50行代码教AI实现动作平衡 | 附完整代码

作者 | Mike Shi
译者 | linstancy
责编 | Jane
出品 | AI科技大本营(id:rgznai100)

【导读】本文将为大家展示如何通过 Numpy 库和 50行 Python 代码,使用标准的 OpenAI Gym平台创建智能体 (agent),就教会机器处理推车杆问题 (cart pole problem) ,保持平衡。
推车杆问题 (cart pole problem) ,大家可以类比好像在手指尖上垂直平衡铅笔一样,需要通过左右推动来平衡车顶部的杆,这是个非常具有挑战性的问题!
今天,我们不过多的讨论强化学习的基础理论,希望大家在下面的编译器里,不断尝试,体会这个项目。一开始,大家只需要点击“Start”,开始配置需要的环境即可。

快速入门强化学习 (RL)
如果你是机器学习或强化学习领域的新人,先了解一下下面的一些基础知识和术语,为后面做铺垫。如果你已经掌握了基础知识,那可以跳过这部分内容。
强化学习
强化学习旨在教会我们的智能体 (算法或机器) 执行特定的任务或动作,而无需显式地告诉它该如何做。想象一个婴儿在随机抬动自己的腿,当站立起来时就给予他一个奖励。同样地,智能体的目标是在其生命周内最大化奖励值,而奖励取决于特定的任务。比如宝宝站立这个例子,站立时给予奖励记为1,否则记为0。
AlphaGo 就是一个典型的强化学习智能体例子,教会智能体如何玩游戏并最大化其奖励 (即赢得游戏)。而在本文中就将创建一个智能体,教它如何通过左右推动推车来解决推车上的杆平衡问题。
状态

状态即当前游戏的样子,通常用数字来表示。在乒乓球比赛中,它可能是每个球拍与x、y坐标轴的垂直位置或者是乒乓球的速度。在推车杆的情况下,这里的状态由4个数字组成:即推车的位置,推车的速度,杆的位置 (作为角度) 和杆的角速度。这4个数字作为向量 (或数组) 提供给智能体,这非常重要:将状态作为一组数字意味着智能体能够对它进行一些数学运算,以便决定如何根据状态来采取什么行动。
策略
策略是一种可以处理游戏状态的函数 (例如棋盘的位置或者推车和杆的位置), 并输出智能体在该位置应该采取的动作 (例如移动或将推车推到左边)。在智能体采取相应的操作后,游戏将以下一个状态更新,此时将再次根据其输入策略做出决策,这个过程一直持续到游戏达到某个终止条件时结束。策略同样是个非常关键的因素,因为它反映了是智能体背后的决策能力,这也是我们所需要认真考虑的。
点积 (dot product)
两个数组 (向量) 之间的点积可以简单理解为,将第一个数组的每个元素乘以第二个数组的对应元素,并将它们全部加在一起。假设想要计算数组 A 和 B 的点积,形如 A[0]*B[0]+A[1]*B[1] ......随后将使用此运算结果再乘以一个状态 (同样是一个向量) 和一个策略值 (同样也是一个向量)。这部分内容将在下一节详细介绍。
制定策略
为了解决推车游戏,我们希望所设计的机器学习策略能够赢得游戏或最大化游戏奖励。对于智能体而言,这里将接收4维数组所表示策略,每一维代表每个组成的重要性 (推车的位置,杆位等四个组成)。随后,再将点积的结果与策略、状态向量进行处理并输出最终的结果。根据结果的正负值决定是向左还是向右推动推车。这听起来可能有点抽象,下面就通过一个具体的例子,来看看整个过程将发生什么。
假设推车在游戏中静止地处在中间位置,当杆向右倾斜时车也将向右倾斜,如下图这样:

所对应的的状态如下图所示:

此时的状态向量为 [0, 0, 0.2, 0.05]。直观地说,现在我们想要将推车推向右侧,并将杆拉直。这里通过训练中得到了一个很好的策略,即 [-0.116, 0.332, 0.207, 0.352]。将上面的状态向量与策略向量进行点积处理,如果得到的结果为正,则将推车向右推动;反之则向左推动。

