一步步构建大型网站架构
之前我简单向大家介绍了各个知名大型网站的架构,MySpace的五个里程碑、Flickr的架构、YouTube的架构、PlentyOfFish的架构、WikiPedia的架构。这几个都很典型,我们可以从中获取很多有关网站架构方面的知识,看了之后你会发现你原来的想法很可能是狭隘的。
今天我们来谈谈一个网站一般是如何一步步来构建起系统架构的,虽然我们希望网站一开始就能有一个很好的架构,但马克思告诉我们事物是在发展中不断前进的,网站架构也是随着业务的扩大、用户的需求不断完善的,下面是一个网站架构逐步发展的基本过程,读完后,请思考,你现在在哪个阶段。
架构演变第一步:物理分离webserver和数据库
最开始,由于某些想法,于是在互联网上搭建了一个网站,这个时候甚至有可能主机都是租借的,但由于这篇文章我们只关注架构的演变历程,因此就假设这个时候 已经是托管了一台主机,并且有一定的带宽了,这个时候由于网站具备了一定的特色,吸引了 部分人访问,逐渐你发现系统的压力越来越高,响应速度越来越慢,而这个时候比较明显的是数据库和应用互相影响,应用出问题了,数据库也很容易出现问题,而 数据库出问题的时候,应用也容易出问题,于是进入了第一步演变阶段:将应用和数据库从物理上分离,变成了两台机器,这个时候技术上没有什么新的要求,但你 发现确实起到效果了,系统又恢复到以前的响应速度了,并且支撑住了更高的流量,并且不会因为数据库和应用形成互相的影响。
看看这一步完成后系统的图示:

