实战:掌握PyTorch图片分类的简明教程 | 附完整代码

作者 | 小宋是呢
转载自CSDN博客
1.引文
深度学习的比赛中,图片分类是很常见的比赛,同时也是很难取得特别高名次的比赛,因为图片分类已经被大家研究的很透彻,一些开源的网络很容易取得高分。如果大家还掌握不了使用开源的网络进行训练,再慢慢去模型调优,很难取得较好的成绩。
我们在[PyTorch小试牛刀]实战六·准备自己的数据集用于训练讲解了如何制作自己的数据集用于训练,这个教程在此基础上,进行训练与应用。
(实战六链接:
https://blog.csdn.net/xiaosongshine/article/details/85225873)
2.数据介绍
数据下载地址:
https://download.csdn.net/download/xiaosongshine/11128410
这次的实战使用的数据是交通标志数据集,共有62类交通标志。其中训练集数据有4572张照片(每个类别大概七十个),测试数据集有2520张照片(每个类别大概40个)。数据包含两个子目录分别train与test:
为什么还需要测试数据集呢?这个测试数据集不会拿来训练,是用来进行模型的评估与调优。
train与test每个文件夹里又有62个子文件夹,每个类别在同一个文件夹内:
我从中打开一个文件间,把里面图片展示出来:
其中每张照片都类似下面的例子,100*100*3的大小。100是照片的照片的长和宽,3是什么呢?这其实是照片的色彩通道数目,RGB。彩色照片存储在计算机里就是以三维数组的形式。我们送入网络的也是这些数组。
3.网络构建
1.导入Python包,定义一些参数
1import torch as t
2import torchvision as tv
3import os
4import time
5import numpy as np
6from tqdm import tqdm
7
8
9class DefaultConfigs(object):
10
11 data_dir = "./traffic-sign/"
12 data_list = ["train","test"]
13
14 lr = 0.001
15 epochs = 10
16 num_classes = 62
17 image_size = 224
18 batch_size = 40
19 channels = 3
20 gpu = "0"
21 train_len = 4572
22 test_len = 2520
23 use_gpu = t.cuda.is_available()
24
25config = DefaultConfigs()
2.数据准备,采用PyTorch提供的读取方式
注意一点Train数据需要进行随机裁剪,Test数据不要进行裁剪了
1normalize = tv.transforms.Normalize(mean = [0.485, 0.456, 0.406],
2 std = [0.229, 0.224, 0.225]
3 )
4
5transform = {
6 config.data_list[0]:tv.transforms.Compose(
7 [tv.transforms.Resize([224,224]),tv.transforms.CenterCrop([224,224]),
8 tv.transforms.ToTensor(),normalize]#tv.transforms.Resize 用于重设图片大小
9 ) ,
10 config.data_list[1]:tv.transforms.Compose(
11 [tv.transforms.Resize([224,224]),tv.transforms.ToTensor(),normalize]
12 )
13}
14
15datasets = {
16 x:tv.datasets.ImageFolder(root = os.path.join(config.data_dir,x),transform=transform[x])
17 for x in config.data_list
18}
19
20dataloader = {
21 x:t.utils.data.DataLoader(dataset= datasets[x],
22 batch_size=config.batch_size,
23 shuffle=True
24 )
25 for x in config.data_list
26}
3.构建网络模型(使用resnet18进行迁移学习,训练参数为最后一个全连接层 t.nn.Linear(512,num_classes))
1def get_model(num_classes):
2
3 model = tv.models.resnet18(pretrained=True)
4 for parma in model.parameters():
5 parma.requires_grad = False
6 model.fc = t.nn.Sequential(
7 t.nn.Dropout(p=0.3),
8 t.nn.Linear(512,num_classes)
9 )
10 return(model)
如果电脑硬件支持,可以把下述代码屏蔽,则训练整个网络,最终准确率会上升,训练数据会变慢。
1for parma in model.parameters():
2 parma.requires_grad = False
模型输出
1ResNet(
2 (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
3 (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
4 (relu): ReLU(inplace)
5 (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
6 (layer1): Sequential(
7 (0): BasicBlock(
8 (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
9 (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
10 (relu): ReLU(inplace)
11 (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
12 (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
13 )
14 (1): BasicBlock(
15 (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
16 (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
17 (relu): ReLU(inplace)
18 (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
19 (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
20 )
21 )
22 (layer2): Sequential(
23 (0): BasicBlock(
24 (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
25 (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
26 (relu): ReLU(inplace)
27 (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
28 (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
29 (downsample): Sequential(
30 (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
31 (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
32 )
33 )
34 (1): BasicBlock(
35 (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
36 (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
37 (relu): ReLU(inplace)
38 (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
39 (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
40 )
41 )
42 (layer3): Sequential(
43 (0): BasicBlock(
44 (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
45 (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
46 (relu): ReLU(inplace)
47 (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
48 (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
49 (downsample): Sequential(
50 (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
51 (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
52 )
53 )
54 (1): BasicBlock(
55 (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
56 (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
57 (relu): ReLU(inplace)
58 (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
59 (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
60 )
61 )
62 (layer4): Sequential(
63 (0): BasicBlock(
64 (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
65 (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
66 (relu): ReLU(inplace)
67 (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
