每天超50亿推广流量、3亿商品展现,阿里妈妈的推荐技术有多牛?

作者 | 夕颜
出品 | AI科技大本营(ID:rgznai100)
随着深度学习、强化学习、知识图谱、AutoML 等 AI 技术出现更多突破,推荐系统领域的企业和开发者开始将这些技术与传统推荐算法相结合,使得推荐效果得到显著提升。
不过,越来越复杂的场景、用户需求等对推荐系统提出了更高的要求。如今推荐系统已经得以大规模应用,然而掀开技术的外壳,审视推荐系统的内核,我们会发现推荐技术还有很多瓶颈亟待突破。

作为 2019 AI ProCon 推荐系统专场(官网:https://aiprocon.csdn.net/)的出品人,阿里妈妈资深算法专家朱小强在接受 AI科技大本营(ID:rgznai100)采访时,对推荐领域也表达出“当我们越深入,越感觉到现有技术的浅薄”这样类似的感受。这不禁让人思考:推荐系统与流行 AI 技术的结合究竟对优化推荐效果起到了多大的作用?打破推荐系统领域瓶颈的突破口在哪里?怎样做,才能让推荐系统更好地服务用户?
两大关键技术模块取得突破
阿里妈妈隶属阿里巴巴集团,拥有其核心商业数据。它每天有超过 50 亿推广流量,完成超过 3 亿件商品推广展现,覆盖高达 98% 的网民。
面对如此大规模的推广展现任务,阿里妈妈的广告推荐系统起到了至关重要的作用。随着历史的推演,从 2012 年起,阿里妈妈的预估模型也在不断的迭代和创新,每年为公司带来数十亿级的收益提高。
朱小强认为,推荐系统的本质,是海量用户与商品/内容之间的信息配对问题。与搜索技术不同的是,推荐系统输入缺乏用户的主动意图表达,因此“听声辨位”是推荐技术的形象描述:“声”即用户的历史行为,这是我们推断用户兴趣的关键线索;“位”即用户当前潜在的兴趣内容,是推荐系统的输出结果。能不能听得真、辨得准,就是推荐技术的核心技能。
定向广告、信息流广告等展示类广告技术,其内核也是系统基于用户的行为偏好进行内容推荐,因此与推荐系统技术异曲同工。
过去的几年时间里,阿里妈妈定向广告团队在推荐技术的两个关键模块上均取得了较大的突破:
匹配召回技术(matching):在业界首创了第三代基于树结构的深度检索系统 TDM[1]。相比于第一代基于统计规则的协同滤波,第二代基于向量化表达的全库检索,TDM 技术可以使用任意复杂高阶的深度学习模型计算 user 与 item 之间的关系,并且结合 tree-based 的高效索引结构、对全部 item 库进行全局最优匹配。得益于强大的模型能力,TDM 可以对用户进行深层次的理解与刻画,从而召回的结果在多样性、精准性等方面,相比前两代技术都有显著的提升。
预估排序技术(ranking):阿里妈妈是业界最早一批全面构建、创新自研大规模端到端深度学习模型的团队,尤其是立足于电商场景、针对海量的用户行为数据,阿里妈妈持续发力用户兴趣建模技术,提出了深度兴趣网络 DIN[2]、用户兴趣演化网络 DIEN[3]、用户多兴趣轨道记忆网络 MIMN[4]、基于行为序贯特性的全空间多任务模型ESMM[5]等一系列业界领先的深度学习算法。这些建模算法极大地拓宽了业界对于点击率、转化率等推荐系统核心排序技术的认知,被业界各大公司的同行参考,并做了各种进一步的优化改进,形成了该领域的一个全新流派。