架构演变第二步:增加页面缓存
好景不长,随着访问的人越来越多,你发现响应速度又开始变慢了,查找原因,发现是访问数据库的操作太多,导致数据连接竞争激烈,所以响应变慢,但数据库连 接又不能开太多,否则数据库机器压力会很高,因此考虑采用缓存机制来减少数据库连接资源的竞争和对数据库读的压力,这个时候首先也许会选择采用squid 等类似的机制来将系统中相对静态的页面(例如一两天才会有更新的页面)进行缓存(当然,也可以采用将页面静态化的方案),这样程序上可以不做修改,就能够 很好的减少对webserver的压力以及减少数据库连接资源的竞争,OK,于是开始采用squid来做相对静态的页面的缓存。
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
前端页面缓存技术,例如squid,如想用好的话还得深入掌握下squid的实现方式以及缓存的失效算法等。
架构演变第三步:增加页面片段缓存
增加了squid做缓存后,整体系统的速度确实是提升了,webserver的压力也开始下降了,但随着访问量的增加,发现系统又开始变的有些慢了,在尝 到了squid之类的动态缓存带来的好处后,开始想能不能让现在那些动态页面里相对静态的部分也缓存起来呢,因此考虑采用类似ESI之类的页面片段缓存策略,OK,于是开始采用ESI来做动态页面中相对静态的片段部分的缓存。
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
页面片段缓存技术,例如ESI等,想用好的话同样需要掌握ESI的实现方式等;
架构演变第四步:数据缓存
在采用ESI之类的技术再次提高了系统的缓存效果后,系统的压力确实进一步降低了,但同样,随着访问量的增加,系统还是开始变慢,经过查找,可能会发现系 统中存在一些重复获取数据信息的地方,像获取用户信息等,这个时候开始考虑是不是可以将这些数据信息也缓存起来呢,于是将这些数据缓存到本地内存,改变完毕后,完全符合预期,系统的响应速度又恢复了,数据库的压力也再度降低了不少。
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
缓存技术,包括像Map数据结构、缓存算法、所选用的框架本身的实现机制等。
架构演变第五步: 增加webserver
好景不长,发现随着系统访问量的再度增加,webserver机器的压力在高峰期会上升到比较高,这个时候开始考虑增加一台webserver,这也是为了同时解决可用性的问题,避免单台的webserver down机的话就没法使用了,在做了这些考虑后,决定增加一台webserver,增加一台webserver时,会碰到一些问题,典型的有:
1、如何让访问分配到这两台机器上,这个时候通常会考虑的方案是Apache自带的负载均衡方案,或LVS这类的软件负载均衡方案;
2、如何保持状态信息的同步,例如用户session等,这个时候会考虑的方案有写入数据库、写入存储、cookie或同步session信息等机制等;
3、如何保持数据缓存信息的同步,例如之前缓存的用户数据等,这个时候通常会考虑的机制有缓存同步或分布式缓存;
4、如何让上传文件这些类似的功能继续正常,这个时候通常会考虑的机制是使用共享文件系统或存储等;
在解决了这些问题后,终于是把webserver增加为了两台,系统终于是又恢复到了以往的速度。
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
负载均衡技术(包括但不限于硬件负载均衡、软件负载均衡、负载算法、linux转发协议、所选用的技术的实现细节等)、主备技术(包括但不限于ARP欺骗、linux heart-beat等)、状态信息或缓存同步技术(包括但不限于Cookie技术、UDP协议、状态信息广播、所选用的缓存同步技术的实现细节等)、共享文件技术(包括但不限于NFS等)、存储技术(包括但不限于存储设备等)。
架构演变第六步:分库
享受了一段时间的系统访问量高速增长的幸福后,发现系统又开始变慢了,这次又是什么状况呢,经过查找,发现数据库写入、更新的这些操作的部分数据库连接的 资源竞争非常激烈,导致了系统变慢,这下怎么办呢,此时可选的方案有数据库集群和分库策 略,集群方面像有些数据库支持的并不是很好,因此分库会成为比较普遍的策略,分库也就意味着要对原有程序进行修改,一通修改实现分库后,不错,目标达到 了,系统恢复甚至速度比以前还快了。
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
这一步更多的是需要从业务上做合理的划分,以实现分库,具体技术细节上没有其他的要求;
但同时随着数据量的增大和分库的进行,在数据库的设计、调优以及维护上需要做的更好,因此对这些方面的技术还是提出了很高的要求的。
架构演变第七步:分表、DAL和分布式缓存
随着系统的不断运行,数据量开始大幅度增长,这个时候发现分库后查询仍然会有些慢,于是按照分库的思想开始做分表的工作,当然,这不可避免的会需要对程序 进行一些修改,也许在这个时候就会发现应用自己要关心分库分表的规则等,还是有些复杂的,于是萌生能否增加一个通用的框架来实现分库分表的数据访问,这个在ebay的架构中对应的就是DAL,这个演变的过程相对而言需要花费较长的时间,当然,也有可能这个通用的框架会等到分表做完后才开始做,同时,在这个阶段可 能会发现之前的缓存同步方案出现问题,因为数据量太大,导致现在不太可能将缓存存在本地,然后同步的方式,需要采用分布式缓存方案了,于是,又是一通考察和折磨,终于是将大量的数据缓存转移到分布式缓存上了。
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
分表更多的同样是业务上的划分,技术上涉及到的会有动态hash算法、consistent hash算法等;
DAL涉及到比较多的复杂技术,例如数据库连接的管理(超时、异常)、数据库操作的控制(超时、异常)、分库分表规则的封装等;
架构演变第八步:增加更多的webserver
在做完分库分表这些工作后,数据库上的压力已经降到比较低了,又开始过着每天看着访问量暴增的幸福生活了,突然有一天,发现系统的访问又开始有变慢的趋势 了,这个时候首先查看数据库,压力一切正常,之后查看webserver,发现apache阻塞了很多的请求,而应用服务器对每个请求也是比较快的,看来 是请求数太高导致需要排队等待,响应速度变慢,这还好办,一般来说,这个时候也会有些钱了,于是添加一些webserver服务器,在这个添加 webserver服务器的过程,有可能会出现几种挑战:
1、Apache的软负载或LVS软负载等无法承担巨大的web访问量(请求连接数、网络流量等)的调度了,这个时候如果经费允许的话,会采取的方案是购 买硬件负载,例如F5、Netsclar、Athelon之类的,如经费不允许的话,会采取的方案是将应用从逻辑上做一定的分类,然后分散到不同的软负载集群中;
2、原有的一些状态信息同步、文件共享等方案可能会出现瓶颈,需要进行改进,也许这个时候会根据情况编写符合网站业务需求的分布式文件系统等;
在做完这些工作后,开始进入一个看似完美的无限伸缩的时代,当网站流量增加时,应对的解决方案就是不断的添加webserver。
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
到了这一步,随着机器数的不断增长、数据量的不断增长和对系统可用性的要求越来越高,这个时候要求对所采用的技术都要有更为深入的理解,并需要根据网站的需求来做更加定制性质的产品。
架构演变第九步:数据读写分离和廉价存储方案
突然有一天,发现这个完美的时代也要结束了,数据库的噩梦又一次出现在眼前了,由于添加的webserver太多了,导致数据库连接的资源还是不够用,而这个时候又已经分库分表了,开始分析数据库的压力状况,可能会发现数据库的读写比很高,这个时候通常会想到数据读写分离的方案,当然,这个方案要实现并不 容易,另外,可能会发现一些数据存储在数据库上有些浪费,或者说过于占用数据库资源,因此在这个阶段可能会形成的架构演变是实现数据读写分离,同时编写一些更为廉价的存储方案,例如BigTable这种。
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
数据读写分离要求对数据库的复制、standby等策略有深入的掌握和理解,同时会要求具备自行实现的技术;
廉价存储方案要求对OS的文件存储有深入的掌握和理解,同时要求对采用的语言在文件这块的实现有深入的掌握。
架构演变第十步:进入大型分布式应用时代和廉价服务器群梦想时代
经过上面这个漫长而痛苦的过程,终于是再度迎来了完美的时代,不断的增加webserver就可以支撑越来越高的访问量了,对于大型网站而言,人气的重要毋 庸置疑,随着人气的越来越高,各种各样的功能需求也开始爆发性的增长,这个时候突然发现,原来部署在webserver上的那个web应用已经非常庞大 了,当多个团队都开始对其进行改动时,可真是相当的不方便,复用性也相当糟糕,基本是每个团队都做了或多或少重复的事情,而且部署和维护也是相当的麻烦, 因为庞大的应用包在N台机器上复制、启动都需要耗费不少的时间,出问题的时候也不是很好查,另外一个更糟糕的状况是很有可能会出现某个应用上的bug就导 致了全站都不可用,还有其他的像调优不好操作(因为机器上部署的应用什么都要做,根本就无法进行针对性的调优)等因素,根据这样的分析,开始痛下决心,将 系统根据职责进行拆分,于是一个大型的分布式应用就诞生了,通常,这个步骤需要耗费相当长的时间,因为会碰到很多的挑战:
1、拆成分布式后需要提供一个高性能、稳定的通信框架,并且需要支持多种不同的通信和远程调用方式;
2、将一个庞大的应用拆分需要耗费很长的时间,需要进行业务的整理和系统依赖关系的控制等;
3、如何运维(依赖管理、运行状况管理、错误追踪、调优、监控和报警等)好这个庞大的分布式应用。
经过这一步,差不多系统的架构进入相对稳定的阶段,同时也能开始采用大量的廉价机器来支撑着巨大的访问量和数据量,结合这套架构以及这么多次演变过程吸取的经验来采用其他各种各样的方法来支撑着越来越高的访问量。
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
这一步涉及的知识体系非常的多,要求对通信、远程调用、消息机制等有深入的理解和掌握,要求的都是从理论、硬件级、操作系统级以及所采用的语言的实现都有清楚的理解。
上文来自:http://www.blogjava.net/BlueDavy/archive/2008/09/03/226749.html
最后,附上一张大型网站的架构图

