肖仰华:知识图谱构建的三要素、三原则和九大策略 | AI ProCon 2019
演讲嘉宾 | 肖仰华(复旦大学教授、博士生导师,知识工场实验室负责人)
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
近两年,知识图谱技术得到了各行各业的关注,无论是企业公司还是开发者个人,都对这项技术有着极大的了解与使用需求。在近日的 AI开发者大会(AI ProCon 2019)的知识图谱技术专题,演讲嘉宾为开发者们分享了该领域技术应用的实践经验与未来发展趋势。
其中,复旦大学教授、博士生导师,知识工场实验室负责人肖仰华教授从知识图谱目前所面临的机遇与挑战出发,分析了大规模知识图谱自动化构建的三个要素、三大原则和五个环节,并重点讲解了知识图谱落地的九大构建策略,这将帮助开发者聚焦知识图谱的主流方向,助力企业构建自己的知识图谱。
以下为肖仰华教授的演讲内容实录,AI科技大本营(ID:rgznai100)整理:
首先非常开心能有机会再次在 CSDN 和大家分享我们在知识图谱的构建和应用方面的工作和一些思考。今天给大家带来的题目是《知识图谱构建与应用 In Practice》。
凡是做知识图谱工作的都有一个体会:最近知识图谱的研究特别火热,大家可以看到大量知识图谱的论文和成果,但真正把这些来自大公司或者名校的论文或技术成果拿到自己的应用场景中时,就会切实感受到各种各样的问题,“技术还是别人家的技术”,尤其在知识图谱领域中更是如此。
但学术界的成果真的没有可取之处吗?其实不然。还是有一些非常实用的方法、经验可以借鉴的。所以,今天我就想跟大家分享在知识图谱的构建和应用这个问题中,真正能够有效解决问题的一些思路、策略和方法,也就是我题目中“In Practice”的核心。
知识图谱是什么?知识图谱为什么重要?今天因为时间有限,这个问题就不细展开了。我认为知识图谱是一个大规模的应用,实际上是知识工程在大数据时代再次复现的产物,这就是我对知识图谱的定位。知识图谱能解决什么问题?很多,比如,知识图谱可以让机器实现语言认知、人工智能、与数据驱动一道成为另外一种解决问题的范式,比如应用在搜索、决策、问答、支持等等,具体内容可以在这本新书中《知识图谱概念与技术》看到。
一、知识图谱作为大数据知识工程的典型代表,以自动化知识获取为其根本特征
今天想传达的第一个观点是,知识图谱实际是一个大数据知识工程的典型产物,是以自动化知识获取为其根本特征。知识图谱既不是NLP也不是语义网,作为这一产物有其独特的价值,即自动化知识获取。为什么这么说?我们可以想一下传统方法是怎么做知识工程的?是依靠专家,专家描述这个事件,把本体定义出来,专家来书写知识,这是一种完全手工的做法。如果说今天做知识图谱的你还在走传统知识工程的老路的话,那你做的就不是我们这个大数据时代的知识图谱,你所做的图谱本质也就不是一个知识图谱,它仍是一个传统的小规模的网络。知识图谱之所以是知识图谱,其根本的特征就是以自动化知识获取为它的根本特征。
知识图谱脱胎于符号主义。符号主义的概念中“智能”的本质就是符号的操作和运算,这是图灵奖以及诺贝尔获得者Newell和Simon的观点,这个观念又被叫做知识+推理。传统的知识工程应用很多都是有限制的,大部分都在规则明确、边界清晰、应用封闭的场景中取得了巨大成功,如石油、医疗、化工等领域。这些领域看起来是垂直封闭的,但实际上绝大部分都不是真正封闭的,在金融领域,与很多因素都有关系,比如跟天气有关,台风一来农作物产量自然下降,相应的公司股票就要下跌,这些都决定了很多领域都不是绝对封闭的。
传统知识工程为什么有这样苛刻的条件呢?因为它是极依赖人的一种做法,称之为典型的自上而下的做法,后来看到很多人也在呼应这种说法。何为自上而下?就是依赖专家,首先依赖专家制作知识表,还需要知识工程师把专家的知识变成计算机处理的知识,还需要人的反馈。这样很重度的人工参与,会导致知识的获取和知识的应用都非常困难。
我个人有一个观点:工业智能化能否成功决定了认知智能是否成功。所以,传统知识工程到了互联网时代就不再适应整个互联网应用的需要,互联网应用的特点,以谷歌搜索这样的互联网应用为例,它的基本特点是大规模开放性,我们永远不知道用户下一个搜索的关键字是什么,目前很多应用推理其实非常简单,互联网搜索大部分使用的还是简单的推理。
