新智元推荐
来源:LinkedIn
作者:Abhishek Thakur
译者:弗格森
【新智元导读】本文是数据科学家Abhishek Thakur发表的Kaggle热门文章。作者总结了自己参加100多场机器学习竞赛的经验,主要从模型框架方面阐述了机器学习过程中可能会遇到的难题,并给出了自己的解决方案,他还列出了自己平时研究所使用的数据库、算法、机器学习框架等等,具有一定的参考价值。作者称:“文章几乎涵盖了机器学习所面临的所有问题。”他说得怎么样?欢迎留言评论,发表你的看法。

本文在Linkedin上贴出后,被迅速转到Kaggle和Hacker News,并引起火热讨论。在Hacker News上,有人认为,作者只是从一名数据科学家的角度对机器学习展开研究,其方法有一定局限性。另外,如果如果真的要使用作者提出的机器学习框架,需要有超大量的数据才可以。
以下是新智元编译的全文:
Abhishek Thakur:数据科学家每天都要处理数据载入问题。有一些研究者称,自己有60%--70%的时间都花在了数据清洗、处理(筛选)和转换上,从而让机器学习模型能使用这些数据。本文关注的是第二部分,也就是数据在机器学习模型的应用上,其中包括预处理的步骤。
本文讨论的几个pipelines是我所参加的上百个计算机比赛后的总结。需要强调的是,文章的相关讨论虽然是概括性的,却也是十分有用的,同时,文中所讨论的也涉及一些既有的、被专业人士采用的复杂方法。
声明:我们使用Python。
数据
在采用机器学习模型前, 数据必须要转化成一个列表(Tabular)的形式。这是最消耗时间,也是最困难的,其过程如下:
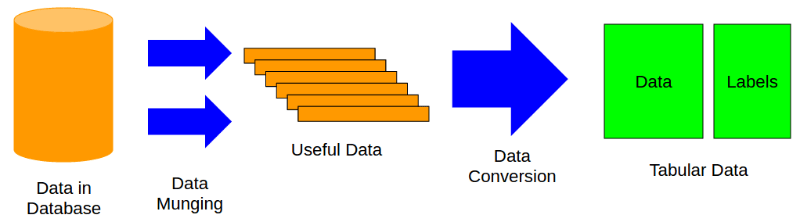
随后,机器学习模型被用于训练列表数据。列表数据是机器学习和数据挖掘中表征数据最常见的呈现方式。我们先是有了一个数据表,然后对不同的样本数据进行排列, 或者用X和Y打上标签。这些标签可以是单行的,或者多行的,取决于要解决的问题的类型。在这,我们将用X来对数据进行表示,用Y来作标签。
