从原理到落地,七大维度读懂协同过滤推荐算法

作者丨gongyouliu
来源 | 大数据与人工智能
导语:本文会从协同过滤思想简介、协同过滤算法原理介绍、离线协同过滤算法的工程实现、近实时协同过滤算法的工程实现、协同过滤算法应用场景、协同过滤算法的优缺点、协同过滤算法落地需要关注的几个问题等7个方面来讲述。希望读者读完本文,可以很好地理解协同过滤的思路、算法原理、工程实现方案,并且具备基于本文的思路自己独立实现一个在真实业务场景中可用的协同过滤推荐系统的能力。
一、协同过滤思想简介
二、协同过滤算法原理介绍
上面一节简单介绍了协同过滤的思想,基于协同过滤的两种推荐算法,核心思想是很朴素的”物以类聚、人以群分“的思想。所谓物以类聚,就是计算出每个标的物最相似的标的物列表,我们就可以为用户推荐用户喜欢的标的物相似的标的物,这就是基于物品(标的物)的协同过滤。所谓人以群分,就是我们可以将与该用户相似的用户喜欢过的标的物的标的物推荐给该用户(而该用户未曾操作过),这就是基于用户的协同过滤。具体思想可以参考下面的图1。
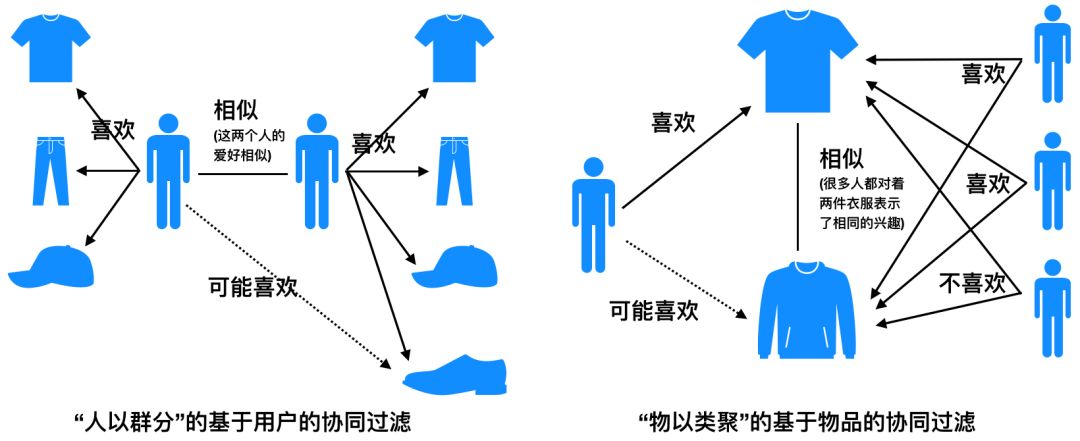
协同过滤的核心是怎么计算标的物之间的相似度以及用户之间的相似度。我们可以采用非常朴素的思想来计算相似度。我们将用户对标的物的评分(或者隐式反馈,如点击、收藏等)构建如下用户行为矩阵(见下面图2),矩阵的某个元素代表某个用户对某个标的物的评分(如果是隐式反馈,值为1),如果某个用户对某个标的物未产生行为,值为0。其中行向量代表某个用户对所有标的物的评分向量,列向量代表所有用户对某个标的物的评分向量。有了行向量和列向量,我们就可以计算用户与用户之间、标的物与标的物之间的相似度了。具体来说,行向量之间的相似度就是用户之间的相似度,列向量之间的相似度就是标的物之间的相似度。为了避免误解,这里简单解释一下隐式反馈,只要不是用户直接评分的操作行为都算隐式反馈,包括浏览、点击、播放、收藏、评论、点赞、转发等等。有很多隐式反馈是可以间接获得评分的,后面会讲解。如果不间接获得评分,就用0、1表示是否操作过。在真实业务场景中用户数和标的物数一般都是很大的(用户数可能是百万、千万、亿级,标的物可能是十万、百万、千万级),而每个用户只会操作过有限个标的物,所以用户行为矩阵是稀疏矩阵。正因为矩阵是稀疏的,会方便我们进行相似度计算及为用户做推荐。
 图2:用户对标的物的操作行为矩阵
图2:用户对标的物的操作行为矩阵相似度的计算可以采用cosine余弦相似度算法来计算两个向量
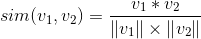
计算完了用户(行向量)或者标的物(列向量)之间的相似度,那么下面说说怎么为用户做个性化推荐。
2.1 基于用户协同过滤
根据上面算法思想的介绍,我们可以将与该用户最相似的用户喜欢的标的物推荐给该用户。这就是基于用户的协同过滤的核心思想。
用户u对标的物s的喜好度sim(u,s)可以采用如下公式计算,其中U是与该用户最相似的用户集合(我们可以基于用户相似度找到与某用户最相似的K个用户),
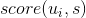 是用户
是用户  是用户
是用户 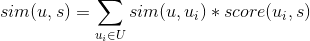 有了用户对每个标的物的评分,基于评分降序排列,就可以取topN推荐给用户了。2.2 基于标的物的协同过滤
有了用户对每个标的物的评分,基于评分降序排列,就可以取topN推荐给用户了。2.2 基于标的物的协同过滤类似地,通过将用户操作过的标的物最相似的标的物推荐给用户,这就是基于标的物的协同过滤的核心思想。用户u对标的物s的喜好度sim(u,s)可以采用如下公式计算,其中S是所有用户操作过的标的物的列表,
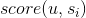 是用户u对标的物
是用户u对标的物 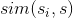 是标的物
是标的物 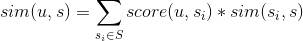 有了用户对每个标的物的评分,基于评分降序排列,就可以取topN推荐给用户了。从上面的介绍中我们可以看到协同过滤算法思路非常直观易懂,计算公式也相对简单,并且后面两节我们也会说明它易于分布式实现,同时该算法也不依赖于用户及标的物的其他metadata信息。协同过滤算法被Netflix、Amazon等大的互联网公司证明效果也非常好,也能够为用户推荐新颖性内容,所以一直以来都在工业界得到非常广泛的应用。
有了用户对每个标的物的评分,基于评分降序排列,就可以取topN推荐给用户了。从上面的介绍中我们可以看到协同过滤算法思路非常直观易懂,计算公式也相对简单,并且后面两节我们也会说明它易于分布式实现,同时该算法也不依赖于用户及标的物的其他metadata信息。协同过滤算法被Netflix、Amazon等大的互联网公司证明效果也非常好,也能够为用户推荐新颖性内容,所以一直以来都在工业界得到非常广泛的应用。三、离线协同过滤算法的工程实现