而我们认为知识图谱之所以出现,实际上是因为这个时代的需要。互联网时代需要新的知识图谱,另外大数据时代的到来也给大规模自动化的知识获取提供了机遇。基于传统知识图谱,我们现在拥有什么?有新的算力,有前所未有的海量数据,有花样繁多的深度学习模型,所以算法、算力和数据都是现在有而过去所没有的。
这个新的机遇使大规模自动化的自动获取成为可能。一方面,现在发展了大量自下而上的自动化知识获取,自下而上的过程就是从数据中自动挖掘得到知识图谱。比如最早从互联网网页,后来从电商购物记录、搜索日志、网页中获取大数据,我们能不能从这些数据中获取简单知识图谱?其实整个知识图谱就代表着这种趋势,用一些模型算法从数据中自动挖掘一些简单的知识表示。
此外,还有众包平台,各种各样的众包平台帮助我们获得知识;高质量的UGC,在互联网上使用问答、社区、维基等用户数据,使得我们构建高质量知识库成为可能。因此,大数据时代的到来势必需要与这个时代相适应的新的知识表示,这就是知识图谱为什么出现的根本原因。而知识图谱的出现,一方面是因为时代的需要,另一方面也是因为这个时代创造了它必要的存在条件,这个时代给它提供了海量数据、算力和算法。
可以说知识图谱的出现说明了一点,就是大规模自动化知识获取已经成为可能,我们延着知识图谱这个趋势有望突破传统知识库的规模和质量上的瓶颈,正因为传统知识库在规模和质量上的瓶颈有望被突破,所以,我们认为知识图谱的到来很有可能是整个认知智能时代到来的一个序曲。我们很有可能将要迎接的是一个大知识的时代,好比我们曾经从小数据进入到大数据时代,我们很有可能正在经历从过去传统的小规模知识表示向以知识图谱为代表的,各种各样大规模知识图谱为代表的大知识时代的到来。
以上想给大家传达知识图谱很重要,同时知识图谱之所以成为知识图谱,必须是依赖自动化获取,还靠人工构建显然不行的。
现在很多的互联网知识图谱动辄数千万、数百亿的实体,依靠人工如何构建?根本不可能。现在大家都知道知识图谱很好,知识图谱有望解决人工智能很多问题,是人工智能实现的一个非常重要的保障。那么问题来了,我们到底怎样做到知识图谱的自动化获取?其实这是所有人都想做到的。谁不想获得数据得到图谱,基于图谱形成认知能力,赋能各种应用场景,这是梦寐以求的事,但难在怎么实现自动化的知识获取?
实现自动化的知识获取,接下来分享一些我们的经验。
二、大规模知识图谱的自动化、高质量构建:关键要素、基本原则、关键技术
1、知识图谱构建的三个核心要素
首先,知识图谱构建有三个非常核心的要素:规模、质量、成本。
其次,知识图谱的整个构建生命周期涉及五个非常重要的环节。第一个环节是抽取,如果你有结构化的数据就可以做自动抽取,但很多时候没有结构化的数据,比如我们有大量存在的非结构化的文本数据,怎么做结构化数据的抽取?获取之后,第二环节是纠错、第三环节是补全,第四是更新,第五是精化,最后知识的对与错还需要交给人来验证。
当前各种各样的应用场景中,整个图谱构建到底面临的基本形势是什么?我认为要从两方面谈起:挑战和机遇。
现在整个图谱构建面临的挑战是什么?一是需求多样,因为数据来源的多样性,有的要做抽取,有的要处理半结构化数据,有的可能是结构化数据做转换就可以了,所以知识图谱构建的需求是多样的;第二是规模往往要求很大;第三,知识图谱构建之后所支撑的业务很庞大;第四,构建知识图谱的数据本身很稀疏,尤其是高质量数据;第五,知识分布不均匀,有一些知识样本很多,有一些知识很少;第六,质量低下,有很多“脏”数据或错误数据;第七,资源有限,没有哪家公司的资源是无限的,即便像华为这样规模的企业,越大的公司资源越有限,它的任务也就越多。
我们的机会在哪儿?是不是一点机会没有?不是,我们也有机会把知识图谱自动化构建做好,特别是在垂直领域,尤其是传统行业。首先,工业场景中专家知识是很丰富的;第二,很多行业虽然没有标准数据、结构化数据,但文本数据还是很多的,尤其是在医疗、金融、工业等领域的应用场景中;第三,有些场景,特别是头部企业中,用户行为数据很多,像电商、搜索,用户有着非常丰富的搜索行为数据、购物记录数据;第四,现在有很多深度学习模型,这也是一个机会;第五,现在已经存在一些高质量图谱、行业词典,并不是从零开始;第六,各种方法并存,我们现在不缺方法,现在各种技术图书中都是在讲方法,问题在于方法这么多,关键是怎么做选择,怎么做合并,怎么做组合,我们能不能把这些方法组合到一起变成一道“大餐”,是一件非常重要的事。
2、知识图谱的构建方式
正因为面临这些挑战和机遇,我们需要怎样的知识图谱构建方式?
