Caffe源码中各种依赖库的作用及简单使用
1. Boost库:它是一个可移植、跨平台,提供源代码的C++库,作为标准库的后备。
在Caffe中用到的Boost头文件包括:
(1)、shared_ptr.hpp:智能指针,使用它可以不需要考虑内存释放的问题;
(2)、date_time/posix_time/posix_time.hpp:时间操作函数;
(3)、python.hpp:C++/Python互操作;
(4)、make_shared.hpp:make_shared工厂函数代替new操作符;
(5)、python/raw_function.hpp:C++/Python互操作;
(6)、python/suite/indexing/vector_indexing_suite.hpp:C++/Python互操作;
(7)、thread.hpp:线程操作;
(8)、math/special_functions/next.hpp:数学函数;
2. GFlags库:它是google的一个开源的处理命令行参数的库,使用C++开发,可以替代getopt函数。GFlags与getopt函数不同,在GFlags中,标记的定义分散在源代码中,不需要列举在一个地方。
3. GLog库:它是一个应用程序的日志库,提供基于C++风格的流的日志API,以及各种辅助的宏。它的使用方式与C++的stream操作类似。
4. LevelDB库:它是google实现的一个非常高效的Key-Value数据库。它是单进程的服务,性能非常高。它只是一个C/C++编程语言的库,不包含网络服务封装。
LevelDB特点:(1)、LevelDB是一个持久化存储的KV系统,它将大部分数据存储到磁盘上;(2)、LevelDB在存储数据时,是根据记录的Key值有序存储的;(3)、像大多数KV系统一样,LevelDB的操作接口很简单,基本操作包括写记录,读记录以及删除记录,也支持针对多条操作的原子批量操作;(4)、LevelDB支持数据快照(snapshot)功能,使得读取操作不受写操作影响,可以在读操作过程中始终看到一致的数据;(5)、LevelDB支持数据压缩(Snappy)等操作。
5. LMDB库:它是一个超级快、超级小的Key-Value数据存储服务,是由OpenLDAP项目的Symas开发的。使用内存映射文件,因此读取的性能跟内存数据库一样,其大小受限于虚拟地址空间的大小。
6. ProtoBuf库:GoogleProtocol Buffer(简称ProtoBuf),它是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或RPC数据交换格式。可用于通信协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
要使用ProtoBuf库,首先需要自己编写一个.proto文件,定义我们程序中需要处理的结构化数据,在protobuf中,结构化数据被称为Message。在一个.proto文件中可以定义多个消息类型。用Protobuf编译器(protoc.exe)将.proto文件编译成目标语言,会生成对应的.h文件和.cc文件,.proto文件中的每一个消息有一个对应的类。
7. HDF5库:HDF(HierarchicalData File)是美国国家高级计算应用中心(NCSA)为了满足各种领域研究需求而研制的一种能高效存储和分发科学数据的新型数据格式。它可以存储不同类型的图像和数码数据的文件格式,并且可以在不同类型的机器上传输,同时还有统一处理这种文件格式的函数库。HDF5推出于1998年,相较于以前的HDF文件,可以说是一种全新的文件格式。HDF5是用于存储科学数据的一种文件格式和库文件。
HDF5是分层式数据管理结构。HDF5不但能处理更多的对象,存储更大的文件,支持并行I/O,线程和具备现代操作系统与应用程序所要求的其它特性,而且数据模型变得更简单,概括性更强。
HDF5只有两种基本结构,组(group)和数据集(dataset)。组,包含0个或多个HDF5对象以及支持元数据(metadata)的一个群组结构。数据集,数据元素的一个多维数组以及支持元数据。
8. snappy库:它是一个C++库,用来压缩和解压缩的开发包。它旨在提供高速压缩速度和合理的压缩率。Snappy比zlib更快,但文件相对要大20%到100%。
下面为各个库的简单使用举例:
#include "stdafx.h"
#include <iostream>
#include <string>
#include <assert.h>
#include <fstream>#include <boost/shared_ptr.hpp>
#include <boost/array.hpp>
#include <boost/thread.hpp>
#include <boost/bind.hpp>
#include <gflags/gflags.h>
#include <glog/logging.h>
#include <levelDB/db.h>
#include <lmdb.h>
#include <hdf5.h>
#include <snappy-c.h>#include <windows.h>#include "ml.helloworld.pb.h"int test_Boost();
int test_GFlags(int argc, char* argv[]);
int test_GLog();
int test_LevelDB();
int test_LMDB();
int test_ProtoBuf();
int test_HDF5();
int test_Snappy();int main(int argc, char* argv[])
{//std::cout << argv[0] << std::endl;//E:\GitCode\Caffe\lib\dbg\x86_vc12\testThridLibrary[dbg_x86_vc12].exe//test_Boost();//test_GFlags(argc, argv);//test_GLog();//test_LevelDB();//test_LMDB();//test_ProtoBuf();//test_HDF5();test_Snappy();std::cout << "ok!!!" << std::endl;return 0;
}class implementation {
public:~implementation() { std::cout << "destroying implementation\n"; }void do_something() { std::cout << "did something\n"; }
};int test_Boost()
