Facebook频谱图模型生成比尔·盖茨声音,性能完胜WaveNet、MAESTRO

作者 | James Vincent 等
编译 | 夕颜、Monanfei
出品 | AI科技大本营(ID:rgznai100)
计算机生成语音领域,正在酝酿着和一场革命。Facebook 工程师们设计创建的机器学习模型 MelNet 就是一个启示。
下面这段听起来怪异的话像极了比尔·盖茨是吧?
但事实上,这几句话是 Facebook 的工程师们设计创建的机器学习模型 MelNet 生成的。AI 合成逼真语音已不是新鲜事,George Takei、Jane Goodall、Stephen Hawking 等大佬的声音早已被模仿了个遍,而且逼真程度让人惊叹。Facebook 此次合成的声音样本还有很多,可以在这里查看:https://audio-samples.github.io/
那么,这次合成比尔·盖茨声音背后的技术有何区别呢?答案是生成声音的机器学习模型 MelNet是通过一种叫做频谱图的技术实现的。而且实验表明,这个模型的性能高于此前曾红火一时的 SampleRNN 和 WaveNet 等模型。
MelNet 的出现并非平地一声雷。最近几年,语音克隆的质量一直在稳步提高,最近著名美国播客 Joe Rogan 的声音克隆证明了我们到底已经走了多远。追溯到 2016 年,AI 声音克隆技术已经有了很大的发展,SampleRNN 和 WaveNet 横空出世,后者是由位于伦敦的人工智能实验室 DeepMind 创建的机器学习文本到语音转换程序,该实验室现在为 Google 智能助理提供支持。
MelNet 技术解读
在论文中,Facebook 的工程师对 MelNet 进行了详解,我们从中摘取重要部分进行了解读。
论文地址:https://arxiv.org/pdf/1906.01083.pdf
本文的主要贡献如下:
提出了 MelNet。一个语谱图的生成模型,它结合了细粒度的自回归模型和多尺度生成过程,能够同时捕获局部和全局的结构。
展示了 MelNet 在长程依赖性上卓越的性能。
展示了 MelNet 在多种音频生成任务上优秀的能力:无条件语音生成任务、音乐生成任务、文字转语音合成任务。而且在这些任务上,MelNet 都是端到端的实现。
摘要
WaveNet、SampleRNN 和类似程序的基本方法是为 AU 系统提供大量数据,并用它来分析人声中的细微差别。(早一点的文本到语音系统不会生成音频,而是进行重构:将语音样本切割成音素,然后拼接在一起创建新单词。)当 WaveNet 和其他模型使用音频波形进行训练时,Facebook 的 MelNet 已经可以使用更多、包含更丰富信息的密集格式:频谱图。
(注:频谱可以表示一个信号是由哪些频率的弦波所组成,也可以看出各频率弦波的大小及相位等信息,是分析振动参数的主要工具)
为了捕获音频波形中的高级结构,本文将时域的波形转化为二维时频的表达,通过将高度表达的概率模型和多尺度的生成模型相结合,提出了一种能够生成高保真音频样本的模型,该模型能够在时间尺度上捕获结构信息,而现存的时域模型尚未实现该功能。为了验证模型的有效性,本文将模型运用到多种音频生成任务,包括无条件语音生成、音乐生成,以及文字转语音合成。运用人工判别和密度估计的评价方法,本文模型的效果都超越了现存的模型。
