使用Caffe进行手写数字识别执行流程解析
之前在 http://blog.csdn.net/fengbingchun/article/details/50987185 中仿照Caffe中的examples实现对手写数字进行识别,这里详细介绍下其执行流程并精简了实现代码,使用Caffe对MNIST数据集进行train的文章可以参考 http://blog.csdn.net/fengbingchun/article/details/68065338 :
1. 先注册所有层,执行layer_factory.hpp中类LayerRegisterer的构造函数,类LayerRegistry的AddCreator和Registry静态函数;关于Caffe中Layer的注册可以参考: http://blog.csdn.net/fengbingchun/article/details/54310956
2. 指定执行mode是采用CPU还是GPU;
3. 指定需要的.prototxt和.caffemodel文件:注意此处的.prototxt文件(lenet_train_test_.prototxt)与train时.prototxt文件(lenet_train_test.prototxt)在内容上的差异。.caffemodel文件即是train后最终生成的二进制文件lenet_iter_10000.caffemodel,里面存放着所有层的权值和偏置。lenet_train_test_.prototxt文件内容如下:
name: "LeNet" # net名
layer { # memory required: (784+1)*4=3140name: "data" # layer名字type: "MemoryData" # layer类型,Data enters Caffe through data layers,read data directly from memorytop: "data" # top名字, shape: 1 1 28 28 (784)top: "label" # top名字, shape: 1 (1) #感觉并无实质作用,仅用于增加一个top blob,不可去掉memory_data_param { # 内存数据参数batch_size: 1 # 指定待识别图像一次的数量channels: 1 # 指定待识别图像的通道数height: 28 # 指定待识别图像的高度width: 28 # 指定待识别图像的宽度}transform_param { # 图像预处理参数scale: 0.00390625 # 对图像像素值进行scale操作,范围[0, 1)}
}
layer { # memory required: 11520*4=46080name: "conv1" # layer名字type: "Convolution" # layer类型,卷积层bottom: "data" # bottom名字top: "conv1" # top名字, shape: 1 20 24 24 (11520)param { # Specifies training parameterslr_mult: 1 # The multiplier on the global learning rate}param { # Specifies training parameterslr_mult: 2 # The multiplier on the global learning rate}convolution_param { # 卷积参数num_output: 20 # 输出特征图(feature map)数量kernel_size: 5 # 卷积核大小(卷积核其实就是权值)stride: 1 # 滑动步长weight_filler { # The filler for the weighttype: "xavier" # 权值使用xavier滤波}bias_filler { # The filler for the biastype: "constant" # 偏置使用常量滤波}}
}
layer { # memory required: 2880*4=11520name: "pool1" # layer名字type: "Pooling" # layer类型,Pooling层bottom: "conv1" # bottom名字top: "pool1" # top名字, shape: 1 20 12 12 (2880)pooling_param { # pooling parameter,pooling层参数pool: MAX # pooling方法:最大值采样kernel_size: 2 # 滤波器大小stride: 2 # 滑动步长}
}
layer { # memory required: 3200*4=12800name: "conv2" # layer名字type: "Convolution" # layer类型,卷积层bottom: "pool1" # bottom名字top: "conv2" # top名字, shape: 1 50 8 8 (3200)param { # Specifies training parameterslr_mult: 1 # The multiplier on the global learning rate}param { # Specifies training parameterslr_mult: 2 # The multiplier on the global learning rate}convolution_param { # 卷积参数num_output: 50 # 输出特征图(feature map)数量kernel_size: 5 # 卷积核大小(卷积核其实就是权值)stride: 1 # 滑动步长weight_filler { # The filler for the weighttype: "xavier" # 权值使用xavier滤波}bias_filler { # The filler for the biastype: "constant" # 偏置使用常量滤波}}
