如何用RNN生成莎士比亚风格的句子?(文末赠书)

来源 | 《深度学习理论与实战:基础篇》

基本概念
普通的全连接网络,它的输入是相互独立的,但对于某些任务来说,比如你想预测一个句子的下一个词,知道之前的词是有帮助的,因此“相互独立”並不是一个好的假设。而利用时序信息的循环神经网络(Recurrent Neural Network,RNN)可以解决这个问题。RNN 中 “Recurrent”的意思就是它会对一个序列的每一个元素执行同样的操作,并且之后的输出依赖于之前的计算。我们可以认为 RNN 有“记忆”能力,能捕获之前计算过的一些信息。理论上 RNN能够利用任意长序列的信息,而实际中它能记忆的长度是有限的。图 4.1 显示了怎么把一个 RNN 展开一个完整的网络。比如我们考虑一个包含 5 个词的句子,我们可以把它展开成 5 层的神经网络,每个词是一层。RNN 的计算公式如:(1)
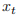 是 t 时刻的输入。
是 t 时刻的输入。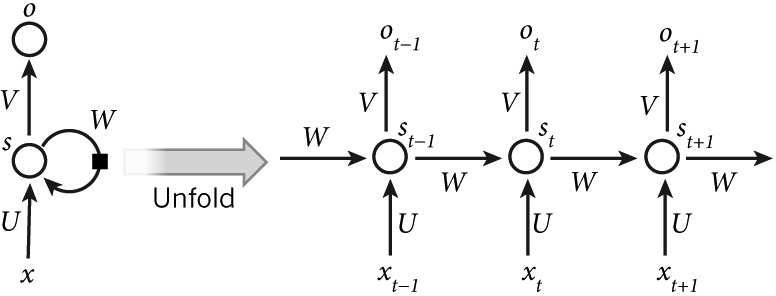 图 4.1 RNN 展开图(2)
图 4.1 RNN 展开图(2)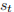 是 t 时刻的隐藏状态。 的计算依赖于前一个时刻的状态和当前时刻的输入: =
是 t 时刻的隐藏状态。 的计算依赖于前一个时刻的状态和当前时刻的输入: = 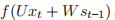 ,实现 RNN 的“记忆”功能。函数 f 通常
,实现 RNN 的“记忆”功能。函数 f 通常  是诸如 tanh 或者 ReLU 的非线性函数。s−1 是初始时刻的隐藏状态,通常可以初始化成 0。
是诸如 tanh 或者 ReLU 的非线性函数。s−1 是初始时刻的隐藏状态,通常可以初始化成 0。 (3)
 是 t 时刻的输出。有一些事情值得注意:
是 t 时刻的输出。有一些事情值得注意:你可以把
看成网络的“记忆”。 捕获了从开始到前一个时刻的所有(感兴趣)的信息,输出 只基于当前时刻的记忆。不过实际应用中 很难记住很久以前的信息。参数共享。传统的神经网络每层均使用不同的参数,而 RNN 的参数(U, V , W)在所有时刻是共享(一样)的,每一步做同样的操作(Operation),只不过输入不同而已。这种结构极大地减少了需要学习和调优的参数。
每一个时刻都有输出。每一个时刻都有输出,但不一定都要使用。比如预测一个句子的情感倾向只需关注最后的输出,而不是每一个词的情感。每个时刻不一定都有输入。RNN 最主要的特点是它有隐藏状态(记忆),能捕获一个序列的信息。
RNN 的扩展
1. 双向 RNN(Bidirectional RNN)双向 RNN 如图 4.2 所示,它的基本思想是 t 时刻的输出,不但依赖于之前的元素,而且还依赖之后的元素。比如,我们做完形填空,在句子中“挖”掉一个词,要想预测这个词,不但会看前面的词,也会分析后面的词。双向 RNN 很简单,它就是两个 RNN 堆叠在一起,输出依赖两个RNN 的隐藏状态。2. 深度双向 RNN(Deep Bidirectional RNN)如图 4.3 所示,它和双向 RNN 类似,不过多加了几层。当然它的表示能力更强,需要的训练数据也更多。
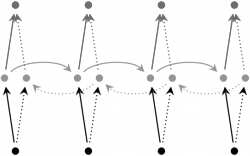
4.2 双向 RNN
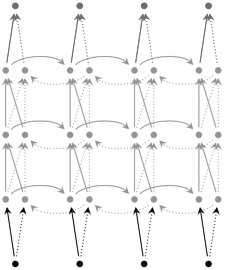
图 4.3 深度双向RNN
Word Embedding 简介
视觉或者听觉信号是比较底层的信号,输入就是一个“稠密”的向量(采样后的声音)或者矩阵(图像);而文本是人类创造的抽象的符号系统,它通常是“稀疏”的。这里介绍常见的表示方法:one-hot。
假设有 1000 个不同的词(实际可能几十万),那么用 1000 维的向量来表示一个词,每个词对应一个下标。比如假设“猫”这个词对应的下标的值为 1,而其余的值为 0,因此一个词只有一个位置不为 0,所以这种表示方法叫作 one-hot。这是一种“稀疏”的表示方法。比如计算两个向量的内积,相同的词内积为 1(表示相似度很高);而不同的词为0(表示完全不同),但实际我们希望“猫”和“狗”的相似度要高于“猫”和“石头”,使用 one-hot 就无法表示出来。
Word Embedding 的思想是,把高维的稀疏向量映射到一个低维的稠密向量,要求是两个相似的词会映射到低维空间里距离比较近的两个点;而不相似两词的映射点间距离较远。我们可以这样来理解这个低维的向量——假设语义可以用 n 个基本的“正交”的“原子”语义表示,那么向量的不同的维代表这个词在这个“原子”语义上的“多少”。当然这只是一种假设,实际这个语义空间是否存在,或者即使存在也可能和人类理解的不同,但是只要能达到前面的要求——相似的词的距离近而不相似的远,也就可以了。
举例来说,假设向量的第一维表示动物,那么猫和狗应该在这个维度上有较大的值,而石头应该较小。
Embedding 一般有两种方式得到,一种是通过与任务无直接关系的无监督任务中学习,比如早期的 RNN 语言模型,它的一个副产品就是 Word Embedding,包括后来的专门 Embedding 方法,如 Word to Vector 或者 GloVe 等,后面将会介绍。另外一种方式就是,在当前任务中,让它自己学习出最合适的 Word Embedding 来。
前一种方法的好处是,可以利用大量的无监督数据,但是由于领域有差别及它不是针对具体任务的最优表示,效果可能不会很好;而后一种方法,它针对当前任务学习出最优的表示(和模型的参数配合),但是它需要大量的训练数据,这对很多任务来说是无法满足的条件。在实践中,如果领域的数据非常少,我们可能直接用其他任务中预训练出的 Embedding 并且固定它;而如果领域数据较多,我们会用预训练出的 Embedding 作为初始值,然后用领域数据对它进行微调。
姓名分类
这个示例训练一个字符级别的 RNN 模型来预测一个姓名是哪个国家人的姓名。数据集收集了 18 个国家的近千个人名。
数据准备
在 data/names 目录下有 18 个文本文件,命名规范为 [国家].txt。每个文件的每一行都是一个姓名。此外,实现了一个 unicode_to_ascii 转换,把诸如 à 之类转换成 a。最终得到一个字典category_lines,language: [names ...]。key 是语言名,value 是姓名的列表。all_letters 里保存所有的字符。
import glob