{//http://www.cnblogs.com/tianfang/archive/2008/09/19/1294521.htmlboost::shared_ptr<implementation> sp1(new implementation());std::cout << "The Sample now has " << sp1.use_count() << " references\n";boost::shared_ptr<implementation> sp2 = sp1;std::cout << "The Sample now has " << sp2.use_count() << " references\n";sp1.reset();std::cout << "After Reset sp1. The Sample now has " << sp2.use_count() << " references\n";sp2.reset();std::cout << "After Reset sp2.\n";return 0;
}DEFINE_bool(big_menu, true, "Include 'advanced' options in the menu listing");
DEFINE_string(languages, "english,french,german", "comma-separated list of languages to offer in the 'lang' menu");int test_GFlags(int argc, char* argv[])
{//http://dreamrunner.org/blog/2014/03/09/gflags-jian-ming-shi-yong///http://www.leoox.com/?p=270int tmp_argc = 3;char** tmp_argv = NULL;tmp_argv = new char*[3];tmp_argv[0] = "";tmp_argv[1] = "--big_menu=false";tmp_argv[2] = "--languages=chinese";//google::ParseCommandLineFlags(&argc, &argv, true);google::ParseCommandLineFlags(&tmp_argc, &tmp_argv, true);std::cout << "argc=" << argc << std::endl;if (FLAGS_big_menu) {std::cout << "big menu is ture" << std::endl;}else {std::cout << "big menu is flase" << std::endl;}std::cout << "languages=" << FLAGS_languages << std::endl;return 0;
}void thread1_test()
{std::string strTmp = "thread1_test";for (int i = 0; i< 1000; i++) {//LOG(INFO) << i;LOG_IF(INFO, i < 10) << i;//CHECK_EQ(i, 100) << "error!";//LOG(INFO) << strTmp;//Sleep(10);}
}void thread2_test()
{std::string strTmp = "thread2_test";for (int i = 1000; i< 2000; i++) {//LOG(INFO) << i;LOG_IF(INFO, i < 1100) << i;//LOG(INFO) << strTmp;//Sleep(10);}
}int test_GLog()
{//http://www.yeolar.com/note/2014/12/20/glog///http://www.cppblog.com/pizzx/archive/2014/06/18/207320.aspxconst char* exe = "E:/GitCode/Caffe/lib/dbg/x86_vc12/testThridLibrary[dbg_x86_vc12].exe";//Initialize Google's logging library.//google::InitGoogleLogging(argv[0]);google::InitGoogleLogging(exe);//为不同级别的日志设置不同的文件basename。google::SetLogDestination(google::INFO, "E:/tmp/loginfo");google::SetLogDestination(google::WARNING, "E:/tmp/logwarn");google::SetLogDestination(google::GLOG_ERROR, "E:/tmp/logerror");//缓存的最大时长,超时会写入文件FLAGS_logbufsecs = 60;//单个日志文件最大,单位MFLAGS_max_log_size = 10;//设置为true,就不会写日志文件了FLAGS_logtostderr = false;boost::thread t1(boost::bind(&thread1_test));boost::thread t2(boost::bind(&thread2_test));t1.join();t2.join();//LOG(FATAL)<<"exit";google::ShutdownGoogleLogging();return 0;
}int test_LevelDB()
{//http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html//http://www.bubuko.com/infodetail-411090.html//http://qiuqiang1985.iteye.com/blog/1255365leveldb::DB* db;leveldb::Options options;options.create_if_missing = true;leveldb::Status status = leveldb::DB::Open(options, "E:/tmp/testLevelDB", &db);assert(status.ok());//write key1,value1std::string key = "key";std::string value = "value";//writestatus = db->Put(leveldb::WriteOptions(), key, value);assert(status.ok());//readstatus = db->Get(leveldb::ReadOptions(), key, &value);assert(status.ok());std::cout << value << std::endl;std::string key2 = "key2";//move the value under key to key2status = db->Put(leveldb::WriteOptions(), key2, value);assert(status.ok());//deletestatus = db->Delete(leveldb::WriteOptions(), key);assert(status.ok());status = db->Get(leveldb::ReadOptions(), key2, &value);assert(status.ok());std::cout << key2 << "===" << value << std::endl;status = db->Get(leveldb::ReadOptions(), key, &value);if (!status.ok())std::cerr << key << " " << status.ToString() << std::endl;else std::cout << key << "===" << value << std::endl;delete db;return 0;