68 (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
69 (downsample): Sequential(
70 (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
71 (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
72 )
73 )
74 (1): BasicBlock(
75 (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
76 (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
77 (relu): ReLU(inplace)
78 (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
79 (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
80 )
81 )
82 (avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)
83 (fc): Sequential(
84 (0): Dropout(p=0.3)
85 (1): Linear(in_features=512, out_features=62, bias=True)
86 )
87)
4.训练模型(支持自动GPU加速)
1def train(epochs):
2
3 model = get_model(config.num_classes)
4 print(model)
5 loss_f = t.nn.CrossEntropyLoss()
6 if(config.use_gpu):
7 model = model.cuda()
8 loss_f = loss_f.cuda()
9
10 opt = t.optim.Adam(model.fc.parameters(),lr = config.lr)
11 time_start = time.time()
12
13 for epoch in range(epochs):
14 train_loss = []
15 train_acc = []
16 test_loss = []
17 test_acc = []
18 model.train(True)
19 print("Epoch {}/{}".format(epoch+1,epochs))
20 for batch, datas in tqdm(enumerate(iter(dataloader["train"]))):
21 x,y = datas
22 if (config.use_gpu):
23 x,y = x.cuda(),y.cuda()
24 y_ = model(x)
25 #print(x.shape,y.shape,y_.shape)
26 _, pre_y_ = t.max(y_,1)
27 pre_y = y
28 #print(y_.shape)
29 loss = loss_f(y_,pre_y)
30 #print(y_.shape)
31 acc = t.sum(pre_y_ == pre_y)
32
33 loss.backward()
34 opt.step()
35 opt.zero_grad()
36 if(config.use_gpu):
37 loss = loss.cpu()
38 acc = acc.cpu()
39 train_loss.append(loss.data)
40 train_acc.append(acc)
41 #if((batch+1)%5 ==0):
42 time_end = time.time()
43 print("Batch {}, Train loss:{:.4f}, Train acc:{:.4f}, Time: {}"\
44 .format(batch+1,np.mean(train_loss)/config.batch_size,np.mean(train_acc)/config.batch_size,(time_end-time_start)))
45 time_start = time.time()
46
47 model.train(False)
48 for batch, datas in tqdm(enumerate(iter(dataloader["test"]))):
49 x,y = datas
50 if (config.use_gpu):
51 x,y = x.cuda(),y.cuda()
52 y_ = model(x)
53 #print(x.shape,y.shape,y_.shape)
54 _, pre_y_ = t.max(y_,1)
55 pre_y = y
56 #print(y_.shape)
57 loss = loss_f(y_,pre_y)
58 acc = t.sum(pre_y_ == pre_y)
59
60 if(config.use_gpu):
61 loss = loss.cpu()
62 acc = acc.cpu()
63
64 test_loss.append(loss.data)
65 test_acc.append(acc)
66 print("Batch {}, Test loss:{:.4f}, Test acc:{:.4f}".format(batch+1,np.mean(test_loss)/config.batch_size,np.mean(test_acc)/config.batch_size))
67
68 t.save(model,str(epoch+1)+"ttmodel.pkl")
69
70
71
72if __name__ == "__main__":
73 train(config.epochs)
训练结果如下:
1Epoch 1/10
2115it [00:48, 2.63it/s]
3Batch 115, Train loss:0.0590, Train acc:0.4635, Time: 48.985504150390625
463it [00:24, 2.62it/s]
5Batch 63, Test loss:0.0374, Test acc:0.6790, Time :24.648272275924683
6Epoch 2/10
7115it [00:45, 3.22it/s]
8Batch 115, Train loss:0.0271, Train acc:0.7576, Time: 45.68823838233948
963it [00:23, 2.62it/s]
10Batch 63, Test loss:0.0255, Test acc:0.7524, Time :23.271782875061035
11Epoch 3/10
12115it [00:45, 3.19it/s]
13Batch 115, Train loss:0.0181, Train acc:0.8300, Time: 45.92648506164551
1463it [00:23, 2.60it/s]
15Batch 63, Test loss:0.0212, Test acc:0.7861, Time :23.80789279937744
16Epoch 4/10
17115it [00:45, 3.28it/s]
18Batch 115, Train loss:0.0138, Train acc:0.8767, Time: 45.27525019645691
1963it [00:23, 2.57it/s]
20Batch 63, Test loss:0.0173, Test acc:0.8385, Time :23.736321449279785
21Epoch 5/10
22115it [00:44, 3.22it/s]
23Batch 115, Train loss:0.0112, Train acc:0.8950, Time: 44.983638286590576
2463it [00:22, 2.69it/s]
25Batch 63, Test loss:0.0156, Test acc:0.8520, Time :22.790074348449707
26Epoch 6/10
27115it [00:44, 3.19it/s]
28Batch 115, Train loss:0.0095, Train acc:0.9159, Time: 45.10426950454712
2963it [00:22, 2.77it/s]
30Batch 63, Test loss:0.0158, Test acc:0.8214, Time :22.80412459373474
31Epoch 7/10
32115it [00:45, 2.95it/s]
33Batch 115, Train loss:0.0081, Train acc:0.9280, Time: 45.30439043045044
3463it [00:23, 2.66it/s]
35Batch 63, Test loss:0.0139, Test acc:0.8528, Time :23.122379541397095
36Epoch 8/10
37115it [00:44, 3.23it/s]
38Batch 115, Train loss:0.0073, Train acc:0.9300, Time: 44.304762840270996
3963it [00:22, 2.74it/s]
40Batch 63, Test loss:0.0142, Test acc:0.8496, Time :22.801835536956787
41Epoch 9/10
42115it [00:43, 3.19it/s]
43Batch 115, Train loss:0.0068, Train acc:0.9361, Time: 44.08414030075073
4463it [00:23, 2.44it/s]
45Batch 63, Test loss:0.0142, Test acc:0.8437, Time :23.604419231414795
46Epoch 10/10
47115it [00:46, 3.12it/s]
48Batch 115, Train loss:0.0063, Train acc:0.9337, Time: 46.76597046852112
4963it [00:24, 2.65it/s]
50Batch 63, Test loss:0.0130, Test acc:0.8591, Time :24.64351773262024
训练10个Epoch,测试集准确率可以到达0.86,已经达到不错效果。通过修改参数,增加训练,可以达到更高的准确率。
原文链接:
https://blog.csdn.net/xiaosongshine/article/details/89409223
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
参与投稿加入作者群,成为全宇宙最优秀的技术人~


