NLP重要模型详解,换个方式学(内附资源)

【导语】本文带你以前所未有的方式了解深度学习神经网络,并利用NLP构建Chatbot!
是否曾经幻想过能和自己的私人助理对话或是漫无边际地探讨任何问题?多亏机器学习和深度神经网络,你曾经的幻想很快会变成现实。让我们来看一下Apple的Siri或亚马逊的Alexa所展示的这一神奇功能吧。
不要太激动,我们在下面一系列帖子中,创建的不是一个无所不能的人工智能,而是创建一个简单的聊天机器人,预先些输入一些信息,它能够对此类信息相关的问题做出是或否的回答。
它远不及Siri或Alexa,但它却能很好地说明:即使使用非常简单的深度神经网络架构,也可以获得不错的结果。在这篇文章中,我们将学习人工神经网络,深度学习,递归神经网络和长短期记忆网络。在下一篇文章中,我们将在真实项目中利用它来回答问题
在开始讨论神经网络之前,先仔细看看下面的图像。其中有两张图片:其中一张图片是一辆校车行驶通过马路,另一张图片是是普通的起居室,这两张图片都有人工注释人员对其进行了描述。

图中为两个不同的图像,附有人工注释人员对其进行的描述
好了,让我们继续吧!
开始 - 人工神经网络
为了构建一个用于创建聊天机器人的神经网络模型,会用到一个非常流行的神经网络Python库:Keras。然而,在进一步研究之前,首先应了解人工神经网络(ANN)是什么。
人工神经网络是一种机器学习模型,它试图模仿人类大脑的功能,它由连接在一起的大量神经元构建而成- 因此命名为“人工神经网络”。
感知器
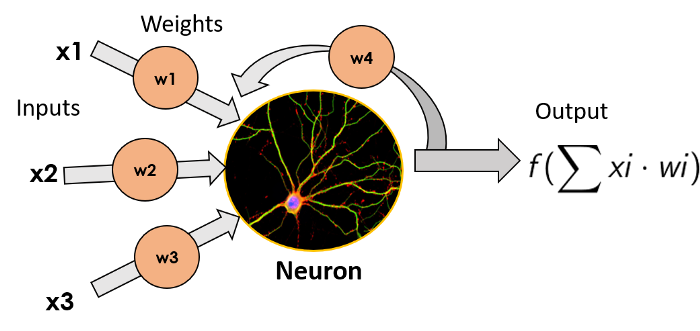
最简单的ANN模型由单个神经元组成, Star-Trek将之命名为感知器(Perceptron)。它由弗朗克·罗森布拉特(Frank Rossenblatt)于1957年发明,它包括一个简单的神经元,对输入的加权和进行函数变换(在生物神经元中是枝状突起),并输出其结果(输出将等同于生物神经元的轴突)。我们不在这里深入研究用到的函数变换的细节,因为这篇文章的目的不是成为专家,而只是需要了解神经网络的工作原理。
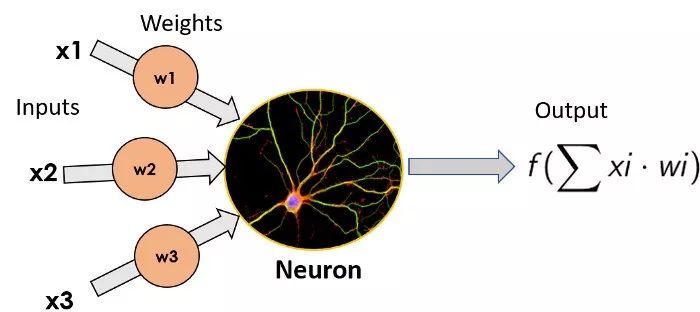
单个神经元的图像,左边为输入,乘以每个输入的权重,神经元将函数变换应用于输入的加权和并输出结果
这些单独的神经元可以堆叠起来,形成包含不同个数神经元的层,这些层可以顺序地相邻放置,从而使得网络更深。
当以这种方式构建网络时,不属于输入层或输出层的神经元叫做隐藏层,正如它们的名称所描述:隐藏层是一个黑盒模型,这也正是ANN的主要特征之一。通常我们对其中的数学原理以及黑盒中发生的事情有一些认知,但是如果仅通过隐藏层的输出试图理解它,我们大脑可能不够用。
尽管如此,ANN却能输出很好的结果,因此不会有人抱怨这些结果缺乏可解释性。
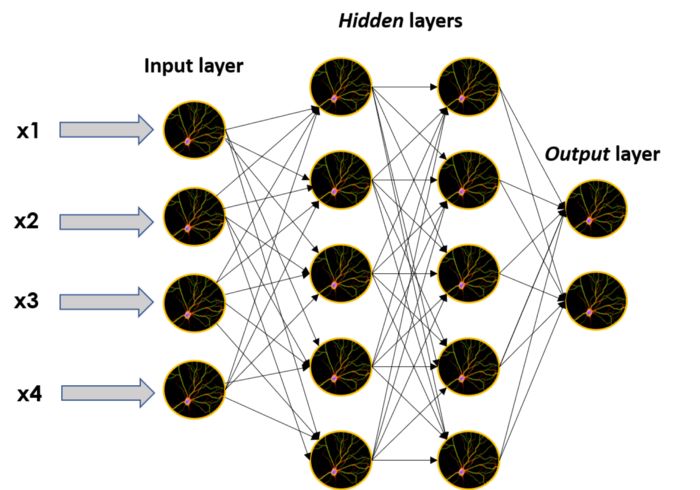
大的神经网络的图像,由许多单独的神经元和层组成:一个输入层,两个隐藏层和一个输出层
神经网络结构以及如何训练一个神经网络,已为人所知有二十多年了。那么,又是什么原因导致了当今对人工神经网络和深度学习的火爆和炒作?下面我们会给出问题的答案,但在此之前,我们先了解一下深度学习的真正含义。
什么是深度学习?