虽然协同过滤算法原理非常简单,但是在大规模用户及海量标的物的场景下,单机是难以解决计算问题的,我们必须借助分布式技术来实现,让整个算法可以应对大规模数据的挑战。在本节,我们基于主流的Spark分布式计算平台相关的技术来详细讲解协同过滤算法的离线(批处理)实现思路,供大家参考(读者可以阅读参考文献1、2、3、4了解协同过滤算法原理及工业应用),同时会在下一节讲解在近实时场景下怎么在工程上实现协同过滤算法。在这里我们只讲解基于标的物的协同过滤算法的工程实现方案,基于用户的协同过滤思路完全一样,不再赘述。为了简单起见,我们可以将推荐过程拆解为2个阶段,先计算相似度,再为用户推荐。下面分别介绍这两个步骤怎么工程实现。3.1 计算topK相似度
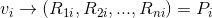
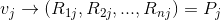 那么
那么 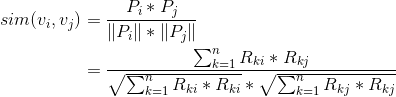 公式1:计算
公式1:计算 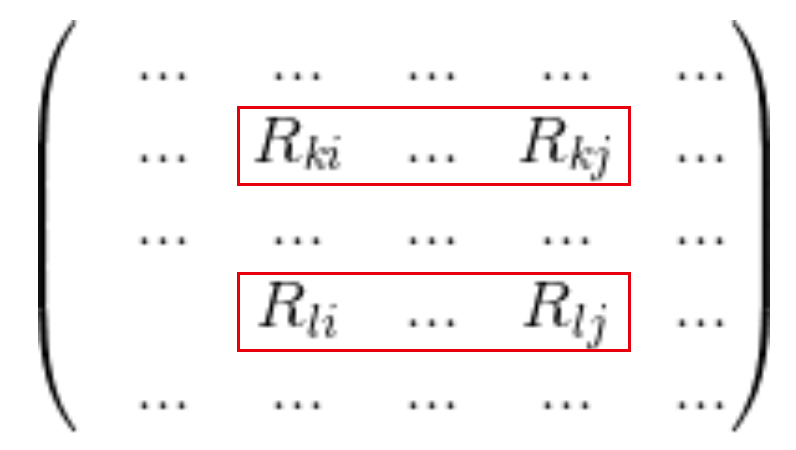 图3:计算两个列向量的cosine余弦可以拆解为简单的加减乘及开根号运算有了上面的简单分析,就容易分布式计算相似度了。下面我们就来讲解,在Spark上怎么简单地计算每个标的物的topK相似度。在Spark上计算相似度,最主要的目标是怎么将上面巨大的计算量(前面已经提到在互联网公司,往往用户数和标的物数都是非常巨大的)通过分布式技术实现,这样就可以利用多台服务器的计算能力,解决大计算问题。首先将所有用户操作过的标的物”收集“起来,形成一个用户行为RDD,具体的数据格式如下:
图3:计算两个列向量的cosine余弦可以拆解为简单的加减乘及开根号运算有了上面的简单分析,就容易分布式计算相似度了。下面我们就来讲解,在Spark上怎么简单地计算每个标的物的topK相似度。在Spark上计算相似度,最主要的目标是怎么将上面巨大的计算量(前面已经提到在互联网公司,往往用户数和标的物数都是非常巨大的)通过分布式技术实现,这样就可以利用多台服务器的计算能力,解决大计算问题。首先将所有用户操作过的标的物”收集“起来,形成一个用户行为RDD,具体的数据格式如下: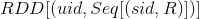 其中uid是用户唯一识别编码,sid是标的物唯一识别编码,R是用户对标的物的评分(即矩阵中的元素)。对于 中的某个用户来说,他操作过的标的物
其中uid是用户唯一识别编码,sid是标的物唯一识别编码,R是用户对标的物的评分(即矩阵中的元素)。对于 中的某个用户来说,他操作过的标的物 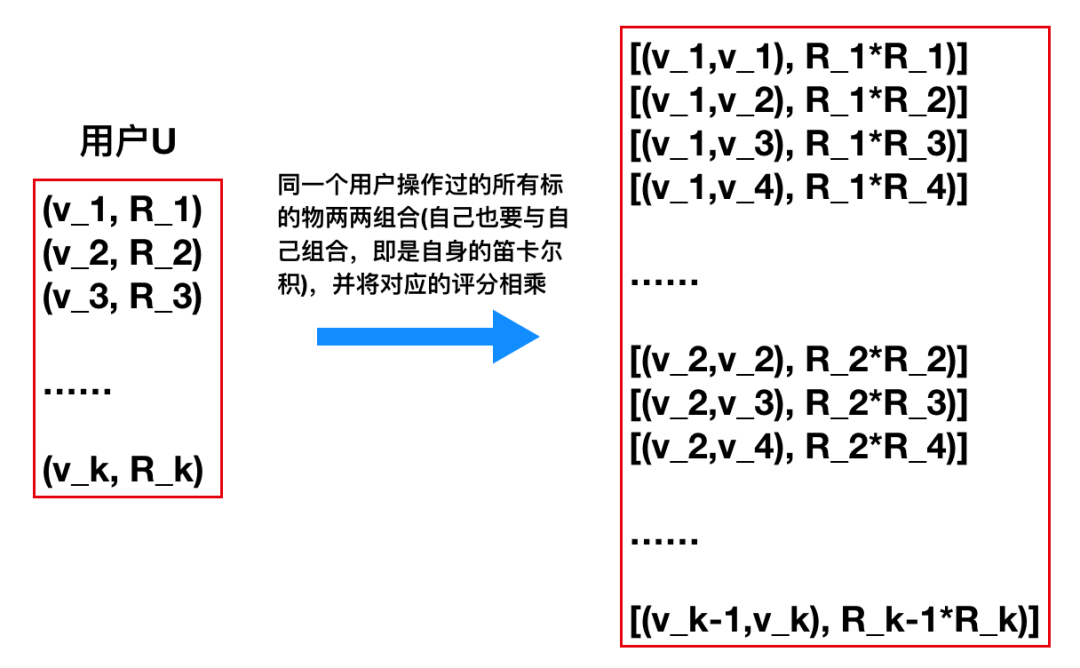 图4:对用户U来说,将他所有操作过的标的物做笛卡尔积当所有用户都按照图4的方式转化为标的物对及得分(图4中右边的
图4:对用户U来说,将他所有操作过的标的物做笛卡尔积当所有用户都按照图4的方式转化为标的物对及得分(图4中右边的  )时,我们就可以对标的物对Group(聚合),将相同的对合并,对应的得分相加,最终得到的RDD为:
)时,我们就可以对标的物对Group(聚合),将相同的对合并,对应的得分相加,最终得到的RDD为: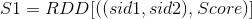 。这样,公式1中分子就计算出来了(上式中的Score即是公式1中的分子)。现在我们需要计算分母,这非常简单,只要从上面的RDD中将标的物sid1等于标的物sid2的列过滤出来就可以了, 通过下图的操作,我们可以得到一个map
。这样,公式1中分子就计算出来了(上式中的Score即是公式1中的分子)。现在我们需要计算分母,这非常简单,只要从上面的RDD中将标的物sid1等于标的物sid2的列过滤出来就可以了, 通过下图的操作,我们可以得到一个map 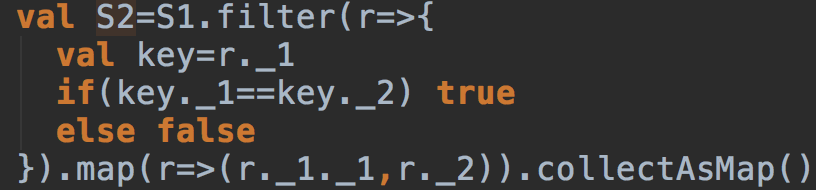 图5:从
图5:从  的元素,用于计算公式1中的分母
的元素,用于计算公式1中的分母 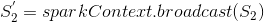 方便我们按照公式1除以分母,最终得到
方便我们按照公式1除以分母,最终得到 通过上面这些步骤,公式1中的分子和分母基本都很容易计算出来了,我们通过下图的代码(下面的broadcast即是
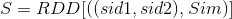 ,其中Sim为sid1和sid2的相似度。
,其中Sim为sid1和sid2的相似度。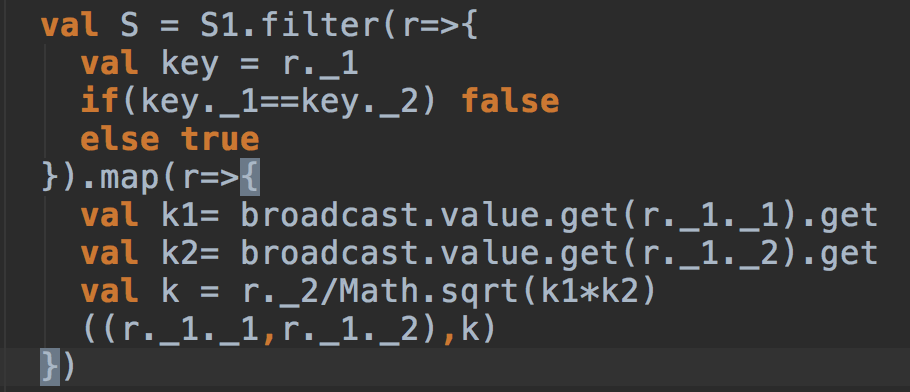 图6:计算每组
图6:计算每组 有了上面的准备,下面我们来说明一下怎么计算每个标的物的topK最相似的标的物。具体的计算过程可以用如下的Spark Transformation来实现。其中第三步的TopK需要我们自己实现一个函数,求
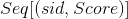 这样的列表中评分最大的TopK个元素,实现也是非常容易的,这里不赘述
这样的列表中评分最大的TopK个元素,实现也是非常容易的,这里不赘述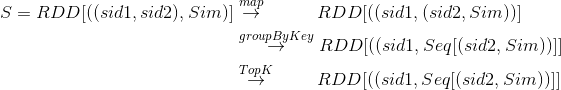 如果我们把每个标的物最相似的K个标的物及相似度看成一个列向量的话,那么我们计算出的标的物相似度其实可以看作如下矩阵,该矩阵每列K个非零元素。
如果我们把每个标的物最相似的K个标的物及相似度看成一个列向量的话,那么我们计算出的标的物相似度其实可以看作如下矩阵,该矩阵每列K个非零元素。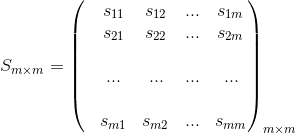 图7:标的物相似度矩阵