标签的类型
这些标签定义了所要解决的问题,可以有不同的形式:
单行,二进制值(分类问题,一个样本只属于一个种类,且种类总数只有2个)
单行,真值(回归问题,预测唯一值)
多行,二进制值(分类问题,一个样本属于一个分类,但是有2个或者多个种类)
多行,真值(回归问题,预测多值)
多个标签(分类问题,一个样本可以属于不同的种类)
评估价值
对于任何机器学习难题,我们必须知道要怎样评估自己的研究结果,或者说,评估的价值和对象是什么。为了防止二进制分类中的负偏(skewed)的问题,我们通常会选择在运行特征曲线(ROC AUC 或者简单的 AUC)的接收器(receiver)下方区域进行评估。
在多标签和多类型分类难题中,我们通常选择分类交互熵,或者多类型的 log loss ,以及在回归问题中降低平方误差。
资料库
观看和进行数据处理:Pandas
各种机器学习模型:Scikit-learn
最好的梯度渐进数据库看:xgboots
神经网络:keras
绘图数据:matplotlib
监控进度:tqdm
我不用Anaconda,它虽然简便好用,但是我想要更多的自由。
机器学习框架
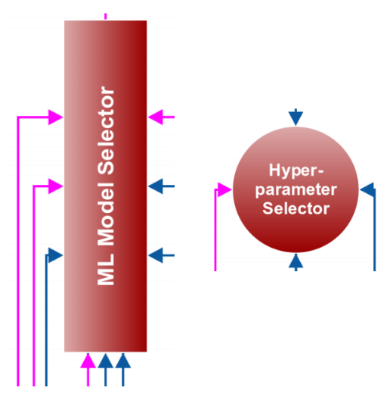
2015年,我构思了一个自动机器学习的框架,现在仍然在开发中,但会很快发布。以下是基本框架:
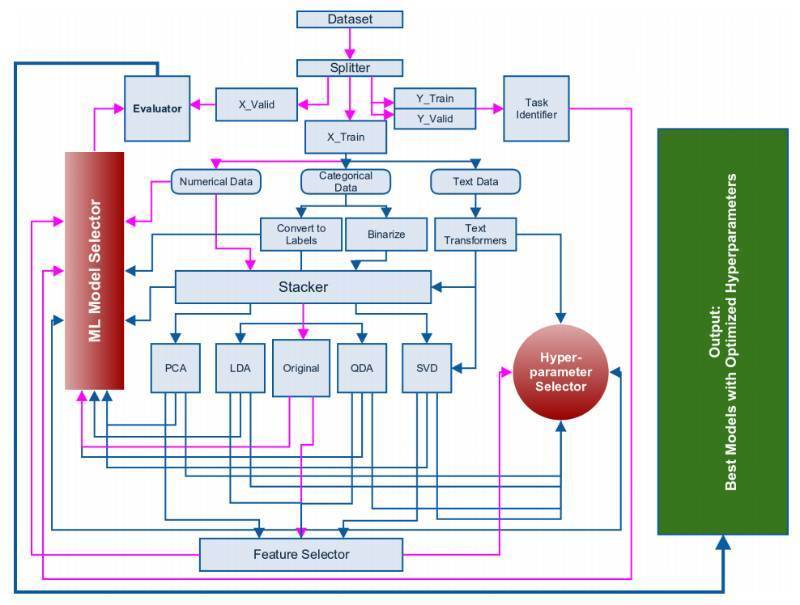
在上图所展示的框架中,粉线代表最常采用的路线。在我们将数据提取或精简到列表式之后,我们就可以继续下一步,建立机器学习模型。
最初始的一步是,定义问题。这可以通过标签确定。研究者首先要明确,你的问题是二进制的、多种类的、多标签分类的还是回归问题。在定义了问题之后,我们可以把数据分为两个不同的部分,如下文描述,一部分是训练数据,另一部分是检验数据。
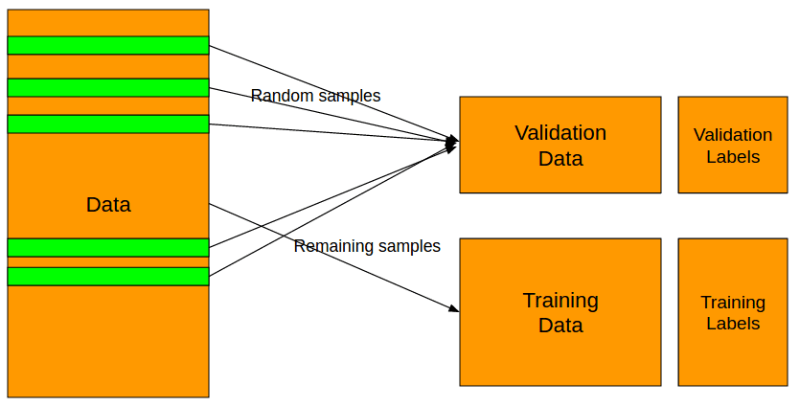