}
layer { # memory required: 800*4=3200name: "pool2" # layer名字type: "Pooling" # layer类型,Pooling层bottom: "conv2" # bottom名字top: "pool2" # top名字, shape: 1 50 4 4 (800)pooling_param { # pooling parameter,pooling层参数pool: MAX # pooling方法:最大值采样kernel_size: 2 # 滤波器大小stride: 2 # 滑动步长}
}
layer { # memory required: 500*4=2000name: "ip1" # layer名字type: "InnerProduct" # layer类型,全连接层bottom: "pool2" # bottom名字top: "ip1" # top名字, shape: 1 500 (500)param { # Specifies training parameterslr_mult: 1 # The multiplier on the global learning rate}param { # Specifies training parameterslr_mult: 2 # The multiplier on the global learning rate}inner_product_param { # 全连接层参数num_output: 500 # 输出特征图(feature map)数量weight_filler { # The filler for the weighttype: "xavier" # 权值使用xavier滤波}bias_filler { # The filler for the biastype: "constant" # 偏置使用常量滤波}}
}
# ReLU: Given an input value x, The ReLU layer computes the output as x if x > 0 and
# negative_slope * x if x <= 0. When the negative slope parameter is not set,
# it is equivalent to the standard ReLU function of taking max(x, 0).
# It also supports in-place computation, meaning that the bottom and
# the top blob could be the same to preserve memory consumption
layer { # memory required: 500*4=2000name: "relu1" # layer名字type: "ReLU" # layer类型bottom: "ip1" # bottom名字top: "ip1" # top名字 (in-place), shape: 1 500 (500)
}
layer { # memory required: 10*4=40name: "ip2" # layer名字type: "InnerProduct" # layer类型,全连接层bottom: "ip1" # bottom名字top: "ip2" # top名字, shape: 1 10 (10)param { # Specifies training parameterslr_mult: 1 # The multiplier on the global learning rate}param { # Specifies training parameterslr_mult: 2 # The multiplier on the global learning rate}inner_product_param {num_output: 10 # 输出特征图(feature map)数量weight_filler { # The filler for the weighttype: "xavier" # 权值使用xavier滤波}bias_filler { # The filler for the biastype: "constant" # 偏置使用常量滤波}}
}
layer { # memory required: 10*4=40name: "prob" # layer名字type: "Softmax" # layer类型bottom: "ip2" # bottom名字top: "prob" # top名字, shape: 1 10 (10)
}
# 占用总内存大小为:3140+46080+11520+12800+3200+2000+2000+40+40=80820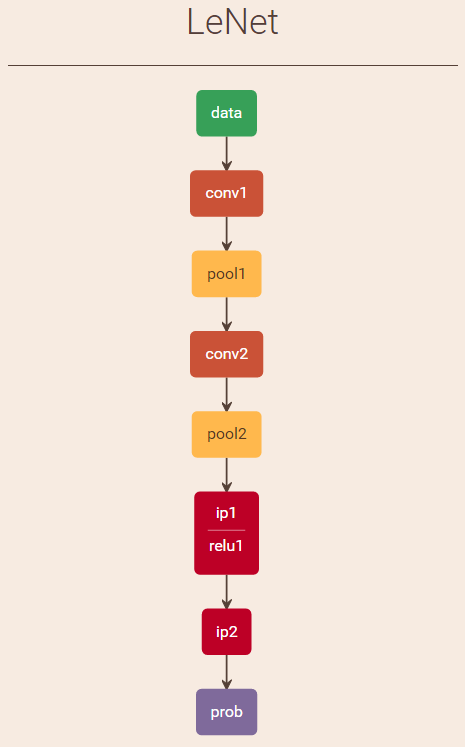
train时lenet_train_test.prototxt与识别时用到的lenet_train_test_.prototxt差异:
(1)、数据层:训练时用Data,是以lmdb数据存储方式载入网络的,而识别时用MemoryData方式直接从内存载入网络;
(2)、Accuracy层:仅训练时用到,用以计算test集的准确率;
