概率论中均值、方差、标准差介绍及C++/OpenCV/Eigen的三种实现
概率论是用于表示不确定性声明(statement)的数学框架。它不仅提供了量化不确定性的方法,也提供了用于导出新的不确定性声明的公理。在人工智能领域,概率论主要有两种用途。首先,概率法则告诉我们AI系统如何推理,据此我们设计一些算法来计算或者估算由概率论导出的表达式。其次,我们可以用概率和统计从理论上分析我们提出的AI系统的行为。
概率论使我们能够作出不确定的声明以及在不确定性存在的情况下进行推理,而信息论使我们能够量化概率分布中的不确定性总量。
1. 为什么要使用概率
机器学习通常必须处理不确定量,有时也可能需要处理随机(非确定性的)量。不确定性和随机性可能来自多个方面。
不确定性有三种可能的来源:(1)、被建模系统内在的随机性。(2)、不完全观测。即使是确定的系统,当我们不能观测到所有驱动系统行为的变量时,该系统也会呈现随机性。(3)、不完全建模。当我们使用一些必须舍弃某些观测信息的模型时,舍弃的信息会导致模型的观测出现不确定性。
在很多情况下,使用一些简单而不确定的规则要比复杂而确定的规则更为实用,即使真正的规则是确定的并且我们建模的系统可以足够精确地容纳复杂的规则。
概率可以被看作是用于处理不确定性的逻辑扩展。逻辑提供了一套形式化的规则,可以在给定某些命题是真或假的假设下,判断另外一些命题是真的还是假的。概率论提供了一套形式化的规则,可以在给定一些命题的似然后,计算其它命题为真的似然。
2. 随机变量
随机变量(random variable)是可以随机地取不同值的变量。就其本身而言,一个随机变量只是对可能的状态的描述;它必须伴随着一个概率分布来指定每个状态的可能性。
随机变量可以是离散的或者连续的。离散随机变量拥有有限或者可数无限多的状态。注意这些状态不一定非要是整数;它们也可能只是一些被命名的状态而没有数值。连续随机变量伴随着实数值。
随机变量:给定样本空间(S、F),如果其上的实值函数X: S→R是F(实值)可测函数,则称X为(实值)随机变量。初等概率论中通常不涉及到可测性的概念,而直接把任何X:S→R的函数称为随机变量。
如果X指定给概率空间S中每一个事件e有一个实数X(e),同时针对每一个实数r都有一个事件集合Ar与其相对应,其中Ar={e:X(e)≤r},那么X被称作随机变量。随机变量实质上是函数。如果随机变量X的取值是有限的或者是可数无穷尽的值,X={x1,x2,x3,…,} 则称X为离散随机变量。如果X由全部实数或者由一部分区间组成,X={x|a≤x≤b}, -∞<a<b<∞,则称X为连续随机变量,连续随机变量的取值是不可数及无穷尽的。
随机变量在不同的条件下由于偶然因素影响,其可能取各种随机变量不同的值,具有不确定性和随机性,但这些取值落在某个范围的概率是一定的,此种变量称为随机变量。随机变量可以是离散型的,也可以是连续型的。简单地说,随机变量是指随机事件的数量表现。
随机试验结果的量的表示。一个随机试验的可能结果(称为基本事件)的全体组成一个基本空间Ω。随机变量x是定义于Ω上的函数,即对每一基本事件ω∈Ω,有一数值x(ω)与之对应。
3. 概率分布
概率分布(probability distribution)用来描述随机变量或一簇随机变量在每一个可能取到的状态的可能性大小。我们描述概率分布的方式取决于随机变量是离散的还是连续的。
(1)、离散型变量和概率质量函数:
离散型变量的概率分布可以用概率质量函数(probability mass function, PMF)来描述。我们通常用大写字母P来表示概率质量函数。通常每一个随机变量都会有一个不同的概率质量函数,并且读者必须根据随机变量来推断所使用的PMF,而不是根据函数的名字来推断。
