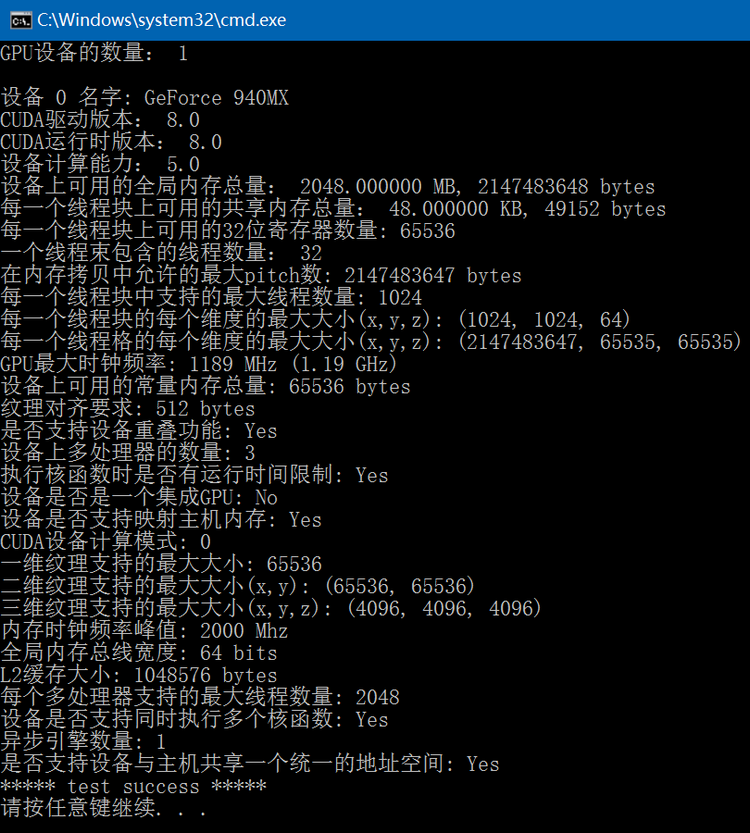
CUDA Samples: 获取设备属性信息
通过调用CUDA的cudaGetDeviceProperties函数可以获得指定设备的相关信息,此函数会根据GPU显卡和CUDA版本的不同得到的结果也有所差异,下面code列出了经常用到的设备信息:
#include "funset.hpp"
#include <iostream>
#include <cuda_runtime.h> // For the CUDA runtime routines (prefixed with "cuda_")
#include <device_launch_parameters.h>/* reference:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\1_Utilities\deviceQuery
*/
int get_device_info()
{int device_count{ 0 };// cudaGetDeviceCount: 获得计算能力设备的数量cudaGetDeviceCount(&device_count);fprintf(stdout, "GPU设备的数量: %d\n", device_count);for (int dev = 0; dev < device_count; ++dev) {int driver_version{ 0 }, runtime_version{ 0 };/* cudaSetDevice: 设置GPU执行时使用的设备,0表示能搜索到的第一个设备号,如果有多个设备,则编号为0,1,2... */cudaSetDevice(dev);/* cudaDeviceProp: 设备属性结构体name: 设备名字,如GeForce 940MXtotalGlobalMem: 设备上可用的全局内存总量(字节)sharedMemPerBlock: 每一个线程块上可用的共享内存总量(字节)regsPerBlock: 每一个线程块上可用的32位寄存器数量warpSize: 一个线程束包含的线程数量,在实际运行中,线程块会被分割成更小的线程束(warp),线程束中的每个线程都将在不同数据上执行相同的命令memPitch: 在内存拷贝中允许的最大pitch数(字节)maxThreadsPerBlock: 每一个线程块中支持的最大线程数量maxThreadsDim[3]: 每一个线程块的每个维度的最大大小(x,y,z)maxGridSize: 每一个线程格的每个维度的最大大小(x,y,z)clockRate: GPU最大时钟频率(千赫兹)totalConstMem: 设备上可用的常量内存总量(字节)major: 设备计算能力主版本号,设备计算能力的版本描述了一种GPU对CUDA功能的支持程度minor: 设备计算能力次版本号textureAlignment: 纹理对齐要求deviceOverlap: GPU是否支持设备重叠(Device Overlap)功能,支持设备重叠功能的GPU能够在执行一个CUDA C核函数的同时,还能在设备与主机之间执行复制等操作,已废弃,使用asyncEngineCount代替multiProcessorCount: 设备上多处理器的数量kernelExecTimeoutEnabled: 指定执行核函数时是否有运行时间限制integrated: 设备是否是一个集成GPUcanMapHostMemory: 设备是否支持映射主机内存,可作为是否支持零拷贝内存的判断条件computeMode: CUDA设备计算模式,可参考cudaComputeModemaxTexture1D: 一维纹理支持的最大大小maxTexture2D[2]:二维纹理支持的最大大小(x,y)maxTexture3D[3]: 三维纹理支持的最大大小(x,y,z)memoryClockRate: 内存时钟频率峰值(千赫兹)memoryBusWidth: 全局内存总线宽度(bits)l2CacheSize: L2缓存大小(字节)maxThreadsPerMultiProcessor: 每个多处理器支持的最大线程数量concurrentKernels: 设备是否支持同时执行多个核函数asyncEngineCount: 异步引擎数量unifiedAddressing: 是否支持设备与主机共享一个统一的地址空间*/cudaDeviceProp device_prop;/* cudaGetDeviceProperties: 获取指定的GPU设备属性相关信息 */cudaGetDeviceProperties(&device_prop, dev);fprintf(stdout, "\n设备 %d 名字: %s\n", dev, device_prop.name);/* cudaDriverGetVersion: 获取CUDA驱动版本 */cudaDriverGetVersion(&driver_version);fprintf(stdout, "CUDA驱动版本: %d.%d\n", driver_version/1000, (driver_version%1000)/10);/* cudaRuntimeGetVersion: 获取CUDA运行时版本 */cudaRuntimeGetVersion(&runtime_version);fprintf(stdout, "CUDA运行时版本: %d.%d\n", runtime_version/1000, (runtime_version%1000)/10);fprintf(stdout, "设备计算能力: %d.