显然,这里的输出是个正数,这意味着在这种策略下智能体将推车向右推动,这也正是我们想要的结果。那么,该如何得到这个策略向量呢,以便智能体能够朝着我们希望的方向推动?或者说如果随机选择一个策略,那么智能体又该如何行动呢?
开始编辑
在该项目主页 repl.it 上弹出一个 Python 实例。repl.it允许用户快速启动大量不同编程环境的云实例环境并在强大云编译器 (IDE) 中编辑代码,这个强大的 IDE 能在任何地方访问,如下图所示。

安装所需的包
安装这个项目所需的两个软件包:numpy 用于帮助数值计算,而 OpenAI Gym 则作为智能体的模拟器。如下图所示,只需在编辑器左侧的包搜索工具中输入 gym 和 numpy,然后单击加号按钮即可安装这两个包。

创建基础环境
这里首先将刚安装的两个依赖包导入到 main.py 脚本中并设置一个新的 gym环境。随后定义一个名为 play 的函数,该函数将被赋予一个环境和一个策略向量,在环境中执行策略向量并返回分数以及每个时间步的游戏观测值。最后,将通过分数高低来反映策略的效果好坏,以及在单次游戏中策略的表现。如此,就可以测试不同的策略,查看他们在游戏中的表现!
import gym
import numpy as np env = gym.make('CartPole-v1')下面从函数定义开始,将游戏重置为开始状态,如下所示。
def play(env, policy): observation = env.reset()接着初始化一些变量,用来跟踪游戏是否达到终止条件,策略得分以及游戏中每个步骤的观测值,如下所示。
done = False score = 0 observations = []现在,只需要一些时间步来开始游戏,直到 gym 提示游戏结束为止。
for _ in range(5000): observations += [observation.tolist()] # Record the observations for normalization and replay if done: # If the simulation was over last iteration, exit loop break # Pick an action according to the policy matrix outcome = np.dot(policy, observation) action = 1 if outcome > 0 else 0 # Make the action, record reward observation, reward, done, info = env.step(action) score += reward return score, observations如下,这部分的代码主要是用于开始游戏并记录结果,而与策略相关的代码就是这两行:
outcome = np.dot(policy, observation) action = 1 if outcome > 0 else 0在这里所做的只是对策略向量和状态 (观测) 数组之间进行点积运算,就像在之前具体例子中所展现的那样。随后根据结果的正负,选择1或0 (向左或右) 的动作。到这里为止,main.py 脚本如下所示:
import gym
import numpy as np env = gym.make('CartPole-v1') def play(env, policy): observation = env.reset() done = False score = 0 observations = [] for _ in range(5000): observations += [observation.tolist()] # Record the observations for normalization and replay if done: # If the simulation was over last iteration, exit loop break # Pick an action according to the policy matrix outcome = np.dot(policy, observation) action = 1 if outcome > 0 else 0 # Make the action, record reward observation, reward, done, info = env.step(action) score += reward return score, observations
下面开始寻找该游戏的最优策略!
第一次游戏
现在已经有了一个函数,用来反映策略的好坏。因此,接下来要做的事开始制定一些策略,并查看他们的表现如何。如果一开始你想尝试一些随机的策略,那么这些策略的结果将会怎样呢?这里使用 numpy 来随机生成一些的策略,这些策略都是4维数组或1x4矩阵,即选择4个0到1之间的数字作为游戏的策略,如下所示。
policy = np.random.rand(1,4)有了这些策略以及上面所创建的环境,下面就可以开始游戏并获得策略分数:
score, observations = play(env, policy)
print('Policy Score', score)只需点击运行即可开始游戏,它将输出每个策略所对应的得分,如下所示。

最后,所有的策略获得的最高得分为500,在这里随机生成的策略可能并不能得到太好的结果,而且通过随机生成的方式,很难解释智能体是如何进行游戏的。下一步将介绍如何选择并设置游戏的策略,来查看智能体的游戏表现。
观察我们的智能体
这里使用 Flask 来设置轻量级服务器,以便可以在浏览器中查看智能体的表现。 Flask 是一个轻量级的 Python HTTP 服务器框架,可以为 HTML UI 和数据提供服务。由于渲染和 HTTP 服务器背后的细节对智能体的训练并不重要,在这里只是简单介绍下。首先需要将 Flask 安装为 Python 包,就像上面安装 gym 和 numpy 包一样,如下所示。

