线性回归介绍及分别使用最小二乘法和梯度下降法对线性回归C++实现
回归:在这类任务中,计算机程序需要对给定输入预测数值。为了解决这个任务,学习算法需要输出函数f:Rn→R。除了返回结果的形式不一样外,这类问题和分类问题是很像的。这类任务的一个示例是预测投保人的索赔金额(用于设置保险费),或者预测证券未来的价格。这类预测也用在算法交易中。
线性回归解决回归问题。换言之,我们的目标是建立一个系统,将向量x∈Rn作为输入,预测标量y∈R作为输出。线性回归的输出是其输入的线性函数。另y’表示模型预测y应该取的值。我们定义输出为:y’=wTx, 其中w∈Rn的参数(parameter)向量。
参数是控制系统行为的值。在这种情况下,wi是系数,会和特征xi相乘之后全部相加起来。我们可以将w看作是一组决定每个特征如何影响预测的权重(weight)。如果特征xi对应的权重wi是正的,那么特征的值增加,我们的预测值y’也会增加。如果特征xi对应的权重wi是负的,那么特征的值减少,我们的预测值y’也会减少。如果特征权重的大小很大,那么它对预测有很大的影响;如果特征权重的大小是零,那么它对预测没有影响。
因此,我们可以定义任务T:通过输出y’=wTx从x预测y。接下来我们需要定义性能度量P。
假设我们有m个输入样本组成的设计矩阵,我们不用它来训练模型,而是评估模型性能如何。我们也有每个样本对应的正确值y组成的回归目标向量。因为这个数据集只是用来评估性能,我们称之为测试集(test set)。我们将输入的设计矩阵记作X(test),回归目标向量记作y(test)。
度量模型性能的一种方法是计算模型在测试集上的均方误差(mean squared error)。如果y’(test)表示模型在测试集上的预测值,那么均方误差表示为:
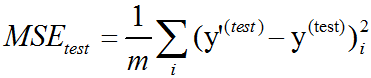
直观上,当y’(test)=y(test)时,我们会发现误差降为0。我们也可以看到:
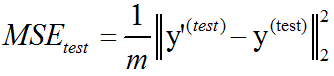
所以当预测值和目标值之间的欧几里得距离增加时,误差也会增加。
为了构建一个机器学习算法,我们需要设计一个算法,通过观察训练集(X(train),y(train))获得经验,减少MSEtest以改进权重w。一种直观方式是最小化训练集上的均方误差,即MSEtrain。
最小化MSEtrain,我们可以简单地求解其导数为0的情况:▽wMSEtrain=0
=> w=(X(train)TX(train))-1X(train)Ty(train)
上式给出解的系统方程被称为正规方程(normal equation)。计算上式构成了一个简单的机器学习算法。
线性回归(linear regression)通常用来指稍微复杂一些,附加额外参数(截距项b)的模型。在这个模型中,y’=wTx+b。因此从参数到预测的映射仍是一个线性函数,而从特征到预测的映射是一个仿射函数。如此扩展到仿射函数意味着模型预测的曲线仍然看起来像是一条直线,只是这条直线没必要经过原点。除了通过添加偏置参数b,我们还可以使用仅含权重的模型,但是x需要增加一项永远为1的元素。对应于额外1的权重起到了偏置参数的作用。
截距项b通常被称为仿射变换的偏置(bias)参数。这个术语的命名源自该变换的输出在没有任何输入时会偏移b。
在统计学中,线性回归(linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量的情况叫多元回归。
在线性回归中,数据使用线性预测函数来建模,并且未知的模型参数也是通过数据来估计。这些模型被叫做线性模型。
线性回归是回归分析中第一种经过严格研究并在实际应用中广泛使用的类型。这是因为线性依赖于其未知参数的模型比非线性依赖于其位置参数的模型更容易拟合,而且产生的估计的统计特性也更容易确定。
线性回归有很多实际用途。分为以下两大类:
(1)、如果目标是预测或者映射,线性回归可以用来对观测数据集和X的值拟合出一个预测模型。当完成这样一个模型以后,对于一个新增的X值,在没有给定与它相配对的y的情况下,可以用这个拟合过的模型预测出一个y值。
(2)、给定一个变量y和一些变量X1,...,Xp,这些变量有可能与y相关,线性回归分析可以用来量化y与Xj之间相关性的强度,评估出与y不相关的Xj,并识别出哪些Xj的子集包含了关于y的冗余信息。
线性回归模型经常用最小二乘逼近来拟合,但也可用别的方法来拟合。最小二乘逼近也可以用来拟合那些非线性的模型。因此,尽管”最小二乘法”和”线性模型”是紧密相连的,但他们是不能划等号的。
理论模型:给一个随机样本(Yi,Xi1,…,Xip),i=1,…,n,一个线性回归模型假设回归子Yi和回归量Xi1,…,Xip之间的关系是除了X的影响以外,还有其它的变数存在。我们加入一个误差项εi(也是一个随机变量)来捕获除了Xi1,…,Xip之外任何对Yi的影响。所以一个多变量回归模型表示为以下的形式:
Yi=β0+β1Xi1+β2Xi2+…+βpXip+εi,i=1,…,n.
其它的模型可能被认定成非线性模型。一个线性回归模型不需要是自变量的线性函数。线性在这里表示Yi的条件均值在参数β里是线性的。例如:模型Yi=β1Xi+β2Xi2+εi在β1和β2里是线性的,但在Xi2里是非线性的,它是Xi的非线性函数。
数据和估计:区分随机变量和这些变量的观测值是很重要的。通常来说,观测值或数据包括了n个值(yi,xi1,…,xip),i=1,…,n. 我们有p+1个参数β0,…, βp需要决定,为了估计这些参数,使用矩阵标记:Y=Xβ+ε.其中Y是一个包括了观测值Y1,…,Yn的列向量,ε包括了未观测的随机成分ε1,…, εn以及回归量的观测值矩阵X。X通常包括一个常数项。如果X列之间存在线性相关,那么参数向量β就不能以最小二乘法估计除非β被限制,比如要求它的一些元素之和为0。
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
以上内容主要摘自: 《深度学习中文版》 和 维基百科
以下是参考网上一些code分别通过最小二乘法和梯度下降法实现的线性回归C++测试代码:
linear_regression.hpp:
#ifndef NN_LINEAR_REGRESSION_HPP_
#define NN_LINEAR_REGRESSION_HPP_#include <memory>
#include <string>
#include <ostream>namespace ANN {typedef enum {LEAST_SQUARES = 0,GRADIENT_DESCENT
} regression_method;template<typename T>
class LinearRegression {template<typename U>friend std::ostream& operator << (std::ostream& out, const LinearRegression<U>& lr);public:LinearRegression() = default;void set_regression_method(regression_method method);int init(const T* x, const T* y, int length);int train(const std::string& model, T learning_rate = 0, int iterations = 0);int load_model(const std::string& model) const;T predict(T x) const; // y = wx+bprivate:int gradient_descent();int least_squares();int store_model() const;regression_method method;std::unique_ptr<T[]> x, y;std::string model = "";int iterations = 1000;int length = 0;T learning_rate = 0.001f;T weight = 0;T bias = 0;
};} // namespace ANN#endif // NN_LINEAR_REGRESSION_HPP_#include "linear_regression.hpp"
#include <fstream>
#include <random>
#include <algorithm>
#include <numeric>namespace ANN {template<typename T>
void LinearRegression<T>::set_regression_method(regression_method method)
{this->method = method;
}template<typename T>
int LinearRegression<T>::init(const T* x, const T* y, int length)
{if (length < 3) {fprintf(stderr, "number of points must be greater than 2: %d\n", length);return -1;}this->x.reset(new T[length]);this->y.reset(new T[length]);for (int i = 0; i < length; ++i) {this->x[i] = x[i];this->y[i] = y[i];}this->length = length;return 0;
}template<typename T>
int LinearRegression<T>::train(const std::string& model, T learning_rate, int iterations)