}#define E(expr) CHECK((rc = (expr)) == MDB_SUCCESS, #expr)
#define RES(err, expr) ((rc = expr) == (err) || (CHECK(!rc, #expr), 0))
#define CHECK(test, msg) ((test) ? (void)0 : ((void)fprintf(stderr, \"%s:%d: %s: %s\n", __FILE__, __LINE__, msg, mdb_strerror(rc)), abort()))int test_LMDB()
{//http://www.jianshu.com/p/yzFf8j//./lmdb-mdb.master/libraries/liblmdb/mtest.cint i = 0, j = 0, rc;MDB_env *env;MDB_dbi dbi;MDB_val key, data;MDB_txn *txn;MDB_stat mst;MDB_cursor *cursor, *cur2;MDB_cursor_op op;int count;int *values;char sval[32] = "";srand(time(NULL));count = (rand() % 384) + 64;values = (int *)malloc(count*sizeof(int));for (i = 0; i<count; i++) {values[i] = rand() % 1024;}E(mdb_env_create(&env));E(mdb_env_set_maxreaders(env, 1));E(mdb_env_set_mapsize(env, 10485760));//E(mdb_env_open(env, "./testdb", MDB_FIXEDMAP /*|MDB_NOSYNC*/, 0664));E(mdb_env_open(env, "E:/tmp/testLMDB", MDB_FIXEDMAP /*|MDB_NOSYNC*/, 0664));E(mdb_txn_begin(env, NULL, 0, &txn));E(mdb_dbi_open(txn, NULL, 0, &dbi));key.mv_size = sizeof(int);key.mv_data = sval;printf("Adding %d values\n", count);for (i = 0; i<count; i++) {sprintf(sval, "%03x %d foo bar", values[i], values[i]);/* Set <data> in each iteration, since MDB_NOOVERWRITE may modify it */data.mv_size = sizeof(sval);data.mv_data = sval;if (RES(MDB_KEYEXIST, mdb_put(txn, dbi, &key, &data, MDB_NOOVERWRITE))) {j++;data.mv_size = sizeof(sval);data.mv_data = sval;}}if (j) printf("%d duplicates skipped\n", j);E(mdb_txn_commit(txn));E(mdb_env_stat(env, &mst));E(mdb_txn_begin(env, NULL, MDB_RDONLY, &txn));E(mdb_cursor_open(txn, dbi, &cursor));while ((rc = mdb_cursor_get(cursor, &key, &data, MDB_NEXT)) == 0) {printf("key: %p %.*s, data: %p %.*s\n",key.mv_data, (int)key.mv_size, (char *)key.mv_data,data.mv_data, (int)data.mv_size, (char *)data.mv_data);}CHECK(rc == MDB_NOTFOUND, "mdb_cursor_get");mdb_cursor_close(cursor);mdb_txn_abort(txn);j = 0;key.mv_data = sval;for (i = count - 1; i > -1; i -= (rand() % 5)) {j++;txn = NULL;E(mdb_txn_begin(env, NULL, 0, &txn));sprintf(sval, "%03x ", values[i]);if (RES(MDB_NOTFOUND, mdb_del(txn, dbi, &key, NULL))) {j--;mdb_txn_abort(txn);}else {E(mdb_txn_commit(txn));}}free(values);printf("Deleted %d values\n", j);E(mdb_env_stat(env, &mst));E(mdb_txn_begin(env, NULL, MDB_RDONLY, &txn));E(mdb_cursor_open(txn, dbi, &cursor));printf("Cursor next\n");while ((rc = mdb_cursor_get(cursor, &key, &data, MDB_NEXT)) == 0) {printf("key: %.*s, data: %.*s\n",(int)key.mv_size, (char *)key.mv_data,(int)data.mv_size, (char *)data.mv_data);}CHECK(rc == MDB_NOTFOUND, "mdb_cursor_get");printf("Cursor last\n");E(mdb_cursor_get(cursor, &key, &data, MDB_LAST));printf("key: %.*s, data: %.*s\n",(int)key.mv_size, (char *)key.mv_data,(int)data.mv_size, (char *)data.mv_data);printf("Cursor prev\n");while ((rc = mdb_cursor_get(cursor, &key, &data, MDB_PREV)) == 0) {printf("key: %.*s, data: %.