XML解析简介及Xerces-C++简单使用举例
XML是由World WideWeb联盟(W3C)定义的元语言。它已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便。XML在不同的语言里解析方式都是一样的,只不过实现的语法不同而已。
XML本身只是以纯文本对数据进行编码的一种格式,要想利用XML,或者说利用XML文件中所编码的数据,必须先将数据从纯文本中解析出来,因此,必须有一个能够识别XML文档中信息的解析器,用来解释XML文档并提取其中的数据。然而,根据数据提取的不同需求,又存在着多种解析方式,不同的解析方式有着各自的优缺点和适用环境。选择合适的XML解析技术能够有效提升应用系统的整体性能。
所有的XML处理都从解析开始,无论是使用XSLT或Java语言,第一步都是要读入XML文件,解码结构和检索信息等等,这就是解析,即把代表XML文档的一个无结构的字符序列转换为满足XML语法的结构化组件的过程。
XML基本的的解析方式主要有两种:SAX(Simple API for XML)和DOM(Document ObjectModel)。
SAX是基于事件流的解析。SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档,它可以在某个条件得到满足时停止解析。一般来说,SAX还比它的替代者DOM快很多。SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。SAX对内存的要求通常会比较低,因为它让开发人员来决定所要处理的tag。特别是当开发人员只需要处理文档中所包含的部分数据时,SAX这种扩展能力得到了更好的体现。但用SAX解析器的时候编码工作会比较困难,而且很难同时访问同一个文档中的多处不同数据。优点:(1)、不需要等待所有数据都被处理,分析就能立即开始;(2)、只在读取数据时检查数据,不需要保存在内存中;(3)、可以在某个条件得到满足时停止解析,不必解析整个文档;(4)、效率和性能较高,能解析大于系统内存的文档。缺点:(1)、需要应用程序自己负责TAG的处理逻辑(例如维护父/子关系等),文档越复杂程序就越复杂;(2)、单向导航,无法定位文档层次,很难同时访问同一文档的不同部分数据,不支持XPath。
DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准。DOM是以层次结构组织的节点或信息片段的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。优点:(1)、允许应用程序对数据和结构做出更改;(2)、访问是双向的,可以在任何时候在树中上下导航,获取和操作任意部分的数据。缺点:通常需要加载整个XML文档来构造层次结构,消耗资源大。
基于C/C++语言的XML解析库包括:
(1)、Expat:http://www.libexpat.org/ ;
(2)、die-xml:https://code.google.com/p/die-xml/;
(3)、Xerces-C++:http://xerces.apache.org/xerces-c/index.html;
(4)、TinyXml:http://www.grinninglizard.com/tinyxml/;
Xerces-C++的编译和使用:
1、 从http://xerces.apache.org/xerces-c/download.cgi#verify下载 xerces-c-3.1.1.zip 源代码,并解压缩;
2、 用vs2010打开xerces-c-3.1.1\projects\Win32\VC10\xerces-all目录下的xerces-all.sln;
3、 分别选择SolutionConfigurations、Solution Platforms中相关项,然后选中Solution ‘xerces-all’,-->单击右键,选择执行Rebuild Solution,会在/Build/Win32/VC10目录下生成相应的动态库和静态库,这里选择Static Debug/xerces-c_static_3D.lib和Static Release/xerces-c_static_3.lib进行测试;
4、在’xerces-all’工作空间的基础上新建一个TestXerces工程,选中此工程,分别在Debug和Release下,工程属性(1)、Configuration Properties -->Character Set:Use Unicode Character Set; (2)、C/C++-->General-->Additional Include Directories: ../../../../../src ,C/C++ -->Prerocessor中加入:_CRT_SECURE_NO_DEPRECATE
_WINDOWS
XERCES_STATIC_LIBRARY
XERCES_BUILDING_LIBRARY
XERCES_USE_TRANSCODER_WINDOWS
XERCES_USE_MSGLOADER_INMEMORY
XERCES_USE_NETACCESSOR_WINSOCK
XERCES_USE_FILEMGR_WINDOWS
XERCES_USE_MUTEXMGR_WINDOWS
XERCES_PATH_DELIMITER_BACKSLASH
HAVE_STRICMP
HAVE_STRNICMP
HAVE_LIMITS_H
HAVE_SYS_TIMEB_H
HAVE_FTIME
HAVE_WCSUPR
HAVE_WCSLWR
HAVE_WCSICMP
HAVE_WCSNICMPstdafx.h:
#pragma once#include "targetver.h"#include <stdio.h>#include "xercesc/util/PlatformUtils.hpp"
#include "xercesc/util/XMLString.hpp"
#include "xercesc/dom/DOM.hpp"
#include "xercesc/util/OutOfMemoryException.hpp"
#include "xercesc/util/TransService.hpp"
#include "xercesc/parsers/SAXParser.hpp"
#include "xercesc/sax/HandlerBase.hpp"
#include "xercesc/framework/XMLFormatter.hpp"stdafx.cpp:
#include "stdafx.h"// TODO: reference any additional headers you need in STDAFX.H
// and not in this file
#ifdef _DEBUG#pragma comment(lib, "../../../../../Build/Win32/VC10/Static Debug/xerces-c_static_3D.lib")
#else#pragma comment(lib, "../../../../../Build/Win32/VC10/Static Release/xerces-c_static_3.lib")
#endifTestXerces.cpp:
#include "stdafx.h"
#include <iostream>using namespace std;XERCES_CPP_NAMESPACE_USEclass XStr
{
public :// -----------------------------------------------------------------------// Constructors and Destructor// -----------------------------------------------------------------------XStr(const char* const toTranscode){// Call the private transcoding methodfUnicodeForm = XMLString::transcode(toTranscode);}~XStr(){XMLString::release(&fUnicodeForm);}// -----------------------------------------------------------------------// Getter methods// -----------------------------------------------------------------------const XMLCh* unicodeForm() const{return fUnicodeForm;}private :// -----------------------------------------------------------------------// Private data members//// fUnicodeForm// This is the Unicode XMLCh format of the string.// -----------------------------------------------------------------------XMLCh* fUnicodeForm;
