CUDA Samples:Vector Add
以下CUDA sample是分别用C++和CUDA实现的两向量相加操作,参考CUDA 8.0中的sample:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\0_Simple,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:
common.hpp:
#ifndef FBC_CUDA_TEST_COMMON_HPP_
#define FBC_CUDA_TEST_COMMON_HPP_#define PRINT_ERROR_INFO(info) { \fprintf(stderr, "Error: %s, file: %s, func: %s, line: %d\n", #info, __FILE__, __FUNCTION__, __LINE__); \return -1; }#define EXP 1.0e-5#endif // FBC_CUDA_TEST_COMMON_HPP_#ifndef FBC_CUDA_TEST_SIMPLE_HPP_
#define FBC_CUDA_TEST_SIMPLE_HPP_// reference: C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\0_Simple
int test_vectorAdd();
int vectorAdd_cpu(const float *A, const float *B, float *C, int numElements);
int vectorAdd_gpu(const float *A, const float *B, float *C, int numElements);#endif // FBC_CUDA_TEST_SIMPLE_HPP_
#include "simple.hpp"
#include <random>
#include <iostream>
#include <vector>
#include "common.hpp"// =========================== vector add =============================
int test_vectorAdd()
{// Vector addition: C = A + B, implements element by element vector additionconst int numElements{ 50000 };std::vector<float> A(numElements), B(numElements), C1(numElements), C2(numElements);// Initialize vectorfor (int i = 0; i < numElements; ++i) {A[i] = rand() / (float)RAND_MAX;B[i] = rand() / (float)RAND_MAX;}int ret = vectorAdd_cpu(A.data(), B.data(), C1.data(), numElements);if (ret != 0) PRINT_ERROR_INFO(vectorAdd_cpu);ret = vectorAdd_gpu(A.data(), B.data(), C2.data(), numElements);if (ret != 0) PRINT_ERROR_INFO(vectorAdd_gpu);for (int i = 0; i < numElements; ++i) {if (fabs(C1[i] - C2[i]) > EXP) {fprintf(stderr, "Result verification failed at element %d!\n", i);return -1;}}return 0;
}int vectorAdd_cpu(const float* A, const float* B, float* C, int numElements)
{for (int i = 0; i < numElements; ++i) {C[i] = A[i] + B[i];}return 0;
}#include "simple.hpp"
#include <iostream>
#include <cuda_runtime.h> // For the CUDA runtime routines (prefixed with "cuda_")
#include <device_launch_parameters.h>
#include "common.hpp"// reference: C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\0_Simple// =========================== vector add =============================
/* __global__: 函数类型限定符;在设备上运行;在主机端调用,计算能力3.2及以上可以在
设备端调用;声明的函数的返回值必须是void类型;对此类型函数的调用是异步的,即在
设备完全完成它的运行之前就返回了;对此类型函数的调用必须指定执行配置,即用于在
设备上执行函数时的grid和block的维度,以及相关的流(即插入<<< >>>运算符);
a kernel,表示此函数为内核函数(运行在GPU上的CUDA并行计算函数称为kernel(内核函
数),内核函数必须通过__global__函数类型限定符定义);*/
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements)
{/* blockDim: 内置变量,用于说明每个block的维度与尺寸.为dim3类型,包含了block在三个维度上的尺寸信息;对于所有线程块来说,这个变量是一个常数,保存的是线程块中每一维的线程数量;blockIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程块的索引;用于说明当前thread所在的block在整个grid中的位置,blockIdx.x取值范围是[0,gridDim.x-1],blockIdx.y取值范围是[0, gridDim.y-1].为uint3类型,包含了一个block在grid中各个维度上的索引信息;threadIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程索引;用于说明当前thread在block中的位置;如果线程是一维的可获取threadIdx.x,如果是二维的还可获取threadIdx.y,如果是三维的还可获取threadIdx.z;为uint3类型,包含了一个thread在block中各个维度的索引信息 */int i = blockDim.x * blockIdx.x + threadIdx.x;if (i < numElements) {C[i] = A[i] + B[i];}
