边界框的回归策略搞不懂?算法太多分不清?看这篇就够了

作者 | fivetrees
来源 | https://zhuanlan.zhihu.com/p/76477248
本文已由作者授权,未经允许,不得二次转载
【导读】目标检测包括目标分类和目标定位 2 个任务,目标定位一般是用一个矩形的边界框来框出物体所在的位置,关于边界框的回归策略,不同算法其回归方法不一。本文主要讲述:1.无 Anchor 的目标检测算法:YOLOv1,CenterNet,CornerNet 的边框回归策略;2.有 Anchor 的目标检测算法:SSD,YOLOv2,Faster R-CNN 的边框回归策略。
无Anchor的目标检测算法边框回归策略
1. YOLOv1
原文链接:
https://pjreddie.com/media/files/papers/yolo.pdf,
解读链接:
https://zhuanlan.zhihu.com/p/75106112
YOLOv1 先将每幅图片 reshape 到 448x448 大小,然后将图片分成 7x7 个单元格,每个格子预测 2 个边界框,而每个边界框的位置坐标有 4 个,分别是 x,y,w,h。其中 x,y 是边界框相对于其所在单元格的偏移(一般是相对于单元格左上角坐标点的偏移,在这里每个正方形单元格的边长视为 1,故 x,y在 [0,1] 之间);w,h 分别是预测的边界框宽,高相对于整张图片宽,高的比例,也是在 [0,1] 之间。YOLOv1 中回归选用的损失函数是均方差损失函数,因此我们训练时,有了预测的边界框位置信息,有了gtbbox,有了损失函数就能按照梯度下降法,优化我们网络的参数,使网络预测的边界框更接近与gt_bbox。

2. CornerNet
原文链接:
https://arxiv.org/pdf/1808.01244.pdf
代码链接:
https://github.com/princeton-vl/CornerNet
这是在 ECCV2018 发表的一篇文章,文章将目标检测问题当作关键点检测问题来解决,具体来说就是通过检测目标框的左上角和右下角两个关键点得到预测框,因此 CornerNet 算法中也没有 anchor 的概念,在目标检测领域 Anchor 大行其道的时候,这种无 Anchor 的做法在目标检测领域是比较创新的而且取得的效果还很不错。此外,整个检测网络的训练是从头开始的,并没有基于预训练的分类模型,这使得用户能够自由设计特征提取网络,不用受预训练模型的限制。
算法结构
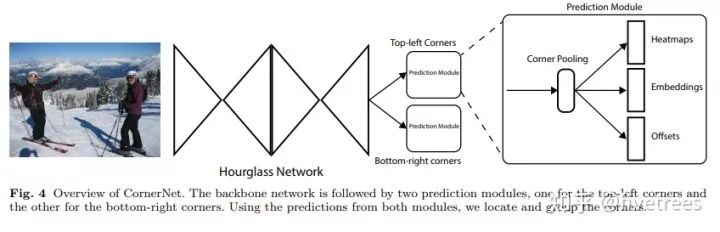
首先原图经过 1 个 7×7 的卷积层将输入图像尺寸缩小为原来的 1/4 (论文中输入图像大小是 511×511,缩小后得到 128×128 大小的输出),然后经过特征提取网络 Hourglass network 提取特征,Hourglass module 后会有两个输出分支模块,分别表示左上角点预测分支和右下角点预测分支,每个分支模块经过应该 Corner pooling 层后输出3个信息:Heatmaps、 Embeddings 和 Offsets。
1. Corner pooling:更好的定位角点,一个角点的定位不能只依靠局部信息,Corner pooling 层有两组特征图,相同的像素点,汇集值一个是该像素水平向右的最大值,一个是垂直向下的最大值,之后两组特征图求和;
2. Heatmaps:预测角点位置信息,一个支路预测左上角,一个支路预测右下角。Heatmaps 可以用维度为 CxHxW 的特征图表示,其中 C 表示目标的类别(不包含背景类),这个特征图的每个通道都是一个 mask,mask 的每个值是 0 到 1 ,表示该点是角点的分数(注意一个通道只预测同一类别的物体的角点信息);
3. Embeddings:用来对预测的角点分组,也就是找到属于同一个目标的左上角角点和右下角角点,同一个预测框的一对角点的角距离短。如下图:

4. Offsets:调整角点位置,使得获得的边界框更紧密。
Corner poolin
1)有无Corner pooling的预测框对比

可以看出有了Corner pooling,预测的目标边界框的角点,位置信息更加的精确了。
2)主要思想

如上图所示,通常一个目标的边界框的角点是不包含该目标的局部特征信息的,那么我们如何判断某一个位置的像素点是否是某一个目标的角点呢?拿左上角点来说,对于左上角点的上边界,我们需要从左往右看寻找目标的特征信息,对于左上角点的左边界,我们需要从上往下看寻找目标的特征信息(比如上图中的第一张图,左上角点的右边有目标顶端的特征信息:第一张图的头顶,左上角点的下边有目标左侧的特征信息:第一张图的手,因此如果左上角点经过池化操作后能有这两个信息,那么就有利于该点的预测,这就是Corner pooling的主要思想)。
3)具体做法
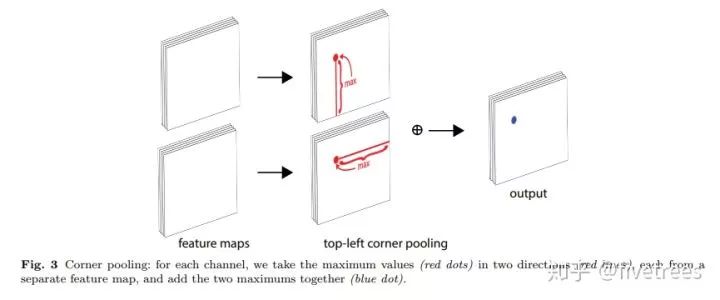
如 Figure3 所示,Corner pooling 层有 2 个输入特征图,特征图的宽高分别用 W 和 H 表示,假设接下来要对图中红色点(坐标假设是(i,j))做 corner pooling,那么首先找到像素点以下(包括本身)即 (i,j) 到 (i,H)(左角点的最下端)这一列中的最大值,然后将这张特征图中 (i,j) 位置的特征值用这个最大值替代,类似于找到 Figure2 中第一张图的左侧手信息;然后找到 (i,j) 到 (W,j)(左角点的最右端)的最大值,然后将这张特征图中 (i,j) 位置的特征值用这个最大值替代,类似于找到 Figure2 中第一张图的头顶信息,然后将这 2 个特征图中的 (i,j) 位置的特征值相加,也就是将找到的这两个最大值相加得到 (i,j) 点的值(对应 Figure3 最后一个图的蓝色点)。
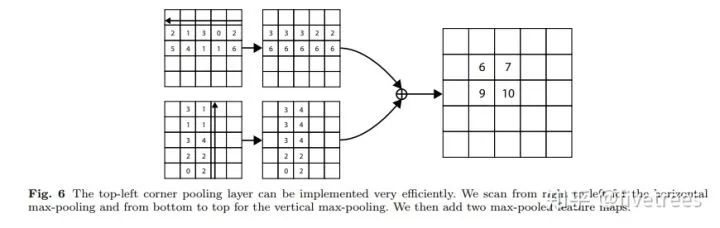
对于右下角点的 Corner pooling 操作类似,只不过找最大值变成从 (i,j) 到 (0,j) 和从 (i,j) 到 (i,0) 中找。比如 Figure6 中,第一张特征图,比如第 2 行的第 1 个点(值为2),其右边同一行的最大值是 3 ,故经过 Corener Pooling 后,其值变为3,其他同理;第 2 张特征图,第 2 列的第一个点为 3,其下面所在列的最大值(包括本身)也是 3,因此经过 Corener pooling 之后,其中也变为 3,最后将 2 张特征图对应位置的点的特征值相加,得到一张特征图。
Heatmaps
CornerNet 的第一个输出是 headmaps,网络一共输出 2 组 Heatmap,一组预测左上角点,一组预测右下角点。每组 Heatmap 有 C 个通道,代表 C 类。每个角点,只要 ground truth处的点为postive,其余位置为negative,因为在 ground-truth 附近的负样本也可以得到 overlap 较大的box ,满足要求。因此,不同负样本的点的损失函数权重不是相等的,而是在以 ground-truth 为中心圆内呈非归一化高斯分布,圆半径以在圆内的点形成的 box 与 ground-truth 的 IoU 不小于 t(t=0.7) 为标准,如下图所示:

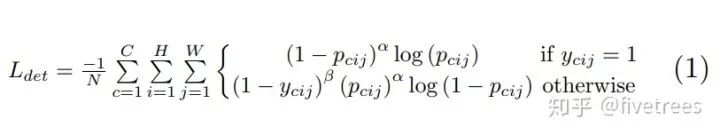
上图是针对角点预测(headmaps)的损失函数,整体上是改良版的 Focal loss 。几个参数的含义:N 为整张图片中目标的数量,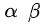 为控制每个点的权重的超参数,具体来说,α 参数用来控制难易分类样本的损失权重(在文章中
为控制每个点的权重的超参数,具体来说,α 参数用来控制难易分类样本的损失权重(在文章中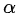 为 2,
为 2, 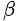 为 4),pcij 表示预测的 heatmaps 在第 c 个通道(类别 c )的 (i,j) 位置的值,ycij 表示对应位置的 ground truth,ycij=1 时候的损失函数就是 focal loss;ycij 等于其他值时表示 (i,j) 点不是类别 c 的目标角点,照理说此时 ycij 应该是 0(大部分算法都是这样处理的),但是这里 ycij 不是0,而是用基于 ground truth 角点的高斯分布计算得到,因此距离 ground truth 比较近的 (i,j) 点的 ycij 值接近 1,这部分通过 β 参数控制权重,这是和Focal loss 的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近 ground truth 的误检角点组成的预测框仍会和 ground truth 有较大的重叠面积。
为 4),pcij 表示预测的 heatmaps 在第 c 个通道(类别 c )的 (i,j) 位置的值,ycij 表示对应位置的 ground truth,ycij=1 时候的损失函数就是 focal loss;ycij 等于其他值时表示 (i,j) 点不是类别 c 的目标角点,照理说此时 ycij 应该是 0(大部分算法都是这样处理的),但是这里 ycij 不是0,而是用基于 ground truth 角点的高斯分布计算得到,因此距离 ground truth 比较近的 (i,j) 点的 ycij 值接近 1,这部分通过 β 参数控制权重,这是和Focal loss 的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近 ground truth 的误检角点组成的预测框仍会和 ground truth 有较大的重叠面积。
Offset
从 heatmap 层回到 input image 会有精度损失(不一定整除存在取整),对小目标影响大,因此预测 location offset ,调整 corner 位置。损失函数如下:
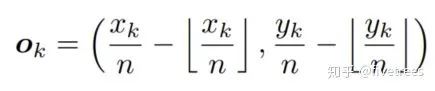

Xk,Yk 是角点的坐标,n 为下采样的倍数,公式中符合为向下取整。
O^k 代表 Offsets 的 predicted offset;Ok 代表 gt 的 offset。
Embeddings
负责检测哪个 top-left corner 和哪个 bottom-right corner 是一对,组成一个 box,同一个 box 的 corner 距离短。top-left 和 bottom-right corner 各预测一个 embedding vector,距离小的 corner 构成一个 box (一个图多个目标,多对点,因此确定 group 是必要的)embedding 这部分的训练是通过两个损失函数实现的,如下图:

etk 表示第 k 个目标的左上角角点的 embedding vector,ebk 表示第 k 个目标的右下角角点的 embedding vector,ek 表示 etk 和 ebk 的均值。公式 4 用来缩小属于同一个目标(第 k 个目标)的两个角点的 embedding vector( etk 和 ebk )距离。公式 5 用来扩大不属于同一个目标的两个角点的 embedding vector 距离。Pull loss 越小,则同一 object 的左上角和右下角的 embedding 得分距离越小;Push loss 越小,则不同 object 的左上角和右下角的 embedding 得分距离越大。
总损失函数
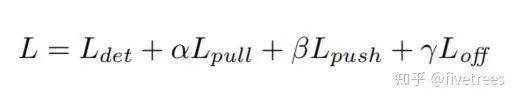
其中,α, β, γ 是超参数,分别取 0.1, 0.1, 1。
回归策略
说了那么多,CornerNet 主要是通过预测目标的左上角点和右下角点,来完全目标的边界框预测。Corner pooling 负责更好的找到角点位置,headmaps输出角点位置信息,Embeddings 负责找到同一个目标的一组角点,Offsets 用于对角点微调,使预测框更加精准。
补充
CornerNet 通过检测物体的左上角点和右下角点来确定目标,但在确定目标的过程中,无法有效利用物体的内部的特征,即无法感知物体内部的信息,因为在判断两个角点是否属于同一物体时,缺乏全局信息的辅助,因此很容易把原本不是同一物体的两个角点看成是一对角点,因此产生了很多错误目标框,另外,角点的特征对边缘比较敏感,这导致很多角点同样对背景的边缘很敏感,因此在背景处也检测到了错误的角点从而导致该类方法产生了很多误检 (错误目标框)。
其实不光是基于关键点的 one-stage 方法无法感知物体内部信息,几乎所有的 one-stage 方法都存在这一问题。与下面介绍的CenterNet同名的还有一篇文章,文章主要基于CorenNet出现的误检问题,作了改进,文章除了预测左上角点和右下角点外,还额外预测了目标的中心点,用三个关键点而不是两个点来确定一个目标,使网络花费了很小的代价便具备了感知物体内部信息的能力,从而能有效抑制误检。大家可以参考以下资料:
论文:
https://arxiv.org/pdf/1904.08189.pdf
解读:
https://zhuanlan.zhihu.com/p/62789701
代码:
https://github.com/Duankaiwen/CenterNet
3. CenterNet
论文链接:
https://arxiv.org/pdf/1904.07850.pdf
代码链接:
https://github.com/xingyizhou/CenterNet
这里区别一下呀,今年好像有 2 篇称 CenterNet 的论文,我要介绍的这篇名为“Objects as Points”,另外一篇就是上面提到的中科院牛津华为诺亚提出的,名为“CenterNet: Keypoint Triplets for Object Detection”是基于CornerNet 作的改进。这篇 CenterNet 算法也是 anchor-free 类型的目标检测算法,基于点的思想和 CornerNet 是相似的,方法上做了较大的调整,与 Corenet 不同的是,CenterNet 预测的是目标的中心点,然后再预测目标框的宽和高,来生成预测框。此外此网络还能作 3D 目标检测和人体姿态估计。
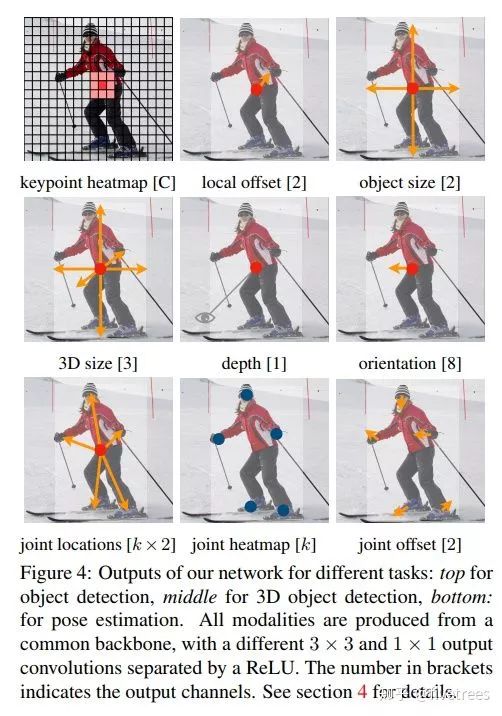
与CornerNet对比
1. CenterNet,从算法名也可以看出这个算法要预测的是目标的中心点,而不再是 CornerNet 中的 2 个角点;相同点是都采用热力图(heatmap)来实现,都引入了预测点的高斯分布区域计算真实预测值,同时损失函数一样(修改版 Focal loss,网络输出的热力图也将先经过 sigmod 函数归一化成 0 到 1 后再传给损失函数)。另外 CenterNet 也不包含 corner pooling 等操作,因为一般目标框的中心点落在目标上的概率还是比较大的,因此常规的池化操作能够提取到有效的特征,这是其一。
2. CerterNet 中也采用了和 CornerNet 一样的偏置(offset)预测,这个偏置表示的是标注信息从输入图像映射到输出特征图时由于取整操作带来的坐标误差,只不过 CornerNet 中计算的是 2 个角点的 offset,而 CenterNet计算的是中心点的 offset 。这部分还有一个不同点:损失函数,在CornerNet 中采用 SmoothL1 损失函数来监督回归值的计算,但是在CenterNet 中发现用 L1 损失函数的效果要更好,差异这么大是有点意外的,这是其二。
3、CenterNet 直接回归目标框尺寸,最后基于目标框尺寸和目标框的中心点位置就能得到预测框,这部分和 CornerNet 是不一样的,因为 CornerNet 是预测 2 个角点,所以需要判断哪些角点是属于同一个目标的过程,在CornerNet 中通过增加一个 corner group 任务预测 embedding vector,最后基于 embedding vector 判断哪些角点是属于同一个框。
而 CenterNet 是预测目标的中心点,所以将 CornerNet 中的 corner group 操作替换成预测目标框的 size(宽和高),这样一来结合中心点位置就能确定目标框的位置和大小了,这部分的损失函数依然采用 L1 损失,这是其三。
回归策略
CenterNet 对目标框的回归策略,采用先预测目标的中心点位置,然后再预测目标框的宽和高来达到目标检测。预测中心点的偏移采用修改版的 Focal loss,对于热力图中中心点到原图映射的偏差,采样 L1 损失函数,对于目标框宽和高的预测也是采用 L1 损失函数。
有 Anchor 的目标检测算法边框回归策略
1. Faster R-CNN
关于论文和解读,网上有很多大佬讲的很好(https://zhuanlan.zhihu.com/p/31426458),这里其他方面我就不说了,主要谈一下,Faster R-CNN 的回归策略。
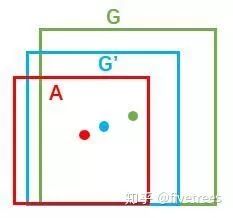

