100多次竞赛后,他研发了一个几乎可以解决所有机器学习问题的框架

(图片由AI科技大本营付费下载自视觉中国)
作者 | XI YANG
来源 | 知乎(机器学习之路)
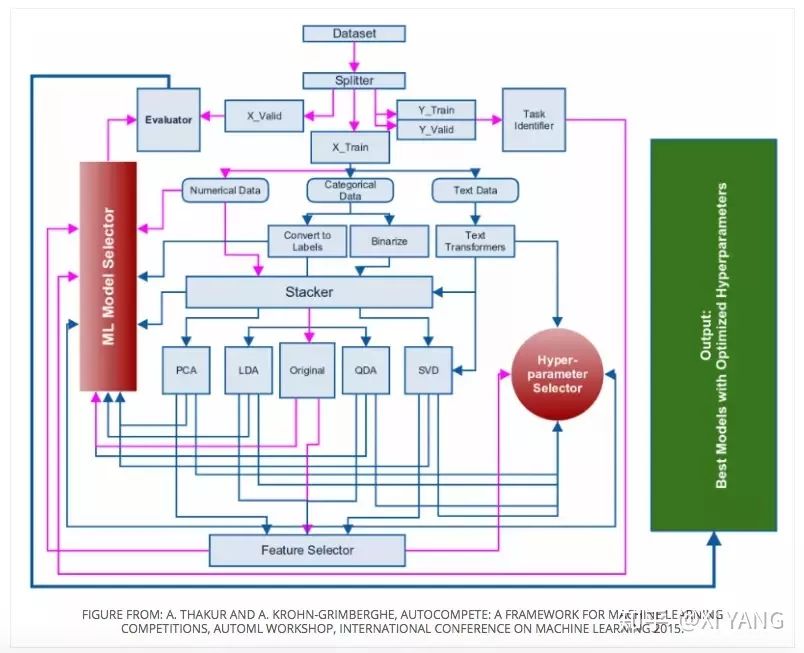
Kaggle是一个数据科学竞赛的平台,很多公司会发布一些接近真实业务的问题,吸引爱好数据科学的人来一起解决,可以通过这些数据积累经验,提高机器学习的水平。
- 第一步:识别问题
- 第二步:分离数据
- 第三步:构造提取特征
- 第四步:组合数据
- 第五步:分解
- 第六步:选择特征
- 第七步:选择算法进行训练
最方便的就是安装 Anaconda,这里面包含大部分数据科学所需要的包,直接引入就可以了,常用的包有:
- pandas:常用来将数据转化成 dataframe 形式进行操作
- scikit-learn:里面有要用到的机器学习算法模型
- matplotlib:用来画图
- 以及 xgboost,keras,tqdm 等。
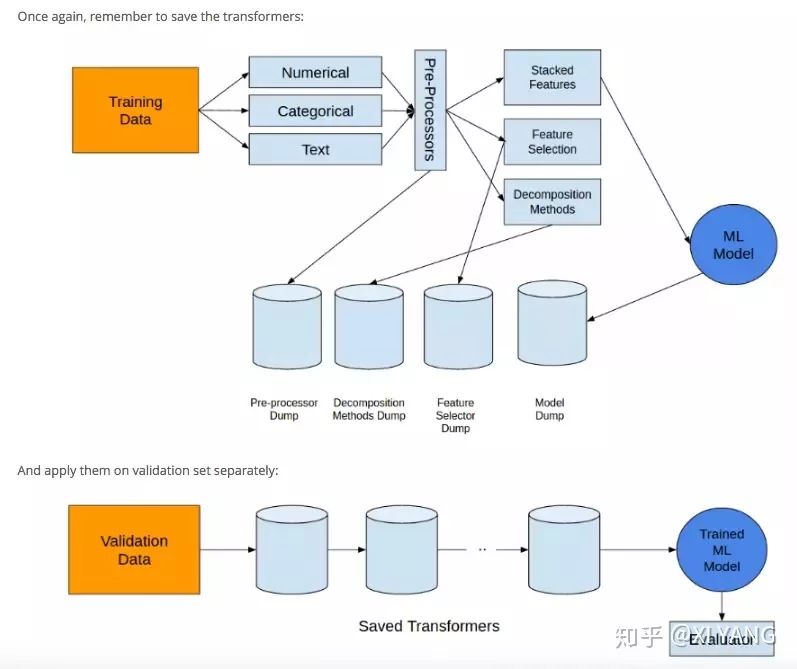
第一步:识别问题
第二步:分离数据
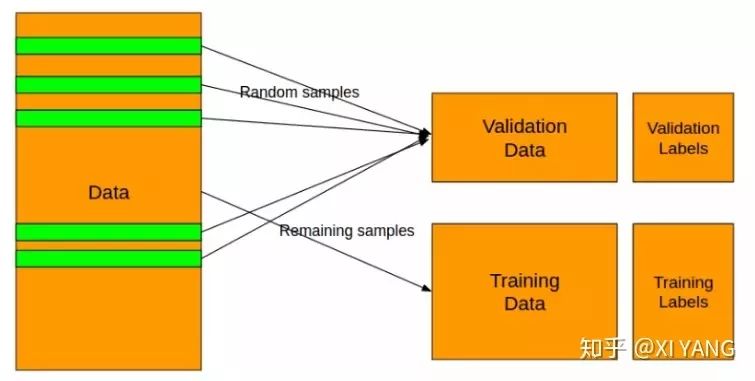
用 Training Data 来训练模型,用 Validation Data 来检验这个模型的表现,不然的话,通过各种调节参数,模型可以在训练数据集上面表现的非常出色,但是这可能会是过拟合,过拟合就是太依赖现有的数据了,拟合的效果特别好,但是只适用于训练集,以致于来一个新的数据,就不知道该预测成什么了。所以需要有 Validation 来验证一下,看这个模型是在那里自娱自乐呢,还是真的表现出色。
分类问题用 StrtifiedKFold
from sklearn.cross_validation import StratifiedKFold回归问题用 KFold
from sklearn.cross_validation import KFold第三步:构造特征
record 1: 性别 女record 2:性别 女record 3:性别 男
男record 1: 1 0record 2:1 0record 3:0 1
from sklearn.preprocessing import LabelEncoder或者
