5大典型模型测试单机训练速度超对标框架,飞桨如何做到?

导读:飞桨(PaddlePaddle)致力于让深度学习技术的创新与应用更简单。在单机训练速度方面,通过高并行、低开销的异步执行策略和高效率的核心算子,优化静态图训练性能,在Paddle Fluid v1.5.0的基准测试中,在7个典型模型上进行了测试(图像领域5个,NLP领域2个),其中5个模型的速度显著优于对标框架(大于15%),2个模型与对标框架持平(5%之内)。如果想让单机训练速度更快,可以根据这篇文档的建议从网络构建、数据准备、模型训练三个方向了解飞桨单机训练中常用的优化方法。来一组测试数据先睹为快。
模型名称 | 对标开源框架 | 飞桨 | 对标开源框架 | 吞吐量对比(%) 飞桨VS对标开源框架 | |
1 | DeepLab V3+ | TensorFlow | 13.70 examples/s | 6.40 examples/s | + 113.98% |
2 | YOLOv3 | MXNet | 29.90 examples/s | 18.58 examples/s | + 60.95% |
3 | BERT | TensorFlow | 4.04 steps/s | 3.42 steps/s | + 18.23% |
4 | Mask-RCNN | PyTorch | 3.81 examples/s | 3.24 examples/s | + 17.62% |
5 | CycleGAN | TensorFlow | 7.51 examples/s | 6.45 examples/s | + 16.44% |
6 | SE-ResNeXt50 | PyTorch | 168.33 examples/s | 163.13 examples/s | + 3.19% |
7 | Transformer | TensorFlow | 4.87 examples/s | 4.75 examples/s | + 2.42% |
测试环境如下:
PaddlePaddle version:1.5.0
Tensorflow version:1.12.0
PyTorch version:1.1.0
MXNet version:1.4.1
GPU:Tesla V100-SXM2
CPU:Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz,38核
Nvida driver: 418.39
CUDNN VERSION:7.4.2.24
CUDA VERSION:9.0.176,单卡模式
1. 网络构建过程中的配置优化
1.1 减少模型中Layer的个数
(1) fluid.layers.softmax_with_cross_entropy,该操作其实是fluid.layers.softmax和fluid.layers.cross_entropy的组合,因此如果模型中有出现fluid.layers.softmax和fluid.layers.cross_entropy的组合,可以直接用fluid.layers.softmax_with_cross_entropy替换;
(2) 如果模型中需要对数据进行标准化,可以直接使用fluid.layers.data_norm,而不用通过一系列layer组合出数据的标准化操作。因此,建议在构建模型时优先使用飞桨提供的单个Layer完成所需操作,这样减少模型中Layer的个数,并因此加速模型训练。
2. 数据准备优化
def data_reader (width, height): def reader(): while True: yield np.random.uniform(-1, 1, size=width*height), \ np.random.randint(0,10) return readertrain_data_reader = data_reader(32, 32)
def reader():
while True:
yield np.random.uniform(-1, 1, size=width*height), \
np.random.randint(0,10)
return reader
train_data_reader = data_reader(32, 32)
飞桨提供了两种方式从Data Reader中读取数据:同步数据读取和异步数据读取。
2.1 同步数据读取
同步数据读取是一种简单并且直观的数据准备方式,代码示例如下:Image = paddle.layer.data("image", ...)label = paddle.layer.data("label", ...)# 模型定义# ……prediction = fluid.layers.fc(input= image, size=10)loss = fluid.layers.cross_entropy(input= prediction, label= label)avg_loss = fluid.layers.mean(loss)# ……# 读取数据# paddle.dataset.mnist.train()返回数据读取的Reader,每次可以从Reader中读取一条样本,batch_size为128train_reader = paddle.batch(paddle.dataset.mnist.train(), 128)end = time.time()for batch_id, batch in enumerate(train_reader): data_time = time.time() - end # 训练网络 executor.run(feed=[...], fetch_list=[...]) batch_time = time.time() - end end = time.time()
label = paddle.layer.data("label", ...)
# 模型定义
# ……
prediction = fluid.layers.fc(input= image, size=10)
loss = fluid.layers.cross_entropy(input= prediction, label= label)
avg_loss = fluid.layers.mean(loss)
# ……
# 读取数据
# paddle.dataset.mnist.train()返回数据读取的Reader,每次可以从Reader中读取一条样本,batch_size为128
train_reader = paddle.batch(paddle.dataset.mnist.train(), 128)
end = time.time()
for batch_id, batch in enumerate(train_reader):
data_time = time.time() - end
# 训练网络
executor.run(feed=[...], fetch_list=[...])
