10分钟搭建你的第一个图像识别模型 | 附完整代码
(图片由AI科技大本营付费下载自视觉中国)
【导读】本文介绍了图像识别的深度学习模型的建立过程,通过陈述实际比赛的问题、介绍模型框架和展示解决方案代码,为初学者提供了解决图像识别问题的基础框架。
序言
“几分钟就可以建立一个深度学习模型?训练就要花几个小时好吗!我甚至没有一台足够好的机器。”我听过无数次有抱负的数据科学家这样说,他们害怕在自己的机器上构建深度学习模型。
其实,你不必在谷歌或其他大型科技公司工作,就可以训练深度学习数据集。你完全可以用几分钟的时间从头搭建起你自己的神经网络,而不需要租谷歌的服务器。Fast.ai的学生花了18分钟设计出了用于ImageNet数据集的一个模型,接下来我将在本文中展示类似的方法。
深度学习是一个广泛的领域,所以我们会缩小我们的关注点在图像分类问题上。而且,我们将使用一个非常简单的深度学习架构来达到一个很好的准确率。
你可以将本文中的Python代码作为构建图像分类模型的基础,一旦你对这些概念有了很好的理解,可以继续编程,参加比赛、登上排行榜。
如果你刚开始深入学习,并且对计算机视觉领域着迷(谁不是呢?!)一定要看一看Computer Vision using Deep Learning的课程,它对这个酷炫的领域进行了全面的介绍,将为你未来进入这个巨大的就业市场奠定基础。
课程链接:
https://trainings.analyticsvidhya.com/courses/course-v1:AnalyticsVidhya+CVDL101+CVDL101_T1/about?utm_source=imageclassarticle&utm_ medium=blog
目录
01 什么是图像分类以及它的应用案例
02 设置图像数据结构
03 分解模型建立过程
04 设置问题定义并认识数据
05 建立图像分类模型的步骤
06 其他挑战
01 什么是图像分类以及它的应用案例
观察以下图片:

你应该可以马上就认出它——是一俩豪华车。退一步来分析一下你是如何得到这个结论的——你被展示了一张图片,然后你将它划分为“车”这个类别(在这个例子中)。简单来说,这个过程就是图像分类。
很多时候,图像会有许多个类别。手动检查并分类图像是一个非常繁琐的过程。尤其当问题变为对10000张甚至1000000张图片的时候,这个任务几乎不可能完成。所以如果我们可以将这个过程自动化的实现并快速的标记图像类别,这该有多大的用处啊。
自动驾驶汽车是一个图像分类在现实世界应用的很好的例子。为了实现自动驾驶,我们可以建立一个图像分类模型来识别道路上的各种物体,如车辆、人、移动物体等。我们将在接下来的部分中看到更多的应用,甚至在我们的身边就有许多的应用。
既然我们已经掌握了主题,那么让我们来深入研究一下如何构建图像分类模型,它的先决条件是什么,以及如何在Python中实现它。
02 设置图像数据结构
我们的数据集需要特殊的结构来解决图像分类问题。我们将在几个部分中看到这一点,但在往下走之前,请记住这些建议。
你应该建立两个文件夹,一个放训练集,另一个放测试集。训练集的文件夹里放一个csv文件和一个图像文件夹:
- csv文件存储所有训练图片的图片名和它们对应的真实标签
- 图像文件夹存储所有的训练图片

03 分解模型搭建的过程
- 第1步:加载和预处理数据——30%时间
- 第2步:定义模型架构——10%时间
- 第3步:训练模型——50%时间
- 第4步:评价模型表现——10%时间
Basics of Image Processing in Python
https://www.analyticsvidhya.com/blog/2014/12/image-processing-python-basics/
- 需要多少个卷积层?
- 每一层的激活函数是什么?
- 每一层有多少隐藏单元?
- 训练图像和它们的真实标签。
- 验证集图像和其真实标签。(我们只用验证集的标签进行模型评估,不用于训练)

04 设置问题定义并认识数据
“识别服装”比赛链接:
https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-apparels/
数据黑客平台:
https://datahack.analyticsvidhya.com/