from sklearn.preprocessing import OneHotEncoder第四步:组合数据
import numpy as npX = np.hstack((x1, x2, ...))
from scipy import sparseX = sparse.hstack((x1, x2, ...))
- RandomForestClassifier
- RandomForestRegressor
- ExtraTreesClassifier
- ExtraTreesRegressor
- XGBClassifier
- XGBRegressor
第五步:分解
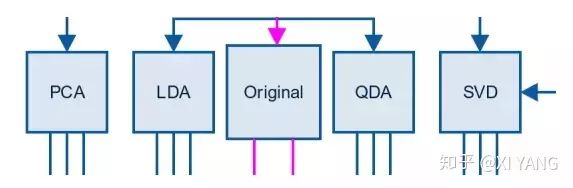
from sklearn.decomposition import PCA对于文字数据,在转化成稀疏矩阵之后,可以用 SVD
from sklearn.decomposition import TruncatedSVD第六步:选择特征
from sklearn.ensemble import RandomForestClassifier或者 xgboost:
import xgboost as xgb对于稀疏的数据,一个比较有名的方法是 chi-2:
from sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2
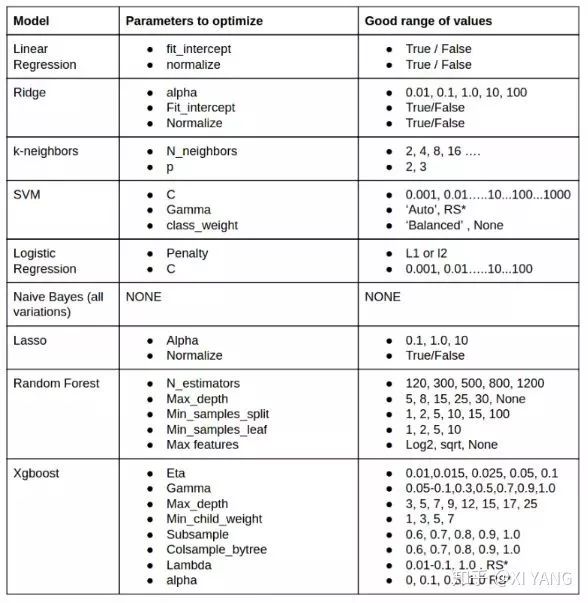
第七步:选择算法进行训练
Random Forest
GBM
Logistic Regression
Naive Bayes
Support Vector Machines
k-Nearest Neighbors
Regression
Random Forest
GBM
Linear Regression
Ridge
Lasso
SVR
为什么那么多算法里,只提出这几个算法呢,这就需要对比不同算法的性能了。
这篇神文 Do we Need Hundreds of Classifiers to Solve Real World Classification Problems 测试了179种分类模型在UCI所有的121个数据上的性能,发现Random Forests 和 SVM 性能最好。
我们可以学习一下里面的调研思路,看看是怎么样得到比较结果的,在我们的实践中也有一定的指导作用。