除了matching、ranking 技术的创新外,结合电商场景推荐商品的图文特性,阿里妈妈在商品创意的理解与自动生成方面也做了大量的工作,如大规模图像行为理解与建模技术CrossMedia[6]、自动文本生成技术[7]。此外,阿里妈妈还推出了支撑这些工业级复杂深度学习模型的开源训练框架 X-DeepLearning[8]、高性能深度学习在线推理引擎 Blaze[9],以及结合广告/推荐场景深度学习模型特点的稀疏模型压缩、量化与剪枝技术,如基于 Distillation 技术的轻量级模型压缩算法Rocket Training[10]等。
这些来自工业实战的独特 AI 技术创新,结合阿里丰富的个性化行为数据,推动了阿里妈妈的广告业务持续、高速的增长。
传统推荐系统+AI技术,超百亿收入增量
阿里妈妈能够不断取得突破,与其将传统推荐技术与新兴的 AI 技术结合起来密不可分。从 2010 年左右,阿里妈妈就开始持续发力人工智能技术,用技术的力量来驱动商业的可持续增长。
众所周知,广告业务的投入产出比极高,往往 1% 的提升就对应数亿、数十亿的收入增长。因此,从最初大规模建设的分布式机器学习技术、图像NLP技术,到最近的深度学习、强化学习、机器翻译等技术,阿里妈妈很早就已经在工业场景中涉猎并且大力投入创新研发。
朱小强进一步解释,今天阿里妈妈绝大部分核心技术模块基本都构建在深度学习基础之上,强化学习则驱动了阿里妈妈的广告策略机制和智能调控算法的关键升级。构建在这些 AI 技术之上的业务算法,给阿里妈妈直接带来的收入增量超百亿。据统计,仅DIN/DIEN/MIMN/TDM 等论文中披露的数字显示,核心场景的点击率累计提升就超过 40%。
在推荐系统与 AI 技术结合中,朱小强还特意强调了 AutoML 技术的应用现状。他表示,根据阿里妈妈的经验和与业界同行的交流来看,类似在图像领域中直接通过 AutoML 技术搜索出更优模型结构并取得显著指标提升的可能性不大。不过,AutoML 技术可以用来进行模型精度与算力需求的联合优化,寻找精度不变情况下更低能耗的模型结构。虽然这种技术本身不会直接带来效果提升,但是由于它的助攻,使得离线模型算法的设计可以有更大的自由度,生产化落地有更多的保障手段。
抗住工业级场景压力的“武器”
阿里妈妈本身庞大的业务场景决定了其推荐系统必然需要过硬的技术架构,才能抗住工业级场景下提出的众多挑战。
面对实际业务需求,阿里妈妈从 2015 年左右就开始系统地推进工业级深度学习的探索与研发。朱小强回忆道,最初,阿里妈妈只是把深度学习当成是一种新的建模算法,但很快就在算法实验上取得了突破,他们发现,端到端地训练一个简单的分组全连接深度网络,就比当时线上优化多年,集结了各种调优 trick 的最强 MLR 模型[11]具有显著优势。
幸运的是,阿里妈妈很快意识并抓住了这个新技术的突破契机,在 2016 年“ALL-IN”深度学习。