概率质量函数将随机变量能够取得的每个状态映射到随机变量取得该状态的概率。概率质量函数可以同时作用于多个随机变量。这种多个变量的概率分布被称为联合概率分布(joint probability distribution)。P(X=x,Y=y)表示X=x和Y=y同时发生的概率。我们也可以简写为P(x,y)。
如果一个函数P是随机变量x的PMF,必须满足下面这几个条件:
1)、P的定义域必须是x所有可能状态的集合。
2)、x∈X, 0≤P(x)≤1.不可能发生的事件概率为0,并且不存在比这概率更低的状态。类似的,能够确保一定发生的事件概率为1,而且不存在比这概率更高的状态。
3)、∑x∈XP(x)=1.我们把这条性质称之为归一化的(normalized)。如果没有这条性质,当我们计算很多事件其中之一发生的概率时可能会得到大于1的概率。
(2)、连续型变量和概率密度函数:
当我们研究的对象是连续型随机变量时,我们用概率密度函数(probability density function, PDF)而不是概率质量函数来描述它的概率分布。如果一个函数p是概率密度函数,必须满足下面这几个条件:
1)、p的定义域必须是x所有可能状态的集合。
2)、x∈X,p(x)≥0.注意,我们并不要求p(x)≤1。
3)、∫p(x)dx=1.
概率密度函数p(x)并没有直接对特定的状态给出概率,相对的,它给出了落在面积为δx的无限小的区域内的概率为p(x) δx。我们可以对概率密度函数求积分来获得点集的真实概率质量。特别地,x落在集合S中的概率可以通过p(x)对这个集合求积分来得到。在单变量的例子中,x落在区间[a, b]的概率是∫[a,b]p(x)dx
概率分布(probability distribution):或简称分布,是概率论的一个概念。使用时可以有以下两种含义:
(1)、广义地,它指称随机变量的概率性质,当我们说概率空间(Ω、F、P)中的两个随机变量X和Y具有同样的分布(或同分布)时,我们是无法用概率P来区别它们的。换言之,称X和Y为同分布的随机变量,当且仅当对任意事件A∈F,有P(X∈A)=P(Y∈A)成立。但是,不能认为同分布的随机变量是相同的随机变量。事实上即使X与Y同分布,也可以没有任何点ω使得X(ω)=Y(ω)。在这个意义上,可以把随机变量分类,每一类称作一个分布,其中的所有随机变量都同分布。用更简要的语言来说,同分布是一种等价关系,每一个等价类就是一个分布。需注意的是,通常谈到的离散分布、均匀分布、伯努利分布、正态分布、泊松分布等,都是指各种类型的分布,而不能视作一个分布。
(2)、狭义地,它是指随机变量的概率分布函数。设X是样本空间(Ω、F)上的随机变量,P为概率测度,则称如下定义的函数是X的分布函数(distribution function),或称累积分布函数(cumulative distribution function,简称CDF):FX(a)=P(X≤a),对任意实数a定义。具有相同分布函数的随机变量一定是同分布的,因此可以用分布函数来描述一个分布,但更常用的描述手段是概率密度函数(probability density function, pdf)。
4. 边缘概率
有时候,我们知道了一组变量的联合概率分布,但想要了解其中一个子集的概率分布。这种定义在子集上的概率分布被称为边缘概率分布(marginal probability distribution)。
例如,假设有离散型随机变量x和y,并且我们知道P(x,y)。我们可以根据下面的求和法则(sum rule)来计算P(x):
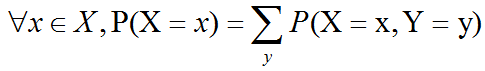
对于连续型变量,我们需要用积分替代求和:p(x)=∫p(x,y)dy.