{this->learning_rate = learning_rate;this->iterations = iterations;this->model = model;if (this->method == LEAST_SQUARES) {least_squares();} else if (this->method == GRADIENT_DESCENT) {gradient_descent();} else {fprintf(stderr, "invalid linear regression method\n");return -1;}return store_model();
}template<typename T>
int LinearRegression<T>::store_model() const
{std::ofstream file;file.open(model.c_str(), std::ios::binary);if (!file.is_open()) {fprintf(stderr, "open file fail: %s\n", model.c_str());return -1;}int m = method;file.write((char*)&m, sizeof(m));file.write((char*)&weight, sizeof(weight));file.write((char*)&bias, sizeof(bias));file.close();return 0;
}template<typename T>
int LinearRegression<T>::load_model(const std::string& model) const
{std::ifstream file;file.open(model.c_str(), std::ios::binary);if (!file.is_open()) {fprintf(stderr, "open file fail: %s\n", model.c_str());return -1;}int m{ -1 };file.read((char*)&m, sizeof(m)* 1);file.read((char*)&weight, sizeof(weight)* 1);file.read((char*)&bias, sizeof(bias)* 1);file.close();return 0;
}template<typename T>
T LinearRegression<T>::predict(T x) const
{return weight * x + bias;
}template<typename T>
int LinearRegression<T>::gradient_descent()
{std::random_device rd; std::mt19937 generator(rd());std::uniform_real_distribution<T> distribution(0, 0.5);weight = distribution(generator);;bias = distribution(generator);;int count{ 0 };std::unique_ptr<T[]> error(new T[length]), error_x(new T[length]);for (int i = 0; i < iterations; ++i) {for (int j = 0; j < length; ++j) {error[j] = weight * x[j] + bias - y[j];error_x[j] = error[j] * x[j];}T error_ = std::accumulate(error.get(), error.get() + length, (T)0) / length;T error_x_ = std::accumulate(error_x.get(), error_x.get() + length, (T)0) / length;// error = p(i) - y(i)// bias(i+1) = bias(i) - learning_rate*errorbias = bias - learning_rate * error_;// weight(i+1) = weight(i) - learning_rate*error*xweight = weight - learning_rate * error_x_;++count;if (count % 100 == 0)fprintf(stdout, "iteration %d\n", count);}return 0;
}template<typename T>
int LinearRegression<T>::least_squares()