从它的名称可以猜测到,深度学习使用多个层逐步从提供给神经网络的数据中提取出更高级别的特征。这个道理很简单:使用多个隐藏层来增强神经模型的性能。
明白了这一点之后,上面问题的答案便简单了:规模。在过去的二十年中,各种类型的可用数据量以及我们的数据存储和处理机器(即,计算机)的功能都呈指数级增长。
计算力的增加,以及用于训练模型的可用数据量的大量增加,使我们能够创建更大、更深的神经网络,这些深度神经网络的性能优于较小的神经网络。
Andrew Ng是世界领先的深度学习专家之一,他在本视频中明确了这一点。在视频中,他展示了与下面图像类似的一副图像,并用它解释了利用更多数据来训练模型的优势,以及大型神经网络与其他机器学习模型相比较的优势。
https://www.youtube.com/watch?v=O0VN0pGgBZM&t=576s
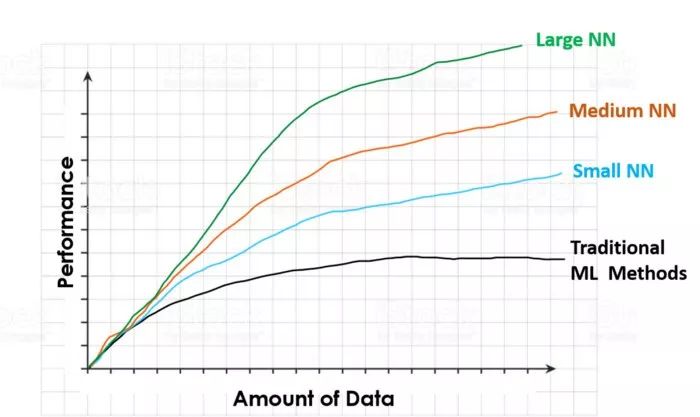
图像显示了当训练数据集增大时,不同算法的性能演变
传统的机器学习算法(线性或逻辑回归,SMV,随机森林等)的性能会随着训练数据集的增大而增加,但是当数据集增大到某一点之后,算法的性能会停止上升。数据集大小超过这一值之后,即便为模型提供了更多的数据,传统模型却不知道如何去处理这些附加的数据,从而性能得不到进一步的提高。
神经网络则不然,这种情况永远不会发生。神经网络的性能总是随着数据量的增加而增加(当然,前提是这些数据质量良好),随着网络大小的增加,训练的速度也会加快。因此,如果想要获得最佳性能,则需要在X轴右侧(高数据量)的绿线(大神经网络)的某个位置。
此外,虽然还需要有一些算法上的改进,但是深度学习和人工神经网络兴起的主要因素便是规模:计算规模和数据规模。
杰夫·迪恩(Jeff Dean)(谷歌深度学习的煽动者之一)是该领域的另一个重要人物,关于深度学习,杰夫如是说:
当听到深度学习这个词时,便会想到一个大的深度神经网络。深度通常指的是层数比较多,这是出版物中的一个流行术语,此刻,我便视它为深度神经网络。
在谈论深度学习时,杰夫强调了神经网络的可扩展性,即随着数据量的增大,模型规模的增大,模型输出的结果会越来越好,同时,训练的计算量也随之增大,这和先前看到的结果一致。
好了,理解了原理之后,那么神经网络如何进行深度学习的呢?
你可能已经猜到了:神经网络从数据中学习。
还记得将多个输入乘以权重之后输入到感知器中吗?连接两个不同神经元的“边”(连接)也需要赋权重。这意味着在较大的神经网络中,权重也存在于每个黑箱边之中,取一个神经元的输出,与其相乘,然后将其作为输入提供给这个边缘所连接的另一个神经元。
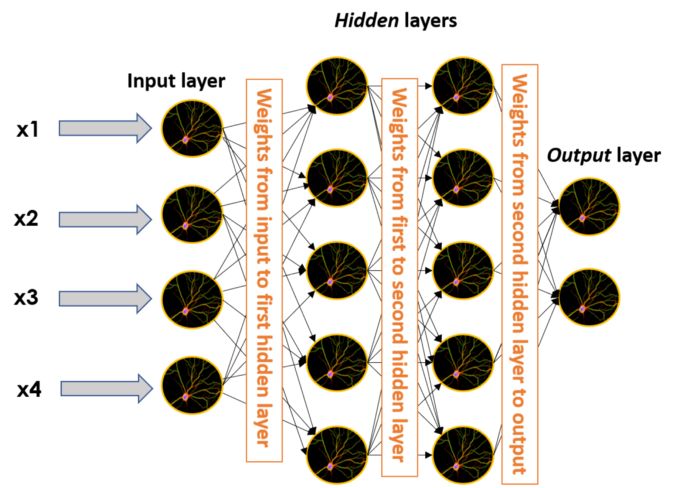
具有两个隐藏层的神经网络以及每个层之间的权重
当训练神经网络(通过ML表达式来训练神经网络使其进行学习)时,首先为它提供一组已知数据(在ML中称为标记数据),让它预测这些数据的特征(比如图像标记“狗”或“猫”)然后将预测结果与实际结果进行比对。
当这个过程在进行中出现错误时,它会调整神经元之间连接的权重,以减少所犯错误的数量。正因如此,如前所示,在大多数情况下,如果我们为网络提供更多的数据,将会提高它的性能。
从序列数据中学习 –递归神经网络
了解了人工神经网络和深度学习之后,我们懂得了神经网络是如何进行学习的,现在可以开始研究用于构建聊天机器人的神经网络:递归神经网络或RNN 。
