BERT的成功是否依赖于虚假相关的统计线索?

作者 | 李理
来源 | 个人博客
导读:本文介绍论文Probing Neural Network Comprehension of Natural Language Arguments,讨论BERT在ACRT任务下的成绩是否依赖虚假的统计线索,同时分享一些个人对目前机器学习尤其是自然语言理解的看法。目录
- 论文解读
- Abstract
- Introduction
- 任务描述和Baseline
- BERT
- 统计线索
- Probing实验
- 对抗测试数据
- 补充一点
- 相关讨论
- 观点1(贴主orenmatar)
- 观点2(neato5000)
- 观点3(lysecret)
- 观点4(贴主orenmatar)
- 观点5(dalgacik)
- 观点6(gamerx88)
- 观点7(fiddlewin)
- 观点8(lugiavn)
- 作者观点
论文解读
Abstract
BERT在Argument Reasoning Comprehension Task(ARCT)任务上的准确率是77%,这比没受过训练的人只底3个百分点,这是让人惊讶的好成绩。但是我们(论文作者)发现这么好的成绩的原因是BERT模型学习到了一些虚假相关的统计线索。我们分析了这些统计线索,发现很多其它的模型也是利用了这些线索。所以我们提出了一种方法来通过已有数据构造等价的对抗(adversarial)数据,在对抗数据下,BERT模型的效果基本等价于随机的分类器(瞎猜)。
Introduction
论辩挖掘(argumentation mining)任务是找到自然语言论辩的结构(argumentative structure)。根据标注的结果分析,即使是人类来说也是一个很难的问题。
这个问题的一种解决方法是关注warrant——支持推理的世界知识。考虑一个简单的论证(argument):(1) 因为现在在下雨;(2) 所以需要打伞。而能够支持(1)到(2)推理的warrant是:(3) 淋湿了不好。
Argument Reasoning Comprehension Task, ACRT是一个关注推理并且期望模型发现隐含的warrant的任务。给定一个论证,它包括一个Claim(论点)和一个Reason,同时提供一个Warrant和一个Alternative。其中Warrant是支持从Reason到Claim推理的世界知识;而Alternative是一个干扰项,它无法支持从Reason到Claim的推理。用数理逻辑符号来表示就是:
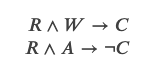
注意:ACRT数据集提供的Alternative一定能推出相反的结论。如果我们找一个随机的Alternative,它不能推导出C,但是也不一定能推导出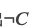 。而这个数据集保证两个候选句子中一个是Warrant(一定能推导出C),而另一个Alternative一定能推导出。这个特性在后面的构造adversarial数据集会非常有用。
。而这个数据集保证两个候选句子中一个是Warrant(一定能推导出C),而另一个Alternative一定能推导出。这个特性在后面的构造adversarial数据集会非常有用。
下面是ACRT数据集的一个例子:
| Claim | Google is not a harmful monopoly |
| Reason | People can choose not to use Google |
| Warrant | Other search engines don’t redirect to Google |
| Alternative | All other search engines redirect to Google |
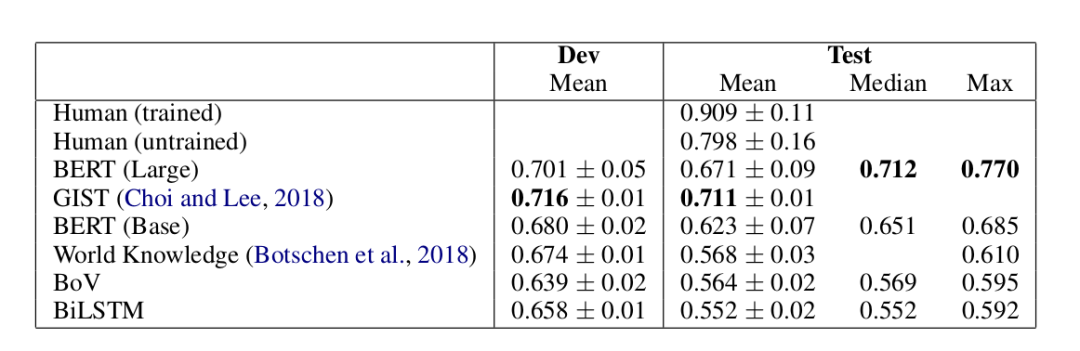 ACRT任务上Baseline和BERT的效果这比没有训练过的人只低3个点,这是非常让人震惊的成绩。因为训练数据里都没有提供这些世界知识,如果BERT真的表现这么好,那么唯一的解释就是它通过无监督的Pretraining从海量的文本里学到了这些世界知识。为了研究BERT的决策,我们选择了那些多次训练BERT都比较容易正确预测的例子来分析。根据SemEval-2018 Task 12: The Argument Reasoning Comprehension Task,Habernal等人在SemEval的任务上的做了类似的分析,和他们的分析类似(参考后面作者的观点),我们发现BERT利用了warrant里的某些词的线索,尤其是”not”。通过寻根究底(probing)的设计实验来隔离这些效果(不让数据包含这种词的线索),我们发现BERT效果好的原因就是它们利用了这些线索。我们可以改进ACRT数据集,因为这个数据集上很好的特性
ACRT任务上Baseline和BERT的效果这比没有训练过的人只低3个点,这是非常让人震惊的成绩。因为训练数据里都没有提供这些世界知识,如果BERT真的表现这么好,那么唯一的解释就是它通过无监督的Pretraining从海量的文本里学到了这些世界知识。为了研究BERT的决策,我们选择了那些多次训练BERT都比较容易正确预测的例子来分析。根据SemEval-2018 Task 12: The Argument Reasoning Comprehension Task,Habernal等人在SemEval的任务上的做了类似的分析,和他们的分析类似(参考后面作者的观点),我们发现BERT利用了warrant里的某些词的线索,尤其是”not”。通过寻根究底(probing)的设计实验来隔离这些效果(不让数据包含这种词的线索),我们发现BERT效果好的原因就是它们利用了这些线索。我们可以改进ACRT数据集,因为这个数据集上很好的特性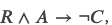 因此我们可以把结论反过来(加一个否定),然后Warrant和Alternative就会互换,这样就可以保证模型无法根据词的分布来猜测哪个是Warrant哪个是Alternative。而通过这种方法得到的对抗(adversarial)数据集,BERT的准确率只有53%,比随机瞎猜没有强多少,因此这个改进的数据集是一个更好的测试模型的数据集。
因此我们可以把结论反过来(加一个否定),然后Warrant和Alternative就会互换,这样就可以保证模型无法根据词的分布来猜测哪个是Warrant哪个是Alternative。而通过这种方法得到的对抗(adversarial)数据集,BERT的准确率只有53%,比随机瞎猜没有强多少,因此这个改进的数据集是一个更好的测试模型的数据集。任务描述和Baseline