(3)、输出层Softmax/SoftmaxWithLoss层:训练时用SoftmaxWithLoss,输出loss值,识别时用Softmax输出10类数字的概率值。
4. 创建Net对象并初始化,有两种方法:一个是通过传入string类型(.prototxt文件)参数创建,一个是通过传入NetParameter参数;
5. 调用Net的CopyTrainedLayersFrom函数加载在train时生成的二进制文件.caffemodel即lenet_iter_10000.caffemodel,有两种方法,一个是通过传入string类型(.caffemodel文件)参数,一个是通过传入NetParameter参数;
6. 获取Net相关参数在后面识别时需要用到:
(1)、通过调用Net的blob_by_name函数获得待识别图像所要求的通道数、宽、高;
(2)、通过调用Net的output_blobs函数获得输出blob的数目及大小,注:这里输出2个blob,第一个是label,count为1,第二个是prob,count为10,即表示数字识别结果的概率值。
7. 开始进行手写数字识别:
(1)、通过opencv的imread函数读入图像;
(2)、根据从Net中获得的需要输入图像的要求对图像进行颜色空间转换和缩放;
(3)、因为MNIST train时,图像为前景为白色,背景为黑色,而现在输入图像为前景为黑色,背景为白色,因此需要对图像进行取反操作;
(4)、将图像数据传入Net,有两种方法:一种是通过MemoryDataLayer类的Reset函数,一种是通过MemoryDataLayer类的AddMatVector函数传入Mat参数;
(5)、调用Net的ForwardPrefilled函数进行前向计算;
(6)、输出识别结果,注,前向计算完返回的Blob有两个,第二个Blob中的数据才是最终的识别结果的概率值,其中最大值的索引即是识别结果。
8. 通过lenet_train_test_.prototxt文件分析各层的权值、偏置和神经元数量,共9层:
(1)、data数据层:无权值和偏置,神经元数量为1*1*28*28+1=785;
(2)、conv1卷积层:卷积窗大小为5*5,输出特征图数量为20,卷积窗种类为20,输出特征图大小为24*24,可训练参数(权值+阈值(偏置))为 20*1*5*5+20=520,神经元数量为1*20*24*24=11520;
(3)、pool1降采样层:滤波窗大小为2*2,输出特征图数量为20,滤波窗种类为20,输出特征图大小为12*12,可训练参数(权值+偏置)为1*20+20=40,神经元数量为1*20*12*12=2880;
(4)、conv2卷积层:卷积窗大小为5*5,输出特征图数量为50,卷积窗种类为50*20,输出特征图大小为8*8,可训练参数(权值+偏置)为50*20*5*5+50=25050,神经元数量为1*50*8*8=3200;
(5)、pool2降采样层:滤波窗大小为2*2,输出特征图数量为50,滤波窗种类为50,输出特征图大小为4*4,可训练参数(权值+偏置)为1*50+50=100,神经元数量为1*50*4*4=800;
(6)、ip1全连接层:滤波窗大小为1*1,输出特征图数量为500,滤波窗种类为500*800,输出特征图大小为1*1,可训练参数(权值+偏置)为500*800*1*1+500=400500,神经元数量为1*500*1*1=500;
(7)、relu1层:in-placeip1;
(8)、ip2全连接层:滤波窗大小为1*1,输出特征图数量为10,滤波窗种类为10*500,输出特征图大小为1*1,可训练参数(权值+偏置)为10*500*1*1+10=5010,神经元数量为1*10*1*1=10;
(9)、prob输出层:神经元数量为1*10*1*1+1=11。
精简后的手写数字识别测试代码如下:
int mnist_predict()
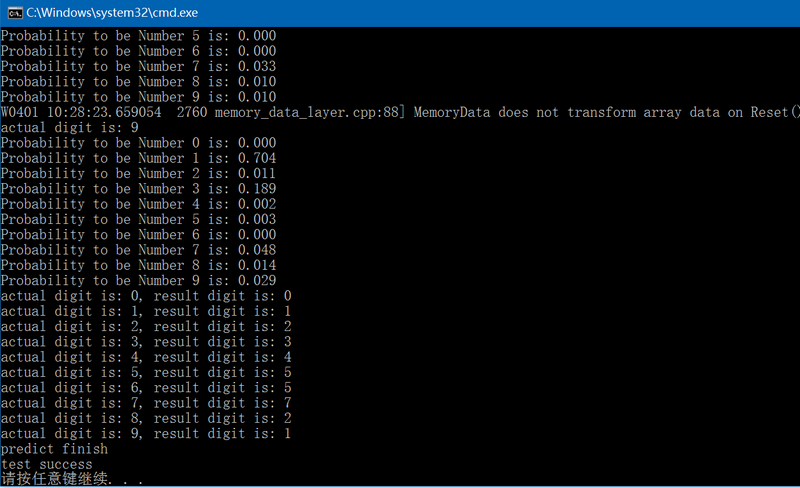
{caffe::Caffe::set_mode(caffe::Caffe::CPU);const std::string param_file{ "E:/GitCode/Caffe_Test/test_data/model/mnist/lenet_train_test_.prototxt" };const std::string trained_filename{ "E:/GitCode/Caffe_Test/test_data/model/mnist/lenet_iter_10000.caffemodel" };const std::string image_path{ "E:/GitCode/Caffe_Test/test_data/images/" };// 有两种方法可以实例化net// 1. 通过传入参数类型为std::stringcaffe::Net<float> caffe_net(param_file, caffe::TEST);caffe_net.CopyTrainedLayersFrom(trained_filename);// 2. 