据集,然后使用类名称属性,如下所示
# Load COCO dataset
dataset = coco.CocoDataset()
dataset.load_coco(COCO_DIR, "train")
dataset.prepare() # Print class names
print(dataset.class_names)我们不希望你为了运行这个演示而下载 COCO 数据集,所以我们在下面列出了类名列表。列表中类名的索引表示其 ID(第一个类是 0,第二个类是 1,第三个类是 2,…等等)。
In [4]:配置类别名
# COCO Class names
# Index of the class in the list is its ID. For example, to get ID of
# the teddy bear class, use: class_names.index('teddy bear')
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']In [5]:读入照片进行识别
原文中采用从 images 文件夹随机读取的方式。我这里注释掉了前两句,采用读取自己准备的照片,这里是我的母校照片。

大家只需要将 image_file 改为自己准备照片地址即可。
# Load a random image from the images folder
#file_names = next(os.walk(IMAGE_DIR))[2]
#image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names))) image_file = os.path.join(IMAGE_DIR, "ahnu.jpg") image = skimage.io.imread(image_file) # Run detection
results = model.detect([image], verbose=1) # Visualize results
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'], class_names, r['scores'])Processing 1 images
image shape: (768, 1024, 3) min: 0.00000 max: 255.00000 uint8
molded_images shape: (1, 1024, 1024, 3) min: -123.70000 max: 151.10000 float64
image_metas shape: (1, 93) min: 0.00000 max: 1024.00000 float64
anchors shape: (1, 261888, 4) min: -0.35390 max: 1.29134 float323. 训练模型
我训练了samples/shapes/train_shapes.ipynb例子,并成功调用了多GPU,如果大家遇到问题可以看我下面的解决方法。。
3.1 MS COCO 培训
我们为 MS COCO 提供预先训练的砝码,使其更容易入手。你可以使用这些权重作为起点来训练您自己在网络上的变化。培训和评估代码在samples/coco/coco.py。你可以在 Jupyter 笔记本中导入此模块(请参阅提供的笔记本中的示例),或者你可以直接从命令行运行它:
# Train a new model starting from pre-trained COCO weights
python3 samples/coco/coco.py train --dataset=/path/to/coco/ --model=coco # Train a new model starting from ImageNet weights
python3 samples/coco/coco.py train --dataset=/path/to/coco/ --model=imagenet # Continue training a model that you had trained earlier
python3 samples/coco/coco.py train --dataset=/path/to/coco/ --model=/path/to/weights.h5 # Continue training the last model you trained. This will find
# the last trained weights in the model directory.
python3 samples/coco/coco.py train --dataset=/path/to/coco/ --model=last你还可以使用以下命令运行 COCO 评估代码:
# Run COCO evaluation on the last trained model
python3 samples/coco/coco.py evaluate --dataset=/path/to/coco/ --model=last应设置培训计划,学习率和其他参数 samples/coco/coco.py。
3.2 对您自己的数据集进行培训
首先阅读关于气球颜色飞溅样本的博客文章。
(https://engineering.matterport.com/splash-of-color-instance-segmentation-with-mask-r-cnn-and-tensorflow-7c761e238b46)
它涵盖了从注释图像到培训再到在示例应用程序中使用结果的过程。
总之,要在您自己的数据集上训练模型,您需要扩展两个类:
Config 该类包含默认配置。对其进行子类化并修改您需要更改的属性。
Dataset 此类提供了一种使用任何数据集的一致方法。它允许您使用新数据集进行培训,而无需更改模型的代码。它还支持同时加载多个数据集,如果要检测的对象在一个数据集中并非全部可用,则此选项非常有用。
见例子samples/shapes/train_shapes.ipynb,samples/coco/coco.py,samples/balloon/balloon.py,和samples/nucleus/nucleus.py。
本人测试了 samples/shapes/train_shapes.ipynb,单 GPU 训练基本都没有问题,使用多 GPU 运行时可能会出现这个问题:
Keras object has no attribute '_is_graph_network'解决方法:
降级Keras到2.1.6可以解决这个问题
pip install keras==2.1.6加速安装
3.3 与官方文件的不同之处
这个实现大部分都遵循 Mask RCNN 文章,但在一些情况下我们偏向于代码简单性和泛化。这些是我们意识到的一些差异。如果您遇到其他差异,请告诉我们。
图像大小调整:为了支持每批训练多个图像,我们将所有图像调整为相同大小。例如,MS COCO上的 1024x1024px 。我们保留纵横比,因此如果图像不是正方形,我们用零填充它。在论文中,调整大小使得最小边为 800px ,最大边为 1000px。
边界框:一些数据集提供边界框,一些仅提供蒙版。为了支持对多个数据集的训练,我们选择忽略数据集附带的边界框,而是动态生成它们。我们选择封装掩码所有像素的最小盒子作为边界框。这简化了实现,并且还使得应用图像增强变得容易,否则图像增强将更难以应用于边界框,例如图像旋转。为了验证这种方法,我们将计算出的边界框与 COCO 数据集提供的边界框进行了比较。我们发现 ~2% 的边界框相差 1px 或更多, ~0.05% 相差 5px 或更多,仅 0.01% 相差 10px 或更多。
学习率:本文使用 0.02 的学习率,但我们发现它太高,并且经常导致重量爆炸,特别是当使用小批量时。这可能与 Caffe 和 TensorFlow 如何计算梯度(总和与批次和 GPU 之间的平均值之间的差异)有关。或者,也许官方模型使用渐变剪辑来避免这个问题。我们使用渐变剪辑,但不要过于激进。我们发现较小的学习率无论如何都会更快收敛,所以我们继续这样做。
4. 总结
花了数个小时完成了这个上手教程,希望能对 MaskRCNN 感兴趣朋友提供帮助。
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

