Caffe源码中Solver文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/solver.hpp文件的内容:
1. include文件:
<caffe/solver.hpp>:此文件的介绍可以参考: http://blog.csdn.net/fengbingchun/article/details/62423060
2. 模板类Solver:虚基类
3. 模板类WorkerSolver:继承父类Solver,用于多GPU训练时仅计算梯度
4. 模板类SGDSolver:继承父类Solver
5. 模板类NesterovSolver:继承SGDSolver
6. 模板类AdaGradSolver:继承SGDSolver
7. 模板类RMSPropSolver:继承SGDSolver
8. 模板类AdaDeltaSolver:继承SGDSolver
9. 模板类AdamSolver:继承SGDSolver
10. 函数GetSolver:new solver对象
Solver通过协调Net的前向推断计算和反向梯度计算(forward inference and backward gradients),来对参数进行更新,从而达到减少loss的目的。Caffe模型的学习被分为两个部分:由Solver进行优化、更新参数,由Net计算出loss和gradient。
solver.prototxt是一个配置文件用来告知Caffe怎样对网络进行训练。
有了Net就可以进行神经网络的前后向传播计算了,但是还缺少神经网络的训练和预测功能,Solver类进一步封装了训练和预测相关的一些功能。Solver定义了针对Net网络模型的求解方法,记录神经网络的训练过程,保存神经网络模型参数,中断并恢复网络的训练过程。自定义Solver能够实现不同的神经网络求解方式。
Caffe支持的solvers包括:
(1)、Stochastic Gradient Descent(type: “SGD”)即随机梯度下降:利用负梯度和上一次权重的更新值的线性组合来更新权重。学习率(learning rate)是负梯度的权重。动量是上一次更新值的权重。一般将学习速率初始化为0.01,然后在训练(training)中当loss达到稳定时,将学习速率除以一个常数(例如10),将这个过程重复多次。对于动量一般设置为0.9,动量使weight得更新更为平缓,使学习过程更为稳定、快速。
(2)、AdaDelta(type:“AdaDelta”):是一种”鲁棒的学习率方法”,同SGD一样是一种基于梯度的优化方法。
(3)、Adaptive Gradient(type: “AdaGrad”)即自适应梯度下降,与随机梯度下降一样是基于梯度的优化方法。
(4)、Adam(type:“Adam”):也是一种基于梯度的优化方法。它包含一对自适应时刻估计变量,可以看做是AdaGrad的一种泛化形式。
(5)、Nesterov’s Accelerated Gradient(type: “Nesterov”):Nesterov提出的加速梯度下降(Nesterov’s accelerated gradient)是凸优化的一种最优算法,其收敛速度可以达到O(1/t^2),而不是O(1/t)。尽管在使用Caffe训练深度神经网络时很难满足O(1/t^2)收敛条件,但实际中NAG对于某些特定结构的深度学习模型仍是一个非常有效的方法。
(6)、RMSprop(type:“RMSProp”):是一种基于梯度的优化方法(同SGD类似)。
Solver:
(1)、用于优化过程的记录、创建训练网络(用于学习)和测试网络(用于评估);
(2)、通过forward和backward过程来迭代地优化和更新参数;
(3)、周期性地用测试网络评估模型性能;
(4)、在优化过程中记录模型和solver状态的快照(snapshot)。
每一次迭代过程中:
(1)、调用Net的前向过程计算出输出和loss;
(2)、调用Net的反向过程计算出梯度(loss对每层的权重w和偏置b求导);
(3)、根据下面所讲的Solver方法,利用梯度更新参数;
(4)、根据学习率(learning rate),历史数据和求解方法更新solver的状态,使权重从初始化状态逐步更新到最终的学习到的状态。
Solvers的运行模式有CPU/GPU两种模式。
Solver方法:用于最小化损失(loss)值。给定一个数据集D,优化的目标是D中所有数据损失的均值,即平均损失,取得最小值。
注:以上关于Solver内容的介绍主要摘自由CaffeCN社区翻译的《Caffe官方教程中译本》。
<caffe/solver.hpp>文件的详细介绍如下:
#ifndef CAFFE_OPTIMIZATION_SOLVER_HPP_
#define CAFFE_OPTIMIZATION_SOLVER_HPP_#include <string>
#include <vector>#include "caffe/net.hpp"namespace caffe {/*** @brief An interface for classes that perform optimization on Net%s.** Requires implementation of ApplyUpdate to compute a parameter update* given the current state of the Net parameters.*/
template <typename Dtype>
class Solver { // Solver模板类,虚基类public:
// 显示构造函数, 内部会调用Init函数explicit Solver(const SolverParameter& param, const Solver* root_solver = NULL);explicit Solver(const string& param_file, const Solver* root_solver = NULL);
// 成员变量赋值,包括param_、iter_、current_step_,并调用InitTrainNet和InitTestNets函数void Init(const SolverParameter& param);
// 为成员变量net_赋值void InitTrainNet();
// 为成员变量test_nets_赋值void InitTestNets();// The main entry of the solver function. In default, iter will be zero. Pass// in a non-zero iter number to resume training for a pre-trained net.
// 依次调用函数Restore、Step、Snapshot,然后执行net_的前向传播函数ForwardPrefilled,最后调用TestAll函数virtual void Solve(const char* resume_file = NULL);inline void Solve(const string resume_file) { Solve(resume_file.c_str()); }
// 反复执行net前向传播反向传播计算,期间会调用函数TestAll、ApplyUpdate、Snapshot及类Callback两个成员函数void Step(int iters);// The Restore method simply dispatches to one of the// RestoreSolverStateFrom___ protected methods. You should implement these// methods to restore the state from the appropriate snapshot type.
// 加载已有的模型void Restore(const char* resume_file);
// 虚析构函数virtual ~Solver() {}// 获得slover parameterinline const SolverParameter& param() const { return param_; }
// 获得train Netinline shared_ptr<Net<Dtype> > net() { return net_; }
// 获得test Netinline const vector<shared_ptr<Net<Dtype> > >& test_nets() {return test_nets_;}
// 获得当前的迭代数int iter() { return iter_; }// Invoked at specific points during an iteration
// 内部Callback类,仅在多卡GPU模式下使用class Callback {protected:virtual void on_start() = 0;virtual void on_gradients_ready() = 0;template <typename T>friend class Solver;};
// 获得Callbackconst vector<Callback*>& callbacks() const { return callbacks_; }
// 添加一个Callbackvoid add_callback(Callback* value) { callbacks_.push_back(value); }protected:// Make and apply the update value for the current iteration.
// 更新net的权值和偏置virtual void ApplyUpdate() = 0;// The Solver::Snapshot function implements the basic snapshotting utility// that stores the learned net. You should implement the SnapshotSolverState()// function that produces a SolverState protocol buffer that needs to be// written to disk together with the learned net.
// 快照,内部会调用SnapshotToBinaryProto或SnapshotToHDF5、SnapshotSolverState函数void Snapshot();
// 获取快照文件名string SnapshotFilename(const string extension);
// 写proto到.caffemodelstring SnapshotToBinaryProto();
// 写proto到HDF5文件string SnapshotToHDF5();// The test routine
// 内部会循环调用Test函数void TestAll();
// 执行测试网络,net前向传播void Test(const int test_net_id = 0);
// 存储snapshot solver statevirtual void SnapshotSolverState(const string& model_filename) = 0;
// 读HDF5文件到solver statevirtual void RestoreSolverStateFromHDF5(const string& state_file) = 0;
// 读二进制文件.solverstate到solver statevirtual void RestoreSolverStateFromBinaryProto(const string& state_file) = 0;
// dummy function,只有声明没有实现void DisplayOutputBlobs(const int net_id);// Caffe中类的成员变量名都带有后缀"_",这样就容易区分临时变量和类成员变量SolverParameter param_; // solver parameterint iter_; // 当前的迭代数int current_step_; // shared_ptr<Net<Dtype> > net_; // train netvector<shared_ptr<Net<Dtype> > > test_nets_; // test netvector<Callback*> callbacks_; // Callback// The root solver that holds root nets (actually containing shared layers)// in data parallelismconst Solver* const root_solver_;// 禁止使用Solver类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(Solver);
};/*** @brief Solver that only computes gradients, used as worker* for multi-GPU training.*/
template <typename Dtype>
class WorkerSolver : public Solver<Dtype> { // 模板类WorkerSolver,继承父类Solverpublic:
// 显示构造函数explicit WorkerSolver(const SolverParameter& param, const Solver<Dtype>* root_solver = NULL): Solver<Dtype>(param, root_solver) {}protected:void ApplyUpdate() {}void SnapshotSolverState(const string& model_filename) {LOG(FATAL) << "Should not be called on worker solver.";}void RestoreSolverStateFromBinaryProto(const string& state_file) {LOG(FATAL) << "Should not be called on worker solver.";}void RestoreSolverStateFromHDF5(const string& state_file) {LOG(FATAL) << "Should not be called on worker solver.";}
};/*** @brief Optimizes the parameters of a Net using* stochastic gradient descent (SGD) with momentum.*/
template <typename Dtype>
class SGDSolver : public Solver<Dtype> { // 模板类SGDSolver,继承父类Solverpublic:
// 显示构造函数,调用PreSolve函数explicit SGDSolver(const SolverParameter& param) : Solver<Dtype>(param) { PreSolve(); }explicit SGDSolver(const string& param_file) : Solver<Dtype>(param_file) { PreSolve(); }
// 获取history数据const vector<shared_ptr<Blob<Dtype> > >& history() { return history_; }protected:
// 成员变量history_, update_, temp_初始化void PreSolve();
// 获取学习率Dtype GetLearningRate();
// 内部会调用ClipGradients、Normalize、Regularize、ComputeUpdateValue,更新net权值和偏置virtual void ApplyUpdate();
// 调用caffe_scal函数virtual void Normalize(int param_id);
// 调用caffe_axpy函数virtual void Regularize(int param_id);
// 计算并更新相应Blob值,调用caffe_cpu_axpby和caffe_copy函数virtual void ComputeUpdateValue(int param_id, Dtype rate);
// clip parameter gradients to that L2 norm,如果梯度值过大,就会对梯度做一个修剪,
// 对所有的参数乘以一个缩放因子,使得所有参数的平方和不超过参数中设定的梯度总值virtual void ClipGradients();
// 存储snapshot solver state,内部会掉用SnapshotSolverStateToBinaryProto或SnapshotSolverStateToHDF5函数virtual void SnapshotSolverState(const string& model_filename);
// 写solver state到二进制文件.solverstatevirtual void SnapshotSolverStateToBinaryProto(const string& model_filename);
// 写solver state到HDF5virtual void SnapshotSolverStateToHDF5(const string& model_filename);// 读HDF5文件到solver statevirtual void RestoreSolverStateFromHDF5(const string& state_file);// 读二进制文件.solverstate到solver statevirtual void RestoreSolverStateFromBinaryProto(const string& state_file);// history maintains the historical momentum data.// update maintains update related data and is not needed in snapshots.// temp maintains other information that might be needed in computation// of gradients/updates and is not needed in snapshots
// Caffe中类的成员变量名都带有后缀"_",这样就容易区分临时变量和类成员变量vector<shared_ptr<Blob<Dtype> > > history_, update_, temp_;// 禁止使用SGDSolver类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(SGDSolver);
};template <typename Dtype>
class NesterovSolver : public SGDSolver<Dtype> { // 模板类NesterovSolver,继承SGDSolverpublic:
// 显示构造函数explicit NesterovSolver(const SolverParameter& param) : SGDSolver<Dtype>(param) {}explicit NesterovSolver(const string& param_file) : SGDSolver<Dtype>(param_file) {}protected:
// 计算并更新相应Blob值,调用caffe_cpu_axpby和caffe_copy函数virtual void ComputeUpdateValue(int param_id, Dtype rate);// 禁止使用NesterovSolver类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(NesterovSolver);
};template <typename Dtype>
class AdaGradSolver : public SGDSolver<Dtype> { // 模板类AdaGradSolver,继承SGDSolverpublic:
// 显示构造函数,调用constuctor_sanity_check函数explicit AdaGradSolver(const SolverParameter& param) : SGDSolver<Dtype>(param) { constructor_sanity_check(); }explicit AdaGradSolver(const string& param_file) : SGDSolver<Dtype>(param_file) { constructor_sanity_check(); }protected:
// 计算并更新相应Blob值virtual void ComputeUpdateValue(int param_id, Dtype rate);void constructor_sanity_check() {CHECK_EQ(0, this->param_.momentum())<< "Momentum cannot be used with AdaGrad.";}// 禁止使用AdaGradSolver类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(AdaGradSolver);
};template <typename Dtype>
class RMSPropSolver : public SGDSolver<Dtype> { // 模板类RMSPropSolver,继承SGDSolverpublic:
// 显示构造函数,调用constructor_sanity_check函数explicit RMSPropSolver(const SolverParameter& param) : SGDSolver<Dtype>(param) { constructor_sanity_check(); }explicit RMSPropSolver(const string& param_file) : SGDSolver<Dtype>(param_file) { constructor_sanity_check(); }protected:
// 计算并更新相应Blob值virtual void ComputeUpdateValue(int param_id, Dtype rate);void constructor_sanity_check() {CHECK_EQ(0, this->param_.momentum())<< "Momentum cannot be used with RMSProp.";CHECK_GE(this->param_.rms_decay(), 0)<< "rms_decay should lie between 0 and 1.";CHECK_LT(this->param_.rms_decay(), 1)<< "rms_decay should lie between 0 and 1.";}// 禁止使用RMSPropSolver类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(RMSPropSolver);
};template <typename Dtype>
class AdaDeltaSolver : public SGDSolver<Dtype> { // 模板类AdaDeltaSolver,继承SGDSolverpublic:
// 显示构造函数,调用AdaDeltaPreSolve函数explicit AdaDeltaSolver(const SolverParameter& param) : SGDSolver<Dtype>(param) { AdaDeltaPreSolve(); }explicit AdaDeltaSolver(const string& param_file) : SGDSolver<Dtype>(param_file) { AdaDeltaPreSolve(); }protected:void AdaDeltaPreSolve();
// 计算并更新相应Blob值virtual void ComputeUpdateValue(int param_id, Dtype rate);// 禁止使用AdaDeltaSolver类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(AdaDeltaSolver);
};/*** @brief AdamSolver, an algorithm for first-order gradient-based optimization* of stochastic objective functions, based on adaptive estimates of* lower-order moments. Described in [1].** [1] D. P. Kingma and J. L. Ba, "ADAM: A Method for Stochastic Optimization."* arXiv preprint arXiv:1412.6980v8 (2014).*/
template <typename Dtype>
class AdamSolver : public SGDSolver<Dtype> { // 模板类AdamSolver,继承SGDSolverpublic:
// 显示构造函数,调用AdamPreSolve函数explicit AdamSolver(const SolverParameter& param) : SGDSolver<Dtype>(param) { AdamPreSolve();}explicit AdamSolver(const string& param_file) : SGDSolver<Dtype>(param_file) { AdamPreSolve(); }protected:void AdamPreSolve();
// 计算并更新相应Blob值virtual void ComputeUpdateValue(int param_id, Dtype rate);// 禁止使用AdamSolver类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(AdamSolver);
};// new一个指定的solver方法对象
template <typename Dtype>