图7:标的物相似度矩阵到此为止,我们通过Spark提供的一些Transformation操作及一些工程实现上的技巧计算出了每个标的物topK最相似的标的物。该计算方法可以横向拓展,所以再大的用户数和标的物数都可以轻松应对,最多可能需要多加一些服务器。3.2 为用户生成推荐
有了1中计算出的标的物topK最相似的标的物,下面我们来说明一下怎么为用户生成个性化推荐。生成个性化推荐有两种工程实现策略,一种是看成矩阵的乘积,另外一种是根据第二节2中”基于标的物的协同过滤“中的公式来计算,这两种方法本质上是一样的,只是工程实现上不一样。下面我们分别讲解这两种实现方案。(1)通过矩阵相乘为用户生成推荐
上面图2中的矩阵是用户行为矩阵,第i行第j列的元素代表了用户i对标的物j的偏好/评分,我们将该矩阵记为 ![]() ,其中n是用户数,m是标的物数。图7中的矩阵是标的物之间的相似度矩阵,我们将它记为
,其中n是用户数,m是标的物数。图7中的矩阵是标的物之间的相似度矩阵,我们将它记为 ![]() ,这是一个方阵。
,这是一个方阵。![]() 和
和 ![]() 其实都是稀疏矩阵,我们通过计算这两个矩阵的乘积(Spark上是可以直接计算两个稀疏矩阵的乘积的),最终的结果矩阵就可以方便用来为用户推荐了:
其实都是稀疏矩阵,我们通过计算这两个矩阵的乘积(Spark上是可以直接计算两个稀疏矩阵的乘积的),最终的结果矩阵就可以方便用来为用户推荐了: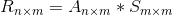 。其中的第i行
。其中的第i行 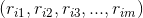 代表的是用户i对每个标的物的偏好得分,我们从这个列表中过滤掉用户操作过的标的物,然后按照得分从高到低降序排列取topN就是最终给用户的推荐。
代表的是用户i对每个标的物的偏好得分,我们从这个列表中过滤掉用户操作过的标的物,然后按照得分从高到低降序排列取topN就是最终给用户的推荐。
(2) 通计算公式为用户生成推荐
标的物相似度矩阵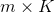 个非零元素(因为每个标的物只保留K个最相似的标的物),一般K取几十或者上百规模的数值,m如果是十万或者百万量级,存储空间在1G左右(例如,如果m=100万,K=100,相似度为双精度浮点数,那么
个非零元素(因为每个标的物只保留K个最相似的标的物),一般K取几十或者上百规模的数值,m如果是十万或者百万量级,存储空间在1G左右(例如,如果m=100万,K=100,相似度为双精度浮点数,那么 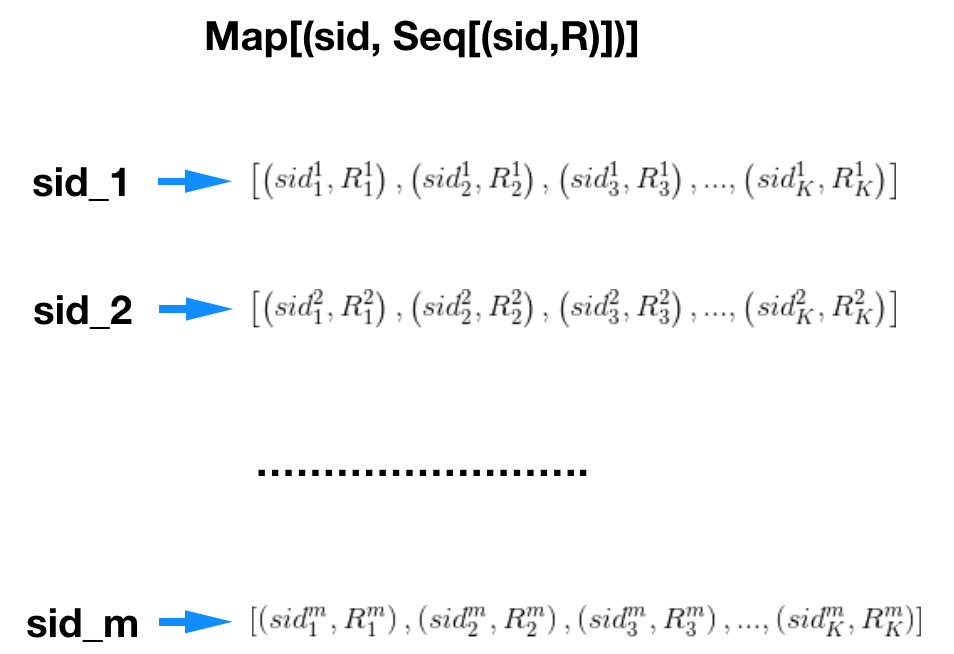 图8:标的物的topK相似列表利用Map数据结构来存储
图8:标的物的topK相似列表利用Map数据结构来存储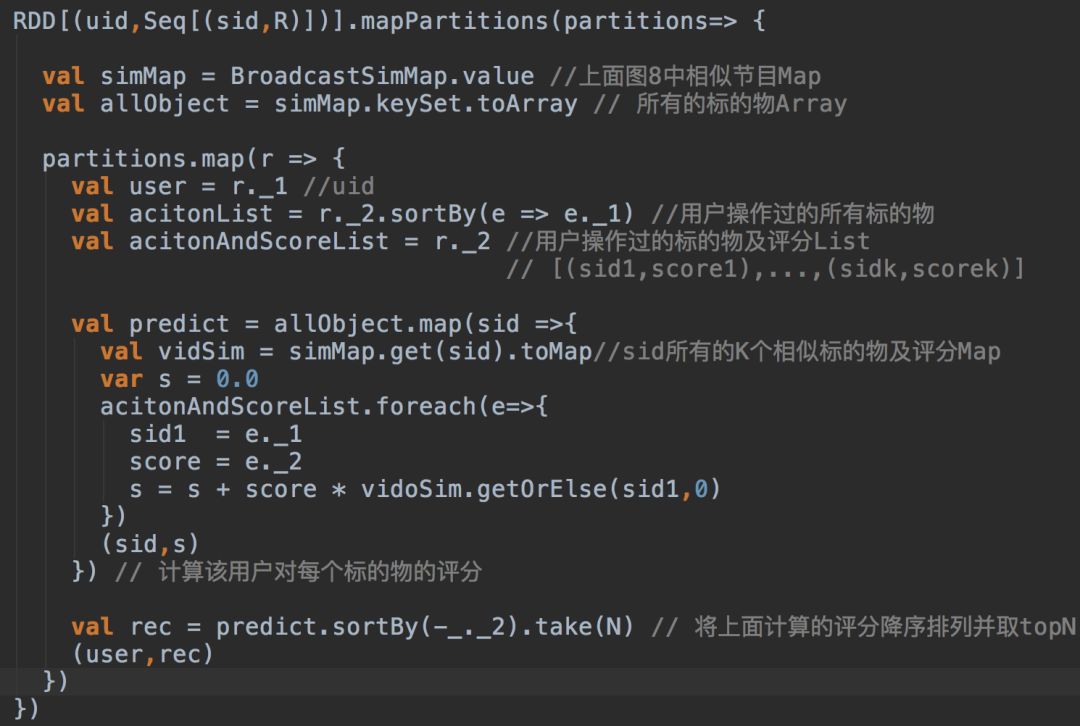 图9:为每个用户计算topN推荐
图9:为每个用户计算topN推荐讲到这里,基于Spark平台离线实现协同过滤算法的工程方案就讲完了。该实现方案强依赖于Spark的数据结构及分布式计算函数,可能在不同的计算平台上(比如Flink、Tensorflow等)具体的实现方式会不一样,但是基本思路和原理是一样的,有兴趣并且平时使用这些平台的读者可以在这些计算平台上独自实现一下,算是对自己的一个挑战。
四、近实时协同过滤算法的工程实现
上面第三节中的协同过滤工程实现方案适合做离线批量计算,比较适合标的物增长较缓慢的场景及产品(比如电商、视频、音乐等),对于新闻、短视频这类增量非常大并且时效性强的产品(如今日头条、快手等)是不太合适的。那么我们是否可以设计出一套适合这类标的物快速增长的产品及场景下的协同过滤算法呢?实际上是可以的,下面我们来简单说一下怎么近实时实现简单的协同过滤算法。我们的近实时协同过滤算法基于Kafka、HBase和Spark Streaming等分布式技术来实现,核心思想跟第三节中的类似,只不过我们这里是实时更新的,具体的算法流程及涉及到的数据结构见下面图10。下面我们对实现原理做简单介绍,整个推荐过程一共分为4步。
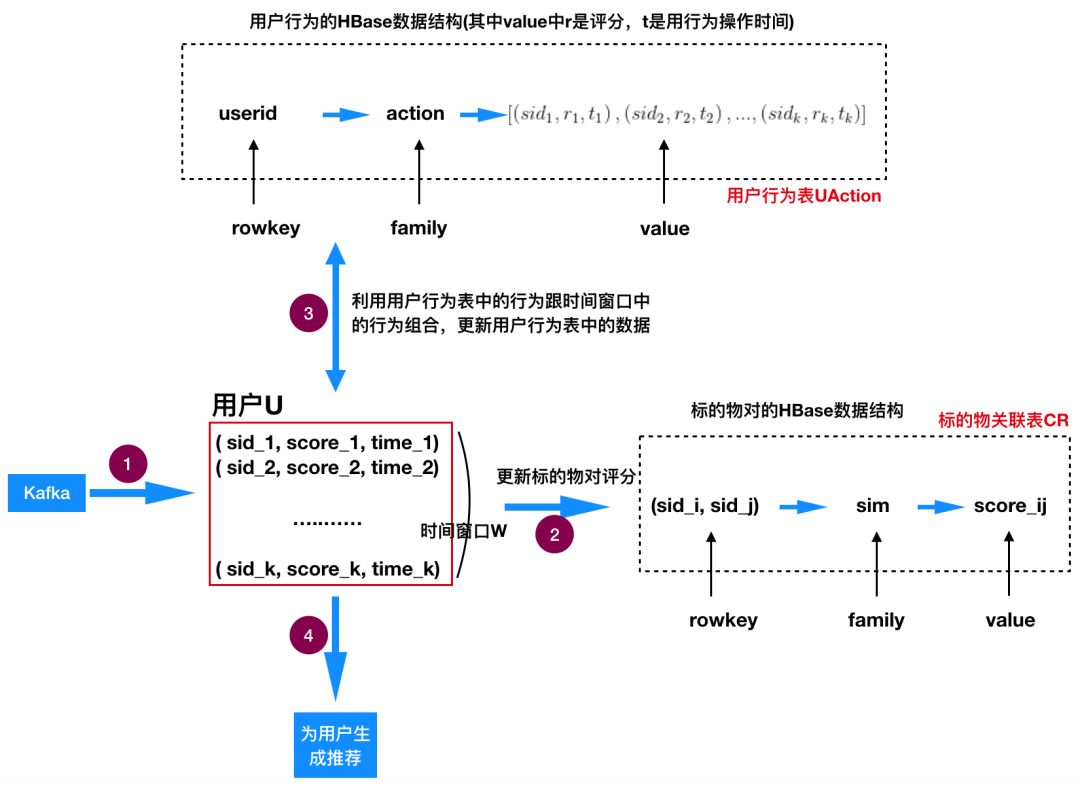 图10:近实时基于标的物的协同过滤算法流程及相关数据结构
图10:近实时基于标的物的协同过滤算法流程及相关数据结构首先Spark Streaming程序从kafka读取一个时间窗口(Window)(一般一个时间窗口几秒钟,时间越短实时性越好,但是对计算能力要求也越高)内的用户行为数据,我们对同一个用户U的行为做聚合,得到上面图中间部分的用户行为列表(用户在该时间窗口中有k次行为记录)。顺便说一下,因为是实时计算,所以用户行为数据会实时传输到Kafka中,供后续的Spark Streaming程序读取。
基于(1)中获取的用户行为记录,在这一步,我们需要更新标的物关联表CR,这里涉及到两类更新。
首先,用户U在时间窗口W内的所有k次行为
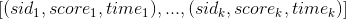 ,我们对标的物两两组合(自身和自身做笛卡尔积)并将得分相乘更新到CR中,比如
,我们对标的物两两组合(自身和自身做笛卡尔积)并将得分相乘更新到CR中,比如 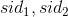 组合,它们的得分
组合,它们的得分 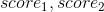 相乘
