CUDA Samples: image normalize(mean/standard deviation)
以下CUDA sample是分别用C++和CUDA实现的通过均值和标准差对图像进行类似归一化的操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:
关于均值和标准差的计算公式可参考: http://blog.csdn.net/fengbingchun/article/details/73323475
funset.cpp:
#include "funset.hpp"
#include <random>
#include <iostream>
#include <vector>
#include <memory>
#include <string>
#include <algorithm>
#include "common.hpp"
#include <opencv2/opencv.hpp>int test_image_normalize()
{std::string image_name{ "E:/GitCode/CUDA_Test/test_images/lena.png" };cv::Mat matSrc = cv::imread(image_name);if (!matSrc.data) {fprintf(stderr, "read image fail: %s\n", image_name.c_str());return -1;}const int width{ 511 }, height{ 473 }, channels{ 3 };cv::resize(matSrc, matSrc, cv::Size(width, height));matSrc.convertTo(matSrc, CV_32FC3);std::vector<cv::Mat> matSplit;cv::split(matSrc, matSplit);CHECK(matSplit.size() == channels);std::unique_ptr<float[]> data(new float[matSplit[0].cols * matSplit[0].rows * channels]);size_t length{ matSplit[0].cols * matSplit[0].rows * sizeof(float) };for (int i = 0; i < channels; ++i) {memcpy(data.get() + matSplit[0].cols * matSplit[0].rows * i, matSplit[i].data, length);}float elapsed_time1{ 0.f }, elapsed_time2{ 0.f }; // millisecondsstd::unique_ptr<float[]> dst1(new float[matSplit[0].cols * matSplit[0].rows * channels]);std::unique_ptr<float[]> dst2(new float[matSplit[0].cols * matSplit[0].rows * channels]);int ret = image_normalize_cpu(data.get(), dst1.get(), width, height, channels, &elapsed_time1);if (ret != 0) PRINT_ERROR_INFO(image_normalize_cpu);ret = image_normalize_gpu(data.get(), dst2.get(), width, height, channels, &elapsed_time2);if (ret != 0) PRINT_ERROR_INFO(image_normalize_gpu);int count{ 0 }, num{ width * height * channels };for (int i = 0; i < num; ++i) {if (fabs(dst1[i] - dst2[i]) > 0.01/*EPS_*/) {fprintf(stderr, "index: %d, val1: %f, val2: %f\n", i, dst1[i], dst2[i]);++count;}if (count > 100) return -1;}std::vector<cv::Mat> merge(channels);for (int i = 0; i < channels; ++i) {merge[i] = cv::Mat(height, width, CV_32FC1, dst2.get() + i * width * height);}cv::Mat dst3;cv::merge(merge, dst3);dst3.convertTo(dst3, CV_8UC3, 255.f);cv::imwrite("E:/GitCode/CUDA_Test/test_images/image_normalize.png", dst3);//cv::resize(matSrc, matSrc, cv::Size(width, height));//cv::imwrite("E:/GitCode/CUDA_Test/test_images/image_src.png", matSrc);fprintf(stderr, "test image normalize: cpu run time: %f ms, gpu run time: %f ms\n", elapsed_time1, elapsed_time2);return 0;
}#include "funset.hpp"
#include <vector>
#include <chrono>
#include "common.hpp"int image_normalize_cpu(const float* src, float* dst, int width, int height, int channels, float* elapsed_time)
{auto start = std::chrono::steady_clock::now();const int offset{ width * height };for (int i = 0; i < channels; ++i) {const float* p1 = src + offset * i;float* p2 = dst + offset * i;float mean{ 0.f }, sd{ 0.f };for (int t = 0; t < offset; ++t) {mean += p1[t];sd += pow(p1[t], 2.f);p2[t] = p1[t];}mean /= offset;sd /= offset;sd -= pow(mean, 2.f);sd = sqrt(sd);if (sd < EPS_) sd = 1.f;for (int t = 0; t < offset; ++t) {p2[t] = (p1[t] - mean) / sd;}}auto end = std::chrono::steady_clock::now();auto duration = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start);*elapsed_time = duration.count() * 1.0e-6;return 0;
}#include "funset.hpp"
#include <iostream>
#include <memory>
#include <algorithm>
#include <cmath>
#include <cuda_runtime.h> // For the CUDA runtime routines (prefixed with "cuda_")
#include <device_launch_parameters.h>