all_filenames = glob.glob('../data/names/*.txt')
print(all_filenames)
import unicodedata
import string
all_letters = string.ascii_letters + " .,;'"
n_letters = len(all_letters)
def unicode_to_ascii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
print(unicode_to_ascii('lusàrski'))
category_lines = {}
all_categories = []
def readLines(filename):
lines = open(filename).read().strip().split('\n')
return [unicode_to_ascii(line) for line in lines]
for filename in all_filenames:
category = filename.split('/')[-1].split('.')[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
print('n_categories =', n_categories)把姓名从字符串变成 Tensor
现在我们已经把数据处理好了,接下来需要把姓名从字符串变成 Tensor,因为机器学习只能处理数字。我们使用“one-hot”的表示方法表示一个字母。这是一个 (1, n_letters) 的向量,对应字符的下标为 1,其余为 0。对于一个姓名,用大小为 (line_length, 1, n_letters) 的 Tensor 来表示。第二维表示样本(batch)大小,因为 PyTorch 的 RNN 要求输入格式是 (time, batch, input_features)。
import torch
# 把一个字母变成<1 x n_letters> Tensor
def letter_to_tensor(letter):
tensor = torch.zeros(1, n_letters)
letter_index = all_letters.find(letter)
tensor[0][letter_index] = 1
return tensor
# 把一行(姓名)转换成<line_length x 1 x n_letters>的Tensor
def line_to_tensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
letter_index = all_letters.find(letter)
tensor[li][0][letter_index] = 1
return tensor创建网络
如果想“手动”创建网络,那么在 PyTorch 里创建 RNN 和全连接网络的代码并没有太大差别。因为 PyTorch 的计算图是动态实时编译的,不同 time-step 的 for 循环不需要“内嵌”在 RNN里。每个训练数据即使长度不同也没有关系,因为计算图每次都是根据当前的数据长度“实时”编译出来的。网络结构如图 4.4 所示。
这个网络结构使用了两个全连接层:一个用于计算新的 hidden;另一个用于计算当前的输出。定义网络的代码如下:
import torch.nn as nn
from torch.autograd import Variable
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.Softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.Softmax(output)
return output, hidden
def init_hidden(self):
return Variable(torch.zeros(1, self.hidden_size))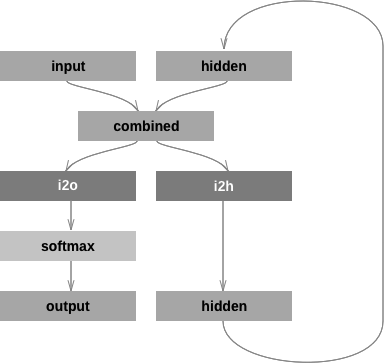
图 4.4 网络结构
类需要继承 nn.Module 并且实现__init__、forward 和 init_hidden 这 3 个方法。__init__方法定义网络中的变量,以及两个全连接层。forward 方法根据当前的输入 input 和上一个时刻的 hidden计算新的输出和 hidden。init_hidden 方法创建一个初始为 0 的隐藏状态。
测试网络
定义好网络之后测试一下:
n_hidden = 128rnn = RNN(n_letters, n_hidden, n_categories)input = Variable(line_to_tensor('Albert'))hidden = Variable(torch.zeros(1, n_hidden))# 实际是遍历所有inputoutput, next_hidden = rnn(input[0], hidden)print(output)hidden=net_hidden准备训练
测试通过之后就可以开始训练了。训练之前,需要工具函数根据网络的输出把它变成分类,这里使用 Tensor.topk 来选取概率最大的那个下标,然后得到分类名称。
def category_from_output(output):
top_n, top_i = output.data.topk(1) # Tensor out of Variable with .data
category_i = top_i[0][0]
return all_categories[category_i], category_i
print(category_from_output(output))需要一个函数来随机挑选一个训练数据:
import random
def random_training_pair():
category = random.choice(all_categories)
line = random.choice(category_lines[category])
category_tensor = Variable(torch.LongTensor([all_categories.index(category)]))
line_tensor = Variable(line_to_tensor(line))
return category, line, category_tensor, line_tensor