相乘  更新到CR表中rowkey为
更新到CR表中rowkey为 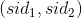 的行中。 的得分score更新为score+ )。其次,对于用户U在时间窗口W中的行为还要与用户行为表UAction中的行为两两组合(做笛卡尔积)采用前面介绍的一样的策略更新到CR表中,这里为了防止组合过多,我们可以只选择时间在一定范围内(比如2天内)的标的物对组合,从而减少计算量。
的行中。 的得分score更新为score+ )。其次,对于用户U在时间窗口W中的行为还要与用户行为表UAction中的行为两两组合(做笛卡尔积)采用前面介绍的一样的策略更新到CR表中,这里为了防止组合过多,我们可以只选择时间在一定范围内(比如2天内)的标的物对组合,从而减少计算量。这里说一下,如果用户操作的某个标的物已经在行为表UAction中(这种情况一般是用户对同一个标的物做了多次操作,昨天看了这短视频,今天刷到了又看了一遍),我们需要将这两次相同的行为合并起来,具体上我们可以将这两次行为中得分高的赋值给行为表中该标的物的得分,同时将操作时间更新为最新操作该标的物的时间。同时将时间窗口W中该操作行为剔除掉,不参上面提到的时间窗口W中的操作行为跟UAction表中同样的操作行为的笛卡尔积计算。4.3 更新用户的行为记录HBase表:UAction基于(1)获取中的用户行为记录,当(2)处理完之后,将行为记录插入用户行为表UAction中。为了计算简单方便及保留用户最近的行为,用户行为表中我们可以只保留最近N条(可以选择的参数,比如20条)行为,同时只保留最近一段时间内(比如5天)的行为。4.4 为用户生成个性化推荐
有了上面(1)、(2)、(3)步的基础,最后一步是为用户做推荐了,我们对计算过程简单说明如下:用户U对标的物的评分
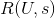 可以采用如下公式计算。
可以采用如下公式计算。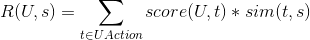
其中t是用户操作过的标的物,
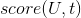 是该用户对标的物t的得分(即图10中UAction数据结构中的评分r),
是该用户对标的物t的得分(即图10中UAction数据结构中的评分r), 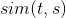 是标的物t和标的物s之间的相似度,可以采用如下公式计算,这里
是标的物t和标的物s之间的相似度,可以采用如下公式计算,这里 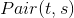 就是标的物关联表CR中(t,s)对应的得分,
就是标的物关联表CR中(t,s)对应的得分, 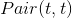 和
和 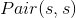 类似。
类似。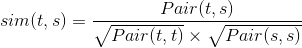
当我们计算完了用户U跟所有标的物的得分之后,通过对得分降序排列取topN就可以作为U的推荐了。当标的物量很大(特别是新闻短视频类产品)时,实时计算还是压力非常大的,这时我们可以采用一个简单的技巧,我们事先从CR表中过滤出跟用户行为表中至少有一个标的物t有交集的标的物s(即标的物对
 ,再从这些标的物中选择得分最大的topN推荐给用户。为什么可以这么做呢?因为如果某个标的物s与用户行为标的物集合无交集,那么根据计算 的公式, 一定为0,这时计算出的 也一定为0。
,再从这些标的物中选择得分最大的topN推荐给用户。为什么可以这么做呢?因为如果某个标的物s与用户行为标的物集合无交集,那么根据计算 的公式, 一定为0,这时计算出的 也一定为0。上面针对一个用户怎么实时计算协同过滤做了讲解,那么在一个时间窗口W中有若干个用户都有操作行为,这时可以将用户均匀分配到不同的Partition中,每个Partition为一批用户计推荐。具体流程可以参考下面图11。为每个用户计算好推荐后,可以插一份到HBase中作为一个副本,另外还可以通过Kafka将推荐结果同步一份到CouchBase集群中,供推荐Web服务为用户提供线上推荐服务。
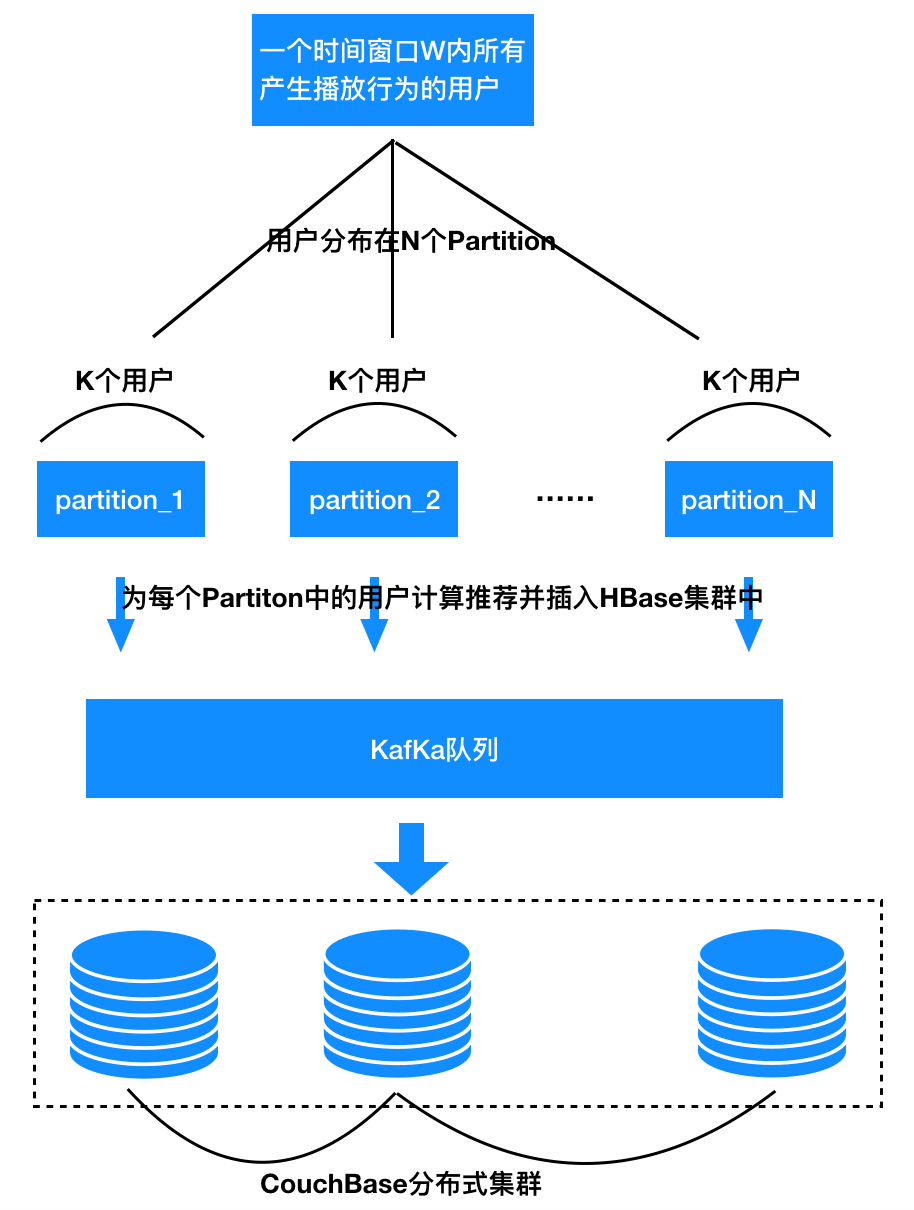 图11:在同一时间窗口W中为多个用户生成个性化推荐
图11:在同一时间窗口W中为多个用户生成个性化推荐五、协同过滤算法的应用场景
协同过滤是非常重要的一类推荐算法,我们在第三、第四节介绍了批处理(离线)协同过滤和近实时协同过滤的工程实现方案,相信大家对怎么基于Spark及HBase技术实现协同过滤有了比较清晰的认知。那么协同过滤算法可以用于哪些推荐业务场景呢?它主要的及延伸的应用场景有如下3类:
5.1 完全个性化推荐(范式)
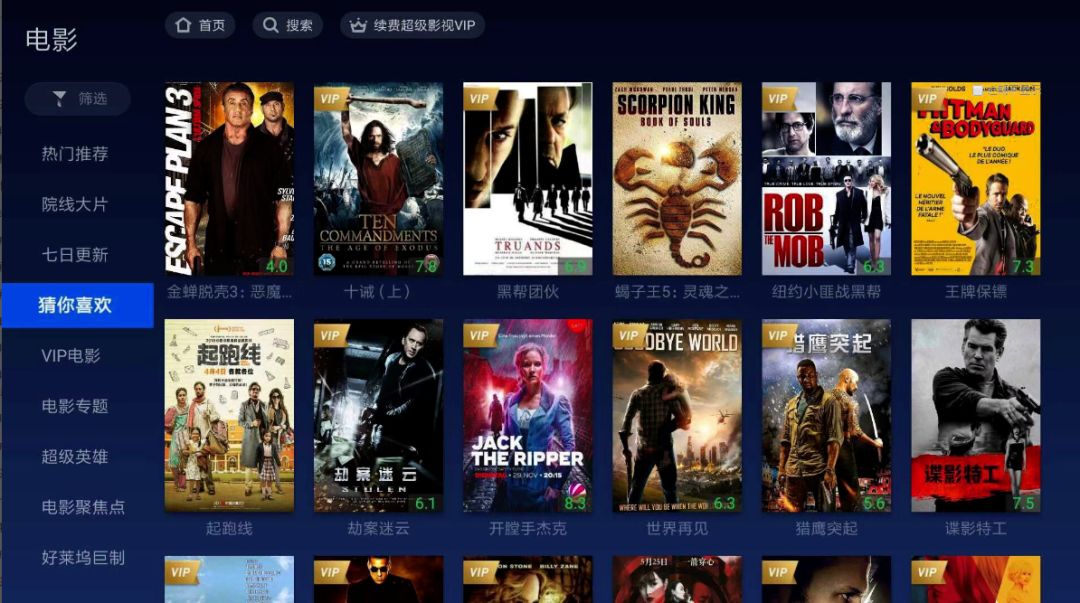 图12:电视猫完全个性化推荐:电影猜你喜欢
图12:电视猫完全个性化推荐:电影猜你喜欢虽然第二节没有直接讲标的物关联标的物的算法,但是讲到了怎么计算两个标的物之间的相似度(即图2中评分矩阵的列向量之间的相似度),我们利用该相似度可以计算某个标的物最相似的K个标的物(在第三节1中我们给出了实现标的物相似性的工程实现,在第四节4中我们也给出了近实时计算标的物相似度的实现方案)。那么这K个最相似的标的物就可以作为该标的物的关联推荐。下图是电视猫相似影片推荐,是一类标的物关联标的物推荐范式,这类推荐可以基于协同过滤算法中间过程中的标的物topN相似度计算来实现。
