CUDA Samples: approximate prior vbox layer
以下CUDA sample是分别用C++和CUDA实现的类似prior vbox layer的操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:
common.hpp:
#ifndef FBC_CUDA_TEST_COMMON_HPP_
#define FBC_CUDA_TEST_COMMON_HPP_#include <typeinfo>
#include<random>
#include <cuda_runtime.h> // For the CUDA runtime routines (prefixed with "cuda_")
#include <device_launch_parameters.h>
#include <opencv2/opencv.hpp>template< typename T >
static inline int check_Cuda(T result, const char * const func, const char * const file, const int line)
{if (result) {fprintf(stderr, "Error CUDA: at %s: %d, error code=%d, func: %s\n", file, line, static_cast<unsigned int>(result), func);cudaDeviceReset(); // Make sure we call CUDA Device Reset before exitingreturn -1;}
}template< typename T >
static inline int check(T result, const char * const func, const char * const file, const int line)
{if (result) {fprintf(stderr, "Error: at %s: %d, error code=%d, func: %s\n", file, line, static_cast<unsigned int>(result), func);return -1;}
}#define checkCudaErrors(val) check_Cuda((val), __FUNCTION__, __FILE__, __LINE__)
#define checkErrors(val) check((val), __FUNCTION__, __FILE__, __LINE__)#define CHECK(x) { \if (x) {} \else { fprintf(stderr, "Check Failed: %s, file: %s, line: %d\n", #x, __FILE__, __LINE__); return -1; } \
}#define PRINT_ERROR_INFO(info) { \fprintf(stderr, "Error: %s, file: %s, func: %s, line: %d\n", #info, __FILE__, __FUNCTION__, __LINE__); \return -1; }#define TIME_START_CPU auto start = std::chrono::steady_clock::now();
#define TIME_END_CPU auto end = std::chrono::steady_clock::now(); \auto duration = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start); \*elapsed_time = duration.count() * 1.0e-6;#define TIME_START_GPU cudaEvent_t start, stop; /* cudaEvent_t: CUDA event types,结构体类型, CUDA事件,用于测量GPU在某个任务上花费的时间,CUDA中的事件本质上是一个GPU时间戳,由于CUDA事件是在GPU上实现的,因此它们不适于对同时包含设备代码和主机代码的混合代码计时 */ \cudaEventCreate(&start); /* 创建一个事件对象,异步启动 */ \cudaEventCreate(&stop); \cudaEventRecord(start, 0); /* 记录一个事件,异步启动,start记录起始时间 */
#define TIME_END_GPU cudaEventRecord(stop, 0); /* 记录一个事件,异步启动,stop记录结束时间 */ \cudaEventSynchronize(stop); /* 事件同步,等待一个事件完成,异步启动 */ \cudaEventElapsedTime(elapsed_time, start, stop); /* 计算两个事件之间经历的时间,单位为毫秒,异步启动 */ \cudaEventDestroy(start); /* 销毁事件对象,异步启动 */ \cudaEventDestroy(stop);#define EPS_ 1.0e-4 // ε(Epsilon),非常小的数
#define PI 3.1415926535897932f
#define INF 2.e10fstatic inline void generator_random_number(float* data, int length, float a = 0.f, float b = 1.f)
{std::random_device rd; std::mt19937 generator(rd()); // 每次产生不固定的不同的值//std::default_random_engine generator; // 每次产生固定的不同的值std::uniform_real_distribution<float> distribution(a, b);for (int i = 0; i < length; ++i) {data[i] = distribution(generator);}
}template<typename T> // unsigned char, char, int , short
static inline void generator_random_number(T* data, int length, T a = (T)0, T b = (T)1)
{std::random_device rd; std::mt19937 generator(rd()); // 每次产生不固定的不同的值//std::default_random_engine generator; // 每次产生固定的不同的值std::uniform_int_distribution<int> distribution(a, b);for (int i = 0; i < length; ++i) {data[i] = static_cast<T>(distribution(generator));}