Google Colab:
https://colab.research.google.com/
05 建立图像分类模型的步骤
- 第1步:设置Google Colab
- 第2步:导入库
- 第3步:导入数据预处理数据(3分钟)
- 第4步:设置验证集
- 第5步:定义模型结构(1分钟)
- 第6步:训练模型(5分钟)
- 第7步:预测(1分钟)
!pip install PyDrive
import os
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
download = drive.CreateFile({'id': '1BZOv422XJvxFUnGh-0xVeSvgFgqVY45q'})
download.GetContentFile('train_LbELtWX.zip')
!unzip train_LbELtWX.zip
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.utils import to_categorical
from keras.preprocessing import image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
from tqdm import tqdm
train = pd.read_csv('train.csv')
# We have grayscale images, so while loading the images we will keep grayscale=True, if you have RGB images, you should set grayscale as False
train_image = []
for i in tqdm(range(train.shape[0])):
img = image.load_img('train/'+train['id'][i].astype('str')+'.png', target_size=(28,28,1), grayscale=True)
img = image.img_to_array(img)
img = img/255
train_image.append(img)
X = np.array(train_image)
y=train['label'].values
y = to_categorical(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',input_shape=(28,28,1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='Adam',metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
download = drive.CreateFile({'id': '1KuyWGFEpj7Fr2DgBsW8qsWvjqEzfoJBY'})
download.GetContentFile('test_ScVgIM0.zip')
!unzip test_ScVgIM0.zip
test = pd.read_csv('test.csv')
test_image = []
for i in tqdm(range(test.shape[0])):
img = image.load_img('test/'+test['id'][i].astype('str')+'.png', target_size=(28,28,1), grayscale=True)
img = image.img_to_array(img)
img = img/255
test_image.append(img)
test = np.array(test_image)
# making predictions
prediction = model.predict_classes(test)
download = drive.CreateFile({'id': '1z4QXy7WravpSj-S4Cs9Fk8ZNaX-qh5HF'})
download.GetContentFile('sample_submission_I5njJSF.csv')
# creating submission file
sample = pd.read_csv('sample_submission_I5njJSF.csv')
sample['label'] = prediction
sample.to_csv('sample_cnn.csv', header=True, index=False)
A Comprehensive Tutorial to learn Convolutional Neural Networks from Scratchhttps://www.analyticsvidhya.com/blog/2018/12/guide-convolutional-neural-network-cnn/
06 开启一个新的挑战

Identify the Digits比赛链接:
https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-digits/
# Setting up Colab
!pip install PyDrive
import os
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
# Replace the id and filename in the below codes
download = drive.CreateFile({'id': '1ZCzHDAfwgLdQke_GNnHp_4OheRRtNPs-'})
download.GetContentFile('Train_UQcUa52.zip')
!unzip Train_UQcUa52.zip
# Importing libraries
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.utils import to_categorical
from keras.preprocessing import image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
from tqdm import tqdm
train = pd.read_csv('train.csv')
# Reading the training images
train_image = []
for i in tqdm(range(train.shape[0])):
img = image.load_img('Images/train/'+train['filename'][i], target_size=(28,28,1), grayscale=True)
img = image.img_to_array(img)
img = img/255
train_image.append(img)
X = np.array(train_image)
# Creating the target variable
y=train['label'].values
y = to_categorical(y)
# Creating validation set
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
# Define the model structure
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',input_shape=(28,28,1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# Compile the model
model.compile(loss='categorical_crossentropy',optimizer='Adam',metrics=['accuracy'])
# Training the model
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
download = drive.CreateFile({'id': '1zHJR6yiI06ao-UAh_LXZQRIOzBO3sNDq'})
download.GetContentFile('Test_fCbTej3.csv')
test_image = []
for i in tqdm(range(test_file.shape[0])):
img = image.load_img('Images/test/'+test_file['filename'][i], target_size=(28,28,1), grayscale=True)
img = image.img_to_array(img)
img = img/255
test_image.append(img)
test = np.array(test_image)
prediction = model.predict_classes(test)
download = drive.CreateFile({'id': '1nRz5bD7ReGrdinpdFcHVIEyjqtPGPyHx'})
download.GetContentFile('Sample_Submission_lxuyBuB.csv')
sample = pd.read_csv('Sample_Submission_lxuyBuB.csv')
sample['filename'] = test_file['filename']
sample['label'] = prediction
sample.to_csv('sample.csv', header=True, index=False)
原文标题:
Build your First Image Classification Model in just 10 Minutes!
原文链接:
https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/
译者:王威力,求职狗,在香港科技大学学习大数据科技。感觉数据科学很有难度,也很有意思,还在学(tu)习(tou)中。一个人肝不动的文献,follow大佬一起肝。
◆
精彩推荐
◆

推荐阅读
阿里飞天大数据&飞天AI平台“双生”系统正式发布,9大全新数据产品集中亮相
阿里披露AI完整布局,飞天AI平台首次亮相
解决掉这些痛点和难点,让知识图谱不再是“噱头”
程序员因接外包坐牢 456 天!两万字揭露心酸经历
11月4日,上海开源基础设施峰会,不见不散!
限时早鸟票 | 2019 中国大数据技术大会(BDTC)超豪华盛宴抢先看!
Pandas中第二好用的函数 | 优雅的Apply
阿里开源物联网操作系统 AliOS Things 3.0 发布,集成平头哥 AI 芯片架构!
雷声大雨点小:Bakkt「见光死」了吗?