{T sum_x{ 0 }, sum_y{ 0 }, sum_x_squared{ 0 }, sum_xy{ 0 };for (int i = 0; i < length; ++i) {sum_x += x[i];sum_y += y[i];sum_x_squared += x[i] * x[i];sum_xy += x[i] * y[i];}if (fabs(length * sum_x_squared - sum_x * sum_x) > DBL_EPSILON) {weight = (length * sum_xy - sum_y * sum_x) / (length * sum_x_squared - sum_x * sum_x); // slopebias = (sum_x_squared * sum_y - sum_x * sum_xy) / (length * sum_x_squared - sum_x * sum_x); // intercept} else {weight = 0;bias = 0;}return 0;
}template<typename T>
std::ostream& operator << (std::ostream& out, const LinearRegression<T>& lr)
{out << "result: y = " << lr.weight << "x + " << lr.bias;return out;
}template std::ostream& operator << (std::ostream& out, const LinearRegression<float>& lr);
template std::ostream& operator << (std::ostream& out, const LinearRegression<double>& lr);
template class LinearRegression<float>;
template class LinearRegression<double>;} // namespace ANN#include "funset.hpp"
#include <iostream>
#include "perceptron.hpp"
#include "BP.hpp""
#include "CNN.hpp"
#include "linear_regression.hpp"
#include "common.hpp"
#include <opencv2/opencv.hpp>int test_linear_regression_train()
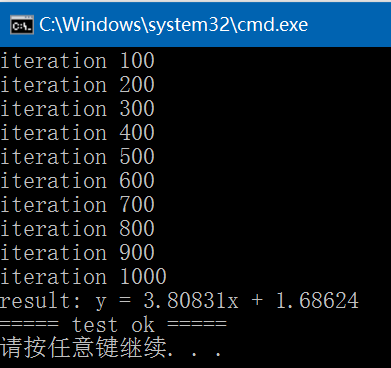
{std::vector<float> x{6.2f, 9.5f, 10.5f, 7.7f, 8.6f, 6.9f, 7.3f, 2.2f, 5.7f, 2.f,2.5f, 4.f, 5.4f, 2.2f, 7.2f, 12.2f, 5.6f, 9.f, 3.6f, 5.f,11.3f, 3.4f, 11.9f, 10.5f, 10.7f, 10.8f, 4.8f};std::vector<float> y{ 29.f, 44.f, 36.f, 37.f, 53.f, 18.f, 31.f, 14.f, 11.f, 11.f,22.f, 16.f, 27.f, 9.f, 29.f, 46.f, 23.f, 39.f, 15.f, 32.f,34.f, 17.f, 46.f, 42.f, 43.f, 34.f, 19.f };CHECK(x.size() == y.size());ANN::LinearRegression<float> lr;lr.set_regression_method(ANN::GRADIENT_DESCENT);lr.init(x.data(), y.data(), x.size());float learning_rate{ 0.001f };int iterations{ 1000 };std::string model{ "E:/GitCode/NN_Test/data/linear_regression.model" };int ret = lr.train(model, learning_rate, iterations);if (ret != 0) {fprintf(stderr, "train fail\n");return -1;}std::cout << lr << std::endl; // y = wx + breturn 0;
}
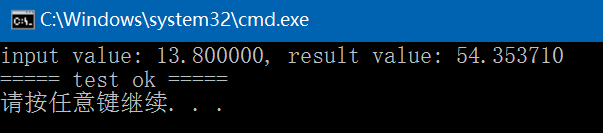
int test_linear_regression_predict()