X 为预测框的中心点坐标,Xa 为 Anchor 的中心点坐标,X 为 gt_bbox 的中心点坐标( y,w,h 同理),目标是使变换因子 tx 跟 tx* 差距最小,损失函数为 Smooth L1 损失函数。
2. YOLOv2
YOLOv2 中作者引入了 Faster R-CNN 中类似的 anchor,但是回归策略不同,对 bbox 中心坐标的预测不是基于 anchor 坐标的偏移量得到的,而是采用了 v1 中预测 anchor 中心点相对于对于单元格左上角位置的偏移,如下图
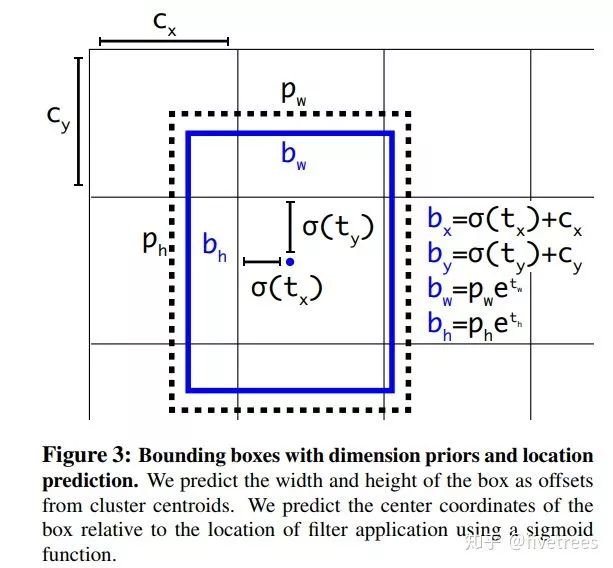
上图中 tx,ty,tw,th 为坐标变换系数,Cx,Cy 为 Anchor 中心的坐标,Pw,Ph 为 Anchor 的宽和高,tx 和 tw 是 Anchor 中心点相对于其所在单元格左上角点坐标的偏移,在这里作者说之所以没有采样 Faster R-CNN 中的回归策略是因为 Faster R-CNN 对于预测框中心点的回归太不稳定了,而YOLOv2 将中心点能够固定在单元格范围之内。损失函数采样的是 MSE 均方差损失函数,回归损失函数输入的参数分别是 Anchor 到预测框的坐标变换系数和 Anchor 到 gt_bbox 的坐标变换系数。
3. SSD
论文链接:
https://arxiv.org/pdf/1512.02325.pdf

回归策略基本和 Faster R-CNN 中一致,对边界框的回归的损失函数也是采样的 Smooth L1 损失函数,不过这里的先验框名字叫 Default Box 和 Faster R-CNN 中的 Anchor 叫法不一样。
参考文献
https://arxiv.org/pdf/1512.02325.pdf
https://arxiv.org/pdf/1808.01244.pdf
https://arxiv.org/pdf/1506.01497.pdf
https://blog.csdn.net/u014380165/article/details/92801206
https://blog.csdn.net/u014380165/article/details/83032273
https://zhuanlan.zhihu.com/p/62789701
(*本文为AI科技大本营转载文章,转载请联系作者)
◆
福利时刻
◆
距离大会参与通道关闭还有 1 天,扫描下方二维码或点击阅读原文,马上参与!(学生票特享 598 元,团购票每人立减优惠,倒计时 1 天!)