原文链接:
https://zhuanlan.zhihu.com/p/61657532
◆
精彩推荐
◆

推荐阅读
王霸之路:从0.1到2.0,一文看尽TensorFlow“奋斗史”
伯克利人工智能研究院开源深度学习数据压缩方法Bit-Swap,性能创新高
NLP被英语统治?打破成见,英语不应是「自然语言」同义词
TensorFlow2.0正式版发布,极简安装TF2.0(CPU&GPU)教程
肖仰华:知识图谱构建的三要素、三原则和九大策略 | AI ProCon 2019
微软语音AI技术与微软听听文档小程序实践 | AI ProCon 2019
AI落地遭“卡脖子”困境:为什么说联邦学习是解决良方?
10分钟搭建你的第一个图像识别模型 | 附完整代码
限时早鸟票 | 2019 中国大数据技术大会(BDTC)超豪华盛宴抢先看!

你点的每个“在看”,我都认真当成了喜欢
相关文章:

mysql中char与varchar的区别分析(补充一句,int和integer没区别)
转自:http://www.jb51.net/article/23575.htm 在mysql教程中char与varchar的区别呢,都是用来存储字符串的,只是他们的保存方式不一样罢了,char有固定的长度,而varchar属于可变长的字符类型。har与varchar的区别 &#…

CUDA Samples: Streams' usage
以下CUDA sample是分别用C和CUDA实现的流的使用code,并对其中使用到的CUDA函数进行了解说,code参考了《GPU高性能编程CUDA实战》一书的第十章,各个文件内容如下:funset.cpp:#include "funset.hpp" #include <random&…

你的神经网络不起作用的37个理由
(图片由AI科技大本营付费下载自视觉中国)作者 | Slav Ivanov译者 | 吴金笛校对 | 丁楠雅、林亦霖编辑 | 王菁来源 | 数据派THU(ID:DatapiTHU)【导语】本文列举了在搭建神经网络过程中的37个易错点,并给出了…
菜鸟Vue学习笔记(三)
菜鸟Vue学习笔记(三)本周使用了Vue来操作表单,接下来说下Vue中双向绑定表单元素的用法。Vue中双向绑定是使用的v-model,所谓的双向绑定即改变变量的值,表单元素的值也会改变,同样的,改变表单元素…
Python中的注释(转)
一、单行注释单行注释以#开头,例如:print 6 #输出6二、多行注释(Python的注释只有针对于单行的注释(用#),这是一种变通的方法)多行注释用三引号将注释括起来,例如:多行注释多行注释三…

CUDA Samples: dot product(使用零拷贝内存)
以下CUDA sample是分别用C和CUDA实现的点积运算code,CUDA包括普通实现和采用零拷贝内存实现两种,并对其中使用到的CUDA函数进行了解说,code参考了《GPU高性能编程CUDA实战》一书的第十一章,各个文件内容如下:funset.cp…

一文读懂线性回归、岭回归和Lasso回归
(图片由AI科技大本营付费下载自视觉中国)作者 | 文杰编辑 | yuquanle本文介绍线性回归模型,从梯度下降和最小二乘的角度来求解线性回归问题,以概率的方式解释了线性回归为什么采用平方损失,然后介绍了线性回归中常用的…
tf.matmul / tf.multiply
import tensorflow as tfimport numpy as np 1.tf.placeholder placeholder()函数是在神经网络构建graph的时候在模型中的占位,此时并没有把要输入的数据传入模型,它只会分配必要的内存。 等建立session,在会话中,运行模型的时候通…

Java 匿名类也能使用构造函数
为什么80%的码农都做不了架构师?>>> 匿名类虽然没有名字,但可以有一个初始化块来充当构造函数。 public enum Ops {ADD, SUB} public class Calculator { private int i, j, result; public Calculator() {} public Calculator(int _i, …

CUDA Samples: matrix multiplication(C = A * B)
以下CUDA sample是分别用C和CUDA实现的两矩阵相乘运算code即C A*B,CUDA中包含了两种核函数的实现方法,第一种方法来自于CUDA Samples\v8.0\0_Simple\matrixMul,第二种采用普通的方法实现,第一种方法较快,但有些复杂&am…