首先是普适,尽量采用普适的方式,如图模型,建模能力强,可解释;二是轻量,大部分都是做一些小模型;第三,还要廉价,如果在自己的业务中评估需要几千万来做数据标注,这也是不现实的;还有,能不能采用无监督,端到端的方式;现在有这么多的数据,不单单是抽取文本数据,如何用行为数据驱动,也是非常重要的。我们有这么多思路,还需要演化出具体的策略,接下来就和大家分享一下我们的具体策略。
3、构建知识图谱的九大策略
第一,端到端 VS Pipeline?
现在设计了很多方法。一种方法是走流水线的方法,但每一步都有可能出错,最后不可收拾,这就是Pipeline的做法,它会带来错误的传播和累计。而我们需要端到端的,这就是深度学习的好处,深度学习不是一点好处没有,好处在于它是端到端的框架。如果在达到同样效果的前提下,显然端到端的方法完胜Pipeline。
第二,无监督 VS 有监督?
我们希望是无监督,无监督才有可能帮我们降低成本。实际上。现在特别迫切需要无监督的方法。无监督能做吗?其实是可以做的。我们最近在很多落地的案例里,知识图谱构建过程中大量的采用了无监督的方法,比如做一个领域的词汇挖掘,绝大多数领域的智能挖掘,就是词汇知识的挖掘。为什么?比如说让在座的所有人,大家都是做IT的,如果我强迫你转业到电力行业,你做的第一件事肯定是从学习这个领域的词汇开始;比如,你以前从没有学过深度学习,现在你开始学深度学习,第一件事肯定是从这个领域的专业词汇知识开始学习,什么是深度学习、卷机、泛化等术语的学习。所以,能不能让机器尽快学会这个领域的词汇,词汇之间的关联,也就是词汇知识挖掘,往往是某一个领域知识图谱构建的第一步,也是整个领域智能化的第一步。
有哪些思路?很多领域有很多文本文档,现在基本上可以做到只要有足量文本,就能从文本中把词汇、缩略词、同义词、上位词、下义词以及一些定义都可以学习出来,但这依赖大量的统计特征。除了这个思路,还充分应用了外部的领域知识来做校正,这是综合的办法,从而避免了数据标注。不用数据标注,基本上一个新领域90%以上词汇挖掘都是可以做到,这就是一个无监督的概念图谱构建。
第三个,数据驱动 VS 文本抽取?