for i in range(10):
category, line, category_tensor, line_tensor = random_training_pair()
print('category =', category, '/ line =', line)训练
现在我们可以训练网络了,因为 RNN 的输出已经求过对数了,所以计算交叉熵只需要选择正确的分类对应的值就可以了,PyTorch 提供了 nn.NLLLoss() 函数来实现这个目的,它实现了loss(x, class) = -x[class]。
criterion = nn.NLLLoss()learning_rate = 0.005
optimizer = torch.optim.SGD(rnn.parameters(), lr=learning_rate创建输入和输出Tensor
创建初始化为零的隐藏状态Tensor
for each letter in 输入Tensor:
output, hidden=rnn(input,hidden)
计算loss
backward计算梯度
optimizer.step
def train(category_tensor, line_tensor):
rnn.zero_grad()
hidden = rnn.init_hidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden
loss = criterion(output, category_tensor)
loss.backward()
optimizer.step()
return output, loss.data[0]import time
import math
n_epochs = 100000
print_every = 5000
plot_every = 1000
current_loss = 0
all_losses = []
def time_since(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
start = time.time()
for epoch in range(1, n_epochs + 1):
# 随机选择一个样本
category, line, category_tensor, line_tensor = random_training_pair()
output, loss = train(category_tensor, line_tensor)
current_loss += loss
if epoch % print_every == 0:
guess, guess_i = category_from_output(output)
correct = '' if guess == category else ' (%s)' % category
print('%d %d%% (%s) %.4f %s / %s %s' % (epoch, epoch / n_epochs * 100,
time_since(start), loss, line, guess, correct))
if epoch % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 0把所有的损失都绘制出来,以显示学习的过程,如图 4.5 所示。
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
plt.figure()
plt.plot(all_losses)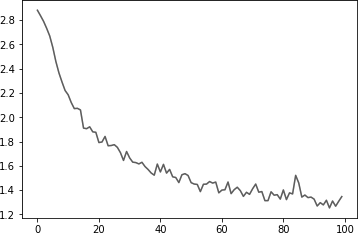 图 4.5 训练的损失评估效果
图 4.5 训练的损失评估效果创建一个混淆矩阵来查看模型的效果,每一行代表样本实际的类别,而每一列表示模型预测的类别。为了计算混淆矩阵,我们需要使用 evaluate 方法来预测,它和 train() 基本一样,只是少了反向计算梯度的过程。
# 混淆矩阵
confusion = torch.zeros(n_categories, n_categories)
n_confusion = 10000
def evaluate(line_tensor):
hidden = rnn.init_hidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
return output
# 从训练数据里随机采样
for i in range(n_confusion):
category, line, category_tensor, line_tensor = random_training_pair()
output = evaluate(line_tensor)
guess, guess_i = category_from_output(output)
category_i = all_categories.index(category)
confusion[category_i][guess_i] += 1
# 归一化
for i in range(n_categories):
confusion[i] = confusion[i] / confusion[i].sum()
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)
# 设置x轴的文字往上走
ax.set_xticklabels([''] + all_categories, rotation=90)
ax.set_yticklabels([''] + all_categories)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()最终的混淆矩阵如图 4.6 所示。
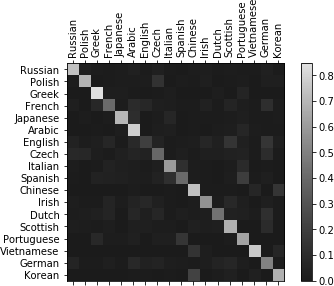 图 4.6 混淆矩阵测试
图 4.6 混淆矩阵测试predict 函数会预测输入姓名概率最大的 3 个国家,然后手动输入几个训练数据里不存在的姓名进行测试。
def predict(input_line, n_predictions=3):
print('\n> %s' % input_line)
output = evaluate(Variable(line_to_tensor(input_line)))
topv, topi = output.data.topk(n_predictions, 1, True)
predictions = []
for i in range(n_predictions):