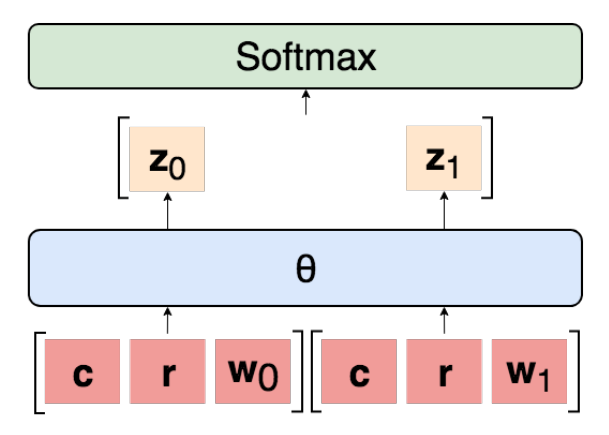
因此给定
 模型最终会输出一个score,表示Warrant-j是正确的Warrant的可能性(logit),然后使用softmax把两个logits变成概率。注意这个模型是独立考虑每一个Warrant的,每个Warrant的打分是和另外一个无关的,如果是相关的,则模型的输入要同时包含
模型最终会输出一个score,表示Warrant-j是正确的Warrant的可能性(logit),然后使用softmax把两个logits变成概率。注意这个模型是独立考虑每一个Warrant的,每个Warrant的打分是和另外一个无关的,如果是相关的,则模型的输入要同时包含 用数学公式描述其计算过程为:
用数学公式描述其计算过程为: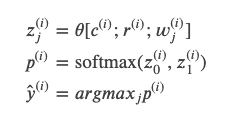
模型?可以有很多种,这里的Baseline包括Bag of Vector(BoV)、双向LSTM(BiLSTM)、SemEval的冠军GIST和人类。结果如上图所示。对于所有的实验,我们都使用了网格搜索(grid search)的方法来选择超参数,同时我们使用了dropout和Adam优化算法。当在验证集上的准确率下降的话我们会把learning rate变为原来的1/10,最后的模型参数是在验证集上准确率最高的那组参数。BoV和BiLSTM的输入是300维的GloVe向量(从640B个Token的数据集上训练得到)。用于复现实验的代码、具体的超参数都放在作者的GitHub上。
BERT
我们的BERT模型如下图所示。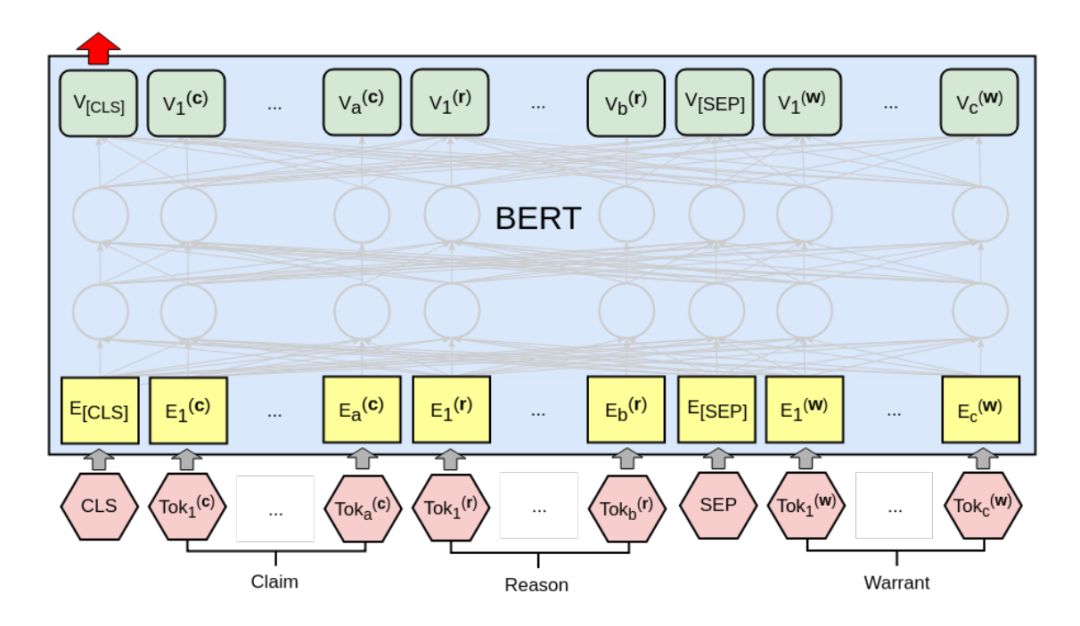
我们把Claim和Reason拼接起来作为BERT的第一个”句子”(它们之间没有特殊的分隔符,因此只能靠句号之类的线索,这么做的原因是BERT最多输入两个句子,我们需要留一个句子给Warrant),而Warrant是第二个”句子”,它们之间用特殊的SEP来分割,而最前面是特殊的CLS。CLS本身无语义,因此可以认为它编码了所有输入的语义,然后在它之上接入一个线性的全连接层得到一个logit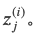 两个Warrant都输入后得到
两个Warrant都输入后得到 最后用softmax变成概率。不熟悉BERT的读者可以参考BERT课程、BERT模型详解和BERT代码阅读。
最后用softmax变成概率。不熟悉BERT的读者可以参考BERT课程、BERT模型详解和BERT代码阅读。
整个模型(包括BERT和CLS上的线性层都会参与Fine-tuning),learning rate是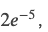 最大的Epoch数是20,选择在验证集上效果最好的那组参数。我们使用的是Hugging Face的PyTorch实现。
最大的Epoch数是20,选择在验证集上效果最好的那组参数。我们使用的是Hugging Face的PyTorch实现。
统计线索