通过传入参数类型为caffe::NetParameter//caffe::NetParameter net_param1, net_param2;//caffe::ReadNetParamsFromTextFileOrDie(param_file, &net_param1);//net_param1.mutable_state()->set_phase(caffe::TEST);//caffe::Net<float> caffe_net(net_param1);//caffe::ReadNetParamsFromBinaryFileOrDie(trained_filename, &net_param2);//caffe_net.CopyTrainedLayersFrom(net_param2);int num_inputs = caffe_net.input_blobs().size(); // 0 ??const boost::shared_ptr<caffe::Blob<float> > blob_by_name = caffe_net.blob_by_name("data");int image_channel = blob_by_name->channels();int image_height = blob_by_name->height();int image_width = blob_by_name->width();int num_outputs = caffe_net.num_outputs();const std::vector<caffe::Blob<float>*> output_blobs = caffe_net.output_blobs();int require_blob_index{ -1 };const int digit_category_num{ 10 };for (int i = 0; i < output_blobs.size(); ++i) {if (output_blobs[i]->count() == digit_category_num)require_blob_index = i;}if (require_blob_index == -1) {fprintf(stderr, "ouput blob don't match\n");return -1;}std::vector<int> target{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };std::vector<int> result;for (auto num : target) {std::string str = std::to_string(num);str += ".png";str = image_path + str;cv::Mat mat = cv::imread(str.c_str(), 1);if (!mat.data) {fprintf(stderr, "load image error: %s\n", str.c_str());return -1;}if (image_channel == 1)cv::cvtColor(mat, mat, CV_BGR2GRAY);else if (image_channel == 4)cv::cvtColor(mat, mat, CV_BGR2BGRA);cv::resize(mat, mat, cv::Size(image_width, image_height));cv::bitwise_not(mat, mat);// 将图像数据载入Net网络,有2种方法boost::shared_ptr<caffe::MemoryDataLayer<float> > memory_data_layer =boost::static_pointer_cast<caffe::MemoryDataLayer<float>>(caffe_net.layer_by_name("data"));// 1. 通过MemoryDataLayer类的Reset函数mat.convertTo(mat, CV_32FC1, 0.00390625);float dummy_label[1] {0};memory_data_layer->Reset((float*)(mat.data), dummy_label, 1);// 2. 通过MemoryDataLayer类的AddMatVector函数//std::vector<cv::Mat> patches{mat}; // set the patch for testing//std::vector<int> labels(patches.size());//memory_data_layer->AddMatVector(patches, labels); // push vector<Mat> to data layerfloat loss{ 0.0 };const std::vector<caffe::Blob<float>*>& results = caffe_net.ForwardPrefilled(&loss); // Net forwardconst float* output = results[require_blob_index]->cpu_data();float tmp{ -1 };int pos{ -1 };fprintf(stderr, "actual digit is: %d\n", target[num]);for (int j = 0; j < 10; j++) {printf("Probability to be Number %d is: %.3f\n", j, output[j]);if (tmp < output[j]) {pos = j;tmp = output[j];}}result.push_back(pos);}for (auto i = 0; i < 10; i++)fprintf(stderr, "actual digit is: %d, result digit is: %d\n", target[i], result[i]);fprintf(stderr, "predict finish\n");return 0;
}
GitHub:https://github.com/fengbingchun/Caffe_Test
相关文章:

前端也能玩转机器学习?Google Brain 工程师来支招
演讲嘉宾 | 俞玶编辑 | 伍杏玲来源 | CSDN(ID:CSDNnews)导语:9 月 7 日,在CSDN主办的「AI ProCon 2019」上,Google Brain 工程师,TensorFlow.js 项目负责人俞玶发表《TensorFlow.js 遇到小程序》的主题演讲,…

mongoDB设置用户名密码的一个要点
2019独角兽企业重金招聘Python工程师标准>>> 增加用户之前, 先选好库 use <库名> #选择admin库后可查看system.users里面的用户数据 db.system.users.find() db.createUser 这个函数填写用户名密码与权限就行了, 在这里设置库的名称没用. 一定要用用use选择好…

基于HTML5的电信网管3D机房监控应用
先上段视频,不是在玩游戏哦,是规规矩矩的电信网管企业应用,嗯,全键盘的漫游3D机房:随着PC端支持HTML5浏览器的普及,加上主流移动终端Android和iOS都已支持HTML5技术,新一代的电信网管应用几乎一致性的首选H…

从原理到实现,详解基于朴素ML思想的协同过滤推荐算法
作者丨gongyouliu编辑丨Zandy来源 | 大数据与人工智能(ID: ai-big-data)作者在《协同过滤推荐算法》、《矩阵分解推荐算法》这两篇文章中介绍了几种经典的协同过滤推荐算法。我们在本篇文章中会继续介绍三种思路非常简单朴素的协同过滤算法,这…

C++/C++11中引用的使用
引用(reference)是一种复合类型(compound type)。引用为对象起了另外一个名字,引用类型引用(refer to)另外一种类型。通过将声明符写成&d的形式来定义引用类型,其中d是声明的变量名。 一、一般引用:一般在初始化变量时,初始值…
node.js学习5--------------------- 返回html内容给浏览器
/*** http服务器的搭建,相当于php中的Apache或者java中的tomcat服务器*/ // 导包 const httprequire("http"); const fsrequire("fs"); //创建服务器 /*** 参数是一个回调函数,回调函数2个参数,1个是请求参数,一个是返回参数*/ let serverhttp.createServe…
内核分析阅读笔记
内核分析阅读笔记 include/Linux/stddef.h中macro offsetof define,list: #define offsetof(TYPE,MEMBER) ((size_t) &((TYPE *)0)->MEMBER) offsetof macro对于上述示例的展开剂分析:&((struct example_struct *)0)->list表示当结构example_struct正好在地址0上…