朱小强表示,站在现在看过去,阿里妈妈工业级深度学习的完整体系构建,涵盖了从算法突破点燃的星星之火,到业界首个面向高维稀疏数据场景的工业级深度学习训练框架 X-DeepLearning、大规模分布式 GPU 训练集群、高性能深度学习在线推理引擎 Blaze、端到端实时深度学习树型检索引擎、深度模型训练/评估/部署的自动化生产链路,后续持续升级的大规模实时深度学习 ODL 架构、面向大规模稀疏深度模型的压缩/量化/剪枝等效能优化技术,以及最新的结合算力算法与系统架构 co-design 的工业级深度学习 2.0 技术体系构建等等。
这个过程并不是一帆风顺的,阿里妈妈在每个阶段都经历了无数的挑战,包括关键技术路径的争论与判断、核心算法的艰难突破、算力资源的争取,以及来自集团/业界的质疑挑战等。所幸,阿里妈妈克服了所有的困难。
不过,他认为真正决定整个技术体系构建成败的关键挑战,是由深度学习引发的新一代技术革新对算法、工程、数据、测试等传统技术工种的融合需求。
“今天我们清楚地认识到,深度学习是一种新的生产力,它需要我们对整个技术体系进行全面改造,阿里妈妈定向广告团队在这一轮的技术升级过程中之所以能够取得一系列的技术领先优势,除了核心驱动者的超前意识和能力,最大的红利来自于我们可以协同算法、工程等全部力量,以算法创新为内驱,以业务场景和需求为孵化的土壤,不受固有架构的局限,勇于打破与重新定义。”
例如,X-DeepLearning 框架就是由算法团队率先研发,由工程团队续力做进一步抽象形成的;TDM 全新检索系统也是依赖算法与工程团队协同开发才能真正落地;大规模实时深度学习 ODL 架构则是集合了算法/工程/数据/测试全部力量合力打造。
这种跨越工种和团队组织的 co-design 研发模式,在他看来是工业级深度学习体系研发成功背后的关键要素。
工业级深度学习 2.0 时代
此前,朱小强曾发表过这样的观点:接下来工业级深度学习将进入 2.0 时代,这个阶段面临的核心问题,是当前深度学习仍然跑在为上一代大规模机器学习模型需求而构建的系统架构之上,但过去的那套架构已经不太适合如今数据、算法和算力背后的需求。
那么,满足现在工业级场景需求的系统架构理想中应该是什么样的?如何从现有基础上进行改进或重新构建?
朱小强认为,没有最理想的系统架构,只有适应当前算力、算法需求,协同发挥最大收益的合理架构。生产关系和生产力从来都是配对出现的。
以推荐系统为例,当前的系统架构普遍遵循的是计算数量逐级约减、计算复杂度逐级上升的结构。但事实上,深度学习算法本身的特性和 GPU 单点算力的巨大飞跃,已经可以打破这种架构设计,后链路尽可能地放宽计算约减的约束,甚至尽可能减少中间环节、构建更短的端到端系统。
例如,阿里妈妈近期对粗排架构做了一次升级,打破了传统粗排模型广泛采用的双塔结构,引入更加复杂的、但算力可控的全连接结构,同时粗排引擎升级为全实时计算引擎。这种全新的粗排架构,直接为其带来了显著的业务收益,同时为后续拓宽了更大的算法空间。
“架构的演进一定是个循序渐进、各模块独立推进的过程,只不过抽象出背后演进的驱动力,我认为可以有一条主线:如何把单点算力通过新的架构放大、进而承载更复杂更实时的计算。”朱小强称。
另一方面,面向业务场景的需求和数据的特性,需要对算力、算法和系统架构之间做协同设计(co-design),具体应该怎么做?