递归神经网络是一种特殊的神经网络,旨在有效地处理序列数据,序列数据包括时间序列(在一定时间段内的参数值列表)、文本文档(可以视为单词序列)或音频(可视为声音频率序列)。
RNN获取每个神经元的输出,并将其作为输入反馈给它,它不仅在每个时间步长中接收新的信息,并且还向这些新信息中添加先前输出的加权值,从而,这些神经元具备了先前输入的一种“记忆”,并以某种方式将量化输出反馈给神经元。
递归神经元,输出数据乘以一个权重并反馈到输入中
来自先前时间步长的输入的函数单元称为记忆单元。
RNN存在的问题是:随着时间的流逝,RNN获得越来越多的新数据,他们开始“遗忘”有关数据,通过激活函数的转化及与权重相乘,稀释新的数据。这意味着RNN有一个很好的短期记忆,但在尝试记住前一段时间发生过的事情时,仍然会存在一些小问题(过去若干时间步长内的数据)。
为此,需要某种长期记忆,LSTM正是提供了长期记忆的能力。
增强记忆力 - 长期短期记忆网络
长短期记忆网络LSTM是RNN的一种变体,可解决前者的长期记忆问题。作为本文的结尾,简要解释它是如何工作的。
与普通的递归神经网络相比,它们具有更为复杂的记忆单元结构,从而使得它们能够更好地调节如何从不同的输入源学习或遗忘。
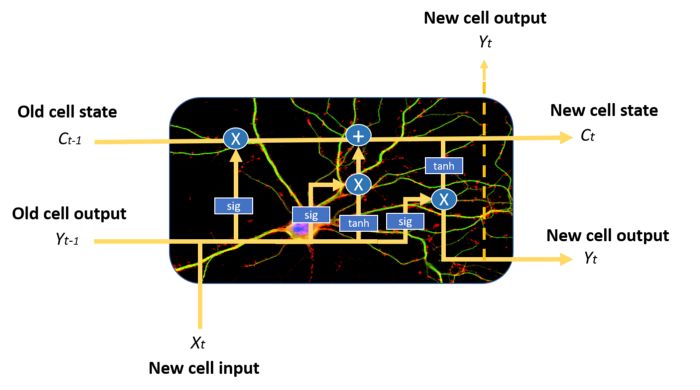
LSTM记忆单元示例。注意蓝色圆圈和方框,可以看出它的结构比普通的RNN单元更复杂,我们将不在本文中介绍它
LSTM神经元通过三个不同的门的状态组合来实现这一点:输入门,遗忘门和输出门。在每个时间步长中,记忆单元可以决定如何处理状态向量:从中读取,写入或删除它,这要归功于明确的选通机制。利用输入门,记忆单元可以决定是否更新单元状态;利用遗忘门,记忆单元可以删除其记忆;通过输出门,单元细胞可以决定输出信息是否可用。
LSTM还可以减轻梯度消失的问题,但这不在此做详细介绍。
就是这样!现在我们对这些不同种类的神经网络已经有了一个初浅的认识,下面可以开始用它来构建第一个深度学习项目!
结论
神经网络会非常神奇。在下一篇文章中,我们将看到,即便是一个非常简单的结构,只有几个层便可以创建一个非常强大的聊天机器人。哦,顺便问一下,记得这张照片吗?
由神经网络创建的带有简短文本描述的两幅不同图像
为了证明深度神经网络是多么酷,不得不承认,我对如何产生这些图像的描述撒了谎。
记得在本文的开头,曾说明这些描述是人工注释的,然而实际上,每幅图像上所的简短文本实际上都是人工神经网络生成的。
太狂啦?
如果想要学习如何使用深度学习来创建一个神奇的聊天机器人,请在媒体上追随我,并继续关注我的下一篇文章!然后,尽情享受人工智能!
其它资源
本帖中描述的概念解释非常初浅,如果想深入学习,请参考以下附加的资源。
- 神经网络如何端到端地工作https://end-to-end-machine-learning.teachable.com/courses/how-deep-neural-networks-work/lectures/9533963
- YouTube视频系列,讲解如何训练神经网络的主要概念https://www.youtube.com/watch?v=sZAlS3_dnk0
- 深度学习和人工神经网络https://machinelearningmastery.com/what-is-deep-learning/
◆
精彩推荐
◆