MelNet 捕捉“高层结构”更胜一筹
在一篇随附的论文(https://arxiv.org/pdf/1906.01083.pdf)中,Facebook 的研究人员指出,虽然 WaveNet 生成更高保真的音频输出,但 MelNet 在捕捉“高层结构”方面更胜一筹——说话者的声音中包含了微妙的一致性,而这几乎无法用文字描述,但是人的耳朵很好地辨别出来。
他们表示,这是因为频谱图中捕获的数据比音频波形中的数据“更紧凑”。这种密度允许算法产生更一致的声音,而不是被波形记录的极端细节分散和磨练(使用过于简单的人类比喻)。
具体来说,在剧烈变化的时间尺度上,音频波形具有复杂的结构,这对音频生成模型提出了挑战。局部结构用于产生高保真音频,跨越数万个时间步长的长程依赖性,则用于产生全局一致的音频,同时捕获局部结构和长程依赖性,是一项很具有挑战的任务。WaveNet 和 SampleRNN 等现存的生成模型擅长捕获局部依赖性,但是它们无法捕获长时的高级结构。基于此,本文引入了一种新的音频生成模型,它捕获了比先存模型更为长程的依赖性。该模型主要通过建模2D时频表示来实现这一目标,如下图所示。
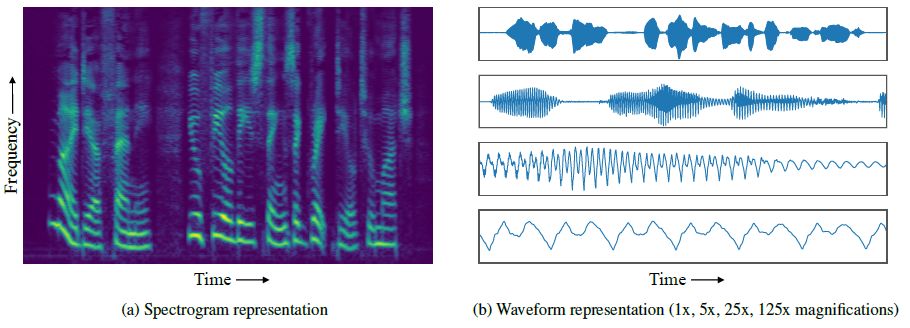
建模频谱图可以简化捕获全局结构的任务,但是会削弱与音频保真度相关的局部特征的捕获。为了减少信息损失,我们对高分辨率频谱图进行了建模。为了限制过度平滑,我们使用了高度表达的自回归模型,在时间和频率维度上对分布进行了分解。除此之外,为了捕获具有数十万个维度的频谱图中的局部和全局结构,我们采用了多尺度的方法,由粗略到精细的方式生成了频谱图。结合这些表征和建模技术,我们可以提出了高度表达、广泛适用且完全端到端的音频生成模型 MelNet。
缺陷:无法复制人类声音在较长时间内的变化
但是,MelNet 也有一些缺陷,其中最重要的一点是该模型无法复制人类声音在较长时间内的变化。有趣的是,这类似于我们在 AI 文本生成中的限制,它只能捕获表面级别的一致性,而不是长期结构。
抛开这些缺陷,MelNet 取得的结果非常好。此外,MelNet 是一个多功能系统,它不仅可以产生逼真的声音,还可以用于生成音乐(虽然有时候输出有点差强人意,但不能以商业用途标准来衡量)。
概率模型
本文使用了自回归模型,将语谱图 x 的联合分布作为条件分布的乘积进行分解。联合概率分解如下:
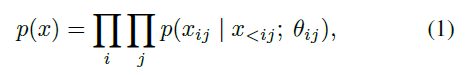
然后,我们用高斯混合模型对其中的每个因子进行建模,每个因子可以被分解如下:
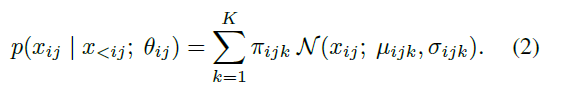
其中图片: https://uploader.shimo.im/f/EInGnyOdsdgBDRKS.png是某个神经网络的输出,为了确保网络输出能够参数化一个有效的高斯混合模型,网络首先要计算无约束的参数,让后再对参数实施以下的限制:
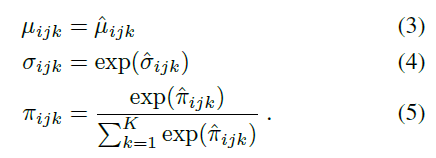
上述限制保证了正的标准差,以及保证了混合系数的和为 1 。
MelNet 网络结构
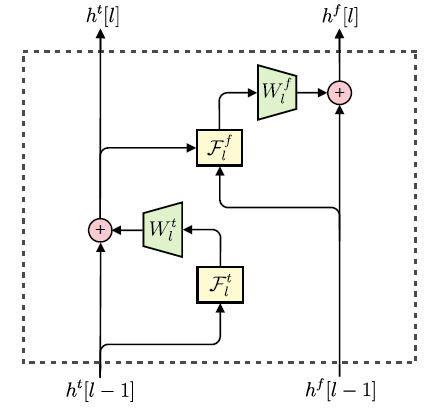