*s\n",(int)key.mv_size, (char *)key.mv_data,(int)data.mv_size, (char *)data.mv_data);}CHECK(rc == MDB_NOTFOUND, "mdb_cursor_get");printf("Cursor last/prev\n");E(mdb_cursor_get(cursor, &key, &data, MDB_LAST));printf("key: %.*s, data: %.*s\n",(int)key.mv_size, (char *)key.mv_data,(int)data.mv_size, (char *)data.mv_data);E(mdb_cursor_get(cursor, &key, &data, MDB_PREV));printf("key: %.*s, data: %.*s\n",(int)key.mv_size, (char *)key.mv_data,(int)data.mv_size, (char *)data.mv_data);mdb_cursor_close(cursor);mdb_txn_abort(txn);printf("Deleting with cursor\n");E(mdb_txn_begin(env, NULL, 0, &txn));E(mdb_cursor_open(txn, dbi, &cur2));for (i = 0; i<50; i++) {if (RES(MDB_NOTFOUND, mdb_cursor_get(cur2, &key, &data, MDB_NEXT)))break;printf("key: %p %.*s, data: %p %.*s\n",key.mv_data, (int)key.mv_size, (char *)key.mv_data,data.mv_data, (int)data.mv_size, (char *)data.mv_data);E(mdb_del(txn, dbi, &key, NULL));}printf("Restarting cursor in txn\n");for (op = MDB_FIRST, i = 0; i <= 32; op = MDB_NEXT, i++) {if (RES(MDB_NOTFOUND, mdb_cursor_get(cur2, &key, &data, op)))break;printf("key: %p %.*s, data: %p %.*s\n",key.mv_data, (int)key.mv_size, (char *)key.mv_data,data.mv_data, (int)data.mv_size, (char *)data.mv_data);}mdb_cursor_close(cur2);E(mdb_txn_commit(txn));printf("Restarting cursor outside txn\n");E(mdb_txn_begin(env, NULL, 0, &txn));E(mdb_cursor_open(txn, dbi, &cursor));for (op = MDB_FIRST, i = 0; i <= 32; op = MDB_NEXT, i++) {if (RES(MDB_NOTFOUND, mdb_cursor_get(cursor, &key, &data, op)))break;printf("key: %p %.*s, data: %p %.*s\n",key.mv_data, (int)key.mv_size, (char *)key.mv_data,data.mv_data, (int)data.mv_size, (char *)data.mv_data);}mdb_cursor_close(cursor);mdb_txn_abort(txn);mdb_dbi_close(env, dbi);mdb_env_close(env);return 0;
}void ListMsg(const lm::helloworld& msg) {std::cout << msg.id() << std::endl;std::cout << msg.str() << std::endl;
}int test_ProtoBuf()
{//http://www.ibm.com/developerworks/cn/linux/l-cn-gpb///http://blog.163.com/jiang_tao_2010/blog/static/12112689020114305013458///http://www.cnblogs.com/dkblog/archive/2012/03/27/2419010.html// 1-->首先编写一个ml.helloworld.proto文件,内容如下:/*syntax = "proto2";package lm;message helloworld{required int32 id = 1; // IDrequired string str = 2; // stroptional int32 opt = 3; //optional field}*/// 2-->利用protoc.exe生成ml.helloworld.pb.h和ml.hellowrold.ph.cc// 3-->Writer,将把一个结构化数据写入磁盘,以便其他人来读取/*lm::helloworld msg1;msg1.set_id(101);msg1.set_str("hello");// Write the new address book back to disk. std::fstream output("./log", std::ios::out | std::ios::trunc | std::ios::binary);if (!msg1.SerializeToOstream(&output)) {std::cerr << "Failed to write msg." << std::endl;return -1;}*/// 4-->Reader,读取结构化数据,log文件lm::helloworld msg2;std::fstream input("./log", std::ios::in | std::ios::binary);if (!msg2.ParseFromIstream(&input)) {std::cerr << "Failed to parse address book." << std::endl;return -1;}ListMsg(msg2);return 0;
}#define H5FILE_NAME "E:/tmp/HDF5/SDS.h5"
#define DATASETNAME "IntArray"
#define NX 5 /* dataset dimensions */
#define NY 6
#define RANK 2int test_HDF5_write_HDF5_Data()