value = topv[0][i]
category_index = topi[0][i]
print('(%.2f) %s' % (value, all_categories[category_index]))
predictions.append([value, all_categories[category_index]])
predict('Dovesky')
predict('Jackson')
predict('Satoshi')RNN 生成莎士比亚风格句子
这个例子会用莎士比亚的著作来训练一个 char-level RNN 语言模型,同时使用它来生成莎士比亚风格的句子。
准备数据
输入文件是纯文本文件,使用 unidecode 函数来把 Unicode 编码的文本转成 ASCII 文本。
import unidecode
import string
import random
import re
all_characters = string.printable
n_characters = len(all_characters)
file = unidecode.unidecode(open('../data/shakespeare.txt').read())
file_len = len(file)
print('file_len =', file_len)chunk_len = 200
def random_chunk():
start_index = random.randint(0, file_len - chunk_len)
end_index = start_index + chunk_len + 1
return file[start_index:end_index]
print(random_chunk())之前例子“手动”实现了最朴素的 RNN,下面的例子里将使用 PyTorch 提供的 GRU 模块来实现 RNN,这比“手动”实现的版本效率更高,也更容易复用。下面会简单地介绍 PyTorch 中的RNN 相关模块。
1.torch.nn.RNN
这个类用于实现vanillaRNN,具体计算公式为:
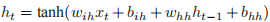 ,其中
,其中 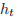 是 t 时刻的隐藏状态,
是 t 时刻的隐藏状态,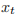 是 t 时刻的输入。如果想使用其他的激活函数,如 ReLU,那么可以在构造函数里传入 nonlinearity=‘relu’。构造函数的参数如下所示。
是 t 时刻的输入。如果想使用其他的激活函数,如 ReLU,那么可以在构造函数里传入 nonlinearity=‘relu’。构造函数的参数如下所示。in输入 xt 的大小。
hidden_size:隐藏单元的个数。
num_layers:RNN 的层数,默认为 1。
nonlinearity:激活函数,可以是“tanh”或者“relu”,默认是“tanh”。
bias:是否有偏置。
batch_first:如果为 True,那么输入要求是 (batch, seq, feature),否则是 (seq, batch, feature),默认是 False。
dropout:Dropout 概率。默认为 0,表示没有 Dropout。
bidirectional:是否为双向 RNN。默认 False。
它的输入是 input,
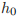 格式如下所示。
格式如下所示。input:shape 是 (seq_len, batch, input_size),如果构造参数 batch_first 是 True,则要求输入是 (batch, seq_len, input_size)。
- :shape 是 (num_layers * num_directions, batch, hidden_size)。
它的输出是 output,
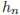 格式如下所示。
格式如下所示。output:最后一层的输出,shape 是 (seq_len, batch, hidden_size * num_directions)。
- :shape 是 (num_layers * num_directions, batch, hidden_size)。它包含的变量如下所示。
weight_ih_l[k]:第 k 层输入到隐藏单元的可训练的权重。如果 k 是 0(第一层),那么它的 shape 是 (hidden_size * input_size),否则是 (hidden_size * hidden_size)。
weight_hh_l[k]:第 k 层(上一个时刻的)隐藏单元到隐藏单元的权重。shape 是 (hidden_size * hidden_size)。
bias_ih_l[k]:第 k 层输入到隐藏单元的偏置。shape 是 (hidden_size)。
bias_hh_l[k]:第 k 层隐藏单元到隐藏单元的偏置。shape 也是 (hidden_size)。
>>> rnn = nn.RNN(10, 20, 2)
>>> input = torch.randn(5, 3, 10)
>>> h0 = torch.randn(2, 3, 20)
>>> output, hn = rnn(input, h0)2. torch.nn.LSTM
PyTorch 实现的 LSTM 计算过程如下:
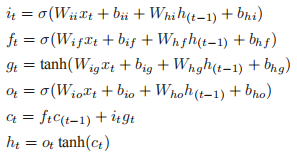
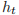 是 t 时刻的隐藏状态,
是 t 时刻的隐藏状态,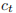 是 t 时刻的单元状态,
是 t 时刻的单元状态,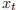 是 t 时刻的输入。
是 t 时刻的输入。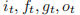 分别是t 时刻的输入门、遗忘门、单元门和输出门。
分别是t 时刻的输入门、遗忘门、单元门和输出门。构造函数参数如下所示。
input_size:输入 x 的特征维数。
hidden_size:隐藏单元个数。
num_layers:LSTM 的层数,默认为 1。
bias:是否有偏置。
