Caffe源码中Net文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/net.hpp文件的内容:
1. include文件:
(1)、<caffe/blob.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/59106613
(2)、<caffe/common.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/54955236
(3)、<caffe/layer.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/60871052
(4)、<caffe/proto/caffe.pb.h>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/55267162
(5)、<caffe/layer_factory.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/54310956
2. 类Net:
通过合成和自动微分,网络同时定义了一个函数和其对应的梯度。通过合成各层的输出来计算这个函数,来执行给定的任务,并通过合成各层的向后传播过程来计算来自损失函数的梯度,从而学习任务。Caffe模型是端到端的机器学习引擎。
Net是由一系列层组成的有向五环(DAG)计算图,Caffe保留了计算图中所有的中间值以确保前向和反向迭代的准确性。一个典型的Net开始于data layer------从磁盘中加载数据,终止于loss layer------计算分类和重构这些任务的目标函数。
Net由一系列层和它们之间的相互连接构成,用的是一种文本建模语言(protobuf)。Net是通过protobuf文件来描述整个Net是怎么由layer组成的。
Caffe中网络的构建与设备无关。网络构建完之后,通过设置Caffe::mode()函数中的Caffe::set_mode()即可实现在CPU或GPU上的运行。CPU与GPU无缝切换并且独立于模型定义。
前传(forward)过程为给定的待推断的输入计算输出。在前传过程中,Caffe组合每一层的计算以得到整个模型的计算”函数”。本过程自底向上进行。
反传(backward)过程根据损失来计算梯度从而进行学习。在反传过程中,Caffe通过自动求导并反向组合每一层的梯度来计算整个网络的梯度。这就是反传过程的本质。本过程自顶向下进行。
反传过程以损失开始,然后根据输出计算梯度。根据链式准则,逐层计算出模型其余部分的梯度。有参数的层,会在反传过程中根据参数计算梯度。
只要定义好了模型,Caffe中前传和反传的计算就可以立即进行,Caffe已经准备好了前传和反传的实现方法。
实现方法:
(1)、Net::Forward()和Net::Backward()方法实现网络的前传和反传,而Layer::Forward()和Layer::Backward()计算每一层的前传和后传。
(2)、每一层都有forward_{cpu,gpu}()和backward_{cpu,gpu}方法来适应不同的计算模式。由于条件限制或者为了使用便利,一个层可能仅实现了CPU或者GPU模式。
与大多数的机器学习模型一样,在Caffe中,学习是由一个损失函数驱动的(通常也被称为误差、代价或者目标函数)。一个损失函数通过将参数集(即当前的网络权值)映射到一个可以标识这些参数”不良程度”的标量值来学习目标。因此,学习的目的是找到一个网络权重的集合,使得损失函数最小。
在Caffe中,损失是通过网络的前向计算得到的。每一层由一系列的输入blobs(bottom),然后产生一系列的输出blobs(top)。这些层的某些输出可以用来作为损失函数。典型的一对多分类任务的损失函数是softMaxWithLoss函数。
Loss weights:对于含有多个损失层的网络(例如,一个网络使用一个softMaxWithLoss输入分类并使用EuclideanLoss层进行重构),损失权值可以被用来指定它们之间的相对重要性。
按照惯例,有着Loss后缀的Caffe层对损失函数有贡献,其它层被假定仅仅用于中间计算。然而,通过在层定义中添加一个loss_weight:<float>字段到由该层的top blob,任何层都可以作为一个loss。对于带后缀Loss的层来说,其对于该层的第一个top blob含有一个隐式的loss_weight:1;其它层对应于所有top blob有一个隐式的loss_weight: 0。
然而,任何可以反向传播的层,可允许给予一个非0的loss_weight,例如,如果需要,对网络的某些中间层所产生的激活进行正则化。对于具有相关非0损失的非单输出,损失函数可以通过对所有blob求和来进行简单地计算。
那么,在Caffe中最终的损失函数可以通过对整个网络中所有的权值损失进行求和计算获得。
为了创建一个Caffe模型,需要在一个protobuf(.prototxt)文件中定义模型的结构。在Caffe中,层和相应的参数都定义在caffe.proto文件里。
注:以上关于Net内容的介绍主要摘自由CaffeCN社区翻译的《Caffe官方教程中译本》。
<caffe/net.hpp>文件的详细介绍如下:
#ifndef CAFFE_NET_HPP_
#define CAFFE_NET_HPP_#include <map>
#include <set>
#include <string>
#include <utility>
#include <vector>#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/layer_factory.hpp"namespace caffe {// 在图论中,如果一个有向图从任意顶点出发无法经过若干条边回到该点,则这个图是一个有向无环图(DAG图)
/*** @brief Connects Layer%s together into a directed acyclic graph (DAG)* specified by a NetParameter.** TODO(dox): more thorough description.*/
//
template <typename Dtype>
class Net {public:
// 显示构造函数,内部调用Init函数explicit Net(const NetParameter& param, const Net* root_net = NULL);explicit Net(const string& param_file, Phase phase, const Net* root_net = NULL);
// 虚析构函数virtual ~Net() {}/// @brief Initialize a network with a NetParameter.