边缘分布(Marginal Distribution)指在概率论和统计学的多维随机变量中,只包含其中部分变量的概率分布。在实际应用中,例如人工神经网络的神经元互相关联,在计算它们各自的参数的时候,就会使用边缘分布计算得到某一特定神经元(变量)的值。
5. 条件概率
在很多情况下,我们感兴趣的是某个事件,在给定其它事件发生时出现的概率。这种概率叫做条件概率。我们将给定X=x,Y=y发生的条件概率记为P(Y=y |X=x)。这个条件概率可以通过下面的公式计算:
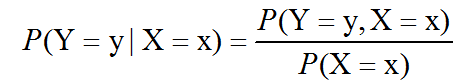
条件概率只在P(X=x)>0时有定义。我们不能计算给定在永远不会发生的事件上的条件概率。
条件概率(conditional probability):就是事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作”在B条件下A的概率”。
联合概率:表示两个事件共同发生的概率。A与B的联合概率表示为P(A∩B)或者P(A,B)或者P(AB)。
边缘概率:是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率)。这称为边缘化(marginalization)。A的边缘概率表示为P(A),B的边缘概率表示为P(B)。需要注意的是,在这些定义中A与B之间不一定有因果或者时间顺序关系。A可能会先于B发生,也可能相反,也可能二者同时发生。A可能会导致B的发生,也可能相反,也可能二者之间根本就没有因果关系。
条件概率定义:设A与B为样本空间Ω的两个事件,其中P(B)>0。那么在事件B发生的条件下,事件A发生的条件概率为:P(A|B)=P(A∩B)/P(B),条件概率有时候也称为后验概率。
6. 条件概率的链式法则
任何多维随机变量的联合概率分布,都可以分解成只有一个变量的条件概率相乘的形式:
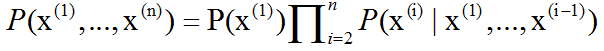
这个规则被称为概率的链式法则(chain rule)或者乘法法则(product rule)。
7. 独立性和条件独立性
两个随机变量x和y,如果它们的概率分布可以表示成两个因子的乘积形式,并且一个因子只包含x另一个因子只包含y,我们就称这两个随机变量是相互独立的(independent):
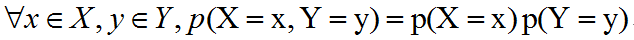
如果关于x和y的条件概率分布对于z的每一个值都可以写成乘积的形式,那么这两个随机变量x和y在给定随机变量z时是条件独立的(conditionally independent):
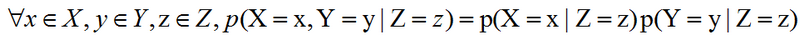
我们可以采用一种简化形式来表示独立性和条件独立性:x⊥y表示x和y相互独立,x⊥y|z表示x和y在给定z时条件独立。
在概率论和统计学中,两事件R和B在给定的另一事件Y发生时条件独立,类似于统计独立性,就是指当事件Y发生时,R发生与否和B发生与否就条件概率分布而言是独立的。换句话讲,R和B在给定Y发生时条件独立,当且仅当已知Y发生时,知道R发生与否无助于知道B发生与否,同样知道B发生与否也无助于知道R发生与否。
R和B在给定Y发生时条件独立,用概率论的标准记号表示为:Pr(R∩B|Y)=Pr(R|Y)Pr(B|Y),也可以等价地表示为Pr(R|B∩Y)=Pr(R|Y)。
两个随机变量X和Y在给定第三个随机变量Z的情况下条件独立当且仅当它们在给定Z时的条件概率分布互相独立,也就是说,给定Z的任一值,X的概率分布和Y的值无关,Y的概率分布也和X的值无关。
8. 期望、方差
函数f(x)关于某分布P(x)的期望(expectation)或者期望值(expected value)是指,当x由P产生,f作用于x时,f(x)的平均值。对于离散型随机变量,这可以通过求和得到:
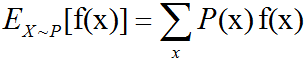
对于连续型随机变量可以通过求积分得到:
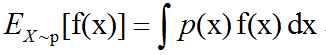
当概率分布在上下文中指明时,我们可以只写出期望作用的随机变量的名称来进行简化,例如Ex[f(x)]。如果期望作用的随机变量也很明确,我们可以完全不写脚标,就像E[f(x)]。默认地,我们假设E[·]表示对方括号内的所有随机变量的值求平均。期望是线性的。
方差(variance)衡量的是当我们对x依据它的概率分布进行采样时,随机变量x的函数值会呈现多大的差异:
Var(f(x))=E[(f(x)-E[f(x)])2]
当方差很小时,f(x)的值形成的簇比较接近它们的期望值。方差的平方根被称为标准差(standard deviation)。