你点的每个“在看”,我都认真当成了喜欢
相关文章:

Rancher 2.2.2 发布,优化 Kubernetes 集群运维
开发四年只会写业务代码,分布式高并发都不会还做程序员? >>> Rancher 2.2.2 发布了。Rancher 是一个开源的企业级 Kubernetes 平台,可以管理所有云上、所有发行版、所有 Kubernetes集群,解决了生产环境中企业用户可能面…
EXP/EXPDP, IMP/IMPDP应用
2019独角兽企业重金招聘Python工程师标准>>> EXP/EXPDP, IMP/IMPDP应用 exp name/pwddbname filefilename.dmp tablestablename rowsy indexesn triggersn grantsn $ sqlplus username/passwordhostname:port/SERVICENAME OR $ sqlplus username Enter password:…

微软语音AI技术与微软听听文档小程序实践 | AI ProCon 2019
演讲嘉宾 | 赵晟、张鹏整理 | 伍杏玲来源 | CSDN(ID:CSDNnews)【导语】9 月 7 日,在CSDN主办的「AI ProCon 2019」上,微软(亚洲)互联网工程院人工智能语音团队首席研发总监赵晟、微软࿰…

C++11中std::condition_variable的使用
<condition_variable>是C标准程序库中的一个头文件,定义了C11标准中的一些用于并发编程时表示条件变量的类与方法等。条件变量是并发程序设计中的一种控制结构。多个线程访问一个共享资源(或称临界区)时,不但需要用互斥锁实现独享访问以避免并发错…
docker基础文档(链接,下载,安装)
一、docker相关链接1.docker中国区官网(包含部分中文文档,下载安装包,镜像加速器):https://www.docker-cn.com/2.docker官方镜像仓库:https://cloud.docker.com/3.docker下载:https://www.docker-cn.com/community-edi…
一个JS对话框,可以显示其它页面,
还不能自适应大小 garyBox.js // JavaScript Document// gary 2014-3-27// 加了 px 在google浏览器没加这个发现设置width 和height没有用 //gary 2014-3-27 //实在不会用那些JS框架,自己弄个,我只是想要个可以加载其它页面的对话框而以,这里用了别人的…

只需4秒,这个算法就能鉴别你的LV是真是假
(图片付费下载自视觉中国)导语:假冒奢侈品制造这个屡禁不止的灰色产业,每年给正品商家和消费者造成上千亿的损失,对企业和消费者造成伤害。作为全球奢侈品巨头,LVMH 对假冒奢侈品的打击十分重视。LVMH 其旗…
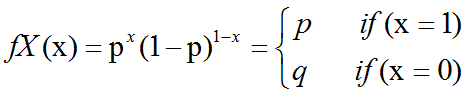
概率论中伯努利分布(bernoulli distribution)介绍及C++11中std::bernoulli_distribution的使用
Bernoulli分布(Bernoulli distribution):是单个二值随机变量的分布。它由单个参数∈[0,1],给出了随机变量等于1的概率。它具有如下的一些性质:P(x1) P(x0)1-P(xx) x(1-)1-xEx[x] Varx(x) (1-)伯努力分布(Bernoulli distribution,又…
关于View测量中的onMeasure函数
在自定义View中我们通常会重写onMeasure,下面来说说这个onMeasure有什么作用 onMeasure主要用于对于View绘制时进行测量 Override protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {super.onMeasure(widthMeasureSpec, heightMeasureSpec);…

zabbix二次开发之从mysql取值在运维平台js图表展现
前沿:集群控制平台已经要慢慢的灰度上线了,出问题的时候,才找点bug,时间有点空闲。正好看了下zabbix的数据库,产生了自己想做一套能更好的展现zabbix的页面。更多内容请到我的个人的博客站点,blog.xiaorui.…
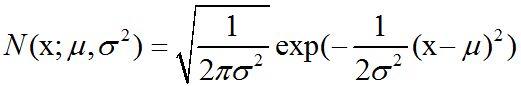
概率论中高斯分布(正态分布)介绍及C++11中std::normal_distribution的使用
高斯分布:最常用的分布是正态分布(normal distribution),也称为高斯分布(Gaussian distribution):正态分布N(x;μ,σ2)呈现经典的”钟形曲线”的形状,其中中心峰的x坐标由μ给出,峰的宽度受σ控制。正态分布由两个参数…