}static int save_image(const cv::Mat& mat1, const cv::Mat& mat2, int width, int height, const std::string& name)
{CHECK(mat1.type() == mat2.type());cv::Mat src1, src2, dst;cv::resize(mat1, src1, cv::Size(width / 2, height));cv::resize(mat2, src2, cv::Size(width / 2, height));dst = cv::Mat(height, width / 2 * 2, mat1.type());cv::Mat tmp = dst(cv::Rect(0, 0, width / 2, height));src1.copyTo(tmp);tmp = dst(cv::Rect(width / 2, 0, width / 2, height));src2.copyTo(tmp);cv::imwrite(name, dst);
}template<typename T>
static inline int compare_result(const T* src1, const T* src2, int length)
{CHECK(src1);CHECK(src2);int count{ 0 };for (int i = 0; i < length; ++i) {if (fabs(src1[i] - src2[i]) > EPS_) {if (typeid(float).name() == typeid(T).name() || typeid(double).name() == typeid(T).name())fprintf(stderr, "index: %d, val1: %f, val2: %f\n", i, src1[i], src2[i]);elsefprintf(stderr, "index: %d, val1: %d, val2: %d\n", i, src1[i], src2[i]);++count;}if (count > 100) return -1;}return 0;
}#endif // FBC_CUDA_TEST_COMMON_HPP_
#include "funset.hpp"
#include <random>
#include <iostream>
#include <vector>
#include <memory>
#include <string>
#include <algorithm>
#include "common.hpp"int test_layer_prior_vbox()
{std::vector<float> vec1{423.f, 245.f, 1333.f, 1444.f, 123.f, 23.f, 32.f, 66.f};std::vector<float> vec2(vec1[6]);std::vector<float> vec3(4);int length = int(vec1[0] * vec1[1] * vec1[6] * 4 * 2);std::unique_ptr<float[]> data1(new float[length]), data2(new float[length]);std::for_each(data1.get(), data1.get() + length, [](float& n) {n = 0.f; });std::for_each(data2.get(), data2.get() + length, [](float& n) {n = 0.f; });generator_random_number(vec2.data(), vec2.size(), 10.f, 100.f);generator_random_number(vec3.data(), vec3.size(), 1.f, 10.f);float elapsed_time1{ 0.f }, elapsed_time2{ 0.f }; // millisecondsint ret = layer_prior_vbox_cpu(data1.get(), length, vec1, vec2, vec3, &elapsed_time1);if (ret != 0) PRINT_ERROR_INFO(layer_prior_vbox_cpu);ret = layer_prior_vbox_gpu(data2.get(), length, vec1, vec2, vec3, &elapsed_time2);if (ret != 0) PRINT_ERROR_INFO(layer_prior_vbox_gpu);compare_result(data1.get(), data2.get(), length);fprintf(stderr, "test layer prior vbox: cpu run time: %f ms, gpu run time: %f ms\n", elapsed_time1, elapsed_time2);return 0;
}#include "funset.hpp"
#include <vector>
#include <chrono>
#include "common.hpp"int layer_prior_vbox_cpu(float* dst, int length, const std::vector<float>& vec1, const std::vector<float>& vec2,const std::vector<float>& vec3, float* elapsed_time)
{TIME_START_CPUint layer_width = (int)vec1[0];int layer_height = (int)vec1[1];int image_width = (int)vec1[2];int image_height = (int)vec1[3];float offset = vec1[4];float step = vec1[5];int num_priors = (int)vec1[6];float width = vec1[7];CHECK(length == layer_width * layer_height * num_priors * 4 * 2);CHECK(vec1.size() == 8);CHECK(vec2.size() == num_priors);CHECK(vec3.size() == 4);float* top_data = dst;int idx = 0;for (int h = 0; h < layer_height; ++h) {for (int w = 0; w < layer_width; ++w) {float center_x = (w + offset) * step;float center_y = (h + offset) * step;for (int s = 0; s < num_priors; ++s) {float box_width = width;float box_height = vec2[s];top_data[idx++] = (center_x - box_width / 2.) / image_width;top_data[idx++] = (center_y - box_height / 2.) / image_height;top_data[idx++] = (center_x + box_width / 2.) / image_width;top_data[idx++] = (center_y + box_height / 2.) / image_height;}}}int len = layer_width * layer_height * num_priors;for (int i = 0; i < len; ++i) {for (int j = 0; j < 4; ++j) {top_data[idx++] = vec3[j];}}TIME_END_CPUreturn 0;