9大技术论坛、60+主题分享,百余家企业、千余名开发者共同相约 2019 AI ProCon!技术驱动产业,聚焦技术实践,倾听大牛分享,和万千开发者共成长。5折优惠票倒计时6天抢购中!

推荐阅读
每天超50亿推广流量、3亿商品展现,阿里妈妈的推荐技术有多牛
面向可解释的NLP:北大、哈工大等提出文本分类的生成性解释框架
物联网将如何影响你的钱包?
写爬虫,怎么可以不会正则呢?
白话中台战略:中台是个什么鬼?
零基础如何自学编程?| 程序员有话说
送50本 Python、数据库、java方面的书,包邮给你!!
鸿蒙霸榜 GitHub,从最初的 Plan B 到“取代 Android”?
9012年了,我不允许你还不会玩 IPFS!

你点的每个“在看”,我都认真当成了喜欢
相关文章:

MNIST数据库介绍及转换
MNIST数据库介绍:MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集。它是NIST数据库的一个子集。MNIST数据库官方网址为:http://yann.lecun.com/exdb/mnist/ ,也可以在windows下直接下载,train-im…

PostgreSQL学习笔记(1)
安装psql brew install postgresql 启动服务 brew services start postgresql 使用psql进入控制台,报错: psql: FATAL: database "<user>" does not exist 看来是没有给我的当前用户创建数据库,使用下面命令进入名为templat…

怎样使一个Android应用不被杀死?(整理)
2019独角兽企业重金招聘Python工程师标准>>> 方法 : 对于一个service,可以首先把它设为在前台运行: public void MyService.onCreate() { super.onCreate(); Notification notification new Notification(android.R.drawable.my_…

Ubuntu 14.04 64位机上用Caffe+MNIST训练Lenet网络操作步骤
1. 将终端定位到Caffe根目录; 2. 下载MNIST数据库并解压缩:$ ./data/mnist/get_mnist.sh 3. 将其转换成Lmdb数据库格式:$ ./examples/mnist/create_mnist.sh 执行完此shell脚本后,会在./examples/mnist下增加两个新…
IJCAI 2019:中国团队录取论文超三成,北大、南大榜上有名
作者 | 神经小姐姐来源 | HyperAI超神经( ID: HyperAI )【导读】AI 顶会 IJCAI 2019 已于 8 月 16 日圆满落幕。在连续 7 天的技术盛会中,与会者在工作坊了解了 AI 技术在各个领域的应用场景,聆听了 AI 界前辈的主题演讲,还有机会…
适合小小白的完整建设流程
时常有中小企业建站的客户问到我要自己建网站,应该怎么开始?建站有一定的技术门槛,首先要明白建站要做的哪些事情,里面有哪些坑,把流程弄清楚了才能避免入坑,半途而废!下面总结了建站的流程还有…
ios项目文件结构 目录的整理
2019独角兽企业重金招聘Python工程师标准>>> /<ProjectName>/Shared/Application # App delegate and related files/Controllers # Base view controllers/Models # Models, Core Data schema etc/Views # Shared views/Libr…