AI落地遭“卡脖子”困境:为什么说联邦学习是解决良方?
作者 | Just出品 | AI科技大本营(ID:rgznai100)毋庸置疑,在业界对人工智能(AI)应用落地备受期待的时期,数据这一重要支点却越来越成为一个“卡脖子”的难题。AI落地需要数据来优化模型效果,但大…
Linux下截取指定时间段日志并输出到指定文件
sed -n /2019-04-22 16:10:/,/2019-04-22 16:20:/p log.log > bbb.txt 转载于:https://www.cnblogs.com/mrwuzs/p/10752037.html
nginx+keepalive主从双机热备+自动切换解决方案
环境采集cenots 6.3 64位迷你安装,因为安装前,你需要做一些工作yum install -y make wget如果你愿意可以更新下系统,更换下yum源.1.安装keepalive官方最新版 keepalived-1.2.7tar zxvf keepalived-1.2.7.tar.gzcd keepalived-1.2.7在此之前。…
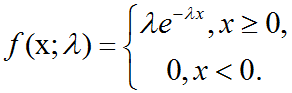
概率论中指数分布介绍及C++11中std::exponential_distribution的使用
指数分布:在深度学习中,我们经常会需要一个在x0点处取得边界点(sharp point)的分布。为了实现这一目的,我们可以使用指数分布(exponential distribution): p(x;λ) λlx≥0exp(-λx)指数分布使用指示函数(indicator function) lx≥…
肖仰华:知识图谱构建的三要素、三原则和九大策略 | AI ProCon 2019
演讲嘉宾 | 肖仰华(复旦大学教授、博士生导师,知识工场实验室负责人) 编辑 | Jane 出品 | AI科技大本营(ID:rgznai100) 近两年,知识图谱技术得到了各行各业的关注,无论是企业公司还…
Docker mongo副本集环境搭建
1、MongoDB Docker 镜像安装 docker pull mongo 2、Docker容器创建 MongoDB Docker 容器创建有以下几个问题: 1- MongoDB 容器基本创建方法和数据目录挂载 2- MongoDB 容器的数据迁移 3- MongoDB 设置登录权限问题docker run -p 27017:27017 -v <LocalDirectoryP…
菜鸟学习HTML5+CSS3(一)
主要内容: 1.新的文档类型声明(DTD) 2.新增的HTML5标签 3.删除的HTML标签 4.重新定义的HTML标签 一、新的文档类型声明(DTD) HTML 5的DTD声明为:<!doctype html>、<!DOCTYPE html>、<!DOCTY…
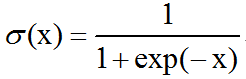
激活函数之logistic sigmoid函数介绍及C++实现
logistic sigmoid函数:logistic sigmoid函数通常用来产生Bernoulli分布中的参数,因为它的范围是(0,1),处在的有效取值范围内。logisitic sigmoid函数在变量取绝对值非常大的正值或负值时会出现饱和(saturate)现象,意味着函数会变得…