期望值:在概率论和统计学中,一个离散性随机变量的期望值(或数学期望、或均值,亦简称期望)是试验中每次可能的结果乘以其结果概率的总和。换句话说,期望值像是随机试验在同样的机会下重复多次,所有那些可能状态平均的结果,便基本上等同”期望值”所期望的数。需要注意的是,期望值并不一定等同于常识中的”期望”------“期望值”也许与每一个结果都不相等。(换句话说,期望值是该变量输出值的平均数。期望值并不一定包含于变量的输出值集合里。)
期望值数学定义:如果X是在概率区间(Ω,P)中的随机变量,那么它的期望值E[X]的定义是:E[X]=∫ΩXdP,并不是每一个随机变量都有期望值的,因为有的时候这个积分不存在。如果两个随机变量的分布相同,那它们的期望值也相同。
如果X是离散的随机变量,输出值为x1,x2,…,和输出值相应的概率为p1,p2,…(概率和为1)。若级数∑ipixi绝对收敛,那么期望值E[X]是一个无限数列的和:E[X]=∑pixi
期望值性质:
(1)、期望值E是线性函数:E[aX+bY]=aE[X]+bE[Y],X和Y为在同一概率空间的两个随机变量(可以独立或者非独立),a和b为任意实数。
(2)、一般的说,一个随机变量的函数的期望值并不等于这个随机变量的期望值的函数。
(3)、在一般情况下,两个随机变量的积的期望值不等于两个随机变量的期望值的积。特殊情况是当这两个随机变量是相互独立的时候E[XY]=E[X]E[Y](也就是说一个随机变量的输出不会影响另一个随机变量的输出)。
在统计学中,当估算变量的期望值时,经常用到的方法是重复测量此变量的值,然后用所得数据的平均值来作为此变量的期望值的估计。在概率分布中,期望值和方差或标准差是一种分布的重要特征。
期望值也可以通过方差计算公式来计算方差:Var(X)=E[X2]-(E[X])2。
方差(Variance):在概率论和统计学中,一个随机变量的方差描述的是它的离散程度,也就是该变量离其期望值的距离。一个实随机变量的方差也称为它的二阶炬或二阶中心动差,恰巧也是它的二阶累积量。这里把复杂说白了,就是将各个误差将之平方(而非取绝对值),使之肯定为正数,相加之后再除以总数,透过这样的方式来算出各个数据分布、零散(相对中心点)的程度。继续延伸的话,方差的算术平方根称为该随机变量的标准差(此为相对各个数据点间)。
方差定义:设X为服从分布F的随机变量,如果E[X]是随机变数X的期望值(平均数μ=E[X]),随机变量X或者分布F的方差为: Var(X)=E[(X-μ)2] ,这个定义涵盖了连续、离散、或两者都有的随机变数。方差亦可当作是随机变数与自己本身的协方差:Var(X)=Cov(X,X)。
方差表示式展开成为:Var(X)=E[X2-2XE[X]+(E[X])2]=E[X2]-2E[X]E[X]+(E[X])2=E[X2]-(E[X])2,上述的表示式可记为”平方的平均减掉平均的平方”。
方差不会是负的。
标准差(Standard Deviation, SD),数学符号σ(sigma),在概率统计中最常使用作为测量一组数值的离散程度之用。标准差定义:为方差开算术平方根,反映组内个体间的离散程度。标准差与期望值之比为标准离差率。
简单来说,标准差是一组数值自平均值分散开来的程度的一种测量观念。一个较大的标准差,代表大部分的数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
总体的标准差:基本定义:

以上内容摘自:《深度学习中文版》和 维基百科
以下是分别采用C++和OpenCV实现的求矩阵的均值、方差、标准差code:
#include "funset.hpp"
#include <math.h>
#include <iostream>
#include <string>
#include <vector>
#include <opencv2/opencv.hpp>
#include "common.hpp"// =============================== 计算均值、方差、标准差 =====================
template<typename _Tp>
int meanStdDev(const std::vector<std::vector<_Tp>>& mat, double* mean, double* variance, double* stddev)
{int h = mat.size(), w = mat[0].size();double sum{ 0. }, sqsum{ 0. };for (int y = 0; y < h; ++y) {for (int x = 0; x < w; ++x) {double v = static_cast<double>(mat[y][x]);sum += v;sqsum += v * v;}}double scale = 1. / (h * w);*mean = sum * scale;*variance = std::max(sqsum*scale - (*mean)*(*mean), 0.);*stddev = std::sqrt(*variance);return 0;