};#define X(str) XStr(str).unicodeForm()/*
* This sample illustrates how you can create a DOM tree in memory.
* It then prints the count of elements in the tree.
*/
int CreateDOMDocument()
{// Initialize the XML4C2 system.try {XMLPlatformUtils::Initialize();} catch(const XMLException& toCatch) {char *pMsg = XMLString::transcode(toCatch.getMessage());XERCES_STD_QUALIFIER cerr << "Error during Xerces-c Initialization.\n"<< " Exception message:"<< pMsg;XMLString::release(&pMsg);return 1;}// Watch for special case help requestint errorCode = 0;/*{XERCES_STD_QUALIFIER cout << "\nUsage:\n"" CreateDOMDocument\n\n""This program creates a new DOM document from scratch in memory.\n""It then prints the count of elements in the tree.\n"<< XERCES_STD_QUALIFIER endl;errorCode = 1;}*/if(errorCode) {XMLPlatformUtils::Terminate();return errorCode;}{// Nest entire test in an inner block.// The tree we create below is the same that the XercesDOMParser would// have created, except that no whitespace text nodes would be created.// <company>// <product>Xerces-C</product>// <category idea='great'>XML Parsing Tools</category>// <developedBy>Apache Software Foundation</developedBy>// </company>DOMImplementation* impl = DOMImplementationRegistry::getDOMImplementation(X("Core"));if (impl != NULL) {try {DOMDocument* doc = impl->createDocument(0, // root element namespace URI.X("company"), // root element name0); // document type object (DTD).DOMElement* rootElem = doc->getDocumentElement();DOMElement* prodElem = doc->createElement(X("product"));rootElem->appendChild(prodElem);DOMText* prodDataVal = doc->createTextNode(X("Xerces-C"));prodElem->appendChild(prodDataVal);DOMElement* catElem = doc->createElement(X("category"));rootElem->appendChild(catElem);catElem->setAttribute(X("idea"), X("great"));DOMText* catDataVal = doc->createTextNode(X("XML Parsing Tools"));catElem->appendChild(catDataVal);DOMElement* devByElem = doc->createElement(X("developedBy"));rootElem->appendChild(devByElem);DOMText* devByDataVal = doc->createTextNode(X("Apache Software Foundation"));devByElem->appendChild(devByDataVal);//// Now count the number of elements in the above DOM tree.//const XMLSize_t elementCount = doc->getElementsByTagName(X("*"))->getLength();XERCES_STD_QUALIFIER cout << "The tree just created contains: " << elementCount<< " elements." << XERCES_STD_QUALIFIER endl;doc->release();} catch (const OutOfMemoryException&) {XERCES_STD_QUALIFIER cerr << "OutOfMemoryException" << XERCES_STD_QUALIFIER endl;errorCode = 5;} catch (const DOMException& e) {XERCES_STD_QUALIFIER cerr << "DOMException code is: " << e.code << XERCES_STD_QUALIFIER endl;errorCode = 2;} catch (...) {XERCES_STD_QUALIFIER cerr << "An error occurred creating the document" << XERCES_STD_QUALIFIER endl;errorCode = 3;}} else{// (inpl != NULL)XERCES_STD_QUALIFIER cerr << "Requested implementation is not supported" << XERCES_STD_QUALIFIER endl;errorCode = 4;}}XMLPlatformUtils::Terminate();return errorCode;
}// ---------------------------------------------------------------------------
// This is a simple class that lets us do easy (though not terribly efficient)
// transcoding of XMLCh data to local code page for display.
// ---------------------------------------------------------------------------
class StrX
{