刚才讲到,现在一想到图谱构建,很多人就会想到从文档中抽取数据,但是大家不要忘了,其实很多领域除了文本数据还有很多用户的数据,用户数据对于构建图谱来说很重要,这里我举几个案例。
首先是基于搜索的数据,很多企业有知识管理平台,有用户的搜索日志,其实通过用户的搜索日志就能构建很多图谱,比如在华为的平台中就可以知道高思是华为的数据库,然后就可以把它挖掘出来,因为高思的人都点各种各样的数据库,所以高思就是数据库公司;其次,还发现点AI的人也点了人工智能,点了人工智能也点了AI,所以这两个词是同义词,这都是基于搜索的用户行为数据
还有电商行为,我们也会从电商的搜索日志里挖掘,因为用户买东西可能不单单搜一种,这几种数据间十有八九是有关联的,比如电饭煲、调味罐他们是有关联的,都属于厨房用品,如果你有用户的行为数据是可以做图谱构建的;还可以利用购物车中的数据,这是电商领域中最宝贵的数据,买了A也买了B?其实往往是有原因的,一个人买了维生素C又买了感冒灵,肯定感冒了,这几样东西一起买一定有道理,我就可以把上面的关联挖掘出来;如果对购物篮数据做充分的挖掘,就可以知道这几种物品为什么在一起,就构建出了场景图谱。
这其中还有一个非常重要的趋势,大数据的统计观点、语义观点将是从事大数据领域一个非常重大的机会。我们不缺数据,我们从数据中挖掘统计关联已经做了很多年,但现在一个非常重要的任务就是探究这些统计关联到底意味着什么?这将是摆在在座各位面前非常重要的任务,谁先解决这个问题就能率先洞察用户的动机和需求,也就可以给你的用户提供更好的服务,这是我们在很多头部场景做了很多业务后发现的一个非常重大的机会,但这才刚刚开始,还有很多事情要做。
如何做互联网热点驱动的主动更新?
要解决这个问题,首先你会发现并不是图谱中所有实体都需要更新,只有那些热门的实体才需要更新,才需要给一个比较高频率的更新,所以,我们要利用互联网的热点数据来驱动更新。大家可以试想,比如秦始皇,这个词条一般不需要更新,除非他又从坟墓里爬出来了,但如果哪个明星离婚了,他的相关信息就要更新了,所以我们要充分利用互联网的热点来驱动我只是图谱的更新,只为互联网的热点实体驱动知识图谱更新,可以先从所有新闻平台的TOP10中找实体种子,看提到了哪些事例,优先更新这些实体就可以了,同时又避免了全量更新所付出的代价。
第四,统计模型+符号知识 VS 单一的统计模型?
肯定选前者。如果能把符号知识用上,很多统计模型最后的准确率是可以提升一个档次的。举个例子,我们做 Entity Typing,给特朗普打很多的标签,比如他是竞选人、他是总统,以前还做过商人、节目主持人,我们希望给特朗普尽可能全的打上标签,也是先通过一些文本、深度模型找到他候选的概念,再进一步就利用很多符号知识,如来自概念图谱中实体的概念、概念与概念之间的关系等符号知识,概念之间的关系可以帮我们构造很多DH。我们知道,如果X是一个人,他就不可能是一本书,如果X是一个政治人物,那他一定是个人物,这就是概率与概率之间的互斥和兼容关系,就能构成(下图)右边的公式,这是融合出来的对概念标签的一个约束。
还可以利用概念知识构造注意力。我们利用概念知识,一大助力是可以在“对”和“错”的概念标签中做选择,另一大帮助是在高质量和低质量的概念标签中做选择,细节我不多讲了,我希望告诉大家一点,实际中,你可以在你构建知识图谱构建时,用上你已经建好的大量的知识库。
第五,间接知识引导 VS 直接数据驱动?