朱小强告诉 AI科技大本营,更大体系内的 co-design 设计是一种新的方法论,具体到每个系统模块或者技术环节,都有着不同的做法。举例来说:
TDM 是第三代匹配检索体系,它重新定义了两个技术:1)全库检索模型突破了向量化架构,采用任意复杂的深度模型;2)实时检索引擎,采用tree-based新型索引而非传统的正排、倒排索引。事实上,这两个技术单独看都不新鲜,甚至以及在其余技术中广泛采用了。但是当算法与索引结构 co-design 时,形成了全新的技术。Google 在 2017 年推出的基于机器学习的数据库 index learning 技术,与 TDM 有着异曲同工之妙。
MIMN 是阿里妈妈研发的新一代点击率预估模型,在今年的 KDD 会议上已经公开发表。单独看 MIMN 算法,它虽然很精妙,但非常复杂,难以部署到实际生产系统提供实时在线服务。MIMN 是业界首个面向超长用户行为序列建模的技术,对淘宝数亿用户、平均历史行为长度超过 1000 的数据进行建模,离线训练总归不是难事,但是如此长的行为序列数据作为特征提供在线实时服务,系统引擎是远远扛不住的。
为此,朱小强团队结合在线引擎的特点,把计算做了异步拆解,构建了一个单独的用户兴趣服务 UIC,专门用来计算 MIMN 中复杂的长行为序列模型;同时结合记忆网络的特点,采用了实时增量计算技术,破解了在线服务的难题。MIMN+UIC的 co-design 设计,使得该团队得以成功地把这项最新的算法部署上线,取得显著收益。
然而,朱小强也指出,co-design 的方法论更多的是一种新的技术思考模式,使得我们设计新的技术时可以从更大的视角出发、敢于打破原有约束、重新定义新的体系,而不是什么灵丹妙药。
推荐系统的瓶颈
从事推荐系统研发多年的朱小强见证了推荐技术近二十年的蓬勃发展,他认为,宏观的技术体系已经相对完整,尤其是近些年来与大规模机器学习、深度学习、强化学习等技术结合后,推荐技术越发强大。不过,掀开技术的外壳,审视推荐系统的内核,他认为有两个关键问题还需要更多的突破:
一是模型跟随问题。数据挖掘领域经典的“啤酒与尿布”案例,在今天的推荐系统中同样存在,而且更加隐蔽和普遍。在构建推荐模型时,往往是基于系统收集的展现-反馈日志体系,同时挖掘用户近期的历史行为,进而训练模型,对未来的用户兴趣进行预测。这个体系乍看很合理,但深入思考后会发现,推荐模型大都时候是依据用户在系统中留下的蛛丝马迹做相应的判断,这种判断本质是在跟随用户的显式行为,或者很多时候我们称之为重定向。
换句话说,用户点击了什么,模型接着给用户推荐什么,不一定是一模一样的推荐,但是非常像。这个问题不是出在模型本身,而是我们构建模型的方式。这类问题还有一些别的叫法,比如数据陷阱、数据循环等直观上大家容易想到一些解法,如经典的 e&e 策略。但是随机的探索不仅低效,而且难以撼动整体数据分布。
阿里妈妈在这个问题上已经做了一些努力,比如 TDM 这种新型的检索算法,已经比传统方法在全库最优计算、模型泛化等方面有所突破,召回结果的多样性也有显著改善;MIMN 排序模型,已经突破了用户历史行为序列长度的建模瓶颈,在淘宝场景下使用超过 1000 长度的超长历史行为来理解用户、刻画其兴趣,这样模型就有更大的可能性跳出短时间的行为重定向,带来一些惊喜的结果。但是坦白讲,这些解法都还是局部优化,真正的突破还需要业界更多持续的努力,其中关键点在于对数据循环链路的掌控,不仅仅拟合数据分布,同时能够主动地扰动数据分布,结合算法设计,构建更具洞察与推理的推荐技术。
二是集合展现问题。这与推荐系统的展现交互密切相关。目前有两类典型的交互方式,一类是淘宝、今日头条等以瀑布流式上下滑动的空间维度集合展现;一类是以抖音、快手等沉浸式左右滑动的时间维度集合展现。不论哪种模式,对于用户而言,会在短时间连续浏览到批量的内容结果。如果把用户的每一次浏览看成是其与推荐系统的一次对话,那么推荐系统在这种连续交互式对话上还处于处级阶段。
