五分钟搭建BERT服务,实现1000+QPS,这个Service-Streamer做到了
作者 | 刘欣
深度学习模型在训练和测试时,通常使用小批量(mini-batch)的方式将样本组装在一起,这样能充分利用GPU的并行计算特性,加快运算速度。
但在将使用了深度学习模型的服务部署上线时,由于用户请求通常是离散和单次的,若采取传统的循环服务器或多线程服务器,在短时间内有大量请求时,会造成GPU计算资源闲置,用户等待时间线性变长。
基于此,我们开发了service-streamer,它是一个中间件,将服务请求排队组成一个完整的batch,再送进GPU运算。这样可以牺牲最小的时延(默认最大0.1s),提升整体性能,极大优化GPU利用率。
功能特色
- 简单易用: 只需添加两三行代码即可让模型服务提速上数十倍。
- 处理高速: 高QPS、低延迟,专门针对速度做了优化,见基准测试。
- 扩展性好: 可轻松扩展到多GPU场景,处理大量请求,见分布式。
- 适用性强: 中间件,适用于所有深度学习框架和web框架。
安装步骤
可通过pip安装,要求Python>=3.5:
pip install service_streamer
五分钟搭建BERT服务
为了演示API使用方法,service-streamer提供了一个完整的教程和示例代码。如何在五分钟搭建起基于BERT模型的完形填空服务,每秒处理1000+请求。
GitHub链接:https://github.com/ShannonAI/service-streamer
1、首先我们定义一个完型填空模型(bert_model.py),其predict方法接受批量的句子,并给出每个句子中[MASK]位置的预测结果。
class TextInfillingModel (object);
...
batch=["twinkletwinkle [MASK] star",
"Happy birthday to [MASK]",
'the answer to life, the [MASK], andeverything']
model=TextaInfillingModel()
outputs=model.predict(batch)
print(outputs)
#['little', 'you', 'universe' ]
2、然后使用Flask将模型封装成web服务flask_example.py。这时候你的web服务每秒钟只能完成12句请求。
model=TextInfillingModel()
@app.route("/naive", methods=["POST"])
def naive_predict( ):
inputs =request.form.getlist("s")
outputs =model.predict(inputs)
return jsonify(outputs)
app.run(port=5005)
3、下面我们通过service_streamer封装你的模型函数,三行代码使BERT服务的预测速度达到每秒200+句(16倍QPS)。
from service_streamer import ThreadStreamer
streamer=ThreadedStreamer (model.predict,batch_size=64, max_latency=0.1)
@app.route("/stream", methods=["POST"])
def stream_predict( ):
inputs =request.form.getlist("s")
outputs= streamer.predict(inputs)
returnisonify(outputs)
app.run(port=5005,debug=False)
4、最后,我们利用Streamer封装模型,启动多个GPU worker,充分利用多卡性能实现每秒1000+句(80倍QPS)。
import multiprocessing
from service_streamer import ManagedModel, Streamer
multiprocessing.set_start_method("spawn", force=True)
class ManagedBertModel(ManagedModel):
def init_model(self):
self.model = TextInfillingModel( )
def predict(self, batch):
return self.model.predict(batch)
streamer =Streamer(ManageBertModel, batch_size=64, max_latency=0.1,
worker_num = 8, cuda_devices=(0,1,2,3))
app.run(port=5005,debug=False)
运行flask_multigpu_example.py这样即可启动8个GPUworker,平均分配在4张卡上。
更多指南
除了上面的5分钟教程,service-streamer还提供了:
分布式API使用方法,可以配合gunicorn实现web server和gpuworker的分布式;
异步FutureAPI,在本地高频小batch调用的情形下如何利用service-streamer加速;
性能Benchmark,利用wrk进行单卡和多卡的性能测试数据。
API介绍
快速入门
通常深度学习的inference按batch输入会比较快。
outputs= model.predict(batch_inputs)
用service_streamer中间件封装predict函数,将request排队成一个完整的batch,再送进GPU。牺牲一定的时延(默认最大0.1s),提升整体性能,极大提高GPU利用率。
from service_streamer import ThreadedStreamer
# 用Streamer封装batch_predict函数
streamer= ThreadedStreamer(model.predict, batch_size=64, max_latency=0.1)
# 用Streamer封装batch_predict函数
outputs= streamer.predict(batch_inouts)