接下来,在脚本的底部创建一个 flask 服务器,它将在 /data 端点上公开游戏的每个帧的记录,并在 / 上托管 UI,如下所示。
from flask import Flask
import json
app = Flask(__name__, static_folder='.')
@app.route("/data")
def data(): return json.dumps(observations)
@app.route('/')
def root(): return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')此外,还需要添加两个文件:一个是项目的空白 Python 文件,这是 repl.it 用于检测 repl 是处于评估模式还是项目模式的关键。这里只需使用新文件按钮添加空白的 Python 脚本即可。随后,还需要创建一个将承载渲染 UI 的 index.html 文件。在此不需要深入了解这部分的内容,只需将此 index.html 上传到 repl.it 项目即可。
好了,现在的项目目录应该像这样,如下所示:

有了这两个新文件,当运行 repl 时它将回放所选择的游戏策略,便于我们寻找一个最优的策略。

策略搜索
在第一次游戏中只是通过 numpy 为智能体随机生成一些策略并开始游戏。那么,如何选择一些游戏策略,并在游戏结束时只保留那个结果最好的策略呢?在这里,制定游戏时并不只是生成一个策略,而是通过编写一个循环来生成一些策略,跟踪每个策略的执行情况并在最后保存最佳的策略。
首先创建一个名为 max 的元组,它将存储游戏过程所出现的最佳策略得分、观测和策略数组,如下所示。
max = (0, [], [])
接下来将生成并评估10个策略,并将得分最大值的策略保存。此外,这里还需要在 /data 端点返回最佳策略的重放,如下所示。
for _ in range(10): policy = np.random.rand(1,4) score, observations = play(env, policy) if score > max[0]: max = (score, observations, policy) print('Max Score', max[0])此外,这个端点:
@app.route("/data")
def data(): return json.dumps(observations) 应改为:
@app.route("/data")
def data(): return json.dumps(max[1])最后 main.py 脚本应像这样,如下图所示:
import gym
import numpy as np
env = gym.make('CartPole-v1')
def play(env, policy): observation = env.reset() done = False score = 0 observations = [] for _ in range(5000): observations += [observation.tolist()] # Record the observations for normalization and replay if done: # If the simulation was over last iteration, exit loop break # Pick an action according to the policy matrix outcome = np.dot(policy, observation) action = 1 if outcome > 0 else 0 # Make the action, record reward observation, reward, done, info = env.step(action) score += reward return score, observations
max = (0, [], [])
for _ in range(10): policy = np.random.rand(1,4) score, observations = play(env, policy) if score > max[0]: max = (score, observations, policy)
print('Max Score', max[0])
from flask import Flask
import json
app = Flask(__name__, static_folder='.')
@app.route("/data")
def data(): return json.dumps(max[1])
@app.route('/')
def root(): return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')如果现在运行 repl,正常情况所得到的最大分数应为500。如果没有的话,请再次尝试运行 repl! 通过这种方式,能够完美地观察游戏策略是如何让杆达到平衡的!
如何加速?
(1)这里智能体达到平衡的速度并不够块。回想前面制定策略时,首先只是在0到1范围内随机创建了策略数组,这恰好是有效的。但如果这里智能体翻转大于运算符所设定的那样,那么可能将看到灾难性的失败结果。可以尝试将 action> 0 if outcome>0 else 0 改为 action=1 if outcome<0 else 0。
效果似乎并没有很明显,这可能是因为如果恰好选择少于而不是大于,那么可能永远也找不到解决游戏的策略。为了缓解这种情况,在实际操作时也应该生成一些带负数的策略。虽然这将使得搜索一个好策略的过程变得更加困难 (因为包含许多负的策略并不好),但所带来的好处是不再需要通过特定算法来匹配特定游戏。如果尝试在 OpenAI gym 的其他环境中这样做,那么算法肯定会失败。
要做到这一点,不能使用 policy = np.random.rand(1,4),需要将改为 policy = np.random.rand(1,4) -0.5。如此,所生成的策略中每个数字都在-0.5到0.5之间,而不是0到1。但是由于这样做会使得最优策略的搜索过程变得困难,因此在上面的 for 循环中,不要迭代10个策略,更改这部分的代码尝试搜索100个策略 (for _ in range (100):)。当然,你也可以先尝试迭代10次,看看用负的策略获得最优策略的困难性。
好了,现在的 main.py 脚本可参考
https://gist.github.com/MikeShi42/e1c5551bbf2cb2064da962ad8b198c1b
如果现在运行 repl,无论使用的是否大于或小于,仍然可以找到一个好的游戏策略。
(2)不仅如此,即使所生成的策略可能能够在一次游戏中得到最高分500的结果,那它能够在每次游戏中都有这样的表现呢?当生成100个策略并选择在单次运行中表现最佳的策略时,该策略可能只是单次最佳策略,或者它可能是一个非常糟糕的策略,只是恰好在一次游戏中有非常好的性能。因为游戏本身具有随机性 (如起始位置每次都不同),因此策略可以只是在一个起始位置表现良好,而不是在其他位置。
因此,为了解决这个问题,需要评估一个策略在多次实验中的表现。现在就采取之前实验得到的最佳政策,查看它在100次游戏实验中的表现。在这里对最优策略进行100次游戏 (最大索引值为2) 并记录每次的游戏得分。随后使用 numpy 计算该策略的平均分数并将其打印到终端。你可能会注意到,最佳的游戏策略实际上并不一定是最优秀的。
总结
好了,以上已经成功创建了一个能够非常有效地解决推车杆问题的 AI 智能体。当然它还有很大的改进空间,这将是后续系列文章的一部分。此外,后续的工作还可以对一些问题展开研究:
寻找“真正的”最优策略 (即在100次独立游戏中表现良好)
优化最佳策略搜索所需的次数 (即样本效率问题)
选择正确搜索策略,而不是尝试随机地选择。
在其他的环境中创建。
原文地址:
https://towardsdatascience.com/from-scratch-ai-balancing-act-in-50-lines-of-python-7ea67ef717
(*本文为 AI科技大本营约稿文章,转载请微信联系 1092722531)
◆
公开课精彩推荐
◆
本次课程将会介绍如何利用TensorRT加速YOLO目标检测,课程将会着重介绍编程方法。本次课程还会涉及到 TensorRT 中数据类型,流处理,多精度推理等细节的展示。本次课程特色是讲解+示例分享。本次课程中,QA也是一个非常精彩的环节。