类似图像空间分布的逐点估计,MelNet 模型在语谱图的时间和频率维度上,对元素的分布逐个进行估计。由于语谱图在频率轴上,没有平移不变性,因此本模型用多维递归代替了 2D 卷积。该模型和 Gated PixelCNN 的结构较为相似,都采用了多层堆叠(stacks)的结构,它们用于提取输入中不同片段的特征,进而综合所有的信息。该模型主要有两类 stack:
Time-delayed stack: 综合历史所有频谱帧的信息
Frequency-delayed stack: 针对某一频谱帧,使用该帧中所有元素的信息,以及 time-dealyed stack 的输出信息,从而计算所有提取到的信息。
这些 stacks 之间相互连接,简单来讲,第 L 层 time-delayed stack 提取的特征,将作为第 L 层 frequency-delayed stack 的输入。为了能够训练更深的网路,两类 stack 内部都采用了残差连接。最后一层 frequency-delayed stack 的输出用于计算非受限的高斯混合参数。
Time-delayed stack
Time-delayed stack 使用了多层多维 RNN来提取历史频谱帧的信息,每层多维RNN 都由 3个1-D RNN组成:一个沿着频率轴向前推进,一个沿着频率轴向后推进,一个沿着时间轴向前推进,如下图所示。
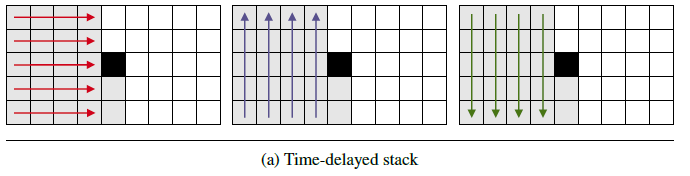
每个 Time-delayed stack 的功能可以用下面的式子表示:
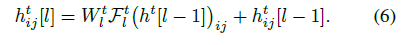
Frequency-delayed stack
Frequency-delayed stack 由1个 1-D RNN组成,该 RNN 沿频率轴向前推进,如下图所示。
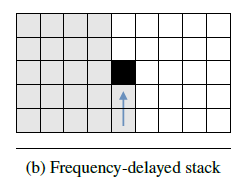
Frequency-delayed stack 具有两个输入:前一层的 Frequency-delayed stack 输出,以及当前层的 Time-delayed stack 输出。两个输入简单相加后作为当前层的 Frequency-delayed stack 的最终输入,表达式如下:
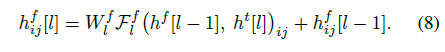
在网络的最后一层中,对 Frequency-delayed stack 进行一个线性映射,从而得到非受限的高斯混合参数:
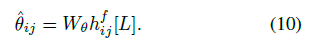
下图所示为网络中每层的 Time-delayed stack 和 Frequency-delayed stack 的连接方式:
Centralized Stack
为了获取更加集中的特征表示,MelNet 模型选择性地加入了 Centralized Stack 。Centralized Stack 由一个 RNN 组成,在每个时间步长下,接受一整帧频谱作为输入,输出由 RNN 隐状态组成的单个向量,公式如下:
Centralized Stack 的输出将作为 Frequency-delayed stack 的输入,因此,Frequency-delayed stack 将会有三个输入。
条件信息