batch_time = time.time() - end
end = time.time()
2.2异步数据读取
train_py_reader = fluid.layers.py_reader( capacity=10, shapes=((-1, 784), (-1, 1)), dtypes=('float32', 'int64'), name="train_reader", use_double_buffer=True)# 使用 read_file() 方法从py_reader中获取模型的输入image, label = fluid.layers.read_file(reader)# 模型定义# ……prediction = fluid.layers.fc(input= image, size=10)loss = fluid.layers.cross_entropy(input= prediction, label= label)avg_loss = fluid.layers.mean(loss)# ……# 读取数据train_reader = paddle.batch(paddle.dataset.mnist.train(), 128)train_py_reader.decorate_paddle_reader(train_reader)# 启动py_readertrain_py_reader.start()try: end = time.time() while True: print("queue size: ", train_py_reader.queue.size()) loss, = executor.run(fetch_list=[...]) # ... batch_time = time.time() - end end = time.time() batch_id += 1except fluid.core.EOFException: train_py_reader.reset()
shapes=((-1, 784), (-1, 1)),
dtypes=('float32', 'int64'),
name="train_reader",
use_double_buffer=True)
# 使用 read_file() 方法从py_reader中获取模型的输入
image, label = fluid.layers.read_file(reader)
# 模型定义
# ……
prediction = fluid.layers.fc(input= image, size=10)
loss = fluid.layers.cross_entropy(input= prediction, label= label)
avg_loss = fluid.layers.mean(loss)
# ……
# 读取数据
train_reader = paddle.batch(paddle.dataset.mnist.train(), 128)
train_py_reader.decorate_paddle_reader(train_reader)
# 启动py_reader
train_py_reader.start()
try:
end = time.time()
while True:
print("queue size: ", train_py_reader.queue.size())
loss, = executor.run(fetch_list=[...])
# ...
batch_time = time.time() - end
end = time.time()
batch_id += 1
except fluid.core.EOFException:
train_py_reader.reset()
用户首先需要通过fluid.layers.py_reader定义py_reader对象,并使用 read_file() 方法从py_reader中获取模型的输入,然后根据输入构建模型,再然后用decorate_paddle_reader将自定义的Reader与py_reader绑定。在训练开始之前,通过调用start()方法来启动数据读取。在数据读取结束之后,executor.run会抛出fluid.core.EOFException,表示训练已经遍历完Reader中的所有数据。 采用异步数据读取时,Python端和C++端共同维护一个数据队列,Python端启动一个线程,负责向队列中插入数据,C++端在训练/预测过程中,从数据队列中获取数据,并将该数据从对队列中移除。用户可以在程序运行过程中,监测数据队列是否为空,如果队列始终不为空,表明数据准备的速度比模型执行的速度快,这种情况下数据读取可能不是瓶颈。 另外,飞桨提供的一些FLAGS也能很好的帮助分析性能。如果用户希望评估一下在完全没有数据读取开销情况下模型的性能,可以设置一下环境变量:FLAGS_reader_queue_speed_test_mode,在该变量为True情况下,C++端从数据队列中获取数据之后,不会从数据队列中移除,这样能够保证数据队列始终不为空,从而避免了C++端读取数据时的等待开销。 需要特别注意的是,FLAGS_reader_queue_speed_test_mode只能在性能分析时打开,正常训练/预测模型时需要关闭。 为降低训练的整体时间,建议用户使用异步数据读取的方式,并开启 use_double_buffer=True 。用户可根据模型的实际情况设置数据队列的大小。如果数据准备的时间大于模型执行的时间,或者出现了数据队列为空的情况,就需要考虑对数据读取Reader进行加速。常用的方法是使用多进程准备数据,可以参考https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/yolov3/reader.py 更多异步数据读取的介绍请参考:https://www.paddlepaddle.org.cn/documentation/docs/en/1.5/user_guides/howto/prepare_data/use_py_reader_en.html
3. 模型训练相关优化
3.1 飞桨的执行器介绍
执行器 | 执行对象 | 执行策略 |
Executor | Program | 根据 Program 中Operator定义的先后顺序依次运行 |
ParallelExecutor | SSA Graph | 根据Graph中各个节点之间的依赖关系,通过多线程运行 |
可以看出,Executor的内部逻辑非常简单,但性能可能会弱一些,因为Executor对于program中的操作是串行执行的。而Parallel Executor首先会将program转变为计算图,并分析计算图中节点间的连接关系,对图中没有相互依赖的节点(OP),通过多线程并行执行。 因此,Executor是一个轻量级的执行器,目前主要用于参数初始化、模型保存、模型加载。Parallel Executor是Executor的升级版本,目前Parallel Executor主要用于模型训练,包括单机单卡、单机多卡以及多机多卡训练。 Parallel Executor执行计算图之前,可以对计算图进行一些优化,比如使计算图中的一些操作是In-place的、将计算图中的参数更新操作进行融合等。用户还可以调整Parallel Executor执行过程中的一些配置,比如执行计算图的线程数等。这些配置分别是构建策略(BuildStrategy)和执行策略(ExecutionStrategy)参数来设置的。 一个简单的使用示例如下:
build_strategy = fluid.BuildStrategy()build_strategy.enable_inplace = Truebuild_strategy.fuse_all_optimizer_ops=Trueexec_strategy = fluid.ExecutionStrategy() exec_strategy.num_threads = 4train_program = fluid.compiler.CompiledProgram(main_program).with_data_parallel( loss_name=loss.name, build_strategy=build_strategy, exec_strategy=exec_strategy)place = fluid.CUDAPlace(0)exe = Executor(place)# 使用py_reader读取数据,因此执行时不需要feedfetch_outs = exe.run(train_program, fetch_list=[loss.name],)
build_strategy.fuse_all_optimizer_ops=True
exec_strategy = fluid.ExecutionStrategy()
exec_strategy.num_threads = 4
train_program = fluid.compiler.CompiledProgram(main_program).with_data_parallel(
loss_name=loss.name,
build_strategy=build_strategy,
exec_strategy=exec_strategy)
place = fluid.CUDAPlace(0)
exe = Executor(place)
# 使用py_reader读取数据,因此执行时不需要feed
fetch_outs = exe.run(train_program, fetch_list=[loss.name],)
更多关于Parallel Executor的介绍请参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/1.5/api_guides/low_level/parallel_executor.html
更多关于CompiledProgram的介绍请参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/1.5/api_guides/low_level/compiled_program.html
3.2 构建策略(BuildStrategy)配置参数介绍
构建策略的详细介绍如下:
选项 | 类型 | 默认值 | 说明 |
reduce_strategy | fluid.BuildStrategy.ReduceStrategy | fluid.BuildStrategy.ReduceStrategy.AllReduce | 使用数据并行训练模型时选用 AllReduce 模式训练还是 Reduce 模式训练。 |
enable_backward_optimizer_op_deps | bool | FALSE | 在反向操作和参数更新操作之间添加依赖,保证在所有的反向操作都运行结束之后才开始运行参数更新操作。 |
fuse_all_optimizer_ops | bool | FALSE | 对模型中的参数更新算法进行融合 |
fuse_all_reduce_ops | bool | FALSE | 多卡训练时,将all_reduce 操作进行融合 |
fuse_relu_depthwise_conv | bool | FALSE | 如果模型中存在relu和depthwise_conv操作,并且是连接的,即relu->depthwise_conv,将这两个操作合并为一个 |
fuse_broadcast_ops | bool | FALSE | 在 Reduce 模式下,对最后的多个Broadcast操作融合为一个 |
mkldnn_enabled_op_types | list | {} | 如果是CPU训练,可以用 mkldnn_enabled_op_types指明模型中的哪些操作可以使用mkldnn库,默认情况下,模型中用到的操作如果在飞桨目前支持的可以使用mkldnn库计算的列表中,这些操作都会调用mkldnn库的接口进行计算 |
debug_graphviz_path | str | “” | 将Graph以graphviz格式输出到debug_graphviz_path所指定的文件 |
参数说明:
(1)关于 reduce_strategy , Parallel Executor 对于数据并行支持两种参数更新模式:AllReduce 和 Reduce 。在 AllReduce 模式下,各个节点上计算得到梯度之后,调用 AllReduce 操作,梯度在各个节点上聚合,然后各个节点分别进行参数更新。在 Reduce 模式下,参数的更新操作被均匀的分配到各个节点上,即各个节点计算得到梯度之后,将梯度在指定的节点上进行 Reduce ,然后在该节点上进行参数的更新,最后将更新之后的参数Broadcast到其他节点。
即:如果模型中有100个参数需要更新,训练使用的节点数为4,在 AllReduce 模式下,各个节点需要分别对这100个参数进行更新;在 Reduce 模式下,各个节点需要分别对这25个参数进行更新,最后将更新的参数Broadcast到其他节点。注意:如果是使用CPU进行数据并行训练,在Reduce模式下,不同CPUPlace 上的参数是共享的,所以在各个CPUPlace 上完成参数更新之后不用将更新后的参数Broadcast到其他CPUPlace。
(2)关于 enable_backward_optimizer_op_deps ,在多卡训练时,打开该选项可能会提升训练速度。
(3)关于 fuse_all_optimizer_ops ,目前只支持SGD、Adam和Momentum算法。注意:目前不支持sparse参数梯度。
(4)关于 fuse_all_reduce_ops ,多GPU训练时,可以对 AllReduce 操作进行融合,以减少 AllReduce 的调用次数。默认情况下会将同一layer中参数的梯度的 AllReduce 操作合并成一个,比如对于 fluid.layers.fc 中有Weight和Bias两个参数,打开该选项之后,原本需要两次 AllReduce 操作,现在只用一次 AllReduce 操作。
此外,为支持更大粒度的参数梯度融合,飞桨提供了 FLAGS_fuse_parameter_memory_size 选项,用户可以指定融合AllReduce操作之后,每个 AllReduce 操作的梯度字节数,比如希望每次 AllReduce 调用传输64MB的梯度,export FLAGS_fuse_parameter_memory_size=64 。注意:目前不支持sparse参数梯度。
(5)关于 mkldnn_enabled_op_types ,目前飞桨的Op中可以使用mkldnn库计算的操作包括:transpose, sum, softmax, requantize, quantize, pool2d, lrn, gaussian_random, fc, dequantize, conv2d_transpose, conv2d, conv3d, concat, batch_norm, relu, tanh, sqrt, abs.