推荐阅读:
开源要自立?华为如何“复制”Google模式
谷歌用1.2万个模型“推翻”现有无监督研究成果!斩获ICML 2019最佳论文
24式,加速你的Python
荔枝“自由”?朋友,你实现了吗?
为防 Android 碎片化?Google 强迫开发者使用自有开发工具!
Docker 存储选型,这些年我们遇到的坑
从制造业转型物联网,看博世如何破界
回报率850%? 这个用Python优化的比特币交易机器人简直太烧脑了...
面试阿里技术岗,竟然挂在第4 轮……
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

图像配准----双向匹配
由Harris提取出的两幅图像的角点个数或对应关系并不是一一对应的。为了后续的配准,需要先对提取出的角点进行初始匹配,双向匹配方法是比较简单的一种方法,它实现容易。 设参考图像特征点集为X {x1, x2, …,xp}, p > 3;待配准图…
[专业亲测]Ubuntu16.04安装Nvidia显卡驱动(cuda)--解决你的所有困惑【转】
本文转载自: 因为要做毕设需要安装caffe2,配置cuda8.0,但是安装nvidia驱动真的是把我难倒了,看了很多篇博文都没有效果,现在我自己重新总结了下几种 安装方法(亲测有效),希望能帮到大…
IE下javascript的console方法
IE下javascript的console方法 FireFox 和 Chrome 下调试JS都有console,IE6下没有。特用此办法来兼容IE6. <br /><pre lang‘‘html‘‘> <!doctype html> <html> <head> <meta charset‘‘utf-8‘‘/> </head> <body&…
图像配准----RANSAC
对角点进行初始匹配后,所选定的角点并不能保证全部是正确的点,也可能有误点,因此,还需要进一步对所选定的角点进行精确匹配。 RANSAC(RANdom Sample And Consensus)方法是由Fischler和Bolles提出的一种鲁棒性的参数估计方法。它的…