为了将额外的条件信息(例如说话人 ID)加入到模型中,我们将条件特征 z 沿着输入语谱图 x 的方向,简单投影到输入层,公式如下所示。
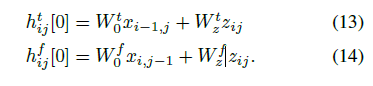
学习对齐
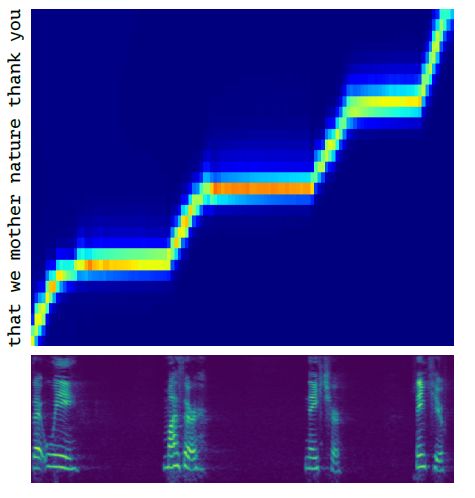
如何将语谱帧和离散字符对齐,是端到端文字转语音任务的关键点,为了学习这一功能,MelNet 模型采用了注意力机制,该机制是基于位置的高斯混合注意力的一种直接变体。如下图所示,为本模型所学习到的对齐效果。
多尺度建模
为了提高合成音频的保真度,我们生成了高分辨率的语谱图,它与相应的时域表示具有相同的维度。由于高维的分布对于自回归模型具有很大的挑战,我们使用了一种多尺度的方法,有效地置换自回归排序,从而由粗到细地生成语谱图。
训练
首先对每帧语谱图进行降采样,从而生成不同分辨率的语谱图。具体做法如下:将语谱图 x 的列标记为奇列和偶列,所有偶列按顺序组合成新的语谱图,剩余的奇列重复前面的操作,从而得到不同分辨率的语谱图,具体操作用 split 函数代替,如下所示:
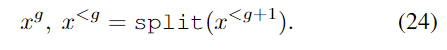
然后我们用低分辨率的语谱图来重建高分辨率的语谱图。在此过程中,我们引入了由一个多维RNN组成的特征提取网络,它由4 个 1-D RNN 组成,用于在各个低分辨率语谱图的两个轴上双向运行,最终生成高分辨率的语谱图。
采样
为了得到高分辨率的结果,我们利用网络学习到的参数,在受限于图片: https://uploader.shimo.im/f/vT2XqPWPsYYitpw7.png的情况下,迭代地对图片: https://uploader.shimo.im/f/WkQfHvaeGq4yQdcd.png进行采样,公式如下:
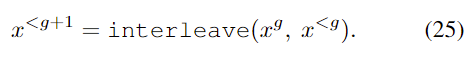
当一个完整的语谱图生成后,采样过程就停止了迭代,生成的各级别分辨率的语谱图如下所示:

采样过程的示意图如下所示:

实验结果
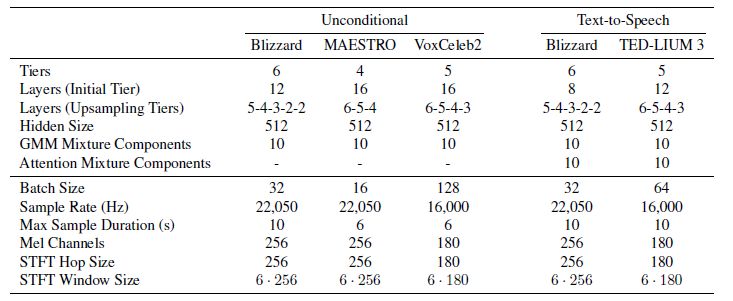
数据集
Blizzard:由专业人士以高度动画的方式进行的有声读物叙述
MAESTRO:包括超过 172 小时的钢琴独奏表演
VoxCeleb2:超过 2000 小时的语音数据,包括笑声、串扰、频道效果、音乐和其他声音。 该数据集也是多语言的,包括来自 145 个不同国籍的演讲者,涵盖了广泛的口音、年龄、种族和语言
TED-LIUM 3:包括长达 452 小时的 TED 演讲
模型的超参数
结果
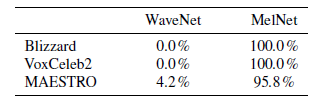
在无条件音频生成任务上,Facebook 团队进行了三个子实验,分别是单说活人语音生成,多说话人语音生成,以及音乐生成,分别使用 Blizzard、VoxCeleb2 和 MAESTRO 数据集进行实验。实验中,将本文的 MelNet 和 现存的 WaveNet 模型进行比较,采用人工判别的方法来评价两者的生成长时结构语音的性能,从下图可以看出,MelNet 的性能要好于 WaveNet 。