3.3 执行策略(ExecutionStrategy)配置参数介绍
选项 | 类型 | 默认值 | 说明 |
num_iteration_per_drop_scope | INT | 1 | 经过多少次迭代之后清理一次local execution scope |
num_threads | INT | 经验值: 对于CPU:2*dev_count;对于GPU:4*dev_count. | ParallelExecutor 中执行所有Op使用的线程池大小 |
参数说明:
(1)关于 num_iteration_per_drop_scope ,框架在运行过程中会产生一些临时变量,通常每经过一个batch就要清理一下临时变量,但是由于GPU是异步设备,在清理之前需要对所有的GPU调用一次同步操作,因此耗费的时间较长。为此我们在 execution_strategy 中添加了 num_iteration_per_drop_scope 选项。用户可以指定经过多少次迭代之后清理一次。
(2)关于 num_threads ,ParallelExecutor 根据OP之间的依赖关系确定OP的执行顺序,即:当OP的输入都已经变为ready状态之后,该OP会被放到一个队列中,等待被执行。ParallelExecutor 内部有一个任务调度线程和一个线程池,任务调度线程从队列中取出所有Ready的OP,并将其放到线程队列中。num_threads 表示线程池的大小。根据以往的经验,对于CPU任务,num_threads=2*dev_count 时性能较好,对于GPU任务,num_threads=4*dev_count 时性能较好。注意:线程池不是越大越好。
4. 运行时FLAGS设置优化
Fluid中有一些FLAGS可以有助于性能优化:
(1)FLAGS_cudnn_exhaustive_search表示在调用cuDNN中的卷积操作时,根据输入数据的shape等信息,采取穷举搜索的策略从算法库中选取到更快的卷积算法,进而实现对模型中卷积操作的加速。需要注意的是:a. 在搜索算法过程中需要使用较多的显存,如果用户的模型中卷积操作较多,或者GPU卡显存较小,可能会出现显存不足问题。
b. 通过穷举搜索选择好算法之后,该算法会进入Cache,以便下次运行时,如果输入数据的shape等信息不变,直接使用Cache中算法。
(2)FLAGS_enable_cublas_tensor_op_math表示是否使用TensorCore加速cuBLAS等NV提供的库中的操作。需要注意的是,这个环境变量只在Tesla V100以及更新的GPU上适用,且可能会带来一定的精度损失,通常该损失不会影响模型的收敛性。
5.最佳实践(Best Practise)
(1)尽可能的使用飞桨提供的单个layer实现所需操作。(2)采用异步数据读取。(3)模型训练相关优化:
a. 使用ParallelExecutor作为底层执行器,代码示例:
compiled_prog = compiler.CompiledProgram( fluid.default_main_program()).with_data_parallel( loss_name=loss.name)
loss_name=loss.name)
如果是单卡训练,也可以调用with_data_parallel方法。
b. 如果模型中参数的梯度都是非sparse的,可以打开fuse_all_optimizer_ops选项,将多个参数更新操作融合为一个。
c. 如果是多卡训练,可以打开enable_backward_optimizer_op_deps、fuse_all_reduce_ops选项。如果想指定每次每次AllReduce操作的数据大小,可以设置FLAGS_fuse_parameter_memory_size,比如 export FLAGS_fuse_parameter_memory_size=1,表示每次 AllReduce 调用传输1MB的梯度。
d. 使用CPU做数据并行训练时,推荐使用Reduce模型,因为在使用CPU进行数据并行训练时,在Reduce模式下,不同CPUPlace 上的参数是共享的,所以在各个CPUPlace 上完成参数更新之后不用将更新后的参数Broadcast到其他CPUPlace上,这对提升速度也有很大帮助。
e. 如果是Reduce模式,可打开fuse_broadcast_ops选项。
f. 如果用户的模型较小,比如mnist、language_model等,可以将num_threads设为1。
g. 在显存足够的前提下,建议将 exec_strategy.num_iteration_per_drop_scope 设置成一个较大的值,比如设置为100 ,这样可以避免反复地申请和释放内存。 目前我们正在推进这些配置自动化的工作:即根据输入的模型结构自动配置这些选项,争取在下一个版本中实现,敬请期待。 (4)FLAGS设置
FLAGS_cudnn_exhaustive_search = TrueFLAGS_enable_cublas_tensor_op_math = True
6.典型案例
飞桨提供了论文《Recurrent Neural Network Regularization》中基于LSTM循环神经网络(RNN)的language model的开源实现。相比于传统的语言模型方法,基于循环神经网络的语言模型方法能够更好地解决稀疏词的问题。 该模型的目的是给定一个输入的词序列,预测下一个词出现的概率。 模型中采用了序列任务常用的RNN网络,实现了一个两层的LSTM网络,然后使用LSTM的结果去预测下一个词出现的概率。由于数据的特殊性,每一个batch的last hidden和last cell会作为下一个batch的init hidden和init cell。