推荐阅读
从垃圾分类到千行百业,如何打响AI“落地战”?
2亿日活,日均千万级视频上传,快手推荐系统如何应对技术挑战
在图数据上做机器学习,应该从哪个点切入?
Docker容器化部署Python应用
AI 假冒老板骗取 24.3 万美元
编程吸金榜:你排第几?网友神回应了!
吴子宁:手握 280 多项专利的斯坦福技术先锋 | 人物志
阿里云 CDN 业务基于边缘容器的云原生转型实践

你点的每个“在看”,我都认真当成了喜欢
相关文章:
人脸识别引擎SeetaFaceEngine简介及在windows7 vs2013下的编译
SeetaFaceEngine是开源的C人脸识别引擎,无需第三方库,它是由中科院计算所山世光老师团队研发。它的License是BSD-2.SeetaFaceEngine库包括三个模块:人脸检测(detection)、面部特征点定位(alignment)、人脸特征提取与比对(identification)。人…

当移动数据分析需求遇到Quick BI
我叫洞幺,是一名大型婚恋网站“我在这等你”的资深老员工,虽然在公司五六年,还在一线搬砖。“我在这等你”成立15年,目前积累注册用户高达2亿多,在我们网站成功牵手的用户达2千多万。目前我们的公司在CEO的英名带领下&…

为什么选择数据分析师这个职业?
我为什么选择做数据分析师? 我大学专业是物流管理,学习内容偏向于管理学和经济学,但其实最感兴趣的还是心理学,即人在各种刺激下反应的机制以及原理。做数据分析师,某种意义上是对群体行为的研究和量化,两者…
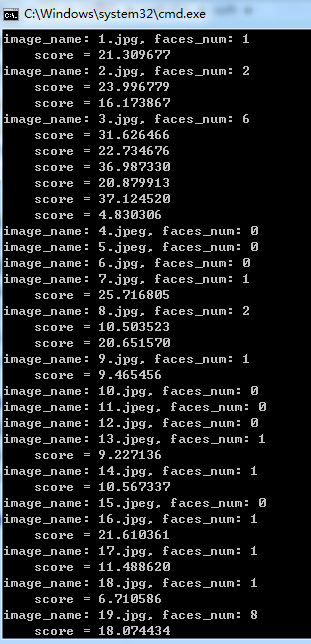
人脸识别引擎SeetaFaceEngine中Detection模块使用的测试代码
人脸识别引擎SeetaFaceEngine中Detection模块用于人脸检测,以下是测试代码:int test_detection() {std::vector<std::string> images{ "1.jpg", "2.jpg", "3.jpg", "4.jpeg", "5.jpeg", "…
基于Pygame写的翻译方法
发布时间:2018-11-01技术:pygameeasygui概述 实现一个翻译功能,中英文的互相转换。并可以播放翻译后的内容。 翻译接口调用的是百度翻译的api接口。详细 代码下载:http://www.demodashi.com/demo/14326.html 一、需求分析 使用pyg…

冠军奖3万元!CSDN×易观算法大赛开赛啦
伴随着5G、物联网与大数据形成的后互联网格局的逐步形成,日益多样化的用户触点、庞杂的行为数据和沉重的业务体量也给我们的数据资产管理带来了不容忽视的挑战。为了建立更加精准的数据挖掘形式和更加智能的机器学习算法,对不断生成的用户行为事件和各类…
快速把web项目部署到weblogic上
weblogic简介 BEA WebLogic是用于开发、集成、部署和管理大型分布式Web应用、网络应用和数据库应 用的Java应用服务器。将Java的动态功能和Java Enterprise标准的安全性引入大型网络应用的开发、集成、部署和管理之中。 BEA WebLogic Server拥有处理关键Web应用系统问题所需的性…
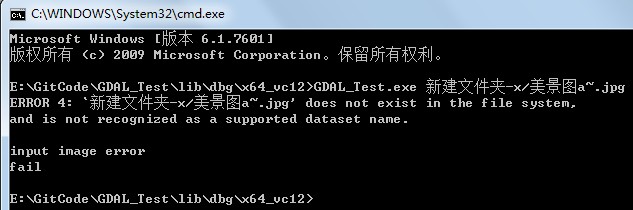
使GDAL库支持中文路径或中文文件名的处理方法
之前生成的gdal 2.1.1动态库,在通过命令行执行时,遇到有中文路径或中文图像名时,GDALOpen函数不能正确的被调用,如下图:解决方法:1. 在所有使用GDALAllRegister();语句后面加上一句CPLSetConfigOption…