推荐阅读
肖仰华:知识图谱构建的三要素、三原则和九大策略 | AI ProCon 2019
微软语音AI技术与微软听听文档小程序实践 | AI ProCon 2019
AI落地遭“卡脖子”困境:为什么说联邦学习是解决良方?
10分钟搭建你的第一个图像识别模型 | 附完整代码
阿里披露AI完整布局,飞天AI平台首次亮相
程序员因接外包坐牢 456 天!两万字揭露心酸经历
限时早鸟票 | 2019 中国大数据技术大会(BDTC)超豪华盛宴抢先看!
Pandas中第二好用的函数 | 优雅的Apply
阿里开源物联网操作系统 AliOS Things 3.0 发布,集成平头哥 AI 芯片架构
雷声大雨点小:Bakkt「见光死」了吗?

你点的每个“在看”,我都认真当成了喜欢
相关文章:
大闸蟹的OO第二单元总结
OO的第二单元是讲多线程的协作与控制,三次作业分别为FAFS电梯,ALS电梯和三部需要协作的电梯。三次作业由浅入深,让我们逐渐理解多线程的工作原理和运行状况。 第一次作业: 第一次作业是傻瓜电梯,也就是完全不需要考虑捎…

构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(31)-MVC使用RDL报表
原文:构建ASP.NET MVC4EF5EasyUIUnity2.x注入的后台管理系统(31)-MVC使用RDL报表这次我们来演示MVC3怎么显示RDL报表,坑爹的微软把MVC升级到5都木有良好的支持报表,让MVC在某些领域趋于短板 我们只能通过一些方式来使用rdl报表。 Razor视图不支持asp.net…