选间接知识引导。我们注意到以前的关系获取或者关系分类,一般建模成一个分类模型,把比尔盖茨和迈克尔分到一个关系,以前是把这个关系当一个ID,用他的ID信息。但事实上,我们有那么多的文本数据,是否能利用文本数据先去挖一挖关系,挖掘这个主题的上下文主题词,来增强这个关系的描述,这就是我们的基本思路。
什么是间接知识引导?先从舆论上挖掘知识,把这个关系的主题词挖掘出来,利用这个关系的主题词增强这个关系的描述,再输入到我们深度模型中。以前就是所有的数据输进去,现在是先挖掘一下这些有用的知识,甚至还可以做一些筛选,选择高质量的知识,提升效果,从实验结果上来看,还是很支撑这一想法的。
再进一步的看这个例子,也是跟文本生成有关系。我们经常会打很多概念标签,以前的模型是很暴力的数据驱动,数据进去,结果出来,现在怎么做?我们有没有可能先去挖掘一个Pattern。我们发现,实体的概念标签都具有一些很常见的Pattern,并且是符合一定的语法Pattern,如都是一个<修饰词>加<核心词>,中间加一个<介词>。
在深度学习趋势之前,我们从文本中挖掘语法、语义Pattern的工作做了很多,现在为什么把以前做的东西都扔掉呢?能不能拿来用呢?我们不要把十年前做的成果都抛弃,其实那时候做的工作还是很有用的。
先通过语料把这些Pattern挖掘出来,之后的输入就不单单是原始输入了,还包括这些Pattern也作为输入进入模型中。所以,最终工作包含两步:先挖Pattern,再把Pattern输入到深度模型中,用来增强和提升我们生成的效率。
第六,图模型 VS 其他模型
我们选择图模型,表达能力强,普适、可解释,图模型也是非常常用的方法。比如在知识补全过程中,我们运用了基于图模型的方法,可以在模型上做很多细微的调整,基于图模型的方法在真正落地时达到95%以上的准确率是不难的,但如果用深度模型做到95%以上是很难很难的,而且我也不知道这个“黑盒子”,没机会调控它,我们实际中构建一个数千万知识图谱的时候都是用基于图模型的方法。
在纠错过程中也是选择了图模型。比如存在一个反向错误,纠错的问题就可以建模成图上三边的问题。
图模型还可以应用于领域知识图谱精化中。在电商平台场景中,(如下图所示)显示的所有词都是关于女性的衣服,在话题上都是同一个话题,现在要把它区分开来是非常困难的,细粒度的主题区分,需要很多很精细的模型来区分,虽然它在主题上都是关于女性衣服的修饰,但它在类别上是完全不同的,这种很细粒度的划分也是图模型可以做的。
第七,利用专家构建的知识自动标注样本 VS 手动标注样本
显然是前者。很多自动化构建知识图谱时都已经有一个专家构建的小规模图谱,此时,你可以利用专家构建的小规模图谱做自动样本标注,也是现在利用知识图谱构建样本在做的工作。
第八,复合架构 VS 单一模型的选择
显然也是前者。还有生成+验证也是一个非常好的框架,很多时候,我们面临一个非常大的挑战,当你需要更多数据时,可以在生成阶段把更多内容吸纳进来,然后再紧跟一个非常精细的验证,来表示它的准确率。
第九,有众包 VS 无众包
一定是选择有众包。知识图谱一定要做最后的验证,而验证一定要众包化。
三、自动化知识图谱构建技术与落地是可行的
最后,总结一些主要结果:
第一,大规模自动化知识获取现在基本可行,在通用领域F-score已接近0.9;
第二,知识图谱探索式交互系统现在做的越来越炫,基本上从空间、时间和语义三个维度做交互都没有任何问题,还有落地案例越来越多。
所以我们说基于自动化知识图谱构建的技术,实现知识图谱的一些落地,现在应该说是基本可行的。
(*本文为 AI科技大本营整理文章,转载请微信联系作者 1092722531)

相关文章:

Docker mongo副本集环境搭建
1、MongoDB Docker 镜像安装 docker pull mongo 2、Docker容器创建 MongoDB Docker 容器创建有以下几个问题: 1- MongoDB 容器基本创建方法和数据目录挂载 2- MongoDB 容器的数据迁移 3- MongoDB 设置登录权限问题docker run -p 27017:27017 -v <LocalDirectoryP…