杨强教授力荐,快速部署落地深度学习应用的实践手册
香港科技大学计算机科学与工程学系讲座教授、国际人工智能联合会(IJCAI)理事会主席(2017—2019)、深圳前海微众银行首席AI 官 杨强为《深度学习模型及应用详解》一书撰序,他提到现在亟需一本介绍深度学习技术实践的图书…
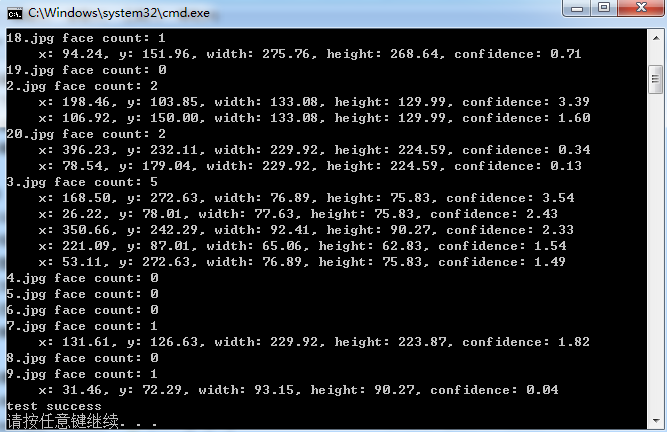
OpenFace库(Tadas Baltrusaitis)中基于HOG进行正脸人脸检测的测试代码
Tadas Baltrusaitis的OpenFace是一个开源的面部行为分析工具,它的源码可以从https://github.com/TadasBaltrusaitis/OpenFace下载。OpenFace主要包括面部关键点检测(facial landmard detection)、头部姿势估计(head pose estimation)、面部动作单元识别(facial acti…
nginx conf 文件配置
打印输出: location / { default_type text/plain; return 502 "$uri"; } $remode_addr 获取访问者的ID$request_method 判断提交方式 GET POST$http_user_agent 获取浏览器软件 if (条件) {} #if之后要有空格 条件3种写法: 1: 来判断相等,用于字符串比较 …
js中 字符串与Unicode 字符值序列的相互转换
一. 字符串转Unicode 字符值序列 var str "abcdef"; var codeArr []; for(var i0;i<str.length;i){codeArr.push(str.charCodeAt(i)); } console.log(codeArr);-->[97, 98, 99, 100, 101, 102] 二.Unicode 字符值序列转字符串 var str String.fromCharCode…
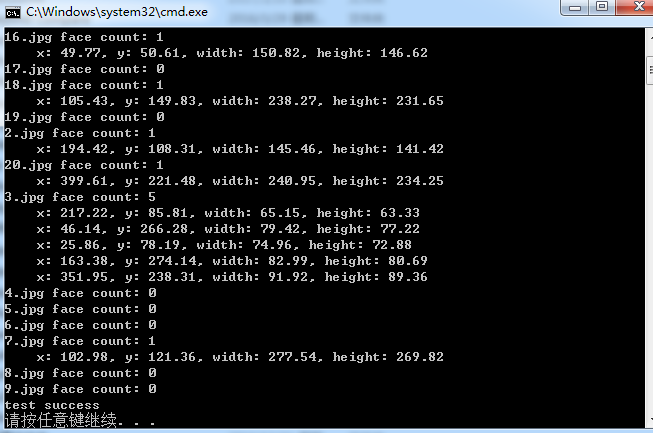
OpenFace库(Tadas Baltrusaitis)中基于Haar Cascade Classifiers进行人脸检测的测试代码
Tadas Baltrusaitis的OpenFace是一个开源的面部行为分析工具,它的源码可以从 https://github.com/TadasBaltrusaitis/OpenFace 下载。OpenFace主要包括面部关键点检测(facial landmard detection)、头部姿势估计(head pose estimation)、面部动作单元识别(facial a…

Uber提出损失变化分配方法LCA,揭秘神经网络“黑盒”
作者 | Janice Lan,Rosanne Liu等译者 | 清儿爸责编 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】神经网络(Neural networks,NN)在过去十年来硕果累累,推动了整个行业的机器学习进程。然而࿰…
范登读书解读《亲密关系》(婚姻、爱情) 笔记
来源:邀请你看《樊登解读《亲密关系》(已婚人士必看)》,https://url.cn/5HJvLk5?sfuri 人们在童年的时候始终追寻着两种东西,第一种叫做归属感,第二叫做确认自己的重要性、价值感。 如果再童年的时候缺失这…
myeclipse莫名其妙的问题
2019独角兽企业重金招聘Python工程师标准>>> 怎么刷新,clean项目都不管用,结果删除相应工作空间下的那个项目就行。类似路径如D:\workspace\.metadata\.plugins\org.eclipse.core.resources\.projects 转载于:https://my.oschina.net/u/14488…

数据科学家需要知道的5种图算法
作者:Rahul Agarwal编译:ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】因为图分析是数据科学家的未来。作为数据科学家,我们对pandas、SQL或任何其他关系数据库非常熟悉。我们习惯于将用户的属性以列的形式显示在…