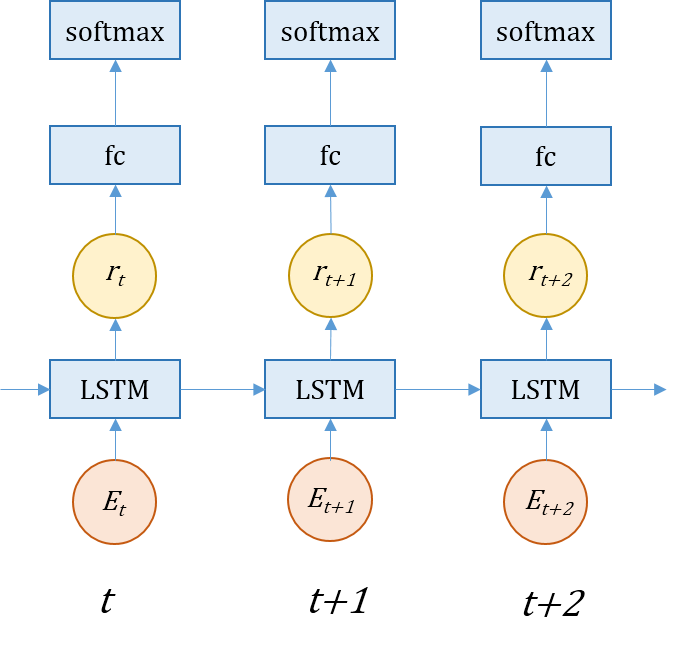
6.2 language_model单GPU训练性能优化效果
language_model中提供了4种RNN运行模式,分别为:static、padding、cudnn和lstm_basic。本案例中测试的为static模式。language_model中同样提供了small、medium、large三种模型配置,主要差别在于隐层的大小、RNN的步数、dropout比例上。我们对这个案例在模型配置、执行选项和数据读取三个方面都进行了优化,我们依次测试了如下优化版本的结果:
(1) Baseline版本
(2) 设置exec_strategy.num_threads = device_count
(3) 设置exec_strategy.num_iteration_per_drop_scope = 100
(4) 设置build_strategy.enable_inplace = True,build_strategy.memory_optimize = False
(5) 设置build_strategy.fuse_all_optimizer_ops = True
(6) 使用py_reader进行异步数据读取
(7) 配置优化
- reshape中设置inplace=True
- 使用split操作代替多次slice
优化前:
for index in range(len): input = layers.slice(input_embedding, axes=[1], starts=[index], ends=[index + 1]) …index in range(len):
input = layers.slice(input_embedding, axes=[1], starts=[index], ends=[index + 1])
…
优化后:
sliced_inputs = layers.split(input_embedding, num_or_sections=len, dim=1)for index in range(len): input = sliced_inputs[index] ...len, dim=1)
for index in range(len):
input = sliced_inputs[index]
...
- 减少reshape的次数
优化前:
for index in range(len): … res.append(layers.reshape(input, shape=[1, -1, hidden_size]))real_res = layers.concat(res, 0)real_res = layers.transpose(x=real_res, perm=[1, 0, 2])in range(len):
…
res.append(layers.reshape(input, shape=[1, -1, hidden_size]))
real_res = layers.concat(res, 0)
real_res = layers.transpose(x=real_res, perm=[1, 0, 2])
优化后:
for index in range(len): … res.append(input)real_res = layers.concat(res, 0)real_res = layers.reshape(real_res, shape=[len, -1, hidden_size], inplace=True)real_res = layers.transpose(x=real_res, perm=[1, 0, 2])
res.append(input)
real_res = layers.concat(res, 0)
real_res = layers.reshape(real_res, shape=[len, -1, hidden_size], inplace=True)
real_res = layers.transpose(x=real_res, perm=[1, 0, 2])
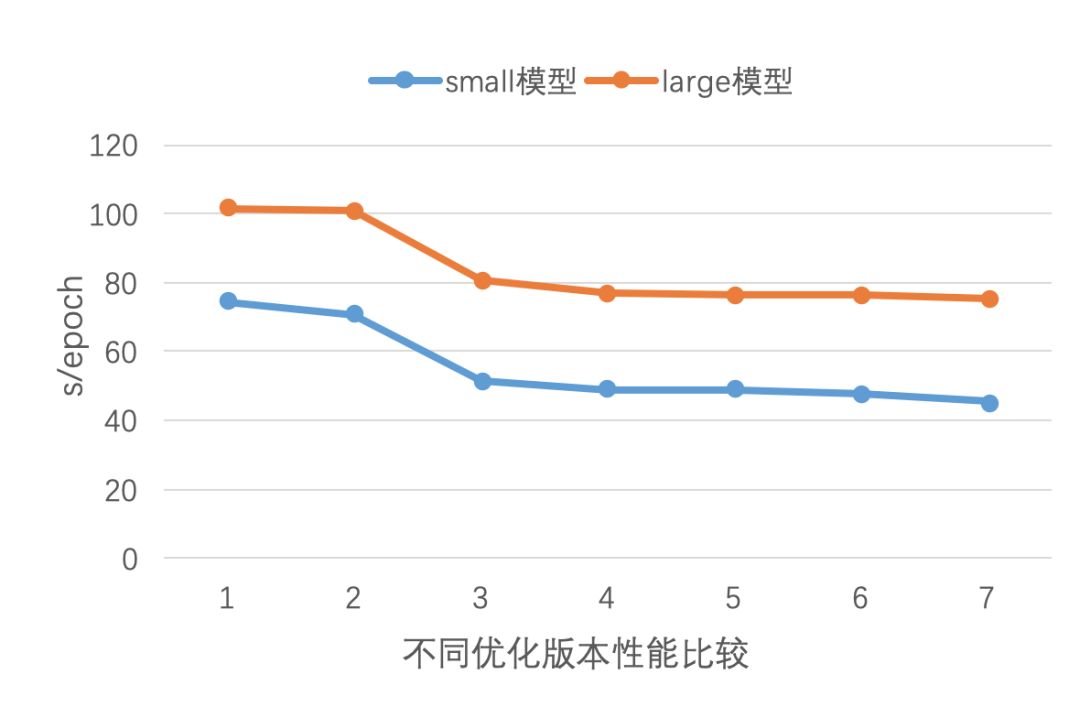
经过7个版本的优化,small和large模型最终分别获得了1.64x和1.35x的加速。从实验结果可以看出,即使是类似的网络结构,调整运行参数产生加速效果也不同,如设置exec_strategy.num_threads = device_count,small模型获得了4.9%的加速,large模型只获得0.8%的加速。另外,异步数据读取对该模型总体训练时间的减少也不明显,主要是因为这个模型的所使用的PTB数据集很小,可以提前将所有数据读取到内存里,因此训练时,数据准备部分对整体时延的影响较小。
有兴趣的同学,可以加入官方QQ群,您将遇上大批志同道合的深度学习同学。官方QQ群:432676488。 如果您想详细了解更多飞桨PaddlePaddle的相关内容,请点击文末阅读原文或参阅以下文档。 官网地址:https://www.paddlepaddle.org.cn
本文提到的项目地址:
模型名称 | 项目地址 | |