public :// -----------------------------------------------------------------------// Constructors and Destructor// -----------------------------------------------------------------------StrX(const XMLCh* const toTranscode){// Call the private transcoding methodfLocalForm = XMLString::transcode(toTranscode);}~StrX(){XMLString::release(&fLocalForm);}// -----------------------------------------------------------------------// Getter methods// -----------------------------------------------------------------------const char* localForm() const{return fLocalForm;}private :// -----------------------------------------------------------------------// Private data members//// fLocalForm// This is the local code page form of the string.// -----------------------------------------------------------------------char* fLocalForm;
};inline XERCES_STD_QUALIFIER ostream& operator<<(XERCES_STD_QUALIFIER ostream& target, const StrX& toDump)
{target << toDump.localForm();return target;
}int SAXPrint()
{// ---------------------------------------------------------------------------// Local data//// doNamespaces// Indicates whether namespace processing should be enabled or not.// Defaults to disabled.//// doSchema// Indicates whether schema processing should be enabled or not.// Defaults to disabled.//// schemaFullChecking// Indicates whether full schema constraint checking should be enabled or not.// Defaults to disabled.//// encodingName// The encoding we are to output in. If not set on the command line,// then it is defaulted to LATIN1.//// xmlFile// The path to the file to parser. Set via command line.//// valScheme// Indicates what validation scheme to use. It defaults to 'auto', but// can be set via the -v= command.// ---------------------------------------------------------------------------static bool doNamespaces = false;static bool doSchema = false;static bool schemaFullChecking = false;static const char* encodingName = "LATIN1";static XMLFormatter::UnRepFlags unRepFlags = XMLFormatter::UnRep_CharRef;static char* xmlFile = 0;static SAXParser::ValSchemes valScheme = SAXParser::Val_Auto;// Initialize the XML4C2 systemtry {XMLPlatformUtils::Initialize();} catch (const XMLException& toCatch) {XERCES_STD_QUALIFIER cerr << "Error during initialization! :\n"<< StrX(toCatch.getMessage()) << XERCES_STD_QUALIFIER endl;return 1;}xmlFile = "../../../../../samples/data/personal-schema.xml";int errorCount = 0;//// Create a SAX parser object. Then, according to what we were told on// the command line, set it to validate or not.//SAXParser* parser = new SAXParser;parser->setValidationScheme(valScheme);parser->setDoNamespaces(doNamespaces);parser->setDoSchema(doSchema);parser->setHandleMultipleImports (true);parser->setValidationSchemaFullChecking(schemaFullChecking);//// Create the handler object and install it as the document and error// handler for the parser-> Then parse the file and catch any exceptions// that propogate out//int errorCode = 0;try {//SAXPrintHandlers handler(encodingName, unRepFlags);//parser->setDocumentHandler(&handler);//parser->setErrorHandler(&handler);parser->parse(xmlFile);errorCount = parser->getErrorCount();} catch (const OutOfMemoryException&) {XERCES_STD_QUALIFIER cerr << "OutOfMemoryException" << XERCES_STD_QUALIFIER endl;errorCode = 5;} catch (const XMLException& toCatch) {XERCES_STD_QUALIFIER cerr << "\nAn error occurred\n Error: "<< StrX(toCatch.getMessage())<< "\n" << XERCES_STD_QUALIFIER endl;errorCode = 4;}if(errorCode) {XMLPlatformUtils::Terminate();return errorCode;}//// Delete the parser itself. Must be done prior to calling Terminate, below.//delete parser;// And call the termination methodXMLPlatformUtils::Terminate();if (errorCount > 0)return 4;elsereturn 0;return 0;
}int main(int argc, char* argv[])
{CreateDOMDocument();SAXPrint();cout<<"ok!"<<endl;return 0;
}相关文章:

[干货]Kaggle热门 | 用一个框架解决所有机器学习难题
新智元推荐 来源:LinkedIn 作者:Abhishek Thakur 译者:弗格森 【新智元导读】本文是数据科学家Abhishek Thakur发表的Kaggle热门文章。作者总结了自己参加100多场机器学习竞赛的经验,主要从模型框架方面阐述了机器学习过程中可能会…

gtest简介及简单使用
gtest是一个跨平台(Liunx、Mac OS X、Windows、Cygwin、Windows CE and Symbian)的C测试框架,有google公司发布。gtest测试框架是在不同平台上为编写C测试而生成的。从http://code.google.com/p/googletest/downloads/detail?namegtest-1.7.0.zip&can2&q下…

新浪微博推广网站的一些实践体会
本以为微博推广很难,每天都要刷粉刷内容的,也本以为做微博推广也很简单,一不卖产品、二不卖服务的,目的单纯灵活性强些,做了之后才发现都不是那么回事,微博虽然也过了“火了”,但新媒体还真是不…

AI和大数据如何落地智能城市?京东城市这6篇论文必读 | KDD 2019
来源 | 京东城市(ID: icity-jd)作为世界数据挖掘领域的最高级别的学术会议,ACM SIGKDD(国际数据挖掘与知识发现大会,简称 KDD)将于 2019 年 8 月 4 日—8 日在美国阿拉斯加州安克雷奇市举行。自 1995 年以来…
OSError: Could not find library geos_c or load any of its variants ['libgeos_c.so.1', 'libgeos_c.so
OSError: Could not find library geos_c or load any of its variants [libgeos_c.so.1, libgeos_c.so 解决: sudo vim /etc/ld.so.conf 添加:/opt/source/geos-3.5.0/build/lib sudo ldconfig
五分钟搭建BERT服务,实现1000+QPS,这个Service-Streamer做到了
作者 | 刘欣简介:刘欣,Meteorix,毕业于华中科技大学,前网易游戏技术总监,现任香侬科技算法架构负责人。之前专注游戏引擎工具架构和自动化领域,2018年在GDC和GoogleIO开源Airtest自动化框架,广泛…
Nagios+pnp4nagios+rrdtool 安装配置为nagios添加自定义插件(三)
nagios博大精深,可以以shell、perl等语句为nagios写插件,来满足自己监控的需要。本文写mysql中tps、qps的插件,并把收集到的结果以图形形式展现出来,这样输出的结果就有一定的要求了。 编写插件tps qps check_qps 插件如下内容 #…
OpenSSL简介及在Windows、Linux、Mac系统上的编译步骤
OpenSSL介绍:OpenSSL是一个强大的安全套接字层密码库,囊括主要的密码算法、常用的密钥和证书封装管理功能及SSL协议,并提供丰富的应用程序供测试或其它目的使用。 SSL是SecureSockets Layer(安全套接层协议)的缩写,可以在Interne…

Guava Cache本地缓存在 Spring Boot应用中的实践
概述 在如今高并发的互联网应用中,缓存的地位举足轻重,对提升程序性能帮助不小。而 3.x开始的 Spring也引入了对 Cache的支持,那对于如今发展得如火如荼的 Spring Boot来说自然也是支持缓存特性的。当然 Spring Boot默认使用的是 SimpleCache…

Windows 8.1 Preview(Windows Blue)预览版简体中文官方下载(ISO完整版镜像)
Windows 8.1是微软继Windows 8以来的又一全新力作,又名Windows Blue(视窗蓝,专注蓝屏30年),个人觉得Win8还是比较流畅的但大众始终觉得还是有很多需要改进或者改善的,如今微软为了迎合大众需求对Win8进行升…