然后你的web server需要开启多线程(或协程)即可。
短短几行代码,通常可以实现数十(batch_size/batch_per_request)倍的加速。
分布式GPU worker
上面的例子是在web server进程中,开启子线程作为GPUworker进行 batch predict,用线程间队列进行通信和排队。
实际项目中web server的性能(QPS)远高于GPU模型的性能,所以我们支持一个web server搭配多个GPUworker进程。
import multiprocessing;
multiprocessing.set_start_method("spawn",force=True)
from service_streamer import Streamer
#spawn出4个gpu worker进程
streamer= Streamer(model.predict, 64, 0.1,worker_num=4)
outputs= streamer.redict(batch)
Streamer默认采用spawn子进程运行gpuworker,利用进程间队列进行通信和排队,将大量的请求分配到多个worker中处理,再将模型batch predict的结果传回到对应的web server,并且返回到对应的http response。
上面这种方式定义简单,但是主进程初始化模型,多占了一份显存,并且模型只能运行在同一块GPU上,所以我们提供了ManageModel类,方便模型lazy初始化和迁移,以支持多GPU。 from service_streamer import ManagedModel class ManagedBertModel(ManagedModel): def init_model(self): self.model = Model( ) def predict(self, batch): return self.model.predict(batch) # spawn出4个gpu worker进程,平均分数在0/1/2/3号GPU上
streamer=Streamer(ManagedBertModel, 64, 0.1,worker_num=4,cuda_devices=(0,1,2,3))outputs = streamer.predict(batch) 分布式web server 有时候,你的web server中需要进行一些CPU密集型计算,比如图像、文本预处理,再分配到GPU worker进入模型。CPU资源往往会成为性能瓶颈,于是我们也提供了多web server搭配(单个或多个)GPU worker的模式。 使用跟任意RedisStreamer指定所有web server 和GPU worke的模式。 # 默认参数可以省略,使用localhost:6379streamer = RedisStreamer(redis_broker="172.22.22.22:6379") 然后跟任意python web server的部署一样,用gunicorn或uwsgi实现反向代理和负载均衡。 cd examplegunicorn -c redis_streamer_gunicorn.py flask_example:app 这样每个请求会负载均衡到每个web server中进行CPU预处理,然后均匀的分布到GPU worke中进行模型predict。 Future API 如果你使用过任意concurrent库,应该对future不陌生。当你的使用场景不是web service,又想使用service_streamer进行排队或者分布式GPU计算,可以直接使用Future API。 from service_streamer import ThreadedStreamerstreamer = ThreadedStreamer(model.predict, 64, 0.1) xs ={}for i in range(200): future =streamer.submit(["Happy birthday to [MASK]", "Today is my lucky [MASK]"]) xs.append(future) # 先拿到所有future对象,再等待异步返回for future in xs: outputs = future.result() print(outputs) 基准测试如何做基准测试 我们使用wrk来使做基准测试。 环境
GPU : Titan Xp
cuda : 9.0
python : 1.1
#benchmark stream api with service_streamer./wrk -t 4 -c 128 -d 20s --timeout=10s -s scripts/streamer.luahttp://127.0.0.1:5005/naive
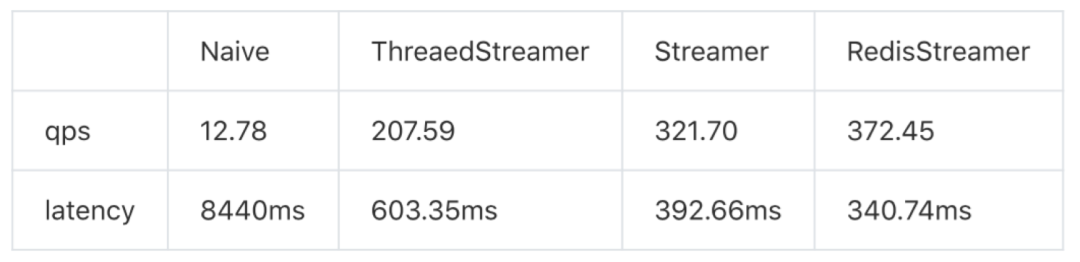
多个GPU进程 这里对比单web server进程的情况下,多GPU worker的性能,验证通过和负载均衡机制的性能损耗。Flask多线程server已经成为性能瓶颈,故采用gevent server。
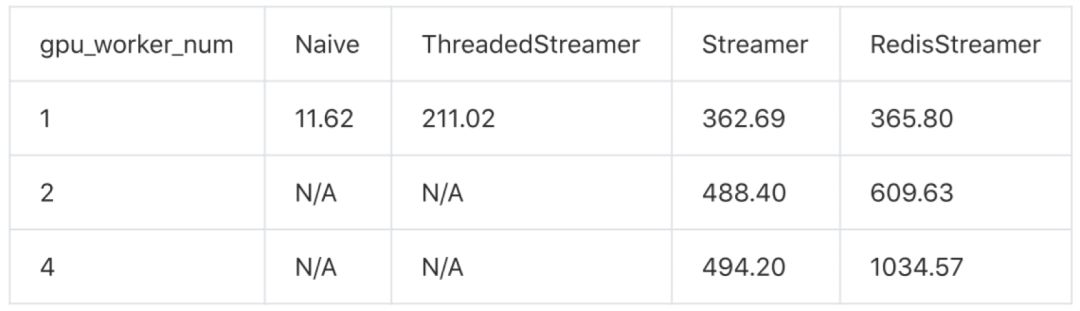 利用Future API使用多个GPU 为了规避web server的性能瓶颈,我们使用底层Future API本地测试多GPU worker的benchmark。 可以看出service_streamer的性能跟GPUworker数量及乎成线性关系,其中进程间通信的效率略高于redis通信。
利用Future API使用多个GPU 为了规避web server的性能瓶颈,我们使用底层Future API本地测试多GPU worker的benchmark。 可以看出service_streamer的性能跟GPUworker数量及乎成线性关系,其中进程间通信的效率略高于redis通信。(*本文为 AI科技大本营转载文章,转载请联系原作者)
社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五更新技术福利,还有不定期的抽奖活动~