在文字转语音合成的任务上,进行了三个子实验,分别是单说活人 TTS,多说话人 TTS,以及密度估计实验。实验中,将本文的 MelNet 和 现存的 MAESTRO 模型进行比较,从下图可以看出,MelNet 的性能要好于 MAESTRO 。
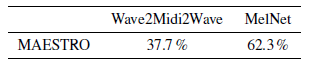
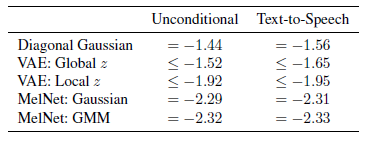
对于密度估计实验,将本文的衍生模型 MelNet: Gaussian 和 MelNet: GMM,与 Diagonal Gaussian、VAE: Global z、VAE: Local z 进行比较,实验结果如下,可以看到 MelNet 可以极大地改善无条件语音生成和 TTS 的密度估计。
结论
这种用于语谱表示的生成模型 MelNet 将高度表达的自回归模型与多尺度模型方案相结合,在局部和全局尺度上生成具有真实结构的高分辨率语谱图。与直接模拟时域信号的模型相比,MelNet 更加适合模拟长程的时间依赖性。实验表明,MelNet 在各种任务中均表现了优秀的性能。
老调重谈:它是把双刃剑
与以往一样,这项技术同样也是一把双刃剑。它能带来什么好处呢?答案很明显,比如帮助创建更高质量的 AI 助手;对于有语言障碍的人,它是实用的语音模型;此外,还可以用于娱乐业。危险也显而易见? 比如破坏对传统证据形式的信任,以及音频骚扰、诈骗和越来越普遍的诽谤。
还记得最近的一项研究吗?如果你想对一段人物特写视频进行重新编辑,只需要对视频所对应的文本内容进行修改,随后人脸会根据修改的文本内容作出与之相配的动作表达,这会造成什么样的后果难以想象。AI 科技大本营在《“篡改”视频脚本,让特朗普轻松“变脸”?AI Deepfake再升级》中对此进行报道。
当然,等到类似技术更加普遍应用之时,会给传统影视行业造成巨大冲击倒是可以预见的,毕竟人脸可以生成,声音可以生成,明星们连出镜,甚至配音的麻烦都可以直接跳过,因为 AI 可以帮他们一键搞定,也许某一天,我们会发现,明星们的盈利模式将变成“人脸出租”?
原文链接:
https://www.theverge.com/2019/6/10/18659897/ai-voice-clone-bill-gates-facebook-melnet-speech-generation
https://arxiv.org/pdf/1906.01083.pdf
(*本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
公开课精彩推荐
◆
本次课程将会介绍如何利用TensorRT加速YOLO目标检测,课程将会着重介绍编程方法。本次课程还会涉及到 TensorRT 中数据类型,流处理,多精度推理等细节的展示。本次课程特色是讲解+示例分享。本次课程中,QA也是一个非常精彩的环节。


推荐阅读
开源要自立?华为如何“复制”Google模式
谷歌用1.2万个模型“推翻”现有无监督研究成果!斩获ICML 2019最佳论文
24式,加速你的Python
荔枝“自由”?朋友,你实现了吗?
为防 Android 碎片化?Google 强迫开发者使用自有开发工具!
Docker 存储选型,这些年我们遇到的坑
从制造业转型物联网,看博世如何破界
回报率850%? 这个用Python优化的比特币交易机器人简直太烧脑了...