教你用OpenCV实现机器学习最简单的k-NN算法
前言:OpenCV 的构建是为了提供计算机视觉的通用基础接口,现在已经成为经典和最优秀的计算机视觉和机器学习的综合算法工具集。作为一个开源项目,研究者、商业用户和政府部门都可以轻松利用和修改现成的代码。k-NN算法可以认为是最简单的机器学…
div 相同属性提取
把样式名或id写在一起,用逗号隔开 <!DOCTYPE html><html lang"en"><head> <meta charset"UTF-8"> <title>信息详情</title> <style type"text/css"> #box-1, #box-2, #box…
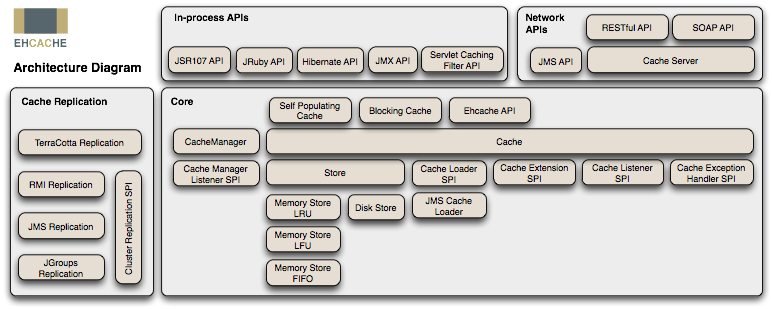
ehcache 简介
hCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。 下图是 Ehcache 在应用程序中的位置: ehcache部署起来很简单,主要分两步: 1.首先要给他写个核心配置XML文件 <ehca…
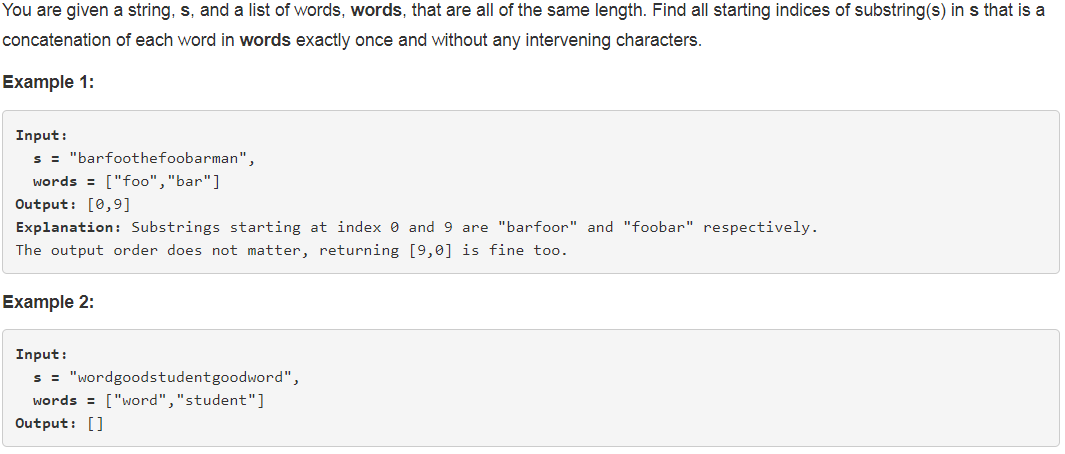
【leetcode】30. Substring with Concatenation of All Words
题目如下: 解题思路:本题题干中有一个非常关键的前提,就是words中的所有word的长度一样,并且都要被使用到。所以,我们可以把输入的s按word的长度进行等分,以s "barfoothefoobarman",words [&qu…
图像配准----SIFT
SIFT算子(Scale Invariant Feature Transform)是David Lowe提出的一种基于尺度空间的、对图像缩放、旋转甚至仿射变换保持不变性的图像局部特征描述算子。SIFT特征提取的是极其细微、大量的特征点,即时少数物体、物体的一小部分也可以产生大量特征向量。 SIFT算法如…