Solver<Dtype>* GetSolver(const SolverParameter& param) {SolverParameter_SolverType type = param.solver_type();switch (type) {case SolverParameter_SolverType_SGD:return new SGDSolver<Dtype>(param);case SolverParameter_SolverType_NESTEROV:return new NesterovSolver<Dtype>(param);case SolverParameter_SolverType_ADAGRAD:return new AdaGradSolver<Dtype>(param);case SolverParameter_SolverType_RMSPROP:return new RMSPropSolver<Dtype>(param);case SolverParameter_SolverType_ADADELTA:return new AdaDeltaSolver<Dtype>(param);case SolverParameter_SolverType_ADAM:return new AdamSolver<Dtype>(param);default:LOG(FATAL) << "Unknown SolverType: " << type;}return (Solver<Dtype>*) NULL;
}} // namespace caffe#endif // CAFFE_OPTIMIZATION_SOLVER_HPP_// NOTE
// Update the next available ID when you add a new SolverParameter field.
//
// SolverParameter next available ID: 40 (last added: momentum2)
message SolverParameter { // Solver参数//// Specifying the train and test networks//// Exactly one train net must be specified using one of the following fields:// train_net_param, train_net, net_param, net// One or more test nets may be specified using any of the following fields:// test_net_param, test_net, net_param, net// If more than one test net field is specified (e.g., both net and// test_net are specified), they will be evaluated in the field order given// above: (1) test_net_param, (2) test_net, (3) net_param/net.// A test_iter must be specified for each test_net.// A test_level and/or a test_stage may also be specified for each test_net.//// Proto filename for the train net, possibly combined with one or more test nets.optional string net = 24; // .prototxt文件名, train or test net// Inline train net param, possibly combined with one or more test nets.optional NetParameter net_param = 25; // net parameter类optional string train_net = 1; // Proto filename for the train net, .prototxt文件名,train netrepeated string test_net = 2; // Proto filenames for the test nets, .prototxt文件名,test netoptional NetParameter train_net_param = 21; // Inline train net params, train net parameter类repeated NetParameter test_net_param = 22; // Inline test net params, test net parameter类// The states for the train/test nets. Must be unspecified or// specified once per net.//// By default, all states will have solver = true;// train_state will have phase = TRAIN,// and all test_state's will have phase = TEST.// Other defaults are set according to the NetState defaults.optional NetState train_state = 26; // train net staterepeated NetState test_state = 27; // test net state// The number of iterations for each test net.repeated int32 test_iter = 3; // 对于测试网络(用于评估)执行一次需要迭代的次数, test_iter * batch_size = 测试图像总数量// The number of iterations between two testing phases.optional int32 test_interval = 4 [default = 0]; // 指定执行多少次训练网络执行一次测试网络optional bool test_compute_loss = 19 [default = false]; // 执行测试网络时是否计算loss// If true, run an initial test pass before the first iteration,// ensuring memory availability and printing the starting value of the loss.optional bool test_initialization = 32 [default = true]; // 在总的开始前,是否先执行一次测试网络optional float base_lr = 5; // The base learning rate,基础学习率// the number of iterations between displaying info. If display = 0, no info// will be displayed.optional int32 display = 6; // 指定迭代多少次显示一次结果信息// Display the loss averaged over the last average_loss iterationsoptional int32 average_loss = 33 [default = 1]; // optional int32 max_iter = 7; // the maximum number of iterations// accumulate gradients over `iter_size` x `batch_size` instancesoptional int32 iter_size = 36 [default = 1]; // // The learning rate decay policy. The currently implemented learning rate// policies are as follows: // 学习率衰减策略// - fixed: always return base_lr.// - step: return base_lr * gamma ^ (floor(iter / step))// - exp: return base_lr * gamma ^ iter// - inv: return base_lr * (1 + gamma * iter) ^ (- power)// - multistep: similar to step but it allows non uniform steps defined by// stepvalue// - poly: the effective learning rate follows a polynomial decay, to be// zero by the max_iter. return base_lr (1 - iter/max_iter) ^ (power)// - sigmoid: the effective learning rate follows a sigmod decay// return base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))//// where base_lr, max_iter, gamma, step, stepvalue and power are defined// in the solver parameter protocol buffer, and iter is the current iteration.optional string lr_policy = 8; // 学习策略,可取的值包括:fixed、step、exp、inv、multistep、poly、sigmoidoptional float gamma = 9; // The parameter to compute the learning rate.optional float power = 10; // The parameter to compute the learning rate.optional float momentum = 11; // The momentum value, 动量optional float weight_decay = 12; // The weight decay. // // regularization types supported: L1 and L2// controlled by weight_decayoptional string regularization_type = 29 [default = "L2"]; // L1 or L2// the stepsize for learning rate policy "step"optional int32 stepsize = 13; //// the stepsize for learning rate policy "multistep"repeated int32 stepvalue = 34; //// Set clip_gradients to >= 0 to clip parameter gradients to that L2 norm,// whenever their actual L2 norm is larger.optional float clip_gradients = 35 [default = -1]; //optional int32 snapshot = 14 [default = 0]; // The snapshot interval, 迭代多少次保存下结果(如权值、偏置)optional string snapshot_prefix = 15; // The prefix for the snapshot,指定保存文件名的前缀// whether to snapshot diff in the results or not. Snapshotting diff will help// debugging but the final protocol buffer size will be much larger.optional bool snapshot_diff = 16 [default = false]; //enum SnapshotFormat {HDF5 = 0;BINARYPROTO = 1;}optional SnapshotFormat snapshot_format = 37 [default = BINARYPROTO]; // HDF5 or BINARYPROTO// the mode solver will use: 0 for CPU and 1 for GPU. Use GPU in default.enum SolverMode {CPU = 0;GPU = 1;}optional SolverMode solver_mode = 17 [default = GPU]; // 指定solve mode是CPU还是GPU// the device_id will that be used in GPU mode. Use device_id = 0 in default.optional int32 device_id = 18 [default = 0]; // GPU mode下使用// If non-negative, the seed with which the Solver will initialize the