虚假相关的统计线索主要来源于Warrant的不均匀的语言(词)分布,从而出现不同标签的不均匀词分布。虽然还有更复杂的线索,这里我们只考虑unigram和bigram。我们会分析如果模型利用这些线索会带来多大的好处,以及这种现象在这个数据集上有多么普遍。形式化的,假设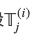 是第i个训练数据的第j(j=0或者1)个warrant的所有的Token的集合。我们定义一个线索(比如一个unigram或者bigram)的applicability
是第i个训练数据的第j(j=0或者1)个warrant的所有的Token的集合。我们定义一个线索(比如一个unigram或者bigram)的applicability 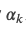 为n个训练数据中只在一个标签里出现的次数。用数学语言描述就是:
为n个训练数据中只在一个标签里出现的次数。用数学语言描述就是: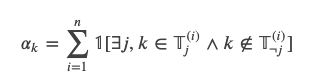
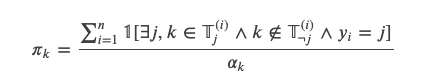
分母是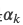 ,分子是里的并且模型分类和线索是同时出现的数量。比如”not”在n个训练数据里单独出现了5次,有3次只出现在warrant0,有2次只出现在warrant1。如果”not”只出现在warrant0的3次里有2次模型预测正确(预测为0),”not”只出现在warrant1的2次里有1次预测正确(预测为1),则分子就是2+1=3,分母就是5,则
,分子是里的并且模型分类和线索是同时出现的数量。比如”not”在n个训练数据里单独出现了5次,有3次只出现在warrant0,有2次只出现在warrant1。如果”not”只出现在warrant0的3次里有2次模型预测正确(预测为0),”not”只出现在warrant1的2次里有1次预测正确(预测为1),则分子就是2+1=3,分母就是5,则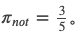 量是模型可能利用线索的”上限”,比如上面的例子,”not”单独出现了5次,模型预测正确了3次,则”not”这个特征对于分类正确”最大”的贡献就是0.6。
量是模型可能利用线索的”上限”,比如上面的例子,”not”单独出现了5次,模型预测正确了3次,则”not”这个特征对于分类正确”最大”的贡献就是0.6。
最后我们定义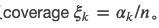 简单来说,productivity就是利用这个线索对于分类的好处,而coverage表示这个线索能够”覆盖”的数据范围。对于m(这里为2)分类的问题,如果
简单来说,productivity就是利用这个线索对于分类的好处,而coverage表示这个线索能够”覆盖”的数据范围。对于m(这里为2)分类的问题,如果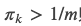 则说明这个线索对于分类是有帮助的。productivity和coverage最强的两个unigram线索是”not”这个词,它的productivity和coverage如下图所示。
则说明这个线索对于分类是有帮助的。productivity和coverage最强的两个unigram线索是”not”这个词,它的productivity和coverage如下图所示。