// Net初始化:创建blobs和layers以搭建整个网络DAG图,以及调用layer的SetUp函数,
// 初始化时也会做另一些记录,例如确认整个网络结构的正确与否等,
// 另外,初始化期间,Net会打印其初始化日志到INFO信息中void Init(const NetParameter& param);/*** @brief Run Forward with the input Blob%s already fed separately.** You can get the input blobs using input_blobs().*/
// 前向传播,以下相关的前向传播函数,内部最终均会调用ForwardFromTo函数const vector<Blob<Dtype>*>& ForwardPrefilled(Dtype* loss = NULL);/*** The From and To variants of Forward and Backward operate on the* (topological) ordering by which the net is specified. For general DAG* networks, note that (1) computing from one layer to another might entail* extra computation on unrelated branches, and (2) computation starting in* the middle may be incorrect if all of the layers of a fan-in are not* included.*/Dtype ForwardFromTo(int start, int end);Dtype ForwardFrom(int start);Dtype ForwardTo(int end);/// @brief Run forward using a set of bottom blobs, and return the result.const vector<Blob<Dtype>*>& Forward(const vector<Blob<Dtype>* > & bottom, Dtype* loss = NULL);/*** @brief Run forward using a serialized BlobProtoVector and return the* result as a serialized BlobProtoVector*/string Forward(const string& input_blob_protos, Dtype* loss = NULL);/*** @brief Zeroes out the diffs of all net parameters.* Should be run before Backward.*/
// 对Net中的所有diff_数据清零void ClearParamDiffs();/*** The network backward should take no input and output, since it solely* computes the gradient w.r.t the parameters, and the data has already been* provided during the forward pass.*/
// 反向传播,以下相关的反向传播函数,内部最终均会调用BackwardFromTo函数void Backward();void BackwardFromTo(int start, int end);void BackwardFrom(int start);void BackwardTo(int end);/*** @brief Reshape all layers from bottom to top.** This is useful to propagate changes to layer sizes without running* a forward pass, e.g. to compute output feature size.*/
// 调整layes shapevoid Reshape();// 前向反向传播Dtype ForwardBackward(const vector<Blob<Dtype>* > & bottom) {Dtype loss;Forward(bottom, &loss);Backward();return loss;}/// @brief Updates the network weights based on the diff values computed.
// 更新Net权值和偏置void Update();/*** @brief Shares weight data of owner blobs with shared blobs.** Note: this is called by Net::Init, and thus should normally not be* called manually.*/
// 共享权值和偏置数据void ShareWeights();/*** @brief For an already initialized net, implicitly copies (i.e., using no* additional memory) the pre-trained layers from another Net.*/
// 从另一个Net拷贝train layersvoid ShareTrainedLayersWith(const Net* other);// For an already initialized net, CopyTrainedLayersFrom() copies the already// trained layers from another net parameter instance./*** @brief For an already initialized net, copies the pre-trained layers from* another Net.*/
// 从另一个Net拷贝train layers,加载已训练好的模型void CopyTrainedLayersFrom(const NetParameter& param);void CopyTrainedLayersFrom(const string trained_filename);void CopyTrainedLayersFromBinaryProto(const string trained_filename);void CopyTrainedLayersFromHDF5(const string trained_filename);/// @brief Writes the net to a proto.
// 写Net到NetParametervoid ToProto(NetParameter* param, bool write_diff = false) const;/// @brief Writes the net to an HDF5 file.
// 写Net weights到HDF5文件void ToHDF5(const string& filename, bool write_diff = false) const;/// @brief returns the network name.
// 获得Net名inline const string& name() const { return name_; }/// @brief returns the layer names
// 获得所有layer名inline const vector<string>& layer_names() const { return layer_names_; }/// @brief returns the blob names
// 获得blob名inline const vector<string>& blob_names() const { return blob_names_; }/// @brief returns the blobs
// 获得blobinline const vector<shared_ptr<Blob<Dtype> > >& blobs() const { return blobs_; }/// @brief returns the layers
// 获得layerinline const vector<shared_ptr<Layer<Dtype> > >& layers() const { return layers_; }/// @brief returns the phase: TRAIN or TEST
// 获得Net phase状态:train or testinline Phase phase() const { return phase_; }/*** @brief returns the bottom vecs for each layer -- usually you won't* need this unless you do per-layer checks such as gradients.*/
// 获得每一个layer的bottom vectorinline const vector<vector<Blob<Dtype>*> >& bottom_vecs() const { return bottom_vecs_; }/*** @brief returns the top vecs for each layer -- usually you won't* need this unless you do per-layer checks such as gradients.*/
// 获得每一个layer的top vectorinline const vector<vector<Blob<Dtype>*> >& top_vecs() const { return top_vecs_; }inline const vector<vector<bool> >& bottom_need_backward() const { return bottom_need_backward_; }inline const vector<Dtype>& blob_loss_weights() const { return blob_loss_weights_; }inline const vector<bool>& layer_need_backward() const { return layer_need_backward_; }/// @brief returns the parameters
// 获得各种参数值inline const vector<shared_ptr<Blob<Dtype> > >& params() const { return params_; }inline const vector<Blob<Dtype>*>& learnable_params() const { return learnable_params_; }/// @brief returns the learnable parameter learning rate multipliersinline const vector<float>& params_lr() const { return params_lr_; }inline const vector<bool>& has_params_lr() const { return has_params_lr_; }/// @brief returns the learnable parameter decay multipliersinline const vector<float>& params_weight_decay() const { return params_weight_decay_; }inline const vector<bool>& has_params_decay() const { return has_params_decay_; }const map<string, int>& param_names_index() const { return param_names_index_; }inline const vector<int>& param_owners() const { return param_owners_; }/// @brief Input and output blob numbers
// input blob数目inline int num_inputs() const { return net_input_blobs_.size(); }
// output blob数目inline int num_outputs() const { return net_output_blobs_.size(); }inline const vector<Blob<Dtype>*>& input_blobs() const { return net_input_blobs_; }inline const vector<Blob<Dtype>*>& output_blobs() const { return net_output_blobs_; }inline const vector<int>& input_blob_indices() const { return net_input_blob_indices_; }inline const vector<int>& output_blob_indices() const { return net_output_blob_indices_; }bool has_blob(const string& blob_name) const;const shared_ptr<Blob<Dtype> > blob_by_name(const string& blob_name) const;bool has_layer(const string& layer_name) const;const shared_ptr<Layer<Dtype> > layer_by_name(const string& layer_name) const;// 设置是否显示debug infovoid set_debug_info(const bool value) { debug_info_ = value; }// Helpers for Init./*** @brief Remove layers that the user specified should be excluded given the current* phase, level, and stage.*/
// 移除指定的layersstatic void FilterNet(const NetParameter& param, NetParameter* param_filtered);/// @brief return whether NetState state meets NetStateRule rulestatic bool StateMeetsRule(const NetState& state, const NetStateRule& rule, const string& layer_name);protected:// Helpers for Init./// @brief Append a new input or top blob to the net.
// 追加top blobvoid AppendTop(const NetParameter& param, const int layer_id,const int top_id, set<string>* available_blobs,map<string, int>* blob_name_to_idx);/// @brief Append a new bottom blob to the net.