菜鸟学习HTML5+CSS3(一)
主要内容: 1.新的文档类型声明(DTD) 2.新增的HTML5标签 3.删除的HTML标签 4.重新定义的HTML标签 一、新的文档类型声明(DTD) HTML 5的DTD声明为:<!doctype html>、<!DOCTYPE html>、<!DOCTY…
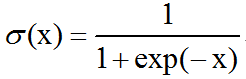
激活函数之logistic sigmoid函数介绍及C++实现
logistic sigmoid函数:logistic sigmoid函数通常用来产生Bernoulli分布中的参数,因为它的范围是(0,1),处在的有效取值范围内。logisitic sigmoid函数在变量取绝对值非常大的正值或负值时会出现饱和(saturate)现象,意味着函数会变得…

NLP重要模型详解,换个方式学(内附资源)
(图片有AI科技大本营付费下载自视觉中国)作者 | Jaime Zornoza,马德里技术大学译者 | 陈之炎校对 | 王威力编辑 | 黄继彦来源 | 数据派THU(ID:DatapiTHU)【导语】本文带你以前所未有的方式了解深度学习神经…
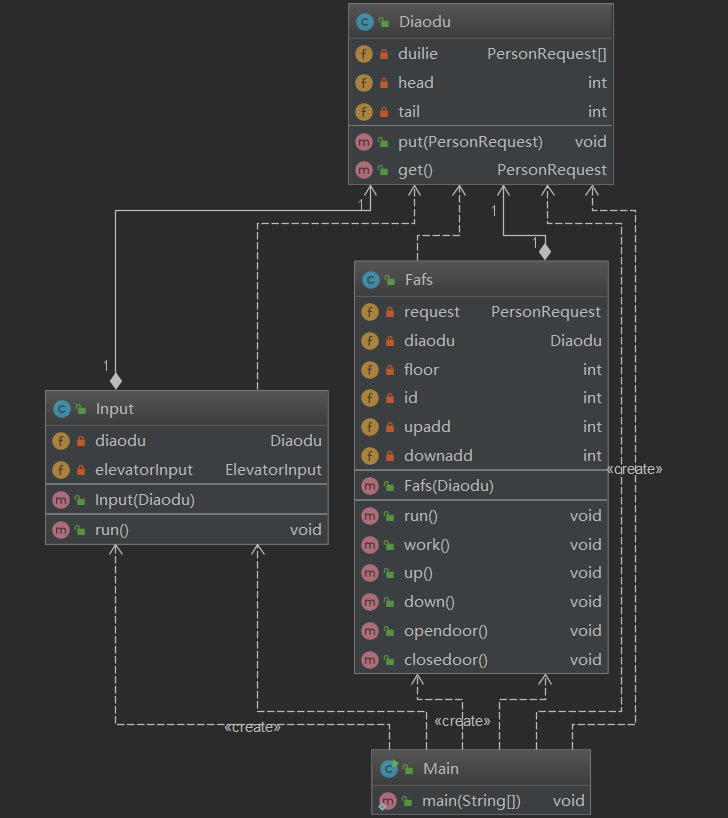
大闸蟹的OO第二单元总结
OO的第二单元是讲多线程的协作与控制,三次作业分别为FAFS电梯,ALS电梯和三部需要协作的电梯。三次作业由浅入深,让我们逐渐理解多线程的工作原理和运行状况。 第一次作业: 第一次作业是傻瓜电梯,也就是完全不需要考虑捎…

构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(31)-MVC使用RDL报表
原文:构建ASP.NET MVC4EF5EasyUIUnity2.x注入的后台管理系统(31)-MVC使用RDL报表这次我们来演示MVC3怎么显示RDL报表,坑爹的微软把MVC升级到5都木有良好的支持报表,让MVC在某些领域趋于短板 我们只能通过一些方式来使用rdl报表。 Razor视图不支持asp.net…

18段代码带你玩转18个机器学习必备交互工具
(图片有AI科技大本营付费下载自视觉中国)作者 | 曼纽尔阿米纳特吉(Manuel Amunategui)、迈赫迪洛佩伊(Mehdi Roopaei)来源 | 大数据(ID:hzdashuju)【导读】本文简要介绍将…
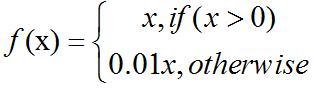
激活函数之ReLU/softplus介绍及C++实现
softplus函数(softplus function):ζ(x)ln(1exp(x)).softplus函数可以用来产生正态分布的β和σ参数,因为它的范围是(0,∞)。当处理包含sigmoid函数的表达式时它也经常出现。softplus函数名字来源于它是另外一个函数的平滑(或”软化”)形式,这…
windows server 2012 用sysdba登录报错 ORA-01031
报错显示:C:\Users\Administrator>sqlplus / as sysdba SQL*Plus: Release 11.2.0.1.0 Production on 星期三 4月 24 09:09:33 2019 Copyright (c) 1982, 2010, Oracle. All rights reserved. ERROR:ORA-01031: 权限不足 请输入用户名: 1、查看本地用户和组确认权…

[SignalR]初步认识以及安装
原文:[SignalR]初步认识以及安装1.什么是ASP.NET SignalR? ASP .NET SignalR是一个 ASP .NET 下的类库,可以在ASP .NET 的Web项目中实现实时通信。什么是实时通信的Web呢?就是让客户端(Web页面)和服务器端可以互相通知…