%d\n", device_prop.major, device_prop.minor);fprintf(stdout, "设备上可用的全局内存总量: %f MB, %llu bytes\n",(float)device_prop.totalGlobalMem / (1024 * 1024), (unsigned long long)device_prop.totalGlobalMem);fprintf(stdout, "每一个线程块上可用的共享内存总量: %f KB, %lu bytes\n",(float)device_prop.sharedMemPerBlock / 1024, device_prop.sharedMemPerBlock);fprintf(stdout, "每一个线程块上可用的32位寄存器数量: %d\n", device_prop.regsPerBlock);fprintf(stdout, "一个线程束包含的线程数量: %d\n", device_prop.warpSize);fprintf(stdout, "在内存拷贝中允许的最大pitch数: %d bytes\n", device_prop.memPitch);fprintf(stdout, "每一个线程块中支持的最大线程数量: %d\n", device_prop.maxThreadsPerBlock);fprintf(stdout, "每一个线程块的每个维度的最大大小(x,y,z): (%d, %d, %d)\n",device_prop.maxThreadsDim[0], device_prop.maxThreadsDim[1], device_prop.maxThreadsDim[2]);fprintf(stdout, "每一个线程格的每个维度的最大大小(x,y,z): (%d, %d, %d)\n",device_prop.maxGridSize[0], device_prop.maxGridSize[1], device_prop.maxGridSize[2]);fprintf(stdout, "GPU最大时钟频率: %.0f MHz (%0.2f GHz)\n",device_prop.clockRate*1e-3f, device_prop.clockRate*1e-6f);fprintf(stdout, "设备上可用的常量内存总量: %lu bytes\n", device_prop.totalConstMem);fprintf(stdout, "纹理对齐要求: %lu bytes\n", device_prop.textureAlignment);fprintf(stdout, "是否支持设备重叠功能: %s\n", device_prop.deviceOverlap ? "Yes" : "No");fprintf(stdout, "设备上多处理器的数量: %d\n", device_prop.multiProcessorCount);fprintf(stdout, "执行核函数时是否有运行时间限制: %s\n", device_prop.kernelExecTimeoutEnabled ? "Yes" : "No");fprintf(stdout, "设备是否是一个集成GPU: %s\n", device_prop.integrated ? "Yes" : "No");fprintf(stdout, "设备是否支持映射主机内存: %s\n", device_prop.canMapHostMemory ? "Yes" : "No");fprintf(stdout, "CUDA设备计算模式: %d\n", device_prop.computeMode);fprintf(stdout, "一维纹理支持的最大大小: %d\n", device_prop.maxTexture1D);fprintf(stdout, "二维纹理支持的最大大小(x,y): (%d, %d)\n", device_prop.maxTexture2D[0], device_prop.maxSurface2D[1]);fprintf(stdout, "三维纹理支持的最大大小(x,y,z): (%d, %d, %d)\n",device_prop.maxTexture3D[0], device_prop.maxSurface3D[1], device_prop.maxSurface3D[2]);fprintf(stdout, "内存时钟频率峰值: %.0f Mhz\n", device_prop.memoryClockRate * 1e-3f);fprintf(stdout, "全局内存总线宽度: %d bits\n", device_prop.memoryBusWidth);fprintf(stdout, "L2缓存大小: %d bytes\n", device_prop.l2CacheSize);fprintf(stdout, "每个多处理器支持的最大线程数量: %d\n", device_prop.maxThreadsPerMultiProcessor);fprintf(stdout, "设备是否支持同时执行多个核函数: %s\n", device_prop.concurrentKernels ? "Yes" : "No");fprintf(stdout, "异步引擎数量: %d\n", device_prop.asyncEngineCount);fprintf(stdout, "是否支持设备与主机共享一个统一的地址空间: %s\n", device_prop.unifiedAddressing ? "Yes" : "No");}return 0;
}
GitHub:https://github.com/fengbingchun/CUDA_Test
相关文章:

apache代理模块proxy使用
1、安装proxy模块[rootlocalhost modules]# cd /usr/local/src/httpd-2.2.16 [rootlocalhost httpd-2.2.16]# cd modules [rootlocalhost modules]# ls aaa config5.m4 debug filters ldap Makefile.in NWGNUmakefile ssl arch database echo …

CUDA Samples: image normalize(mean/standard deviation)
以下CUDA sample是分别用C和CUDA实现的通过均值和标准差对图像进行类似归一化的操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:关于均值和标准差的计算公式可参考: http://blog.csdn.net/fengbingchun/article/detai…

中文预训练ALBERT模型来了:小模型登顶GLUE,Base版模型小10倍、速度快1倍
(图片由AI科技大本营付费下载自视觉中国)作者 | 徐亮(实在智能算法专家) 来源 | AINLP(ID:nlpjob)谷歌ALBERT论文刚刚出炉一周,中文预训练ALBERT模型来了,感兴趣的同学可以直接尝鲜试…
树莓派安装go
简介 大学的时候在使用openfalcon的时候讲过这个东西,但是那时候是介绍open-falcon的,所以感觉不是很具体,所以今天在安装frp的时候也碰到了这个问题,我就具体的说下 安装go1.4 编译最新版本的go的时候一定要先编译安装go1.4&…
设计模式中的原则
设计模式(详情click)这个术语是由Erich Gamma等人在1990年代从建筑设计领域引入到计算机科学的。它是对软件设计中普遍存在(反复出现)的各种问题,所提出的解决方案。 设计模式并不直接用来完成代码的编写,而是描述在各种不同情况下…

CUDA Samples: approximate image reverse
以下CUDA sample是分别用C和CUDA实现的对图像进行某种类似reverse的操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CUDA_TEST_COMMON_HPP_ #define FBC_CUDA_TEST_COMMON_HPP_#include<random> #i…

超详细支持向量机知识点,面试官会问的都在这里了
(图片付费下载自视觉中国)作者 | 韦伟来源 | 知乎导语:持续准备面试中,准备的过程中,慢慢发现,如果死记硬背的话很难,可当推导一遍并且细细研究里面的缘由的话,面试起来应该什么都不…
vue-router点击切换路由报错
报错: 报错原因: 设置mode:history解决方法: 将router的mode设置为‘hash就不报错了 原因下次再分析?
gvim配置相关
用 vundle 来管理 vim 插件(包含配置文件vimrc和gvimrc) gvim插件管理神器:vundle的安装与使用 Vim插件管理Vundle Linux 下VIM的配置 Vim配置系列(一) ---- 插件管理 Vim配置系列(二) —- 好看的statusline vim优秀插件整理 一些有用的 VIM …