1 | DeepLab V3+ | https://github.com/PaddlePaddle/models/tree/v1.5/PaddleCV/deeplabv3%2B |
2 | YOLOv3 | https://github.com/PaddlePaddle/models/tree/v1.5/PaddleCV/yolov3 |
3 | BERT | https://github.com/PaddlePaddle/ERNIE |
4 | Mask-RCNN | https://github.com/PaddlePaddle/models/tree/v1.5/PaddleCV/rcnn |
5 | CycleGAN | https://github.com/PaddlePaddle/models/tree/v1.5/PaddleCV/PaddleGAN/cycle_gan |
6 | SE-ResNeXt50 | https://github.com/PaddlePaddle/models/tree/v1.5/PaddleCV/image_classification |
7 | Transformer | https://github.com/PaddlePaddle/models/tree/v1.5/PaddleNLP/models/neural_machine_translation/transformer |
相关文章:
windowsXP用户被禁用导致不能网站登录
1、查看系统事件,发现弹出如下的错误 2、根据上面的错误,我们很容易就可以判断是禁用了账户引起的 2.1后面进入计算机管理,再进入用户管理 2.2双击点开Internet来宾用于,发现此用户已经停用了。 2.3双击点开与IIS访问有关用户&…

从头到尾使用Geth的说明-3-geth参数说明和环境配置
1.参数说明 ETHEREUM选项:--config value TOML 配置文件--datadir "/home/user4/.ethereum" 数据库和keystore密钥的数据目录--keystore keystore存放目录(默认在datadir内)--nousb …

OpenSSL中对称加密算法DES常用函数使用举例
主要包括3个文件: 1. cryptotest.h:#ifndef _CRYPTOTEST_H_ #define _CRYPTOTEST_H_#include <string>using namespace std;typedef enum {GENERAL 0,ECB,CBC,CFB,OFB,TRIPLE_ECB,TRIPLE_CBC }CRYPTO_MODE;string DES_Encrypt(const string cleartext, const…

从原理到落地,七大维度读懂协同过滤推荐算法
作者丨gongyouliu来源 | 大数据与人工智能导语:本文会从协同过滤思想简介、协同过滤算法原理介绍、离线协同过滤算法的工程实现、近实时协同过滤算法的工程实现、协同过滤算法应用场景、协同过滤算法的优缺点、协同过滤算法落地需要关注的几个问题等7个方面来讲述。…
sql查询语句优化需要注意的几点
为了获得稳定的执行性能,SQL语句越简单越好。对复杂的SQL语句,要设法对之进行简化。 常见的简化规则如下: 1)不要有超过5个以上的表连接(JOIN) 2)考虑使用临时表或表变量存放中间结果。 3&#…
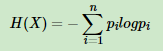
决策树算法原理(ID3,C4.5)
决策树算法原理(CART分类树) CART回归树 决策树的剪枝 决策树可以作为分类算法,也可以作为回归算法,同时特别适合集成学习比如随机森林。 1. 决策树ID3算法的信息论基础 1970年昆兰找到了用信息论中的熵来度量决策树的决策选择过程,昆兰把这…

对称加密算法之RC4介绍及OpenSSL中RC4常用函数使用举例
RC4是一种对称密码算法,它属于对称密码算法中的序列密码(streamcipher,也称为流密码),它是可变密钥长度,面向字节操作的流密码。 RC4是流密码streamcipher中的一种,为序列密码。RC4加密算法是Ron Rivest在1987年设计出的密钥长度…
SpringMVC中实现的token,防表单重复提交
一:首先创建一个token处理类 ,这里的类名叫 TokenHandlerprivate static Logger logger Logger.getLogger(TokenHandler.class);static Map<String, String> springmvc_token new HashMap<String, String>();//生成一个唯一值的tokenSupp…
利用CxImage实现编解码Gif图像代码举例
Gif(Graphics Interchange Format,图形交换格式)是由CompuServe公司在1987年开发的图像文件格式,分为87a和89a两种版本。Gif是基于LZW算法的无损压缩算法。Gif图像是基于颜色表的,最多只支持8位(256色)。Gif减少了图像调色板中的色彩数量&…
SpringBoot b2b2c 多用户商城系统 ssm b2b2c
来源: SpringBoot b2b2c 多用户商城系统 ssm b2b2c用java实施的电子商务平台太少了,使用spring cloud技术构建的b2b2c电子商务平台更少,大型企业分布式互联网电子商务平台,推出PC微信APP云服务的云商平台系统,其中包括…

AI“生死”落地:谁有资格入选AI Top 30+案例?