把数据进行“训练”和“检验”的区分,必须要根据数据标签进行。在所有的分类问题中,都要试用分层分割。在Python中,你可以使用Scikit-learn来轻易地做到。

在回归任务中,一个简单的K-Fold分割应该就足够了。但是,有一些复杂的方法,倾向于保持训练数据和检验数据中标签的一致性。

在上面的例子中,我选择 eval_size 或者 size of the validation set作为全部数据的10%,但是,你可以根据自己拥有的数据选择赋值。
在数据分层完成后,先把它们搁在一旁不要碰。在训练数据集上的任何操作都要保存,最后会运用到检验数据集中。而检验数据集,在任何情况下都不应该跟训练数据集混淆。如果能做到这样,就会得到非常好的分数。否则,你可能建立的是一个没多大用,且过度拟合的模型。
下一步就是在数据中确定不同的变量。一般,我们处理的变量有3种:一个是数据变量、种类变量和内含文本的变量。
以下是以流行的Titanic 数据库举的例子:
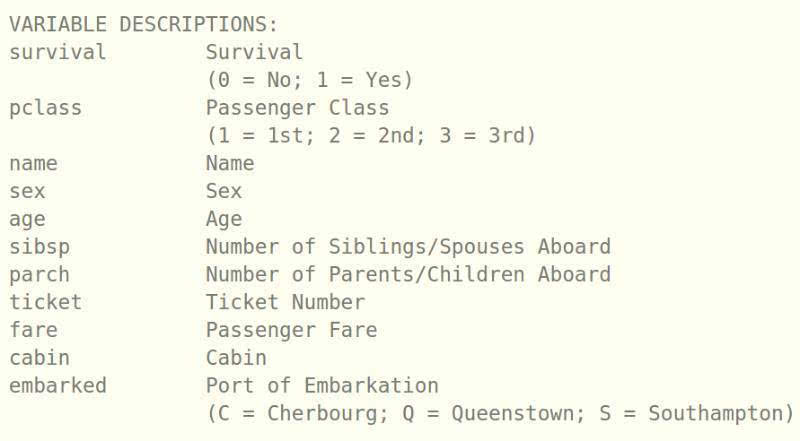
在这儿,标签就是Survival。此前,我们已经从训练数据中对标签进行了区隔。然后,我们有 pclass, sex, embarked。这些变量有着不同的层次,所以它们是种类变量。其他变量,比如,age、sibsp、parch等则属于数字变量。姓名现在也是变量,但根据之前的研究,我并不认为这是一个可用于预测survival的变量。
首先把数据变量排除。这些变量并不需要任何的处理,我们可以使用标准的机器学习模型来处理。
在种类变量的处理上,我们有两个方式:
把种类数据变成标签
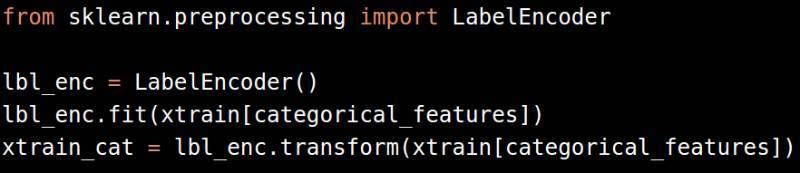
把标签转化成二进制变量(one-hot 编码)
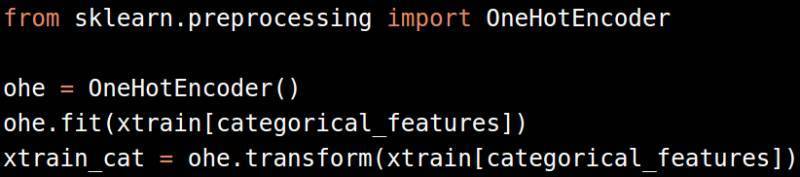
在应用 one-hot 编码前,记得先用LabelEncoder把种类转化为数据。
