十大机器智能新型芯片:华为抢占一席,Google占比最多

(图片付费下载自视觉中国)
当年,阿基米德爷爷说出“给我一个支点,我就能撬动地球”这句话时,估计没少遭受嘲讽。
然而后来的我们,都曾在物理课本上学过这句话。
事实证明,小,也可以很有力量。
芯片,便是小体积、大能量的典型代表之一。
近日,一位外国科技作者,总结了10个用于机器智能的新型硅芯片的详细信息,从这10个硅芯片来看,谷歌占比最多,国内仅有华为一个。
一起来看看,这10个硅芯片的完整信息吧!
当当当当!先PO出一张图,来一个总览!
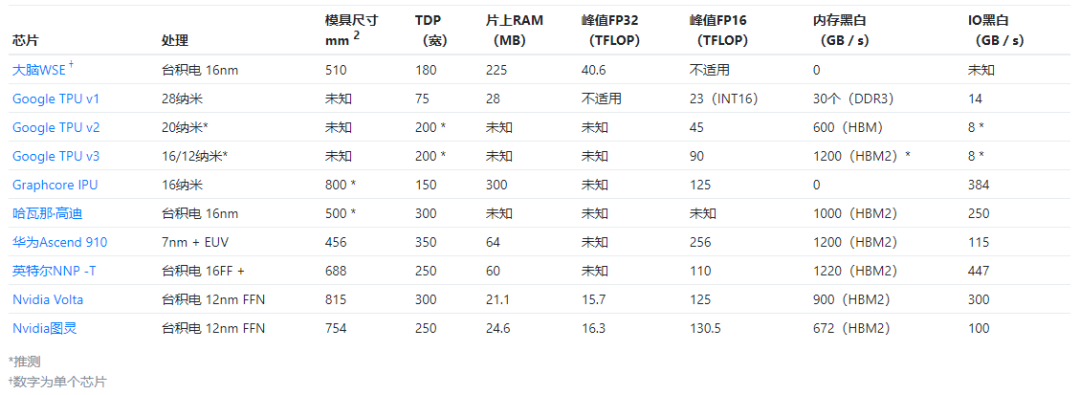
(图源:James W. Hanlon.com)
Cerebras晶圆级引擎芯片(Cerebras Wafer-Scale Engine)
Cerebras晶圆级引擎(WSE)芯片,无疑是最近出现的最大胆和创新的设计。晶圆级集成并不是一个新主意,但是与产量、功率传输和热膨胀有关的集成问题,使其难以商业化。
Cerebras使用这种方法将84个芯片与高速互连集成在一起,从而将基于2D网格的互连按比例缩放到很大比例。
这样可以为机器提供大量内存(18 GB)分布在大量计算中(3.3 Peta FLOP峰值)。
目前,尚不清楚该架构如何扩展到单个WSE之外。当前神经网络的趋势是拥有数十亿权重的大型网络,这将需要进行这样的缩放。
该芯片细节:
- 宣布于2019年8月。
- TSMC 16 nm的46,225 mm 2晶圆级集成系统(215 mm x 215 mm)。
- 1.2T晶体管。
- 许多单独的筹码:总共84(12宽乘7高)。
- 总共18 GB的SRAM存储器,分布在内核之间。
- 426,384个简单计算核心。
- 硅缺陷可以通过使用冗余内核和链路绕过故障区域来修复。
- 推测的时钟速度约为1 GHz,功耗为15 kW。
- 跨越划线的芯片之间的互连,以及在常规晶圆制造后的后处理步骤中添加的布线。
- IO在晶圆的东西边缘带出,这受每个边缘的焊盘密度限制。不可能有高速SerDes,因为这些高速SerDes需要集成在每个芯片中,从而使晶圆区域中相当大的一部分与外围具有边缘的芯片成为多余。
- 基于2D网格的互连,支持单字消息。据官方白皮书表示:“ Cerebras软件将WSE上的所有核心配置为支持所需的精确通信”。
- 互连需要静态配置以支持特定的通信模式。
- 未在互连上传输零以优化稀疏性。
- 是〜0.1 mm 2的硅。
- 具有47 kB SRAM存储器。
- 零未从内存中加载,零未相乘。
- 假定FP32精度和标量执行(无法使用SIMD从内存中过滤零)。
- FMAC数据路径(每个周期8个峰值操作)。
- 张量控制单元向FMAC数据路径提供来自内存的跨步访问或来自链接的入站数据。
- 有四个与其邻居相邻的8 GB / s双向链接。
- 是17毫米x 30毫米= 510毫米2的硅。
- 具有225 MB SRAM 内存。
- 具有54 x 94 = 5,076个核心(由于修复方案而剩下4,888个可用核心,每行/列两个核心可能未使用)。
- FP32的峰值FP32性能达到40 Tera FLOP。
Google TPU v3
- 2018年5月宣布。
- 可能是16nm或12nm。
- 预计TDP为 200W 。
- BFloat16的105个TFLOP,可能是将MXU加倍到四个。
- 每个MXU都具有对8 GB内存的专用访问权限。
- 集成在四芯片模块(如图)中,峰值性能达420个TFLOP。
- 32 GB HBM2集成内存,访问带宽为1200 GBps(假定)。
- 假定PCIe-3 x8为8 GBps。
Google TPU v2
- 2017年5月宣布。
- 可能是20nm。
- 预计TDP为 200-250W 。
- 45 TFLOP的BFloat16。
- 具有标量和矩阵单元的两个核心。
- 还支持FP32。
- 集成在四芯片模块(如图)中,具有180个TFLOP峰值性能。
- 具有BFloat16乘法和FP32累加的128x128x32b脉动矩阵单元(MXU)。
- 8GB专用HBM,访问带宽为300 GBps。
- BFloat16的峰值吞吐量为22.5 TFLOP。
- 16 GB HBM集成内存,带宽为600 GBps(假定)。
- PCIe-3 x8(8 GBps)。
Google TPU v1
- 在2016年宣布。
- 331 mm 2在28nm工艺上死亡。
- 时钟频率为700 MHz,TDP为 28-40W 。
- 28 MB片上SRAM存储器:24 MB用于激活,4 MB用于累加器。
- 芯片面积的比例:35%的内存,24%的矩阵乘法单元,41%的逻辑剩余空间。
- 256x256x8b脉动矩阵乘法单元(64K MAC /周期)。
- INT8和INT16算术(分别为峰值92和23 TOPs / s)。
- 可通过两个端口以34 GB / s的速度访问8 GB DDR3 -2133 DRAM。
- PCIe-3 x 16(14 GBps)。
Graphcore IPU
- 16 nm,236亿个晶体管,〜800mm 2芯片尺寸。
- 1216个处理器块。
- 具有FP32累加功能的125个TFLOP峰值FP16算法。
- 300 MB的总片上内存分布在处理器内核之间,提供45 TBps的总访问带宽。
- 所有模型状态都保存在芯片上,没有直接连接的DRAM。
- 150 W TDP(300 W PCIe卡)。
- 2个PCIe-4主机IO链接。
- 10x卡间“ IPU 链接”。