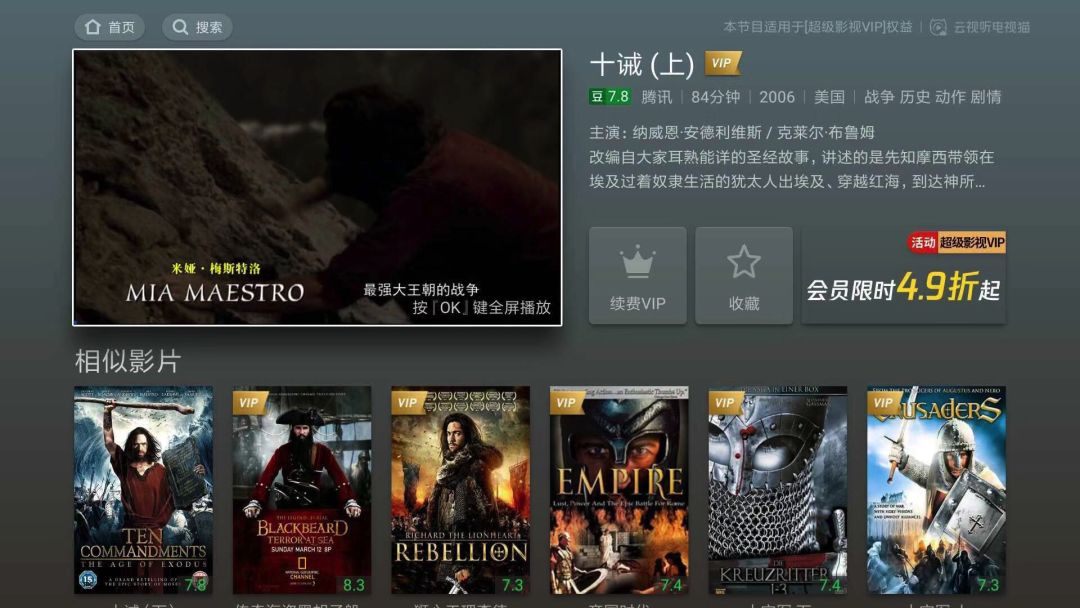 图13:电视猫标的物关联标的物推荐:相似影片5.3其他应用形式及场景在协同过滤算法的讲解中,我们可以将用户或者标的物用向量表示(用户行为矩阵中的行向量和列向量),有了用户和标的物的向量表示,我们就可以对用户和标的物做聚类了。对用户聚类后,当然可以用于做推荐,将同一类中其他用户操作过的标的物推荐给该用户就是一种可行的推荐策略。同时,用户聚类后,也可以用于做lookalike类的商业化(如广告)尝试。对标的物聚类后,也可以用于做标的物关联推荐,将同一类中的其他标的物作为关联推荐结果。另外,标的物聚类后,这些类可以作为专题供编辑或者运营团队来作为一种内容分发的素材。
图13:电视猫标的物关联标的物推荐:相似影片5.3其他应用形式及场景在协同过滤算法的讲解中,我们可以将用户或者标的物用向量表示(用户行为矩阵中的行向量和列向量),有了用户和标的物的向量表示,我们就可以对用户和标的物做聚类了。对用户聚类后,当然可以用于做推荐,将同一类中其他用户操作过的标的物推荐给该用户就是一种可行的推荐策略。同时,用户聚类后,也可以用于做lookalike类的商业化(如广告)尝试。对标的物聚类后,也可以用于做标的物关联推荐,将同一类中的其他标的物作为关联推荐结果。另外,标的物聚类后,这些类可以作为专题供编辑或者运营团队来作为一种内容分发的素材。六、协同过滤算法的优缺点
前面对协同过滤算法做了比较完备的讲解,也提到了协同过滤算法的一些特点,这里我们简单罗列一些协同过滤算法的优缺点,方便大家更进一步深入了解协同过滤算法。优点协同过滤算有很多优点,总结下来最大的优点有如下几个:(1) 算法原理简单、思想朴素从前面的几节讲解中不难看出,协同过滤算法的实现非常简单,只要懂简单的四则混合运算,了解向量和矩阵的基本概念就可以理解算法的原理。估计在整个机器学习领域,没有比这个算法更直观简单的算法了。协同过滤的思想是简单的”物以类聚“、”人以群分“的思想,相信大家都可以理解,正因为思想朴素,所以算法原理简单。(2) 算法易于分布式实现、可以处理海量数据集我们在第三、第四节分别讲解了协同过滤算法的离线和实时工程实现,大家应该很容易看到,协同过滤算法可以非常容易利用Spark分布式平台来实现,因此可以通过增加计算节点很容易处理大规模数据集。(3) 算法整体效果很不错协同过滤算法是得到工业界验证过的一类重要算法,在Netflix、Google、Amazon及国内大型互联网公司都有很好的落地和应用。(4) 能够为用户推荐出多样性、新颖性的标的物前面讲到协同过滤算法是基于群体智慧的一类算法,它利用群体行为来做决策。在实践使用中已经被证明可以很好的为用户推荐多样性、新颖性的标的物。特别是当群体规模越大,用户行为越多,推荐的效果越好。(5) 协同过滤算法只需要用户的行为信息,不依赖用户及标的物的其他信息从前面的算法及工程实践中大家可以知道,协同过滤算法只依赖用户的操作行为,不依赖具体用户相关和标的物相关的信息就可以做推荐,往往用户信息和标的物信息都是比较复杂的半结构化或者非结构化的信息,处理起来很不方便。这是一个极大的优势,正因为这个优势让协同过滤算法在工业界大放异彩。
缺点除了上面介绍的这些优点外,协同过滤算法也存在一些不足的方面,具体来说,在下面这些点,协同过滤算法存在软肋,有提升和优化的空间。(1) 冷启动问题协同过滤算法依赖用户的行为来为用户做推荐,如果用户行为少(比如新上线的产品或者用户规模不大的产品),这时就很难发挥协同过滤算法的优势和价值,甚至根本无法为用户做推荐。这时可以采用基于内容的推荐算法作为补充。另外,对于新入库的标的物,由于只有很少的用户操作行为,这时相当于用户行为矩阵中该标的物对应的列基本都是零,这时无法计算出该标的物的相似标的物,同时,该标的物也不会出现在其他标的物的相似列表中,因此无法将该标的物推荐出去。这时,可以采用人工的策略将该标的物在一定的位置曝光,或者强行以一定的比例或者概率加入推荐列表中,通过收集该标的物的行为解决该标的物无法被推荐出去的问题。在第七节我们会更加详细介绍协同过滤的冷启动解决方案。(2) 稀疏性问题对于现代的互联网产品,用户基数大,标的物数量多(特别是新闻、UGC短视频类产品),一般用户只对很少量的标的物产生操作行为,这是用户操作行为矩阵是非常稀疏的,太稀疏的行为矩阵计算出的标的物相似度往往不够精准,最终影响推荐结果的精准度。协同过滤算法虽然简单,但是在实际业务中,为了让它有较好的效果,最终对业务产生较大的价值,我们在使用该算法时需要注意如下问题。7.1 是采用基于用户的协同过滤还是采用基于标的物的协同过滤
在互联网产品中一般会采用基于标的物的协同过滤,因为对于互联网产品来说,用户相对于标的物变化更大,用户是增长较快的,标的物增长相对较慢(这也不是绝对的,像新闻、短视频类应用标的物也是增速巨大的),利用基于标的物的协同过滤算法效果更稳定。7.2 对时间加权一般来说,用户的兴趣是随着时间变化的,越是久远的行为对用户当前的兴趣贡献越小,基于该思考,我们可以对用户的行为矩阵做时间加权处理。将用户评分加上一个时间惩罚因子,对久远的行为进行一定的惩罚,可行的惩罚方案可以采用指数衰减的方式。例如,我们可以采用如下的公式来对时间做衰减,我们可以选择一个时间作为基准值,比如当前时间,下式中的n是标的物操作时间与基准时间相差的天数(n=0时,w(0)=1)。