终于把微软BING搜索-SPTAG算法的原理搞清了
作者 | beyondma转载自 CSDN 博客近日,微软在GitHub上开源了其BING的搜索算法SPTAG,github地址:https://github.com/microsoft/SPTAG。这个算法笔者简单看了一下,的确是很有价值可以看大家介绍下,这种称为SPTAG &#…
把握每天的第一个钟头
当我十七岁的时候,我读到一段话,它是这么说的:“如果你把每天都当做最后一天来活着,那么有一天你将会是对的。”这句话让我留下了深刻的印象,从那时候开始,过去的 33 年来,我每天早上都对着镜子…
向量叉积计算法
如果向量A为{a, b, c},向量B为{m, n, p},如何计算向量A与向量B的叉积呢? 用行列式: |i j k| |a b c| |m n p| (bp-cn)i (mc-pa)j (an-bm)k 例如用matlab实现两个向量的叉积: a [1 2 3]; …

你是个成熟的C位检测器了,应该可以自动找C位了
作者 | 李翔转载自视说AI(ID:techtalkai)写在前面C位是近年网络上一个比较热门的词,最早来源于DOTA等游戏领域,是核心位置(Carry位)的简称,代表的是能够在游戏前中期打钱发育并在游戏后期带领队…
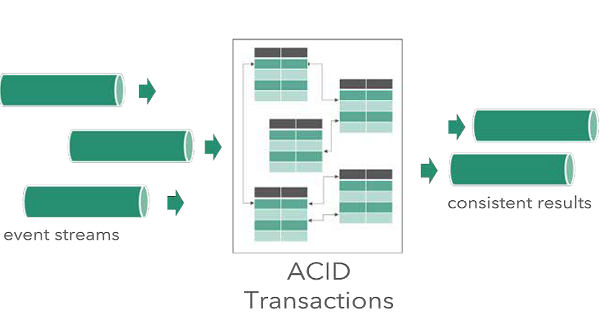
Data Artisans发布支持ACID事务的流式处理框架Streaming Ledger
data Artisans宣布推出Streaming Ledger,它扩展了Apache Flink,提供了跨表、键和事件流执行可序列化ACID事务的功能。这项正在申请专利的技术是Flink的专有附加技术,超越了当前一次只能在一个键上实现一致性的标准。\\在发布Streaming Ledger…

The Life Cycle of a Servlet
为什么80%的码农都做不了架构师?>>> Servlet的生命周期由Servlet容器管理,包含如下几个步骤: 1. 装载Servlet类; 2. 创建Servlet的实例; 3. 调用Servlet的init()方法; 4. 调用Servlet的service()方法; 5. 调用Servlet的destroy()…
矩阵奇异值分解
转自:http://www.madio.net/forum-redirect-goto-nextnewset-tid-47409.html 奇异值分解是线性代数中一种重要的矩阵分解,在信号处理、统计学等领域有重要应用。定义:设A为m*n阶矩阵,AHA的n个特征值的非负平方根叫作A的奇异值。记…
智课雅思词汇---十、pend是什么意思
智课雅思词汇---十、pend是什么意思 一、总结 一句话总结:【词根含义】:悬挂,垂;称量;支付 词根:-pend-, -pens- 【词根含义】:悬挂,垂;称量;支付 【词根来源】:来源于拉丁语动词pendeo, pendere, pependi, - (悬挂,下…