Caffe// random number generator -- useful for reproducible results. Otherwise,// (and by default) initialize using a seed derived from the system clock.optional int64 random_seed = 20 [default = -1]; // // Solver typeenum SolverType { // solver优化方法SGD = 0;NESTEROV = 1;ADAGRAD = 2;RMSPROP = 3;ADADELTA = 4;ADAM = 5;}optional SolverType solver_type = 30 [default = SGD]; // 指定solver优化方法// numerical stability for RMSProp, AdaGrad and AdaDelta and Adamoptional float delta = 31 [default = 1e-8]; // // parameters for the Adam solveroptional float momentum2 = 39 [default = 0.999]; // // RMSProp decay value// MeanSquare(t) = rms_decay*MeanSquare(t-1) + (1-rms_decay)*SquareGradient(t)optional float rms_decay = 38; // // If true, print information about the state of the net that may help with// debugging learning problems.optional bool debug_info = 23 [default = false]; // // If false, don't save a snapshot after training finishes.optional bool snapshot_after_train = 28 [default = true]; //
}#include "funset.hpp"
#include <string>
#include <vector>
#include <map>
#include "common.hpp"int test_caffe_solver()
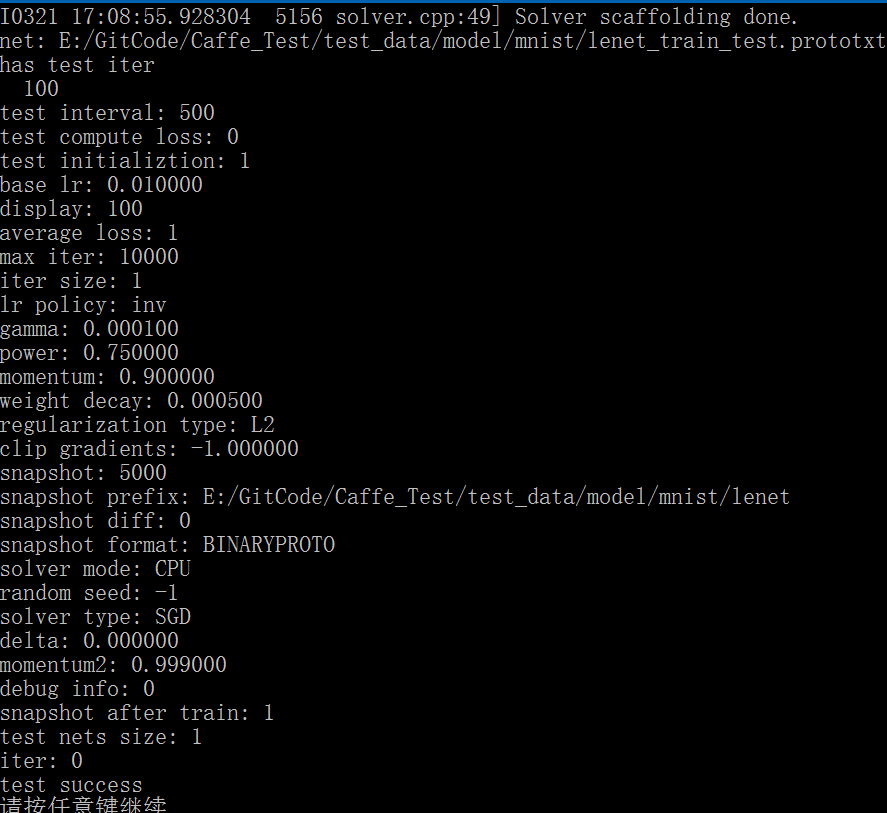
{caffe::Caffe::set_mode(caffe::Caffe::CPU); // set run caffe modeconst std::string solver_prototxt{ "E:/GitCode/Caffe_Test/test_data/model/mnist/lenet_solver.prototxt" };caffe::SolverParameter solver_param;if (!caffe::ReadProtoFromTextFile(solver_prototxt.c_str(), &solver_param)) {fprintf(stderr, "parse solver.prototxt fail\n");return -1;}boost::shared_ptr<caffe::Solver<float> > solver(caffe::GetSolver<float>(solver_param));caffe::SolverParameter param = solver->param();if (param.has_net())fprintf(stderr, "net: %s\n", param.net().c_str());if (param.has_net_param()) {fprintf(stderr, "has net param\n");caffe::NetParameter net_param = param.net_param();if (net_param.has_name())fprintf(stderr, "net param name: %s\n", net_param.name().c_str());}if (param.has_train_net())fprintf(stderr, "train_net: %s\n", param.train_net());if (param.test_net().size() > 0) {for (auto test_net : param.test_net())fprintf(stderr, "test_net: %s\n", test_net);}if (param.has_train_net_param()) {fprintf(stderr, "has train net param\n");caffe::NetParameter train_net_param = param.train_net_param();}if (param.test_net_param().size() > 0) {fprintf(stderr, "has test net param\n");std::vector<caffe::NetParameter> test_net_param;for (auto net_param : param.test_net_param())test_net_param.push_back(net_param);}if (param.has_train_state()) {fprintf(stderr, "has train state\n");caffe::NetState state = param.train_state();}if (param.test_state().size()) {fprintf(stderr, "has test state\n");}if (param.test_iter_size() > 0) {fprintf(stderr, "has test iter\n");for (auto iter : param.test_iter())fprintf(stderr, " %d ", iter);fprintf(stderr, "\n");}if (param.has_test_interval())fprintf(stderr, "test interval: %d\n", param.test_interval());bool test_compute_loss = param.test_compute_loss();fprintf(stderr, "test compute loss: %d\n", test_compute_loss);bool test_initialization = param.test_initialization();fprintf(stderr, "test initializtion: %d\n", test_initialization);if (param.has_base_lr()) {float base_lr = param.base_lr();fprintf(stderr, "base lr: %f\n", base_lr);}if (param.has_display()) {int display = param.display();fprintf(stderr, "display: %d\n", display);}int average_loss = param.average_loss();fprintf(stderr, "average loss: %d\n", average_loss);if (param.has_max_iter()) {int max_iter = param.max_iter();fprintf(stderr, "max iter: %d\n", max_iter);}int iter_size = param.iter_size();fprintf(stderr, "iter size: %d\n", iter_size);if (param.has_lr_policy())fprintf(stderr, "lr policy: %s\n", param.lr_policy().c_str());if (param.has_gamma())fprintf(stderr, "gamma: %f\n", param.gamma());if (param.has_power())fprintf(stderr, "power: %f\n", param.power());if (param.has_momentum())fprintf(stderr, "momentum: %f\n", param.momentum());if (param.has_weight_decay())fprintf(stderr, "weight decay: %f\n", param.weight_decay());std::string regularization_type = param.regularization_type();fprintf(stderr, "regularization type: %s\n", param.regularization_type().c_str());if (param.has_stepsize())fprintf(stderr, "stepsize: %d\n", param.stepsize());if (param.stepvalue_size() > 0) {fprintf(stderr, "has stepvalue\n");for (auto value : param.stepvalue())fprintf(stderr, " %d ", value);fprintf(stderr, "\n");}fprintf(stderr, "clip gradients: %f\n", param.clip_gradients());fprintf(stderr, "snapshot: %d\n", param.snapshot());if (param.has_snapshot_prefix())fprintf(stderr, "snapshot prefix: %s\n", param.snapshot_prefix().c_str());fprintf(stderr, "snapshot diff: %d\n", param.snapshot_diff());caffe::SolverParameter_SnapshotFormat snapshot_format = param.snapshot_format();fprintf(stderr, "snapshot format: %s\n", snapshot_format == 0 ? "HDF5" : "BINARYPROTO");caffe::SolverParameter_SolverMode solver_mode = param.solver_mode();fprintf(stderr, "solver mode: %s\n", solver_mode == 0 ? "CPU" : "GPU");if (param.has_device_id())fprintf(stderr, "device id: %d\n", param.device_id());fprintf(stderr, "random seed: %d\n", param.random_seed());caffe::SolverParameter_SolverType solver_type = param.solver_type();std::string solver_method[] {"SGD", "NESTEROV", "ADAGRAD", "RMSPROP", "ADADELTA", "ADAM"};fprintf(stderr, "solver type: %s\n", solver_method[solver_type].c_str());fprintf(stderr, "delta: %f\n", param.delta());fprintf(stderr, "momentum2: %f\n", param.momentum2());if (param.has_rms_decay())fprintf(stderr, "rms decy: %f\n", param.rms_decay());fprintf(stderr, "debug info: %d\n", param.debug_info());fprintf(stderr, "snapshot after train: %d\n", param.snapshot_after_train());boost::shared_ptr<caffe::Net<float>> net = solver->net();std::vector<boost::shared_ptr<caffe::Net<float>>> test_nets = solver->test_nets();fprintf(stderr, "test nets size: %d\n", test_nets.size());fprintf(stderr, "iter: %d\n", solver->iter());return 0;
}
相关文章:
百度大脑金秋九月CV盛典,人脸识别新产品及伙伴计划发布会压轴开启
提起人脸识别你最先想到的是什么?是告别排队,刷脸就能支付的超市;还是告别黄牛,刷脸就能自助挂号建档的医院?其实,“刷脸”的时代早已到来,并且人脸识别技术的发展已经超越你的想象,…