它的意思就是平均来说,64%的数据都有”not”出现,如果只利用这个线索能够得到准确率为61%的分类结果。那么我们可以这么来得到一个分类器:如果”not”出现,我们就分类为0(假设训练数据中”not”出现更容易分类为0);如果”not”不出现,我们就随机分类。那么这个分类器的准确率是多少呢?64%*61%+(1-64%)*50%=0.57。根据前面的描述,大部分分类器的准确率都没有超过0.6,而使用这样的特征就可以做到0.57。如果还有和”not”类似的特征,而且它们不完全相关(有一定的额外信息),那么再加上其它的这类词特征可以进一步提高预测的准确率(前提是假设测试数据的词分布也是和训练数据一样的)。
Probing实验
如果某个模型能只利用了Warrant的词的线索,那么我们只把warrant作为输入也应该会得到类似的准确率。当然这不是”真正”的解决了这个问题,因为你连claim(论点)和reason都没有看到,只看到warrant里出现了not就分类为0,这显然是不对的。举个前面的例子,我们的分类器会把”Other search engines don’t redirect to Google”分类为0,这显然是正确的,但是它分类的理由是:因为这个warrant包含了”not”。这显然是不对的。类似的我们也可以只把warrant和claim、warrant和reason作为输入来训练模型,这样的模型学到的特征也肯定是不对的。但是实验的结果如下:
图:BERT Large、BoV和BiLSTM模型的probing实验
我们看到在BERT Large模型里只用Warrant作为输入就可以得到71%的准确率,这和之前最好的GIST模型差不多,而把Warrant和Reason作为输入可以得到最高75%的准确率。因此ACRT数据集是有问题的,我们的输入不完整就可以得到75%的准确率,这就好比老师的题目还没写完,你就把答案写出来了,这只能说明你作弊或者是瞎猜的。
对抗测试数据
ACRT数据集的词的统计不均匀问题可以使用下面的技巧来解决。因为?∧?→?,我们可以把claim变成它的否命题,这样Warrant和Alternative就会互换,这样就能保证通用一个句子既是Warrant0也是Warrant1,从而在所有的Warrant里词的部分完全是均匀的。下图是一个示例。 图:一个原始的训练数据以及有它生成的对抗数据
图:一个原始的训练数据以及有它生成的对抗数据这个对抗例子为:我们可以使用其它的搜索引擎,但是其它搜索引擎最终会重定向到Google,所以Google是一个垄断者。也就是把Claim加一个否定(双重否定就是肯定,就可以去掉not),原来的Alternative就变成的新的Warrant。这样”All other search engines redirect to Google”在Warrant0和Alternative都出现一次,从而词的分布是均匀的。对于这种方法生成的对抗训练数据,我们做了两个实验。第一个实验使用原始的(没有加入对抗样本)训练数据和验证数据训练模型,然后在对抗数据集上测试,其结果比随机猜(50%)还差,因为它过拟合了某些根本不对的特征,测试数据根本不是这样的分布。第二个使用是使用对抗数据进行训练和测试,则BERT最好的效果只有53%。
补充一点
我个人觉得这篇文章还有一点小缺陷,那就是没有使用ACRT排名第一的模型GIST跑一下对抗数据集。因为GIST会使用SNLI等NLI任务的数据进行预训练,也许从这里可以学到一些世界知识用于解决ACRT的推理问题。我在这里里提了这个问题,不过作者认为NLI的数据并不包含解决ACRT问题的世界知识,因此没有必要做这个实验(也许更主要的问题是不想重新实现一遍GIST模型?这也许说明了论文开源代码的价值,别的研究者可以很容易的check和利用其工作)。相关讨论
这里收集了一些来自Reddit的帖子BERT’s success in some benchmarks tests may be simply due to the exploitation of spurious statistical cues in the dataset. Without them it is no better then random.讨论里的一些观点。下面的内容都是我摘录和翻译(意译)的部分观点。观点1(贴主orenmatar)
首先我们来看Reddit帖子的标题:BERT在某些benchmark上的成功是因为简单的利用了不相关的统计线索。如果不(能)利用这些线索,它的效果就是随机的瞎猜。这个观点相对比较客观,只是描述了一个事实。观点2(neato5000)
赞成贴主的观点,并且提到Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference里有类似的结论。观点3(lysecret)
同意贴主的观点,但是认为BERT模型依然很有用,在3个个人项目中比其它模型好很多。贴主orenmatar同意BERT,他说自己发帖并没有否定BERT的价值,但是强调只是在ACRT这个特定集合上BERT学到的只是不相关的统计线索。观点4(贴主orenmatar)
这种论文应该更多一些。我们每天都听到NLP的各种突破,每过几个月就出现更好大模型,得到超乎想象的结果。但是很少有人实际的想办法分析这些模型是否只是因为学习到一些无意义的特征。因此我们有必要往后一步,仔细看看数据集和分析一下模型到底学到了什么东西。针对观点4,melesigenes认为这个观点对于文章大家结论过于扩大范围了(overgeneralizing)。BERT在ACRT数据集上没有学到什么并不代表在其它的数据集上没有学到有意义的东西。观点5(dalgacik)
