你是个成熟的C位检测器了,应该可以自动找C位了

作者 | 李翔
转载自视说AI(ID:techtalkai)
写在前面
C位是近年网络上一个比较热门的词,最早来源于DOTA等游戏领域,是核心位置(Carry位)的简称,代表的是能够在游戏前中期打钱发育并在游戏后期带领队伍力挽狂澜的角色。现在C位一词逐渐扩大到了娱乐圈乃至我们的生活中,在社交、表演、比赛以及各种日常活动场景中,只要当某一个人在人群中处于中心位置,即最重要的人,大家便称呼他是C位(Center位)。

在包含众多人像的照片中,由于每个人的穿着和动作各异,同时人与人之间存在各种交互信息,以及所处的场景不同,我们通过肉眼来确定C位的时候可能会出现各种偏差。在人工智能快速发展的今天,我们能否可以通过AI来自动找出C位呢?答案当然是肯定的。在这篇文章中,我们将介绍如何利用计算机视觉和深度学习技术构建一个性能优异的C位检测器,从而快速准确地在一群人中发现真正站C位的那个最重要的人。
C位检测器前传
C位检测器的目标是检测出一群人中最重要的人。一般来说,C位检测器主要由两部分组成,第一部分是人脸/全身检测模型,通过该模型首先检测出照片中的所有人像;第二部分是人像重要性预测模型,通过该模型对检测出的每个人像计算重要性得分,重要性得分最高的人即为C位。
当前的人脸/全身检测模型的性能已经比较理想,而人像重要性预测模型还处在研究和探索阶段,所以下面我们的内容将主要围绕如何量化一群人中每个人的重要性展开。

最直接的人像重要性计算可以基于照片中人像所处的位置和面积进行设计,例如,离照片中心点越近则重要性越高,人像的面积越大则重要性越高等等。然而我们判断一个人是不是C位,除了利用照片中人像所处的位置和面积这类人像自身的几何信息外,还会根据照片上的各种信息综合判断:人像自身的外表信息(上图(a))、与其他人之间的关系信息(上图(b))以及所处的全局场景信息(上图(c))。
人与人之间的关系和人与场景之间的关系对C位的判断起到关键性作用。如果我们只利用人像的自身特征进行重要性计算,例如上图(a)中的红框女性,我们其实无法知道她是否是照片中最重要的人。但我们通过她与周围人之间和与整体场景之间的关系信息分析便可以得出她是C位的结论。
一个理想的人像重要性预测模型应根据上面提到的各方面信息进行联合计算。如何提取照片上丰富的多元化信息?如何对人与人之间和人与场景之间的关系建模,从而获取高层次的语义信息?如何最终根据照片上人像的多元化信息和高层次语义信息的特征进行重要性评估?这些都是摆在我们面前的问题,需要我们去一一解决。
一个出色的C位检测器
为了解决上节末提出的三个问题,我们实验室的小伙伴们攻坚克难,提出了一种全新而高效的人像重要性预测模型,构建了一个出色的C位检测器,相关工作发表在CVPR 2019。下面我们对其中的模型框架和建模思路进行一一介绍,希望给大家带来更多的启发和思考。
整个人像重要性预测模型分为三个模块,分别是特征表达模块、关系计算模块和重要性分类模块。特征表达模块能够有效地提取照片中每个人的自身特征和整张照片的全局场景特征。关系计算模块能够对人与人之间和人与场景之间的关系进行建模。重要性分类模块能够计算每个人像的重要性得分,从而最终识别出最重要的C位人选。完整的模型框架如下图所示。