◆
精彩推荐
◆

60+技术大咖与你相约 2019 AI ProCon!大会早鸟票已售罄,优惠票速抢进行中......2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
推荐阅读
通俗易懂:图解10大CNN网络架构
BERT的成功是否依赖于虚假相关的统计线索
AI+DevOps正当时
5天破10亿的哪吒,为啥这么火,Python来分析
5G+AI重新定义生老病死
如何从零开始设计一颗芯片?
在其他国家被揭穿骗子又盯上非洲? 这几个骗子公司可把非洲人民坑苦了…
国内首款 5G 机型开售;Google Chrome 大部分插件无人用;Firefox 69 Beta 9 发布
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

Nagios+pnp4nagios+rrdtool 安装配置为nagios添加自定义插件(三)
nagios博大精深,可以以shell、perl等语句为nagios写插件,来满足自己监控的需要。本文写mysql中tps、qps的插件,并把收集到的结果以图形形式展现出来,这样输出的结果就有一定的要求了。 编写插件tps qps check_qps 插件如下内容 #…
OpenSSL简介及在Windows、Linux、Mac系统上的编译步骤
OpenSSL介绍:OpenSSL是一个强大的安全套接字层密码库,囊括主要的密码算法、常用的密钥和证书封装管理功能及SSL协议,并提供丰富的应用程序供测试或其它目的使用。 SSL是SecureSockets Layer(安全套接层协议)的缩写,可以在Interne…

Guava Cache本地缓存在 Spring Boot应用中的实践
概述 在如今高并发的互联网应用中,缓存的地位举足轻重,对提升程序性能帮助不小。而 3.x开始的 Spring也引入了对 Cache的支持,那对于如今发展得如火如荼的 Spring Boot来说自然也是支持缓存特性的。当然 Spring Boot默认使用的是 SimpleCache…

Windows 8.1 Preview(Windows Blue)预览版简体中文官方下载(ISO完整版镜像)
Windows 8.1是微软继Windows 8以来的又一全新力作,又名Windows Blue(视窗蓝,专注蓝屏30年),个人觉得Win8还是比较流畅的但大众始终觉得还是有很多需要改进或者改善的,如今微软为了迎合大众需求对Win8进行升…

Linux下编辑器vi/vim的使用介绍
vi编辑器是所有Unix及Linux系统下标准的编辑器。对Unix及Linux系统的任何版本,vi编辑器是完全相同的。 基本上vi可以分为三种状态,分别是命令模式(commandmode)、插入模式(insert mode)和底行模式(last line mode),各模式的功能为࿱…

Clojure程序设计
《Clojure程序设计》基本信息作者: (美)Stuart Halloway Aaron Bedra [作译者介绍]出版社:人民邮电出版社ISBN:9787115308474上架时间:2013-3-1出版日期:2013 年3月开本:16开页码:230版次&#…