- 总共384 GBps IO带宽。
- 混合精度浮点随机算法。
- 最多运行六个程序线程。
哈瓦那实验室高迪(Habana Labs Gaudi)
- 2019年6月宣布。
- 采用CoWoS的TSMC 16 nm,假定管芯尺寸为〜500mm 2。
- 异构架构,具有:
- 一个GEMM操作引擎;
- 8个Tensor处理核心(TPC);
- 共享的SRAM存储器(可通过RDMA管理和访问的软件)。
- PCIe卡为200W TDP,夹层卡为300W TDP。
- 未知的总片上存储器。
- 芯片之间的显式内存管理(无一致性)。
- VLIW SIMD并行性和本地SRAM 存储器。
- 混合精度:FP32,BF16以及整数格式(INT32,INT16,INT8,UINT32,UINT8)。
- 随机数生成。
- 超越函数:Sigmoid,Tanh,高斯误差线性单位(GeLU)。
- 张量寻址和跨步访问。
- 每个TPC未知的本地内存。
- 4个HBM2 -2000 DRAM堆栈,以1 TBps的速度提供32 GB。
- 片上集成了10个100GbE接口,支持基于融合以太网(RoCE v2)的RDMA。
- IO使用20个56 Gbps PAM4 Tx / Rx SerDes实现,也可以配置为20个50 GbE。这样最多可连接64个芯片,并且吞吐量无阻塞。
- PCIe-4 x16主机接口。
- 宣布于2019年8月。
- 456 mm 2逻辑芯片在7+ nm EUV工艺上进行。
- 与四个96 mm 2 HBM2堆栈和“ Nimbus” IO处理器芯片共同封装。
- 32个达芬奇核心。
- 峰值256个TFLOP(32 x 4096 x 2)FP16性能,是INT8的两倍。
- 32 MB共享片上SRAM(二级缓存)。
- 350W TDP。
- 内核在6 x 4 2D网状分组交换网络中互连,每个内核提供128 GBps的双向带宽。
- 对L2缓存的访问速度为4 TBps。
- 1.2 TBps HBM2访问带宽。
- 3个30 GBps的芯片间IO。
- 2个25 GBps RoCE网络接口。
- 3D 16x16x16矩阵乘法单元,提供4,096个FP16 MAC和8,192个INT8 MAC。
- FP32(x64),FP16(x128)和INT8 (x256)的2,048位SIMD矢量操作。
- 支持标量运算。
英特尔NNP -T
- 270亿个晶体管。
- 在带有CoWoS的TSMC 16FF + TSMC上,688 mm 2模具。
- 四个8 GB堆栈中的32 GB HBM2 -2400 集成在1200 mm 2的无源硅中介层上。
- 60 MB的片上SRAM存储器分布在内核之间,并 受ECC保护。
- 最高1.1 GHz核心时钟。
- 150-250W TDP。
- 24个Tensor处理群集(TCP)内核。
- TPC以2D网状网络拓扑连接。
- 用于不同类型数据的独立网络:控制,存储器和芯片间通信。
- 支持多播。
- 119个最佳性能峰值。
- HBM2带宽为1.22TBps 。
- 芯片间IO的64个SerDes通道的峰值带宽为3.58Tbps(每个通道的每个方向28 Gbps)。
- x16 PCIe-4主机接口(还支持OAM和Open Compute)。
- 2个32x32 BFloat16乘法器阵列,支持FMAC操作和FP32累加。
- 向量FP32和BFloat16操作。
- 支持先验功能,随机数生成,减少和累积。
- 可编程FP32查找表。
- 用于非MAC计算的独立卷积引擎。
- 2.5 MB的两端口专用内存,具有1.4 TBps的读/写带宽。
- 内存支持张量转置操作。
- 通信接口支持网状网络上的动态数据包路由(虚拟通道,可靠的传输)。
- 多达1024个具有直接互连的芯片,提供相同的分布式内存编程模型(显式内存管理,同步原语,消息传递)。
- 扩展展示了以环形拓扑连接的多达32个芯片。
Nvidia Volta
- 2017年5月宣布。
- 815毫米2上TSMC 12海里FFN,21.1 BN晶体管。
- 300 W TDP(SXM2尺寸)。
- 6 MB二级缓存。
- 84个SM,每个SM包含:64个FP32 CUDA内核,32个FP64 CUDA内核和8个Tensor内核(5376 FP32内核,2688 FP64内核,672个TC)。
- Tensor Core执行4x4 FMA,实现64 FMA运算/周期和128 FLOP。
- 每个SM 128 KB L1数据高速缓存/共享内存和四个16K 32位寄存器。
- 32 GB HBM2 DRAM,900 GBps带宽
- NVLink 2.0(300 GBps)。
Nvidia图灵
- 2018年9月宣布。
- 台积电12nm FFN,754 mm 2芯片,186亿个晶体管。
- 260瓦TDP。
- 72个SM,每个SM包含:64个FP32内核和64个INT32内核,8个Tensor内核(4608 FP32内核,4608 INT32内核和576个TC)。
- 带有升压时钟的峰值性能:16.3 TFLOPs FP32、130.5 TFLOPs FP16、261 TFLOPs INT8、522 TFLOPs INT4。
- 24.5 MB片上存储器,介于6 MB L2高速缓存和256 KB SM寄存器文件之间。
- 1455 MHz基本时钟。
- 12个32位GDDR6内存,可提供672 GBps的聚合带宽。
- 2个NVLink x8链接,每个链接提供高达26 GBps的双向速度。
◆
精彩推荐
◆