BIML 101 - ETL数据清洗 系列 - BIML 快速入门教程 - 序
BIML 101 - BIML 快速入门教程 做大数据的项目,最花时间的就是数据清洗。 没有一个相对可靠的数据,数据分析就是无木之舟,无水之源。 如果你已经进了ETL这个坑,而且预算有限,并且有大量的活要做; 时间紧&am…
ADO数据库操作
void CSjtestDlg::OnBnClickedButtonAdd() {// TODO: 在此添加控件通知处理程序代码this->ShowWindow(SW_HIDE);DigAdd dig ;dig.DoModal() ;this->ShowWindow(SW_SHOW);m_Grid.DeleteAllItems() ;ADOConn m_Adoconn ;m_Adoconn.OnInitADOConn() ;CString sql ;sql.Forma…

C++中try/catch/throw的使用
C异常是指在程序运行时发生的反常行为,这些行为超出了函数正常功能的范围。当程序的某部分检测到一个它无法处理的问题时,需要用到异常处理。异常提供了一种转移程序控制权的方式。C异常处理涉及到三个关键字:try、catch、throw。 在C语言中…

掌握这些步骤,机器学习模型问题药到病除
作者 | Cecelia Shao编译 | ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】这篇文章提供了切实可行的步骤来识别和修复机器学习模型的训练、泛化和优化问题。众所周知,调试机器学习代码非常困难。即使对于简单的前馈神经网络也是这样&am…