创新工场论文入选NeurIPS 2019,研发最强“AI蒙汗药”
9月4日,被誉为机器学习和神经网络领域的顶级会议之一的 NeurIPS 2019 揭晓收录论文名单,创新工场人工智能工程院的论文《Learning to Confuse: Generating Training Time Adversarial Data with Auto-Encoder》被接收在列。这篇论文围绕现阶段人工智能系…
Flutter环境搭建(Windows)
SDK获取 去官方网站下载最新的安装包 ,或者在Github中的Flutter项目去 下载 。 将下载的安装包解压 注意:不要将Flutter安装到高权限路径,例如 C:\Program Files\ 配置环境变量,在Path中添加flutter\bin的全路径(如:D…
Android在eoe分享一篇推荐开发组件或者框架的文章
http://www.eoeandroid.com/thread-311194-1-1.html y4078275315 主题 62 帖子 352 e币实习版主 积分314发消息电梯直达楼主 回复 发表于 2013-11-7 09:58:45 | 只看该作者 |只看大图 34本帖最后由 y407827531 于 2013-11-28 15:07 编辑感谢版主推荐,本贴会持续更新…

如何打造高质量的机器学习数据集?这份超详指南不可错过
作者 | 周岩,夕小瑶,霍华德,留德华叫兽转载自知乎博主『运筹OR帷幄』导读:随着计算机行业的发展,人工智能和数据科学近几年成为了学术和工业界关注的热点。特别是这些年人工智能的发展日新月异,每天都有新的…

人脸识别引擎SeetaFaceEngine中Alignment模块使用的测试代码
人脸识别引擎SeetaFaceEngine中Alignment模块用于检测人脸关键点,包括5个点,两个眼的中心、鼻尖、两个嘴角,以下是测试代码:int test_alignment() {std::vector<std::string> images{ "1.jpg", "2.jpg"…

微软宣布 Win10 设备数突破8亿,距离10亿还远吗?
开发四年只会写业务代码,分布式高并发都不会还做程序员? >>> 微软高管 Yusuf Mehdi 昨天在推特发布了一条推文,宣布运行 Windows 10 的设备数已突破 8 亿,比半年前增加了 1 亿。 根据之前的报道,两个月前 W…
领导者必须学会做的十件事情
在这个世界上你可以逃避很多事情并且仍然能够获得成功,但是有些事情你根本就无法走捷径。商业领导者们并不存在于真空之中。成功总是与竞争有关。你可能拥有伟大的产品、服务、概念、战略、团队等等,如果它不能从某种程度上超越竞争对手,这对…

人脸识别引擎SeetaFaceEngine中Identification模块使用的测试代码
人脸识别引擎SeetaFaceEngine中Identification模块用于比较两幅人脸图像的相似度,以下是测试代码:int test_recognize() {const std::string path_images{ "E:/GitCode/Face_Test/testdata/recognization/" };seeta::FaceDetection detector(&…

李沐亲授加州大学伯克利分校深度学习课程移师中国,现场资料新鲜出炉
2019 年 9 月 5 日,AI ProCon 2019 在北京长城饭店正式拉开帷幕。大会的第一天,以亚马逊首席科学家李沐面对面亲自授课完美开启!“大神”,是很多人对李沐的印象。除了是亚马逊首席科学家李,李沐还拥有多重身份…
对Python课的看法
学习Python已经有两周的时间了,我是计算机专业的学生,我抱着可以多了解一种语言的想法报了Python的选修课,从第一次听肖老师的课开始,我便感受到一种好久没有感受到的课堂氛围,感觉十分舒服,不再是那种高中…
维护学习的一点体会与看法
学习维护的知识也有2个月了,对于知识的学习也有一定的看法。接下来我就说一下我对学习的看法。首先,你要学会自学,无论是看书还是上网查资料,维护的知识很多很杂,想要人一下子来教是不可能。只能是自己慢慢的学。其次&…
Dlib简介及在windows7 vs2013编译过程
Dlib是一个C库,包含了许多机器学习算法。它是跨平台的,可以应用在Windows、Linux、Mac、embedded devices、mobile phones等。它的License是Boost Software License 1.0,可以商用。Dlib的主要特点可以参考官方网站:http://dlib.ne…