业界首个实时多目标跟踪系统开源
(图片由AI科技大本营付费下载自视觉中国)作者 | CV君来源 | 我爱计算机视觉(ID:aicvml)相对业界研究比较多的单目标跟踪,多目标跟踪(Multi-Object Tracking,MOT)系统在实…
python基础 练习题
【练习题1】实现一个整数加法计算器如 content input(">>> ") # 59 , 64 count0 while 1:contentinput(>>>)s1 content.split()print(s1)count 0for i in s1:count int(i)print(count) 【练习题2】请编写1 - 100 所有数的和 sum0 for i in r…
[再寄小读者之数学篇](2014-04-18 from 352558840@qq.com [南开大学 2014 年高等代数考研试题]二次型的零点)...
(2014-04-18 from 352558840qq.com [南开大学 2014 年高等代数考研试题]) 设 ${\bf A}$ 为实对称矩阵, 存在线性无关的向量 ${\bf x}_1,{\bf x}_2$, 使得 ${\bf x}_1^T{\bf A}{\bf x}_1>0$, ${\bf x}_2^T{\bf A}{\bf x}_2<0$. 证明: 存在线性无关的向量 ${\bf x}_3,{\bf …

从0到1详解推荐系统中的嵌入方法,原理、算法到应用都讲明白了
(图片由AI科技大本营付费下载自视觉中国)作者丨gongyouliu编辑丨lily来源 | 大数据与人工智能(ID:)前言作者曾在这篇文章中提到,矩阵分解算法是一类嵌入方法,通过将用户行为矩阵分解为用户特征矩…
iOS-Swift中的递增(++)和递减(--)被取消的原因-官方答复
众所周知,在很多编程语言中,对一个变量递增1用,递减1用--,在Swift3之前也是可以这么用的,但之后被取消了。 所以在目前Swift5的版本中,只能用1和-1来进行递增和递减了 如果坚持用或--将会提示以下错误&…
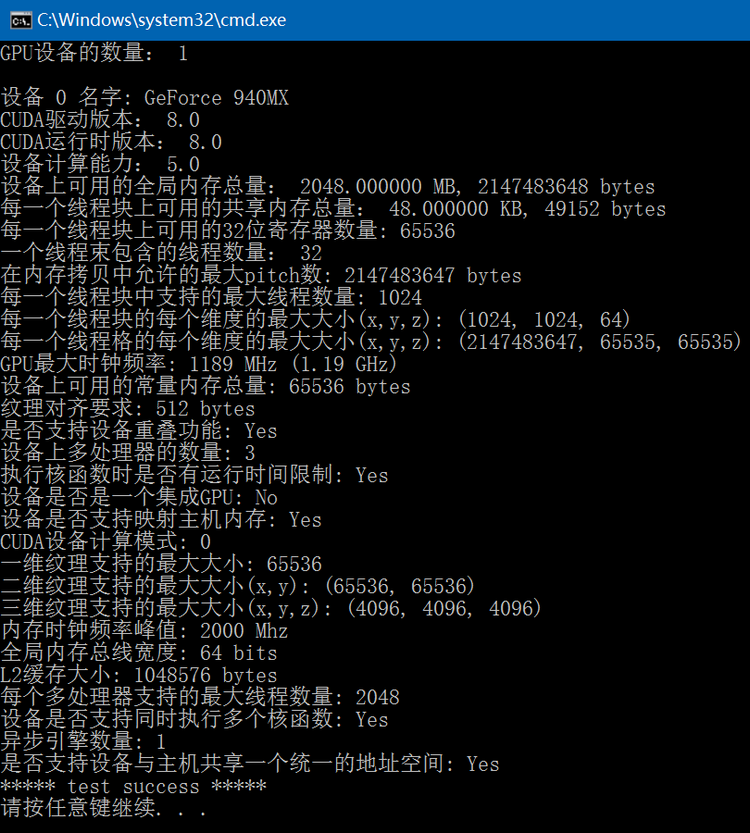
CUDA Samples: 获取设备属性信息
通过调用CUDA的cudaGetDeviceProperties函数可以获得指定设备的相关信息,此函数会根据GPU显卡和CUDA版本的不同得到的结果也有所差异,下面code列出了经常用到的设备信息:#include "funset.hpp" #include <iostream> #include…
apache代理模块proxy使用
1、安装proxy模块[rootlocalhost modules]# cd /usr/local/src/httpd-2.2.16 [rootlocalhost httpd-2.2.16]# cd modules [rootlocalhost modules]# ls aaa config5.m4 debug filters ldap Makefile.in NWGNUmakefile ssl arch database echo …