#include "common.hpp"/* __global__: 函数类型限定符;在设备上运行;在主机端调用,计算能力3.2及以上可以在
设备端调用;声明的函数的返回值必须是void类型;对此类型函数的调用是异步的,即在
设备完全完成它的运行之前就返回了;对此类型函数的调用必须指定执行配置,即用于在
设备上执行函数时的grid和block的维度,以及相关的流(即插入<<< >>>运算符);
a kernel,表示此函数为内核函数(运行在GPU上的CUDA并行计算函数称为kernel(内核函
数),内核函数必须通过__global__函数类型限定符定义);*/
__global__ static void image_normalize(const float* src, float* dst, int count, int offset)
{/* gridDim: 内置变量,用于描述线程网格的维度,对于所有线程块来说,这个变量是一个常数,用来保存线程格每一维的大小,即每个线程格中线程块的数量.一个grid最多只有二维,为dim3类型;blockDim: 内置变量,用于说明每个block的维度与尺寸.为dim3类型,包含了block在三个维度上的尺寸信息;对于所有线程块来说,这个变量是一个常数,保存的是线程块中每一维的线程数量;blockIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程块的索引;用于说明当前thread所在的block在整个grid中的位置,blockIdx.x取值范围是[0,gridDim.x-1],blockIdx.y取值范围是[0, gridDim.y-1].为uint3类型,包含了一个block在grid中各个维度上的索引信息;threadIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程索引;用于说明当前thread在block中的位置;如果线程是一维的可获取threadIdx.x,如果是二维的还可获取threadIdx.y,如果是三维的还可获取threadIdx.z;为uint3类型,包含了一个thread在block中各个维度的索引信息 */int index = threadIdx.x + blockIdx.x * blockDim.x;if (index > count - 1) return;const float* input = src + index * offset;float* output = dst + index * offset;float mean{ 0.f }, sd{ 0.f };for (size_t i = 0; i < offset; ++i) {mean += input[i];sd += pow(input[i], 2.f);output[i] = input[i];}mean /= offset;sd /= offset;sd -= pow(mean, 2.f);sd = sqrt(sd);if (sd < EPS_) sd = 1.f;for (size_t i = 0; i < offset; ++i) {output[i] = (input[i] - mean) / sd;}
}int image_normalize_gpu(const float* src, float* dst, int width, int height, int channels, float* elapsed_time)
{/* cudaEvent_t: CUDA event types,结构体类型, CUDA事件,用于测量GPU在某个任务上花费的时间,CUDA中的事件本质上是一个GPU时间戳,由于CUDA事件是在GPU上实现的,因此它们不适于对同时包含设备代码和主机代码的混合代码计时 */cudaEvent_t start, stop;// cudaEventCreate: 创建一个事件对象,异步启动cudaEventCreate(&start);cudaEventCreate(&stop);// cudaEventRecord: 记录一个事件,异步启动,start记录起始时间cudaEventRecord(start, 0);float *dev_src{ nullptr }, *dev_dst{ nullptr };size_t length{ width * height * channels * sizeof(float) };// cudaMalloc: 在设备端分配内存cudaMalloc(&dev_src, length);cudaMalloc(&dev_dst, length);/* cudaMemcpy: 在主机端和设备端拷贝数据,此函数第四个参数仅能是下面之一:(1). cudaMemcpyHostToHost: 拷贝数据从主机端到主机端(2). cudaMemcpyHostToDevice: 拷贝数据从主机端到设备端(3). cudaMemcpyDeviceToHost: 拷贝数据从设备端到主机端(4). cudaMemcpyDeviceToDevice: 拷贝数据从设备端到设备端(5). cudaMemcpyDefault: 从指针值自动推断拷贝数据方向,需要支持统一虚拟寻址(CUDA6.0及以上版本)cudaMemcpy函数对于主机是同步的 */cudaMemcpy(dev_src, src, length, cudaMemcpyHostToDevice);/* <<< >>>: 为CUDA引入的运算符,指定线程网格和线程块维度等,传递执行参数给CUDA编译器和运行时系统,用于说明内核函数中的线程数量,以及线程是如何组织的;尖括号中这些参数并不是传递给设备代码的参数,而是告诉运行时如何启动设备代码,传递给设备代码本身的参数是放在圆括号中传递的,就像标准的函数调用一样;不同计算能力的设备对线程的总数和组织方式有不同的约束;必须先为kernel中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误,例如越界等;使用运行时API时,需要在调用的内核函数名与参数列表直接以<<<Dg,Db,Ns,S>>>的形式设置执行配置,其中:Dg是一个dim3型变量,用于设置grid的维度和各个维度上的尺寸.设置好Dg后,grid中将有Dg.x*Dg.y个block,Dg.z必须为1;Db是一个dim3型变量,用于设置block的维度和各个维度上的尺寸.设置好Db后,每个block中将有Db.x*Db.y*Db.z个thread;Ns是一个size_t型变量,指定各块为此调用动态分配的共享存储器大小,这些动态分配的存储器可供声明为外部数组(extern __shared__)的其他任何变量使用;Ns是一个可选参数,默认值为0;S为cudaStream_t类型,用于设置与内核函数关联的流.S是一个可选参数,默认值0. */image_normalize << < channels, 512 >> >(dev_src, dev_dst, channels, width*height);cudaMemcpy(dst, dev_dst, length, cudaMemcpyDeviceToHost);// cudaFree: 释放设备上由cudaMalloc函数分配的内存cudaFree(dev_src);cudaFree(dev_dst);// cudaEventRecord: 记录一个事件,异步启动,stop记录结束时间cudaEventRecord(stop, 0);// cudaEventSynchronize: 事件同步,等待一个事件完成,异步启动cudaEventSynchronize(stop);// cudaEventElapseTime: 计算两个事件之间经历的时间,单位为毫秒,异步启动cudaEventElapsedTime(elapsed_time, start, stop);// cudaEventDestroy: 销毁事件对象,异步启动cudaEventDestroy(start);cudaEventDestroy(stop);return 0;
}