推荐阅读
谷歌用1.2万个模型“推翻”现有无监督研究成果!斩获ICML 2019最佳论文
“篡改”视频脚本,让特朗普轻松“变脸”?AI Deepfake再升级
从0到1:Web开发绕不开的WSGI到底是什么?
24式,加速你的Python
基于智能演化算法,Ta在重新定义知识社交
回报率850%? 这个用Python优化的比特币交易机器人简直太烧脑了...
Spark精华问答 | RDD的核心概念是什么?
阿里腾讯进击韩国互联网
面试阿里技术岗,竟然挂在第4 轮……
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

python group()
正则表达式中,group()用来提出分组截获的字符串,()用来分组 import re a "123abc456" print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体 print re.sea…
图像配准的方法
转自:http://blog.sina.com.cn/s/blog_4b9b714a0100d5k5.html 图像配准的方法 1 基于特征的图像配准 基于特征的图像配准首先提取图像信息的特征,然后以这些特征为模型进行配准。特征提取的结果是一含有特征的表和对图像的描述,每个特征由…

微软发布Visual Studio 2017 15.8
2019独角兽企业重金招聘Python工程师标准>>> 对于C#/VB/C项目,在Git分支检出和分支切换操作后不再需要重新加载解决方案,这加快了操作的完成。15.8支持新推出的F# 4.5,这无疑将会受到F#开发人员的欢迎。此外,用于F#项目…

推荐系统产品与算法概述 | 深度
作者丨gongyouliu转载自大数据与人工智能(ID:gh_b8b5b02c348b)作者在《推荐系统的工程实现》(点击蓝字可回顾)这篇文章的第五部分“推荐系统范式”中讲到工业级推荐系统有非个性化范式、完全个性化范式、群组个性化范式、标的物关…