转载于:https://blog.51cto.com/519116/971216
相关文章:

商汤科技举办病理、放疗两大MICCAI国际挑战赛,推动AI医疗落地
近日,商汤科技宣布将联合衡道病理、上海交通大学医学院附属瑞金医院、西京医院、上海市松江区中心医院举办MICCAI 2019消化道病理图像检测与分割国际挑战赛,联合医诺智能科技、浙江省肿瘤医院举办MICCAI 2019放疗规划自动结构勾画国际挑战赛,…

vue实战(1)——解决element-ui中upload组件使用多个时无法绑定对应的元素
解决element-ui中upload组件使用多个时无法绑定对应的元素 以前写的项目关于图片上传的都是单张或几张图片上传(主要是基于vue的element),图片路径都是固定写的,所以遇见过列表中多个上传图片的问题,先看下常用的形式 …

MVVM开发模式MVVM Light Toolkit中使用事件和参数传递
Light中定义了类GalaSoft.MvvmLight.Command.RelayCommand这个类继承了ICommand方法,实现了其中的方法,Action就是一个方法参数// 摘要: // A command whose sole purpose is to relay its functionality to other objects // by invoki…
harris角点检测与ncc匹配
转自:http://zixuanjinan.blog.163.com/blog/static/11543032620097510122831/ file1:-------------------------------------------------------------------------------------- function [y1,y2,r,c]harris(X)% 角点的检测,利用harris 算法% 输出的是…