18段代码带你玩转18个机器学习必备交互工具
(图片有AI科技大本营付费下载自视觉中国)作者 | 曼纽尔阿米纳特吉(Manuel Amunategui)、迈赫迪洛佩伊(Mehdi Roopaei)来源 | 大数据(ID:hzdashuju)【导读】本文简要介绍将…
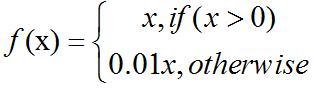
激活函数之ReLU/softplus介绍及C++实现
softplus函数(softplus function):ζ(x)ln(1exp(x)).softplus函数可以用来产生正态分布的β和σ参数,因为它的范围是(0,∞)。当处理包含sigmoid函数的表达式时它也经常出现。softplus函数名字来源于它是另外一个函数的平滑(或”软化”)形式,这…

windows server 2012 用sysdba登录报错 ORA-01031
报错显示:C:\Users\Administrator>sqlplus / as sysdba SQL*Plus: Release 11.2.0.1.0 Production on 星期三 4月 24 09:09:33 2019 Copyright (c) 1982, 2010, Oracle. All rights reserved. ERROR:ORA-01031: 权限不足 请输入用户名: 1、查看本地用户和组确认权…

[SignalR]初步认识以及安装
原文:[SignalR]初步认识以及安装1.什么是ASP.NET SignalR? ASP .NET SignalR是一个 ASP .NET 下的类库,可以在ASP .NET 的Web项目中实现实时通信。什么是实时通信的Web呢?就是让客户端(Web页面)和服务器端可以互相通知…
CUDA Samples:Vector Add
以下CUDA sample是分别用C和CUDA实现的两向量相加操作,参考CUDA 8.0中的sample:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\0_Simple,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CU…

你和人工智能的对话,正在被人工收听
(图片有AI科技大本营付费下载自视觉中国)作者 | 周晶晶编辑 | 阿伦来源 | 燃财经(ID:rancaijing)如今,智能设备越来越多地出现在每个人的生活中,在享受它们带来的便利时,很多人或许没有意识到&a…

python数据结构与算法总结
python常用的数据结构与算法就分享到此处,本月涉及数据结构与算法的内容有如下文章: 《数据结构和算法对python意味着什么?》 《顺序表数据结构在python中的应用》 《python实现单向链表数据结构及其基本方法》 《python实现单向循环链表数据…

自定义classloader中的接口调用
2019独角兽企业重金招聘Python工程师标准>>> 注意其中转型异常的描述,左边声明和强转括号内都是appclassloader加载的,而让自定义加载类的接口也由appclassloader加载,所以转型成功 转载于:https://my.oschina.net/heatonn1/blog/…

学点基本功:机器学习常用损失函数小结
(图片付费下载自视觉中国)作者 | 王桂波转载自知乎用户王桂波【导读】机器学习中的监督学习本质上是给定一系列训练样本 ,尝试学习 的映射关系,使得给定一个 ,即便这个不在训练样本中,也能够得到尽量接近…
python生成简单的FTP弱口令扫描
2019独角兽企业重金招聘Python工程师标准>>> 前言 Ftp这个类实现了Ftp客户端的大多数功能,比如连接Ftp服务器、查看服务器中的文件、上传、下载文件等功能,Ftp匿名扫描器的实现,需要使用FTP这个类,首先用主机名构造了一个Ftp对象(即ftp),然后用这个ftp调…
C++中const指针用法汇总
这里以int类型为例,进行说明,在C中const是类型修饰符:int a; 定义一个普通的int类型变量a,可对此变量的值进行修改。const int a 3;与 int const a 3; 这两条语句都是有效的code,并且是等价的,说明a是一个…
mongodb基础应用
一些概念 一个mongod服务可以有建立多个数据库,每个数据库可以有多张表,这里的表名叫collection,每个collection可以存放多个文档(document),每个文档都以BSON(binary json)的形式存…
【leetcode】1030. Matrix Cells in Distance Order
题目如下: We are given a matrix with R rows and C columns has cells with integer coordinates (r, c), where 0 < r < R and 0 < c < C. Additionally, we are given a cell in that matrix with coordinates (r0, c0). Return the coordinates of…
深度学习面临天花板,亟需更可信、可靠、安全的第三代AI技术|AI ProCon 2019
整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 在人工智能领域中,深度学习掀起了最近一次浪潮,但在实践和应用中也面临着诸多挑战,特别是关系到人的生命,如医疗、自动驾驶等领域场景时,黑盒…