7.3 关于用户对标的物的评分
在真实业务场景中,用户不一定对标的物评分,可能只有操作行为。这时可以采用隐式反馈的方式来做协同过滤,虽然隐式反馈的效果可能会差一些。但同时,我们是可以通过一些方法和技巧来间接获得隐式反馈的评分的,主要有如下两类方法,通过这两类方法获得评分,是非常直观的,效果肯定比隐式反馈直接用0或者1好。虽然很多时候用户的反馈是隐式的,但用户的操作行为是多样化的,有浏览、点击、点赞、购买、收藏、分享、评论等等,我们可以基于用户这些隐式行为的投入度(投入的时间成本、资金成本、社交压力等,投入成本越大给定越高的分数)对这些行为人为打分,比如浏览给1分,点赞给2分,转发给4分等等。这样我们就可以针对用户不同的行为生成差异化的评分。对于像音乐、视频、文章等,我们可以记录用户在消费这些标的物上所花的时间来计算评分。拿视频来说,如果一个电影总时长是100分钟,如果用户看了60分钟就退出了,那么我们就可以给用户打6分(10分制,因为用户看了60%,所以打6分)。7.4 相似度计算我们在前面讲解协同过滤算法时需要计算两个向量的相似度,本文前面采用的是cosine余弦相似度。其实,计算两个向量相似度的方式非常多,cosine余弦是被证明在很多场景效果都不错的一个算法,但并不是所有场景cosine余弦都是最好的,需要针对不同场景做尝试和对比。在这里,我们简单罗列一些常用的相似度计算的方法,供大家参考。
(1) cosine余弦相似度前面已经花了很大篇幅讲解了cosine的计算公式,这里不赘述。需要提一点的是,针对隐式反馈(用户只有点击等行为,没有评分),向量的元素要么为1要么为0,直接用cosine余弦公式效果不是很好,参考文献5针对隐式反馈给出了一个更好的计算公式(见下面图14),其中
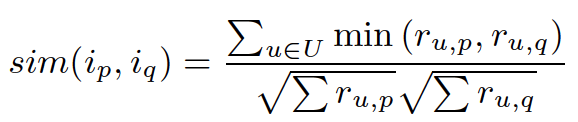 图14:一种优化后的计算隐式反馈相似度的公式,类似cosine余弦公式(2) 皮尔森相关系数(Pearson correlation coefficient)皮尔森相关系数是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关的程度的统计量。具体计算公式如下面图15,其中
图14:一种优化后的计算隐式反馈相似度的公式,类似cosine余弦公式(2) 皮尔森相关系数(Pearson correlation coefficient)皮尔森相关系数是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关的程度的统计量。具体计算公式如下面图15,其中 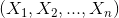 和
和 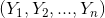 是两个向量,
是两个向量, 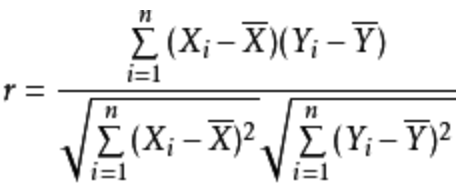 图15:皮尔逊相关系数的计算公式(3) Jaccard coefficientJaccard系数用于计算两个集合之间的相似度,也比较适合隐式反馈类型的用户行为,假设两个标的物
图15:皮尔逊相关系数的计算公式(3) Jaccard coefficientJaccard系数用于计算两个集合之间的相似度,也比较适合隐式反馈类型的用户行为,假设两个标的物 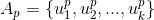 和
和 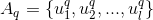 ,那么Jaccard系数的计算公式如下:
,那么Jaccard系数的计算公式如下: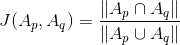 7.5 冷启动问题
7.5 冷启动问题前面在讲协同过滤算法的缺点时讲到协同过滤算法会存在严重的冷启动问题,主要表现在如下3个方面:(1) 用户冷启动
所谓用户冷启动就是新用户没有太多的行为,我们无法为他计算个性化推荐。这时可行的推荐策略是为这类用户推荐热门标的物、通过人工编排筛选出的标的物。或者用户只有很少的行为,协同过滤效果也不好,这时可以采用基于内容的推荐算法补充。
(2)标的物冷启动
所谓标的物冷启动就是新的标的物加入系统,没有用户操作行为,这时协同过滤算法也无法将该标的物推荐给用户。可行的解决方案有三个:
首先,这类标的物可以通过人工曝光到比较好的推荐位(如首页)上,在尽短的时间内获得足够多的用户行为,这样就可以“启动”协同过滤算法了。这里有个比较大的问题是,如果该标的物不是主流的标的物、不够热门的话,放在好的位子不光占用资源同时对用户体验还不好。其次,在推荐算法上做一些策略,可以将这类新的标的物以一定的概率混杂在用户的推荐列表中,让这些标的物有足够多的曝光,在曝光过程中收集用户行为,同时该方法也可以提升用户推荐的多样性。最后,这类标的物也可以通过基于内容的推荐算法来分发出去,作者在《基于内容的推荐算法》中已经讲过内容推荐,这里不再赘述。(3)系统冷启动所谓系统冷启动,就是该产品是一个新开发不久的产品,还在发展用户初期阶段,这时协同过滤算法基本无法起作用,最好采用基于内容的推荐算法或者直接利用编辑编排一些多样性的优质内容作为推荐备选推荐。至此,协同过滤推荐算法基本讲完了,在最后我们做一个简单总结。本文对协同过滤算法原理、工程实践进行了介绍,在工程实践上既讲解了批处理实现方案,同时也讲解了一种近实时实现方案。并且对协同过滤的产品形态及应用场景、优缺点、在落地协同过滤算法中需要注意的问题进行了介绍。希望本文可以帮助读者更深入地了解协同过滤推荐算法。参考文献中的材料从学术上、工业界都对协同过滤算法原理、实践从不同视角及场景进行了论述,具有非常大的参考价值,值得大家阅读学习。