这个观点认为这篇论文并没有说明BERT模型有什么问题,只是指出了ACRT这个数据集有问题。观点6(gamerx88)
很多进展其实都是模型过拟合了这个数据集而已,这在很多比赛类的任务都出现过。观点7(fiddlewin)
我发现很多评论错误的解读了论文?论文只是说模型(包括BERT和其它)在某个特定任务(ARCT)上利用了统计线索(比如是否出现”not”)。当引入对抗样本从而去掉这些线索之后,BERT的性能只有50%,和没有训练的人的80%相比差别很大,说明这个任务很难需要很深层次的语义理解。但是这篇论文从来没有怀疑BERT在其它任务的能力,这也是符合常识的——学习算法解决问题的方法不一定是人(想象)那样的。观点8(lugiavn)
这篇文章TLDR(Too long, don’t read)的描述了一个很简单的事实:不平衡数据上训练的模型在和训练集不同分布的测试集上表现不会太好。这并没有什么稀奇。所有的机器学习模型都是这样。为什么要把BERT单独拎出来呢?delunar对这个观点持不同态度,他认为这不是不平衡数据的问题。而是因为BERT错误的”理解”了文本的意思但是做出了相对程度正确的预测。作者观点
这篇文章之所以引起大家的关注首先是因为BERT模型最近很火,另外一个原因其实就是很多研究者对于现在机器学习(深度学习)社区对于这种刷榜的研究风气的担忧。很多研究者不在模型结构和其它方面做创新,只是使用更大的模型和更多的数据追求在某些公开数据集上刷榜。而这篇文章正是在这样的背景下引起了极大的关注。其实类似的文章还包括SemEval-2018 Task 12: The Argument Reasoning Comprehension Task、Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference和Is It Worth the Attention? A Comparative Evaluation of Attention Layers for Argument Unit Segmentation。另外在计算机视觉领域最近也有一篇文章Natural Adversarial Examples,大家可能认为ImageNet已经是一个解决的问题。但是作者找到了很多”自然”(真实)的对抗性的数据,现有的模型在上面的分类准确率非常低,基本都到不了5%。即使通过一些办法来优化,作者也只能做的15%。下面是一些示例数据:
图:ImageNet-A中的自然对抗数据
比如最右边的图,实际分类是牛蛙(bullfrog),但是模型很容易分成黑松鼠(fox squirrel)。当然视觉和语言还是有较大的区别,但是现在的模型确实有可能学到的特征和人类(甚至动物)学到的有很大区别(当然也可以argue人或者动物大脑学到的也许是类似的东西)。我们还是回到语言和BERT是否学到不相关的统计线索的问题上来。首先我认为BERT是非常有用的一种模型,它最大的优点是可以是无监督的Pretraining从海量的数据中学习Token(词)的上下文语义关系。因此Fine-tuning之后能在很多(浅层)的语言理解任务上去掉了很好的效果。但是BERT不是万能的,论文里也提到训练数据很少的情况下它可能不能训练。我们在工作中也发现了一个很有趣的意图分类的例子——有一个客户的数据量很少,大概1000+训练数据作用,而意图数(分类数)是100+。我们发现使用简单的Logistic Regression或者CNN都能达到非常好的效果——在测试集合上能有99%,但是使用BERT怎么调参也只有不到80%。后来我们分析数据发现这个客户的意图定义的很特别——只有包含某个词就作为一个意图(分类),它并不需要特殊的泛化和上下文。因此我们猜测可能的原因是因为BERT的参数过多,而且同样一个词在不同的上下文可能会被编码成不同的向量,因此在训练数据不够的情况下反而没有学到这个任务最简单和重要的特征——只要有这个词就分为这个类别。其次我认为就是现在的NLP模型(不管是BERT还是其它的模型)它没有办法获得(足够多的)常识(世界知识)。虽然海量的文本里包含了大量的世界知识(其实我觉得很多世界知识是不能在Wiki这样的地方找到的,比如前面的例子:下雨为什么要打伞,因为淋湿了不好。淋湿的感觉不舒服,那这个不舒服能用精确的语言描述吗?也许可以,也许在文学作品里有描述,但是很难用数学语言描述,很多要靠类比,但是淋过雨的人都有类似的感受),但是现在的模型(包括BERT)都很难学习到这些知识。因为它看到的只是这些世界知识通过语法编码后的文字,通过分析文字的共现之类的方法可能发现一些浅层的语法和语义,但是很难学到更深层次的语义和逻辑。至少我们人类的学习不是这样的——给你100TB的火星文,然后遮住某个词让你猜测可能是哪个词。语言只不过是人类定义的用于沟通的符号系统,它背后的根源还是我们生存的这个宇宙以及我们通过视觉、听觉等感觉器官对这个世界的感觉。当然除了当下的感觉之外也包括很久以前的感觉甚至是我们出生前通过文化传承下来的先人们的感觉。如果抛开我们的身体和感觉器官,只是从符号的角度来研究自然语言,我觉得是不能根本解决这个问题的。当然这并不是说BERT这样的模型不重要,我们在还没有更好的方法的时候这些模型可以帮助我们解决一些问题,但是千万不能以为它们能解决所有问题。
原文链接:https://fancyerii.github.io/2019/07/26/bert-spurious-stats-cue/
(*本文为 AI科技大本营转载文章,转载请联系原作者)
社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五更新技术福利,还有不定期的抽奖活动~