}#include "funset.hpp"
#include <iostream>
#include <memory>
#include <algorithm>
#include <cmath>
#include <cuda_runtime.h> // For the CUDA runtime routines (prefixed with "cuda_")
#include <device_launch_parameters.h>
#include "common.hpp"/* __global__: 函数类型限定符;在设备上运行;在主机端调用,计算能力3.2及以上可以在
设备端调用;声明的函数的返回值必须是void类型;对此类型函数的调用是异步的,即在
设备完全完成它的运行之前就返回了;对此类型函数的调用必须指定执行配置,即用于在
设备上执行函数时的grid和block的维度,以及相关的流(即插入<<< >>>运算符);
a kernel,表示此函数为内核函数(运行在GPU上的CUDA并行计算函数称为kernel(内核函
数),内核函数必须通过__global__函数类型限定符定义);*/
__global__ static void layer_prior_vbox(float* dst, int layer_width, int layer_height, int image_width, int image_height,float offset, float step, int num_priors, float width, const float* height, const float* variance, int channel_size)
{/* gridDim: 内置变量,用于描述线程网格的维度,对于所有线程块来说,这个变量是一个常数,用来保存线程格每一维的大小,即每个线程格中线程块的数量.一个grid为三维,为dim3类型;blockDim: 内置变量,用于说明每个block的维度与尺寸.为dim3类型,包含了block在三个维度上的尺寸信息;对于所有线程块来说,这个变量是一个常数,保存的是线程块中每一维的线程数量;blockIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程块的索引;用于说明当前thread所在的block在整个grid中的位置,blockIdx.x取值范围是[0,gridDim.x-1],blockIdx.y取值范围是[0, gridDim.y-1].为uint3类型,包含了一个block在grid中各个维度上的索引信息;threadIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程索引;用于说明当前thread在block中的位置;如果线程是一维的可获取threadIdx.x,如果是二维的还可获取threadIdx.y,如果是三维的还可获取threadIdx.z;为uint3类型,包含了一个thread在block中各个维度的索引信息 */int x = threadIdx.x + blockIdx.x * blockDim.x;int y = threadIdx.y + blockIdx.y * blockDim.y;if (x < layer_width && y < layer_height) {float center_x = (x + offset) * step;float center_y = (y + offset) * step;int idx = x * num_priors * 4 + y * (layer_width * num_priors * 4);for (int s = 0; s < num_priors; ++s) {float box_width = width;float box_height = height[s];int idx1 = idx + s * 4;dst[idx1] = (center_x - box_width / 2.) / image_width;dst[idx1 + 1] = (center_y - box_height / 2.) / image_height;dst[idx1 + 2] = (center_x + box_width / 2.) / image_width;dst[idx1 + 3] = (center_y + box_height / 2.) / image_height;int idx2 = channel_size + idx + s * 4;dst[idx2] = variance[0];dst[idx2 + 1] = variance[1];dst[idx2 + 2] = variance[2];dst[idx2 + 3] = variance[3];}}
}int layer_prior_vbox_gpu(float* dst, int length, const std::vector<float>& vec1, const std::vector<float>& vec2,const std::vector<float>& vec3, float* elapsed_time)
{float *dev_dst{ nullptr }, *dev_vec;// cudaMalloc: 在设备端分配内存cudaMalloc(&dev_dst, length * sizeof(float));cudaMalloc(&dev_vec, (vec2.size()+vec3.size()) * sizeof(float));/* cudaMemcpy: 在主机端和设备端拷贝数据,此函数第四个参数仅能是下面之一:(1). cudaMemcpyHostToHost: 拷贝数据从主机端到主机端(2). cudaMemcpyHostToDevice: 拷贝数据从主机端到设备端(3). cudaMemcpyDeviceToHost: 拷贝数据从设备端到主机端(4). cudaMemcpyDeviceToDevice: 拷贝数据从设备端到设备端(5). cudaMemcpyDefault: 从指针值自动推断拷贝数据方向,需要支持统一虚拟寻址(CUDA6.0及以上版本)cudaMemcpy函数对于主机是同步的 */cudaMemcpy(dev_dst, dst, length * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(dev_vec, vec2.data(), vec2.size() * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(dev_vec + vec2.size(), vec3.data(), vec3.size() * sizeof(float), cudaMemcpyHostToDevice);int layer_width = (int)vec1[0];int layer_height = (int)vec1[1];int image_width = (int)vec1[2];int image_height = (int)vec1[3];float offset = vec1[4];float step = vec1[5];int num_priors = (int)vec1[6];float width = vec1[7];int channel_size = layer_width * layer_height * num_priors * 4;TIME_START_GPU/* dim3: 基于uint3定义的内置矢量类型,相当于由3个unsigned int类型组成的结构体,可表示一个三维数组,在定义dim3类型变量时,凡是没有赋值的元素都会被赋予默认值1 */// Note:每一个线程块支持的最大线程数量为1024,即threads.x*threads.y必须小于等于1024dim3 threads(32, 32);dim3 blocks((layer_width + 31) / 32, (layer_height + 31) / 32);/* <<< >>>: 为CUDA引入的运算符,指定线程网格和线程块维度等,传递执行参数给CUDA编译器和运行时系统,用于说明内核函数中的线程数量,以及线程是如何组织的;尖括号中这些参数并不是传递给设备代码的参数,而是告诉运行时如何启动设备代码,传递给设备代码本身的参数是放在圆括号中传递的,就像标准的函数调用一样;不同计算能力的设备对线程的总数和组织方式有不同的约束;必须先为kernel中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误,例如越界等 ;使用运行时API时,需要在调用的内核函数名与参数列表直接以<<<Dg,Db,Ns,S>>>的形式设置执行配置,其中:Dg是一个dim3型变量,用于设置grid的维度和各个维度上的尺寸.设置好Dg后,grid中将有Dg.x*Dg.y*Dg.z个block;Db是一个dim3型变量,用于设置block的维度和各个维度上的尺寸.设置好Db后,每个block中将有Db.x*Db.y*Db.z个thread;Ns是一个size_t型变量,指定各块为此调用动态分配的共享存储器大小,这些动态分配的存储器可供声明为外部数组(extern __shared__)的其他任何变量使用;Ns是一个可选参数,默认值为0;S为cudaStream_t类型,用于设置与内核函数关联的流.S是一个可选参数,默认值0. */// Note: 核函数不支持传入参数为vector的data()指针,需要cudaMalloc和cudaMemcpy,因为vector是在主机内存中layer_prior_vbox << <blocks, threads>> >(dev_dst, layer_width, layer_height, image_width, image_height,offset, step, num_priors, width, dev_vec, dev_vec + vec2.size(), channel_size);/* cudaDeviceSynchronize: kernel的启动是异步的, 为了定位它是否出错, 一般需要加上cudaDeviceSynchronize函数进行同步; 将会一直处于阻塞状态,直到前面所有请求的任务已经被全部执行完毕,如果前面执行的某个任务失败,将会返回一个错误;当程序中有多个流,并且流之间在某一点需要通信时,那就必须在这一点处加上同步的语句,即cudaDeviceSynchronize;异步启动reference: https://stackoverflow.com/questions/11888772/when-to-call-cudadevicesynchronize */cudaDeviceSynchronize();TIME_END_GPUcudaMemcpy(dst, dev_dst, length * sizeof(float), cudaMemcpyDeviceToHost);// cudaFree: 释放设备上由cudaMalloc函数分配的内存cudaFree(dev_dst);cudaFree(dev_vec);return 0;
}
相关文章:

如何成为一名成功的 iOS 程序员?
前言: 编程是一个仅靠兴趣仍不足以抵达成功彼岸的领域。你必须充满激情,并且持之以恒地不断汲取更多有关编程的知识。只是对编程感兴趣还不足以功成名就——众所周知,我们工作起来像疯子。 编程是一个没有极限的职业,所以要成为一…

C#之委托与事件
委托与事件废话一堆:网上关于委托、事件的文章有很多,一千个哈姆雷特就有一千个莎士比亚,以下内容均是本人个人见解。1. 委托1.1 委托的使用这一小章来学习一下怎么简单的使用委托,了解一些基本的知识。这里先看一下其他所要用到的…

24式加速你的Python
作者 | 梁云1991来源 Python与算法之美一、分析代码运行时间第1式,测算代码运行时间平凡方法快捷方法(jupyter环境)第2式,测算代码多次运行平均时间平凡方法快捷方法(jupyter环境)第3式,按调用函…
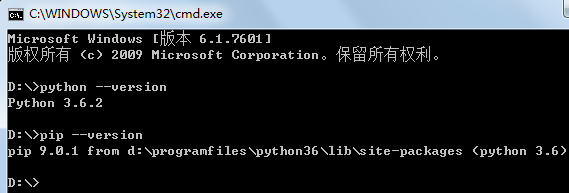
pip、NumPy、Matplotlib在Windows上的安装过程
Windows上Python 3.6.2 64位的安装步骤:1. 从 https://www.python.org/downloads/windows/ 下载Windows x86-64 executable installer(即python-3.6.2-amd64.exe);2. 直接以管理员身份运行安装,勾选添加到环境变量、pip等即可。可以同时在Wi…

分享:个人是怎么学习新知识的
为什么80%的码农都做不了架构师?>>> 挺多童鞋问我是怎么学习新知识的,干脆写篇文章总结一下,希望对大家有所帮助。对照书、技术博客、极客时间等学习的方式我就不说了。 一、早期 在15年及更早,由于知识储备少&#x…
easyui的datagrid
datagrid数据的绑定方式: 1)data 后跟数据行的json串 2)url 后跟{"total":,"rows":,"foot":},其中total代码返回总行数,rows为数据行json串 .NET MVC,controll控制类方法中获取datagrid…
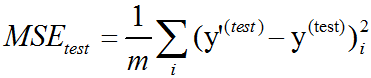
线性回归介绍及分别使用最小二乘法和梯度下降法对线性回归C++实现
回归:在这类任务中,计算机程序需要对给定输入预测数值。为了解决这个任务,学习算法需要输出函数f:Rn→R。除了返回结果的形式不一样外,这类问题和分类问题是很像的。这类任务的一个示例是预测投保人的索赔金额(用于设置保险费)&am…
4种最常问的编码算法面试问题,你会吗?