参考文献
1. Item-based collaborative filtering recommendation algorithms
2. item-based top-n recommendation algorithms3. Collaborative filtering for implicit feedback datasets4. Amazon.com reecommendations: Item-to-item collaborative filtering5. TencentRec- Real-time Stream Recommendation in Practice6. Google news personalization:Scalable online collaborative flitering7. Forgetting mechanisms for incremental collaborative filtering8. Scalable collaborative filtering using incremental update and local link prediction9. GroupLens:An Open Architecture for Collaborative Filtering of Netnews(*本文为 AI科技大本营转载文章,转载请微信原作者)
社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五更新技术福利,还有不定期的抽奖活动~

◆
精彩推荐
◆
60+技术大咖与你相约 2019 AI ProCon!大会早鸟票已售罄,优惠票3.5折限时速抢进行中......2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
推荐阅读
连续亏损6年,负债超10亿美元,DeepMind靠烧钱模式能走多远?
七夕大礼包:26个AI学习资源送给你
玩王者荣耀用不好英雄?两阶段算法帮你精准推荐精彩视频
突发!Python再次第一,Java和C下降,凭什么?
白话中台战略:中台是个什么鬼?
伟创力回应扣押华为物资;谷歌更新图片界面;Python 3.8.0b3 发布 | 极客头条
沃尔玛也要发币了,Libra忙活半天为他人做了嫁衣?
知名饮料制造商股价暴涨500%惊动FBI,只因在名字中加入了"区块链" ?
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

sql查询语句优化需要注意的几点
为了获得稳定的执行性能,SQL语句越简单越好。对复杂的SQL语句,要设法对之进行简化。 常见的简化规则如下: 1)不要有超过5个以上的表连接(JOIN) 2)考虑使用临时表或表变量存放中间结果。 3&#…
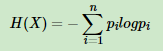
决策树算法原理(ID3,C4.5)
决策树算法原理(CART分类树) CART回归树 决策树的剪枝 决策树可以作为分类算法,也可以作为回归算法,同时特别适合集成学习比如随机森林。 1. 决策树ID3算法的信息论基础 1970年昆兰找到了用信息论中的熵来度量决策树的决策选择过程,昆兰把这…

对称加密算法之RC4介绍及OpenSSL中RC4常用函数使用举例
RC4是一种对称密码算法,它属于对称密码算法中的序列密码(streamcipher,也称为流密码),它是可变密钥长度,面向字节操作的流密码。 RC4是流密码streamcipher中的一种,为序列密码。RC4加密算法是Ron Rivest在1987年设计出的密钥长度…
SpringMVC中实现的token,防表单重复提交
一:首先创建一个token处理类 ,这里的类名叫 TokenHandlerprivate static Logger logger Logger.getLogger(TokenHandler.class);static Map<String, String> springmvc_token new HashMap<String, String>();//生成一个唯一值的tokenSupp…
利用CxImage实现编解码Gif图像代码举例
Gif(Graphics Interchange Format,图形交换格式)是由CompuServe公司在1987年开发的图像文件格式,分为87a和89a两种版本。Gif是基于LZW算法的无损压缩算法。Gif图像是基于颜色表的,最多只支持8位(256色)。Gif减少了图像调色板中的色彩数量&…
SpringBoot b2b2c 多用户商城系统 ssm b2b2c
来源: SpringBoot b2b2c 多用户商城系统 ssm b2b2c用java实施的电子商务平台太少了,使用spring cloud技术构建的b2b2c电子商务平台更少,大型企业分布式互联网电子商务平台,推出PC微信APP云服务的云商平台系统,其中包括…

AI“生死”落地:谁有资格入选AI Top 30+案例?