GitHub: https://github.com/fengbingchun/CUDA_Test
相关文章:

中文预训练ALBERT模型来了:小模型登顶GLUE,Base版模型小10倍、速度快1倍
(图片由AI科技大本营付费下载自视觉中国)作者 | 徐亮(实在智能算法专家) 来源 | AINLP(ID:nlpjob)谷歌ALBERT论文刚刚出炉一周,中文预训练ALBERT模型来了,感兴趣的同学可以直接尝鲜试…

树莓派安装go
简介 大学的时候在使用openfalcon的时候讲过这个东西,但是那时候是介绍open-falcon的,所以感觉不是很具体,所以今天在安装frp的时候也碰到了这个问题,我就具体的说下 安装go1.4 编译最新版本的go的时候一定要先编译安装go1.4&…
设计模式中的原则
设计模式(详情click)这个术语是由Erich Gamma等人在1990年代从建筑设计领域引入到计算机科学的。它是对软件设计中普遍存在(反复出现)的各种问题,所提出的解决方案。 设计模式并不直接用来完成代码的编写,而是描述在各种不同情况下…

CUDA Samples: approximate image reverse
以下CUDA sample是分别用C和CUDA实现的对图像进行某种类似reverse的操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CUDA_TEST_COMMON_HPP_ #define FBC_CUDA_TEST_COMMON_HPP_#include<random> #i…