◆
精彩推荐
◆

60+技术大咖与你相约 2019 AI ProCon!大会早鸟票已售罄,优惠票速抢进行中......2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
推荐阅读
通俗易懂:图解10大CNN网络架构AI+DevOps正当时
5天破10亿的哪吒,为啥这么火,Python来分析5G+AI重新定义生老病死
北上深人均月薪超 2 万元,清华近三成毕业生年入 50 万+,5G 人才月薪超 4 万
如何从零开始设计一颗芯片?
在其他国家被揭穿骗子又盯上非洲? 这几个骗子公司可把非洲人民坑苦了…
国内首款 5G 机型开售;Google Chrome 大部分插件无人用;Firefox 69 Beta 9 发布 | 极客头条
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

【电子基础】模拟电路问答
模拟电路基础知识问答整理 mystery 1、温度对半导体材料的导电性能有什么影响? 答:温度对半导体的导电性能有很大影响。当温度升高时,半导体材料内的自由电子和空穴数量迅速增加,半导体的导电性能将迅速提高。 2、什么是本征半导体和杂质半导…
XML解析简介及Xerces-C++简单使用举例
XML是由World WideWeb联盟(W3C)定义的元语言。它已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便。XML在不同的语言里解析方式都是一样的,只不过实现的语法不…

[干货]Kaggle热门 | 用一个框架解决所有机器学习难题
新智元推荐 来源:LinkedIn 作者:Abhishek Thakur 译者:弗格森 【新智元导读】本文是数据科学家Abhishek Thakur发表的Kaggle热门文章。作者总结了自己参加100多场机器学习竞赛的经验,主要从模型框架方面阐述了机器学习过程中可能会…
gtest简介及简单使用
gtest是一个跨平台(Liunx、Mac OS X、Windows、Cygwin、Windows CE and Symbian)的C测试框架,有google公司发布。gtest测试框架是在不同平台上为编写C测试而生成的。从http://code.google.com/p/googletest/downloads/detail?namegtest-1.7.0.zip&can2&q下…