推荐阅读
诺贝尔物理学奖出炉,三大天体物理学家获奖
美政府再将8家中国企业列入“黑名单”,海康、科大讯飞、旷视等做出回应
Python入门你要懂哪些?
如何保护你的Python代码(一)——现有加密方案
百度回应李彦宏卸任百度云执行董事;甲骨文拟增聘 2000 员工拓展云服务;PostgreSQL 12 正式发布 | 极客头条
真·上天!NASA招聘区块链"多功能复合型"人才, 欲保护飞行数据安全……
10 月全国程序员工资统计,一半以上的职位 5 个月没招到人!
【光说不练假把式】今天说一说Kubernetes 在有赞的实践

你点的每个“在看”,我都认真当成了喜欢
相关文章:

C++/C++11中头文件numeric的使用
<numeric>是C标准程序库中的一个头文件,定义了C STL标准中的基础性的数值算法(均为函数模板): (1)、accumulate: 以init为初值,对迭代器给出的值序列做累加,返回累加结果值,值类型必须支持””算符。它还有一个…
Spring基础16——使用FactoryBean来创建
1.配置bean的方式 配置bean有三种方式:通过全类名(class反射)、通过工厂方法(静态工厂&实例工厂)、通过FactoryBean。前面我们已经一起学习过全类名方式和工厂方法方式,下面通过这篇文章来学习一下Fact…