2019 年,人工智能应用落地的重要性正在逐步得到验证,这是关乎企业生死攸关的一环。科技巨头、AI 独角兽还有起于草莽的创业公司在各领域进行着一场多方角斗。进行平台布局的科技巨头们,正在加快承载企业部署 AI 应用的步伐,曾经无…
liunx 下su 和sudo 的区别
一. 使用 su 命令临时切换用户身份1、su 的适用条件和威力su命令就是切换用户的工具,怎么理解呢?比如我们以普通用户beinan登录的,但要添加用户任务,执行useradd ,beinan用户没有这个权限,而这个权限恰恰由…
非对称加密算法之RSA介绍及OpenSSL中RSA常用函数使用举例
RSA算法,在1977年由Ron Rivest、Adi Shamirh和LenAdleman,在美国的麻省理工学院开发完成。这个算法的名字,来源于三位开发者的名字。RSA已经成为公钥数据加密标准。 RSA属于公开密钥密码体制。公开密钥体制就是产生两把密钥,一把…

依图科技CEO朱珑:“智能密度”对AI发展意味着什么?
8月9日,由中央网信办、工业和信息化部、公安部联合指导,厦门市政府主办的“中国人工智能峰会”于厦门召开。中国工程院院士、北京大学教授高文,依图科技创始人兼CEO朱珑博士等出席峰会并发表了主题演讲。当前,人工智能正在扮演越来…

Office 2016使用NTKO OFFICE控件提示“文件存取错误”的解决办法
2019独角兽企业重金招聘Python工程师标准>>> 之前使用NTKO,电脑安装的说OFFICE2007,但是前2天电脑固态硬盘坏了 ,重新安装了系统,安装的说win10和office2016,再访问网站使用ntko时,却提示“文件存取错误”&…
如何制作一个类似Tiny Wings的游戏 Cocos2d-x 2.1.4
在第一篇《如何使用CCRenderTexture创建动态纹理》基础上,增加创建动态山丘,原文《How To Create A Game Like Tiny Wings with Cocos2D 2.X Part 1》,在这里继续以Cocos2d-x进行实现。有关源码、资源等在文章下面给出了地址。 步骤如下&…

腾讯优图开源业界首个3D医疗影像大数据预训练模型
整理 | Jane出品 | AI科技大本营(ID:rgznai100)近日,腾讯优图首个医疗AI深度学习预训练模型 MedicalNet 正式对外开源。这也是全球第一个提供多种 3D 医疗影像专用预训练模型的项目,将为全球医疗AI发展提供基础。许多研…
接口冲突的一种解决方法
问题描述:在一个大的项目中往往会包括很多模块,会有不同的部门或公司来负责实现某个模块,也有可能有第三方或客户的参与。假如他们都用到了某个开源软件,底层模块根据自身的需求对这个开源软件进行了修改或裁减。上层也用到了此开…

程序员:请你不要对业务「置之不理」
成长是条孤独的路,一个人会走得更快;有志同道合者同行,会走得更远。本篇内容整理自 21 天鲲鹏新青年计划线上分享内容。鲲鹏新青年计划是由 TGO 鲲鹏会组织的线上分享活动,希望能帮助更多同学一起学习、成长。12 月 28 日…

史上最简单的人脸识别项目登上GitHub趋势榜
来源 | GitHub Trending整理 | Freesia译者 | TommyZihao出品 | AI科技大本营(ID: rgznai100)导读:近日,一个名为 face_recognition 的人脸识别项目登上了 GitHub Trending 趋势榜,赚足了眼球。自开源至截稿࿰…
Centos 64位 Install certificate on apache 即走https协议
2019独角兽企业重金招聘Python工程师标准>>> 一: 先要apache 请求ssl证书的csr 一下是步骤: 重要注意事项 An Important Note Before You Start 在生成CSR文件时同时生成您的私钥,如果您丢了私钥或忘了私钥密码,则颁发 证书给您…
C/C++中“#”和“##”的作用和用法
在C/C的宏中,”#”的功能是将其后面的宏参数进行字符串化操作(Stringfication),简单说就是在对它所引用的宏变量通过替换后在其左右各加上一个双引号。而”##”被称为连接符(concatenator),用来将两个子串Token连接为一个Token。注意这里连接…
国贫县山西永和:“一揽子”保险“保”脱贫
永和是吕梁山特困连片地区的深度贫困县,生产生活条件极差。 范丽芳 摄 永和是吕梁山特困连片地区的深度贫困县,生产生活条件极差。 范丽芳 摄 中新网太原1月16日电 题:国贫县山西永和:“一揽子”保险“保”脱贫 作者范丽芳 李海金…
内存泄漏检测工具VLD在VS2010中的使用举例
Visual LeakDetector(VLD)是一款用于Visual C的免费的内存泄露检测工具。它的特点有:(1)、它是免费开源的,采用LGPL协议;(2)、它可以得到内存泄露点的调用堆栈,可以获取到所在文件及行号;(3)、它可以得到泄露内存的完整…
天下武功,唯快不破,论推荐系统的“实时性”
作者 | 王喆转载自知乎王喆的机器学习笔记导读:周星驰著名的电影《功夫》里面有一句著名的台词——“天下武功,无坚不摧,唯快不破”。如果说推荐系统的架构是那把“无坚不摧”的“玄铁重剑”,那么推荐系统的实时性就是“唯快不破”…
新疆兵团开展迎新春“送文化下基层”慰问演出活动
演员表演舞蹈。 戚亚平 摄 演员表演舞蹈。 戚亚平 摄演员表演豫剧《花木兰》选段。 戚亚平 摄为物业公司员工送春联。 戚亚平 摄公安民警收到春联后留影。 戚亚平 摄走进退休职工家中表演节目。 戚亚平 摄为退休职工送春联。 戚亚平 摄 1月16日,2019年迎新春新疆生产…

Python爬取B站5000条视频,揭秘为何千万人为它流泪
作者 | Yura编辑 | 胡巍巍来源 | CSDN(ID:CSDNnews)导语:我们特邀作者Yura爬取B站5000条视频,为你揭秘电影《哪吒》的更多“优秀梗”,看完还能Get新技能,赶快往下滑吧。这个夏天,《哪…
父域与子域之的信任关系
搭了一个测试环境,做一个父、子域间信任关系的测试,过程如下:两台测试服务器,主域为primary.com,子域为child.primary.com客户机Clientpri加入父域,客户机Clientcli加入子域,父域中有一个用户为…
Ubantu安装maven
2019独角兽企业重金招聘Python工程师标准>>> 一、下载maven http://maven.apache.org/download.cgi 二、解压到指定目录 tar -xvf apache-maven-3.6.0-bin.tar.gz 三、添加环境变量 cd /etc vi profile 向其中添加 export M2_HOMEmaven所在目录 export M2$M2_HOME/b…
Leptonica在VS2010中的编译及简单使用举例
在tesseract-ocr中会用到leptonica库,这里对leptonica简单介绍下。Leptonica是一个开源的图像处理和图像分析库,它的license是BSD 2-clause。它主要包括的操作有:位图操作、仿射变换、形态学操作、连通区域填充、图像变换及像素掩模、融合、增…
IJCAI 2019精选论文一览,从底层到应用都有了
作者 | 神经小姐姐来源 | HyperAI超神经(ID: HyperAI)导语:为期一周的 IJCAI 第一天议程已经圆满结束。在前三天的工作坊上,全球各地人工智能行业人士,在此讨论 AI 在各个领域与方向的最新研究成果与未来动向。超神经特…
UITableView 添加长按手势UILongPressGestureRecognizer
2019独角兽企业重金招聘Python工程师标准>>> 给UITableView 添加长按手势,识别长按哪一行。 长按手势类UILongPressGestureRecognizer, 属性minimumPressDuration表示最短长按的时间 添加手势代码: UILongPressGestureRecogniz…
像我这种垃圾学校出来的人...【原话,不是我编的】
今天这标题,是咱们先行者课程的学生的原话,不是我编的,咱有截图为证,我这没别的意思,就是想说一下我自己的想法, 这种情况怎么办呢?也得生活啊,对吧,也不能人人都上清华北…
二维码Data Matrix简介及在VS2010中的编译
Data Matrix 二维条码原名Datacode,由美国国际资料公司(International Data Matrix, 简称ID Matrix)于1989年发明。Data-Matrix二维条码是一种矩阵式二维条码。Data Matrix符号由规则排列的深浅色正方形模块构成,每个正方形模块就是一个基本单元&#x…