Linux下编辑器vi/vim的使用介绍
vi编辑器是所有Unix及Linux系统下标准的编辑器。对Unix及Linux系统的任何版本,vi编辑器是完全相同的。 基本上vi可以分为三种状态,分别是命令模式(commandmode)、插入模式(insert mode)和底行模式(last line mode),各模式的功能为࿱…

Clojure程序设计
《Clojure程序设计》基本信息作者: (美)Stuart Halloway Aaron Bedra [作译者介绍]出版社:人民邮电出版社ISBN:9787115308474上架时间:2013-3-1出版日期:2013 年3月开本:16开页码:230版次&#…

重磅!AI Top 30+案例评选正式启动
2019 年,人工智能应用落地的重要性正在逐步得到验证,这是关乎企业生死攸关的一环。科技巨头、AI 独角兽还有起于草莽的创业公司在各领域进行着一场多方角斗。进行平台布局的科技巨头们,正在加快承载企业部署 AI 应用的步伐,曾经无…

直播回顾 | 关于Apollo 5.0控制在环仿真技术的分享
Apollo 用于模型验证和测试的基于 Web 的仿真平台 Dreamland 已经更新到能使用更强大的场景编辑器和环控制模拟。基于 Apollo 流水线和机器学习的动力学模型,复杂度较高,同时基于 AI 的全景数据建模,模型精细度高,误差比传统方式可…
eclipes 安装 pytdev,svn,插件
1, python pydevhttp://pydev.org/updates2, svnhttp://subclipse.tigris.org/update3, 推荐http://subclipse.tigris.org/update_1.10.x 转载于:https://blog.51cto.com/swq499809608/1240873
FFmpeg简介及在vc2010下编译步骤
FFmpeg是一个开源的多媒体库,最新版本是2.4.3,它的License是LGPL或GPL。FFmpeg可以用来记录、转换数字音频、视频,并能将其转换为流的开源计算机程序。它包括了音/视频编码库libavcodec。FFmpeg是在Linux下开发出来的,但它可以在包…
医院六级电子病历建设思路及要点
产生背景 在医院电子病历信息化发展的过程中,先后经历了纸质病历、电子病历、结构化电子病历以及具有全医疗过程管理能力的电子病历四个阶段。临床业务需求质量的逐步提升,标准规范的逐步细化,互联网战略的落地实施,无疑对目前电子…
上手必备!不可错过的TensorFlow、PyTorch和Keras样例资源
作者 | 黄海广来源 | 机器学习初学者(ID: ai-start-com)TensorFlow、Keras和PyTorch是目前深度学习的主要框架,也是入门深度学习必须掌握的三大框架,但是官方文档相对内容较多,初学者往往无从下手。本人从github里搜到…
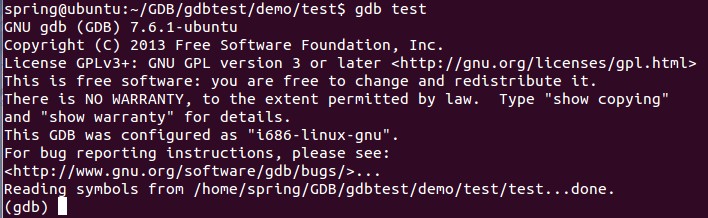
Linux下gdb调试工具的使用
gdb是GNU开源组织发布的一个强大的Linux下的程序调试工具。 gdb主要完成四个方面的功能:(1)、启动你的程序,可以按照你的自定义的要求随心所欲的运行程序;(2)、可让被调试的程序在你所指定的调试的断点处停住(断点可以是条件表达式)…
UESTC 1726 整数划分(母函数)
题目链接:http://222.197.181.5/problem.php?pid1726 题意:求n的划分数。一种划分方案中不能有相同的数字。 思路:(1x)(1x^2)(1x^3)……(1x^1000). int f[N];void init() {f[1]1;int a[N]{0};a[0]1; a[1]1;int i,j;for(i2;i<1000;i){for(…
JS nodeType返回类型
JS nodeType返回类型 前几天朋友正好问道 这个 js的nodeType是个什么概念(做浏览器底层的)正好遇到这篇文章可以向大家解释下 将HTML DOM中几个容易常用的属性做下记录: nodeName、nodeValue 以及 nodeType 包含有关于节点的信息。 nodeName …
C# 获取指定目录下所有文件信息、移动目录、拷贝目录
/// <summary>/// 返回指定目录下的所有文件信息/// </summary>/// <param name"strDirectory"></param>/// <returns></returns>public List<FileInfo> GetAllFilesInDirectory(string strDirectory){List<FileInfo&g…
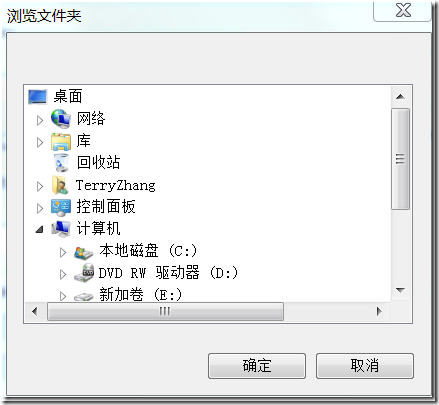
文件夹浏览(SHBrowseForFolder)
from http://www.cnblogs.com/Clingingboy/archive/2011/04/16/2018284.html 一.首先要为SHBrowseForFolder准备一个结构体BROWSEINFO typedef struct _browseinfoW {HWND hwndOwner;PCIDLIST_ABSOLUTE pidlRoot;LPWSTR pszDisplayName; // Return display…
技术新贵:RPA与NLP技术的结合与应用
什么是 RPA(Robotic Process Automation)?机器人流程自动化(RPA)是一种自动化工具,用于创建软件机器人的虚拟劳动力,从而优化和降低企业中端到端业务流程的成本。RPA 可以翻译成机器人流程自动化…
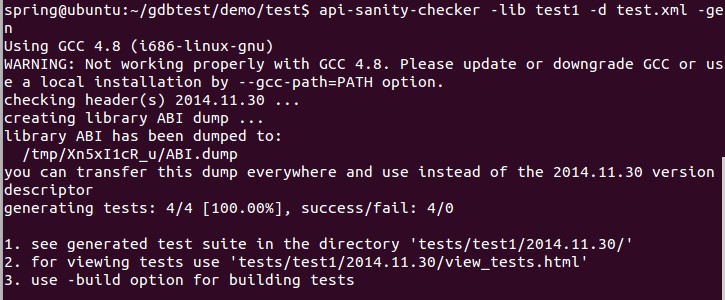
API Sanity Checker在Ubuntu中的使用
API Sanity Checker是一个自动生成单元测试用例的工具,可用于链接测试。它可用于三大桌面平台,下面简单介绍它在Linux下的使用步骤:1. 从http://ispras.linuxbase.org/index.php/API_Sanity_Autotest 下载最新的api-sanity-checker-1.98…