CVPR 2019超全论文合集新鲜出炉!| 资源帖
整理 | 夕颜出品 | AI科技大本营(ID: rgznai100)实不相瞒,这是一个资源福利帖——CVPR 2019 接收论文超全合集!此前关于 CVPR 2019 论文和合集出过不少,但是这个可能是最全面最丰富的,链接奉上:…
ROS 用 roboware实现节点信息发送和接收
在ros下实现节点编程,实现一个节点发送消息,另一个节点接收。实现方式有多种,可以直接在命令窗口创建工作空间包以及节点,用catkin_make进行编译,添加.bash路径,然后执行rosrun package node_name 。这种…
javah生成JNI头文件
Administratoribm /cygdrive/z/workspace/com.example.hellojni.hellojni/src <---- 从此文件夹执行 javah *************** project root dir ******************* *** source dir *** javah -jni -classpath . com.example.hellojni.HelloJni*** package name *** ** c…

【码书】一本经典且内容全面算法书籍,学算法必备
之前推荐了好几本算法书,有《啊哈!算法》,有《算法图解》,有《漫画算法》,也有《我的第一本算法书》,很多粉丝不乐意了,觉得我推荐了这么多算法书籍,竟然没有经典算法书籍《算法导论…
Ubuntu16.04.1 安装Nginx
Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,第一个公开版本0.1.0发布于2004年10月4日。其将源代码以类BSD许可证…
linux下jboss的安装配置
闲来无事突然间想到和tomcat相同的java容器jboss,就想测试一下jboss和tomcat性能的差异之处。但是之前只安装过tomcat,想来跟tomcat安装方式应该是相同的都需要jdk的支持。查找资料后进行了安装。一下是我安装jboss的一些步骤:Linux版本&…
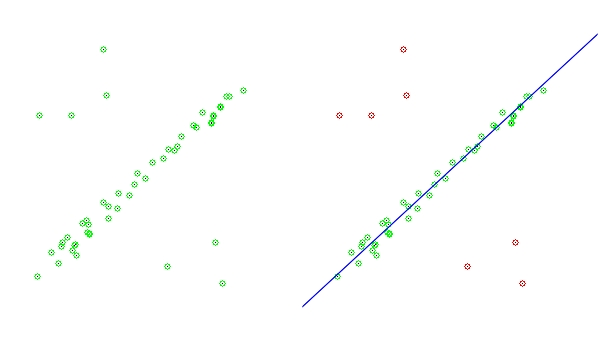
RANSAC鲁棒参数估计
转自:http://blog.csdn.net/zhanglei8893/archive/2010/01/23/5249470.aspx RANSAC 是"RANdom SAmple Consensus"的缩写。该算法是用于从一组观测数据中估计数学模型参数的迭代方法,由Fischler and Bolles在1981 提出,它是一种非确…

AlphaGo之父DeepMind再出神作,PrediNet原理详解
作者 | beyondma转载自CSDN博客近期,DeepMind发表论文,称受Marta Garnelo和 Murray Shanahan的论文“Reconciling deep learning with symbolic artificial intelligence: representing objects and relations”启发,他们提出了一种新的架构…
php中file_get_contents如何读取大容量文件
php中file_get_contents如何读取大容量文件 一、总结 一句话总结:使用file_get_contents()进行分段读取,file_get_contents()函数可以分段读取 1、读取大文件是,file_get_contents()函数为什么会发生错误? 发生内存溢出而打开错误…

Vmware虚拟机的复制后无法使用的问题和解决
为什么80%的码农都做不了架构师?>>> 我在自己的机器上用Vmware安装的Ubuntu 12.04系统,并在里面部署了Openstack的开发环境,部署的过程有些复杂,不希望再次重复这个过程,于是就复制整个的虚拟机文件到其他…

Facebook频谱图模型生成比尔·盖茨声音,性能完胜WaveNet、MAESTRO
作者 | James Vincent 等编译 | 夕颜、Monanfei出品 | AI科技大本营(ID:rgznai100)计算机生成语音领域,正在酝酿着和一场革命。Facebook 工程师们设计创建的机器学习模型 MelNet 就是一个启示。下面这段听起来怪异的话像极了比尔盖茨是吧&…
数据表设计的原则
如何设计数据表: 三个范式 ER图
图像配准----Harris算子
Harris算子是C.Harris和M.J.Stephens在1988年提出的一种特征点提取算子。它用一阶偏导来描述亮度变化,这种算子受信号处理中自相关函数的启发,给出与自相关函数相联系的矩阵M。M矩阵的特征值是自相关函数的一阶曲率,如果两个曲率值都高&#…
关于ORA-01950: no privileges on tablespace 的解决
前天晚上,本想在家里搭一个公司项目的开发环境,以便在工作忙的时候做点“家庭作业”。下班之前,通过PLSQL Developer导数据库时,不知道什么原因,以.dmp格式导出时总不成功,于是选择以.sql格式导出ÿ…