新浪微博推广网站的一些实践体会
本以为微博推广很难,每天都要刷粉刷内容的,也本以为做微博推广也很简单,一不卖产品、二不卖服务的,目的单纯灵活性强些,做了之后才发现都不是那么回事,微博虽然也过了“火了”,但新媒体还真是不…
AI和大数据如何落地智能城市?京东城市这6篇论文必读 | KDD 2019
来源 | 京东城市(ID: icity-jd)作为世界数据挖掘领域的最高级别的学术会议,ACM SIGKDD(国际数据挖掘与知识发现大会,简称 KDD)将于 2019 年 8 月 4 日—8 日在美国阿拉斯加州安克雷奇市举行。自 1995 年以来…
OSError: Could not find library geos_c or load any of its variants ['libgeos_c.so.1', 'libgeos_c.so
OSError: Could not find library geos_c or load any of its variants [libgeos_c.so.1, libgeos_c.so 解决: sudo vim /etc/ld.so.conf 添加:/opt/source/geos-3.5.0/build/lib sudo ldconfig
五分钟搭建BERT服务,实现1000+QPS,这个Service-Streamer做到了
作者 | 刘欣简介:刘欣,Meteorix,毕业于华中科技大学,前网易游戏技术总监,现任香侬科技算法架构负责人。之前专注游戏引擎工具架构和自动化领域,2018年在GDC和GoogleIO开源Airtest自动化框架,广泛…
Nagios+pnp4nagios+rrdtool 安装配置为nagios添加自定义插件(三)
nagios博大精深,可以以shell、perl等语句为nagios写插件,来满足自己监控的需要。本文写mysql中tps、qps的插件,并把收集到的结果以图形形式展现出来,这样输出的结果就有一定的要求了。 编写插件tps qps check_qps 插件如下内容 #…
OpenSSL简介及在Windows、Linux、Mac系统上的编译步骤
OpenSSL介绍:OpenSSL是一个强大的安全套接字层密码库,囊括主要的密码算法、常用的密钥和证书封装管理功能及SSL协议,并提供丰富的应用程序供测试或其它目的使用。 SSL是SecureSockets Layer(安全套接层协议)的缩写,可以在Interne…

Guava Cache本地缓存在 Spring Boot应用中的实践
概述 在如今高并发的互联网应用中,缓存的地位举足轻重,对提升程序性能帮助不小。而 3.x开始的 Spring也引入了对 Cache的支持,那对于如今发展得如火如荼的 Spring Boot来说自然也是支持缓存特性的。当然 Spring Boot默认使用的是 SimpleCache…

Windows 8.1 Preview(Windows Blue)预览版简体中文官方下载(ISO完整版镜像)
Windows 8.1是微软继Windows 8以来的又一全新力作,又名Windows Blue(视窗蓝,专注蓝屏30年),个人觉得Win8还是比较流畅的但大众始终觉得还是有很多需要改进或者改善的,如今微软为了迎合大众需求对Win8进行升…

Linux下编辑器vi/vim的使用介绍
vi编辑器是所有Unix及Linux系统下标准的编辑器。对Unix及Linux系统的任何版本,vi编辑器是完全相同的。 基本上vi可以分为三种状态,分别是命令模式(commandmode)、插入模式(insert mode)和底行模式(last line mode),各模式的功能为࿱…

Clojure程序设计
《Clojure程序设计》基本信息作者: (美)Stuart Halloway Aaron Bedra [作译者介绍]出版社:人民邮电出版社ISBN:9787115308474上架时间:2013-3-1出版日期:2013 年3月开本:16开页码:230版次&#…

重磅!AI Top 30+案例评选正式启动
2019 年,人工智能应用落地的重要性正在逐步得到验证,这是关乎企业生死攸关的一环。科技巨头、AI 独角兽还有起于草莽的创业公司在各领域进行着一场多方角斗。进行平台布局的科技巨头们,正在加快承载企业部署 AI 应用的步伐,曾经无…