面试阿里技术岗,竟然挂在第4 轮……
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

数据表设计的原则
如何设计数据表: 三个范式 ER图
图像配准----Harris算子
Harris算子是C.Harris和M.J.Stephens在1988年提出的一种特征点提取算子。它用一阶偏导来描述亮度变化,这种算子受信号处理中自相关函数的启发,给出与自相关函数相联系的矩阵M。M矩阵的特征值是自相关函数的一阶曲率,如果两个曲率值都高&#…
关于ORA-01950: no privileges on tablespace 的解决
前天晚上,本想在家里搭一个公司项目的开发环境,以便在工作忙的时候做点“家庭作业”。下班之前,通过PLSQL Developer导数据库时,不知道什么原因,以.dmp格式导出时总不成功,于是选择以.sql格式导出ÿ…

继往开来!目标检测二十年技术综述
作者 | 周强来源 | 我爱计算机视觉(id:aicvml)计算机视觉中的目标检测,因其在真实世界的大量应用需求,比如自动驾驶、视频监控、机器人视觉等,而被研究学者广泛关注。几天前,arXiv新出一篇目标检…
python+selenium百度贴吧自动签到
#-*- coding:utf-8 -*- from selenium import webdriver import time import os import random from selenium.webdriver.common.action_chains import ActionChainsbrowser webdriver.Chrome()# 最大等待加载完的时间 max_loading 600 # 延时随机n秒执行 wait_time random.…
图像配准----NCC
在用Harris算子对图像进行角点提取后,两幅图像得到的角点个数不一定相等,这时就要先对它们进行处理,得出一一对应的角点对。 归一化互相关(Normalized Cross Correlation method, NCC)匹配算法是一种经典的统计匹配算法,通过计算模…

Ext Scheduler Web资源甘特图控件
原文来自 http://www.fanganwang.com/Product-detail-item-1430.html欢迎转载。 关键字: 资源甘特图又叫负荷图,其纵轴不再列出活动,而是列出整个部门或特定的资源。 Ext Scheduler资源甘特图是基于Extjs核心库的开发的,基于WEB浏…

50行代码教AI实现动作平衡 | 附完整代码
作者 | Mike Shi译者 | linstancy责编 | Jane出品 | AI科技大本营(id:rgznai100)【导读】本文将为大家展示如何通过 Numpy 库和 50行 Python 代码,使用标准的 OpenAI Gym平台创建智能体 (agent),就教会机器处理推车杆问…
图像配准----双向匹配
由Harris提取出的两幅图像的角点个数或对应关系并不是一一对应的。为了后续的配准,需要先对提取出的角点进行初始匹配,双向匹配方法是比较简单的一种方法,它实现容易。 设参考图像特征点集为X {x1, x2, …,xp}, p > 3;待配准图…
[专业亲测]Ubuntu16.04安装Nvidia显卡驱动(cuda)--解决你的所有困惑【转】
本文转载自: 因为要做毕设需要安装caffe2,配置cuda8.0,但是安装nvidia驱动真的是把我难倒了,看了很多篇博文都没有效果,现在我自己重新总结了下几种 安装方法(亲测有效),希望能帮到大…
IE下javascript的console方法