超详细支持向量机知识点,面试官会问的都在这里了
(图片付费下载自视觉中国)作者 | 韦伟来源 | 知乎导语:持续准备面试中,准备的过程中,慢慢发现,如果死记硬背的话很难,可当推导一遍并且细细研究里面的缘由的话,面试起来应该什么都不…
vue-router点击切换路由报错
报错: 报错原因: 设置mode:history解决方法: 将router的mode设置为‘hash就不报错了 原因下次再分析?
gvim配置相关
用 vundle 来管理 vim 插件(包含配置文件vimrc和gvimrc) gvim插件管理神器:vundle的安装与使用 Vim插件管理Vundle Linux 下VIM的配置 Vim配置系列(一) ---- 插件管理 Vim配置系列(二) —- 好看的statusline vim优秀插件整理 一些有用的 VIM …

深度学习有哪些接地气又好玩的应用?
过去几年中,深度学习中的很多技术如计算机视觉、自然语言处理等被应用在很多实际问题中,而且相关成果也表明深度学习能让人们的工作效果比以前更好。我们收集了一些深度学习方面的创意应用,虽然没有对每项应用进行详尽描述,但是希…
Ubuntu下通过CMake文件编译CUDA+OpenCV代码操作步骤
在 CUDA_Test 工程中,CUDA测试代码之前仅支持在Windows10 VS2013编译,今天在Ubuntu 14.04下写了一个CMakeLists.txt文件,支持在Linux下也可以通过CMake编译CUDA_Test工程,CMakeLists.txt文件内容如下:# CMake file f…
JAVA 多用户商城系统b2b2c-Spring Cloud常见问题与总结(一)
在使用Spring Cloud的过程中,难免会遇到一些问题。所以对Spring Cloud的常用问题做一些总结。需要JAVA Spring Cloud大型企业分布式微服务云构建的B2B2C电子商务平台源码 一零三八七七四六二六 一、Eureka常见问题 1.1 Eureka 注册服务慢 默认情况下,服务…
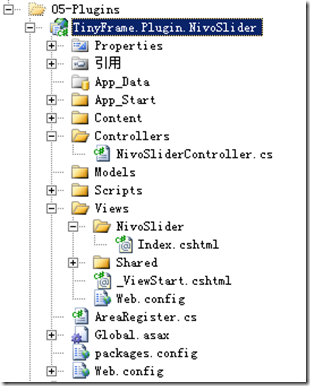
TinyFrame升级之八:实现简易插件化开发
本章主要讲解如何为框架新增插件化开发功能。 在.net 4.0中,我们可以在Application开始之前,通过PreApplicationStartMethod方法加载所需要的任何东西。那么今天我们主要做的工作就集中在这个时间段: 1.将插件DLL及文件拷贝入主网站目录并编译…
快手王华彦:端上视觉技术的极致效率及其短视频应用实践 | AI ProCon 2019
演讲嘉宾 | 王华彦(快手硅谷Y-tech实验室负责人) 编辑 | Just 出品 | AI科技大本营(ID:rgznai100) 快手用户日均上传1500万个视频,要把这些作品准确的分发给超2亿活跃用户,如果没有强大的AI技术系统去理解…
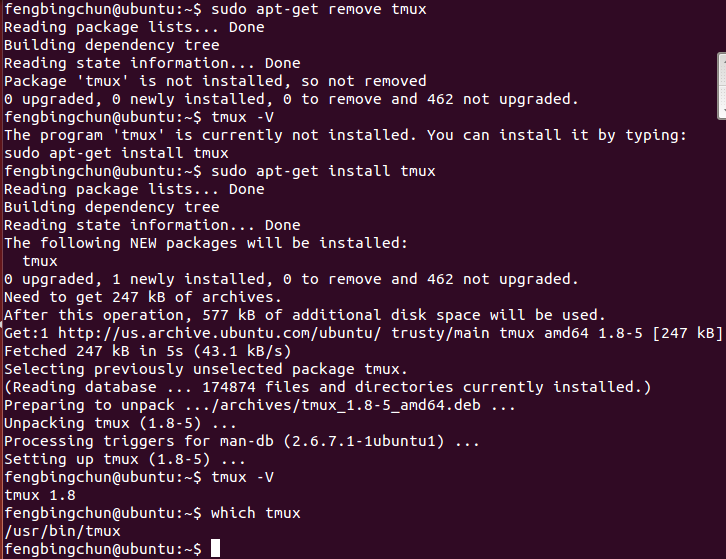
tmux简介及安装
tmux是一个开源工具,用于在一个终端窗口中运行多个终端会话。它可以减少过多的打开终端控制台。tmux的源码在 https://github.com/tmux/tmux ,它的License是BSD。tmux可以直接通过sudo apt-get install tmux命令安装(通过sudo apt-get remove tmux移除)…
Swift中依赖注入的解耦策略
原文地址:Dependency Injection Strategies in Swift 简书地址:Swift中依赖注入的解耦策略 今天我们将深入研究Swift中的依赖注入,这是软件开发中最重要的技术之一,也是许多编程语言中使用频繁的概念。 具体来说,我们将…