【iOS-cocos2d-X 游戏开发之十六】Cocos2dx编译后的Android自动使用(-hd)高清图设置自适应屏幕...
本篇主要介绍Cocos2dx项目开发过程中或者说项目务必遇到的一些知识点(ps.貌似Himi博客写的都是务必的 :tx: Himi认为写别人没写的才更容易吸引人不是~) OK,不多说废话,第一个介绍的是修改项目配置让你的Android项目支…
matlab图像处理命令(一)
转自:http://blog.csdn.net/langyuewu/archive/2009/05/02/4144120.aspx(非原处) 1.applylut 功能: 在二进制图像中利用lookup表进行边沿操作. 语法: A applylut(BW,lut) 举例 lut makelut(sum(x(:)) 4,2); BW1 imread(text.tif); BW2 applylut(BW1,lut); imsh…
MYSQL 查询数据排序数据和分组数据
在mysql查询过程中,可以对数据进行过滤,也可以对数据进行排序,可以对数据分组,下面分别讲述排序数据和分组数据例子。1,数据的排序 使用 ORDER BYselect * from where id10 order by id (正序,倒序)正序 AS…
Oracle RAC系列之:利用srvctl管理RAC数据库
srvctl即Server Control,是Oracle提供的一个命令行工具,用以用于管理Oracle的RAC环境。srvctl在Oracle 9i中被引入,Oracle10g、11g对其功能进行了很大的增强和改进。下面介绍下此命令的简单用法。 一、 查看实例状态(srvctl statu…
matlab图像处理命令(二)
转自:http://blog.163.com/crazyzcs126/blog/static/1297420502010229104452729/ (非原处) 图像增强 1. 直方图均衡化的 Matlab 实现 1.1 imhist 函数 功能:计算和显示图像的色彩直方图 格式:imhist(I,n) imhist(X,map) 说明&#x…

10万人的1000万张图像,微软悄然删除最大公开人脸数据集
作者 | 神经小姐姐转载自HyperAI超神经(ID:HyperAI)前几日,微软静悄悄地删除了一个公开的名人图片数据集。这个本为世界上最大的公开人脸识别数据集,现在已经不能通过微软的渠道访问。这个数据集包含了 10 万张名人面部…

密码学原理学习笔记
攻击的类型: 唯密文攻击(COA):攻击者只知道密文 已知明文攻击(KPA):攻击者知道同一密钥下密文对应的明文。 选择明文攻击(CPA):攻击者可以事先任意选择一定数量的明文,让被攻击的加密算法加密,并得到相应的密文。 选择…
终于申请博客了
今天终于下定决心在51CTO博客安家了。以后要坚持不断的写博客。以此来督促自己不断的学习和总结。把自己所掌握的技术和过往经验总结出来。转载于:https://blog.51cto.com/weijishui/971044
一种二维条码图像处理流程
目前,二维条码主要分两类: (1)、堆叠式二维条码:PDF417、Code 49; (2)、矩阵式二维条码:QR Code、Maxicode、Data Matrix。 本条码类似于Maxicode,处理过程大致为: (1)、图像灰度化ÿ…
vue中 静态文件引用注意事项
(一)assets文件夹与static文件夹的区别区别一:assets文件是src下的,所以最后运行时需要进行打包,而static文件不需要打包就直接放在最终的文件中了区别二:assets中的文件在vue中的template/style下用../这种…

百度AI快车道—企业深度学习实战营,推荐系统主题专场即将开课
身处信息过载的时代,在各大门户网站上,每天会有十万左右的新闻报道产出,京东淘宝等购物平台每小时就有上百万的商品上架出售,在B站、优酷、爱奇艺、搜狐等视频网站上每秒就有几百个小时的视频上线。所有人都正在经历一场信息变革。…

SIFT特征提取算法总结
转自:http://www.jellon.cn/index.php/archives/374 一、综述 Scale-invariant feature transform(简称SIFT)是一种图像特征提取与匹配算法。SIFT算法由David.G.Lowe于1999年提出,2004年完善总结,后来Y.Ke(2004)将其描述子部分用PCA代替直方…

一步步构建大型网站架构
之前我简单向大家介绍了各个知名大型网站的架构,MySpace的五个里程碑、Flickr的架构、YouTube的架构、PlentyOfFish的架构、WikiPedia的架构。这几个都很典型,我们可以从中获取很多有关网站架构方面的知识,看了之后你会发现你原来的想法很可能…