NLP重要模型详解,换个方式学(内附资源)
(图片有AI科技大本营付费下载自视觉中国)作者 | Jaime Zornoza,马德里技术大学译者 | 陈之炎校对 | 王威力编辑 | 黄继彦来源 | 数据派THU(ID:DatapiTHU)【导语】本文带你以前所未有的方式了解深度学习神经…
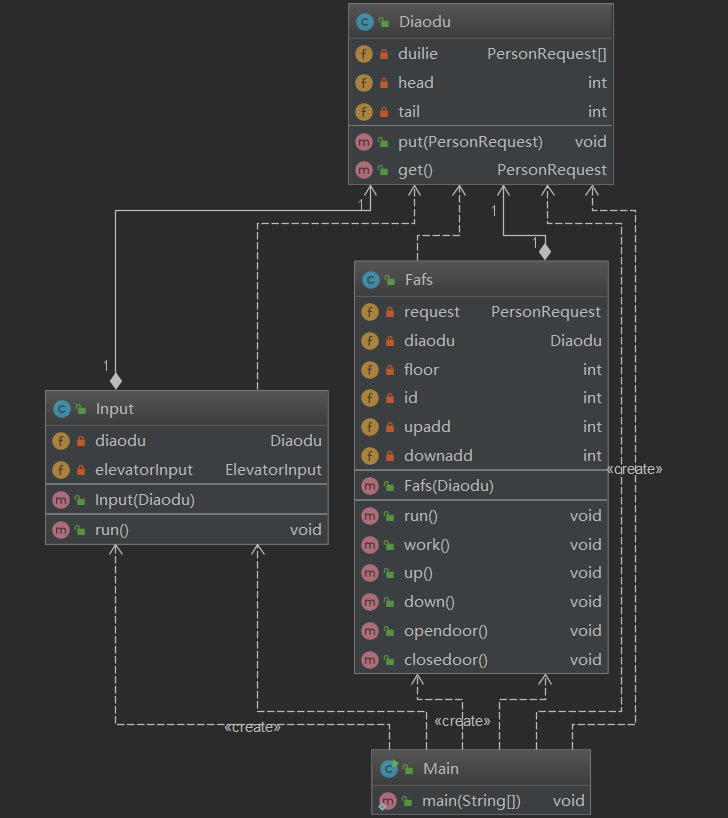
大闸蟹的OO第二单元总结
OO的第二单元是讲多线程的协作与控制,三次作业分别为FAFS电梯,ALS电梯和三部需要协作的电梯。三次作业由浅入深,让我们逐渐理解多线程的工作原理和运行状况。 第一次作业: 第一次作业是傻瓜电梯,也就是完全不需要考虑捎…

构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(31)-MVC使用RDL报表
原文:构建ASP.NET MVC4EF5EasyUIUnity2.x注入的后台管理系统(31)-MVC使用RDL报表这次我们来演示MVC3怎么显示RDL报表,坑爹的微软把MVC升级到5都木有良好的支持报表,让MVC在某些领域趋于短板 我们只能通过一些方式来使用rdl报表。 Razor视图不支持asp.net…

18段代码带你玩转18个机器学习必备交互工具
(图片有AI科技大本营付费下载自视觉中国)作者 | 曼纽尔阿米纳特吉(Manuel Amunategui)、迈赫迪洛佩伊(Mehdi Roopaei)来源 | 大数据(ID:hzdashuju)【导读】本文简要介绍将…
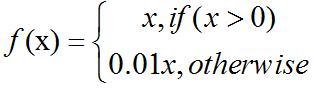
激活函数之ReLU/softplus介绍及C++实现
softplus函数(softplus function):ζ(x)ln(1exp(x)).softplus函数可以用来产生正态分布的β和σ参数,因为它的范围是(0,∞)。当处理包含sigmoid函数的表达式时它也经常出现。softplus函数名字来源于它是另外一个函数的平滑(或”软化”)形式,这…
windows server 2012 用sysdba登录报错 ORA-01031
报错显示:C:\Users\Administrator>sqlplus / as sysdba SQL*Plus: Release 11.2.0.1.0 Production on 星期三 4月 24 09:09:33 2019 Copyright (c) 1982, 2010, Oracle. All rights reserved. ERROR:ORA-01031: 权限不足 请输入用户名: 1、查看本地用户和组确认权…

[SignalR]初步认识以及安装
原文:[SignalR]初步认识以及安装1.什么是ASP.NET SignalR? ASP .NET SignalR是一个 ASP .NET 下的类库,可以在ASP .NET 的Web项目中实现实时通信。什么是实时通信的Web呢?就是让客户端(Web页面)和服务器端可以互相通知…
CUDA Samples:Vector Add
以下CUDA sample是分别用C和CUDA实现的两向量相加操作,参考CUDA 8.0中的sample:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\0_Simple,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CU…

你和人工智能的对话,正在被人工收听
(图片有AI科技大本营付费下载自视觉中国)作者 | 周晶晶编辑 | 阿伦来源 | 燃财经(ID:rancaijing)如今,智能设备越来越多地出现在每个人的生活中,在享受它们带来的便利时,很多人或许没有意识到&a…

python数据结构与算法总结
python常用的数据结构与算法就分享到此处,本月涉及数据结构与算法的内容有如下文章: 《数据结构和算法对python意味着什么?》 《顺序表数据结构在python中的应用》 《python实现单向链表数据结构及其基本方法》 《python实现单向循环链表数据…
自定义classloader中的接口调用
2019独角兽企业重金招聘Python工程师标准>>> 注意其中转型异常的描述,左边声明和强转括号内都是appclassloader加载的,而让自定义加载类的接口也由appclassloader加载,所以转型成功 转载于:https://my.oschina.net/heatonn1/blog/…