深度学习有哪些接地气又好玩的应用?
过去几年中,深度学习中的很多技术如计算机视觉、自然语言处理等被应用在很多实际问题中,而且相关成果也表明深度学习能让人们的工作效果比以前更好。我们收集了一些深度学习方面的创意应用,虽然没有对每项应用进行详尽描述,但是希…
Ubuntu下通过CMake文件编译CUDA+OpenCV代码操作步骤
在 CUDA_Test 工程中,CUDA测试代码之前仅支持在Windows10 VS2013编译,今天在Ubuntu 14.04下写了一个CMakeLists.txt文件,支持在Linux下也可以通过CMake编译CUDA_Test工程,CMakeLists.txt文件内容如下:# CMake file f…
JAVA 多用户商城系统b2b2c-Spring Cloud常见问题与总结(一)
在使用Spring Cloud的过程中,难免会遇到一些问题。所以对Spring Cloud的常用问题做一些总结。需要JAVA Spring Cloud大型企业分布式微服务云构建的B2B2C电子商务平台源码 一零三八七七四六二六 一、Eureka常见问题 1.1 Eureka 注册服务慢 默认情况下,服务…
TinyFrame升级之八:实现简易插件化开发
本章主要讲解如何为框架新增插件化开发功能。 在.net 4.0中,我们可以在Application开始之前,通过PreApplicationStartMethod方法加载所需要的任何东西。那么今天我们主要做的工作就集中在这个时间段: 1.将插件DLL及文件拷贝入主网站目录并编译…
快手王华彦:端上视觉技术的极致效率及其短视频应用实践 | AI ProCon 2019
演讲嘉宾 | 王华彦(快手硅谷Y-tech实验室负责人) 编辑 | Just 出品 | AI科技大本营(ID:rgznai100) 快手用户日均上传1500万个视频,要把这些作品准确的分发给超2亿活跃用户,如果没有强大的AI技术系统去理解…
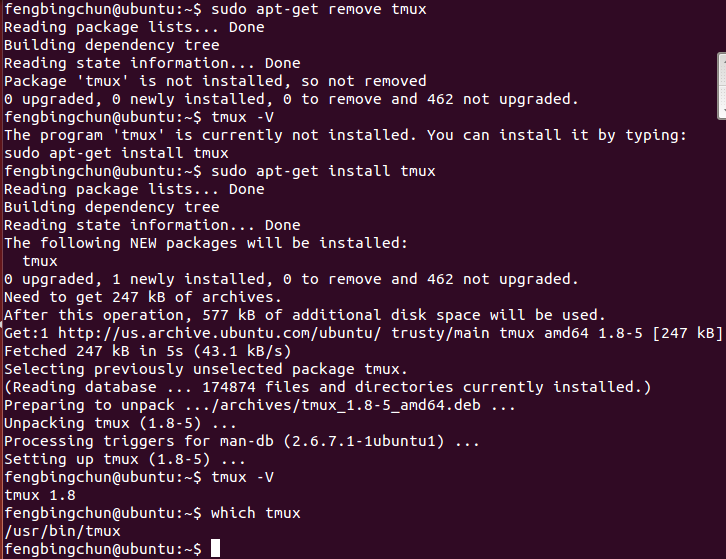
tmux简介及安装
tmux是一个开源工具,用于在一个终端窗口中运行多个终端会话。它可以减少过多的打开终端控制台。tmux的源码在 https://github.com/tmux/tmux ,它的License是BSD。tmux可以直接通过sudo apt-get install tmux命令安装(通过sudo apt-get remove tmux移除)…
Swift中依赖注入的解耦策略
原文地址:Dependency Injection Strategies in Swift 简书地址:Swift中依赖注入的解耦策略 今天我们将深入研究Swift中的依赖注入,这是软件开发中最重要的技术之一,也是许多编程语言中使用频繁的概念。 具体来说,我们将…

Eclipse mac 下的快捷键
2019独角兽企业重金招聘Python工程师标准>>> Eclipse,MyEclipse 的preference 在“windows”下边,mac下在左上角苹果图标边上 win下我们都习惯了ctrl c,在Mac 下使用标准键盘变成了win键c 系统的偏好设定 -> 键盘 -> 修饰…
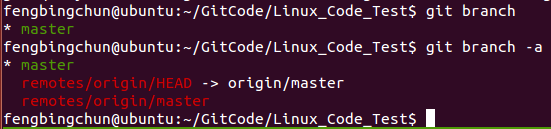
Ubuntu上使终端显示Git分支(oh-my-zsh)
oh-my-zsh是基于Zsh(Zsh是一个Linux用户很少使用的power-shell,这是由于大多数Linux产品安装,以及默认使用bash shell)的功能作了一个扩展,方便插件管理、主体自定义等。oh-my-zsh源码在 https://github.com/robbyrussell/oh-my-zsh &#x…