How to list/dump dm thin pool metadata device?
2019独角兽企业重金招聘Python工程师标准>>> See: How to create metadata-snap for thin tools using? I dont think LVM provides any support for metadata snapshots so you will need to drive this process through dmsetup. The kernel interface is descri…

Linux基础(二)--基础的命令ls和date的详细用法
本文中主要介绍了linu系统下一些基础命令的用法,重点介绍了ls和date的用法。1.basename:作用:返回一个字符串参数的基本文件名称。用法:basename PATH例如:basename /usr/share/doc 返回结果为doc2.dirname:作用:返回一…
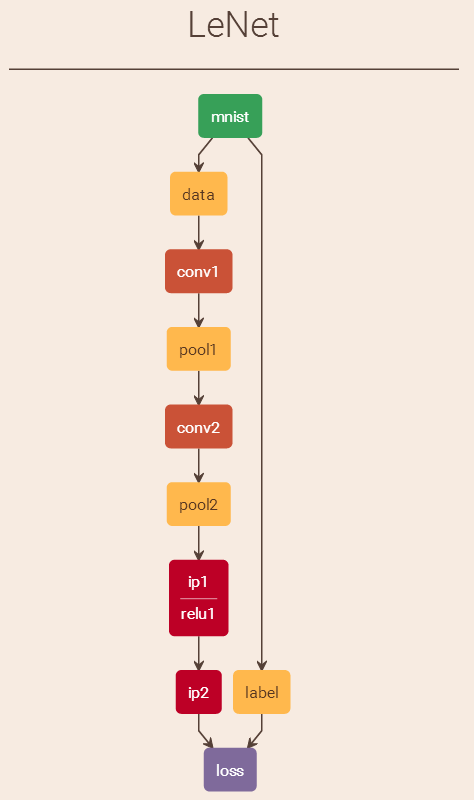
Caffe中对MNIST执行train操作执行流程解析
之前在 http://blog.csdn.net/fengbingchun/article/details/49849225 中简单介绍过使用Caffe train MNIST的文章,当时只是仿照caffe中的example实现了下,下面说一下执行流程,并精简代码到仅有10余行:1. 先注册所有层&…