{ANN::LinearRegression<float> lr;std::string model{ "E:/GitCode/NN_Test/data/linear_regression.model" };int ret = lr.load_model(model);if (ret != 0) {fprintf(stderr, "load model fail: %s\n", model.c_str());return -1;}float x = 13.8f;float result = lr.predict(x);fprintf(stdout, "input value: %f, result value: %f\n", x, result);return 0;
}
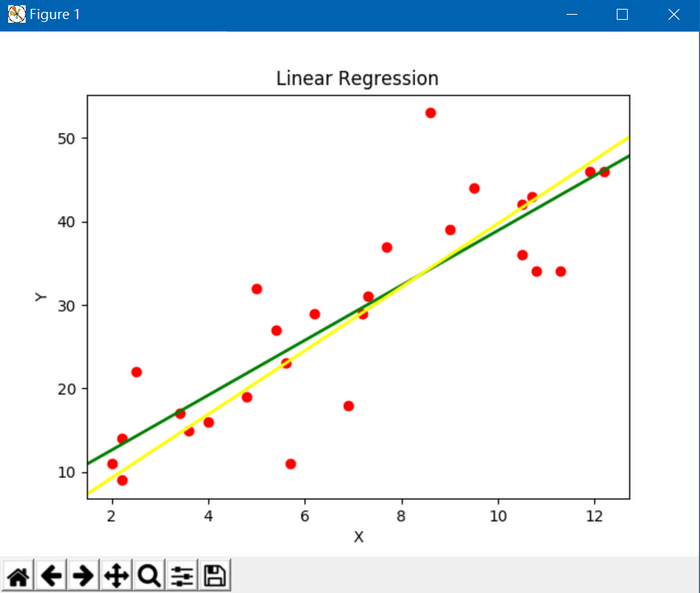
以下是通过Python实现的画曲线图:黄线是梯度下降法的结果,绿线是最小二乘法的结果
Python代码如下:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.lines import Line2Dx = [6.2, 9.5, 10.5, 7.7, 8.6, 6.9, 7.3, 2.2, 5.7, 2.,2.5, 4., 5.4, 2.2, 7.2, 12.2, 5.6, 9., 3.6, 5.,11.3, 3.4, 11.9, 10.5, 10.7, 10.8, 4.8]
y = [29., 44., 36., 37., 53., 18., 31., 14., 11., 11.,22., 16., 27., 9., 29., 46., 23., 39., 15., 32.,34., 17., 46., 42., 43., 34., 19.]fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title('Linear Regression')
plt.xlabel('X')
plt.ylabel('Y')
ax.scatter(x,y,c = 'r',marker = 'o')line1 = [(0.0, 6.0506), (40, 137.5202)] # least squares
line2 = [(0, 1.68624), (40, 154.01864)] # gradient descent(line1_xs, line1_ys) = zip(*line1)
(line2_xs, line2_ys) = zip(*line2)ax.add_line(Line2D(line1_xs, line1_ys, linewidth=2, color='green')) # least squares
ax.add_line(Line2D(line2_xs, line2_ys, linewidth=2, color='yellow')) # gradient descentplt.show()GitHub: https://github.com/fengbingchun/NN_Test
相关文章:
4种最常问的编码算法面试问题,你会吗?
导语:面试是测查和评价人员能力素质的一种考试活动。最常问的编码算法面试问题你知道多少呢?作者 | Rahul Sabnis译者 | 苏本如,编辑 | 刘静来源 | CSDN(ID:CSDNnews)在许多采访中,我经常被要求…

[小梅的体验课堂]Microsoft edge canary mac版本体验
简介 华硕微软越来越没有自己的JC了,不经在windows里面加了wsl而且还废弃了自己的老edge浏览器,重新基于chromium内核开发了新的edge浏览器了,不管怎么说mac上又多了一款新的浏览器,对于一个爱好新鲜的我来说那就简单安装体验下 下…
SQL Server用户自定义函数
用户自定义函数不能用于执行一系列改变数据库状态的操作,但它可以像系统 函数一样在查询或存储过程等的程序段中使用,也可以像存储过程一样通过EXECUTE 命令来执行。在 SQL Server 中根据函数返回值形式的不同将用户自 定义函数分为三种类型:…
C++11中std::initializer_list的使用
initializer_list是一种标准库类型,用于表示某种特定类型的值的数组。和vector一样,initializer_list也是一种模板类型,定义initializer_list对象时,必须说明列表中所含元素的类型。和vector不一样的是,initializer_li…

WijmoJS 2019V1正式发布:全新的在线 Demo 系统,助您快速上手,开发无忧
2019独角兽企业重金招聘Python工程师标准>>> 下载WijmoJS 2019 v1 WijmoJS是为企业应用程序开发而推出的一系列包含HTML5和JavaScript的开发控件。其中包含了金融图表、FlexSheet、先进的JavaScript控件(Wijmo 5)和经典的jQuery小部件&#x…

最后3天,BDTC 2019早鸟票即将售罄,超强阵容及议题抢先曝光!