天哪!我的十一假期被AI操控了
(图片付费下载自视觉中国)导语:这个假期,除了脑海一直在唱歌,庆祝祖国成立的 70 周年,当然也闲不住,要乘机出去浪一浪。目前小长假进度条已经进行到 71.4% 了,有没有发现这个假期与以…
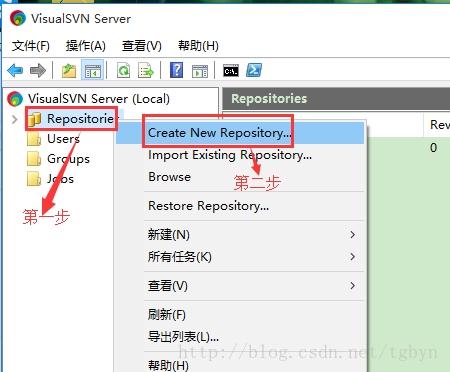
使用SVN+Axure RP 8.0创建团队项目
一、使用到的工具:VisualSVN Server --SVN服务器:https://www.visualsvn.com/server/ Axure RP 8.0 :http://www.downcc.com/soft/103078.html 二、VisualSVN Server 安装以及操作1、安装 : 默认安装即可 2、操作: &a…
no no no.不要使用kill -9.
2019独角兽企业重金招聘Python工程师标准>>> no no no.不要使用kill -9. 它没有给进程留下善后的机会: 1) 关闭socket链接 2) 清理临时文件 3) 将自己将要被销毁的消息通知给子进程 4) 重置自己的终止状态 等等。 通常,应该发送15,…

人工智能的“天罗地网”
(图片付费下载自视觉中国)整理 | 弯月编辑 | 郭芮来源 | CSDN(ID:CSDNnews)人工智能(AI)技术正在全球迅速崛起。不断涌现的最新发展令世人瞩目,从以假乱真的深度伪造视频,…
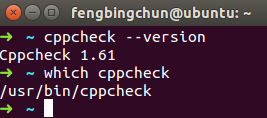
Ubuntu下安装Cppcheck源码操作步骤
Cppcheck是用在C、C中对code进行静态检查的工具。它的源码在 https://github.com/danmar/cppcheck 。它的License是GPL-3.0。Cppcheck可以检查不通过编译的文件,执行的检查包括:(1)、自动变量检查;(2)、数组的边界检查;(3)、clas…

用“脸”打卡,抬头就能签到!
科技正在飞速改变我们的生活,以前我们上班的时候,脖子上总会挂一个IC卡用来验证身份和签到打卡,后来指纹识别出现了,我们又逐渐习惯了指纹打卡,到如今,随着人脸识别技术的出现,我们开始用“脸”…
OC基础第四讲--字符串、数组、字典、集合的常用方法
OC基础第四讲--字符串、数组、字典、集合的常用方法 字符串、数组、字典、集合有可变和不可变之分。以字符串为例,不可变字符串本身值不能改变,必须要用相应类型来接收返回值;而可变字符串调用相应地方法后,本身会改变;…

分类、检测、分割任务均有SOTA表现,ACNet有多强?
(图片付费下载自视觉中国)作者 | 路一直都在来源 | 知乎专栏Abstract本文提出了一种新的自适应连接神经网络(ACNet),从两个方面对传统的卷积神经网络(CNNs)进行了改进。首先,ACNet通过自适应地确定特征节点之间的连接状态…

CUDA Samples: approximate prior vbox layer
以下CUDA sample是分别用C和CUDA实现的类似prior vbox layer的操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下:common.hpp:#ifndef FBC_CUDA_TEST_COMMON_HPP_ #define FBC_CUDA_TEST_COMMON_HPP_#include <typeinfo> #inc…
如何成为一名成功的 iOS 程序员?
前言: 编程是一个仅靠兴趣仍不足以抵达成功彼岸的领域。你必须充满激情,并且持之以恒地不断汲取更多有关编程的知识。只是对编程感兴趣还不足以功成名就——众所周知,我们工作起来像疯子。 编程是一个没有极限的职业,所以要成为一…

C#之委托与事件
委托与事件废话一堆:网上关于委托、事件的文章有很多,一千个哈姆雷特就有一千个莎士比亚,以下内容均是本人个人见解。1. 委托1.1 委托的使用这一小章来学习一下怎么简单的使用委托,了解一些基本的知识。这里先看一下其他所要用到的…

24式加速你的Python
作者 | 梁云1991来源 Python与算法之美一、分析代码运行时间第1式,测算代码运行时间平凡方法快捷方法(jupyter环境)第2式,测算代码多次运行平均时间平凡方法快捷方法(jupyter环境)第3式,按调用函…