// 追加bottom blobint AppendBottom(const NetParameter& param, const int layer_id,const int bottom_id, set<string>* available_blobs,map<string, int>* blob_name_to_idx);/// @brief Append a new parameter blob to the net.
// 追加blob参数void AppendParam(const NetParameter& param, const int layer_id, const int param_id);// 显示debug info/// @brief Helper for displaying debug info in Forward about input Blobs.void InputDebugInfo(const int layer_id);/// @brief Helper for displaying debug info in Forward.void ForwardDebugInfo(const int layer_id);/// @brief Helper for displaying debug info in Backward.void BackwardDebugInfo(const int layer_id);/// @brief Helper for displaying debug info in Update.void UpdateDebugInfo(const int param_id);// Caffe中类的成员变量名都带有后缀"_",这样就容易区分临时变量和类成员变量/// @brief The network namestring name_; // Net名/// @brief The phase: TRAIN or TESTPhase phase_; // Net Phase状态:train or test/// @brief Individual layers in the netvector<shared_ptr<Layer<Dtype> > > layers_; // layersvector<string> layer_names_; // layers名map<string, int> layer_names_index_; // layers 索引vector<bool> layer_need_backward_; // 指定layers是否需要backward/// @brief the blobs storing intermediate results between the layer.vector<shared_ptr<Blob<Dtype> > > blobs_; // 存储每一个layer产生的中间结果vector<string> blob_names_; // blobs名map<string, int> blob_names_index_; // blobs 索引vector<bool> blob_need_backward_; // 指定blobs是否需要backward/// bottom_vecs stores the vectors containing the input for each layer./// They don't actually host the blobs (blobs_ does), so we simply store pointers.vector<vector<Blob<Dtype>*> > bottom_vecs_; // 存储每一个layer input bottom blobs 指针vector<vector<int> > bottom_id_vecs_; // 存储每一个bottom blobs idvector<vector<bool> > bottom_need_backward_; // 指定bottom blobs是否需要backward/// top_vecs stores the vectors containing the output for each layervector<vector<Blob<Dtype>*> > top_vecs_; // 存储每一个layer output top blobs 指针vector<vector<int> > top_id_vecs_; // 存储每一个layer output top blobs id/// Vector of weight in the loss (or objective) function of each net blob,/// indexed by blob_id.vector<Dtype> blob_loss_weights_; // layer 的loss函数值vector<vector<int> > param_id_vecs_; // vector<int> param_owners_;vector<string> param_display_names_;vector<pair<int, int> > param_layer_indices_;map<string, int> param_names_index_;/// blob indices for the input and the output of the netvector<int> net_input_blob_indices_;vector<int> net_output_blob_indices_;vector<Blob<Dtype>*> net_input_blobs_;vector<Blob<Dtype>*> net_output_blobs_;/// The parameters in the network.vector<shared_ptr<Blob<Dtype> > > params_; // vector<Blob<Dtype>*> learnable_params_;/*** The mapping from params_ -> learnable_params_: we have* learnable_param_ids_.size() == params_.size(),* and learnable_params_[learnable_param_ids_[i]] == params_[i].get()* if and only if params_[i] is an "owner"; otherwise, params_[i] is a sharer* and learnable_params_[learnable_param_ids_[i]] gives its owner.*/vector<int> learnable_param_ids_;/// the learning rate multipliers for learnable_params_vector<float> params_lr_;vector<bool> has_params_lr_;/// the weight decay multipliers for learnable_params_vector<float> params_weight_decay_;vector<bool> has_params_decay_;/// The bytes of memory used by this netsize_t memory_used_;/// Whether to compute and display debug info for the net.bool debug_info_; // 是否显示debug info/// The root net that actually holds the shared layers in data parallelismconst Net* const root_net_;// 禁止使用Net类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(Net);
};} // namespace caffe#endif // CAFFE_NET_HPP_message NetParameter { // Net参数optional string name = 1; // consider giving the network a name,Net名// The input blobs to the network.repeated string input = 3; // Net的输入blobs// The shape of the input blobs.repeated BlobShape input_shape = 8; // 输入blobs的shape// 4D input dimensions -- deprecated. Use "shape" instead.// If specified, for each input blob there should be four// values specifying the num, channels, height and width of the input blob.// Thus, there should be a total of (4 * #input) numbers.repeated int32 input_dim = 4; // 输入blobs的维度,已被废弃,推荐用BlobShape代替// Whether the network will force every layer to carry out backward operation.// If set False, then whether to carry out backward is determined// automatically according to the net structure and learning rates.optional bool force_backward = 5 [default = false]; // 是否每一层都需要执行反向操作// The current "state" of the network, including the phase, level, and stage.// Some layers may be included/excluded depending on this state and the states// specified in the layers' include and exclude fields.optional NetState state = 6; // Net三种状态:Phase、level、stage// Print debugging information about results while running Net::Forward,// Net::Backward, and Net::Update.optional bool debug_info = 7 [default = false]; // 是否打印Net的前向、反向、更新的结果// The layers that make up the net. Each of their configurations, including// connectivity and behavior, is specified as a LayerParameter.repeated LayerParameter layer = 100; // ID 100 so layers are printed last. layer参数// DEPRECATED: use 'layer' instead.repeated V1LayerParameter layers = 2; // 已被废弃,用LayerParameter代替