CUDA Samples:Vector Add
以下CUDA sample是分别用C和CUDA实现的两向量相加操作,参考CUDA 8.0中的sample:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\0_Simple,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CU…

你和人工智能的对话,正在被人工收听
(图片有AI科技大本营付费下载自视觉中国)作者 | 周晶晶编辑 | 阿伦来源 | 燃财经(ID:rancaijing)如今,智能设备越来越多地出现在每个人的生活中,在享受它们带来的便利时,很多人或许没有意识到&a…

python数据结构与算法总结
python常用的数据结构与算法就分享到此处,本月涉及数据结构与算法的内容有如下文章: 《数据结构和算法对python意味着什么?》 《顺序表数据结构在python中的应用》 《python实现单向链表数据结构及其基本方法》 《python实现单向循环链表数据…

自定义classloader中的接口调用
2019独角兽企业重金招聘Python工程师标准>>> 注意其中转型异常的描述,左边声明和强转括号内都是appclassloader加载的,而让自定义加载类的接口也由appclassloader加载,所以转型成功 转载于:https://my.oschina.net/heatonn1/blog/…

学点基本功:机器学习常用损失函数小结
(图片付费下载自视觉中国)作者 | 王桂波转载自知乎用户王桂波【导读】机器学习中的监督学习本质上是给定一系列训练样本 ,尝试学习 的映射关系,使得给定一个 ,即便这个不在训练样本中,也能够得到尽量接近…
python生成简单的FTP弱口令扫描
2019独角兽企业重金招聘Python工程师标准>>> 前言 Ftp这个类实现了Ftp客户端的大多数功能,比如连接Ftp服务器、查看服务器中的文件、上传、下载文件等功能,Ftp匿名扫描器的实现,需要使用FTP这个类,首先用主机名构造了一个Ftp对象(即ftp),然后用这个ftp调…
C++中const指针用法汇总
这里以int类型为例,进行说明,在C中const是类型修饰符:int a; 定义一个普通的int类型变量a,可对此变量的值进行修改。const int a 3;与 int const a 3; 这两条语句都是有效的code,并且是等价的,说明a是一个…
mongodb基础应用
一些概念 一个mongod服务可以有建立多个数据库,每个数据库可以有多张表,这里的表名叫collection,每个collection可以存放多个文档(document),每个文档都以BSON(binary json)的形式存…
【leetcode】1030. Matrix Cells in Distance Order
题目如下: We are given a matrix with R rows and C columns has cells with integer coordinates (r, c), where 0 < r < R and 0 < c < C. Additionally, we are given a cell in that matrix with coordinates (r0, c0). Return the coordinates of…
深度学习面临天花板,亟需更可信、可靠、安全的第三代AI技术|AI ProCon 2019
整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 在人工智能领域中,深度学习掀起了最近一次浪潮,但在实践和应用中也面临着诸多挑战,特别是关系到人的生命,如医疗、自动驾驶等领域场景时,黑盒…

java robot类自动截屏