重磅!全球首个可视化联邦学习产品与联邦pipeline生产服务上线
【导读】作为全球首个联邦学习工业级技术框架,FATE支持联邦学习架构体系与各种机器学习算法的安全计算,实现了基于同态加密和多方计算(MPC)的安全计算协议,能够帮助多个组织机构在符合数据安全和政府法规前提下&#x…
SpringBoot之集成swagger2
maven配置 <dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.5.0</version> </dependency> <dependency><groupId>io.springfox</groupId><artifact…
Windows Caffe中MNIST数据格式转换实现
Caffe源码中src/caffe/caffe/examples/mnist/convert_mnist_data.cpp提供的实现代码并不能直接在Windows下运行,这里在源码的基础上进行了改写,使其可以直接在Windows 64位上直接运行,改写代码如下:#include "stdafx.h"…

关于less在DW中高亮显示问题
首先, 找到DW 安装目录。 Adobe Dreamweaver CS5.5\configuration\DocumentTypes 中的,MMDocumentTypes.xml 这个文件,然后用记事本打开,查找CSS 把 CSS 后边加上,less 然后到。C:\Users\Administrator\AppData\Roamin…
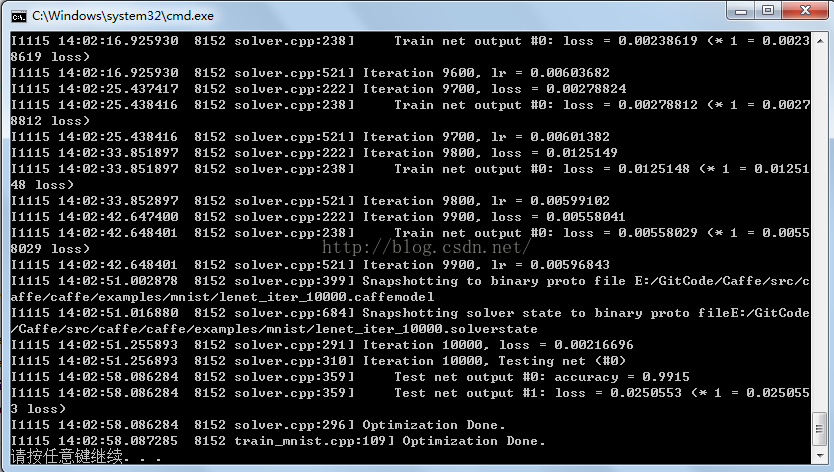
Windows7 64bit VS2013 Caffe train MNIST操作步骤
1. 使用http://blog.csdn.net/fengbingchun/article/details/47905907中生成的Caffe静态库; 2. 使用http://blog.csdn.net/fengbingchun/article/details/49794453中生成的LMDB数据库文件; 3. 新建一个train_mnist控制台工程&#…

NLP机器翻译深度学习实战课程基础 | 深度应用
作者 | 小宋是呢来源 | CSDN博客0.前言深度学习用的有一年多了,最近开始 NLP 自然处理方面的研发。刚好趁着这个机会写一系列 NLP 机器翻译深度学习实战课程。本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:…
个人站点渲染和跳转过滤功能
核心逻辑:在url里加入正则,匹配分类、标签、年月日和其后面的参数,在视图函数接收这些参数,然后进行过滤。 urls.py # 个人站点的跳转 re_path(r^(?P<username>\w)/(?P<condition>tag|category|archive)/(?P<pa…

三步10分钟搞定数据库版本的降迁 (将后台数据库SQL2008R2降为SQL2005版本)
三步10分钟搞定数据库版本的降迁 (将SQL2008R2降为SQL2005版本)转载原文,并注明出处!虽无多少技术含量,毕竟是作者心血原创,希望理解。转自 http://blog.csdn.net/claro/article/details/6449824前思后想仍…

jdbc链接数据库
JDBC简介 JDBC全称为:Java Data Base Connectivity (java数据库连接),可以为多种数据库提供填统一的访问。JDBC是sun开发的一套数据库访问编程接口,是一种SQL级的API。它是由java语言编写完成,所以具有很好的跨平台特性…
Google Protocol Buffers介绍
Google Protocol Buffers(简称Protobuf),是Google的一个开源项目,它是一种结构化数据存储格式,是Google公司内部的混合语言数据标准,是一个用来序列化(将对象的状态信息转换为可以存储或传输的形式的过程)结…