}#include "funset.hpp"
#include <string>
#include <vector>
#include <map>
#include "common.hpp"int test_caffe_net2()
{caffe::Caffe::set_mode(caffe::Caffe::CPU); // set run caffe mode// reference: caffe/src/caffe/test/test_net.cppstd::string prototxt{ "E:/GitCode/Caffe_Test/test_data/model/test_net_8.prototxt" };caffe::Phase phase = caffe::Phase::TRAIN;// 1. Net(const string& param_file, Phase phase, const Net* root_net = NULL)boost::shared_ptr<caffe::Net<float>> net(new caffe::Net<float>(prototxt, phase, nullptr));//caffe::Caffe::set_random_seed(1701);{std::vector<caffe::Blob<float>*> bottom;// 2. Dtype ForwardBackward(const vector<Blob<Dtype>* > & bottom)float loss = net->ForwardBackward(bottom);fprintf(stderr, "loss: %f\n", loss);}{// 3. Dtype ForwardFromTo(int start, int end)float loss = net->ForwardFromTo(0, net->layers().size() - 1);// 4. void BackwardFromTo(int start, int end)net->BackwardFromTo(net->layers().size() - 1, 0);fprintf(stderr, "loss: %f\n", loss);}{// 5. Dtype ForwardTo(int end)float loss = net->ForwardTo(net->layers().size() - 2);// 6. void BackwardFrom(int start)net->BackwardFrom(net->layers().size() - 2);fprintf(stderr, "loss: %f\n", loss);}{// 7. Dtype ForwardFrom(int start)float loss = net->ForwardFrom(1);// 8. void BackwardTo(int end)net->BackwardTo(1);fprintf(stderr, "loss: %f\n", loss);}{// 9. vector<Blob<Dtype>*>& ForwardPrefilled(Dtype* loss = NULL)float loss;std::vector<caffe::Blob<float>*> net_output_blobs = net->ForwardPrefilled(&loss);// 10. void Backward()net->Backward();fprintf(stderr, "net output blobs size: %d; loss: %f\n", net_output_blobs.size(), loss);}{// 11. string Forward(const string& input_blob_protos, Dtype* loss = NULL)std::string input_blob_protos{ " " };float loss;std::string output = net->Forward(input_blob_protos, &loss);net->Backward();fprintf(stderr, "output string: %s; loss: %f\n", output.c_str(), loss);}{// 12. vector<Blob<Dtype>*>& Forward(const vector<Blob<Dtype>* > & bottom, Dtype* loss = NULL)std::vector<caffe::Blob<float>*> bottom;float loss;std::vector<caffe::Blob<float>*> net_output_blobs = net->Forward(bottom, &loss);net->Backward();fprintf(stderr, "net output blobs size: %d; loss: %f\n", net_output_blobs.size(), loss);}// 13. void ShareWeights()net->ShareWeights();// 14. void Update()net->Update();// 15. void Reshape()net->Reshape();// 16. void ClearParamDiffs()net->ClearParamDiffs();// 17. void CopyTrainedLayersFrom(const NetParameter& param)caffe::NetParameter net_param;net->ToProto(&net_param, false);net->CopyTrainedLayersFrom(net_param);// 加载已训练好的模型// 18. void CopyTrainedLayersFrom(const string trained_filename)std::string trained_filename{ " " };//net->CopyTrainedLayersFrom(trained_filename);// 19. void CopyTrainedLayersFromBinaryProto(const string trained_filename)//net->CopyTrainedLayersFromBinaryProto(trained_filename);// 20. void CopyTrainedLayersFromHDF5(const string trained_filename)//net->CopyTrainedLayersFromHDF5(trained_filename);// 21. void ShareTrainedLayersWith(const Net* other)caffe::Net<float> net1(prototxt, phase, nullptr);net->ShareTrainedLayersWith(&net1);// 22. static void FilterNet(const NetParameter& param, NetParameter* param_filtered)caffe::NetParameter param1, param2;net->FilterNet(param1, ¶m2);// 23. static bool StateMeetsRule(const NetState& state, const NetStateRule& rule, const string& layer_name)const caffe::NetState state;const caffe::NetStateRule rule;const std::string layer_name;bool ret = net->StateMeetsRule(state, rule, layer_name);fprintf(stderr, "state meet rule: %d\n", ret);return 0;
}int test_caffe_net1()
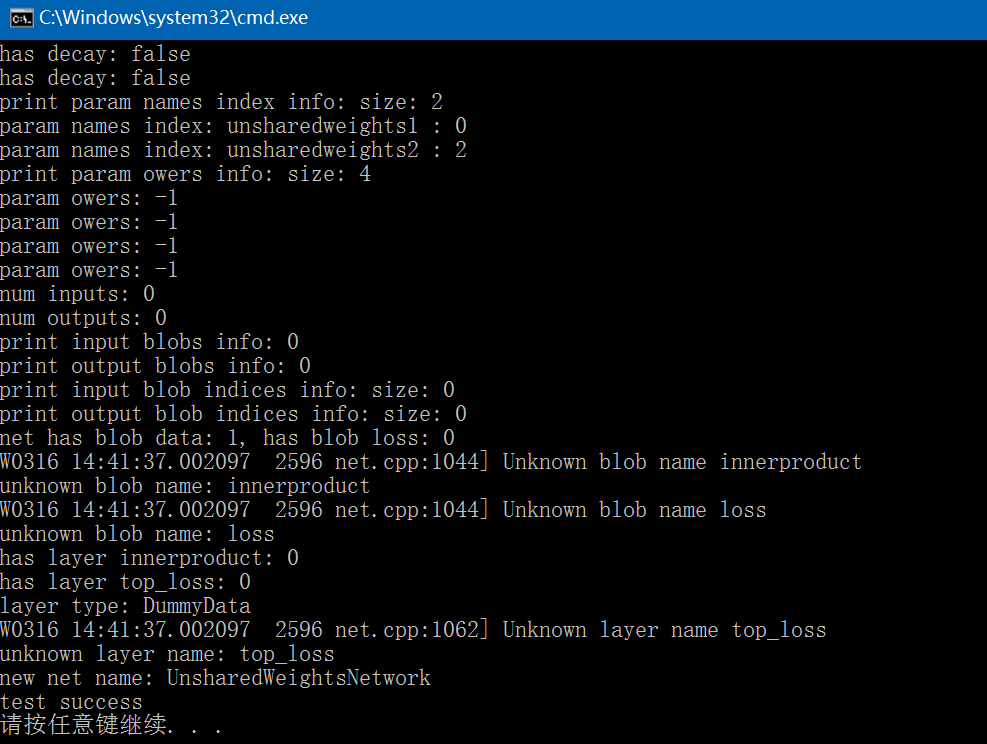
{caffe::Caffe::set_mode(caffe::Caffe::CPU); // set run caffe mode// reference: caffe/src/caffe/test/test_net.cppstd::string prototxt{"E:/GitCode/Caffe_Test/test_data/model/test_net_8.prototxt"}; // 1~8caffe::NetParameter param;caffe::ReadNetParamsFromTextFileOrDie(prototxt, ¶m);// 1. Net(const NetParameter& param, const Net* root_net = NULL)boost::shared_ptr<caffe::Net<float>> net(new caffe::Net<float>(param, nullptr));// 2. const string& name()std::string name = net->name();fprintf(stderr, "Net name: %s\n", name.c_str());// 3. const vector<string>& layer_names()std::vector<std::string> layer_names = net->layer_names();fprintf(stderr, "print all layer names: layer size: %d\n", layer_names.size());for (auto layer_name : layer_names) {fprintf(stderr, " %s\n", layer_name.c_str());}// 4. const vector<string>& blob_names()std::vector<std::string> blob_names = net->blob_names();fprintf(stderr, "print all blob names: blob size: %d\n", blob_names.size());for (auto blob_name : blob_names) {fprintf(stderr, " %s\n", blob_name.c_str());}// 5. const vector<shared_ptr<Blob<Dtype> > >& blobs()std::vector<boost::shared_ptr<caffe::Blob<float>>> blobs = net->blobs();fprintf(stderr, "print all blobs dim: blob size: %d\n", blobs.size());for (auto blob : blobs) {std::vector<int> shape = blob->shape();fprintf(stderr, "blob dim: %d, ", shape.size());for (auto value : shape) {fprintf(stderr, " %d ", value);}fprintf(stderr, "\n");}// 6. const vector<shared_ptr<Layer<Dtype> > >& layers()std::vector<boost::shared_ptr<caffe::Layer<float>>> layers = net->layers();fprintf(stderr, "print all layers bottom and top blobs num: layer size: %d\n", layers.size());for (const auto layer : layers) {fprintf(stderr, "layer type: %s, bottom blob num: %d, top blob num: %d\n",layer->type(), layer->ExactNumBottomBlobs(), layer->ExactNumTopBlobs());}// 7. Phase phase()caffe::Phase phase = net->phase();fprintf(stderr, "net phase: %d\n", phase);// 8. const vector<vector<Blob<Dtype>*> >& bottom_vecs()std::vector<std::vector<caffe::Blob<float>*>> bottom_vecs = net->bottom_vecs();fprintf(stderr, "print layer bottom blob: layer size: %d\n", bottom_vecs.size());for (auto layer : bottom_vecs) {for (auto blob : layer) {fprintf(stderr, "layer blob shape: %s\n", (blob->shape_string()).c_str());}}// 9. const vector<vector<Blob<Dtype>*> >& top_vecs()std::vector<std::vector<caffe::Blob<float>*>> top_vecs = net->top_vecs();fprintf(stderr, "print layer top blol: layer size: %d\n", top_vecs.size());for (auto layer : top_vecs) {for (const auto blob : layer) {fprintf(stderr, "layer top shape: %s\n", (blob->shape_string()).c_str());}}// 10. const vector<vector<bool> >& bottom_need_backward()std::vector<std::vector<bool>> bottom_need_backward = net->bottom_need_backward();fprintf(stderr, "print bottom need backward info: layer size: %d\n", bottom_need_backward.size());for (auto layer : bottom_need_backward) {for (auto flag : layer) {fprintf(stderr, " %s ", flag ? "true" : "false");}fprintf(stderr, "\n");}fprintf(stderr, "\n");// 11. const vector<Dtype>& blob_loss_weights()std::vector<float> blob_loss_weights = net->blob_loss_weights();fprintf(stderr, "print blob loss weights: blob size: %d\n", blob_loss_weights.size());for (auto weight : blob_loss_weights) {fprintf(stderr, "weight: %f\n", weight);}// 12. const vector<bool>& layer_need_backward()std::vector<bool> layer_need_backward = net->layer_need_backward();fprintf(stderr, "print layer need backward: layer size: %d\n", layer_need_backward.size());for (auto flag : layer_need_backward) {fprintf(stderr, "layer need backward: %s\n", flag ? "true" : "false");}// 13. const vector<shared_ptr<Blob<Dtype> > >& params()std::vector<boost::shared_ptr<caffe::Blob<float>>> params = net->params();fprintf(stderr, "print net params info: blob size: %d\n", params.size());for (auto blob : params) {fprintf(stderr, "blob shape: %s\n", blob->shape_string().c_str());}// 14. const vector<Blob<Dtype>*>& learnable_params()std::vector<caffe::Blob<float>*> learnable_params = net->learnable_params();fprintf(stderr, "print learnable params info: blob size: %d\n", learnable_params.size());for (const auto blob : learnable_params) {fprintf(stderr, "blob shape: %s\n", blob->shape_string().c_str());}// 15. const vector<float>& params_lr()std::vector<float> params_lr = net->params_lr();fprintf(stderr, "print learnable rate info: size: %d\n", params_lr.size());for (auto value : params_lr) {fprintf(stderr, "learnable rate: %f\n", value);}// 16. const vector<bool>& has_params_lr()std::vector<bool> has_params_lr = net->has_params_lr();fprintf(stderr, "print has learnable rate info: size: %d\n", has_params_lr.size());for (auto flag : has_params_lr) {fprintf(stderr, "has learnable rate: %s\n", flag ? "true" : "false");}// 17. const vector<float>& params_weight_decay()std::vector<float> params_weight_decay = net->params_weight_decay();fprintf(stderr, "print weight decay info: size: %d\n", params_weight_decay.size());for (auto value : params) {fprintf(stderr, "weight decay: %f\n", value);}// 18. const vector<bool>& has_params_decay()std::vector<bool> has_params_decay = net->has_params_decay();fprintf(stderr, "print has decay info: size: %d\n", has_params_decay.size());for (auto value : has_params_decay) {fprintf(stderr, "has decay: %s\n", value ? "true" : "false");}// 19. const map<string, int>& param_names_index()const std::map<std::string, int> param_names_index = net->param_names_index();fprintf(stderr, "print param names index info: size: %d\n", param_names_index.size());auto it = param_names_index.begin();while (it != param_names_index.end()) {fprintf(stderr, "param names index: %s : %d\n", it->first.c_str(), it->second);++it;}// 20. const vector<int>& param_owners()std::vector<int> param_owers = net->param_owners();fprintf(stderr, "print param owers info: size: %d\n", param_owers.size());for (auto value : param_owers) {fprintf(stderr, "param owers: %d\n", value);}// 21. int num_inputs() constint num_inputs = net->num_inputs();fprintf(stderr, "num inputs: %d\n", num_inputs);// 22. int num_outputs() constint num_outputs = net->num_outputs();fprintf(stderr, "num outputs: %d\n", num_outputs);// 23. const vector<Blob<Dtype>*>& input_blobs()const std::vector<caffe::Blob<float>*> input_blobs = net->input_blobs();fprintf(stderr, "print input blobs info: %d\n", input_blobs.size());for (auto blob : input_blobs) {fprintf(stderr, "input blob shape: %s\n", blob->shape_string().c_str());}// 24. const vector<Blob<Dtype>*>& output_blobs()const std::vector<caffe::Blob<float>*> output_blobs = net->output_blobs();fprintf(stderr, "print output blobs info: %d\n", output_blobs.size());for (auto blob : output_blobs) {fprintf(stderr, "output blob shape: %s\n", blob->shape_string().c_str());}// 25. const vector<int>& input_blob_indices()std::vector<int> input_blob_indices = net->input_blob_indices();fprintf(stderr, "print input blob indices info: size: %d\n", input_blob_indices.size());for (auto value : input_blob_indices) {fprintf(stderr, "input blob indices: %d\n", value);}// 26. const vector<int>& output_blob_indices()std::vector<int> output_blob_indices = net->output_blob_indices();fprintf(stderr, "print output blob indices info: size: %d\n", output_blob_indices.size());for (auto value : output_blob_indices) {fprintf(stderr, "output blob indices: %d\n", value);}// 27. bool has_blob(const string& blob_name)bool has_blob1 = net->has_blob("data");bool has_blob2 = net->has_blob("loss");fprintf(stderr, "net has blob data: %d, has blob loss: %d\n", has_blob1, has_blob2);// 28. const shared_ptr<Blob<Dtype> > blob_by_nameconst std::vector<std::string> blob_by_names{ "innerproduct", "loss" };for (auto name : blob_by_names) {const boost::shared_ptr<caffe::Blob<float>> blob = net->blob_by_name(name);if (blob != nullptr)fprintf(stderr, "blob shape: %s\n", blob->shape_string().c_str());elsefprintf(stderr, "unknown blob name: %s\n", name.c_str());}// 29. bool has_layer(const string& layer_name)const std::vector<std::string> has_layers{"innerproduct", "top_loss"};for (auto name : has_layers) {bool has_layer = net->has_layer(name);fprintf(stderr, "has layer %s: %d\n", name.c_str(), has_layer);}// 30. const shared_ptr<Layer<Dtype> > layer_by_nameconst std::vector<std::string> layer_by_names{ "data", "top_loss" };for (auto name : layer_by_names) {const boost::shared_ptr<caffe::Layer<float>> layer = net->layer_by_name(name);if (layer != nullptr)fprintf(stderr, "layer type: %s\n", layer->type());elsefprintf(stderr, "unknown layer name: %s\n", name.c_str());}// 31. void set_debug_info(const bool value)net->set_debug_info(true);// 32. void ToHDF5(const string& filename, bool write_diff = false)// std::string hdf5_name{"E:/GitCode/Caffe_Test/test_data/hdf5.h5"};// net->ToHDF5(hdf5_name, false); // Note: some .prototxt will crash// 33. void ToProto(NetParameter* param, bool write_diff = false)caffe::NetParameter param2;net->ToProto(¶m2, false);fprintf(stderr, "new net name: %s\n", param2.name().c_str());return 0;
}
相关文章:
满满干货的硬核技术沙龙,免费看直播还送书 | CSDN新书发布会
周一的时候,我拖着疲惫的身体回到家中,躺倒床上刷刷朋友圈,什么,周杰伦出新歌了?朋友圈都是在分享周杰伦的新歌《说好的不哭》,作为周杰伦的粉丝,我赶紧打开我手机上的QQ音乐,准备去…

【重磅上线】思维导图工具XMind:ZEN基础问题详解合集
XMind是XMind Ltd公司旗下一款出色的思维导图和头脑风暴软件。黑暗的UI设计、独特的ZEN模式、丰富的风格和主题、多分支的颜色等等功能会让你的工作更加便捷与高效。在视觉感官上也会给你带来最佳的体验感。 对于初学者来说,肯定会遇到各种各样的问题,有…

Linux内置的审计跟踪工具:last命令
这个命令是last。它对于追踪非常有用。让我们来看一下last可以为你做些什么。last命令的功能是什么last显示的是自/var/log/wtmp文件创建起所有登录(和登出)的用户。这个文件是二进制文件,它不能被文本编辑器浏览,比如vi、Joe或者其他软件。这是非常有用…
C++/C++11中std::set用法汇总
一个容器就是一些特定类型对象的集合。顺序容器(sequential container)为程序员提供了控制元素存储和访问顺序的能力。这种顺序不依赖于元素的值,而是与元素加入容器时的位置相对应。与之相对的,有序和无序关联容器,则根据关键字的值来存储元…

值得收藏!基于激光雷达数据的深度学习目标检测方法大合集(下)
作者 | 黄浴来源 | 转载自知乎专栏自动驾驶的挑战和发展【导读】在近日发布的《值得收藏!基于激光雷达数据的深度学习目标检测方法大合集(上)》一文中,作者介绍了一部分各大公司和机构基于激光雷达的目标检测所做的工作࿰…

java B2B2C源码电子商务平台 -commonservice-config配置服务搭建
2019独角兽企业重金招聘Python工程师标准>>> Spring Cloud Config为分布式系统中的外部配置提供服务器和客户端支持。使用Config Server,您可以在所有环境中管理应用程序的外部属性。客户端和服务器上的概念映射与Spring Environment和PropertySource抽象…
Topshelf:一款非常好用的 Windows 服务开发框架
背景 多数系统都会涉及到“后台服务”的开发,一般是为了调度一些自动执行的任务或从队列中消费一些消息,开发 windows service 有一点不爽的是:调试麻烦,当然你还需要知道 windows service 相关的一些开发知识(也不难&…
C++中nothrow的介绍及使用
在C中,使用malloc等分配内存的函数时,一定要检查其返回值是否为”空指针”,并以此作为检查内存操作是否成功的依据,这种Test-for-NULL代码形式是一种良好的编程习惯,也是编写可靠程序所必需的。在C中new在申请内存失败…
你猜猜typeof (typeof 1) 会返回什么值(类型)?!