由于Titanic数据并没有一个很好的文本变量样本,让我们构建一个通用的规则,来处理文本变量。我们可以把所有的文本变量变为一个,然后用一些算法,来把这些文本转换成数字。
文本变量的融合如下:

随后我们可以使用CountVectorizer 或TfidfVectorizer :

或者:

TfidfVectorizer的表现一直都比其他工具要好,据我观察,以下的参数几乎每次都有效:
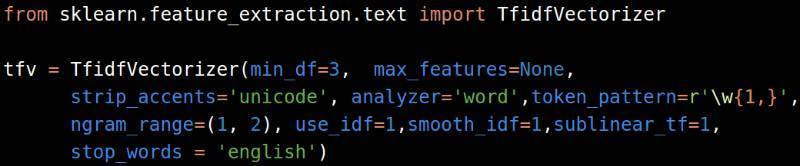
如果你只是在训练数据集上使用这些向量,请确保你已经把它们存到硬盘中,这样以后你在检验数据集中也可以使用。

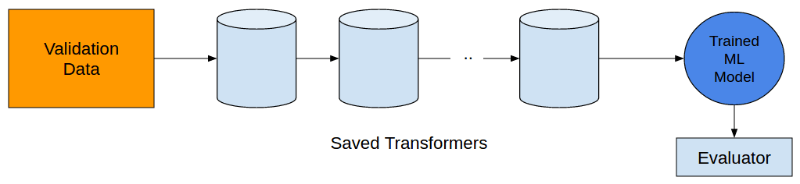
下一步,我们就来到了叠式储存器(stacker) 模块。Stacker并不是一个模型stacker,而是一个特征stacker。在上文提到的处理步骤完成后,不同的特征可以被结合起来,用到Stacker模块中。
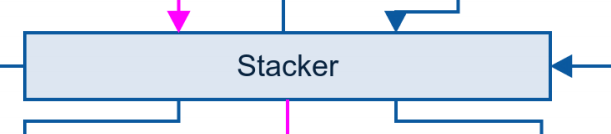
在进行下一步的处理之前,你可以使用numpyhstack或者sparse hstack把所有的特征水平堆叠起来,这取决你拥有的是稀疏或者紧密特征。
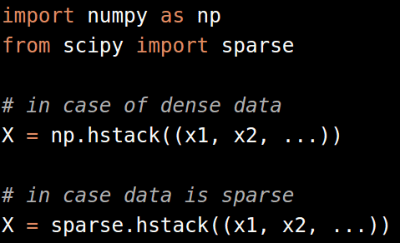
这也可以通过FeatureUnion模块来实现,防止要求其他的处理步骤,比如 pca 或者特征选择。
一旦我们把所有的特征都堆叠到一起,我们就能开始把它们应用到机器学习模型上。在这一阶段,你唯一可用的模型应该是基于ensemble tree 的。这些模型包括:
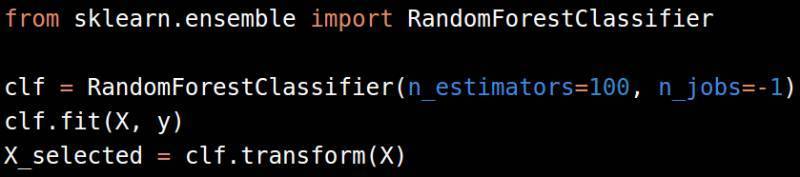
RandomForestClassifier
RandomForestRegressor
ExtraTreesClassifier
ExtraTreesRegressor