{hid_t file, dataset; /* file and dataset handles */hid_t datatype, dataspace; /* handles */hsize_t dimsf[2]; /* dataset dimensions */herr_t status;int data[NX][NY]; /* data to write */int i, j;//Data and output buffer initialization.for (j = 0; j < NX; j++)for (i = 0; i < NY; i++)data[j][i] = i + j + 100;//changed/** 0 1 2 3 4 5* 1 2 3 4 5 6* 2 3 4 5 6 7* 3 4 5 6 7 8* 4 5 6 7 8 9*//** Create a new file using H5F_ACC_TRUNC access,* default file creation properties, and default file* access properties.*/file = H5Fcreate(H5FILE_NAME, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);/** Describe the size of the array and create the data space for fixed* size dataset.*/dimsf[0] = NX;dimsf[1] = NY;dataspace = H5Screate_simple(RANK, dimsf, NULL);/** Define datatype for the data in the file.* We will store little endian INT numbers.*/datatype = H5Tcopy(H5T_NATIVE_INT);status = H5Tset_order(datatype, H5T_ORDER_LE);/** Create a new dataset within the file using defined dataspace and* datatype and default dataset creation properties.*/dataset = H5Dcreate2(file, DATASETNAME, datatype, dataspace, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);//Write the data to the dataset using default transfer properties.status = H5Dwrite(dataset, H5T_NATIVE_INT, H5S_ALL, H5S_ALL, H5P_DEFAULT, data);//Close/release resources.H5Sclose(dataspace);H5Tclose(datatype);H5Dclose(dataset);H5Fclose(file);return 0;
}#define NX_SUB 3 /* hyperslab dimensions */
#define NY_SUB 4
#define NX 7 /* output buffer dimensions */
#define NY 7
#define NZ 3
#define RANK 2
#define RANK_OUT 3int test_HDF5_read_HDF5_data()
{hid_t file, dataset; /* handles */hid_t datatype, dataspace;hid_t memspace;H5T_class_t t_class; /* data type class */H5T_order_t order; /* data order */size_t size; /** size of the data element* stored in file*/hsize_t dimsm[3]; /* memory space dimensions */hsize_t dims_out[2]; /* dataset dimensions */herr_t status;int data_out[NX][NY][NZ]; /* output buffer */hsize_t count[2]; /* size of the hyperslab in the file */hsize_t offset[2]; /* hyperslab offset in the file */hsize_t count_out[3]; /* size of the hyperslab in memory */hsize_t offset_out[3]; /* hyperslab offset in memory */int i, j, k, status_n, rank;for (j = 0; j < NX; j++) {for (i = 0; i < NY; i++) {for (k = 0; k < NZ; k++)data_out[j][i][k] = 0 - 1000;//changed}}/** Open the file and the dataset.*/file = H5Fopen(H5FILE_NAME, H5F_ACC_RDONLY, H5P_DEFAULT);dataset = H5Dopen2(file, DATASETNAME, H5P_DEFAULT);/** Get datatype and dataspace handles and then query* dataset class, order, size, rank and dimensions.*/datatype = H5Dget_type(dataset); /* datatype handle */t_class = H5Tget_class(datatype);if (t_class == H5T_INTEGER) printf("Data set has INTEGER type \n");order = H5Tget_order(datatype);if (order == H5T_ORDER_LE) printf("Little endian order \n");size = H5Tget_size(datatype);printf("Data size is %d \n", (int)size);dataspace = H5Dget_space(dataset); /* dataspace handle */rank = H5Sget_simple_extent_ndims(dataspace);status_n = H5Sget_simple_extent_dims(dataspace, dims_out, NULL);printf("rank %d, dimensions %lu x %lu \n", rank,(unsigned long)(dims_out[0]), (unsigned long)(dims_out[1]));/** Define hyperslab in the dataset.*/offset[0] = 1;offset[1] = 2;count[0] = NX_SUB;count[1] = NY_SUB;status = H5Sselect_hyperslab(dataspace, H5S_SELECT_SET, offset, NULL,count, NULL);/** Define the memory dataspace.