目前大都数推荐系统构建均采用点估计加后链路集合调控为主的方式。最近也出现了一些面向集合推荐的技术,如 beam-search 式整页推荐。但是这些技术还缺乏跟用户有效的及时对话和反馈机制。这也是受限于系统硬件以及计算时效性等因素,很难在用户浏览或点击完一个结果后快速进行针对性调整。今天,端计算的逐步兴起,给这个领域带来了新的契机。此外,集合结果的最优生成与动态反馈调优算法,仍然需要新的突破。
理想中的推荐系统
最后,朱小强还补充了自己从多年从事推荐系统研发工作的经验中得出的一些思考,“当我们越深入、越感觉到现有技术的浅薄。我心中理想的推荐系统,应该是像相知多年的老友一样,了解你的喜好习性,洞察你此刻的心情,给予贴心甚至惊喜的推荐。它健谈但不聒噪,懂得适可而止。当然,它也一定是让你足够信赖的。我们今天的推荐系统,就像一个恼人的喋喋不休的话痨,你刚开始谈一个话题,它就源源不断地给你轰炸同质的消息,让你审美疲劳。”
正如朱小强所说,推荐系统作为最重要的个性化服务应用之一,它的主要功能是提供服务、吸引更多的用户使用和停留。从这个角度来看,未来推荐技术还有很大的进步空间。
参考文献:
[1] Han Zhu et al, Learning Tree-based Deep Model for Recommender Systems, KDD 2018
[2] Guorui Zhou et al, Deep Interest Network for Click-Through Rate Prediction, KDD 2018
[3] Guorui Zhou et al, Deep Interest Evolution Network for Click-Through Rate Prediction,AAAI 2019
[4] Qi Pi et al, Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction, KDD 2019
[5] Xiao Ma et al, Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate, SIGIR 2018
[6] Tiezheng Ge et al, Image Matters: Visually modeling user behaviors using Advanced Model Server, CIKM 2018
[7] Yuchi Zhang et al, Improve diverse text generation by self labeling conditional variational auto encoder. ICASSP 2019
[8] https://github.com/alibaba/x-deeplearning/tree/master/xdl
[9] https://github.com/alibaba/x-deeplearning/tree/master/blaze
[10] Guorui Zhou et al, Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net, AAAI 2018
[11] https://mp.weixin.qq.com/s/MtnHYmPVoDAid9SNHnlzUw
好消息!AI ProCon 2019推荐系统技术专场迎来重磅嘉宾
想要听到朱小强老师更多关于阿里妈妈推荐系统的详情吗?欢迎来到 AI ProCon 2019,在大会专设的推荐系统技术专场上,朱小强老师将带来一场推荐系统技术的精彩分享!
讲师简介:
朱小强,花名怀人,毕业于清华大学,阿里资深算法专家,现任阿里妈妈深度学习算法平台负责人、兼任定向广告&信息流广告排序技术团队负责人。他主持了三代核心算法架构(大规模、深度端到端、深度实时化)的设计和落地,驱动了深度学习对阿里广告技术的全面变革与创新,领导了阿里开源深度学习框架X-DeepLearning从0到1的自研、从1到开源演进的全过程,在KDD、AAAI、SIGIR等顶级会议上发表过DIN/DIEN/ESMM等多篇有影响力的工业实战论文,是workshop DLP-KDD 2019的发起人和联合主席。
演讲题目:
工业级深度学习2.0:算力+算法+系统架构的co-design理念与实践
演讲内容简介:
推荐系统是个性化服务时代最为典型的应用技术之一,其技术本质是海量用户与物品的信息配对问题。近些年来,工业级深度学习大规模应用到推荐系统,推动了技术的整体变革升级,取得显著的业务收益。然而,随着技术发展的深入,我们很快触及了深度学习在工业场景应用的天花板:算力突破曾经是引爆深度学习技术的重要推力,今天却成为了新的阻力;深度学习如黑洞一样短短数年时间就吞噬掉了上一代技术体系积累的数据、系统、架构以及算力存量,使得新技术的迭代速度逐步下降。
新的挑战下,如何破局,如何进一步释放算力、算法的威力,推动技术的下一步升级?联动算力与算法重新定义新的系统架构,把单点算力通过新的架构放大、进而承载更复杂更实时的计算,这是我们认为的关键解法,我称之为工业级深度学习 2.0。本次演讲中我将围绕着 co-design 的全新方法论,以阿里妈妈的技术演化为样本,介绍工业级深度学习 2.0 的理念思考与具体实践。
演讲提纲:
宏观解析推荐系统中,算法体系、计算力、系统框架、数据链路的关系
梳理深度学习前后的两代推荐技术体系,总结工业级深度学习当前面临的挑战
以阿里妈妈具体实践为例,介绍以co-design为内核的工业级深度学习2.0发展趋势
(演讲内容以现场为准)
除此之外, AI ProCon 2019 推荐系统分论坛还邀请到京东集团高级总监殷大伟、快手科技推荐架构负责人任恺和华为诺亚方舟实验室推荐与搜索项目组资深研究员唐睿明商、短视频等领域的应用和实践

(议程不断更新中)
特惠票价限时抢购中,扫码或点击阅读原文,了解更多嘉宾和大会信息。
相关文章:

常用的JQuery数字类型验证正则表达式
var regexEnum { intege:"^-?[1-9]//d*$", //整数 intege1:"^[1-9]//d*$", //正整数 intege2:"^-[1-9]//d*$", //负整数 num:"^([-]?)//d*//.?//d$", //数字 num1:"^([1-9]//d*|0)$", //正数ÿ…
Java多线程编程实战:模拟大量数据同步
背景 最近对于 Java 多线程做了一段时间的学习,笔者一直认为,学习东西就是要应用到实际的业务需求中的。否则要么无法深入理解,要么硬生生地套用技术只是达到炫技的效果。 不过笔者仍旧认为自己对于多线程掌握不够熟练,不敢轻易应…
Ubuntu中Atom编辑器显示中文乱码的处理方法
在Ubuntu14.04 64位机上安装Atom,依次在终端输入如下命令: 1. $ sudo add-apt-repository ppa:webupd8team/atom 2. $ sudo apt-get update 3. $ sudo apt-get install atom处理中文乱码的问题: 1. 安装文泉驿正黑等相关中文字体&#…

我的世界游戏安装
2019独角兽企业重金招聘Python工程师标准>>> Minecraft 是一款沙盘独立视频游戏,灵感来自于Infiniminer,使用Java编写,由Markus "Notch" Persson 所建立,现由Mojang AB 公司开发。 这里我们介绍如何在pcDuin…

RSA签名的PSS模式
本文由云社区发表作者:mariolu 一、什么是PSS模式? 1.1、两种签名方式之一RSA-PSS PSS (Probabilistic Signature Scheme)私钥签名流程的一种填充模式。目前主流的RSA签名包括RSA-PSS和RSA-PKCS#1 v1.5。相对应PKCS(Public Key Cryptography …
AI真人表情包、斗地主AI......DeeCamp学员做了50个好玩又实用的AI项目
8月16日,2019 DeeCamp人工智能训练营的结营仪式上,展示了600名DeeCamp学员的50个AI实践课题。 结营仪式上,由2019 DeeCamp学员组成的6个项目小组作为代表,现场展示了自己Demo成果,并由李开复、张潼等学术及产业导师现…
libcurl库的使用(通过libcurl库下载url图像)