typeof typeof操作符返回一个字符串,表示未经计算的操作数的类型。 语法: var num a; console.log(typeof (num)); 或console.log(typeof num) 复制代码typeof 可以返回的类型为:number、string、boolean、undefined、null、object、functi…

阿里云智能运维的自动化三剑客
整理 | 王银出品 | AI科技大本营(ID:rgznai100)近日,2019 AI开发者大会在北京举行。会上,近百位中美顶尖AI专家、知名企业代表以及千余名AI开发者进行技术解读和产业论证。而在AIDevOps论坛上,阿里巴巴高级技术专家滕圣…
Sublime Text2.0.2注册码
直接输入注册码就可以了 ----- BEGIN LICENSE ----- Andrew Weber Single User License EA7E-855605 813A03DD 5E4AD9E6 6C0EEB94 BC99798F 942194A6 02396E98 E62C9979 4BB979FE 91424C9D A45400BF F6747D88 2FB88078 90F5CC94 1CDC92DC 8457107A F151657B 1D22E383 A997F016 …
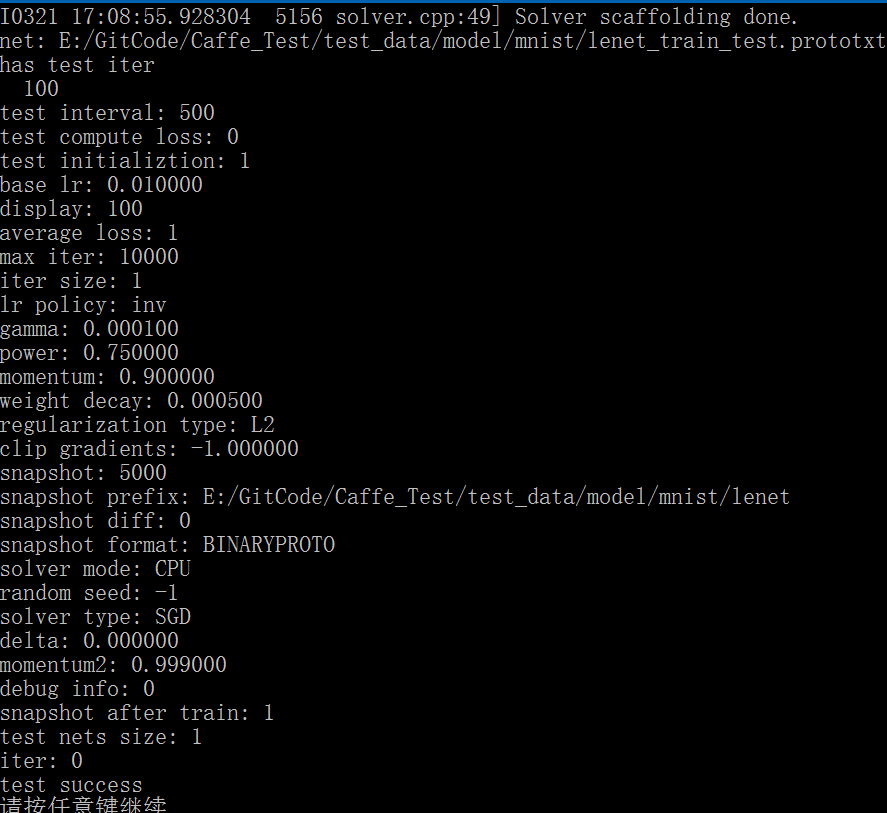
Caffe源码中Solver文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/solver.hpp文件的内容:1. include文件: <caffe/solver.hpp>:此文件的介绍可以参考: http://b…
百度大脑金秋九月CV盛典,人脸识别新产品及伙伴计划发布会压轴开启
提起人脸识别你最先想到的是什么?是告别排队,刷脸就能支付的超市;还是告别黄牛,刷脸就能自助挂号建档的医院?其实,“刷脸”的时代早已到来,并且人脸识别技术的发展已经超越你的想象,…
BIML 101 - ETL数据清洗 系列 - BIML 快速入门教程 - 序
BIML 101 - BIML 快速入门教程 做大数据的项目,最花时间的就是数据清洗。 没有一个相对可靠的数据,数据分析就是无木之舟,无水之源。 如果你已经进了ETL这个坑,而且预算有限,并且有大量的活要做; 时间紧&am…
ADO数据库操作
void CSjtestDlg::OnBnClickedButtonAdd() {// TODO: 在此添加控件通知处理程序代码this->ShowWindow(SW_HIDE);DigAdd dig ;dig.DoModal() ;this->ShowWindow(SW_SHOW);m_Grid.DeleteAllItems() ;ADOConn m_Adoconn ;m_Adoconn.OnInitADOConn() ;CString sql ;sql.Forma…

C++中try/catch/throw的使用
C异常是指在程序运行时发生的反常行为,这些行为超出了函数正常功能的范围。当程序的某部分检测到一个它无法处理的问题时,需要用到异常处理。异常提供了一种转移程序控制权的方式。C异常处理涉及到三个关键字:try、catch、throw。 在C语言中…

掌握这些步骤,机器学习模型问题药到病除
作者 | Cecelia Shao编译 | ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】这篇文章提供了切实可行的步骤来识别和修复机器学习模型的训练、泛化和优化问题。众所周知,调试机器学习代码非常困难。即使对于简单的前馈神经网络也是这样&am…
How to list/dump dm thin pool metadata device?