Eclipse mac 下的快捷键
2019独角兽企业重金招聘Python工程师标准>>> Eclipse,MyEclipse 的preference 在“windows”下边,mac下在左上角苹果图标边上 win下我们都习惯了ctrl c,在Mac 下使用标准键盘变成了win键c 系统的偏好设定 -> 键盘 -> 修饰…
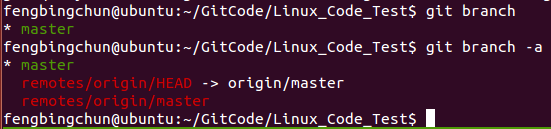
Ubuntu上使终端显示Git分支(oh-my-zsh)
oh-my-zsh是基于Zsh(Zsh是一个Linux用户很少使用的power-shell,这是由于大多数Linux产品安装,以及默认使用bash shell)的功能作了一个扩展,方便插件管理、主体自定义等。oh-my-zsh源码在 https://github.com/robbyrussell/oh-my-zsh &#x…

天哪!我的十一假期被AI操控了
(图片付费下载自视觉中国)导语:这个假期,除了脑海一直在唱歌,庆祝祖国成立的 70 周年,当然也闲不住,要乘机出去浪一浪。目前小长假进度条已经进行到 71.4% 了,有没有发现这个假期与以…
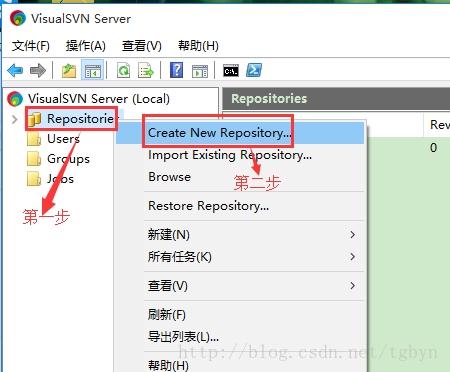
使用SVN+Axure RP 8.0创建团队项目
一、使用到的工具:VisualSVN Server --SVN服务器:https://www.visualsvn.com/server/ Axure RP 8.0 :http://www.downcc.com/soft/103078.html 二、VisualSVN Server 安装以及操作1、安装 : 默认安装即可 2、操作: &a…
no no no.不要使用kill -9.
2019独角兽企业重金招聘Python工程师标准>>> no no no.不要使用kill -9. 它没有给进程留下善后的机会: 1) 关闭socket链接 2) 清理临时文件 3) 将自己将要被销毁的消息通知给子进程 4) 重置自己的终止状态 等等。 通常,应该发送15,…