2019 年,人工智能应用落地的重要性正在逐步得到验证,这是关乎企业生死攸关的一环。科技巨头、AI 独角兽还有起于草莽的创业公司在各领域进行着一场多方角斗。进行平台布局的科技巨头们,正在加快承载企业部署 AI 应用的步伐,曾经无…
liunx 下su 和sudo 的区别
一. 使用 su 命令临时切换用户身份1、su 的适用条件和威力su命令就是切换用户的工具,怎么理解呢?比如我们以普通用户beinan登录的,但要添加用户任务,执行useradd ,beinan用户没有这个权限,而这个权限恰恰由…
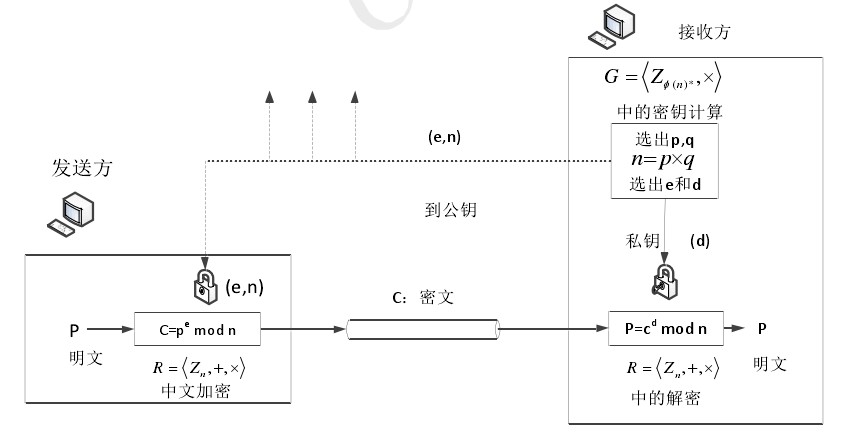
非对称加密算法之RSA介绍及OpenSSL中RSA常用函数使用举例
RSA算法,在1977年由Ron Rivest、Adi Shamirh和LenAdleman,在美国的麻省理工学院开发完成。这个算法的名字,来源于三位开发者的名字。RSA已经成为公钥数据加密标准。 RSA属于公开密钥密码体制。公开密钥体制就是产生两把密钥,一把…

依图科技CEO朱珑:“智能密度”对AI发展意味着什么?
8月9日,由中央网信办、工业和信息化部、公安部联合指导,厦门市政府主办的“中国人工智能峰会”于厦门召开。中国工程院院士、北京大学教授高文,依图科技创始人兼CEO朱珑博士等出席峰会并发表了主题演讲。当前,人工智能正在扮演越来…

Office 2016使用NTKO OFFICE控件提示“文件存取错误”的解决办法
2019独角兽企业重金招聘Python工程师标准>>> 之前使用NTKO,电脑安装的说OFFICE2007,但是前2天电脑固态硬盘坏了 ,重新安装了系统,安装的说win10和office2016,再访问网站使用ntko时,却提示“文件存取错误”&…
如何制作一个类似Tiny Wings的游戏 Cocos2d-x 2.1.4
在第一篇《如何使用CCRenderTexture创建动态纹理》基础上,增加创建动态山丘,原文《How To Create A Game Like Tiny Wings with Cocos2D 2.X Part 1》,在这里继续以Cocos2d-x进行实现。有关源码、资源等在文章下面给出了地址。 步骤如下&…

腾讯优图开源业界首个3D医疗影像大数据预训练模型
整理 | Jane出品 | AI科技大本营(ID:rgznai100)近日,腾讯优图首个医疗AI深度学习预训练模型 MedicalNet 正式对外开源。这也是全球第一个提供多种 3D 医疗影像专用预训练模型的项目,将为全球医疗AI发展提供基础。许多研…
接口冲突的一种解决方法
问题描述:在一个大的项目中往往会包括很多模块,会有不同的部门或公司来负责实现某个模块,也有可能有第三方或客户的参与。假如他们都用到了某个开源软件,底层模块根据自身的需求对这个开源软件进行了修改或裁减。上层也用到了此开…

程序员:请你不要对业务「置之不理」
成长是条孤独的路,一个人会走得更快;有志同道合者同行,会走得更远。本篇内容整理自 21 天鲲鹏新青年计划线上分享内容。鲲鹏新青年计划是由 TGO 鲲鹏会组织的线上分享活动,希望能帮助更多同学一起学习、成长。12 月 28 日…

史上最简单的人脸识别项目登上GitHub趋势榜
来源 | GitHub Trending整理 | Freesia译者 | TommyZihao出品 | AI科技大本营(ID: rgznai100)导读:近日,一个名为 face_recognition 的人脸识别项目登上了 GitHub Trending 趋势榜,赚足了眼球。自开源至截稿࿰…
Centos 64位 Install certificate on apache 即走https协议