XGBClassifier
XGBRegressor
由于还没有被标准化,我们在上面的特征中不能使用线性模型。要使用线性模型,你可以从scikit-learn上使用Normalizer或StandardScaler。这些规范化的方法只有在紧密特征中才起作用,在稀疏特征中不会有好的效果。
如果以上的步骤得出了一个“好”的模型,我们就能对超参数进行优化。为了防止模型不好,我们可以通过以下几步进行优化:
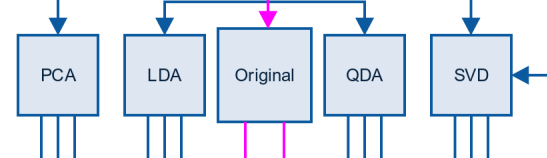
出于简化的目的,我将忽略LDA和QDA的转化。对于高维数据,通常PCA会被用于分解。对于其他类型的数据,我们选择了50-60个组件。
对于文本数据,在把文本转换为稀疏矩阵后,使用 Singular Value Decomposition (SVD)。在scikit-learn中可以找到一个 TruncatedSVD。

一般情况下,对TF-IDF 有用的SVD组件为120-200个。超过这一数字可能会提高性能,但是并不能持续,并且计算能力的成本会增加。
在评估了模型的性能后,我们再去扩展数据库,这样我们就能评估线性模型。标准化和可扩展的特征能被输入机器学习模型或者特征选择模块。
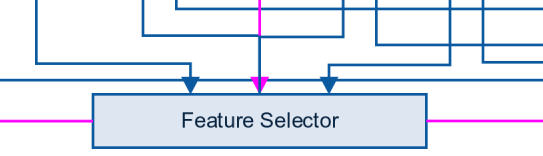
特征的选择,有多种方式可以实现。最常见的是贪婪特征的选择(正向或反向)。在贪婪特征的选择上,我们选择一个特征,训练一个模型并用一个修正的评估值来评估模型的性能。我们不断增加或者移除一个又一个特征,并逐步记录模型的表现。随后,我们选出得分最高的特征。必须说明的是,这种方法并不是完美的,需要根据要求改变或修正。
其他更快的特征选择方法包括:从一个模型中选择最佳的特征。我们可以观察一个逻辑模型的稀疏,或者训练一个随机森林,来选择最佳的特征,然后在其他的机器学习模型上使用。
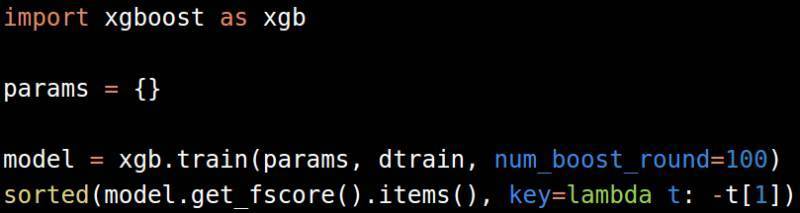