IE下javascript的console方法 FireFox 和 Chrome 下调试JS都有console,IE6下没有。特用此办法来兼容IE6. <br /><pre lang‘‘html‘‘> <!doctype html> <html> <head> <meta charset‘‘utf-8‘‘/> </head> <body&…
图像配准----RANSAC
对角点进行初始匹配后,所选定的角点并不能保证全部是正确的点,也可能有误点,因此,还需要进一步对所选定的角点进行精确匹配。 RANSAC(RANdom Sample And Consensus)方法是由Fischler和Bolles提出的一种鲁棒性的参数估计方法。它的…

教你用OpenCV实现机器学习最简单的k-NN算法
前言:OpenCV 的构建是为了提供计算机视觉的通用基础接口,现在已经成为经典和最优秀的计算机视觉和机器学习的综合算法工具集。作为一个开源项目,研究者、商业用户和政府部门都可以轻松利用和修改现成的代码。k-NN算法可以认为是最简单的机器学…
div 相同属性提取
把样式名或id写在一起,用逗号隔开 <!DOCTYPE html><html lang"en"><head> <meta charset"UTF-8"> <title>信息详情</title> <style type"text/css"> #box-1, #box-2, #box…
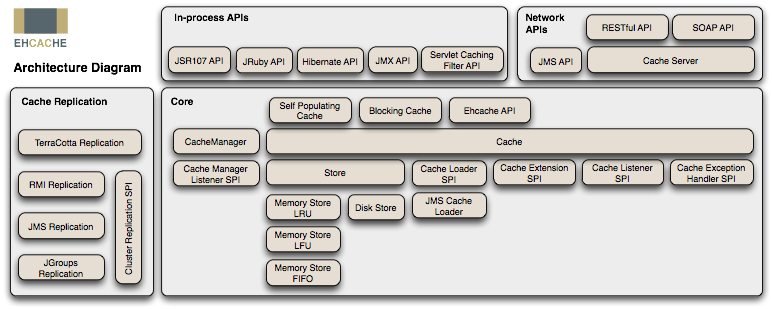
ehcache 简介
hCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。 下图是 Ehcache 在应用程序中的位置: ehcache部署起来很简单,主要分两步: 1.首先要给他写个核心配置XML文件 <ehca…
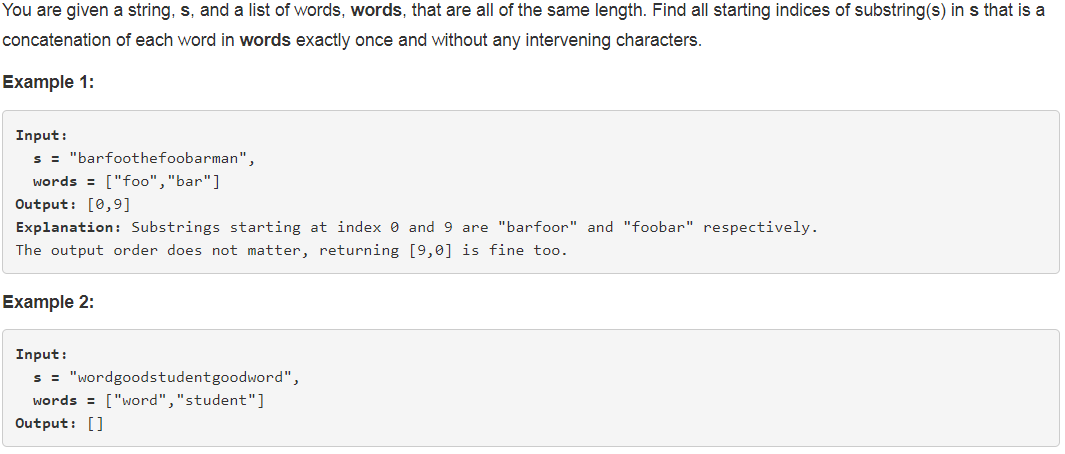
【leetcode】30. Substring with Concatenation of All Words
题目如下: 解题思路:本题题干中有一个非常关键的前提,就是words中的所有word的长度一样,并且都要被使用到。所以,我们可以把输入的s按word的长度进行等分,以s "barfoothefoobarman",words [&qu…
图像配准----SIFT
SIFT算子(Scale Invariant Feature Transform)是David Lowe提出的一种基于尺度空间的、对图像缩放、旋转甚至仿射变换保持不变性的图像局部特征描述算子。SIFT特征提取的是极其细微、大量的特征点,即时少数物体、物体的一小部分也可以产生大量特征向量。 SIFT算法如…

终于把微软BING搜索-SPTAG算法的原理搞清了
作者 | beyondma转载自 CSDN 博客近日,微软在GitHub上开源了其BING的搜索算法SPTAG,github地址:https://github.com/microsoft/SPTAG。这个算法笔者简单看了一下,的确是很有价值可以看大家介绍下,这种称为SPTAG &#…
把握每天的第一个钟头
当我十七岁的时候,我读到一段话,它是这么说的:“如果你把每天都当做最后一天来活着,那么有一天你将会是对的。”这句话让我留下了深刻的印象,从那时候开始,过去的 33 年来,我每天早上都对着镜子…
向量叉积计算法
如果向量A为{a, b, c},向量B为{m, n, p},如何计算向量A与向量B的叉积呢? 用行列式: |i j k| |a b c| |m n p| (bp-cn)i (mc-pa)j (an-bm)k 例如用matlab实现两个向量的叉积: a [1 2 3]; …

你是个成熟的C位检测器了,应该可以自动找C位了
作者 | 李翔转载自视说AI(ID:techtalkai)写在前面C位是近年网络上一个比较热门的词,最早来源于DOTA等游戏领域,是核心位置(Carry位)的简称,代表的是能够在游戏前中期打钱发育并在游戏后期带领队…