*/dimsm[0] = NX;dimsm[1] = NY;dimsm[2] = NZ;memspace = H5Screate_simple(RANK_OUT, dimsm, NULL);/** Define memory hyperslab.*/offset_out[0] = 3;offset_out[1] = 0;offset_out[2] = 0;count_out[0] = NX_SUB;count_out[1] = NY_SUB;count_out[2] = 1;status = H5Sselect_hyperslab(memspace, H5S_SELECT_SET, offset_out, NULL,count_out, NULL);/** Read data from hyperslab in the file into the hyperslab in* memory and display.*/status = H5Dread(dataset, H5T_NATIVE_INT, memspace, dataspace,H5P_DEFAULT, data_out);for (j = 0; j < NX; j++) {for (i = 0; i < NY; i++) printf("%d ", data_out[j][i][0]);printf("\n");}/** 0 0 0 0 0 0 0* 0 0 0 0 0 0 0* 0 0 0 0 0 0 0* 3 4 5 6 0 0 0* 4 5 6 7 0 0 0* 5 6 7 8 0 0 0* 0 0 0 0 0 0 0*//** Close/release resources.*/H5Tclose(datatype);H5Dclose(dataset);H5Sclose(dataspace);H5Sclose(memspace);H5Fclose(file);return 0;
}int test_HDF5()
{//http://wenku.baidu.com/link?url=HDnqbrqqJ27GSvVGTcCbfM-bn5K2QCYxSlqTEtY_jwFvBVi3B97DK6s9qBUwXDjVgMHFQq-MLGSKcMKeGJkq87GF_8vchhsleRWISq9PwO3//http://baike.baidu.com/link?url=TqYZDUzu_XFMYa9XswMS1OVSyboWzu3RtK6L-DiOFZT6zugtXjBUIFa4QHerxZcSbPNuTO84BomEGgxpchWojK//http://www.docin.com/p-608918978.html// 1-->./examples/h5_write.c:This example writes data to the HDF5 filetest_HDF5_write_HDF5_Data();// 2-->./examples/h5_read.c:This example reads hyperslab from the SDS.h5 filetest_HDF5_read_HDF5_data();return 0;
}int test_Snappy()
{//http://baike.baidu.com/link?url=X8PCUvwS0MFJF5xS2DdzMrVDj9hNV8VsXL40W_jgiI1DeGNW5q5PsfEbL9RwUSrIilseenbFiulT1ceONYL5E_//exaples:./snappy_unittest.cc、snappy-test.cc//https://snappy.angeloflogic.com/cpp-tutorial/char* filename = "E:/tmp/snappy/fireworks.jpeg";size_t input_length = 200;snappy_status status;size_t output_length = snappy_max_compressed_length(input_length);char* output = (char*)malloc(output_length);status = snappy_compress(filename, input_length, output, &output_length);if (status != SNAPPY_OK) {std::cout << "snappy compress fail!" << std::endl;}free(output);size_t output_length1;snappy_status status1;status1 = snappy_uncompressed_length(filename, input_length, &output_length1);if (status != SNAPPY_OK) {std::cout << "get snappy uncompress length fail!" << std::endl;}char* output1 = (char*)malloc(output_length1);status1 = snappy_uncompress(filename, input_length, output1, &output_length1);if (status != SNAPPY_OK) {std::cout << "snappy uncompress fail!" << std::endl;}free(output1);return 0;
}GitHub: https://github.com/fengbingchun/Caffe_Test
相关文章:

漫画:5分钟了解什么是动态规划?
作者 | 调皮的阿广来源 | 视学算法(ID:z872561826)动态规划,英文是Dynamic Programming,简称DP,擅长解决“多阶段决策问题”,利用各个阶段阶段的递推关系,逐个确定每个阶段的最优决策…

小程序大转盘红包雨营销组件
前言 商城没几个营销活动能叫商城吗?所以就来几个组件吧,写的不好轻踩,对你有帮助记得给个小星星哦直接上链接github链接 运行例子 git clone https://github.com/sunnie1992/soul-weapp.git 微信开发者工具打开项目 营销组件 大转盘 "p…
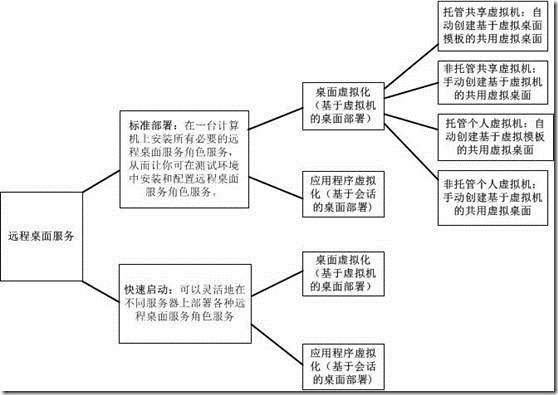
Windows Server 2012 RDS系列:虚拟桌面化(5)
概述:本次将系列地测试Windows Server 2012 远程桌面服务(RDS),将过程进行分享,总的感觉比2008 R2更简单了,体现着2012的自动化。2012的RDS部署有标准部署和快速启动两种,快速启动就是自动快速配…
里程碑式成果Faster RCNN复现难?我们试了一下 | 附完整代码
作者 | 已退逼乎 来源 | 知乎【导读】2019年以来,除各AI 大厂私有网络范围外,MaskRCNN,CascadeRCNN 成为了支撑很多业务得以开展的基础,而以 Faster RCNN 为基础去复现其他的检测网络既省时又省力,也算得上是里程碑性成…

【跃迁之路】【725天】程序员高效学习方法论探索系列(实验阶段482-2019.2.15)...