batch_first:如果为 True,那么输入要求是 (batch, seq, feature),否则是 (seq, batch, feature),默认是 False。
dropout:Dropout 概率。默认为 0,表示没有 Dropout。
bidirectional:是否为双向 RNN。默认为 False。
输入 input,(h_0, c_0) 格式如下所示。
input:shape 是 (seq_len, batch, input_size),如果构造参数 batch_first 是 True,则要求输入是 (batch, seq_len, input_size)。
h_0:shape 是 (num_layers * num_directions, batch, hidden_size)。
c_0:shape 是 (num_layers * num_directions, batch, hidden_size)。
输出 output,(hn, cn) 格式如下所示。
output:最后一层 LSTM 的输出,shape (seq_len, batch, hidden_size * num_directions)。
h_n:隐藏状态,shape 是 (num_layers * num_directions, batch, hidden_size)。
c_n:单元状态,shape 是 (num_layers * num_directions, batch, hidden_size)。它包含的变量如下所示。
weight_ih_l[k]:第 k 层输入到隐藏单元的可训练的权重。shape 是 (4*hidden_size * input_size)。
weight_hh_l[k]:第 k 层(上一个时刻的)隐藏单元到隐藏单元的权重。shape 是 (4*hidden_size * hidden_size)。
bias_ih_l[k]:第 k 层输入到隐藏单元的偏置。shape 是 (4*hidden_size)。
bias_hh_l[k]:第 k 层隐藏单元到隐藏单元的偏置。shape 也是 (4*hidden_size)。
示例:
>>> rnn = nn.LSTM(10, 20, 2)
>>> input = torch.randn(5, 3, 10)
>>> h0 = torch.randn(2, 3, 20)
>>> c0 = torch.randn(2, 3, 20)
>>> output, hn = rnn(input, (h0, c0))和前面的 RNN 例子类似,只是多了一个 h0。
3. torch.nn.GRUGRU 的计算过程如下:
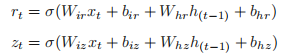
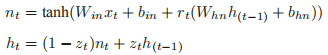
input_size:输入 x 的特征维数。
hidden_size:隐藏单元个数。
num_layers:LSTM 的层数,默认为 1。
bias:是否有偏置。
batch_first:如果为 True,那么输入要求是 (batch, seq, feature),否则是 (seq, batch, feature),默认是 False。
dropout:Dropout 概率。默认为 0,表示没有 Dropout。
bidirectional:是否为双向 RNN。默认为 False。
它的输入是 input,
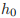 格式如下所示。
格式如下所示。input:shape 是 (seq_len, batch, input_size),如果构造参数 batch_first 是 True,则要求输入是 (batch, seq_len, input_size)。
- :shape 是 (num_layers * num_directions, batch, hidden_size)。
关于 PyTorch 的输出,比如
的 shape 是 (num_layers * num_directions, batch, hidden_size),虽然文档没有明确说明,但是我们一般可以“猜测”输出的第一维 (num_layers * num_directions)是先 num_layers 后 num_directions 的。举例来说,如果 RNN 是 2 层且是双向的,那么输出 h0 的顺序是这样的:(layer1-正向的隐藏状态,layer1-逆向的隐藏状态,layer2-正向的隐藏状态,layer2-逆向的隐藏状态)。它的输出是 output,hn 格式如下所示。
output:最后一层的输出,shape 是 (seq_len, batch, hidden_size * num_directions)。
hn:shape 是 (num_layers * num_directions, batch, hidden_size)。
它包含的变量如下所示。
weight_ih_l[k]:第 k 层输入到隐藏单元的可训练的权重。shape 是 (3*hidden_size * input_size)。
weight_hh_l[k]:第 k 层(上一个时刻的)隐藏单元到隐藏单元的权重。shape 是 (3*hidden_size * hidden_size)。
bias_ih_l[k]:第 k 层输入到隐藏单元的偏置。shape 是 (3*hidden_size)。
bias_hh_l[k]:第 k 层隐藏单元到隐藏单元的偏置。shape 也是 (3*hidden_size)。
示例:
>>> rnn = nn.GRU(10, 20, 2)
>>> input = torch.randn(5, 3, 10)
>>> h0 = torch.randn(2, 3, 20)
>>> output, hn = rnn(input, h0)定义模型
之前的姓名分类例子中是没有 Embedding 的,直接用字母的 one-hot 作为输入。这里会使用Embedding。
import torch
import torch.nn as nn
from torch.autograd import Variable
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.encoder = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers)
self.decoder = nn.Linear(hidden_size, output_size)
def forward(self, input, hidden):