导语:面试是测查和评价人员能力素质的一种考试活动。最常问的编码算法面试问题你知道多少呢?作者 | Rahul Sabnis译者 | 苏本如,编辑 | 刘静来源 | CSDN(ID:CSDNnews)在许多采访中,我经常被要求…
[小梅的体验课堂]Microsoft edge canary mac版本体验
简介 华硕微软越来越没有自己的JC了,不经在windows里面加了wsl而且还废弃了自己的老edge浏览器,重新基于chromium内核开发了新的edge浏览器了,不管怎么说mac上又多了一款新的浏览器,对于一个爱好新鲜的我来说那就简单安装体验下 下…
SQL Server用户自定义函数
用户自定义函数不能用于执行一系列改变数据库状态的操作,但它可以像系统 函数一样在查询或存储过程等的程序段中使用,也可以像存储过程一样通过EXECUTE 命令来执行。在 SQL Server 中根据函数返回值形式的不同将用户自 定义函数分为三种类型:…
C++11中std::initializer_list的使用
initializer_list是一种标准库类型,用于表示某种特定类型的值的数组。和vector一样,initializer_list也是一种模板类型,定义initializer_list对象时,必须说明列表中所含元素的类型。和vector不一样的是,initializer_li…
WijmoJS 2019V1正式发布:全新的在线 Demo 系统,助您快速上手,开发无忧
2019独角兽企业重金招聘Python工程师标准>>> 下载WijmoJS 2019 v1 WijmoJS是为企业应用程序开发而推出的一系列包含HTML5和JavaScript的开发控件。其中包含了金融图表、FlexSheet、先进的JavaScript控件(Wijmo 5)和经典的jQuery小部件&#x…

最后3天,BDTC 2019早鸟票即将售罄,超强阵容及议题抢先曝光!
大会官网:https://t.csdnimg.cn/U1wA2019 年12月5-7 日,由中国计算机学会主办,CCF 大数据专家委员会承办,CSDN、中科天玑数据科技股份有限公司协办的 2019 中国大数据技术大会,将于北京长城饭店隆重举行。届时…
php_mongo.dll下载(php操作mongoDB需要)
php_mongo.dll下载(php操作mongoDB需要)如果PHP连接操作mongoDB就必须要加入此扩展:php_mongo.dll,放到你对应php的扩展目录在你的php.ini中加入:extensionphp_mongo.dll重启apache,在phpinfo()中查看是否有…

十大机器智能新型芯片:华为抢占一席,Google占比最多
(图片付费下载自视觉中国)整理 | 胡巍巍来源 | CSDN(ID:CSDNnews)当年,阿基米德爷爷说出“给我一个支点,我就能撬动地球”这句话时,估计没少遭受嘲讽。然而后来的我们,都…
C++/C++11中头文件numeric的使用
<numeric>是C标准程序库中的一个头文件,定义了C STL标准中的基础性的数值算法(均为函数模板): (1)、accumulate: 以init为初值,对迭代器给出的值序列做累加,返回累加结果值,值类型必须支持””算符。它还有一个…
Spring基础16——使用FactoryBean来创建
1.配置bean的方式 配置bean有三种方式:通过全类名(class反射)、通过工厂方法(静态工厂&实例工厂)、通过FactoryBean。前面我们已经一起学习过全类名方式和工厂方法方式,下面通过这篇文章来学习一下Fact…
查看进程 端口
2019独角兽企业重金招聘Python工程师标准>>> 一 进程 ps -ef 1.UID 用户ID2.PID 进程ID3.PPID 父进程ID4.C CPU占用率5.STIME 开始时间6.TTY 开始此进程的TTY7.TIME 此进程运行的总时间8.CMD 命令名 二端口 netstat Linux下如果我…
深度学习中的欠拟合和过拟合简介
通常情况下,当我们训练机器学习模型时,我们可以使用某个训练集,在训练集上计算一些被称为训练误差(training error)的度量误差,目标是降低训练误差。机器学习和优化不同的地方在于,我们也希望泛化误差(generalization …