}int vectorAdd_gpu(const float *A, const float *B, float *C, int numElements)
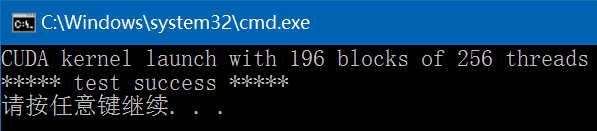
{/* Error code to check return values for CUDA callscudaError_t: CUDA Error types, 枚举类型,CUDA错误码,成功返回cudaSuccess(0),否则返回其它(>0) */cudaError_t err{ cudaSuccess };size_t length{ numElements * sizeof(float) };float *d_A{ nullptr }, *d_B{ nullptr }, *d_C{ nullptr };// cudaMalloc: 在设备端分配内存err = cudaMalloc(&d_A, length);if (err != cudaSuccess) {// cudaGetErrorString: 返回错误码的描述字符串fprintf(stderr, "Failed to allocate device vector A (error code %s)!\n",cudaGetErrorString(err));return -1;}err = cudaMalloc(&d_B, length);if (err != cudaSuccess) PRINT_ERROR_INFO(cudaMalloc);err = cudaMalloc(&d_C, length);if (err != cudaSuccess) PRINT_ERROR_INFO(cudaMalloc);/* cudaMemcpy: 在主机端和设备端拷贝数据,此函数第四个参数仅能是下面之一:(1). cudaMemcpyHostToHost: 拷贝数据从主机端到主机端(2). cudaMemcpyHostToDevice: 拷贝数据从主机端到设备端(3). cudaMemcpyDeviceToHost: 拷贝数据从设备端到主机端(4). cudaMemcpyDeviceToDevice: 拷贝数据从设备端到设备端(5). cudaMemcpyDefault: 从指针值自动推断拷贝数据方向,需要支持统一虚拟寻址(CUDA6.0及以上版本) */err = cudaMemcpy(d_A, A, length, cudaMemcpyHostToDevice);if (err != cudaSuccess) PRINT_ERROR_INFO(cudaMemcpy);err = cudaMemcpy(d_B, B, length, cudaMemcpyHostToDevice);if (err != cudaSuccess) PRINT_ERROR_INFO(cudaMemcpy);// Launch the Vector Add CUDA kernelconst int threadsPerBlock{ 256 };const int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;fprintf(stderr, "CUDA kernel launch with %d blocks of %d threads\n",blocksPerGrid, threadsPerBlock);/* <<< >>>: 为CUDA引入的运算符,指定线程网格和线程块维度等,传递执行参数给CUDA编译器和运行时系统,用于说明内核函数中的线程数量,以及线程是如何组织的;尖括号中这些参数并不是传递给设备代码的参数,而是告诉运行时如何启动设备代码,传递给设备代码本身的参数是放在圆括号中传递的,就像标准的函数调用一样;不同计算能力的设备对线程的总数和组织方式有不同的约束;必须先为kernel中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误,例如越界等;使用运行时API时,需要在调用的内核函数名与参数列表直接以<<<Dg,Db,Ns,S>>>的形式设置执行配置,其中:Dg是一个dim3型变量,用于设置grid的维度和各个维度上的尺寸.设置好Dg后,grid中将有Dg.x*Dg.y个block,Dg.z必须为1;Db是一个dim3型变量,用于设置block的维度和各个维度上的尺寸.设置好Db后,每个block中将有Db.x*Db.y*Db.z个thread;Ns是一个size_t型变量,指定各块为此调用动态分配的共享存储器大小,这些动态分配的存储器可供声明为外部数组(extern __shared__)的其他任何变量使用;Ns是一个可选参数,默认值为0;S为cudaStream_t类型,用于设置与内核函数关联的流.S是一个可选参数,默认值0. */vectorAdd <<<blocksPerGrid, threadsPerBlock >>>(d_A, d_B, d_C, numElements);/* cudaGetLastError: 在同一个主机线程中,返回运行时调用中产生的最后一个错误并将其重置为cudaSuccess;此函数也可能返回以前异步启动的错误码;当有多个错误在对cudaGetLastError的调用之间发生时,仅最后一个错误会被报告;kernel的启动是异步的,为了定位它是否出错,一般需要加上cudaDeviceSynchronize函数进行同步,然后再调用cudaGetLastError函数;*/err = cudaGetLastError();if (err != cudaSuccess) PRINT_ERROR_INFO(cudaGetLastError);// Copy the device result vector in device memory to the host result vector in host memory.err = cudaMemcpy(C, d_C, length, cudaMemcpyDeviceToHost);if (err != cudaSuccess) PRINT_ERROR_INFO(cudaMemcpy);// cudaFree: 释放设备上由cudaMalloc函数分配的内存err = cudaFree(d_A);if (err != cudaSuccess) PRINT_ERROR_INFO(cudaFree);err = cudaFree(d_B);if (err != cudaSuccess) PRINT_ERROR_INFO(cudaFree);err = cudaFree(d_C);if (err != cudaSuccess) PRINT_ERROR_INFO(cudaFree);return err;
}
GitHub: https://github.com/fengbingchun/CUDA_Test
相关文章:

你和人工智能的对话,正在被人工收听
(图片有AI科技大本营付费下载自视觉中国)作者 | 周晶晶编辑 | 阿伦来源 | 燃财经(ID:rancaijing)如今,智能设备越来越多地出现在每个人的生活中,在享受它们带来的便利时,很多人或许没有意识到&a…

python数据结构与算法总结
python常用的数据结构与算法就分享到此处,本月涉及数据结构与算法的内容有如下文章: 《数据结构和算法对python意味着什么?》 《顺序表数据结构在python中的应用》 《python实现单向链表数据结构及其基本方法》 《python实现单向循环链表数据…

自定义classloader中的接口调用
2019独角兽企业重金招聘Python工程师标准>>> 注意其中转型异常的描述,左边声明和强转括号内都是appclassloader加载的,而让自定义加载类的接口也由appclassloader加载,所以转型成功 转载于:https://my.oschina.net/heatonn1/blog/…

学点基本功:机器学习常用损失函数小结
(图片付费下载自视觉中国)作者 | 王桂波转载自知乎用户王桂波【导读】机器学习中的监督学习本质上是给定一系列训练样本 ,尝试学习 的映射关系,使得给定一个 ,即便这个不在训练样本中,也能够得到尽量接近…
python生成简单的FTP弱口令扫描
2019独角兽企业重金招聘Python工程师标准>>> 前言 Ftp这个类实现了Ftp客户端的大多数功能,比如连接Ftp服务器、查看服务器中的文件、上传、下载文件等功能,Ftp匿名扫描器的实现,需要使用FTP这个类,首先用主机名构造了一个Ftp对象(即ftp),然后用这个ftp调…

C++中const指针用法汇总
这里以int类型为例,进行说明,在C中const是类型修饰符:int a; 定义一个普通的int类型变量a,可对此变量的值进行修改。const int a 3;与 int const a 3; 这两条语句都是有效的code,并且是等价的,说明a是一个…
mongodb基础应用
一些概念 一个mongod服务可以有建立多个数据库,每个数据库可以有多张表,这里的表名叫collection,每个collection可以存放多个文档(document),每个文档都以BSON(binary json)的形式存…
【leetcode】1030. Matrix Cells in Distance Order
题目如下: We are given a matrix with R rows and C columns has cells with integer coordinates (r, c), where 0 < r < R and 0 < c < C. Additionally, we are given a cell in that matrix with coordinates (r0, c0). Return the coordinates of…
深度学习面临天花板,亟需更可信、可靠、安全的第三代AI技术|AI ProCon 2019
整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 在人工智能领域中,深度学习掀起了最近一次浪潮,但在实践和应用中也面临着诸多挑战,特别是关系到人的生命,如医疗、自动驾驶等领域场景时,黑盒…