查看进程 端口
2019独角兽企业重金招聘Python工程师标准>>> 一 进程 ps -ef 1.UID 用户ID2.PID 进程ID3.PPID 父进程ID4.C CPU占用率5.STIME 开始时间6.TTY 开始此进程的TTY7.TIME 此进程运行的总时间8.CMD 命令名 二端口 netstat Linux下如果我…
深度学习中的欠拟合和过拟合简介
通常情况下,当我们训练机器学习模型时,我们可以使用某个训练集,在训练集上计算一些被称为训练误差(training error)的度量误差,目标是降低训练误差。机器学习和优化不同的地方在于,我们也希望泛化误差(generalization …

今日头条首次改进DQN网络,解决推荐中的在线广告投放问题
(图片付费下载自视觉中国)作者 | 深度传送门来源 | 深度传送门(ID:gh_5faae7b50fc5)【导读】本文主要介绍今日头条推出的强化学习应用在推荐的最新论文[1],首次改进DQN网络解决推荐中的在线广告投放问题。背景介绍随着…
RPA实施过程中可能会遇到的14个坑
RPA的实施过程并非如我们所想的那样,总是一帆风顺。碰坑,在所难免。但也不必为此过于惊慌,因为,我们已经帮你把RPA实施之路上的坑找了出来。RPA实施过程中,将会遇到哪些坑? 【不看全文大纲版】●组织层面&a…
Android问题汇总
2019独角兽企业重金招聘Python工程师标准>>> 1. Only the original thread that created a view hierarchy can touch its views 在初始化activity是需要下载图片,所以重新开启了一个线程,下载图片更新ui,此时就出现了上面的错误。…
深度学习中的验证集和超参数简介
大多数机器学习算法都有超参数,可以设置来控制算法行为。超参数的值不是通过学习算法本身学习出来的(尽管我们可以设计一个嵌套的学习过程,一个学习算法为另一个学习算法学出最优超参数)。在多项式回归示例中,有一个超参数:多项式…
自定义View合辑(8)-跳跃的小球(贝塞尔曲线)
为了加强对自定义 View 的认知以及开发能力,我计划这段时间陆续来完成几个难度从易到难的自定义 View,并简单的写几篇博客来进行介绍,所有的代码也都会开源,也希望读者能给个 star 哈 GitHub 地址:github.com/leavesC/…

分析Booking的150种机器学习模型,我总结了六条成功经验
(图片付费下载自视觉中国)作者 | Adrian Colyer译者 | Monanfei出品 | AI科技大本营(ID:rgznai100)本文是一篇有趣的论文(150 successful machine learning models: 6 lessons learned at Booking.com Bernadi et al.,…
Android官方提供的支持不同屏幕大小的全部方法
2019独角兽企业重金招聘Python工程师标准>>> 本文将告诉你如何让你的应用程序支持各种不同屏幕大小,主要通过以下几种办法: 让你的布局能充分的自适应屏幕根据屏幕的配置来加载合适的UI布局确保正确的布局应用在正确的设备屏幕上提供可以根据…
C++/C++11中头文件iterator的使用
<iterator>是C标准程序库中的一个头文件,定义了C STL标准中的一些迭代器模板类,这些类都是以std::iterator为基类派生出来的。迭代器提供对集合(容器)元素的操作能力。迭代器提供的基本操作就是访问和遍历。迭代器模拟了C中的指针,可以…

从多媒体技术演进看AI技术
(图片付费下载自视觉中国)文 / LiveVideoStack主编 包研在8月的LiveVideoStackCon2019北京开场致辞中,我分享了一组数据——把2019年和2017年两场LiveVideoStackCon上的AI相关的话题做了统计,这是数字从9.3%增长到31%,…
五. python的日历模块
一 .日历 import calendar# 日历模块# 使用# 返回指定某年某月的日历 print(calendar.month(2017,7))# July 2017 # Mo Tu We Th Fr Sa Su # 1 2 # 3 4 5 6 7 8 9 # 10 11 12 13 14 15 16 # 17 18 19 20 21 22 23 # 24 25 26 27 28 29 30 # 31# 返…
Linux下的Shell工作原理
为什么80%的码农都做不了架构师?>>> Linux系统提供给用户的最重要的系统程序是Shell命令语言解释程序。它不 属于内核部分,而是在核心之外,以用户态方式运行。其基本功能是解释并 执行用户打入的各种命令,实现用户与L…
C++/C++11中头文件functional的使用
<functional>是C标准库中的一个头文件,定义了C标准中多个用于表示函数对象(function object)的类模板,包括算法操作、比较操作、逻辑操作;以及用于绑定函数对象的实参值的绑定器(binder)。这些类模板的实例是具有函数调用运算符(functi…