实验说明 从2017.10.6起,开启这个系列,目标只有一个:探索新的学习方法,实现跃迁式成长实验期2年(2017.10.06 - 2019.10.06)我将以自己为实验对象。我将开源我的学习方法,方法不断更新迭代&#…
C/C++各种数据类型转换汇总
以下是Windows/Linux系统中常用的C/C各种数据类型转换汇总:#ifndef FBC_MESSY_TEST_DATA_TYPE_CONVERT_HPP_ #define FBC_MESSY_TEST_DATA_TYPE_CONVERT_HPP_#include <stdio.h> #include <stdlib.h> #include <iostream> #include <string>…
ASP.NET技巧:两个截取字符串的实用方法
两个截取字符串的实用方法(超过一定长度自动换行)1/** <summary> 2 /// 截取字符串,不限制字符串长度 3 /// </summary> 4 /// <param name"str">待截取的字符串</param> 5 /…
吃瓜腾讯平均月薪7.27万后,微信又出大招
腾讯最新财报一出,喜提热搜!据腾讯第二季度财报显示:2019 年上半年腾讯有员工56310人,总薪酬成本为242.59亿元,腾讯员工平均半年薪为43.08万元。在第一季度里,腾讯员工平均季度薪资为21.27万元,…
回调函数在C/C++中的使用
回调函数就是一个通过函数指针调用的函数。假如把A函数的指针当作参数传给B函数,然后在B函数中通过A函数传进来的这个指针调用A函数,那么就是回调机制。A函数就是回调函数,而通常情况下,A函数是在系统符合你设定的条件下自动执行。使用回调函…
excel单元格加引号及逗号,转换为sql需要的样式
A1 B1BXQY001 ------> BXQY001,BXQY001 -----> BXQY001 在B1中输入公式: ""&A1&""&"," 在B2中输入公式: ""&A1&"" 去掉了后面的逗号。其实就是 " "&A1&…
Win7/Win8 系统下安装Oracle 10g 提示“程序异常终止,发生未知错误”的解决方法...
我的Oracle 10g版本是10.2.0.1.0,(10.1同理)选择高级安装,提示“程序异常终止,发生未知错误”。1.修改Oracle 10G\database\stage\prereq\db\refhost.xml当打开refhost.xml 后会发现有</SYSTEM> <CERTIFIED…
Caffe基础介绍
Caffe的全称应该是Convolutional Architecture for Fast Feature Embedding,它是一个清晰、高效的深度学习框架,它是开源的,核心语言是C,它支持命令行、Python和Matlab接口,它既可以在CPU上运行也可以在GPU上运行。它的…

飞桨博士会第三期来啦!中国深度学习技术俱乐部诚邀您加入
飞桨博士会是由百度开源深度学习平台飞桨(PaddlePaddle)发起的中国深度学习技术俱乐部,旨在打造深度学习核心开发者交流圈,助力会员拓展行业高端人脉、交流前沿技术。俱乐部为会员制,成员皆为博士生导师或博士…

canvas 拼图
效果 代码 <!DOCTYPE html> <html lang"zh_CN"> <head><meta charset"UTF-8"><title>拼图</title><script src"https://code.jquery.com/jquery-3.3.1.js"></script> </head> <body&g…
性能优化之Java(Android)代码优化
最新最准确内容建议直接访问原文:性能优化之Java(Android)代码优化 本文为Android性能优化的第三篇——Java(Android)代码优化。主要介绍Java代码中性能优化方式及网络优化,包括缓存、异步、延迟、数据存储、算法、JNI、逻辑等优化方式。(时间仓促&#…

1小时上手MaskRCNN·Keras开源实战 | 深度应用
作者 | 小宋是呢来源 | CSDN博客0. 前言介绍开源地址:https://github.com/matterport/Mask_RCNN个人主页:http://www.yansongsong.cn/MaskRCNN 是何恺明基于以往的 faster rcnn 架构提出的新的卷积网络,一举完成了 object instance segmentat…

MNIST数据库介绍及转换
MNIST数据库介绍:MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集。它是NIST数据库的一个子集。MNIST数据库官方网址为:http://yann.lecun.com/exdb/mnist/ ,也可以在windows下直接下载,train-im…
PostgreSQL学习笔记(1)
安装psql brew install postgresql 启动服务 brew services start postgresql 使用psql进入控制台,报错: psql: FATAL: database "<user>" does not exist 看来是没有给我的当前用户创建数据库,使用下面命令进入名为templat…