java robot类自动截屏
直接上代码:package robot;import java.awt.Rectangle;import java.awt.Robot;import java.awt.event.InputEvent;import java.awt.p_w_picpath.BufferedImage;import java.io.File;import java.io.IOException;import javax.p_w_picpathio.ImageIO;import com.sun.glass.event…
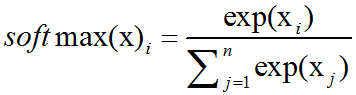
激活函数之softmax介绍及C++实现
下溢(underflow):当接近零的数被四舍五入为零时发生下溢。许多函数在其参数为零而不是一个很小的正数时才会表现出质的不同。例如,我们通常要避免被零除或避免取零的对数。上溢(overflow):当大量级的数被近似为∞或-∞时发生上溢。进一步的运…
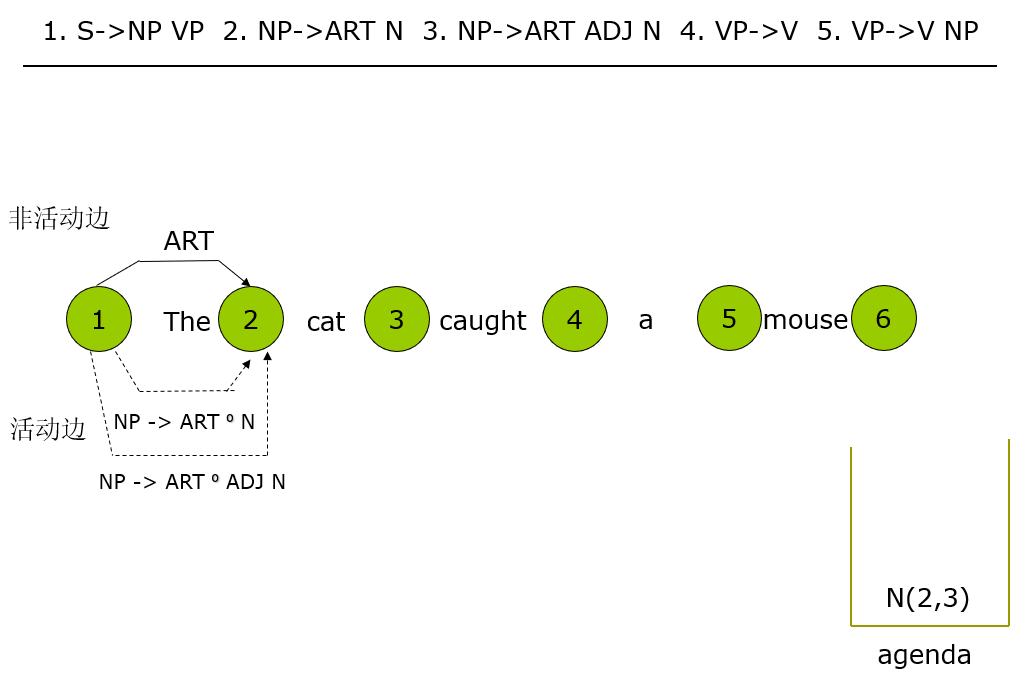
parsing:NLP之chart parser句法分析器
已迁移到我新博客,阅读体验更佳parsing:NLP之chart parser句法分析器 完整代码实现放在我的github上:click me 一、任务要求 实现一个基于简单英语语法的chart句法分析器。二、技术路线 采用自底向上的句法分析方法,简单的自底向上句法分析效率不高,常常…

图解Python算法
普通程序员,不学算法,也可以成为大神吗?对不起,这个,绝对不可以。可是算法好难啊~~看两页书就想睡觉……所以就不学了吗?就一直当普通程序员吗?如果有一本算法书,看着很轻松……又有…
详解SSH框架的原理和优点
Struts的原理和优点. Struts工作原理 MVC即Model-View-Controller的缩写,是一种常用的设计模式。MVC 减弱了业务逻辑接口和数据接口之间的耦合,以及让视图层更富于变化。MVC的工作原理,如下图1所示:Struts 是MVC的一种实现࿰…

Numpy and Matplotlib
Numpy介绍 编辑 一个用python实现的科学计算,包括:1、一个强大的N维数组对象Array;2、比较成熟的(广播)函数库;3、用于整合C/C和Fortran代码的工具包;4、实用的线性代数、傅里叶变换和随机数生成…
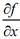
梯度下降法简介
条件数表征函数相对于输入的微小变化而变化的快慢程度。输入被轻微扰动而迅速改变的函数对于科学计算来说可能是有问题的,因为输入中的舍入误差可能导致输出的巨大变化。大多数深度学习算法都涉及某种形式的优化。优化指的是改变x以最小化或最大化某个函数f(x)的任务…