商汤科技举办病理、放疗两大MICCAI国际挑战赛,推动AI医疗落地
近日,商汤科技宣布将联合衡道病理、上海交通大学医学院附属瑞金医院、西京医院、上海市松江区中心医院举办MICCAI 2019消化道病理图像检测与分割国际挑战赛,联合医诺智能科技、浙江省肿瘤医院举办MICCAI 2019放疗规划自动结构勾画国际挑战赛,…
vue实战(1)——解决element-ui中upload组件使用多个时无法绑定对应的元素
解决element-ui中upload组件使用多个时无法绑定对应的元素 以前写的项目关于图片上传的都是单张或几张图片上传(主要是基于vue的element),图片路径都是固定写的,所以遇见过列表中多个上传图片的问题,先看下常用的形式 …

MVVM开发模式MVVM Light Toolkit中使用事件和参数传递
Light中定义了类GalaSoft.MvvmLight.Command.RelayCommand这个类继承了ICommand方法,实现了其中的方法,Action就是一个方法参数// 摘要: // A command whose sole purpose is to relay its functionality to other objects // by invoki…
harris角点检测与ncc匹配
转自:http://zixuanjinan.blog.163.com/blog/static/11543032620097510122831/ file1:-------------------------------------------------------------------------------------- function [y1,y2,r,c]harris(X)% 角点的检测,利用harris 算法% 输出的是…

CVPR 2019超全论文合集新鲜出炉!| 资源帖
整理 | 夕颜出品 | AI科技大本营(ID: rgznai100)实不相瞒,这是一个资源福利帖——CVPR 2019 接收论文超全合集!此前关于 CVPR 2019 论文和合集出过不少,但是这个可能是最全面最丰富的,链接奉上:…
ROS 用 roboware实现节点信息发送和接收
在ros下实现节点编程,实现一个节点发送消息,另一个节点接收。实现方式有多种,可以直接在命令窗口创建工作空间包以及节点,用catkin_make进行编译,添加.bash路径,然后执行rosrun package node_name 。这种…
javah生成JNI头文件
Administratoribm /cygdrive/z/workspace/com.example.hellojni.hellojni/src <---- 从此文件夹执行 javah *************** project root dir ******************* *** source dir *** javah -jni -classpath . com.example.hellojni.HelloJni*** package name *** ** c…

【码书】一本经典且内容全面算法书籍,学算法必备
之前推荐了好几本算法书,有《啊哈!算法》,有《算法图解》,有《漫画算法》,也有《我的第一本算法书》,很多粉丝不乐意了,觉得我推荐了这么多算法书籍,竟然没有经典算法书籍《算法导论…
Ubuntu16.04.1 安装Nginx
Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,第一个公开版本0.1.0发布于2004年10月4日。其将源代码以类BSD许可证…
linux下jboss的安装配置
闲来无事突然间想到和tomcat相同的java容器jboss,就想测试一下jboss和tomcat性能的差异之处。但是之前只安装过tomcat,想来跟tomcat安装方式应该是相同的都需要jdk的支持。查找资料后进行了安装。一下是我安装jboss的一些步骤:Linux版本&…
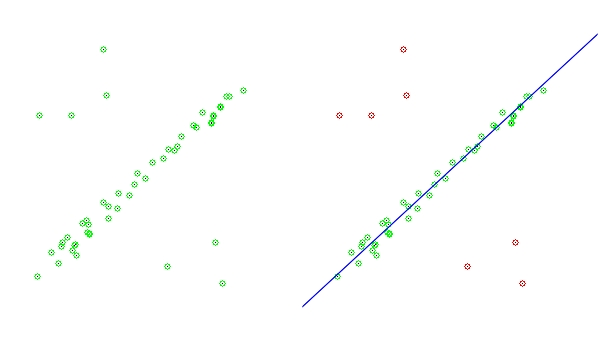
RANSAC鲁棒参数估计
转自:http://blog.csdn.net/zhanglei8893/archive/2010/01/23/5249470.aspx RANSAC 是"RANdom SAmple Consensus"的缩写。该算法是用于从一组观测数据中估计数学模型参数的迭代方法,由Fischler and Bolles在1981 提出,它是一种非确…

AlphaGo之父DeepMind再出神作,PrediNet原理详解
作者 | beyondma转载自CSDN博客近期,DeepMind发表论文,称受Marta Garnelo和 Murray Shanahan的论文“Reconciling deep learning with symbolic artificial intelligence: representing objects and relations”启发,他们提出了一种新的架构…
php中file_get_contents如何读取大容量文件
php中file_get_contents如何读取大容量文件 一、总结 一句话总结:使用file_get_contents()进行分段读取,file_get_contents()函数可以分段读取 1、读取大文件是,file_get_contents()函数为什么会发生错误? 发生内存溢出而打开错误…