打造 AI Beings,和微信合作…第七代微软小冰的成长之路
8月15日, “第七代微软小冰”年度发布会在北京举行。本次发布会上,微软(亚洲)互联网工程院带来了微软小冰在 Dual AI 领域的新进展,全新升级的部分核心技术,最新的人工智能创造成果,以及更多的合作与产品落地。其中&am…

感知机介绍及实现
感知机(perceptron)由Rosenblatt于1957年提出,是神经网络与支持向量机的基础。感知机是最早被设计并被实现的人工神经网络。感知机是一种非常特殊的神经网络,它在人工神经网络的发展史上有着非常重要的地位,尽管它的能力非常有限,…
不甘心只做输入工具,搜狗输入法上线AI助手,提供智能服务
8月19日搜狗输入法上线了新功能——智能汪仔,在输入法中引入了AI助手,这是搜狗输入法继今年5月推出“语音变声功能”后又一个AI落地产品。 有了智能汪仔AI助手的加持后,搜狗输入法能够在不同的聊天场景,提供丰富多样的表达方式从…

可构造样式表 - 通过javascript来生成css的新方式
可构造样式表是一种使用Shadow DOM进行创建和分发可重用样式的新方法。 使用Javascript来创建样式表是可能的。然而,这个过程在历史上一直是使用document.createElement(style)来创建<style>元素,然后通过访问其sheet属性来获得一个基础的CSSStyle…
模板方法模式与策略模式的区别
2019独角兽企业重金招聘Python工程师标准>>> 模板方法模式:在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。 策略模式:定义一个…

简单明了,一文入门视觉SLAM
作者 | 黄浴转载自知乎【导读】SLAM是“Simultaneous Localization And Mapping”的缩写,可译为同步定位与建图。最早,SLAM 主要用在机器人领域,是为了在没有任何先验知识的情况下,根据传感器数据实时构建周围环境地图,…

大主子表关联的性能优化方法
【摘要】主子表是数据库最常见的关联关系之一,最典型的包括合同和合同条款、订单和订单明细、保险保单和保单明细、银行账户和账户流水、电商用户和订单、电信账户和计费清单或流量详单。当主子表的数据量较大时,关联计算的性能将急剧降低,在…
Windows7上配置Python Protobuf 操作步骤
1、 按照http://blog.csdn.net/fengbingchun/article/details/8183468 中步骤,首先安装Python 2.7.10; 2、 按照http://blog.csdn.net/fengbingchun/article/details/47905907 中步骤,配置、编译Protobuf; 3、 将(2)中生成的pr…
鲜为人知的静态、命令式编程语言——Nimrod
Nimrod是一个新型的静态类型、命令式编程语言,支持过程式、函数式、面向对象和泛型编程风格而保持简单和高效。Nimrod从Lisp继承来的一个特殊特性抽象语法树(AST)作为语言规范的一部分,可以用作创建领域特定语言的强大宏系统。它还…

机器学习进阶-图像形态学操作-腐蚀操作 1.cv2.erode(进行腐蚀操作)
1.cv2.erode(src, kernel, iteration) 参数说明:src表示的是输入图片,kernel表示的是方框的大小,iteration表示迭代的次数 腐蚀操作原理:存在一个kernel,比如(3, 3),在图像中不断的平移,在这个9…
无需成对示例、无监督训练,CycleGAN生成图像简直不要太简单
作者 | Jason Brownlee译者 | Freesia,Rachel编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】图像到图像的转换技术一般需要大量的成对数据,然而要收集这些数据异常耗时耗力。因此本文主要介绍了无需成对示例便能实现图…
Git使用常见问题解决方法汇总
1. 在Ubuntu下使用$ git clone时出现server certificate verification failed. CAfile:/etc/ssl/certs/ca-certificates.crt CRLfile: none 解决方法:在执行$ git clone 之前,在终端输入: export GIT_SSL_NO_VERIFY1 2. 在Windows上更新了…

服务器监控常用命令
在网站性能优化中,我们经常要检查服务器的各种指标,以便快速找到害群之马。大多情况下,我们会使用cacti、nagois或者zabbix之类的监控软件,但是这类软件安装起来比较麻烦,在一个小型服务器,我们想尽快找到问…