input = self.encoder(input.view(1, -1))
output, hidden = self.gru(input.view(1, 1, -1), hidden)
output = self.decoder(output.view(1, -1))
return output, hidden
def init_hidden(self):
return Variable(torch.zeros(self.n_layers, 1, self.hidden_size))输入和输出
把 String 变成一个 LongTensor,做法是遍历每一个字母,然后把它变成 all_characters 里的下标。
# 把String变成LongTensor
def char_tensor(string):
tensor = torch.zeros(len(string)).long()
for c in range(len(string)):
tensor[c] = all_characters.index(string[c])
return Variable(tensor)
print(char_tensor('abcDEF'))最后随机选择一个字符串作为训练数据,输入是字符串的第一个字母到倒数第二个字母,而输出是从第二个字母到最后一个字母。比如字符串是“abc”,那么输入就是“ab”,输出是“bc”。
def random_training_set():
chunk = random_chunk()
inp = char_tensor(chunk[:-1])
target = char_tensor(chunk[1:])
return inp, target生成句子
为了评估模型生成的效果,需要让它来生成一些句子。
def evaluate(prime_str='A', predict_len=100, temperature=0.8):hidden = decoder.init_hidden()prime_input = char_tensor(prime_str)predicted = prime_str# 假设输入的前缀是字符串prime_str,先用它来改变隐藏状态for p in range(len(prime_str) - 1):_, hidden = decoder(prime_input[p], hidden)inp = prime_input[-1]for p in range(predict_len):output, hidden = decoder(inp, hidden)# 根据输出概率采样output_dist = output.data.view(-1).div(temperature).exp()top_i = torch.multinomial(output_dist, 1)[0]# 用上一个输出作为下一个输入predicted_char = all_characters[top_i]predicted += predicted_charinp = char_tensor(predicted_char)return predicted训练
def train(inp, target):
hidden = decoder.init_hidden()
decoder.zero_grad()
loss = 0
for c in range(chunk_len):
output, hidden = decoder(inp[c], hidden)
loss += criterion(output, target[c])
loss.backward()
decoder_optimizer.step()
return loss.data[0] / chunk_len接下来定义模型的参数,初始化模型,开始训练:
n_epochs = 2000
print_every = 100
plot_every = 10
hidden_size = 100
n_layers = 1
lr = 0.005
decoder = RNN(n_characters, hidden_size, n_characters, n_layers)
decoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
start = time.time()
all_losses = []
loss_avg = 0
for epoch in range(1, n_epochs + 1):
loss = trainrandom_training_set())loss_avg += lossif epoch
print('[print(evaluate('Wh', 100), 'n')if epoch
all_losses.append(loss_avg / plot_every)loss_avg = 0import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
plt.figure()
plt.plot(all_losses)结果如图 4.7 所示。
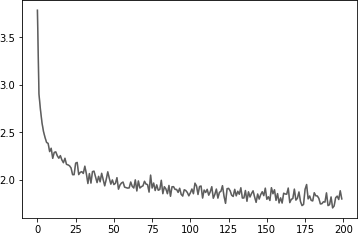 4.7 训练的损失测试
4.7 训练的损失测试测试
print(evaluate('Th', 200, temperature=0.8))
输出:
Ther
you go what loved ancut that me to the werefered all your to they
That the pessce, shap treed for time sok theie chator
The vuent tere my treance her will not youe
Which my bessin, shall brie lans以上内容节选自李理老师新书《深度学习理论与实战:基础篇》,通过这篇文章,你学会如何用RNN生成莎士比亚风格句子了吗?想要了解关于RNN的更多干货知识,关注AI科技大本营微信公众号,评论区分享你对本文的学习心得,营长将从中选出5条优质评论,送出《深度学习理论与实战:基础篇》一本。
相关文章:

图像相似度计算之哈希值方法OpenCV实现
感知哈希算法(perceptual hash algorithm),它的作用是对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。结果越接近,就说明图像越相似。 实现步骤: 1. 缩小尺寸:将图像缩小到8*8的尺寸&am…
七夕大礼包:26个AI学习资源送给你!