1. 从http://curl.haxx.se/download.html下载libcurl源码,解压缩; 2. 通过CMake(cmake-gui)生成vs2013 x64位 CURL.sln; 3. 打开CURL.sln,编译会生成libcurl.dll动态库; 4. 在CURL.sln基础上&a…
SQL Server 2005/2008 用户数据库文件默认路径和默认备份路径修改方法
2019独角兽企业重金招聘Python工程师标准>>> 一直想把数据库的默认路径修改一下,在网上找了一下,真的发现有办法 , 特拿 来与大家共同分享。 以下仅为参照,如果有多个实例,可能会有些许不同: …
Linux下多线程编程互斥锁和条件变量的简单使用
Linux下的多线程遵循POSIX线程接口,称为pthread。编写Linux下的多线程程序,需要使用头文件pthread.h,链接时需要使用库libpthread.a。线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基…
03基于python玩转人工智能最火框架之TensorFlow介绍
一句话介绍: Google开源的基于数据流图的科学计算库,适用于机器学习 不局限于机器学习,但目前被大多用于机器学习等。 TensorFlow计算流图的概念图 Tensor在图中流动。 TensorFlow的含义 拆字释义: Tensor 张量(tf中数据的表征) flow 流动 张量在图中流…
赴约北大,2019 CCF大数据与计算智能大赛正式启动
8月17日,以“数据驱动,智创未来”为主题的2019 CCF大数据与计算智能大赛(2019 CCF BDCI)全球启动仪式,在北京大学英杰交流中心阳光厅正式启幕。自2013年创办以来,大赛已成功举办六届,连续获得教…
Hadoop入门(10)_通过java代码实现从本地的文件上传到Hadoop的文件系统
2019独角兽企业重金招聘Python工程师标准>>> 第一步:首先搭建java的编译环境。创建一个Java Project工程,名为upload。 第二步:选中所需的Jar包。 选中JRE System Library 选择BuildPath Configure Build Path 选择ha…
Caffe源码中各种依赖库的作用及简单使用
1. Boost库:它是一个可移植、跨平台,提供源代码的C库,作为标准库的后备。 在Caffe中用到的Boost头文件包括: (1)、shared_ptr.hpp:智能指针,使用它可以不需要考虑内存释放的问题; (2)、dat…

漫画:5分钟了解什么是动态规划?
作者 | 调皮的阿广来源 | 视学算法(ID:z872561826)动态规划,英文是Dynamic Programming,简称DP,擅长解决“多阶段决策问题”,利用各个阶段阶段的递推关系,逐个确定每个阶段的最优决策…

小程序大转盘红包雨营销组件
前言 商城没几个营销活动能叫商城吗?所以就来几个组件吧,写的不好轻踩,对你有帮助记得给个小星星哦直接上链接github链接 运行例子 git clone https://github.com/sunnie1992/soul-weapp.git 微信开发者工具打开项目 营销组件 大转盘 "p…
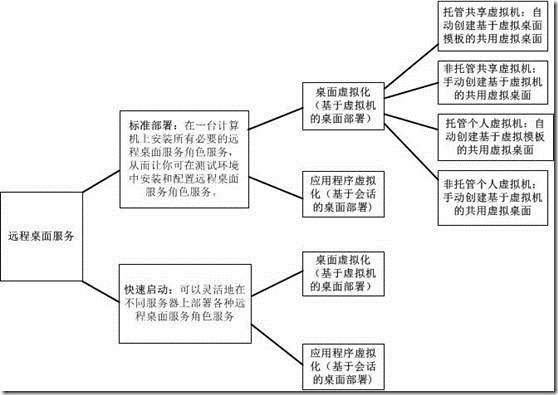
Windows Server 2012 RDS系列:虚拟桌面化(5)
概述:本次将系列地测试Windows Server 2012 远程桌面服务(RDS),将过程进行分享,总的感觉比2008 R2更简单了,体现着2012的自动化。2012的RDS部署有标准部署和快速启动两种,快速启动就是自动快速配…
里程碑式成果Faster RCNN复现难?我们试了一下 | 附完整代码
作者 | 已退逼乎 来源 | 知乎【导读】2019年以来,除各AI 大厂私有网络范围外,MaskRCNN,CascadeRCNN 成为了支撑很多业务得以开展的基础,而以 Faster RCNN 为基础去复现其他的检测网络既省时又省力,也算得上是里程碑性成…
【跃迁之路】【725天】程序员高效学习方法论探索系列(实验阶段482-2019.2.15)...