微软亚研院CV大佬代季峰跳槽商汤为哪般?
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)近日,知乎上一篇离开关于MSRA(微软亚洲研究院)和MSRA CV未来发展的帖子讨论热度颇高,这个帖子以MSRA CV执行研究主任代季峰离职加入商汤为引子,引…
iOS Block实现探究
2019独角兽企业重金招聘Python工程师标准>>> 使用clang的rewrite-objc filename 可以将有block的c代码转换成cpp代码。从中可以看到block的实现。 #include <stdio.h> int main() {void (^blk)(void) ^{printf("Block\n");};blk();return 0; } 使…
CUDA Samples: Long Vector Add
以下CUDA sample是分别用C和CUDA实现的两个非常大的向量相加操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CUDA_TEST_COMMON_HPP_ #define FBC_CUDA_TEST_COMMON_HPP_#include<random>template&l…

TensorFlow2.0正式版发布,极简安装TF2.0(CPUGPU)教程
作者 | 小宋是呢转载自CSDN博客【导读】TensorFlow 2.0,昨天凌晨,正式放出了2.0版本。不少网友表示,TensorFlow 2.0比PyTorch更好用,已经准备全面转向这个新升级的深度学习框架了。本篇文章就带领大家用最简单地方式安装TF2.0正式…
javascript全栈开发实践-准备
目标: 我们将会通过一些列教程,在只使用JavaScript开发的情况下,实现一个手写笔记应用。该应用具有以下特点: 全平台,有手机客户端(Android/iOS),Windows,macOSÿ…

POJ 1017 Packets 贪心 模拟
一步一步模拟,做这种题好累 先放大的的,然后记录剩下的空位有多少,塞1*1和2*2的进去 //#pragma comment(linker, "/STACK:1024000000,1024000000") #include<cstdio> #include<cstring> #include<cstdlib> #incl…

NLP被英语统治?打破成见,英语不应是「自然语言」同义词
(图片付费下载自视觉中国)作者 | Emily M. Bender译者 | 陆离责编 | 夕颜出品 | AI科技大本营(ID: rgznai100) 【导读】在NLP领域,多资源语言以英语、汉语(普通话)、阿拉伯语和法语为代表&#…
CUDA Samples: Dot Product
以下CUDA sample是分别用C和CUDA实现的两个非常大的向量实现点积操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CUDA_TEST_COMMON_HPP_ #define FBC_CUDA_TEST_COMMON_HPP_#include<random>templa…

element ui只输入数字校验
注意:圈起来的两个地方,刚开始忘记写typenumber了,导致可以输入‘123abc’这样的,之后加上了就OK了 转载于:https://www.cnblogs.com/samsara-yx/p/10774270.html
对DeDecms之index.php页面的补充
2019独角兽企业重金招聘Python工程师标准>>> 1、301是什么? 其实就是HTTP状态表。就是当用户输入url请求时,服务器的一个反馈状态。 详细链接http://www.cnblogs.com/kunhony/archive/2006/06/16/427305.html 2、common.inc.php和arc.partvi…
OpenCV-Python:K值聚类
关于K聚类,我曾经在一篇博客中提到过,这里简单的做个回顾。 KMeans的步骤以及其他的聚类算法 K-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算 其他聚类算法:二分K-均值 讲解一下步骤,其实…

CUDA Samples: Julia
以下CUDA sample是分别用C和CUDA实现的绘制Julia集曲线,并对其中使用到的CUDA函数进行了解说,code参考了《GPU高性能编程CUDA实战》一书的第四章,各个文件内容如下:funset.cpp:#include "funset.hpp" #include <rand…

给初学者的深度学习入门指南
从无人驾驶汽车到AlphaGo战胜人类,机器学习成为了当下最热门的技术。而机器学习中一种重要的方法就是深度学习。作为一个有理想的程序员,若是不懂人工智能(AI)领域中深度学习(DL)这个超热的技术,…
epoll/select
为什么80%的码农都做不了架构师?>>> epoll相对select优点主要有三: 1. select的句柄数目受限,在linux/posix_types.h头文件有这样的声明:#define __FD_SETSIZE 1024 表示select最多同时监听1024个fd。而epoll没…