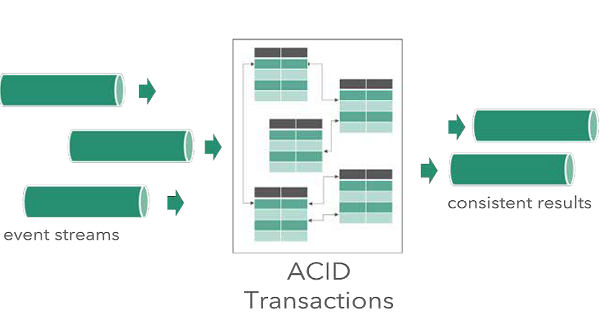
Data Artisans发布支持ACID事务的流式处理框架Streaming Ledger
data Artisans宣布推出Streaming Ledger,它扩展了Apache Flink,提供了跨表、键和事件流执行可序列化ACID事务的功能。这项正在申请专利的技术是Flink的专有附加技术,超越了当前一次只能在一个键上实现一致性的标准。\\在发布Streaming Ledger…

The Life Cycle of a Servlet
为什么80%的码农都做不了架构师?>>> Servlet的生命周期由Servlet容器管理,包含如下几个步骤: 1. 装载Servlet类; 2. 创建Servlet的实例; 3. 调用Servlet的init()方法; 4. 调用Servlet的service()方法; 5. 调用Servlet的destroy()…
矩阵奇异值分解
转自:http://www.madio.net/forum-redirect-goto-nextnewset-tid-47409.html 奇异值分解是线性代数中一种重要的矩阵分解,在信号处理、统计学等领域有重要应用。定义:设A为m*n阶矩阵,AHA的n个特征值的非负平方根叫作A的奇异值。记…
智课雅思词汇---十、pend是什么意思
智课雅思词汇---十、pend是什么意思 一、总结 一句话总结:【词根含义】:悬挂,垂;称量;支付 词根:-pend-, -pens- 【词根含义】:悬挂,垂;称量;支付 【词根来源】:来源于拉丁语动词pendeo, pendere, pependi, - (悬挂,下…

新技术“红”不过十年,半监督学习为什么是个例外?
作者 | 严林来源 | 授权转载自知乎(ID:严林)这一波深度学习的发展,以2006年Hinton发表Deep Belief Networks的论文为起点,到今年已经超过了10年。从过往学术界和产业界对新技术的追捧周期,超过10年的是极少数。从深度学…
常用Linux路由命令(route、ip、ifconfig等等)
第一组命令: ifconfig, ifup, ifdown 1) ifconfig 作用:手动启动、观察与修改网络接口的相关参数,包括IP地址以及MTU大小等。 例1.1:暂时修改IP地址 # ifconfig eth0 192.168.100.100 例1.2:修改IP地址、掩码和MTU # i…
洛谷P1074 靶形数独(跳舞链)
传送门 坑着,等联赛之后再填(联赛挂了就不填了233) 1 //minamoto2 #include<iostream>3 #include<cstdio>4 #include<cstring>5 using namespace std;6 #define getc() (p1p2&&(p2(p1buf)fread(buf,1,1<<21,…

直播写代码|英伟达工程师亲授如何加速YOLO目标检测
NVIDIA TensorRT是一种高性能深度学习推理优化器和运行时加速库,可以为深度学习推理应用程序提供低延时和高吞吐量。通过TensorRT,开发者可以优化神经网络模型,以高精度校对低精度,最后将模型部署到超大规模数据中心、嵌入式平台或…
OpenCV的cvLoadImage函数
转自:http://lijian2005lj.blog.163.com/blog/static/2569113720091111104856644/ 一直不太懂得cvLoadImage的第二个参数,今天知道,原来第二个参数是指定读入图像的颜色和深度。 指定的颜色可以将输入的图片转为3信道(CV_LOAD_IMAGE_COLOR)也…