新技术“红”不过十年,半监督学习为什么是个例外?
作者 | 严林来源 | 授权转载自知乎(ID:严林)这一波深度学习的发展,以2006年Hinton发表Deep Belief Networks的论文为起点,到今年已经超过了10年。从过往学术界和产业界对新技术的追捧周期,超过10年的是极少数。从深度学…
常用Linux路由命令(route、ip、ifconfig等等)
第一组命令: ifconfig, ifup, ifdown 1) ifconfig 作用:手动启动、观察与修改网络接口的相关参数,包括IP地址以及MTU大小等。 例1.1:暂时修改IP地址 # ifconfig eth0 192.168.100.100 例1.2:修改IP地址、掩码和MTU # i…
洛谷P1074 靶形数独(跳舞链)
传送门 坑着,等联赛之后再填(联赛挂了就不填了233) 1 //minamoto2 #include<iostream>3 #include<cstdio>4 #include<cstring>5 using namespace std;6 #define getc() (p1p2&&(p2(p1buf)fread(buf,1,1<<21,…

直播写代码|英伟达工程师亲授如何加速YOLO目标检测
NVIDIA TensorRT是一种高性能深度学习推理优化器和运行时加速库,可以为深度学习推理应用程序提供低延时和高吞吐量。通过TensorRT,开发者可以优化神经网络模型,以高精度校对低精度,最后将模型部署到超大规模数据中心、嵌入式平台或…
OpenCV的cvLoadImage函数
转自:http://lijian2005lj.blog.163.com/blog/static/2569113720091111104856644/ 一直不太懂得cvLoadImage的第二个参数,今天知道,原来第二个参数是指定读入图像的颜色和深度。 指定的颜色可以将输入的图片转为3信道(CV_LOAD_IMAGE_COLOR)也…
DX11 preprocessor Dynamic shader linkage
(参照例子DXSDK sample:DynamicShaderLinkage11) 一、preprocessor 实现shader静态分支的经典方法,代码示例如下 shader中(如果显卡不支持DX11,则STATIC_PERMUTE为True): #if !defined( STATIC_PERMUTE )iB…
OpenCV中与matlab中相对应的函数
1、matlab中的imread相当于OpenCV中的cvLoadImage(imageName, CV_LOAD_IAMGE_ANYDEPTH | CV_LOAD_IMAGE_ANYCOLOR):读出的图像信息保持了原有图像的信息(包括通道信息和位深信息); rgb2gray相当于cvLoadImage(imageName, CV_LOAD_IMAGE_GRAYSCALE)&…

AI假新闻满天飞,打假神器GROVER帮你看清一切
最近AI换脸术与AI假新闻叠加在一起,造成了不少乌龙事件,比如最近美国的议长南希佩洛西就的一段醉酒视频就在Facebook上流传甚广,视频中的议长明显是状态晕沉,醉意十足,不过这后来被证明是一段是由deepfake生成的假视频…
NYOJ 93
汉诺塔(三) 时间限制:3000 ms | 内存限制:65535 KB难度:3描述在印度,有这么一个古老的传说:在世界中心贝拿勒斯(在印度北部)的圣庙里,一块黄铜板上插着三根宝…
C/C++中二维数组作函数形参时,调用函数时,可传递的实参类型的小结
转自:http://blog.163.com/tianhityeah/blog/static/165747821201052195212719/ #include<iostream>using namespace std;int fun(int a[][3],int n) // 其中二维数组形参必须确定数组的第二维的长度,第一维长度可以不定//int fun(int (*a)[…

打破欧美垄断,国防科大斩获“航天界奥林匹克”大赛首冠
整理 | Jane责编 | 一一出品 | AI科技大本营(id:rgznai100)近日,第十届国际空间轨道设计大赛(GTOC X)结束并公布最终成绩,中国参赛队国防科技大学与西安卫星测控中心联队(NUDT&X…
Hive 中的变量
Hive的变量前面有一个命名空间,包括三个hiveconf,system,env,还有一个hivevar hiveconf的命名空间指的是hive-site.xml下面的配置变量值。system的命名空间是系统的变量,包括JVM的运行环境。env的命名空间,…
你必须非常努力,才能看起来毫不费力
有一群人,他们积极自律,每天按计划行事,有条不紊;他们不张扬,把自己当成最卑微的小草,等待着人生开出花朵的那天。他们早晨5点多起来健身,你在睡觉;7点开始享受丰盛的早餐࿰…