}int test_meanStdDev()
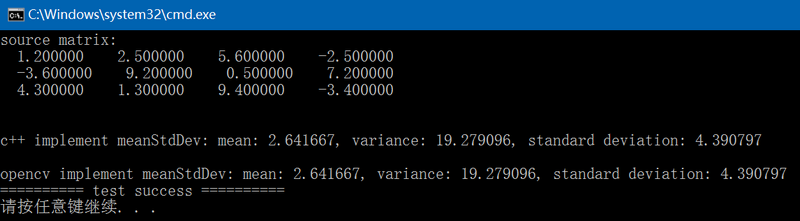
{std::vector<std::vector<float>> vec{ { 1.2f, 2.5f, 5.6f, -2.5f },{ -3.6f, 9.2f, 0.5f, 7.2f },{ 4.3f, 1.3f, 9.4f, -3.4f } };const int rows{ 3 }, cols{ 4 };fprintf(stderr, "source matrix:\n");fbc::print_matrix(vec);double mean1 = 0., variance1 = 0., stddev1 = 0.;if (fbc::meanStdDev(vec, &mean1, &variance1, &stddev1) != 0) {fprintf(stderr, "C++ implement meanStdDev fail\n");return -1;}fprintf(stderr, "\nc++ implement meanStdDev: mean: %f, variance: %f, standard deviation: %f\n",mean1, variance1, stddev1);cv::Mat mat(rows, cols, CV_32FC1);for (int y = 0; y < rows; ++y) {for (int x = 0; x < cols; ++x) {mat.at<float>(y, x) = vec.at(y).at(x);}}cv::Scalar mean2_, stddev2_;cv::meanStdDev(mat, mean2_, stddev2_);auto mean2 = mean2_.val[0];auto stddev2 = stddev2_.val[0];auto variance2 = stddev2 * stddev2;fprintf(stderr, "\nopencv implement meanStdDev: mean: %f, variance: %f, standard deviation: %f\n",mean2, variance2, stddev2);return 0;
}
#include "funset.hpp"
#include <math.h>
#include <iostream>
#include <vector>
#include <string>
#include <opencv2/opencv.hpp>
#include <Eigen/Dense>
#include "common.hpp"int test_meanStdDev()
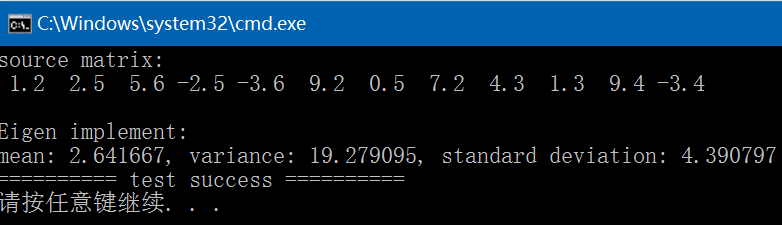
{std::vector<std::vector<float>> vec{ { 1.2f, 2.5f, 5.6f, -2.5f },{ -3.6f, 9.2f, 0.5f, 7.2f },{ 4.3f, 1.3f, 9.4f, -3.4f } };const int rows{ 3 }, cols{ 4 };std::vector<float> vec_;for (int i = 0; i < rows; ++i) {vec_.insert(vec_.begin() + i * cols, vec[i].begin(), vec[i].end());}Eigen::Map<Eigen::Matrix<float, Eigen::Dynamic, Eigen::Dynamic, Eigen::RowMajor>> m(vec_.data(), 1, rows * cols);fprintf(stderr, "source matrix:\n");std::cout << m << std::endl;Eigen::MatrixXf mean = m.rowwise().mean(); //<==> m.rowwise().sum() / m.cols();float mean_ = mean(0, 0);Eigen::MatrixXf sqsum = (m * m.transpose()).rowwise().sum();float sqsum_ = sqsum(0, 0);float scale = 1. / (rows*cols);float variance_ = sqsum_ * scale - mean_ * mean_;float stddev_ = std::sqrt(variance_);fprintf(stdout, "\nEigen implement:\n");fprintf(stdout, "mean: %f, variance: %f, standard deviation: %f\n", mean_, variance_, stddev_);return 0;