直接上代码:package robot;import java.awt.Rectangle;import java.awt.Robot;import java.awt.event.InputEvent;import java.awt.p_w_picpath.BufferedImage;import java.io.File;import java.io.IOException;import javax.p_w_picpathio.ImageIO;import com.sun.glass.event…
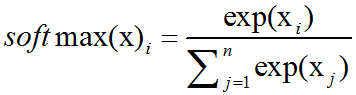
激活函数之softmax介绍及C++实现
下溢(underflow):当接近零的数被四舍五入为零时发生下溢。许多函数在其参数为零而不是一个很小的正数时才会表现出质的不同。例如,我们通常要避免被零除或避免取零的对数。上溢(overflow):当大量级的数被近似为∞或-∞时发生上溢。进一步的运…
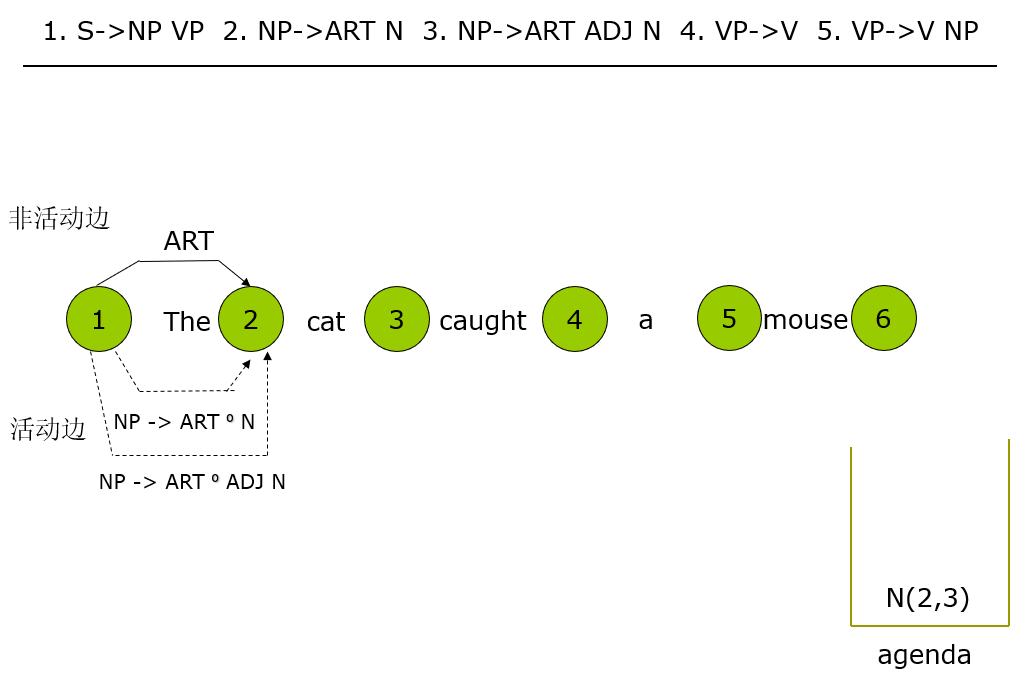
parsing:NLP之chart parser句法分析器
已迁移到我新博客,阅读体验更佳parsing:NLP之chart parser句法分析器 完整代码实现放在我的github上:click me 一、任务要求 实现一个基于简单英语语法的chart句法分析器。二、技术路线 采用自底向上的句法分析方法,简单的自底向上句法分析效率不高,常常…

图解Python算法
普通程序员,不学算法,也可以成为大神吗?对不起,这个,绝对不可以。可是算法好难啊~~看两页书就想睡觉……所以就不学了吗?就一直当普通程序员吗?如果有一本算法书,看着很轻松……又有…
详解SSH框架的原理和优点
Struts的原理和优点. Struts工作原理 MVC即Model-View-Controller的缩写,是一种常用的设计模式。MVC 减弱了业务逻辑接口和数据接口之间的耦合,以及让视图层更富于变化。MVC的工作原理,如下图1所示:Struts 是MVC的一种实现࿰…

Numpy and Matplotlib
Numpy介绍 编辑 一个用python实现的科学计算,包括:1、一个强大的N维数组对象Array;2、比较成熟的(广播)函数库;3、用于整合C/C和Fortran代码的工具包;4、实用的线性代数、傅里叶变换和随机数生成…
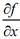
梯度下降法简介
条件数表征函数相对于输入的微小变化而变化的快慢程度。输入被轻微扰动而迅速改变的函数对于科学计算来说可能是有问题的,因为输入中的舍入误差可能导致输出的巨大变化。大多数深度学习算法都涉及某种形式的优化。优化指的是改变x以最小化或最大化某个函数f(x)的任务…

微软亚研院CV大佬代季峰跳槽商汤为哪般?
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)近日,知乎上一篇离开关于MSRA(微软亚洲研究院)和MSRA CV未来发展的帖子讨论热度颇高,这个帖子以MSRA CV执行研究主任代季峰离职加入商汤为引子,引…
iOS Block实现探究
2019独角兽企业重金招聘Python工程师标准>>> 使用clang的rewrite-objc filename 可以将有block的c代码转换成cpp代码。从中可以看到block的实现。 #include <stdio.h> int main() {void (^blk)(void) ^{printf("Block\n");};blk();return 0; } 使…
CUDA Samples: Long Vector Add
以下CUDA sample是分别用C和CUDA实现的两个非常大的向量相加操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CUDA_TEST_COMMON_HPP_ #define FBC_CUDA_TEST_COMMON_HPP_#include<random>template&l…