2019独角兽企业重金招聘Python工程师标准>>> 一: 先要apache 请求ssl证书的csr 一下是步骤: 重要注意事项 An Important Note Before You Start 在生成CSR文件时同时生成您的私钥,如果您丢了私钥或忘了私钥密码,则颁发 证书给您…
C/C++中“#”和“##”的作用和用法
在C/C的宏中,”#”的功能是将其后面的宏参数进行字符串化操作(Stringfication),简单说就是在对它所引用的宏变量通过替换后在其左右各加上一个双引号。而”##”被称为连接符(concatenator),用来将两个子串Token连接为一个Token。注意这里连接…
国贫县山西永和:“一揽子”保险“保”脱贫
永和是吕梁山特困连片地区的深度贫困县,生产生活条件极差。 范丽芳 摄 永和是吕梁山特困连片地区的深度贫困县,生产生活条件极差。 范丽芳 摄 中新网太原1月16日电 题:国贫县山西永和:“一揽子”保险“保”脱贫 作者范丽芳 李海金…
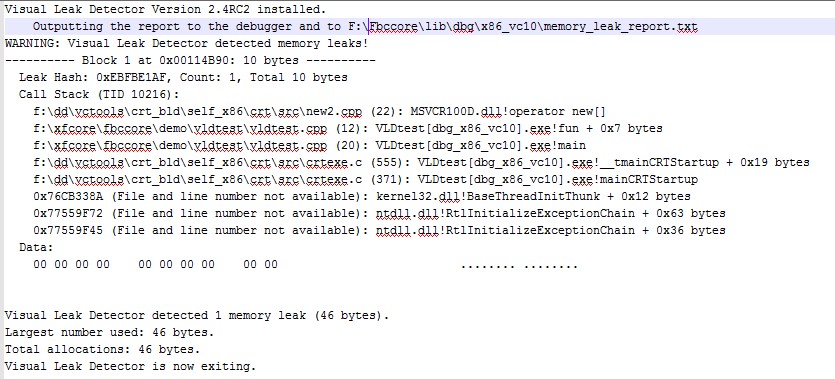
内存泄漏检测工具VLD在VS2010中的使用举例
Visual LeakDetector(VLD)是一款用于Visual C的免费的内存泄露检测工具。它的特点有:(1)、它是免费开源的,采用LGPL协议;(2)、它可以得到内存泄露点的调用堆栈,可以获取到所在文件及行号;(3)、它可以得到泄露内存的完整…
天下武功,唯快不破,论推荐系统的“实时性”
作者 | 王喆转载自知乎王喆的机器学习笔记导读:周星驰著名的电影《功夫》里面有一句著名的台词——“天下武功,无坚不摧,唯快不破”。如果说推荐系统的架构是那把“无坚不摧”的“玄铁重剑”,那么推荐系统的实时性就是“唯快不破”…
新疆兵团开展迎新春“送文化下基层”慰问演出活动
演员表演舞蹈。 戚亚平 摄 演员表演舞蹈。 戚亚平 摄演员表演豫剧《花木兰》选段。 戚亚平 摄为物业公司员工送春联。 戚亚平 摄公安民警收到春联后留影。 戚亚平 摄走进退休职工家中表演节目。 戚亚平 摄为退休职工送春联。 戚亚平 摄 1月16日,2019年迎新春新疆生产…

Python爬取B站5000条视频,揭秘为何千万人为它流泪
作者 | Yura编辑 | 胡巍巍来源 | CSDN(ID:CSDNnews)导语:我们特邀作者Yura爬取B站5000条视频,为你揭秘电影《哪吒》的更多“优秀梗”,看完还能Get新技能,赶快往下滑吧。这个夏天,《哪…
父域与子域之的信任关系
搭了一个测试环境,做一个父、子域间信任关系的测试,过程如下:两台测试服务器,主域为primary.com,子域为child.primary.com客户机Clientpri加入父域,客户机Clientcli加入子域,父域中有一个用户为…
Ubantu安装maven
2019独角兽企业重金招聘Python工程师标准>>> 一、下载maven http://maven.apache.org/download.cgi 二、解压到指定目录 tar -xvf apache-maven-3.6.0-bin.tar.gz 三、添加环境变量 cd /etc vi profile 向其中添加 export M2_HOMEmaven所在目录 export M2$M2_HOME/b…
Leptonica在VS2010中的编译及简单使用举例
在tesseract-ocr中会用到leptonica库,这里对leptonica简单介绍下。Leptonica是一个开源的图像处理和图像分析库,它的license是BSD 2-clause。它主要包括的操作有:位图操作、仿射变换、形态学操作、连通区域填充、图像变换及像素掩模、融合、增…