在Windows7/10上快速搭建深度学习框架Caffe开发环境
之前在 http://blog.csdn.net/fengbingchun/article/details/50987353 中介绍过在Windows7上搭建Caffe开发环境的操作步骤,那时caffe的项目是和其它依赖项目分开的,每次换新的PC机时再次重新配置搭建还是很不方便,而且caffe的版本较老&#x…
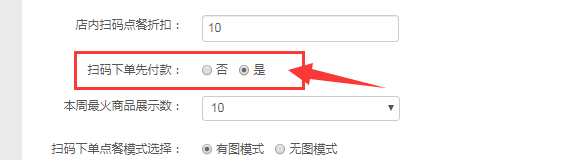
扫码下单支持同桌单人点餐FAQ
一、使用场景 满足较多商户希望同一桌台,各自点各自的菜品的业态场景(例如杭味面馆,黄焖鸡米饭店,面馆等大多数轻快餐店) 二、配置步骤及注意事项 管理员后台配置--配置管理--店铺配置--扫码点餐tab页 1、开启扫码下单…
使用photoshop 10.0制作符合社保要求的照片
2019独角兽企业重金招聘Python工程师标准>>> 北京市社保新参统人员照片修制方法 修改目标:照片规格:358像素(宽)×441像素(高),分辨率350dpi。 颜色模式:24位RGB真彩色。 储存格式&am…
C++11中std::addressof的使用
C11中的std::addressof获得一个对象的实际地址,即使 operator& 操作符已被重载。它常用于原本要使用 operator& 的地方,它接受一个参数,该参数为要获得地址的那个对象的引用。一般,若operator &()也被重载且不一致的话…

一份职位信息的精准推荐之旅,从AI底层架构说起
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】也许,每天早上你的邮箱中又多了一封职位推荐信息,点开一看,你可能发现这些推荐正合你意,于是按照这些信息,你顺利找到一份符合自己期待的…
Vue.js 生命周期
2019独角兽企业重金招聘Python工程师标准>>> 每个 Vue 实例在被创建之前都要经过一系列的初始化过程 vue在生命周期中有这些状态, beforeCreate,created,beforeMount,mounted,beforeUpdate,updated,beforeDestroy,destroyed。Vue在实例化的过程中&#x…
AX2009取销售订单的税额
直接用以下方法即可: Tax::calcTaxAmount(salesLine.TaxGroup, salesLine.TaxItemGroup, systemDateGet(), salesLine.CurrencyCode, salesParmLine.LineAmount, salesTable.taxModuleType()); salesParmLine.LineAmount:这个直接取的是装箱单或者发票…
Dubbo源码解析之服务路由策略
1. 简介 服务目录在刷新 Invoker 列表的过程中,会通过 Router 进行服务路由,筛选出符合路由规则的服务提供者。在详细分析服务路由的源码之前,先来介绍一下服务路由是什么。服务路由包含一条路由规则,路由规则决定了服务消费者的调…
C++中std::reverse和std::reverse_copy的使用
std::reverse:反转排序容器内指定范围中的元素。std::reverse_copy与std::reverse唯一的区别是:reverse_copy会将结果拷贝到另外一个容器中,而不影响原容器的内容。std::reverse: defined in header <algorithm>, reverses the order …

真相!30K拿到互联网大厂offer,网友:我服了!
最近笔者在知乎刷到一个帖子,其中,这条回答让人印象深刻:其实,最近几年人工智能大火,其中深度学习岗位的薪酬爆增,BAT大厂高薪招聘AI人才,收到的简历却寥寥无几?究竟是大厂岗位要求高…

OracleDesigner学习笔记1――安装篇
OracleDesigner学习笔记1――安装篇 QQ:King MSN:qiutianwhmsn.com Email:qqkinggmail.com 一. 前言 Oracle是当今最流行的关系型数据库之一,和很多朋友一样,我也是一个Oracle的爱好者,从…
C++/C++11中std::queue的使用
std::queue: 模板类queue定义在<queue>头文件中。队列(Queue)是一个容器适配器(Container adaptor)类型,被特别设计用来运行于FIFO(First-in first-out)场景,在该场景中,只能从容器一端添加(Insert)元素,而在另一端提取(Ext…
常见的http状态码(Http Status Code)
常见的http状态码:(收藏学习) 2**开头 (请求成功)表示成功处理了请求的状态代码。 200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。201 (已创…

“不给钱就删库”的勒索病毒, 程序员该如何防护?
作者 | 阿木,王洪鹏,运营有个人公众号新新生活志。目前任职网易云计算技术部高级工程师,近3年云计算从业经验,爱读书、爱写作、爱技术。责编 | 郭芮来源 | CSDN(ID:CSDNnews)近期一家名为ProPub…