重磅!AI Top 30+案例评选正式启动
2019 年,人工智能应用落地的重要性正在逐步得到验证,这是关乎企业生死攸关的一环。科技巨头、AI 独角兽还有起于草莽的创业公司在各领域进行着一场多方角斗。进行平台布局的科技巨头们,正在加快承载企业部署 AI 应用的步伐,曾经无…

直播回顾 | 关于Apollo 5.0控制在环仿真技术的分享
Apollo 用于模型验证和测试的基于 Web 的仿真平台 Dreamland 已经更新到能使用更强大的场景编辑器和环控制模拟。基于 Apollo 流水线和机器学习的动力学模型,复杂度较高,同时基于 AI 的全景数据建模,模型精细度高,误差比传统方式可…
eclipes 安装 pytdev,svn,插件
1, python pydevhttp://pydev.org/updates2, svnhttp://subclipse.tigris.org/update3, 推荐http://subclipse.tigris.org/update_1.10.x 转载于:https://blog.51cto.com/swq499809608/1240873
FFmpeg简介及在vc2010下编译步骤
FFmpeg是一个开源的多媒体库,最新版本是2.4.3,它的License是LGPL或GPL。FFmpeg可以用来记录、转换数字音频、视频,并能将其转换为流的开源计算机程序。它包括了音/视频编码库libavcodec。FFmpeg是在Linux下开发出来的,但它可以在包…
医院六级电子病历建设思路及要点
产生背景 在医院电子病历信息化发展的过程中,先后经历了纸质病历、电子病历、结构化电子病历以及具有全医疗过程管理能力的电子病历四个阶段。临床业务需求质量的逐步提升,标准规范的逐步细化,互联网战略的落地实施,无疑对目前电子…

上手必备!不可错过的TensorFlow、PyTorch和Keras样例资源
作者 | 黄海广来源 | 机器学习初学者(ID: ai-start-com)TensorFlow、Keras和PyTorch是目前深度学习的主要框架,也是入门深度学习必须掌握的三大框架,但是官方文档相对内容较多,初学者往往无从下手。本人从github里搜到…
Linux下gdb调试工具的使用
gdb是GNU开源组织发布的一个强大的Linux下的程序调试工具。 gdb主要完成四个方面的功能:(1)、启动你的程序,可以按照你的自定义的要求随心所欲的运行程序;(2)、可让被调试的程序在你所指定的调试的断点处停住(断点可以是条件表达式)…
UESTC 1726 整数划分(母函数)
题目链接:http://222.197.181.5/problem.php?pid1726 题意:求n的划分数。一种划分方案中不能有相同的数字。 思路:(1x)(1x^2)(1x^3)……(1x^1000). int f[N];void init() {f[1]1;int a[N]{0};a[0]1; a[1]1;int i,j;for(i2;i<1000;i){for(…
JS nodeType返回类型
JS nodeType返回类型 前几天朋友正好问道 这个 js的nodeType是个什么概念(做浏览器底层的)正好遇到这篇文章可以向大家解释下 将HTML DOM中几个容易常用的属性做下记录: nodeName、nodeValue 以及 nodeType 包含有关于节点的信息。 nodeName …
C# 获取指定目录下所有文件信息、移动目录、拷贝目录
/// <summary>/// 返回指定目录下的所有文件信息/// </summary>/// <param name"strDirectory"></param>/// <returns></returns>public List<FileInfo> GetAllFilesInDirectory(string strDirectory){List<FileInfo&g…
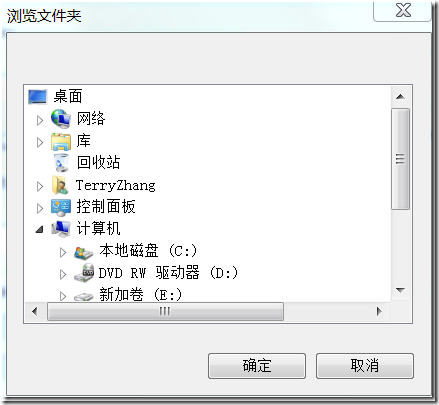
文件夹浏览(SHBrowseForFolder)
from http://www.cnblogs.com/Clingingboy/archive/2011/04/16/2018284.html 一.首先要为SHBrowseForFolder准备一个结构体BROWSEINFO typedef struct _browseinfoW {HWND hwndOwner;PCIDLIST_ABSOLUTE pidlRoot;LPWSTR pszDisplayName; // Return display…
技术新贵:RPA与NLP技术的结合与应用
什么是 RPA(Robotic Process Automation)?机器人流程自动化(RPA)是一种自动化工具,用于创建软件机器人的虚拟劳动力,从而优化和降低企业中端到端业务流程的成本。RPA 可以翻译成机器人流程自动化…
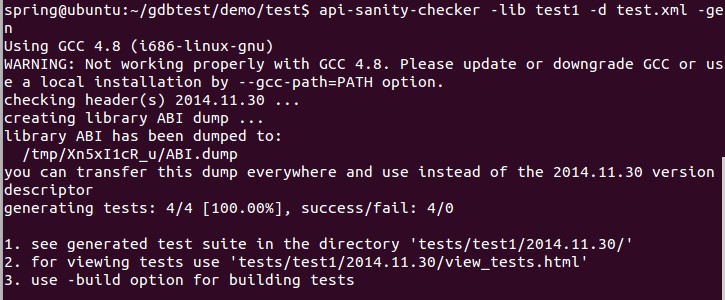
API Sanity Checker在Ubuntu中的使用
API Sanity Checker是一个自动生成单元测试用例的工具,可用于链接测试。它可用于三大桌面平台,下面简单介绍它在Linux下的使用步骤:1. 从http://ispras.linuxbase.org/index.php/API_Sanity_Autotest 下载最新的api-sanity-checker-1.98…