人工智能的“天罗地网”
(图片付费下载自视觉中国)整理 | 弯月编辑 | 郭芮来源 | CSDN(ID:CSDNnews)人工智能(AI)技术正在全球迅速崛起。不断涌现的最新发展令世人瞩目,从以假乱真的深度伪造视频,…
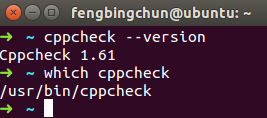
Ubuntu下安装Cppcheck源码操作步骤
Cppcheck是用在C、C中对code进行静态检查的工具。它的源码在 https://github.com/danmar/cppcheck 。它的License是GPL-3.0。Cppcheck可以检查不通过编译的文件,执行的检查包括:(1)、自动变量检查;(2)、数组的边界检查;(3)、clas…

用“脸”打卡,抬头就能签到!
科技正在飞速改变我们的生活,以前我们上班的时候,脖子上总会挂一个IC卡用来验证身份和签到打卡,后来指纹识别出现了,我们又逐渐习惯了指纹打卡,到如今,随着人脸识别技术的出现,我们开始用“脸”…
OC基础第四讲--字符串、数组、字典、集合的常用方法
OC基础第四讲--字符串、数组、字典、集合的常用方法 字符串、数组、字典、集合有可变和不可变之分。以字符串为例,不可变字符串本身值不能改变,必须要用相应类型来接收返回值;而可变字符串调用相应地方法后,本身会改变;…

分类、检测、分割任务均有SOTA表现,ACNet有多强?
(图片付费下载自视觉中国)作者 | 路一直都在来源 | 知乎专栏Abstract本文提出了一种新的自适应连接神经网络(ACNet),从两个方面对传统的卷积神经网络(CNNs)进行了改进。首先,ACNet通过自适应地确定特征节点之间的连接状态…

CUDA Samples: approximate prior vbox layer
以下CUDA sample是分别用C和CUDA实现的类似prior vbox layer的操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CUDA_TEST_COMMON_HPP_ #define FBC_CUDA_TEST_COMMON_HPP_#include <typeinfo> #inc…
如何成为一名成功的 iOS 程序员?
前言: 编程是一个仅靠兴趣仍不足以抵达成功彼岸的领域。你必须充满激情,并且持之以恒地不断汲取更多有关编程的知识。只是对编程感兴趣还不足以功成名就——众所周知,我们工作起来像疯子。 编程是一个没有极限的职业,所以要成为一…

C#之委托与事件
委托与事件废话一堆:网上关于委托、事件的文章有很多,一千个哈姆雷特就有一千个莎士比亚,以下内容均是本人个人见解。1. 委托1.1 委托的使用这一小章来学习一下怎么简单的使用委托,了解一些基本的知识。这里先看一下其他所要用到的…

24式加速你的Python
作者 | 梁云1991来源 Python与算法之美一、分析代码运行时间第1式,测算代码运行时间平凡方法快捷方法(jupyter环境)第2式,测算代码多次运行平均时间平凡方法快捷方法(jupyter环境)第3式,按调用函…
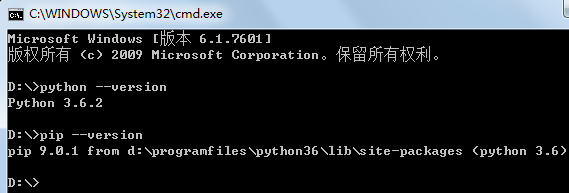
pip、NumPy、Matplotlib在Windows上的安装过程
Windows上Python 3.6.2 64位的安装步骤:1. 从 https://www.python.org/downloads/windows/ 下载Windows x86-64 executable installer(即python-3.6.2-amd64.exe);2. 直接以管理员身份运行安装,勾选添加到环境变量、pip等即可。可以同时在Wi…
分享:个人是怎么学习新知识的
为什么80%的码农都做不了架构师?>>> 挺多童鞋问我是怎么学习新知识的,干脆写篇文章总结一下,希望对大家有所帮助。对照书、技术博客、极客时间等学习的方式我就不说了。 一、早期 在15年及更早,由于知识储备少&#x…