华为云垃圾分类AI大赛三强出炉,ModelArts2.0让行业按下AI开发“加速键”
9月20日,华为云人工智能大赛垃圾分类挑战杯决赛在上海世博中心2019华为全联接大会会场顺利举办。经过近两个月赛程的层层筛选,入围决赛阵列的11支战队的高光时刻也如期而至。最终华为云垃圾分类挑战杯三强出炉。本次华为云人工智能大赛垃圾分类挑战杯聚焦…

王坚十年前的坚持,才有了今天世界顶级大数据计算平台MaxCompute...
如果说十年前,王坚创立阿里云让云计算在国内得到了普及,那么王坚带领团队自主研发的大数据计算平台MaxCompute则推动大数据技术向前跨越了一大步。数据是企业的核心资产,但十年前阿里巴巴的算力已经无法满足当时急剧增长数据量的需求。基于Ha…

tomcat简单配置
-----------------------------------------一、前言二、环境三、安装JDK四、安装tomcat五、安装mysql六、安装javacenter七、tomcat后台管理-----------------------------------------一、前言Tomcat是Apache 软件基金会(Apache Software Foundation)的…
使用Caffe进行手写数字识别执行流程解析
之前在 http://blog.csdn.net/fengbingchun/article/details/50987185 中仿照Caffe中的examples实现对手写数字进行识别,这里详细介绍下其执行流程并精简了实现代码,使用Caffe对MNIST数据集进行train的文章可以参考 http://blog.csdn.net/fengbingchun/…

前端也能玩转机器学习?Google Brain 工程师来支招
演讲嘉宾 | 俞玶编辑 | 伍杏玲来源 | CSDN(ID:CSDNnews)导语:9 月 7 日,在CSDN主办的「AI ProCon 2019」上,Google Brain 工程师,TensorFlow.js 项目负责人俞玶发表《TensorFlow.js 遇到小程序》的主题演讲,…
mongoDB设置用户名密码的一个要点
2019独角兽企业重金招聘Python工程师标准>>> 增加用户之前, 先选好库 use <库名> #选择admin库后可查看system.users里面的用户数据 db.system.users.find() db.createUser 这个函数填写用户名密码与权限就行了, 在这里设置库的名称没用. 一定要用用use选择好…

基于HTML5的电信网管3D机房监控应用
先上段视频,不是在玩游戏哦,是规规矩矩的电信网管企业应用,嗯,全键盘的漫游3D机房:随着PC端支持HTML5浏览器的普及,加上主流移动终端Android和iOS都已支持HTML5技术,新一代的电信网管应用几乎一致性的首选H…

从原理到实现,详解基于朴素ML思想的协同过滤推荐算法
作者丨gongyouliu编辑丨Zandy来源 | 大数据与人工智能(ID: ai-big-data)作者在《协同过滤推荐算法》、《矩阵分解推荐算法》这两篇文章中介绍了几种经典的协同过滤推荐算法。我们在本篇文章中会继续介绍三种思路非常简单朴素的协同过滤算法,这…
C++/C++11中引用的使用
引用(reference)是一种复合类型(compound type)。引用为对象起了另外一个名字,引用类型引用(refer to)另外一种类型。通过将声明符写成&d的形式来定义引用类型,其中d是声明的变量名。 一、一般引用:一般在初始化变量时,初始值…
node.js学习5--------------------- 返回html内容给浏览器
/*** http服务器的搭建,相当于php中的Apache或者java中的tomcat服务器*/ // 导包 const httprequire("http"); const fsrequire("fs"); //创建服务器 /*** 参数是一个回调函数,回调函数2个参数,1个是请求参数,一个是返回参数*/ let serverhttp.createServe…
内核分析阅读笔记
内核分析阅读笔记 include/Linux/stddef.h中macro offsetof define,list: #define offsetof(TYPE,MEMBER) ((size_t) &((TYPE *)0)->MEMBER) offsetof macro对于上述示例的展开剂分析:&((struct example_struct *)0)->list表示当结构example_struct正好在地址0上…