手动脱壳—dump与重建输入表(转)
文章中用到的demo下载地址: http://download.csdn.net/detail/ccnyou/4540254 附件中包含demo以及文章word原稿 用到工具: Ollydbg LordPE ImportREC 这些工具请自行下载准备 Dump原理这里也不多做描述,想要了解google it!常见的dump软件有Lo…
如何用RNN生成莎士比亚风格的句子?(文末赠书)
作者 | 李理,环信人工智能研发中心vp,十多年自然语言处理和人工智能研发经验。主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。来源 | 《深度学习理论与实战:基础篇》基本概…
图像相似度计算之哈希值方法OpenCV实现
感知哈希算法(perceptual hash algorithm),它的作用是对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。结果越接近,就说明图像越相似。 实现步骤: 1. 缩小尺寸:将图像缩小到8*8的尺寸&am…
七夕大礼包:26个AI学习资源送给你!
整理 | Jane出品 | AI科技大本营(ID:rgznai100)免费的在线学习课程一直是大多数人学习 AI 知识和技能的方式之一。今天,基于 Github 上一位小姐姐 Chip Huyen 分享的 10 门机器学习课程,AI科技大本营将这份收藏大礼包进…

HTML Inspector – 帮助你编写高质量的 HTML 代码
HTML Inspector 是一款代码质量检测工具,帮助你编写更优秀的 HTML 代码。HTML Inspector 使用 JavaScript 编写,运行在浏览器中,是最好的 HTML 代码检测工具。 您可能感兴趣的相关文章Metronic – 赞!Bootstrap 响应式后台管理模板…