继往开来!目标检测二十年技术综述
作者 | 周强来源 | 我爱计算机视觉(id:aicvml)计算机视觉中的目标检测,因其在真实世界的大量应用需求,比如自动驾驶、视频监控、机器人视觉等,而被研究学者广泛关注。几天前,arXiv新出一篇目标检…
python+selenium百度贴吧自动签到
#-*- coding:utf-8 -*- from selenium import webdriver import time import os import random from selenium.webdriver.common.action_chains import ActionChainsbrowser webdriver.Chrome()# 最大等待加载完的时间 max_loading 600 # 延时随机n秒执行 wait_time random.…
图像配准----NCC
在用Harris算子对图像进行角点提取后,两幅图像得到的角点个数不一定相等,这时就要先对它们进行处理,得出一一对应的角点对。 归一化互相关(Normalized Cross Correlation method, NCC)匹配算法是一种经典的统计匹配算法,通过计算模…

Ext Scheduler Web资源甘特图控件
原文来自 http://www.fanganwang.com/Product-detail-item-1430.html欢迎转载。 关键字: 资源甘特图又叫负荷图,其纵轴不再列出活动,而是列出整个部门或特定的资源。 Ext Scheduler资源甘特图是基于Extjs核心库的开发的,基于WEB浏…

50行代码教AI实现动作平衡 | 附完整代码
作者 | Mike Shi译者 | linstancy责编 | Jane出品 | AI科技大本营(id:rgznai100)【导读】本文将为大家展示如何通过 Numpy 库和 50行 Python 代码,使用标准的 OpenAI Gym平台创建智能体 (agent),就教会机器处理推车杆问…
图像配准----双向匹配
由Harris提取出的两幅图像的角点个数或对应关系并不是一一对应的。为了后续的配准,需要先对提取出的角点进行初始匹配,双向匹配方法是比较简单的一种方法,它实现容易。 设参考图像特征点集为X {x1, x2, …,xp}, p > 3;待配准图…
[专业亲测]Ubuntu16.04安装Nvidia显卡驱动(cuda)--解决你的所有困惑【转】
本文转载自: 因为要做毕设需要安装caffe2,配置cuda8.0,但是安装nvidia驱动真的是把我难倒了,看了很多篇博文都没有效果,现在我自己重新总结了下几种 安装方法(亲测有效),希望能帮到大…
IE下javascript的console方法
IE下javascript的console方法 FireFox 和 Chrome 下调试JS都有console,IE6下没有。特用此办法来兼容IE6. <br /><pre lang‘‘html‘‘> <!doctype html> <html> <head> <meta charset‘‘utf-8‘‘/> </head> <body&…
图像配准----RANSAC
对角点进行初始匹配后,所选定的角点并不能保证全部是正确的点,也可能有误点,因此,还需要进一步对所选定的角点进行精确匹配。 RANSAC(RANdom Sample And Consensus)方法是由Fischler和Bolles提出的一种鲁棒性的参数估计方法。它的…

教你用OpenCV实现机器学习最简单的k-NN算法
前言:OpenCV 的构建是为了提供计算机视觉的通用基础接口,现在已经成为经典和最优秀的计算机视觉和机器学习的综合算法工具集。作为一个开源项目,研究者、商业用户和政府部门都可以轻松利用和修改现成的代码。k-NN算法可以认为是最简单的机器学…
div 相同属性提取
把样式名或id写在一起,用逗号隔开 <!DOCTYPE html><html lang"en"><head> <meta charset"UTF-8"> <title>信息详情</title> <style type"text/css"> #box-1, #box-2, #box…
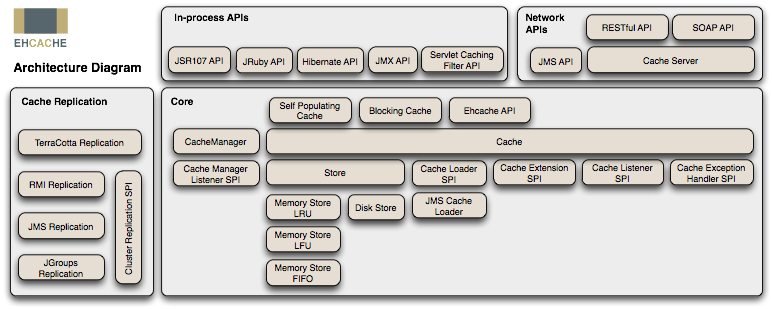
ehcache 简介
hCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。 下图是 Ehcache 在应用程序中的位置: ehcache部署起来很简单,主要分两步: 1.首先要给他写个核心配置XML文件 <ehca…