六大主题报告,四大技术专题,AI开发者大会首日精华内容全回顾
9月6-7日,2019中国AI开发者大会(AI ProCon 2019) 在北京拉开帷幕。本次大会由新一代人工智能产业技术创新战略联盟(AITISA)指导,鹏城实验室、北京智源人工智能研究院支持,专业中文IT技术社区CSD…
Git安装配置(Linux)
使用yum安装Git yum install git -y 编译安装 # 安装依赖关系 yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel # 编译安装 tar -zxf git-2.0.0.tar.gz cd git-2.0.0 make configure ./configure --prefix/usr make make install 配置Git…
卷积神经网络(CNN)代码实现(MNIST)解析
在http://blog.csdn.net/fengbingchun/article/details/50814710中给出了CNN的简单实现,这里对每一步的实现作个说明:共7层:依次为输入层、C1层、S2层、C3层、S4层、C5层、输出层,C代表卷积层(特征提取),S代表降采样层…
一点感悟和自勉
来学习linux,其实目的很简单,也很现实,就是为了学成之后找一份好的工作,能够养家糊口。 接触了几天,感觉挺难的,可能是因为我没有基础的原因吧,以前电脑只是用来打游戏和看电影,第一…

入门数据分析师,从了解元数据中心开始
作者丨凯凯连编辑丨Zandy来源 | 大数据与人工智能(ID:ai-big-data)【导读】上一篇文章,我们简单讲解了数据仓库的概念,并介绍了它的分层架构设计,相信大家对数据仓库体系已经有一定的了解了。那么ÿ…
PhpMyAdmin的简单安装和一个mysql到Redis迁移的简单例子
1.phpmyadmin的安装 sudo apt-get install phpmyadmin 之后发现http://localhost/phpmyadmin显示没有此url,于是想到本机上能显示的网页都在/var/www文件夹内,因此执行命令行:sudo ln /usr/share/phpmyadmin /var/www 这样就能使用了; 之…
聊聊flink的HistoryServer
为什么80%的码农都做不了架构师?>>> 序 本文主要研究一下flink的HistoryServer HistoryServer flink-1.7.2/flink-runtime-web/src/main/java/org/apache/flink/runtime/webmonitor/history/HistoryServer.java public class HistoryServer {private st…
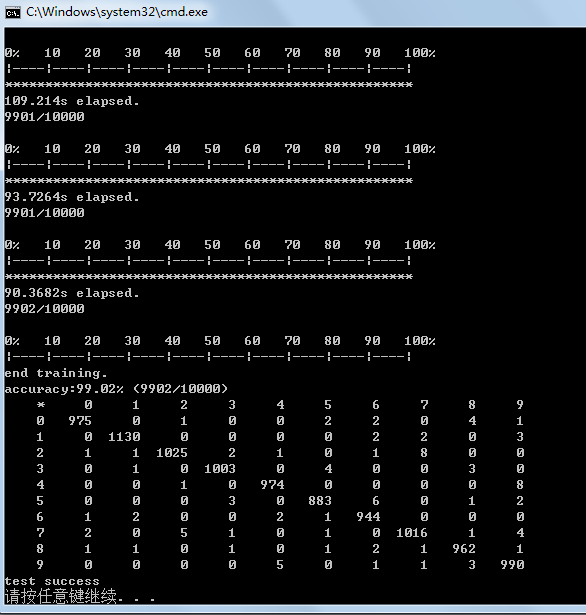
深度学习开源库tiny-dnn的使用(MNIST)
tiny-dnn是一个基于DNN的深度学习开源库,它的License是BSD 3-Clause。之前名字是tiny-cnn是基于CNN的,tiny-dnn与tiny-cnn相关又增加了些新层。此开源库很活跃,几乎每天都有新的提交,因此下面详细介绍下tiny-dnn在windows7 64bit …

如何学习SVM?怎么改进实现SVM算法程序?答案来了
编辑 | 忆臻来源 | 深度学习这件小事(ID:DL_NLP)【导读】在 3D 动作识别领域,需要用到 SVM(支持向量机算法),但是现在所知道的 SVM 算法很多很乱,相关的程序包也很多,有什…
跟着石头哥哥学cocos2d-x(三)---2dx引擎中的内存管理模型
2019独角兽企业重金招聘Python工程师标准>>> 2dx引擎中的对象内存管理模型,很简单就是一个对象池引用计数,本着学好2dx的好奇心,先这里开走吧,紧接上面两节,首先我们看一个编码场景代码: hello…