特征表达模块针对上节末“如何提取照片上丰富的多元化信息?”这一问题进行设计。为了充分地获取人像自身丰富的特征表达,人像的外表信息和几何信息都会进行特征提取。深度卷积神经网络被用来实现提取流程,如下图所示。其中,外表信息被分为内在(绿框)和外在(蓝框)两部分,内在区域更多提取人像固有的外表信息,外在区域更多用于提取人像外表以及与周围环境的上下文信息,从而保证了人像信息的多元化。此外整张照片的全局场景信息(黄框)也会通过卷积神经网络实现特征提取。
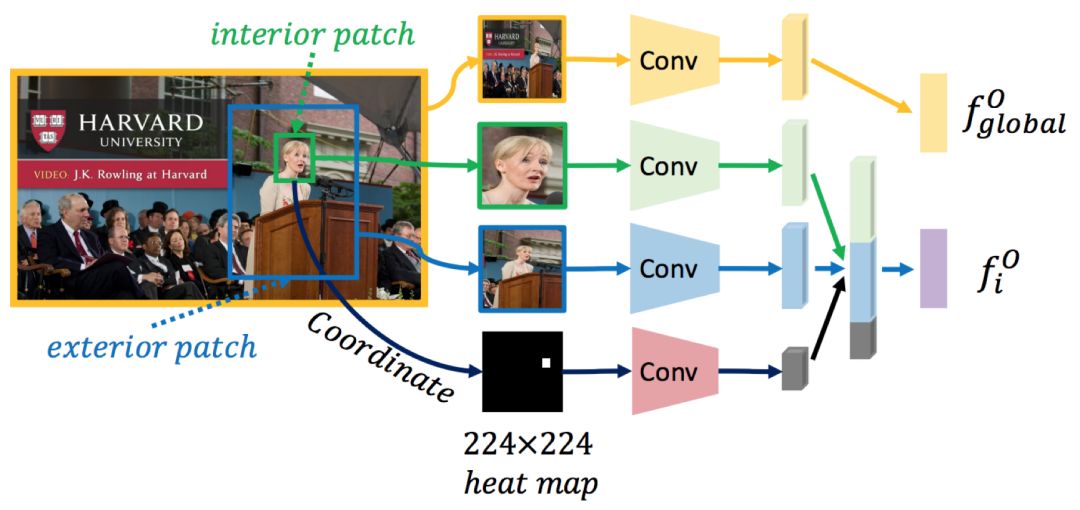
关系计算模块针对上节末“如何对人与人之间和人与场景之间的关系建模,从而获取高层次的语义信息?”这一问题进行设计,是整个模型中最关键的模块。在该模块中,关系网络(Relation Networks)被用来对在特征表达模块中提取的人像特征和场景特征进行关系建模。关系网络能够在没有额外监督信息的前提下,自动学习人与人之间和人与场景之间的关系,从而提取更高层次的语义信息以表征人在场景中的重要性。具体会分别建立人与人之间的关系图和人与场景之间的关系图,通过多个并行的关系网络提取关系特征并连接,再与原有的人像特征相加,得到最终的特征表达。
重要性分类模块针对上节末“如何最终根据照片上人像的多元化信息以及高层次语义信息的特征进行重要性评估?”这一问题进行设计。通过对在关系计算模型中提取的每个人像的最终特征表达进行重要/不重要的二分类,将每个人像被分为重要这个类别的概率作为重要性得分,得分最高的人像就是模型认定的C位。

以上三个模块一起实现了端到端的人像重要性训练和预测。最后我们来看一看利用上述模型进行C位检测的可视化结果。红框代表的是模型检测出来的C位,绿框代表的是当前其他最好方法的检测结果,可以看出在充分考虑了照片中人与人之间和人与场景之间的关系信息后,在各种复杂场景下,AI均能够准确地检测出真正的C位。
写在最后
C位检测可以自动快速地在人群中找出最重要的那个人。通过这篇文章,我们介绍了利用AI进行C位检测的一般流程和遇到的挑战,也进一步分享了一种优秀的C位检测器的构建思路与过程。其中的更多细节大家可以在arXiv上搜索《Learning to Learn Relation for Important People Detection in Still Images》进行查看。最后祝大家都能在各自的领域内不断进步,实现自我价值,站上属于自己的C位。
作者简介
李翔,国内某互联网大厂AI民工,前携程酒店图像技术负责人,计算机视觉和深度学习重度爱好者。
一些资料
[1] Learning to learn relation for important people detection in still images
[2] Personrank: Detecting important people in images
[3] Relation networks for object detection
(*本文为 AI科技大本营转载文章,转载请联系作者)
◆
公开课精彩推荐
◆
本次课程将会介绍如何利用TensorRT加速YOLO目标检测,课程将会着重介绍编程方法。本次课程还会涉及到 TensorRT 中数据类型,流处理,多精度推理等细节的展示。本次课程特色是讲解+示例分享。本次课程中,QA也是一个非常精彩的环节。


推荐阅读
拍照技术烂?实时在线AI构图模型VPN,让你变身摄影大神!
继往开来!目标检测二十年技术综述
阿里巴巴杨群:高并发场景下Python的性能挑战
为Python回测代码提升10倍性能,具体做了哪些?
鸿蒙将至,安卓安否?
面试阿里,我还是挂在了第四轮……
独家对话V神! 质疑之下的以太坊路在何方?
那些去德国的程序员后来怎么样了?
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:
Data Artisans发布支持ACID事务的流式处理框架Streaming Ledger
data Artisans宣布推出Streaming Ledger,它扩展了Apache Flink,提供了跨表、键和事件流执行可序列化ACID事务的功能。这项正在申请专利的技术是Flink的专有附加技术,超越了当前一次只能在一个键上实现一致性的标准。\\在发布Streaming Ledger…