直播回顾 | 关于Apollo 5.0控制在环仿真技术的分享
Apollo 用于模型验证和测试的基于 Web 的仿真平台 Dreamland 已经更新到能使用更强大的场景编辑器和环控制模拟。基于 Apollo 流水线和机器学习的动力学模型,复杂度较高,同时基于 AI 的全景数据建模,模型精细度高,误差比传统方式可…
eclipes 安装 pytdev,svn,插件
1, python pydevhttp://pydev.org/updates2, svnhttp://subclipse.tigris.org/update3, 推荐http://subclipse.tigris.org/update_1.10.x 转载于:https://blog.51cto.com/swq499809608/1240873
FFmpeg简介及在vc2010下编译步骤
FFmpeg是一个开源的多媒体库,最新版本是2.4.3,它的License是LGPL或GPL。FFmpeg可以用来记录、转换数字音频、视频,并能将其转换为流的开源计算机程序。它包括了音/视频编码库libavcodec。FFmpeg是在Linux下开发出来的,但它可以在包…
医院六级电子病历建设思路及要点
产生背景 在医院电子病历信息化发展的过程中,先后经历了纸质病历、电子病历、结构化电子病历以及具有全医疗过程管理能力的电子病历四个阶段。临床业务需求质量的逐步提升,标准规范的逐步细化,互联网战略的落地实施,无疑对目前电子…
上手必备!不可错过的TensorFlow、PyTorch和Keras样例资源
作者 | 黄海广来源 | 机器学习初学者(ID: ai-start-com)TensorFlow、Keras和PyTorch是目前深度学习的主要框架,也是入门深度学习必须掌握的三大框架,但是官方文档相对内容较多,初学者往往无从下手。本人从github里搜到…
Linux下gdb调试工具的使用
gdb是GNU开源组织发布的一个强大的Linux下的程序调试工具。 gdb主要完成四个方面的功能:(1)、启动你的程序,可以按照你的自定义的要求随心所欲的运行程序;(2)、可让被调试的程序在你所指定的调试的断点处停住(断点可以是条件表达式)…
UESTC 1726 整数划分(母函数)
题目链接:http://222.197.181.5/problem.php?pid1726 题意:求n的划分数。一种划分方案中不能有相同的数字。 思路:(1x)(1x^2)(1x^3)……(1x^1000). int f[N];void init() {f[1]1;int a[N]{0};a[0]1; a[1]1;int i,j;for(i2;i<1000;i){for(…
JS nodeType返回类型
JS nodeType返回类型 前几天朋友正好问道 这个 js的nodeType是个什么概念(做浏览器底层的)正好遇到这篇文章可以向大家解释下 将HTML DOM中几个容易常用的属性做下记录: nodeName、nodeValue 以及 nodeType 包含有关于节点的信息。 nodeName …
C# 获取指定目录下所有文件信息、移动目录、拷贝目录
/// <summary>/// 返回指定目录下的所有文件信息/// </summary>/// <param name"strDirectory"></param>/// <returns></returns>public List<FileInfo> GetAllFilesInDirectory(string strDirectory){List<FileInfo&g…
文件夹浏览(SHBrowseForFolder)
from http://www.cnblogs.com/Clingingboy/archive/2011/04/16/2018284.html 一.首先要为SHBrowseForFolder准备一个结构体BROWSEINFO typedef struct _browseinfoW {HWND hwndOwner;PCIDLIST_ABSOLUTE pidlRoot;LPWSTR pszDisplayName; // Return display…
技术新贵:RPA与NLP技术的结合与应用
什么是 RPA(Robotic Process Automation)?机器人流程自动化(RPA)是一种自动化工具,用于创建软件机器人的虚拟劳动力,从而优化和降低企业中端到端业务流程的成本。RPA 可以翻译成机器人流程自动化…
API Sanity Checker在Ubuntu中的使用
API Sanity Checker是一个自动生成单元测试用例的工具,可用于链接测试。它可用于三大桌面平台,下面简单介绍它在Linux下的使用步骤:1. 从http://ispras.linuxbase.org/index.php/API_Sanity_Autotest 下载最新的api-sanity-checker-1.98…

手动脱壳—dump与重建输入表(转)
文章中用到的demo下载地址: http://download.csdn.net/detail/ccnyou/4540254 附件中包含demo以及文章word原稿 用到工具: Ollydbg LordPE ImportREC 这些工具请自行下载准备 Dump原理这里也不多做描述,想要了解google it!常见的dump软件有Lo…
如何用RNN生成莎士比亚风格的句子?(文末赠书)
作者 | 李理,环信人工智能研发中心vp,十多年自然语言处理和人工智能研发经验。主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。来源 | 《深度学习理论与实战:基础篇》基本概…
图像相似度计算之哈希值方法OpenCV实现
感知哈希算法(perceptual hash algorithm),它的作用是对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。结果越接近,就说明图像越相似。 实现步骤: 1. 缩小尺寸:将图像缩小到8*8的尺寸&am…