java robot类自动截屏
直接上代码:package robot;import java.awt.Rectangle;import java.awt.Robot;import java.awt.event.InputEvent;import java.awt.p_w_picpath.BufferedImage;import java.io.File;import java.io.IOException;import javax.p_w_picpathio.ImageIO;import com.sun.glass.event…
激活函数之softmax介绍及C++实现
下溢(underflow):当接近零的数被四舍五入为零时发生下溢。许多函数在其参数为零而不是一个很小的正数时才会表现出质的不同。例如,我们通常要避免被零除或避免取零的对数。上溢(overflow):当大量级的数被近似为∞或-∞时发生上溢。进一步的运…
parsing:NLP之chart parser句法分析器
已迁移到我新博客,阅读体验更佳parsing:NLP之chart parser句法分析器 完整代码实现放在我的github上:click me 一、任务要求 实现一个基于简单英语语法的chart句法分析器。二、技术路线 采用自底向上的句法分析方法,简单的自底向上句法分析效率不高,常常…

图解Python算法
普通程序员,不学算法,也可以成为大神吗?对不起,这个,绝对不可以。可是算法好难啊~~看两页书就想睡觉……所以就不学了吗?就一直当普通程序员吗?如果有一本算法书,看着很轻松……又有…
详解SSH框架的原理和优点
Struts的原理和优点. Struts工作原理 MVC即Model-View-Controller的缩写,是一种常用的设计模式。MVC 减弱了业务逻辑接口和数据接口之间的耦合,以及让视图层更富于变化。MVC的工作原理,如下图1所示:Struts 是MVC的一种实现࿰…

Numpy and Matplotlib
Numpy介绍 编辑 一个用python实现的科学计算,包括:1、一个强大的N维数组对象Array;2、比较成熟的(广播)函数库;3、用于整合C/C和Fortran代码的工具包;4、实用的线性代数、傅里叶变换和随机数生成…
梯度下降法简介
条件数表征函数相对于输入的微小变化而变化的快慢程度。输入被轻微扰动而迅速改变的函数对于科学计算来说可能是有问题的,因为输入中的舍入误差可能导致输出的巨大变化。大多数深度学习算法都涉及某种形式的优化。优化指的是改变x以最小化或最大化某个函数f(x)的任务…

微软亚研院CV大佬代季峰跳槽商汤为哪般?
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)近日,知乎上一篇离开关于MSRA(微软亚洲研究院)和MSRA CV未来发展的帖子讨论热度颇高,这个帖子以MSRA CV执行研究主任代季峰离职加入商汤为引子,引…
iOS Block实现探究
2019独角兽企业重金招聘Python工程师标准>>> 使用clang的rewrite-objc filename 可以将有block的c代码转换成cpp代码。从中可以看到block的实现。 #include <stdio.h> int main() {void (^blk)(void) ^{printf("Block\n");};blk();return 0; } 使…
CUDA Samples: Long Vector Add
以下CUDA sample是分别用C和CUDA实现的两个非常大的向量相加操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CUDA_TEST_COMMON_HPP_ #define FBC_CUDA_TEST_COMMON_HPP_#include<random>template&l…

TensorFlow2.0正式版发布,极简安装TF2.0(CPUGPU)教程
作者 | 小宋是呢转载自CSDN博客【导读】TensorFlow 2.0,昨天凌晨,正式放出了2.0版本。不少网友表示,TensorFlow 2.0比PyTorch更好用,已经准备全面转向这个新升级的深度学习框架了。本篇文章就带领大家用最简单地方式安装TF2.0正式…
javascript全栈开发实践-准备
目标: 我们将会通过一些列教程,在只使用JavaScript开发的情况下,实现一个手写笔记应用。该应用具有以下特点: 全平台,有手机客户端(Android/iOS),Windows,macOSÿ…
POJ 1017 Packets 贪心 模拟
一步一步模拟,做这种题好累 先放大的的,然后记录剩下的空位有多少,塞1*1和2*2的进去 //#pragma comment(linker, "/STACK:1024000000,1024000000") #include<cstdio> #include<cstring> #include<cstdlib> #incl…

NLP被英语统治?打破成见,英语不应是「自然语言」同义词
(图片付费下载自视觉中国)作者 | Emily M. Bender译者 | 陆离责编 | 夕颜出品 | AI科技大本营(ID: rgznai100) 【导读】在NLP领域,多资源语言以英语、汉语(普通话)、阿拉伯语和法语为代表&#…