The Life Cycle of a Servlet
为什么80%的码农都做不了架构师?>>> Servlet的生命周期由Servlet容器管理,包含如下几个步骤: 1. 装载Servlet类; 2. 创建Servlet的实例; 3. 调用Servlet的init()方法; 4. 调用Servlet的service()方法; 5. 调用Servlet的destroy()…

矩阵奇异值分解
转自:http://www.madio.net/forum-redirect-goto-nextnewset-tid-47409.html 奇异值分解是线性代数中一种重要的矩阵分解,在信号处理、统计学等领域有重要应用。定义:设A为m*n阶矩阵,AHA的n个特征值的非负平方根叫作A的奇异值。记…
智课雅思词汇---十、pend是什么意思
智课雅思词汇---十、pend是什么意思 一、总结 一句话总结:【词根含义】:悬挂,垂;称量;支付 词根:-pend-, -pens- 【词根含义】:悬挂,垂;称量;支付 【词根来源】:来源于拉丁语动词pendeo, pendere, pependi, - (悬挂,下…

新技术“红”不过十年,半监督学习为什么是个例外?
作者 | 严林来源 | 授权转载自知乎(ID:严林)这一波深度学习的发展,以2006年Hinton发表Deep Belief Networks的论文为起点,到今年已经超过了10年。从过往学术界和产业界对新技术的追捧周期,超过10年的是极少数。从深度学…
常用Linux路由命令(route、ip、ifconfig等等)
第一组命令: ifconfig, ifup, ifdown 1) ifconfig 作用:手动启动、观察与修改网络接口的相关参数,包括IP地址以及MTU大小等。 例1.1:暂时修改IP地址 # ifconfig eth0 192.168.100.100 例1.2:修改IP地址、掩码和MTU # i…
洛谷P1074 靶形数独(跳舞链)
传送门 坑着,等联赛之后再填(联赛挂了就不填了233) 1 //minamoto2 #include<iostream>3 #include<cstdio>4 #include<cstring>5 using namespace std;6 #define getc() (p1p2&&(p2(p1buf)fread(buf,1,1<<21,…

直播写代码|英伟达工程师亲授如何加速YOLO目标检测
NVIDIA TensorRT是一种高性能深度学习推理优化器和运行时加速库,可以为深度学习推理应用程序提供低延时和高吞吐量。通过TensorRT,开发者可以优化神经网络模型,以高精度校对低精度,最后将模型部署到超大规模数据中心、嵌入式平台或…
OpenCV的cvLoadImage函数
转自:http://lijian2005lj.blog.163.com/blog/static/2569113720091111104856644/ 一直不太懂得cvLoadImage的第二个参数,今天知道,原来第二个参数是指定读入图像的颜色和深度。 指定的颜色可以将输入的图片转为3信道(CV_LOAD_IMAGE_COLOR)也…
DX11 preprocessor Dynamic shader linkage
(参照例子DXSDK sample:DynamicShaderLinkage11) 一、preprocessor 实现shader静态分支的经典方法,代码示例如下 shader中(如果显卡不支持DX11,则STATIC_PERMUTE为True): #if !defined( STATIC_PERMUTE )iB…
OpenCV中与matlab中相对应的函数
1、matlab中的imread相当于OpenCV中的cvLoadImage(imageName, CV_LOAD_IAMGE_ANYDEPTH | CV_LOAD_IMAGE_ANYCOLOR):读出的图像信息保持了原有图像的信息(包括通道信息和位深信息); rgb2gray相当于cvLoadImage(imageName, CV_LOAD_IMAGE_GRAYSCALE)&…

AI假新闻满天飞,打假神器GROVER帮你看清一切
最近AI换脸术与AI假新闻叠加在一起,造成了不少乌龙事件,比如最近美国的议长南希佩洛西就的一段醉酒视频就在Facebook上流传甚广,视频中的议长明显是状态晕沉,醉意十足,不过这后来被证明是一段是由deepfake生成的假视频…
NYOJ 93
汉诺塔(三) 时间限制:3000 ms | 内存限制:65535 KB难度:3描述在印度,有这么一个古老的传说:在世界中心贝拿勒斯(在印度北部)的圣庙里,一块黄铜板上插着三根宝…
C/C++中二维数组作函数形参时,调用函数时,可传递的实参类型的小结
转自:http://blog.163.com/tianhityeah/blog/static/165747821201052195212719/ #include<iostream>using namespace std;int fun(int a[][3],int n) // 其中二维数组形参必须确定数组的第二维的长度,第一维长度可以不定//int fun(int (*a)[…