记得保持较少数量的Estimator,并对超参数进行最小优化,这样你就不会过度拟合。
特征的选择也可以通过Gradient Boosting Machines来实现。如果我们使用xgboost而不是在 scikit-learn中使用GBM时,效果会很好。因为xgboost速度更快、可扩展性更高。
我们也可以使用RandomForestClassifier 、RandomForestRegressor 和xgboost,在稀疏数据集中进行特征选择。
另一个较为流行的方法是基于chi-2的特征选择。
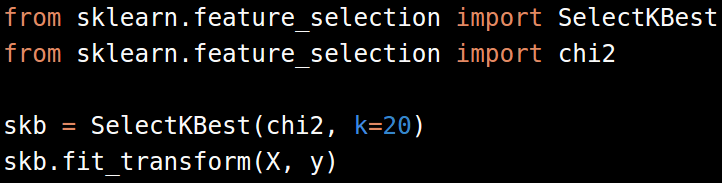
在这儿,我们使用Chi2和 SelectKBes从数据中选择20个特征。这也变成了我们希望优化,来提升机器学习模型结果的超参数。
在这一过程中,千万不要忘记保存你任何一步的转换,在检验数据集中,你会用得到。
下一个主要的步骤是模型的选择,和超参数优化。
主要使用以下算法:
分类:
· Random Forest
· GBM
· Logistic Regression
· Naive Bayes
· Support Vector Machines
· k-Nearest Neighbors
回归:
· Random Forest
· GBM
· Linear Regression
· Ridge
· Lasso
· SVR
我该优化哪些参数?我怎样才能选到最匹配的参数?这是人们考虑得最多的两个问题。没有在大量的数据库上体验过不同的模型和参数,是无法回答这一问题的。还有一点,许多人并不愿意分享这方面的经验。所幸我还有一点经验,也愿意分享:
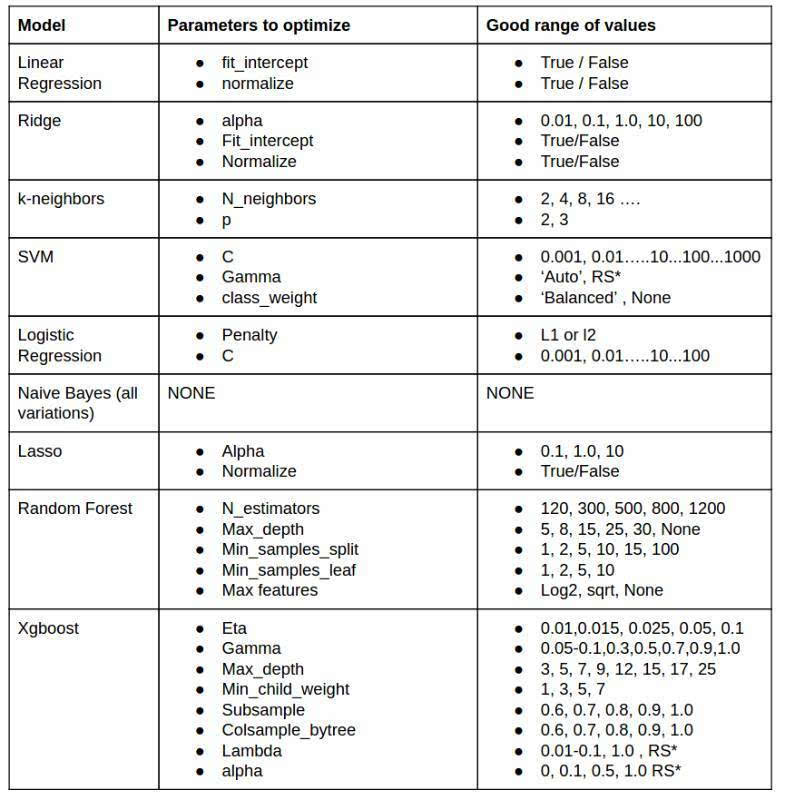
RS*指不能确定合适的值
在我看来,以上的模型在性能上已经是最优,我们不需要再评估其他模型。再次提醒,记得保存。
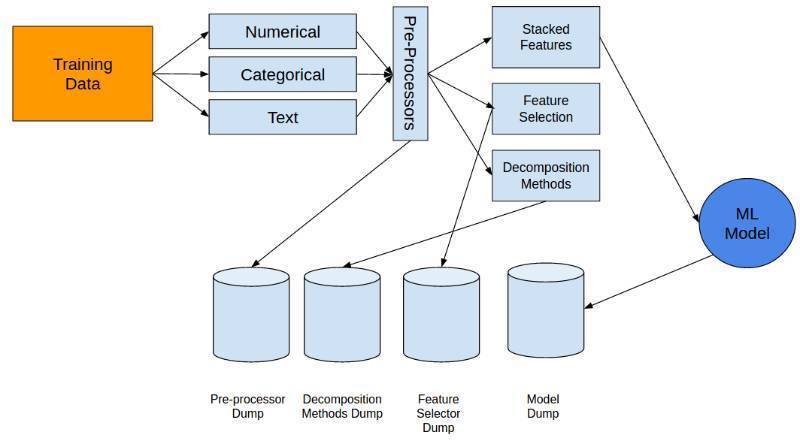
在检验数据集中进行验证。