}
相关文章:

[转]CentOS 5.5下FTP安装及配置
一、FTP的安装 1、检测是否安装了FTP : [rootlocalhost ~]# rpm -q vsftpd vsftpd-2.0.5-16.el5_5.1 否则显示:[rootlocalhost ~]# package vsftpd is not installed 查看ftp运行状态 service vsftpd status 2、如果没安装FTP,运行yum install vsftpd命令进行安装 如…
C++11中头文件thread的使用
C11中加入了<thread>头文件,此头文件主要声明了std::thread线程类。C11的标准类std::thread对线程进行了封装。std::thread代表了一个线程对象。应用C11中的std::thread便于多线程程序的移值。 <thread>是C标准程序库中的一个头文件,定义了…

python3 urllib 类
urllib模块中的方法 1.urllib.urlopen(url[,data[,proxies]]) 打开一个url的方法,返回一个文件对象,然后可以进行类似文件对象的操作。本例试着打开google >>> import urllib >>> f urllib.urlopen(http://www.google.com.hk/) >&…
阿里飞天大数据飞天AI平台“双生”系统正式发布,9大全新数据产品集中亮相
作者 | 夕颜 责编 | 唐小引 出品 | AI科技大本营(ID:rgznai100) 如今,大数据和 AI 已经成为两个分不开的词汇,没有大数据,AI 就失去了根基;没有 AI,数据不会呈现爆发式的增长。如何将 AI 与大…
关于JavaScript的闭包(closure)
(转载自阮一峰博客) 闭包(closure)是Javascript语言的一个难点,也是它的特色,更是函数式编程的重要思想之一,很多高级应用都要依靠闭包实现。 下面就是我的学习笔记,对于Javascript初…
Vagrant控制管理器——“Hobo”
Hobo是控制Vagrant盒子和在Mac上编辑Vagrantfiles的最佳和最简单的方法。您可以快速启动,停止和重新加载您的Vagrant机器。您可以从头开始轻松创建新的Vagrantfile。点击进入,尽享Hobo for Mac全部功能! Hobo做什么? 启动…

微众银行AI团队开源联邦学习框架,并发布《联邦学习白皮书1.0》
(图片由AI科技大本营付费下载自视觉中国)编辑 | Jane来源 | 《联邦学习白皮书1.0》出品 | AI科技大本营(ID:rgznai100)【导语】2019年,联邦学习成为业界技术研究与应用的焦点。近日,微众银行 AI 项目组编制…
C++11中头文件atomic的使用
原子库为细粒度的原子操作提供组件,允许无锁并发编程。涉及同一对象的每个原子操作,相对于任何其他原子操作是不可分的。原子对象不具有数据竞争(data race)。原子类型对象的主要特点就是从不同线程访问不会导致数据竞争。因此从不同线程访问某个原子对象…
Oracle回收站
回收站是删除对象使用的存储空间。可以使用实例参数recyclebin禁用回收站,默认是on,可以为某个会话或系统设置为off或on。所有模式都有一个回收站。 当表空间不足时可以自动重用回收站对象占用的表空间(此后不可能恢复对象)&#…
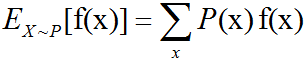
协方差矩阵介绍及C++/OpenCV/Eigen的三种实现
函数f(x)关于某分布P(x)的期望(expectation)或者期望值(expected value)是指,当x由P产生,f作用于x时,f(x)的平均值。对于离散型随机变量,这可以通过求和得到:对于连续型随机变量可以通过求积分得到:当概率分…
10分钟搭建你的第一个图像识别模型 | 附完整代码
(图片由AI科技大本营付费下载自视觉中国)作者 | Pulkit Sharma译者 | 王威力来源 | 数据派THU(ID:DatapiTHU)【导读】本文介绍了图像识别的深度学习模型的建立过程,通过陈述实际比赛的问题、介绍模型框架和…

Rancher 2.2.2 发布,优化 Kubernetes 集群运维