怎样使一个Android应用不被杀死?(整理)
2019独角兽企业重金招聘Python工程师标准>>> 方法 : 对于一个service,可以首先把它设为在前台运行: public void MyService.onCreate() { super.onCreate(); Notification notification new Notification(android.R.drawable.my_…

Ubuntu 14.04 64位机上用Caffe+MNIST训练Lenet网络操作步骤
1. 将终端定位到Caffe根目录; 2. 下载MNIST数据库并解压缩:$ ./data/mnist/get_mnist.sh 3. 将其转换成Lmdb数据库格式:$ ./examples/mnist/create_mnist.sh 执行完此shell脚本后,会在./examples/mnist下增加两个新…
IJCAI 2019:中国团队录取论文超三成,北大、南大榜上有名
作者 | 神经小姐姐来源 | HyperAI超神经( ID: HyperAI )【导读】AI 顶会 IJCAI 2019 已于 8 月 16 日圆满落幕。在连续 7 天的技术盛会中,与会者在工作坊了解了 AI 技术在各个领域的应用场景,聆听了 AI 界前辈的主题演讲,还有机会…
适合小小白的完整建设流程
时常有中小企业建站的客户问到我要自己建网站,应该怎么开始?建站有一定的技术门槛,首先要明白建站要做的哪些事情,里面有哪些坑,把流程弄清楚了才能避免入坑,半途而废!下面总结了建站的流程还有…
ios项目文件结构 目录的整理
2019独角兽企业重金招聘Python工程师标准>>> /<ProjectName>/Shared/Application # App delegate and related files/Controllers # Base view controllers/Models # Models, Core Data schema etc/Views # Shared views/Libr…

重磅!全球首个可视化联邦学习产品与联邦pipeline生产服务上线
【导读】作为全球首个联邦学习工业级技术框架,FATE支持联邦学习架构体系与各种机器学习算法的安全计算,实现了基于同态加密和多方计算(MPC)的安全计算协议,能够帮助多个组织机构在符合数据安全和政府法规前提下&#x…
SpringBoot之集成swagger2
maven配置 <dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.5.0</version> </dependency> <dependency><groupId>io.springfox</groupId><artifact…
Windows Caffe中MNIST数据格式转换实现
Caffe源码中src/caffe/caffe/examples/mnist/convert_mnist_data.cpp提供的实现代码并不能直接在Windows下运行,这里在源码的基础上进行了改写,使其可以直接在Windows 64位上直接运行,改写代码如下:#include "stdafx.h"…

关于less在DW中高亮显示问题
首先, 找到DW 安装目录。 Adobe Dreamweaver CS5.5\configuration\DocumentTypes 中的,MMDocumentTypes.xml 这个文件,然后用记事本打开,查找CSS 把 CSS 后边加上,less 然后到。C:\Users\Administrator\AppData\Roamin…
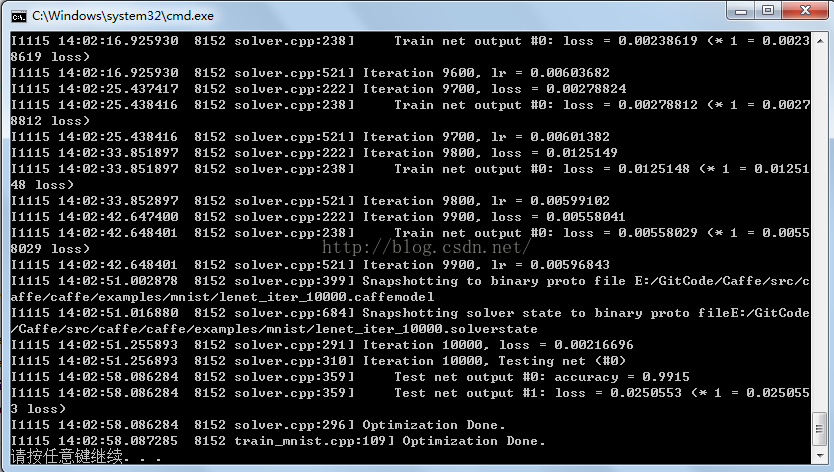
Windows7 64bit VS2013 Caffe train MNIST操作步骤
1. 使用http://blog.csdn.net/fengbingchun/article/details/47905907中生成的Caffe静态库; 2. 使用http://blog.csdn.net/fengbingchun/article/details/49794453中生成的LMDB数据库文件; 3. 新建一个train_mnist控制台工程&#…

NLP机器翻译深度学习实战课程基础 | 深度应用
作者 | 小宋是呢来源 | CSDN博客0.前言深度学习用的有一年多了,最近开始 NLP 自然处理方面的研发。刚好趁着这个机会写一系列 NLP 机器翻译深度学习实战课程。本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:…
个人站点渲染和跳转过滤功能
核心逻辑:在url里加入正则,匹配分类、标签、年月日和其后面的参数,在视图函数接收这些参数,然后进行过滤。 urls.py # 个人站点的跳转 re_path(r^(?P<username>\w)/(?P<condition>tag|category|archive)/(?P<pa…