飞天AI平台到底哪里与众不同?听听它的架构者怎么说
采访嘉宾 | 林伟 整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 天下没有不散的宴席。 9 月 25 日,云栖大会在云栖小镇开始,历经三天的技术盛宴,于 9 月 27 日的傍晚结束。 三天、全球6.7万人现场参会、超1250万人…
浅谈 sessionStorage、localStorage、cookie 的区别以及使用
1、sessionStorage、localStorage、cookie 之间的区别 相同点 cookie 和 webStorage 都是用来存储客户端的一些信息不同点 localStorage localStorage 的生命周期是 永久的。也就是说 只要不是 手动的去清除。localStorage 会一直存储 sessionStorage 相反 sessionStorage 的生…

任务栏窗口和状态图标的闪动 z
Demo程序: 实现任务栏窗体和图标的闪动: 整个程序是基于Windows Forms的,对于任务栏右下角状态图标的闪动,创建了一个类型:NotifyIconAnimator,基本上是包装了Windows Forms中的NotifyIcon类型,…

深度学习中的最大似然估计简介
统计领域为我们提供了很多工具来实现机器学习目标,不仅可以解决训练集上的任务,还可以泛化。例如参数估计、偏差和方差,对于正式地刻画泛化、欠拟合和过拟合都非常有帮助。点估计:点估计试图为一些感兴趣的量提供单个”最优”预测…
简单粗暴上手TensorFlow 2.0,北大学霸力作,必须人手一册!
(图片付费下载自视觉中国) 整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 【导读】 TensorFlow 2.0 于近期正式发布后,立即受到学术界与科研界的广泛关注与好评。此前,AI 科技大本营曾特邀专家回顾了 Te…

常见运维漏洞-Rsync-Redis
转载于:https://blog.51cto.com/10945453/2394651

zabbix笔记
(1)转载于:https://blog.51cto.com/zlong37/1406441
C++/C++11中头文件algorithm的使用
<algorithm>是C标准程序库中的一个头文件,定义了C STL标准中的基础性的算法(均为函数模板)。<algorithm>定义了设计用于元素范围的函数集合。任何对象序列的范围可以通过迭代器或指针访问。 std::adjacent_find:在序列中查找第一对相邻且值…
js filter 用法
filter filter函数可以看成是一个过滤函数,返回符合条件的元素的数组 filter需要在循环的时候判断一下是true还是false,是true才会返回这个元素; filter()接收的回调函数,其实可以有多个参数。通常我们仅使用第一个参数ÿ…

每30秒学会一个Python小技巧,GitHub星数4600+
(图片付费下载自视觉中国)作者 | xiaoyu,数据爱好者来源 | Python数据科学(ID:PyDataScience)很多学习Python的朋友在项目实战中会遇到不少功能实现上的问题,有些问题并不是很难的问题,或者已经…
Nginx自定义模块编写:根据post参数路由到不同服务器
Nginx可以轻松实现根据不同的url 或者 get参数来转发到不同的服务器,然而当我们需要根据http包体来进行请求路由时,Nginx默认的配置规则就捉襟见肘了,但是没关系,Nginx提供了强大的自定义模块功能,我们只要进行需要的扩…
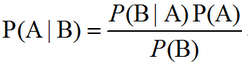
深度学习中的贝叶斯统计简介
贝叶斯用概率反映知识状态的确定性程度。数据集能够被直接观测到,因此不是随机的。另一方面,真实参数θ是未知或不确定的,因此可以表示成随机变量。在观察到数据前,我们将θ的已知知识表示成先验概率分布(prior probability distr…

少走弯路:强烈推荐的TensorFlow快速入门资料(可下载)
(图片付费下载自视觉中国)作者 | 黄海广来源 | 机器学习初学者(ID: ai-start-com)知识更新非常快,需要一直学习才能跟上时代进步,举个例子:吴恩达老师在深度学习课上讲的TensorFlow使用…
有状态bean与无状态bean
在学习bean的作用域的时候,了解了这个问题。 bean5种作用域:分别是:singleton、prototype、request、session、gloabal session 接下来就讲一下有状态bean与无状态bean: 有状态会话bean :每个用户有自己特有的一个实例…