整理 | Jane出品 | AI科技大本营(ID:rgznai100)免费的在线学习课程一直是大多数人学习 AI 知识和技能的方式之一。今天,基于 Github 上一位小姐姐 Chip Huyen 分享的 10 门机器学习课程,AI科技大本营将这份收藏大礼包进…

HTML Inspector – 帮助你编写高质量的 HTML 代码
HTML Inspector 是一款代码质量检测工具,帮助你编写更优秀的 HTML 代码。HTML Inspector 使用 JavaScript 编写,运行在浏览器中,是最好的 HTML 代码检测工具。 您可能感兴趣的相关文章Metronic – 赞!Bootstrap 响应式后台管理模板…
Git简介以及与SVN的区别
Git是由著名Linux内核(Kernel)开发者Linus Torvalds为了便利维护Linux而开发的。 Git是一个分布式的版本控制系统。作为一个分布式的版本控制系统,在Git中并不存在主库这样的概念,每一份复制出的库都可以独立使用,任何两个库之间的不一致之处…
java集合中某一个元素出现的次数
int count Collections.frequency(list, key); java的内置方法转载于:https://www.cnblogs.com/wysAC666/p/10252676.html

加密解密-DES算法和RSA算法
昨天忽然对加密解密有了兴趣,今天上班查找了一些资料,现在就整理一下吧:) 一.DES算法 这种算法如图所示,这里将描述它的每一个步骤。这个算法进行了16次迭代(圈),把各块明文交织起来…
开始Dojo之路
开始Dojo之路waiting……转载于:https://blog.51cto.com/frabbit2013/1242108
图像相似度计算之直方图方法OpenCV实现
操作步骤: 1. 载入图像(灰度图或者彩色图),并使其大小一致; 2. 若为彩色图,增进行颜色空间变换,从RGB转换到HSV,若为灰度图则无需变换; 3. 若为灰度图,直接计算其直方…

黄皓之后,计算机科学上帝Don Knuth仅用一页纸证明布尔函数敏感度猜想
作者 | Freesia编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100)导读:近日,美国艾默里大学计算机与数学科学系教授黄皓(Hao Huang)用一篇短短 6 页的论文证明了布尔函数,引发了计算机和数学领域社…

数位DP 不断学习中。。。。
1, HDU 2089 不要62 :http://acm.hdu.edu.cn/showproblem.php?pid2089 题意:不能出现4,或者相邻的62, dp[i][0],表示不存在不吉利数字 dp[i][1],表示不存在不吉利数字,且最高位为2 dp[i][2],表示存在不吉利数字 #i…
linux 性能 管理 与 优化
一、影响Linux服务器性能的因素操作系统级:CPU、内存、磁盘I/O带宽、网络I/O带宽程序应用级二、系统性能评估影响性能因素 评判标准 好 坏 糟糕 CPU user% sys%< 70% user% sys% 85% user% sys% >90% 内存 Swap In(si&…
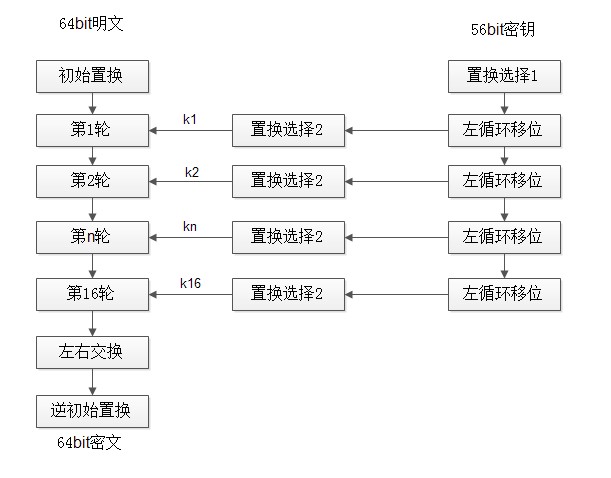
对称加密算法之DES介绍
DES(Data Encryption Standard)是分组对称密码算法。DES采用了64位的分组长度和56位的密钥长度,它将64位的输入经过一系列变换得到64位的输出。解密则使用了相同的步骤和相同的密钥。DES的密钥长度为64位,由于第n*8(n1,2,…8)是校验位,因此实…
200行代码解读TDEngine背后的定时器
作者 | beyondma来源 | CSDN博客导读:最近几周,本文作者几篇有关陶建辉老师最新的创业项目-TdEngine代码解读文章出人意料地引起了巨大的反响,原以为C语言已经是昨日黄花,不过从读者的留言来看,C语言还是老当益壮&…

fastJson结合Nutz.Mapl的进阶应用
为什么80%的码农都做不了架构师?>>> 今天要做一堆数据的序列化, 反序列化, 序列化没问题, 反序列化却遇到了点小意外, 这一堆数据不是一个类!!!!!!当然可以通过类内部的一个类型对象来判断, 但是fastJson并没有这个功能, 只能自己一个一个的遍历一个一个…
OpenCV实现遍历文件夹下所有文件
OpenCV中有实现遍历文件夹下所有文件的类Directory,它里面包括3个成员函数:(1)、GetListFiles:遍历指定文件夹下的所有文件,不包括指定文件夹内的文件夹;(2)、GetListFolders:遍历指定文件夹下的所有文件夹…
阿里、京东、快手、华为......他们是如何构建一个个推荐系统“帝国”的?
推荐系统在人们的日常生活中随处可见,成为我们生命中不可或缺的一部分。作为当今应用最为广泛和成熟的 AI 技术之一,它是信息生产者、传播者与用户之间的桥梁,可以让信息最精准、最高效地到达需求不一的用户面前。每天打开手机或电脑端的大部…
前端基础_ES6
声明 三大关键字声明变量:var (ES5语法) let (ES6语法)声明常量:const (ES6语法) var 声明变量特性1、支持 函数作用域2、支持 JS预解析 (所谓变量提升)3、支持 重复声明 ÿ…
5大典型模型测试单机训练速度超对标框架,飞桨如何做到?