杨强教授力荐,快速部署落地深度学习应用的实践手册
香港科技大学计算机科学与工程学系讲座教授、国际人工智能联合会(IJCAI)理事会主席(2017—2019)、深圳前海微众银行首席AI 官 杨强为《深度学习模型及应用详解》一书撰序,他提到现在亟需一本介绍深度学习技术实践的图书…
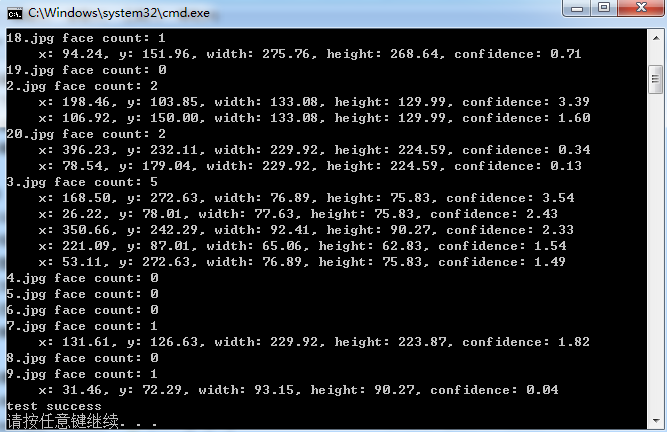
OpenFace库(Tadas Baltrusaitis)中基于HOG进行正脸人脸检测的测试代码
Tadas Baltrusaitis的OpenFace是一个开源的面部行为分析工具,它的源码可以从https://github.com/TadasBaltrusaitis/OpenFace下载。OpenFace主要包括面部关键点检测(facial landmard detection)、头部姿势估计(head pose estimation)、面部动作单元识别(facial acti…
nginx conf 文件配置
打印输出: location / { default_type text/plain; return 502 "$uri"; } $remode_addr 获取访问者的ID$request_method 判断提交方式 GET POST$http_user_agent 获取浏览器软件 if (条件) {} #if之后要有空格 条件3种写法: 1: 来判断相等,用于字符串比较 …
js中 字符串与Unicode 字符值序列的相互转换
一. 字符串转Unicode 字符值序列 var str "abcdef"; var codeArr []; for(var i0;i<str.length;i){codeArr.push(str.charCodeAt(i)); } console.log(codeArr);-->[97, 98, 99, 100, 101, 102] 二.Unicode 字符值序列转字符串 var str String.fromCharCode…
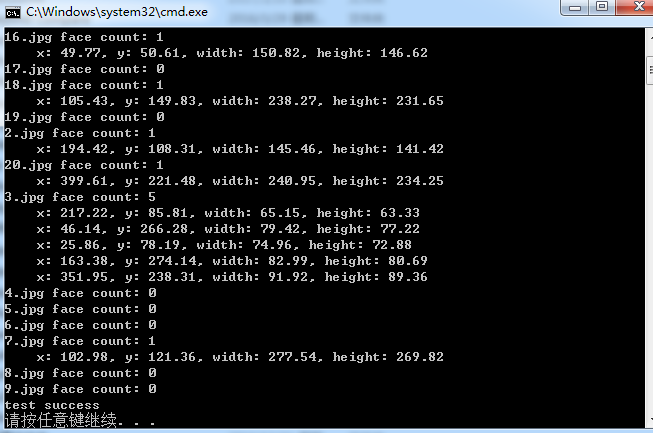
OpenFace库(Tadas Baltrusaitis)中基于Haar Cascade Classifiers进行人脸检测的测试代码
Tadas Baltrusaitis的OpenFace是一个开源的面部行为分析工具,它的源码可以从 https://github.com/TadasBaltrusaitis/OpenFace 下载。OpenFace主要包括面部关键点检测(facial landmard detection)、头部姿势估计(head pose estimation)、面部动作单元识别(facial a…

Uber提出损失变化分配方法LCA,揭秘神经网络“黑盒”
作者 | Janice Lan,Rosanne Liu等译者 | 清儿爸责编 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】神经网络(Neural networks,NN)在过去十年来硕果累累,推动了整个行业的机器学习进程。然而࿰…
范登读书解读《亲密关系》(婚姻、爱情) 笔记
来源:邀请你看《樊登解读《亲密关系》(已婚人士必看)》,https://url.cn/5HJvLk5?sfuri 人们在童年的时候始终追寻着两种东西,第一种叫做归属感,第二叫做确认自己的重要性、价值感。 如果再童年的时候缺失这…
myeclipse莫名其妙的问题
2019独角兽企业重金招聘Python工程师标准>>> 怎么刷新,clean项目都不管用,结果删除相应工作空间下的那个项目就行。类似路径如D:\workspace\.metadata\.plugins\org.eclipse.core.resources\.projects 转载于:https://my.oschina.net/u/14488…

数据科学家需要知道的5种图算法
作者:Rahul Agarwal编译:ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】因为图分析是数据科学家的未来。作为数据科学家,我们对pandas、SQL或任何其他关系数据库非常熟悉。我们习惯于将用户的属性以列的形式显示在…

在Windows7/10上快速搭建深度学习框架Caffe开发环境
之前在 http://blog.csdn.net/fengbingchun/article/details/50987353 中介绍过在Windows7上搭建Caffe开发环境的操作步骤,那时caffe的项目是和其它依赖项目分开的,每次换新的PC机时再次重新配置搭建还是很不方便,而且caffe的版本较老&#x…
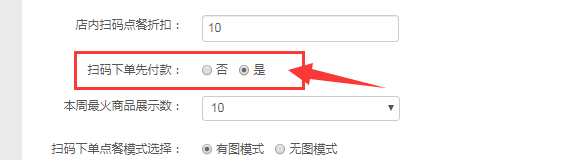
扫码下单支持同桌单人点餐FAQ
一、使用场景 满足较多商户希望同一桌台,各自点各自的菜品的业态场景(例如杭味面馆,黄焖鸡米饭店,面馆等大多数轻快餐店) 二、配置步骤及注意事项 管理员后台配置--配置管理--店铺配置--扫码点餐tab页 1、开启扫码下单…