打破欧美垄断,国防科大斩获“航天界奥林匹克”大赛首冠
整理 | Jane责编 | 一一出品 | AI科技大本营(id:rgznai100)近日,第十届国际空间轨道设计大赛(GTOC X)结束并公布最终成绩,中国参赛队国防科技大学与西安卫星测控中心联队(NUDT&X…
Hive 中的变量
Hive的变量前面有一个命名空间,包括三个hiveconf,system,env,还有一个hivevar hiveconf的命名空间指的是hive-site.xml下面的配置变量值。system的命名空间是系统的变量,包括JVM的运行环境。env的命名空间,…
你必须非常努力,才能看起来毫不费力
有一群人,他们积极自律,每天按计划行事,有条不紊;他们不张扬,把自己当成最卑微的小草,等待着人生开出花朵的那天。他们早晨5点多起来健身,你在睡觉;7点开始享受丰盛的早餐࿰…
cvGetSubRect与cvMul用法
1、对于cvGetSubRect(mat1, mat2, rect),当用cvGetSubRect函数时,不能事先对mat2申请内存,否则会产生内存泄漏。 只要这样定义mat2即可:CvMat *mat2; mat2 cvCreateMatHeader(imgHeight, imgWidth, CV_64FC1); 2、对于cvGetSubR…
浅谈WPF的VisualBrush
原文:浅谈WPF的VisualBrush首先看看VisualBrush的解释,msdn上面的解释是使用 Visual 绘制区域,那么我们再来看看什么是Visual呢?官方的解释是:获取或设置画笔的内容,Visual 是直接继承自DependencyObject,U…

AI换脸技术再创新高度,DeepMind发布的VQ-VAE二代算法有多厉害?
作者 | beyondma转载自CSDN网站近日DeepMind发布VQ-VAE-2算法,也就是之前VQ-VAE算法2代,这个算法从感观效果上来看比生成对抗神经网络(GAN)的来得更加真实,堪称AI换脸界的大杀器,如果我不说,相信读者也很难…
cisco设备常用命令
router> enable 从用户模式进入特权模式 router# disable or exit 从特权模式退出到用户模式router# show sessions 查看本机上的TELNET会话router# disconnect …

opencv图像处理梯度边缘和角点
转自:http://blog.sina.com.cn/s/blog_4b9b714a0100c9f7.html 梯度、边缘和角点 Sobel 使用扩展 Sobel 算子计算一阶、二阶、三阶或混合图像差分 void cvSobel( const CvArr* src, CvArr* dst, int xorder, int yorder, int aperture_size3 ); src 输入图像. dst …

性能全面超数据库专家,腾讯提基于机器学习的性能优化系统 | SIGMOD 2019
腾讯与华中科技大学合作的最新研究成果入选了国际数据库顶级会议SIGMOD的收录论文,并将于6月30日在荷兰阿姆斯特丹召开SIGMOD 2019国际会议上公开发表。入选论文的题目为“An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforcement Learning…
swift 语言评价
杂而不精,一团乱麻!模式乱套,不适合作为一门学习和研究语言。 谢谢 LZ 介绍,看完之后更不想用 Swift 了。从 C那里抄个 V-Table 来很先进嘛?别跟 C一样搞什么 STL 就好了,整这么复杂,入个门都需…
Creative Web Typography Styles | Codrops
Creative Web Typography Styles | Codrops. 非常好的文字效果

OpenCV 图像采样 插值 几何变换
转自:http://hi.baidu.com/xiaoduo170/blog/item/6eefc612c9f8e9c6c2fd786f.html InitLineIterator 初始化线段迭代器 int cvInitLineIterator( const CvArr* image, CvPoint pt1, CvPoint pt2, CvLineIterator* line_iterator, int connectivity8 ); image 带采…
centos 6.* 修改时间
一、查看Centos的时区和时间 1、使用date命令查看Centos时区 [rootVM_centos ~]# date -R Mon, 26 Mar 2018 19:14:03 0800 2、查看clock系统配置文件 [rootVM_centos ~]# cat /etc/sysconfig/clock ZONE"Asia/Shanghai" 3、查看系统的硬件时间,即BIOS时间…

别光发Paper,搞点实际问题
文 / LVS话说几个月前,我参加了一场学术大会,台上的教授不是北大、清华就是浙大、上交大,几位教授不约而同的吐槽招通信、算法和编解码的学生太难了。为什么呢?原来,先不比金融,仅仅与同是IT领域的AI专业就…
spring mvc文件上传小例子
spring mvc文件上传小例子 1.jsp页面 <%page contentType"text/html;charsetUTF-8"%> <%page pageEncoding"UTF-8"%> <% taglib prefix"c" uri"http://java.sun.com/jsp/jstl/core"%> <% taglib prefix"fmt…

解密Kernel:为什么适用任何机器学习算法?
作者 | Marin Vlastelica Pogančić译者 | 陆离编辑 | 一一出品 | AI科技大本营(ID:rgznai100)机器学习中Kernel的秘密(一)本文探讨的不是关于深度学习方面的,但可能也会涉及一点儿,主要是因为…