导读:飞桨(PaddlePaddle)致力于让深度学习技术的创新与应用更简单。在单机训练速度方面,通过高并行、低开销的异步执行策略和高效率的核心算子,优化静态图训练性能,在Paddle Fluid v1.5.0的基准测试中&…
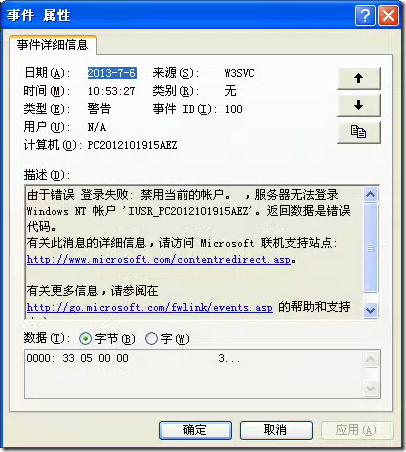
windowsXP用户被禁用导致不能网站登录
1、查看系统事件,发现弹出如下的错误 2、根据上面的错误,我们很容易就可以判断是禁用了账户引起的 2.1后面进入计算机管理,再进入用户管理 2.2双击点开Internet来宾用于,发现此用户已经停用了。 2.3双击点开与IIS访问有关用户&…

从头到尾使用Geth的说明-3-geth参数说明和环境配置
1.参数说明 ETHEREUM选项:--config value TOML 配置文件--datadir "/home/user4/.ethereum" 数据库和keystore密钥的数据目录--keystore keystore存放目录(默认在datadir内)--nousb …
OpenSSL中对称加密算法DES常用函数使用举例
主要包括3个文件: 1. cryptotest.h:#ifndef _CRYPTOTEST_H_ #define _CRYPTOTEST_H_#include <string>using namespace std;typedef enum {GENERAL 0,ECB,CBC,CFB,OFB,TRIPLE_ECB,TRIPLE_CBC }CRYPTO_MODE;string DES_Encrypt(const string cleartext, const…

从原理到落地,七大维度读懂协同过滤推荐算法
作者丨gongyouliu来源 | 大数据与人工智能导语:本文会从协同过滤思想简介、协同过滤算法原理介绍、离线协同过滤算法的工程实现、近实时协同过滤算法的工程实现、协同过滤算法应用场景、协同过滤算法的优缺点、协同过滤算法落地需要关注的几个问题等7个方面来讲述。…
sql查询语句优化需要注意的几点
为了获得稳定的执行性能,SQL语句越简单越好。对复杂的SQL语句,要设法对之进行简化。 常见的简化规则如下: 1)不要有超过5个以上的表连接(JOIN) 2)考虑使用临时表或表变量存放中间结果。 3&#…
决策树算法原理(ID3,C4.5)
决策树算法原理(CART分类树) CART回归树 决策树的剪枝 决策树可以作为分类算法,也可以作为回归算法,同时特别适合集成学习比如随机森林。 1. 决策树ID3算法的信息论基础 1970年昆兰找到了用信息论中的熵来度量决策树的决策选择过程,昆兰把这…

对称加密算法之RC4介绍及OpenSSL中RC4常用函数使用举例
RC4是一种对称密码算法,它属于对称密码算法中的序列密码(streamcipher,也称为流密码),它是可变密钥长度,面向字节操作的流密码。 RC4是流密码streamcipher中的一种,为序列密码。RC4加密算法是Ron Rivest在1987年设计出的密钥长度…
SpringMVC中实现的token,防表单重复提交
一:首先创建一个token处理类 ,这里的类名叫 TokenHandlerprivate static Logger logger Logger.getLogger(TokenHandler.class);static Map<String, String> springmvc_token new HashMap<String, String>();//生成一个唯一值的tokenSupp…
利用CxImage实现编解码Gif图像代码举例
Gif(Graphics Interchange Format,图形交换格式)是由CompuServe公司在1987年开发的图像文件格式,分为87a和89a两种版本。Gif是基于LZW算法的无损压缩算法。Gif图像是基于颜色表的,最多只支持8位(256色)。Gif减少了图像调色板中的色彩数量&…
SpringBoot b2b2c 多用户商城系统 ssm b2b2c
来源: SpringBoot b2b2c 多用户商城系统 ssm b2b2c用java实施的电子商务平台太少了,使用spring cloud技术构建的b2b2c电子商务平台更少,大型企业分布式互联网电子商务平台,推出PC微信APP云服务的云商平台系统,其中包括…

AI“生死”落地:谁有资格入选AI Top 30+案例?
2019 年,人工智能应用落地的重要性正在逐步得到验证,这是关乎企业生死攸关的一环。科技巨头、AI 独角兽还有起于草莽的创业公司在各领域进行着一场多方角斗。进行平台布局的科技巨头们,正在加快承载企业部署 AI 应用的步伐,曾经无…
liunx 下su 和sudo 的区别
一. 使用 su 命令临时切换用户身份1、su 的适用条件和威力su命令就是切换用户的工具,怎么理解呢?比如我们以普通用户beinan登录的,但要添加用户任务,执行useradd ,beinan用户没有这个权限,而这个权限恰恰由…