大会官网:https://t.csdnimg.cn/U1wA2019 年12月5-7 日,由中国计算机学会主办,CCF 大数据专家委员会承办,CSDN、中科天玑数据科技股份有限公司协办的 2019 中国大数据技术大会,将于北京长城饭店隆重举行。届时…
php_mongo.dll下载(php操作mongoDB需要)
php_mongo.dll下载(php操作mongoDB需要)如果PHP连接操作mongoDB就必须要加入此扩展:php_mongo.dll,放到你对应php的扩展目录在你的php.ini中加入:extensionphp_mongo.dll重启apache,在phpinfo()中查看是否有…

十大机器智能新型芯片:华为抢占一席,Google占比最多
(图片付费下载自视觉中国)整理 | 胡巍巍来源 | CSDN(ID:CSDNnews)当年,阿基米德爷爷说出“给我一个支点,我就能撬动地球”这句话时,估计没少遭受嘲讽。然而后来的我们,都…
C++/C++11中头文件numeric的使用
<numeric>是C标准程序库中的一个头文件,定义了C STL标准中的基础性的数值算法(均为函数模板): (1)、accumulate: 以init为初值,对迭代器给出的值序列做累加,返回累加结果值,值类型必须支持””算符。它还有一个…
Spring基础16——使用FactoryBean来创建
1.配置bean的方式 配置bean有三种方式:通过全类名(class反射)、通过工厂方法(静态工厂&实例工厂)、通过FactoryBean。前面我们已经一起学习过全类名方式和工厂方法方式,下面通过这篇文章来学习一下Fact…
查看进程 端口
2019独角兽企业重金招聘Python工程师标准>>> 一 进程 ps -ef 1.UID 用户ID2.PID 进程ID3.PPID 父进程ID4.C CPU占用率5.STIME 开始时间6.TTY 开始此进程的TTY7.TIME 此进程运行的总时间8.CMD 命令名 二端口 netstat Linux下如果我…
深度学习中的欠拟合和过拟合简介
通常情况下,当我们训练机器学习模型时,我们可以使用某个训练集,在训练集上计算一些被称为训练误差(training error)的度量误差,目标是降低训练误差。机器学习和优化不同的地方在于,我们也希望泛化误差(generalization …

今日头条首次改进DQN网络,解决推荐中的在线广告投放问题
(图片付费下载自视觉中国)作者 | 深度传送门来源 | 深度传送门(ID:gh_5faae7b50fc5)【导读】本文主要介绍今日头条推出的强化学习应用在推荐的最新论文[1],首次改进DQN网络解决推荐中的在线广告投放问题。背景介绍随着…
RPA实施过程中可能会遇到的14个坑
RPA的实施过程并非如我们所想的那样,总是一帆风顺。碰坑,在所难免。但也不必为此过于惊慌,因为,我们已经帮你把RPA实施之路上的坑找了出来。RPA实施过程中,将会遇到哪些坑? 【不看全文大纲版】●组织层面&a…
Android问题汇总
2019独角兽企业重金招聘Python工程师标准>>> 1. Only the original thread that created a view hierarchy can touch its views 在初始化activity是需要下载图片,所以重新开启了一个线程,下载图片更新ui,此时就出现了上面的错误。…
深度学习中的验证集和超参数简介
大多数机器学习算法都有超参数,可以设置来控制算法行为。超参数的值不是通过学习算法本身学习出来的(尽管我们可以设计一个嵌套的学习过程,一个学习算法为另一个学习算法学出最优超参数)。在多项式回归示例中,有一个超参数:多项式…
自定义View合辑(8)-跳跃的小球(贝塞尔曲线)
为了加强对自定义 View 的认知以及开发能力,我计划这段时间陆续来完成几个难度从易到难的自定义 View,并简单的写几篇博客来进行介绍,所有的代码也都会开源,也希望读者能给个 star 哈 GitHub 地址:github.com/leavesC/…

分析Booking的150种机器学习模型,我总结了六条成功经验
(图片付费下载自视觉中国)作者 | Adrian Colyer译者 | Monanfei出品 | AI科技大本营(ID:rgznai100)本文是一篇有趣的论文(150 successful machine learning models: 6 lessons learned at Booking.com Bernadi et al.,…