开发四年只会写业务代码,分布式高并发都不会还做程序员? >>> Rancher 2.2.2 发布了。Rancher 是一个开源的企业级 Kubernetes 平台,可以管理所有云上、所有发行版、所有 Kubernetes集群,解决了生产环境中企业用户可能面…
EXP/EXPDP, IMP/IMPDP应用
2019独角兽企业重金招聘Python工程师标准>>> EXP/EXPDP, IMP/IMPDP应用 exp name/pwddbname filefilename.dmp tablestablename rowsy indexesn triggersn grantsn $ sqlplus username/passwordhostname:port/SERVICENAME OR $ sqlplus username Enter password:…

微软语音AI技术与微软听听文档小程序实践 | AI ProCon 2019
演讲嘉宾 | 赵晟、张鹏整理 | 伍杏玲来源 | CSDN(ID:CSDNnews)【导语】9 月 7 日,在CSDN主办的「AI ProCon 2019」上,微软(亚洲)互联网工程院人工智能语音团队首席研发总监赵晟、微软࿰…
C++11中std::condition_variable的使用
<condition_variable>是C标准程序库中的一个头文件,定义了C11标准中的一些用于并发编程时表示条件变量的类与方法等。条件变量是并发程序设计中的一种控制结构。多个线程访问一个共享资源(或称临界区)时,不但需要用互斥锁实现独享访问以避免并发错…
docker基础文档(链接,下载,安装)
一、docker相关链接1.docker中国区官网(包含部分中文文档,下载安装包,镜像加速器):https://www.docker-cn.com/2.docker官方镜像仓库:https://cloud.docker.com/3.docker下载:https://www.docker-cn.com/community-edi…
一个JS对话框,可以显示其它页面,
还不能自适应大小 garyBox.js // JavaScript Document// gary 2014-3-27// 加了 px 在google浏览器没加这个发现设置width 和height没有用 //gary 2014-3-27 //实在不会用那些JS框架,自己弄个,我只是想要个可以加载其它页面的对话框而以,这里用了别人的…

只需4秒,这个算法就能鉴别你的LV是真是假
(图片付费下载自视觉中国)导语:假冒奢侈品制造这个屡禁不止的灰色产业,每年给正品商家和消费者造成上千亿的损失,对企业和消费者造成伤害。作为全球奢侈品巨头,LVMH 对假冒奢侈品的打击十分重视。LVMH 其旗…
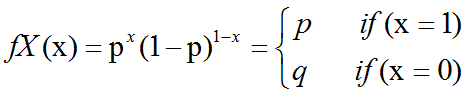
概率论中伯努利分布(bernoulli distribution)介绍及C++11中std::bernoulli_distribution的使用
Bernoulli分布(Bernoulli distribution):是单个二值随机变量的分布。它由单个参数∈[0,1],给出了随机变量等于1的概率。它具有如下的一些性质:P(x1) P(x0)1-P(xx) x(1-)1-xEx[x] Varx(x) (1-)伯努力分布(Bernoulli distribution,又…
关于View测量中的onMeasure函数
在自定义View中我们通常会重写onMeasure,下面来说说这个onMeasure有什么作用 onMeasure主要用于对于View绘制时进行测量 Override protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {super.onMeasure(widthMeasureSpec, heightMeasureSpec);…

zabbix二次开发之从mysql取值在运维平台js图表展现
前沿:集群控制平台已经要慢慢的灰度上线了,出问题的时候,才找点bug,时间有点空闲。正好看了下zabbix的数据库,产生了自己想做一套能更好的展现zabbix的页面。更多内容请到我的个人的博客站点,blog.xiaorui.…
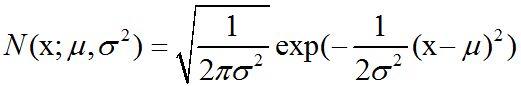
概率论中高斯分布(正态分布)介绍及C++11中std::normal_distribution的使用
高斯分布:最常用的分布是正态分布(normal distribution),也称为高斯分布(Gaussian distribution):正态分布N(x;μ,σ2)呈现经典的”钟形曲线”的形状,其中中心峰的x坐标由μ给出,峰的宽度受σ控制。正态分布由两个参数…

AI落地遭“卡脖子”困境:为什么说联邦学习是解决良方?