2019独角兽企业重金招聘Python工程师标准>>> See: How to create metadata-snap for thin tools using? I dont think LVM provides any support for metadata snapshots so you will need to drive this process through dmsetup. The kernel interface is descri…

Linux基础(二)--基础的命令ls和date的详细用法
本文中主要介绍了linu系统下一些基础命令的用法,重点介绍了ls和date的用法。1.basename:作用:返回一个字符串参数的基本文件名称。用法:basename PATH例如:basename /usr/share/doc 返回结果为doc2.dirname:作用:返回一…
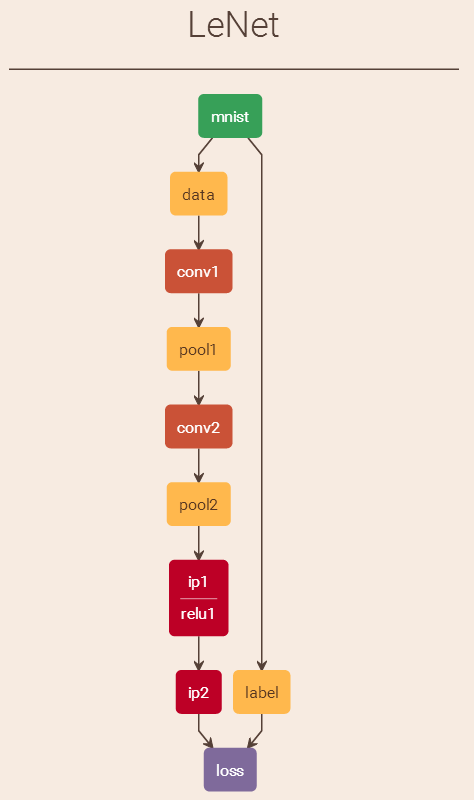
Caffe中对MNIST执行train操作执行流程解析
之前在 http://blog.csdn.net/fengbingchun/article/details/49849225 中简单介绍过使用Caffe train MNIST的文章,当时只是仿照caffe中的example实现了下,下面说一下执行流程,并精简代码到仅有10余行:1. 先注册所有层&…

华为云垃圾分类AI大赛三强出炉,ModelArts2.0让行业按下AI开发“加速键”
9月20日,华为云人工智能大赛垃圾分类挑战杯决赛在上海世博中心2019华为全联接大会会场顺利举办。经过近两个月赛程的层层筛选,入围决赛阵列的11支战队的高光时刻也如期而至。最终华为云垃圾分类挑战杯三强出炉。本次华为云人工智能大赛垃圾分类挑战杯聚焦…

王坚十年前的坚持,才有了今天世界顶级大数据计算平台MaxCompute...
如果说十年前,王坚创立阿里云让云计算在国内得到了普及,那么王坚带领团队自主研发的大数据计算平台MaxCompute则推动大数据技术向前跨越了一大步。数据是企业的核心资产,但十年前阿里巴巴的算力已经无法满足当时急剧增长数据量的需求。基于Ha…

tomcat简单配置
-----------------------------------------一、前言二、环境三、安装JDK四、安装tomcat五、安装mysql六、安装javacenter七、tomcat后台管理-----------------------------------------一、前言Tomcat是Apache 软件基金会(Apache Software Foundation)的…
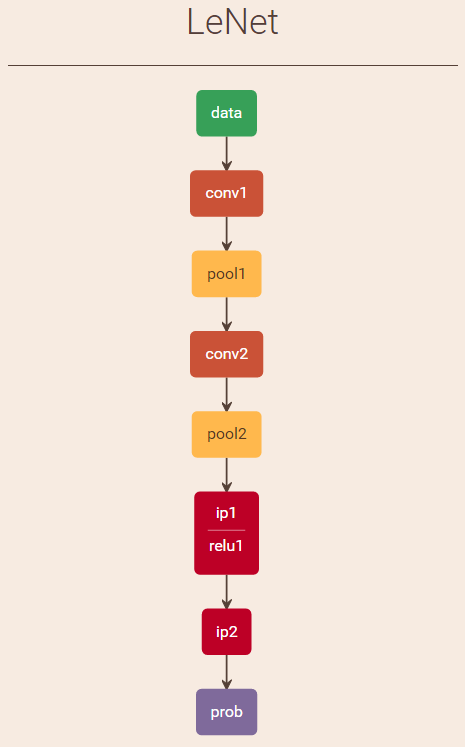
使用Caffe进行手写数字识别执行流程解析
之前在 http://blog.csdn.net/fengbingchun/article/details/50987185 中仿照Caffe中的examples实现对手写数字进行识别,这里详细介绍下其执行流程并精简了实现代码,使用Caffe对MNIST数据集进行train的文章可以参考 http://blog.csdn.net/fengbingchun/…

前端也能玩转机器学习?Google Brain 工程师来支招
演讲嘉宾 | 俞玶编辑 | 伍杏玲来源 | CSDN(ID:CSDNnews)导语:9 月 7 日,在CSDN主办的「AI ProCon 2019」上,Google Brain 工程师,TensorFlow.js 项目负责人俞玶发表《TensorFlow.js 遇到小程序》的主题演讲,…
mongoDB设置用户名密码的一个要点
2019独角兽企业重金招聘Python工程师标准>>> 增加用户之前, 先选好库 use <库名> #选择admin库后可查看system.users里面的用户数据 db.system.users.find() db.createUser 这个函数填写用户名密码与权限就行了, 在这里设置库的名称没用. 一定要用用use选择好…

基于HTML5的电信网管3D机房监控应用
先上段视频,不是在玩游戏哦,是规规矩矩的电信网管企业应用,嗯,全键盘的漫游3D机房:随着PC端支持HTML5浏览器的普及,加上主流移动终端Android和iOS都已支持HTML5技术,新一代的电信网管应用几乎一致性的首选H…

从原理到实现,详解基于朴素ML思想的协同过滤推荐算法
作者丨gongyouliu编辑丨Zandy来源 | 大数据与人工智能(ID: ai-big-data)作者在《协同过滤推荐算法》、《矩阵分解推荐算法》这两篇文章中介绍了几种经典的协同过滤推荐算法。我们在本篇文章中会继续介绍三种思路非常简单朴素的协同过滤算法,这…
C++/C++11中引用的使用
引用(reference)是一种复合类型(compound type)。引用为对象起了另外一个名字,引用类型引用(refer to)另外一种类型。通过将声明符写成&d的形式来定义引用类型,其中d是声明的变量名。 一、一般引用:一般在初始化变量时,初始值…
node.js学习5--------------------- 返回html内容给浏览器
/*** http服务器的搭建,相当于php中的Apache或者java中的tomcat服务器*/ // 导包 const httprequire("http"); const fsrequire("fs"); //创建服务器 /*** 参数是一个回调函数,回调函数2个参数,1个是请求参数,一个是返回参数*/ let serverhttp.createServe…