手动脱壳—dump与重建输入表(转)
文章中用到的demo下载地址: http://download.csdn.net/detail/ccnyou/4540254 附件中包含demo以及文章word原稿 用到工具: Ollydbg LordPE ImportREC 这些工具请自行下载准备 Dump原理这里也不多做描述,想要了解google it!常见的dump软件有Lo…
如何用RNN生成莎士比亚风格的句子?(文末赠书)
作者 | 李理,环信人工智能研发中心vp,十多年自然语言处理和人工智能研发经验。主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。来源 | 《深度学习理论与实战:基础篇》基本概…
图像相似度计算之哈希值方法OpenCV实现
感知哈希算法(perceptual hash algorithm),它的作用是对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。结果越接近,就说明图像越相似。 实现步骤: 1. 缩小尺寸:将图像缩小到8*8的尺寸&am…
七夕大礼包:26个AI学习资源送给你!
整理 | Jane出品 | AI科技大本营(ID:rgznai100)免费的在线学习课程一直是大多数人学习 AI 知识和技能的方式之一。今天,基于 Github 上一位小姐姐 Chip Huyen 分享的 10 门机器学习课程,AI科技大本营将这份收藏大礼包进…

HTML Inspector – 帮助你编写高质量的 HTML 代码
HTML Inspector 是一款代码质量检测工具,帮助你编写更优秀的 HTML 代码。HTML Inspector 使用 JavaScript 编写,运行在浏览器中,是最好的 HTML 代码检测工具。 您可能感兴趣的相关文章Metronic – 赞!Bootstrap 响应式后台管理模板…
Git简介以及与SVN的区别
Git是由著名Linux内核(Kernel)开发者Linus Torvalds为了便利维护Linux而开发的。 Git是一个分布式的版本控制系统。作为一个分布式的版本控制系统,在Git中并不存在主库这样的概念,每一份复制出的库都可以独立使用,任何两个库之间的不一致之处…
java集合中某一个元素出现的次数
int count Collections.frequency(list, key); java的内置方法转载于:https://www.cnblogs.com/wysAC666/p/10252676.html

加密解密-DES算法和RSA算法
昨天忽然对加密解密有了兴趣,今天上班查找了一些资料,现在就整理一下吧:) 一.DES算法 这种算法如图所示,这里将描述它的每一个步骤。这个算法进行了16次迭代(圈),把各块明文交织起来…
开始Dojo之路
开始Dojo之路waiting……转载于:https://blog.51cto.com/frabbit2013/1242108
图像相似度计算之直方图方法OpenCV实现
操作步骤: 1. 载入图像(灰度图或者彩色图),并使其大小一致; 2. 若为彩色图,增进行颜色空间变换,从RGB转换到HSV,若为灰度图则无需变换; 3. 若为灰度图,直接计算其直方…

黄皓之后,计算机科学上帝Don Knuth仅用一页纸证明布尔函数敏感度猜想
作者 | Freesia编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100)导读:近日,美国艾默里大学计算机与数学科学系教授黄皓(Hao Huang)用一篇短短 6 页的论文证明了布尔函数,引发了计算机和数学领域社…