实验说明 从2017.10.6起,开启这个系列,目标只有一个:探索新的学习方法,实现跃迁式成长实验期2年(2017.10.06 - 2019.10.06)我将以自己为实验对象。我将开源我的学习方法,方法不断更新迭代&#…
C/C++各种数据类型转换汇总
以下是Windows/Linux系统中常用的C/C各种数据类型转换汇总:#ifndef FBC_MESSY_TEST_DATA_TYPE_CONVERT_HPP_ #define FBC_MESSY_TEST_DATA_TYPE_CONVERT_HPP_#include <stdio.h> #include <stdlib.h> #include <iostream> #include <string>…
ASP.NET技巧:两个截取字符串的实用方法
两个截取字符串的实用方法(超过一定长度自动换行)1/** <summary> 2 /// 截取字符串,不限制字符串长度 3 /// </summary> 4 /// <param name"str">待截取的字符串</param> 5 /…
吃瓜腾讯平均月薪7.27万后,微信又出大招
腾讯最新财报一出,喜提热搜!据腾讯第二季度财报显示:2019 年上半年腾讯有员工56310人,总薪酬成本为242.59亿元,腾讯员工平均半年薪为43.08万元。在第一季度里,腾讯员工平均季度薪资为21.27万元,…
回调函数在C/C++中的使用
回调函数就是一个通过函数指针调用的函数。假如把A函数的指针当作参数传给B函数,然后在B函数中通过A函数传进来的这个指针调用A函数,那么就是回调机制。A函数就是回调函数,而通常情况下,A函数是在系统符合你设定的条件下自动执行。使用回调函…
excel单元格加引号及逗号,转换为sql需要的样式
A1 B1BXQY001 ------> BXQY001,BXQY001 -----> BXQY001 在B1中输入公式: ""&A1&""&"," 在B2中输入公式: ""&A1&"" 去掉了后面的逗号。其实就是 " "&A1&…
Win7/Win8 系统下安装Oracle 10g 提示“程序异常终止,发生未知错误”的解决方法...
我的Oracle 10g版本是10.2.0.1.0,(10.1同理)选择高级安装,提示“程序异常终止,发生未知错误”。1.修改Oracle 10G\database\stage\prereq\db\refhost.xml当打开refhost.xml 后会发现有</SYSTEM> <CERTIFIED…
Caffe基础介绍
Caffe的全称应该是Convolutional Architecture for Fast Feature Embedding,它是一个清晰、高效的深度学习框架,它是开源的,核心语言是C,它支持命令行、Python和Matlab接口,它既可以在CPU上运行也可以在GPU上运行。它的…

飞桨博士会第三期来啦!中国深度学习技术俱乐部诚邀您加入
飞桨博士会是由百度开源深度学习平台飞桨(PaddlePaddle)发起的中国深度学习技术俱乐部,旨在打造深度学习核心开发者交流圈,助力会员拓展行业高端人脉、交流前沿技术。俱乐部为会员制,成员皆为博士生导师或博士…

canvas 拼图
效果 代码 <!DOCTYPE html> <html lang"zh_CN"> <head><meta charset"UTF-8"><title>拼图</title><script src"https://code.jquery.com/jquery-3.3.1.js"></script> </head> <body&g…
性能优化之Java(Android)代码优化
最新最准确内容建议直接访问原文:性能优化之Java(Android)代码优化 本文为Android性能优化的第三篇——Java(Android)代码优化。主要介绍Java代码中性能优化方式及网络优化,包括缓存、异步、延迟、数据存储、算法、JNI、逻辑等优化方式。(时间仓促&#…

1小时上手MaskRCNN·Keras开源实战 | 深度应用
作者 | 小宋是呢来源 | CSDN博客0. 前言介绍开源地址:https://github.com/matterport/Mask_RCNN个人主页:http://www.yansongsong.cn/MaskRCNN 是何恺明基于以往的 faster rcnn 架构提出的新的卷积网络,一举完成了 object instance segmentat…

MNIST数据库介绍及转换
MNIST数据库介绍:MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集。它是NIST数据库的一个子集。MNIST数据库官方网址为:http://yann.lecun.com/exdb/mnist/ ,也可以在windows下直接下载,train-im…