今日头条首次改进DQN网络,解决推荐中的在线广告投放问题
(图片付费下载自视觉中国)作者 | 深度传送门来源 | 深度传送门(ID:gh_5faae7b50fc5)【导读】本文主要介绍今日头条推出的强化学习应用在推荐的最新论文[1],首次改进DQN网络解决推荐中的在线广告投放问题。背景介绍随着…
RPA实施过程中可能会遇到的14个坑
RPA的实施过程并非如我们所想的那样,总是一帆风顺。碰坑,在所难免。但也不必为此过于惊慌,因为,我们已经帮你把RPA实施之路上的坑找了出来。RPA实施过程中,将会遇到哪些坑? 【不看全文大纲版】●组织层面&a…
Android问题汇总
2019独角兽企业重金招聘Python工程师标准>>> 1. Only the original thread that created a view hierarchy can touch its views 在初始化activity是需要下载图片,所以重新开启了一个线程,下载图片更新ui,此时就出现了上面的错误。…
深度学习中的验证集和超参数简介
大多数机器学习算法都有超参数,可以设置来控制算法行为。超参数的值不是通过学习算法本身学习出来的(尽管我们可以设计一个嵌套的学习过程,一个学习算法为另一个学习算法学出最优超参数)。在多项式回归示例中,有一个超参数:多项式…
自定义View合辑(8)-跳跃的小球(贝塞尔曲线)
为了加强对自定义 View 的认知以及开发能力,我计划这段时间陆续来完成几个难度从易到难的自定义 View,并简单的写几篇博客来进行介绍,所有的代码也都会开源,也希望读者能给个 star 哈 GitHub 地址:github.com/leavesC/…

分析Booking的150种机器学习模型,我总结了六条成功经验
(图片付费下载自视觉中国)作者 | Adrian Colyer译者 | Monanfei出品 | AI科技大本营(ID:rgznai100)本文是一篇有趣的论文(150 successful machine learning models: 6 lessons learned at Booking.com Bernadi et al.,…
Android官方提供的支持不同屏幕大小的全部方法
2019独角兽企业重金招聘Python工程师标准>>> 本文将告诉你如何让你的应用程序支持各种不同屏幕大小,主要通过以下几种办法: 让你的布局能充分的自适应屏幕根据屏幕的配置来加载合适的UI布局确保正确的布局应用在正确的设备屏幕上提供可以根据…
C++/C++11中头文件iterator的使用
<iterator>是C标准程序库中的一个头文件,定义了C STL标准中的一些迭代器模板类,这些类都是以std::iterator为基类派生出来的。迭代器提供对集合(容器)元素的操作能力。迭代器提供的基本操作就是访问和遍历。迭代器模拟了C中的指针,可以…

从多媒体技术演进看AI技术
(图片付费下载自视觉中国)文 / LiveVideoStack主编 包研在8月的LiveVideoStackCon2019北京开场致辞中,我分享了一组数据——把2019年和2017年两场LiveVideoStackCon上的AI相关的话题做了统计,这是数字从9.3%增长到31%,…
五. python的日历模块
一 .日历 import calendar# 日历模块# 使用# 返回指定某年某月的日历 print(calendar.month(2017,7))# July 2017 # Mo Tu We Th Fr Sa Su # 1 2 # 3 4 5 6 7 8 9 # 10 11 12 13 14 15 16 # 17 18 19 20 21 22 23 # 24 25 26 27 28 29 30 # 31# 返…
Linux下的Shell工作原理
为什么80%的码农都做不了架构师?>>> Linux系统提供给用户的最重要的系统程序是Shell命令语言解释程序。它不 属于内核部分,而是在核心之外,以用户态方式运行。其基本功能是解释并 执行用户打入的各种命令,实现用户与L…