作者 | Just出品 | AI科技大本营(ID:rgznai100)毋庸置疑,在业界对人工智能(AI)应用落地备受期待的时期,数据这一重要支点却越来越成为一个“卡脖子”的难题。AI落地需要数据来优化模型效果,但大…
Linux下截取指定时间段日志并输出到指定文件
sed -n /2019-04-22 16:10:/,/2019-04-22 16:20:/p log.log > bbb.txt 转载于:https://www.cnblogs.com/mrwuzs/p/10752037.html
nginx+keepalive主从双机热备+自动切换解决方案
环境采集cenots 6.3 64位迷你安装,因为安装前,你需要做一些工作yum install -y make wget如果你愿意可以更新下系统,更换下yum源.1.安装keepalive官方最新版 keepalived-1.2.7tar zxvf keepalived-1.2.7.tar.gzcd keepalived-1.2.7在此之前。…
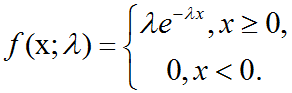
概率论中指数分布介绍及C++11中std::exponential_distribution的使用
指数分布:在深度学习中,我们经常会需要一个在x0点处取得边界点(sharp point)的分布。为了实现这一目的,我们可以使用指数分布(exponential distribution): p(x;λ) λlx≥0exp(-λx)指数分布使用指示函数(indicator function) lx≥…
肖仰华:知识图谱构建的三要素、三原则和九大策略 | AI ProCon 2019
演讲嘉宾 | 肖仰华(复旦大学教授、博士生导师,知识工场实验室负责人) 编辑 | Jane 出品 | AI科技大本营(ID:rgznai100) 近两年,知识图谱技术得到了各行各业的关注,无论是企业公司还…
Docker mongo副本集环境搭建
1、MongoDB Docker 镜像安装 docker pull mongo 2、Docker容器创建 MongoDB Docker 容器创建有以下几个问题: 1- MongoDB 容器基本创建方法和数据目录挂载 2- MongoDB 容器的数据迁移 3- MongoDB 设置登录权限问题docker run -p 27017:27017 -v <LocalDirectoryP…
菜鸟学习HTML5+CSS3(一)
主要内容: 1.新的文档类型声明(DTD) 2.新增的HTML5标签 3.删除的HTML标签 4.重新定义的HTML标签 一、新的文档类型声明(DTD) HTML 5的DTD声明为:<!doctype html>、<!DOCTYPE html>、<!DOCTY…
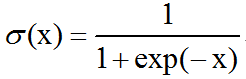
激活函数之logistic sigmoid函数介绍及C++实现
logistic sigmoid函数:logistic sigmoid函数通常用来产生Bernoulli分布中的参数,因为它的范围是(0,1),处在的有效取值范围内。logisitic sigmoid函数在变量取绝对值非常大的正值或负值时会出现饱和(saturate)现象,意味着函数会变得…