CUDA Samples: image normalize(mean/standard deviation)
以下CUDA sample是分别用C和CUDA实现的通过均值和标准差对图像进行类似归一化的操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:关于均值和标准差的计算公式可参考: http://blog.csdn.net/fengbingchun/article/detai…

中文预训练ALBERT模型来了:小模型登顶GLUE,Base版模型小10倍、速度快1倍
(图片由AI科技大本营付费下载自视觉中国)作者 | 徐亮(实在智能算法专家) 来源 | AINLP(ID:nlpjob)谷歌ALBERT论文刚刚出炉一周,中文预训练ALBERT模型来了,感兴趣的同学可以直接尝鲜试…
树莓派安装go
简介 大学的时候在使用openfalcon的时候讲过这个东西,但是那时候是介绍open-falcon的,所以感觉不是很具体,所以今天在安装frp的时候也碰到了这个问题,我就具体的说下 安装go1.4 编译最新版本的go的时候一定要先编译安装go1.4&…
设计模式中的原则
设计模式(详情click)这个术语是由Erich Gamma等人在1990年代从建筑设计领域引入到计算机科学的。它是对软件设计中普遍存在(反复出现)的各种问题,所提出的解决方案。 设计模式并不直接用来完成代码的编写,而是描述在各种不同情况下…

CUDA Samples: approximate image reverse
以下CUDA sample是分别用C和CUDA实现的对图像进行某种类似reverse的操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CUDA_TEST_COMMON_HPP_ #define FBC_CUDA_TEST_COMMON_HPP_#include<random> #i…

超详细支持向量机知识点,面试官会问的都在这里了
(图片付费下载自视觉中国)作者 | 韦伟来源 | 知乎导语:持续准备面试中,准备的过程中,慢慢发现,如果死记硬背的话很难,可当推导一遍并且细细研究里面的缘由的话,面试起来应该什么都不…
vue-router点击切换路由报错
报错: 报错原因: 设置mode:history解决方法: 将router的mode设置为‘hash就不报错了 原因下次再分析?
gvim配置相关
用 vundle 来管理 vim 插件(包含配置文件vimrc和gvimrc) gvim插件管理神器:vundle的安装与使用 Vim插件管理Vundle Linux 下VIM的配置 Vim配置系列(一) ---- 插件管理 Vim配置系列(二) —- 好看的statusline vim优秀插件整理 一些有用的 VIM …

深度学习有哪些接地气又好玩的应用?
过去几年中,深度学习中的很多技术如计算机视觉、自然语言处理等被应用在很多实际问题中,而且相关成果也表明深度学习能让人们的工作效果比以前更好。我们收集了一些深度学习方面的创意应用,虽然没有对每项应用进行详尽描述,但是希…
Ubuntu下通过CMake文件编译CUDA+OpenCV代码操作步骤
在 CUDA_Test 工程中,CUDA测试代码之前仅支持在Windows10 VS2013编译,今天在Ubuntu 14.04下写了一个CMakeLists.txt文件,支持在Linux下也可以通过CMake编译CUDA_Test工程,CMakeLists.txt文件内容如下:# CMake file f…
JAVA 多用户商城系统b2b2c-Spring Cloud常见问题与总结(一)
在使用Spring Cloud的过程中,难免会遇到一些问题。所以对Spring Cloud的常用问题做一些总结。需要JAVA Spring Cloud大型企业分布式微服务云构建的B2B2C电子商务平台源码 一零三八七七四六二六 一、Eureka常见问题 1.1 Eureka 注册服务慢 默认情况下,服务…
TinyFrame升级之八:实现简易插件化开发
本章主要讲解如何为框架新增插件化开发功能。 在.net 4.0中,我们可以在Application开始之前,通过PreApplicationStartMethod方法加载所需要的任何东西。那么今天我们主要做的工作就集中在这个时间段: 1.将插件DLL及文件拷贝入主网站目录并编译…
快手王华彦:端上视觉技术的极致效率及其短视频应用实践 | AI ProCon 2019
演讲嘉宾 | 王华彦(快手硅谷Y-tech实验室负责人) 编辑 | Just 出品 | AI科技大本营(ID:rgznai100) 快手用户日均上传1500万个视频,要把这些作品准确的分发给超2亿活跃用户,如果没有强大的AI技术系统去理解…