Android官方提供的支持不同屏幕大小的全部方法
2019独角兽企业重金招聘Python工程师标准>>> 本文将告诉你如何让你的应用程序支持各种不同屏幕大小,主要通过以下几种办法: 让你的布局能充分的自适应屏幕根据屏幕的配置来加载合适的UI布局确保正确的布局应用在正确的设备屏幕上提供可以根据…
C++/C++11中头文件iterator的使用
<iterator>是C标准程序库中的一个头文件,定义了C STL标准中的一些迭代器模板类,这些类都是以std::iterator为基类派生出来的。迭代器提供对集合(容器)元素的操作能力。迭代器提供的基本操作就是访问和遍历。迭代器模拟了C中的指针,可以…

从多媒体技术演进看AI技术
(图片付费下载自视觉中国)文 / LiveVideoStack主编 包研在8月的LiveVideoStackCon2019北京开场致辞中,我分享了一组数据——把2019年和2017年两场LiveVideoStackCon上的AI相关的话题做了统计,这是数字从9.3%增长到31%,…
五. python的日历模块
一 .日历 import calendar# 日历模块# 使用# 返回指定某年某月的日历 print(calendar.month(2017,7))# July 2017 # Mo Tu We Th Fr Sa Su # 1 2 # 3 4 5 6 7 8 9 # 10 11 12 13 14 15 16 # 17 18 19 20 21 22 23 # 24 25 26 27 28 29 30 # 31# 返…
Linux下的Shell工作原理
为什么80%的码农都做不了架构师?>>> Linux系统提供给用户的最重要的系统程序是Shell命令语言解释程序。它不 属于内核部分,而是在核心之外,以用户态方式运行。其基本功能是解释并 执行用户打入的各种命令,实现用户与L…
C++/C++11中头文件functional的使用
<functional>是C标准库中的一个头文件,定义了C标准中多个用于表示函数对象(function object)的类模板,包括算法操作、比较操作、逻辑操作;以及用于绑定函数对象的实参值的绑定器(binder)。这些类模板的实例是具有函数调用运算符(functi…

飞天AI平台到底哪里与众不同?听听它的架构者怎么说
采访嘉宾 | 林伟 整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 天下没有不散的宴席。 9 月 25 日,云栖大会在云栖小镇开始,历经三天的技术盛宴,于 9 月 27 日的傍晚结束。 三天、全球6.7万人现场参会、超1250万人…
浅谈 sessionStorage、localStorage、cookie 的区别以及使用
1、sessionStorage、localStorage、cookie 之间的区别 相同点 cookie 和 webStorage 都是用来存储客户端的一些信息不同点 localStorage localStorage 的生命周期是 永久的。也就是说 只要不是 手动的去清除。localStorage 会一直存储 sessionStorage 相反 sessionStorage 的生…

任务栏窗口和状态图标的闪动 z
Demo程序: 实现任务栏窗体和图标的闪动: 整个程序是基于Windows Forms的,对于任务栏右下角状态图标的闪动,创建了一个类型:NotifyIconAnimator,基本上是包装了Windows Forms中的NotifyIcon类型,…

深度学习中的最大似然估计简介
统计领域为我们提供了很多工具来实现机器学习目标,不仅可以解决训练集上的任务,还可以泛化。例如参数估计、偏差和方差,对于正式地刻画泛化、欠拟合和过拟合都非常有帮助。点估计:点估计试图为一些感兴趣的量提供单个”最优”预测…
简单粗暴上手TensorFlow 2.0,北大学霸力作,必须人手一册!
(图片付费下载自视觉中国) 整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 【导读】 TensorFlow 2.0 于近期正式发布后,立即受到学术界与科研界的广泛关注与好评。此前,AI 科技大本营曾特邀专家回顾了 Te…

常见运维漏洞-Rsync-Redis
转载于:https://blog.51cto.com/10945453/2394651